
副词“就”的用法及其自动识别研究
2010-06-19 06:25昝红英张军珲朱学锋俞士汶
中文信息学报 2010年5期
昝红英,张军珲,朱学锋,俞士汶
(1.郑州大学信息工程学院,河南 郑州 450001;2.北京大学计算语言学教育部重点实验室,北京 100871)
1 引言
“就”在现代汉语中是一个复杂的词语。根据不同的上下文语境,“就”可以用作副词、介词、连词以及动词。下面例句选自文献[1]和[2]:
(1)足球联赛明天就开始。
(2)大家就创作方法进行了热烈的讨论。
(3)这东西他就拿了去也没用。
(4)花生仁儿就酒。
其中,(1)中的“就”为副词,即“就/d”,(2)中的“就”为介词,即“就/p”,(3)中的“就”为连词,即“就/c”,(4)中的“就”为动词,即“就/v”。一般来讲,词性的确定可以在一定程度上确认词义。但对“就”来讲,特别是对副词“就”,其语义的确定具有很高的复杂度,其用法灵活多变,并且在真实文本语料中具有很高的出现频率。
一般来讲,越是常用的词汇,用法越是多样,表现越是复杂。根据我们对1998年1月《人民日报》分词与词性标注语料库的统计,“就”一共出现了2586 次 ,其中“就/d”为2255 次,“就/p”为 324次,“就/v”为7次。可见,副词“就”在分布上占有绝对的优势,可见副词“就”对于与“就”相关的汉语句子语义研究的重要性。在我们目前构建的包括副词、介词、连词、助词以及语气词的现代汉语虚词知识库[4]中,共收录 1181 个副词的 2040 个用法,其中具有单个用法的副词有776个,而副词“就”则具有7个语义和21个用法,是用法数最多的副词,也是用法最复杂的副词之一。因此,副词“就”的用法研究对于整个副词的用法及汉语句子语法、语义的研究具有重要的推动作用。
本文旨在通过对副词“就”的用法分析及其在真实文本语料中用法的考察与计算,总结副词“就”的用法规律,进行有关用法规则的形式化描述以及用法规律的特征统计,从而在一定程度实现副词“就”用法的机器自动识别。
2 副词“就”的用法描述
从副词自身的特点来看,由于虚化程度不一,副词在整体上是一个比较混杂而模糊的集合。副词“就”则是用法最复杂的副词,也是现代汉语副词中用法最多变最灵活的副词。
2.1 面向人用的副词“就”用法描述
副词“就”是现代汉语中重要的虚词之一。根据文献[1](标记为<b>),并参考文献[2](标记为<h>)和文献[3](标记为<x>),以及1998年1月《人民日报》分词与词性标注语料库(标记为<r>)中副词“就”的统计分布以及其他语法学家有关论著中对副词“就”的用法描述,我们整理了副词“就”的7个义项,共21个用法,详见附表 A。
2.2 面向机器的副词“就”用法描述
面向人用的副词“就”的用法描述,不便于自然语言处理系统的直接应用,而且有时难以避免主观性和模糊性。为了进一步形式化严格地描述副词“就”的用法规律,我们对面向人用的研究结果进行了BNF规则的形式描述[5],但是对读音的区别(如用法<d_jiu4_4b>、<d_jiu4_4c>等)、“短语”(如用法<d_jiu4_5a>等)以及“小句”(如用法<d_jiu4_5c>等)目前仍不能进行准确的规则描述。近年来文献[7-9]对虚词用法知识库及虚词用法的自动识别进行了初步的研究。下面是副词“就”的用法规则样例,其中大写字母为指定用法的上下文特征,如F表示句首,M表示左合用,L表示左连用,R表示右连用,N表示右合用,E表示句尾;小写字母表示词性,汉字表示词形。符号标记含义详见文献[6]。

3 副词“就”的用法自动识别研究
为了适应自然语言处理的需求,根据对副词“就”用法的形式化描述以及对真实文本语料中副词“就”不同用法的语境考察,我们对副词“就”进行用法自动识别的研究。
3.1 基于规则的副词“就”用法自动识别研究
基于规则的方法具有简单、直观、针对性强等优点,但一般也有覆盖程度低、难于进一步优化等缺点。在面向机器的副词“就”的用法规则描述中,除了目前无法准确描述的读音、短语、小句等特征外,某些规则描述还有形式上或语法上的交叉现象。为保证规则识别具有较高的准确率,必须按照规则之间的互相包含或覆盖关系,将比较独立的规则或易于准确识别的用法规则赋予较高的优先级,即排在比较靠前的位置,以使得这些规则能以较高的优先级应用于句子中副词“就”的用法辨识。根据对现有虚词知识库中副词“就”各用法例句以及1998年1月《人民日报》分词与词性标注语料中副词“就”不同用法的上下文语境考察,我们将副词“就”的规则顺序进行了调整。利用调整后的副词“就”的用法规则描述,对现有虚词知识库中副词“就”的例句进行基于规则的自动识别研究[10]。实验结果表明,在副词“就”的7个义项、21个用法的75个例句(其中每个用法大致有3至5个例句)中正确识别的有54个例句,准确率是72%。
进一步,我们利用调整顺序后的副词“就”的用法规则对1998年1月《人民日报》分词与词性标注语料库中的副词“就”进行自动标注,实验结果表明,在语料中所有副词“就”的2255 个出现中正确识别的只有492个,准确率仅为21.82%,大大低于对例句的标注结果。这说明根据语言学家给出的有关用法的参考例句,我们人工总结得到的副词“就”的规则描述与在真实文本语料中的副词“就”用法语境相比,还有较大的差距,如何根据语料中用法的实际情况,不断调整和修正副词“就”的用法规则,是基于规则方法进行副词“就”用法自动识别需要解决的首要问题,也是我们目前正在建设的现代汉语虚词知识库中有关规则库建设的重要内容。
3.2 基于统计的副词“就”用法自动识别研究
基于统计的经验主义方法是从训练数据中自动地或半自动地获取语言知识,建立有效的统计语言模型。基于规则的理性主义方法在实际应用中的表现往往不如基于统计的经验主义方法好,这是因为基于统计的经验主义方法可以根据实际训练数据的情况不断优化[11],3.1节的实验结果也充分说明了规则方法对大规模语料的局限性。近年来,隐马尔科夫模型(Hidden Markov Model,HMM)、支持向量机(Support Vector Machine,SVM)、最大熵(Maximum Entropy,ME)以及条件随机场(Conditional Random Fields,CRF)等许多机器学习的统计模型在自然语言处理领域中得到了广泛的应用。
SVM是基于统计学习理论的学习方法,其准则是结构风险最小化。该方法通过使用一些策略来最大化具有不同特征的数据中间的界限,并针对数据的特征来判断该数据属于相应的类别。与通常的统计方法相比,SVM通过核函数变换的方式,将无法线性分类的低维空间中的样本映射到高维空间进行分类,这样很好地解决了有限数量样本的高维模型构造问题。SVM 尤其适用于小样本数据的学习,具有很好的推广能力,近年来广泛应用于文本分类、短语识别、词汇消歧、文本自动分类和信息过滤等自然语言处理领域。
ME模型是一个比较成熟的统计模型,广泛用于分类问题。其基本思想是,给定已知事件集,并在已知事件集上挖掘出潜在的约束条件,然后选择一种模型,这个模型必须满足已知的约束条件,同时对未知事件尽可能使其分布均匀。在自然语言处理应用方面,基于ME建立的语言模型不依赖于领域知识,独立于特定的任务,已经有许多重要的应用。在命名实体识别[12]、词性标注[13]、组块分析[14]、词义消歧、文本情感倾向分类等自然语言处理研究领域取得了较好的效果。
CRF是一个在给定输入节点条件下计算输出节点条件概率的无向图模型,它考察给定输入序列对应的标注序列的条件概率,训练目标是使得条件概率最大化。该模型没有隐马尔科夫模型的强独立性假设,同时还克服了最大熵马尔可夫模型标记偏置的缺点,在序列标注和分割方面有着出色的表现。CRF自从2001年由 Lafferty[15]提出以来,在分词与词性标注[16]、实体名识别[17]、句法分析[18-19]以及情感计算[20]等多个自然语言处理研究领域得到了有效的应用,并取得了不错的效果。
我们分别采用ME和CRF模型来研究副词“就”的用法自动识别问题。本文分别利用LibSVM工具包(http://www.csie.ntu.edu.tw/~cjlin/libsvm)、Zhang Le的最大熵工具包 maxent(http://homepages.inf.ed.ac.uk/s0450736/maxent_toolkit.html)以及CRF++工具包(CRF++:Yet Another Toolkit[CP/OL].http://www.chasen.org/~ taku/software/CRF++)作为自动标注工具。实验数据是1998年1月《人民日报》虚词用法标注语料库中人工校对后的副词“就”相关用法语句。为了研究基于统计方法的副词“就”用法的自动识别,我们对基于规则的自动标注的结果进行了多人交叉人工校对,形成副词“就”用法标注的标准语料。其中,副词“就”在 1998年1月《人民日报》虚词用法语料中的用法分布如表1所示。
由表1可以看出,副词“就”的用法在1998年1月《人民日报》真实文本语料中分布极为不均,为了统计方便,我们舍去了其中不足5次出现的用法,将其他含有副词“就”的句子按用法类别基本均匀地散列为5份数据集,采用5折交叉进行验证实验。标注系统的性能很大程度上取决于训练和测试模型所使用的特征,根据LibSVM、maxent和 CRF++的训练数据格式以及副词“就”用法的语境特点,实验中特征模板选取副词“就”前后n个词语的词形与词性,图1是副词“就”的用法自动识别分别在三种统计模型下的实验结果,其中横坐标1~6分别表示n取 2、3、4、5、6、7 时的结果 ,即上下文窗口的变换范围。从对比实验结果看,随着上下文有效范围的逐渐增大,识别效果并没有明显的递增。因此,在当前语料库的规模下,副词“就”的用法识别并不是上下文窗口越大越好,随着窗口的增大可能会给识别带来更大的噪音。

表1 语料库中副词“就”的用法分布
可见,统计模型在副词“就”的用法自动识别方面具有较好的适应性,相对于基于规则的自动标注的21.82%准确率,基于统计的自动标注在总体上取得较高的准确率,尤其是CRF模型得到了良好的结果。

图1 副词“就”的用法自动识别分别在三种统计模型下的实验结果
3.3 基于规则与基于统计的副词“就”用法自动识别结果分析
从上述实验结果我们看出,在目前所构建的副词“就”的用法规则库和用法语料库的基础上,基于统计的副词“就”的用法自动识别明显优于基于规则的副词“就”的用法自动识别。但是,我们就此还不能断言,关于副词“就”的用法识别,统计的方法一定优于规则的方法。经过对上述各种方法的结果进行细致的对比分析,我们发现基于统计和基于规则对于副词“就”用法的识别在某些具体用法的识别上一致率很低,它们针对具体的用法在识别结果上表现差异显著,具有各自明显的优势和不足。表2为基于CRF统计与基于规则对于1998年1月《人民日报》部分语料中部分用法多于5次出现的副词“就”用法识别结果对比。
从实验数据可以看出,尽管基于统计的方法总体上比基于规则的方法标注效果要好,但是规则与统计方法对于副词“就”用法的自动标注结果呈现各自明显不同的规律,一致率较低。例如,对于用法<d_jiu4_4a>,规则方法自动标注的准确率为26.04%(150/576),而基于CRF的统计方法自动标注的准确率为98.96%(570/576);对于用法<d_jiu4_4b>,规则方法自动标注的准确率为69.57%(48/69),而基于CRF的统计方法自动标注的准确率为8.70%(6/69)。因此,对于副词“就”用法的自动识别,虽然基于统计方法的结果明显优于基于规则方法的结果,但是二者的表现差异显著,且均有较大的改进空间。在现有工作的基础上,进而继续研究规则与统计相结合的副词“就”的用法自动识别,将会进一步推动副词“就”以及现代汉语虚词用法的自动识别研究。

表2 基于CRF统计和基于规则的副词“就”识别结果对比
4 结语及进一步工作
本文对副词“就”的用法分别进行了基于规则和基于统计的自动识别研究,从实验结果可以看出,它们具有各自的优点和不足。将规则与统计相结合,把现有的现代汉语虚词知识库中副词“就”的用法规则有机地融入机器学习模型中,不断提高副词“就”的自动识别准确率,将推动现代汉语其他虚词用法的自动识别研究,并有助于现代汉语文本内容的自动理解以及中文信息处理相关的自然语言处理领域的研究进展。
下一步我们计划尝试在规则方法中引用统计信息。即在虚词用法语料的基础上,统计各个用法的具体分布,用相对频率作为概率的估计值,并将概率信息附加在相应的规则上,对规则进行加权处理,以调整规则匹配的优先级,提高基于规则的副词“就”用法自动识别的准确率。同时,利用规则信息对基于统计的副词“就”用法自动识别结果的进行校正。在目前汉语虚词用法标注语料有限的情况下,有些稀有的用法会严重偏置或根本得不到训练数据。对于这种情况,一方面考虑在统计方法识别之前用准确率高的强势规则对某些用法进行预先标注,避免它们受统计分布的偏置影响;另一方面则考虑用适当的规则进行统计方法识别结果的后处理,以修正某些特殊用法的标注结果。另外,我们还计划在标准虚词用法标注语料的基础上,与自动标注的结果进行对比,采用错误驱动法对现有的规则进行自动校正,以及对某些目前难于形式化描述的用法进行有关规则的自动发现。
[1]吕叔湘.现代汉语八百词[M].北京:商务印书馆,1980.
[2]中国社会科学院语言研究所词典编辑室.现代汉语词典(第五版)[M].北京:商务印书馆,2007.
[3]张斌.现代汉语虚词词典[M].北京:商务印书馆,2005.
[4]昝红英,朱学锋.面向自然语言处理的汉语虚词研究与广义虚词知识库构建[J].当代语言学,2009,2:124-135.
[5]陈火旺.程序设计语言编译原理(第三版)[M].国防工业出版社,2001.
[6]昝红英,张坤丽,柴玉梅,等.现代汉语副词用法的形式化描述[C]//第八届汉语词汇语义学研讨会论文集.香港理工大学,2007.
[7]Hongying Zan,Junhui Zhang,Studies on Automatic Recognition of Chinese Adverb CAI's usages Based on Statistic[C]//Proceeding of the3th international conference on Natrual Language Processing and Knowledge Engineering.393-397.
[8]昝红英,张坤丽,柴玉梅,等.现代汉语虚词知识库的研究[J].中文信息学报,2007,21(5):107-111.
[9]Liping Hao,Hongying Zan,Kunli Zhang,Ming Fan.Research on Chinese Adverb Usage for Machine Recognition[C]//Proceedings of the 7thInternational Conference on Chinese Computing(ICCC2007),122-125.
[10]刘锐,昝红英,张坤丽.现代汉语副词用法的自动识别研究[J].计算机科学,2008(8A):172-174.
[11]宗成庆,统计自然语言处理[M].北京:清华大学出版社,2008.
[12]王江伟.基于最大熵模型的中文命名实体识别[D].南京理工大学,2005.
[13]黄德根.基于最大熵模型的汉语词性标注研究[D].大连理工大学,2008.
[14]李素建,刘群,杨志峰.基于最大熵模型的组块分析[J].计算机学报,2003(12):1722-1727.
[15]LaffertyJ,McCallum A,Pereira F.Conditional Random Fields:Probabilistic Models for Segmenting and Labeling Sequence Data[C]//Proceedings of the 18thICM L-01.2001:282-289.
[16]Zhao H,Huang C,Li M.An Improved Chinese Word Segmentation System with Conditional Random Field[C]//Proceedings of the Fifth SIGHAN Workshop on Chinese Language Processing(SIGHAN-5).2006:162-165.
[17]周俊生,戴新宇,尹存燕,陈家俊.基于条件随机场模型的中文机构名自动识别[J].电子学报,2006,(5):804-809.
[18]Sha F,Pereira F.Shallow Parsing with Conditional Random Fields[C]//Proceedings of Human Language Technology Conference and North American Chapter of the Association for Computational Linguistics(HLT—NAACI),2003.
[19]程月,陈小荷.基于条件随机场的汉语动宾搭配自动识别[J],中文信息学报,2009,23(1):9-15.
[20]刘康,赵军.基于层叠CRF模型的句子褒贬度分析研究[J].中文信息学报,2008,22(1):123-128.

附表A 副词“就”的义项及用法
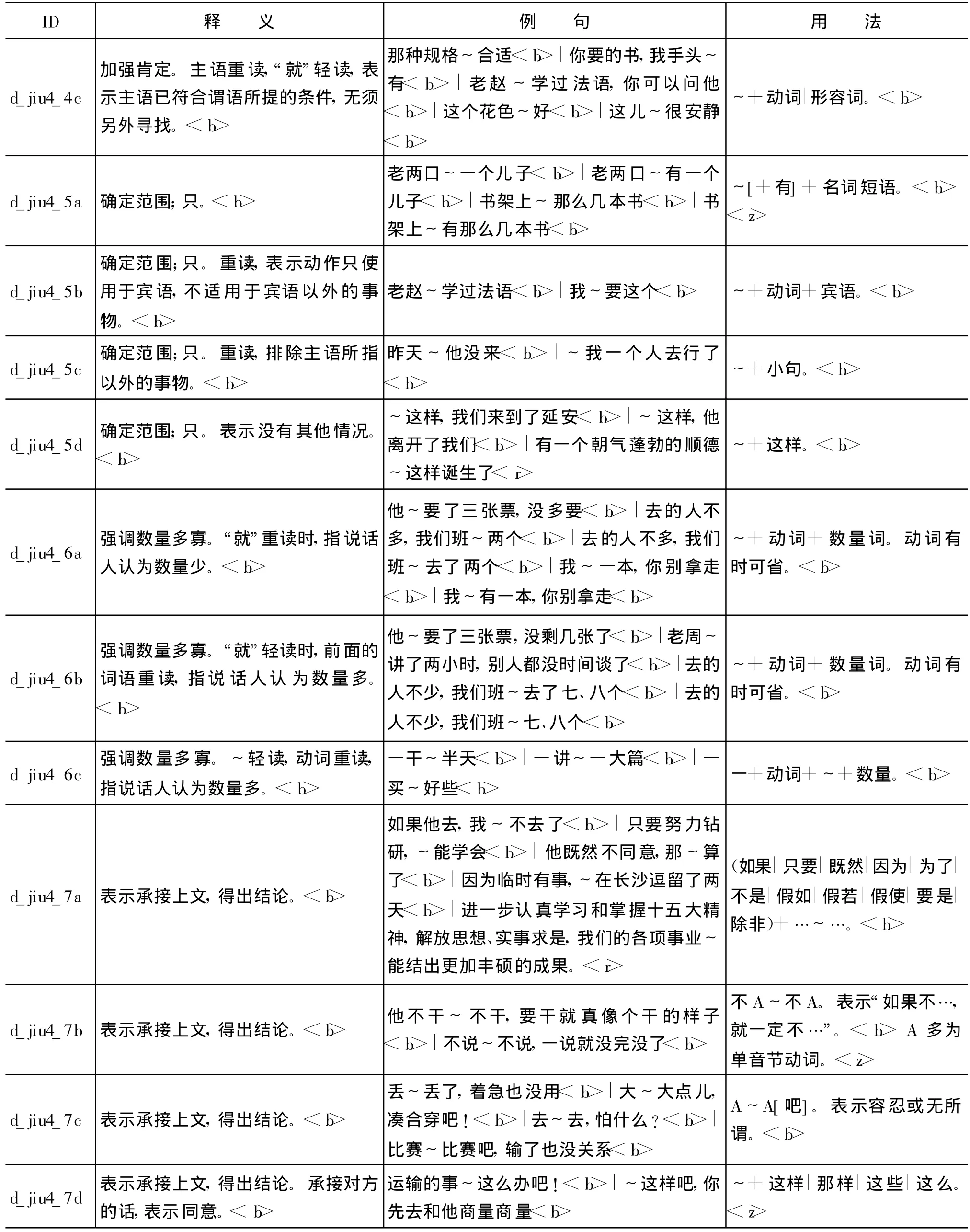
续表
猜你喜欢
舰船科学技术(2022年10期)2022-06-17
通信技术(2021年12期)2022-01-25
中国交通信息化(2019年7期)2019-10-08
水上消防(2019年3期)2019-08-20
中文信息学报(2019年7期)2019-08-05
特别健康(2018年3期)2018-07-04
文贝:比较文学与比较文化(2016年1期)2016-11-14
民族古籍研究(2014年0期)2014-10-27
环球人文地理(2014年14期)2014-08-15
外语教学理论与实践(2014年2期)2014-06-21
