
云计算与云数据管理
2010-06-11 11:03:42周奇年陈玲玲
电信科学 2010年1期
周奇年 ,陈玲玲 ,李 革
(1.浙江理工大学信息电子学院 杭州 310018;2.浙江理工大学机械与控制学院 杭州 310018)
1 引言
近年来,由于数据的快速增长以及用户对计算机计算能力的要求越来越高,如何提高普通计算机快速处理复杂问题的能力变成了一个极其重要的问题,为此,云计算应运而生。云计算能够改变普通用户使用计算机的模式,为用户提供按需分配的计算能力、存储能力及应用服务能力,目的是方便用户,大大降低用户的软、硬件采购费用[1]。
云计算中的“云”就是指计算机群,每一个机群都包括几十万台甚至上百万台计算机。在云计算中,用户所处理的数据并不存储在本地,而是存储在“云端”,所需的应用程序并不是运行在个人计算机上,而是运行在“云端”。用户可以通过任意一台连接到互联网的终端来访问 “云”中的数据以及使用“云”中的应用软件,而不必依赖某一台特定的计算机来访问处理自己的数据。云计算的应用无疑给我们的生活带来了许多方便,我们不会再有由于硬盘坏损、断电等造成资料丢失的困扰,也不用担心计算机病毒,因为“云”会为我们存储数据,并且将数据备份到不同的机架上,在“云”端有专业人员对应用程序进行维护升级。但是,由此带来的一些信息安全问题,我们也不能忽视,处理不好就会阻碍云计算的发展。
近年来,各知名IT企业都在大力开发和推进云计算,如IBM推出的 “蓝云”计划,亚马逊推出的弹性计算云(EC2)服务,Google推出Google Apps的企业服务平台等。目前,初步的云计算产品已经投入使用,但云计算还处在发展阶段,各项技术还不够成熟。
2 云计算的概念
云计算没有统一的定义,不同的企业可根据自己强调的云计算服务模式而给出不同的定义,但是云计算的最终目的还是服务用户。下面给出一种云计算的定义:云计算是由一系列可以动态升级和被虚拟化的资源组成,这些资源被所有云计算的用户共享,并且可以方便地通过网络访问,用户无需掌握云计算的技术,只需要按照个人或者团体的需要租赁云计算的资源[2]。在云计算中,用户通过虚拟平台来使用网络资源、计算资源以及存储资源等,这就相当于在操作自己的计算机。
云计算是对分布式处理、并行处理、网格计算及分布式数据库的改进处理,其前身是利用并行计算,解决大型文体的网格计算和将计算资源作为可计量的服务提供的功用计算,是在互联网宽带技术和虚拟化技术高速发展后萌生出来的[3]。云计算可为我们提供众多的服务,如SaaS(软件即服务)、PaaS(平台即服务)以及 MSP(管理服务提供商)等,这些服务都可使得用户更加专注于自己的创新,而不必担心一些繁琐的细节,极大地降低了成本。
3 两种典型的云数据管理技术
云计算的特点是要求云数据管理技术必须能管理大数据集,使得云数据管理具有一些共同的特点,如:计算资源的可伸缩性、数据具有备份以及数据存储在大量的分布节点上等。
3.1 BigTable技术
现行最著名的云数据管理技术是Google提出的BigTable技术。 BigTable是建立在GFS、Scheduler、LockService和MapReduce之上的一个大型的分布式数据库,它将所有数据都作为对象来处理,形成一个巨大的表格,用来结构化数据。Google给出了如下定义:“BigTable是一种为了管理结构化数据而设计的分布式存储系统,这些数据可以扩展到非常大的规模,例如在数千台商用服务器上的达到PB (Petabytes)规模的数据[4]。”现在,有很多Google的应用程序建立在BigTable之 上 ,例 如 Web Indexing、Personalized Search、Google Earth、Orkut和RSS 阅读器等。
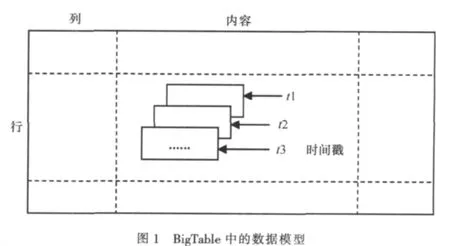
从结构上看,BigTable是一个有序、稀疏、多维度的映射表,在设计上具备很好的伸缩性以及高可用性等特点。主要包含三个基本元素,即行(row)、列(column)和时间戳(timestamps)。行是划分BigTable内容的标准,同时将多个行组成一个小表,保存到某一个服务器节点中,这一个小表就被称为Tablet;列名具有两层结构,即family:optional_qualifier,family是一个访问控制单元,与数据类型有关,为了增强可读性,optional_qualifier是在有必要时增加的索引;时间戳用来存储数据的不同版本。BigTable管理数据的存储结构为:(row:string,column:string,time:int64)→string。BigTable 中的数据模型如图1所示。
BigTable的实现主要由3个部分组成,即一个链接到每个客户端的库、一个主服务器和多个Tablet服务器。主服务器主要负责给Tablet服务器分配任务并使其达到负载平衡,探测Tablet服务器的添加或终结状态以及垃圾回收等。Tablet服务器可以被动态地添加或删除。每个Tablet服务器管理10到1 000个Tablet,它负责处理Tablet的读写请求,并将非常大的Tablet进行分割,以满足需要。在实现的过程中,客户端数据并不通过主服务器,而是直接与Tablet服务器进行交互。事实上,大部分的客户端并不与主服务器进行交互,而使得主服务器的负载很轻。
BigTable利用三层模型来存储Tablet的位置信息,如图2所示。
其中,Chubby中存储着Root tablet的位置信息,Root table中存储着Metadata tables中所有Tablet的位置信息,Root tablet是Metadata tables中的第一个表,且不会被分割,Metadata tables中存储着许多User Table的位置信息。因此,当用户读取数据时,需先从Chubby中读取Root tablet的位置信息,然后逐层往下读取,直至找到所需数据为止。

BigTable在执行任务时,在任意时刻每个Tablet只被分配到一个Tablet服务器,主服务器对Tablet服务器的活动状态进行监控,及时处理出现故障的服务器,同时也对未分配任务的记录板进行监控,并且清楚地知道当前Tablet服务器对Tablet的分配情况,以调节Tablet服务器的负载平衡。
3.2 Hadoop技术
Hadoop主要包括两个部分:Hadoop分布式文件系统(hadoop distributed file system,HDFS)和MapReduce编程模型。Hadoop设计时有以下几点的假设:服务器失效是正常的,存储和处理的数据是海量的,文件不会被频繁写入和修改,机柜内的数据传输速度大于机柜间的数据传输速度,在海量数据的情况下移动计算比移动数据更有效[1]。Hadoop文件系统的整体结构如图3所示。
由图3可知,HDFS是由一个Namenode(命名节点)和多个Datanode(数据节点)组成的。Namenode存储着文件系统的元数据,它的作用就像是文件系统的总指挥,维护文件系统命名空间、规范客户对于文件的存取和提供对于文件目录的操作;Datanode中存储着实际的数据,负责管理存储结点上的存储空间和来自客户的读写请求。Datanode也执行块创建、删除和来自Namenode的复制命令。
由于Hadoop将服务器失效看成是一种常态,因此,在大多数情况下,数据会有3个副本:HDFS采用的副本存放策略是将一个副本存储在本地机架的一个节点上,一个副本存储在同一机架的不同节点上,最后一个副本存储在不同机架的一个节点上。由于机架的错误远远比节点的错误少,这个策略不会影响到数据的可靠性和有效性。三分之一的副本在一个节点上,三分之二在一个机架上,其他保存在剩下的机架中,这一策略最大限度地避免了数据丢失及在节点失效后的恢复。在执行任务时,主节点会不断地通过心跳检测监控子节点的状态,并对子节点进行管理。

Hadoop在对数据处理上采用的是计算向存储迁移的策略,在Hadoop中由于有HDFS文件系统的支持,数据是分布存储在各个节点的,计算时各节点读取存储在自己节点上的数据进行处理,或将计算迁移到距离数据更近的位置,而不是将数据移动到应用程序运行的位置,从而避免了大量数据在网络上的传递,实现了“计算向存储迁移”。
4 云数据管理技术所要注意的问题
在云计算中,数据首先遇到的是数据分类问题,数据分类是将数据标志为是否需要分割存储的数据类型,如需分割,则将数据进行分割存储,分割信息存储在一个表中,分割的小数据块进行复制,存储在系统的不同地方。当有任务时,将分割的数据块进行整合,且计算向存储迁移,数据不需要在网络中传送,若正在执行任务的数据块的服务器损坏,则计算很快地被迁移到该数据块副本所在的服务器,如此循环,直至完成任务,系统汇总后将计算结果反馈给用户。具体过程如图4所示。
由此可知,在云计算中,对数据的主要操作有分类、分块、计算与存储,下面分别介绍数据副本的存放策略、文件的分块以及数据的隔离技术。
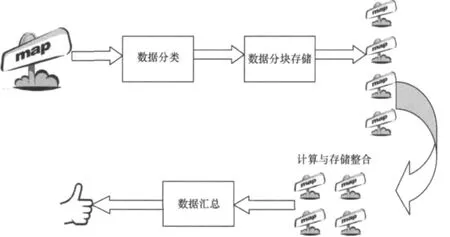
图4 数据在云计算中的“旅程”
4.1 数据副本的存放策略
由于在同一个云计算系统中存在着不同类型的客户(企业和个人)。不同用户对数据安全性的要求不一样,而且支付能力也不同,因此要求云计算系统能为不同用户提供不同级别的数据安全保障。可将计算机文件的安全级别划分为几个等级,如单机级、跨服务器级、跨机柜级以及跨数据中心级[1]。对于未实行分块存储的小型文件,可以考虑采用安全级别不高的单机级存储安全策略;而对于安全性要求高的文件,可以采用跨机柜级甚至是跨数据中心级的存储安全策略。采用何种安全级别,需根据用户对数据的不同要求而定,这体现了云计算按需服务的理念。
4.2 文件的分块技术
何时该对文件进行分块存储以及怎样分块,需由文件的上传和下载速度决定。对于小文件以及频繁存取的数据,我们可以不考虑分块,因为分块存储后反而会使系统的效率大大降低。文件实现分块存储的原因主要是利用各硬盘的读取速度,提高总体读取数据的速度,减少读取数据的时间。文件分块运算的地点是集群主服务器,由主服务器来维护文件的分块策略。
4.3 数据的隔离技术
在云计算中,数据都处于共享的环境中,在同一时刻,可能有许多用户在共享着同样的资源,要使这些用户在云计算平台中独立地运行而不出现数据和计算的交叉,数据的隔离技术显得至关重要。在云计算应用中,采用一种目录映射的单向指针分层用户隔离的方法,即通过设置文件目录同一层和不同层节点的访问权限来达到数据隔离的目的。
5 云数据管理展望
在云计算这种新型的商业模式下,公司和个人都可以进行存储空间和计算能力的租借,只需要一个简单的终端,而不需耗费大量的投资去构造和准备大规模的计算机设备。现有的存储系统和数据库系统都存在着缺陷,如扩展性不好、成本高等,因此,如何有效地存储和分析大规模的数据,如何在海量数据中找到特定的数据,变成了一个很有挑战性的技术问题,迫切需要新一代的云存储和云数据管理系统。同时,由于云存储和云数据管理通常要面临多种不同的应用,还需针对各种应用分别做出优化,可以说,云计算和云数据管理技术还有很长的路要走。
6 结束语
云计算具有广阔的应用前景、海量的存储、高速的计算和数据安全等特点,这些也是云计算在今后的发展中需要努力的方向。云计算根据按需服务的理念而设计,必将得到更大的发展。
1 王鹏.云计算的关键技术与应用示例.北京:人民邮电出版社,2010
2 云计算和云数据管理中面临的挑战,http://cloud.it168.com/a2010/0428/879/000000879838.shtml,2010
3 王鹏.走进云计算.北京:人民邮电出版社,2009
4 陈全,邓倩妮.云计算及其关键技术.计算机应用,2009,29(9):2 562~2 567
5 Chang F,Dean J,Ghemawat S,et al.BigTable:a distributed storage system forstructured data.ACM Transactions on Computer Systems,2008,26(2):1~26
6 Dean J,Ghemawat S.MapReduce: simplified data processing on large clusters.In:Proceedings of the 6th Symposium on Operating System Design and Imp Lementation.New York ACM Press,2004
7 Apache Hadoop,http://hadoop.apache.org,2009
8 曹强,黄建忠,万继光等.海量网络存储系统原理与设计.武汉:华中科技大学出版社,2010
9 孙少陵,罗治国,徐萌等.云计算及应用的研究与实现.电信工程技术与标准化,2009(11):2~7
10 葛慧.云计算的信息安全.硅谷,2009(2):42~43
猜你喜欢
汽车实用技术(2022年10期)2022-06-09 11:33:52
汽车实用技术(2022年5期)2022-04-02 09:36:52
海洋信息技术与应用(2021年2期)2021-11-02 06:59:10
铁道通信信号(2020年4期)2020-09-21 09:15:24
山东农业工程学院学报(2020年12期)2020-03-19 01:58:44
计算机系统应用(2019年2期)2019-04-10 05:08:46
计算机与生活(2016年11期)2016-11-22 02:07:32
湖州师范学院学报(2016年2期)2016-08-21 13:50:52
山西大同大学学报(自然科学版)(2016年6期)2016-01-30 08:29:19
地理与地理信息科学(2015年4期)2015-10-13 08:29:16
