
分数像素运动估计的VLSI结构设计*
2010-06-07 02:04王庆春何晓燕曹喜信
电视技术 2010年6期
王庆春,何晓燕,曹喜信
(1.安康学院 电子与信息技术研究中心,陕西 安康 725000;2.北京大学 软件与微电子学院,北京 102600)
1 引言
分数像素运动估计(Fractional Motion Estimation,FME)是H.264/AVC标准中实现帧间预测编码的重要技术,其主要功能包括分数像素插值、拉格朗日模式选取和运动补偿;虽然它对编码压缩性能有0.5~2 dB的提升[1],但由于其预测运算流程复杂,功能子模块多,实现结构复杂,硬件利用率低,成为H.264/AVC编码器芯片设计中的难点。为了提高编码器的硬件效率,FME的结构设计需要在设计方法上根据具体的系统需求,遵循面积和速度的平衡与互换设计原则,尽可能地通过功能模块复用来减小FME模块的硬件实现代价,开发出与之相适应的、高效的VLSI设计结构。
在H.264/AVC视频编码器的VLSI设计中,由于编码系统的目标档次、编码图像的大小和使用范围有较大差别,这就给FME的数据处理能力提出了不同的具体要求。只有针对具体编码需求的FME设计才是优化的;而不能盲目地追求运算速度或最小化面积。根据H.264/AVC的编码数据流程合理使用并行处理结构、时序串行和流水处理结构来优化设计FME的1/2像素运动估计、1/4像素运动估计、宏块编码模式选取(拉格朗日模式判断)和帧间运动补偿(MC)等4个基本功能模块,在芯片面积和编码速度之间寻求最佳的平衡。笔者针对不同的H.264/AVC视频编码系统,提出了4种FME的VLSI结构设计来满足不同的编码需求。
2 基于硬件实现的分数像素运动估计
H.264/AVC视频编解码标准中的帧间运动估计使用了可变块、多参考帧和率失真优化(RDO)技术而获得了较高的视频编码效率,同时这些复杂算法也使编码运算过程变得更加复杂[1-3]。这些技术具体到FME中,首先,要求在每个参考帧中对宏块的7种分割子块 (41个子块)依次进行1/2像素的运动估计和1/4像素的运动估计;然后,在1/4像素运动搜索结的基础上进行宏块编码模式选取 (8×8块编码模式和16×16块编码模式判断);最后,根据得到的最佳宏块编码模式再进行帧间运动补偿(亮度残差计算)。而且,上述的分数像素运动估计和宏块编码模式选取都是要通过计算率失真代价 (RD_cost)来完成的;这里的率失真代价计算不但包括了编码失真度SAD/SATD(绝对误差和/绝对变换差和),而且还要考虑编码运动矢量(Motion Vector,MV)的编码代价(编码比特数)、参考帧的编码代价和预测编码模式代价[2,4-5]。
在基于宏块(16×16)流水的H.264/AVC视频编码器芯片设计中,FME的VLSI设计主要面临着以下方面的挑战:首先,在分数像素运动估计过程中参与运算的数据量大。对于1个16×16宏块需要进行分数像素匹配运算的子块数目达到41×n个,n表示参考帧数目,并且子块的大小各异(4×4~16×16)。 对于多参考帧的视频编码系统,待运算的子块数会成倍增长,这就要求必要的并行处理结构来满足系统的编码运算速度需求。
其次,FME中的分数像素要求插值到1/4精度 (亮度信号),要先用6阶滤波器(FIR)完成1/2像素插值,再进行双线性1/4像素插值,插值后的数据量就会剧增。1个4×4子块(128 bit)对应的1/2像素匹配搜索区是9×9(648 bit),1/4 像素搜索区是 19×19(2888 bit),并且这些插值得到的分数像素会在1/2像素运估计、1/4像素运动估计和帧间运动补偿这3个过程中重复使用,所以尽可能利用过程数据复用就能有效减小硬件实现代价。
最后,宏块的编码模式选取(拉格朗日模式判断)过程极其复杂。这是因为宏块的编码模式选取是在得到所有参考帧的所有子块(41×n个)的1/4像素运动估计的率失真(RD_cost)代价后进行的,要在259种可能分割模式中确定出1种模式;并且宏块的编码模式选取又包括针对所有参考帧的16×16宏块编码模式选取和针对每个参考帧的8×8子块编码模式选取这2个过程,把这个宏块编码模式选取过程映射到VLSI硬件结构设计上也是一个难点。
3 FME的VLSI结构设计
3.1 全复用的FME结构
根据文献[5-6]中的复用设计思想,得到全复用的FME设计结构如图1所示,其中,1/2像素运动估计、1/4像素运动估计(包括宏块编码模式选取)和帧间运动补偿(MC)这3个数据处理阶段是完全顺序地进行的。在全复用的FME设计结构中,不同功能模块的选择组合就能实现不同阶段的运算。图1中的路径①完成了1/2像素运动估计;路径②完成了1/4像素运动估计和宏块的帧间编码模式选取;路径③实现了帧间的运动补偿,这样的设计使得1/2像素插值单元的硬件利用率达到100%(3个运算阶段复用),整个FME模块的运算速度都要受到它的制约;1/2像素运动估计和1/4像素运动估计复用了一个计算SATD的4×4块处理单元(PU)阵列(9个PU),分数像素运动矢量代价计算的硬件结构也是复用的。
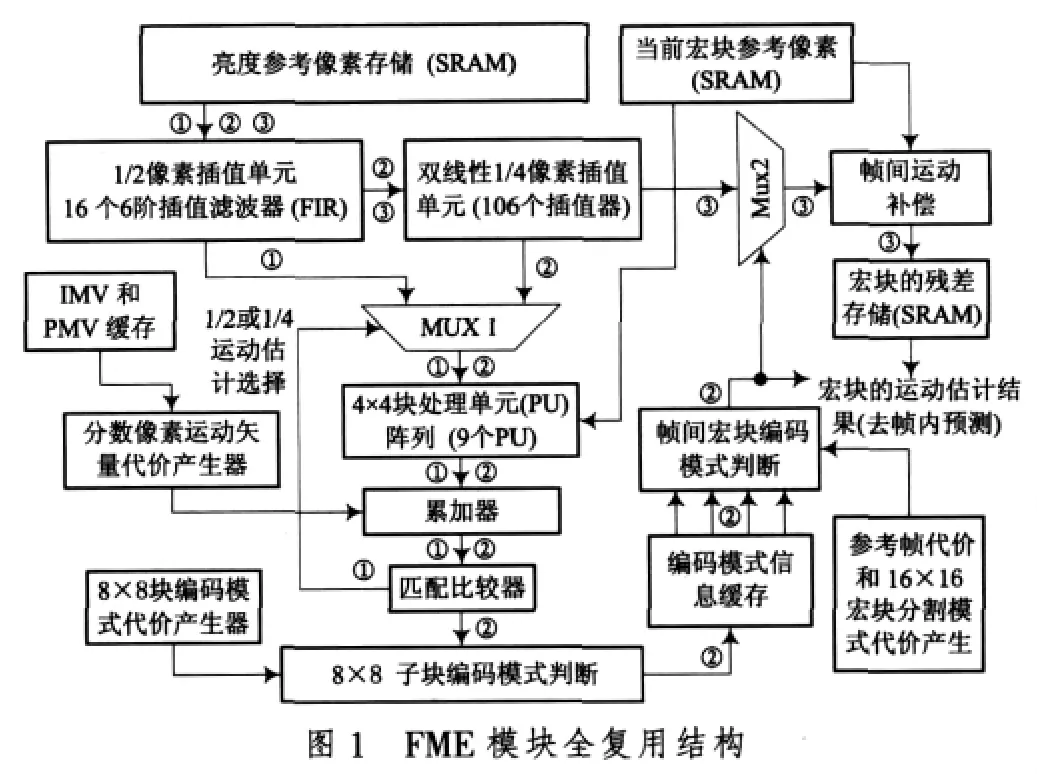
全复用FME结构虽然在每一步运动估计的内部采用了36倍数据并行度,PU阵列使用了9个处理单元PU(每个PU并行计算同一行上相邻4个像素的残差和变换)来并行计算9个分数像素匹配位置的失真度SATD值,但是FME的3个数据处理阶段是顺序执行的,因此这样的FME设计在数据处理能力上是很有限的,对于使用2个参考帧运动估计的H.264/AVC视频编码系统,完成FME至少就需要3488个时钟周期。如果要把它直接使用到H.264/AVC基本档次(level 3,4个参考帧)、CIF 图像格式(352×288)的实时(30 f/s)视频编码系统中,就要求有90 MHz以上的时钟频率。所以,这样的全复用结构FME比较适合于参考帧比较少的简单视频编码系统。如果在FME模块之前就解决了宏块匹配的多参考帧问题,这样的FME结构也完全能够应用到复杂的H.264/AVC视频编码系统中。
3.2 部分模块复用的FME结构
H.264/AVC视频编码器的FME要对每一个参考帧的41个子块(41个MV所对应41个子块)进行1/2像素、1/4像素运动估计和8×8子块编码模式选取,而16×16宏块模式选取和帧间运动补偿是在所有参考帧运算结果的基础上进行的[7],所以对不同参考帧进行的1/2像素、1/4像素运动估计、8×8子块编码模式选取可以采用并行处理结构来实现硬件加速,提出的FME结构如图2所示。这个结构中不同参考帧的数据处理是并行的,但是针对每个参考帧中41个子块的1/2像素运动估计和1/4像素运动估计还是复用的VLSI设计。
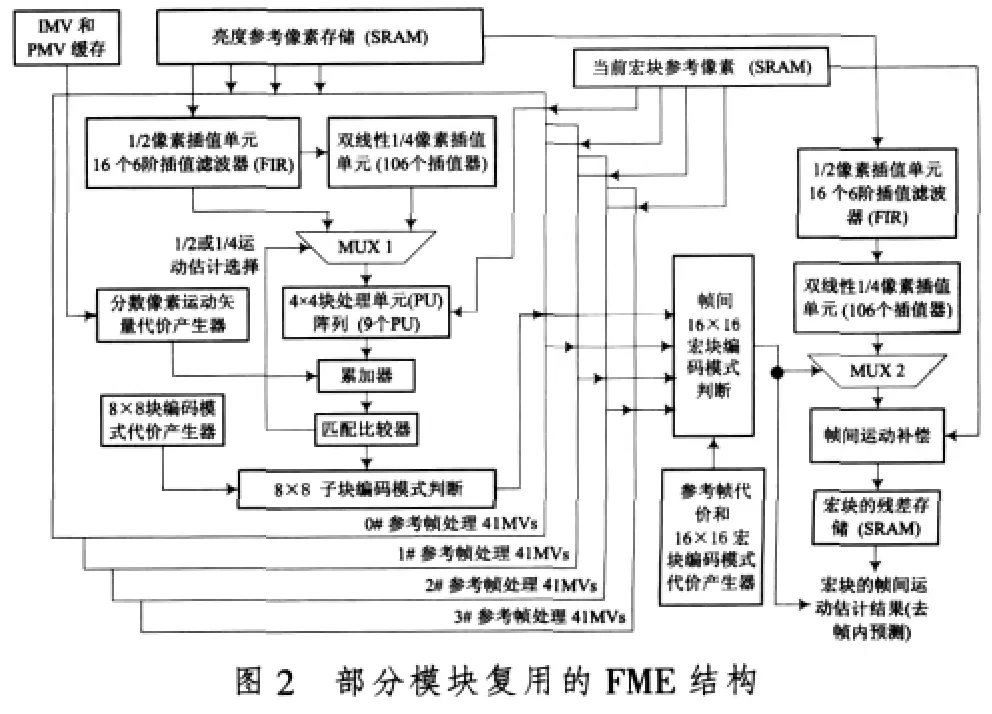
图2所示的FME结构是针对H.264/AVC基本档次(level 3,4个参考帧)的视频编码系统,4个参考帧的分数像素运动估计模块是并行的结构,而在每个模块的内部,1/2像素和1/4像素的运动估计单元又是结构复用的。在这个设计结构中的宏块编码模式选取和帧间运动补偿又是一个独立的结构 (各有独立的分数像素插值单元),这样的结构虽然硬件实现代价比较高、对参考像素存储器的访问带宽大,但是它的数据处理能力强、运算速度快,而且所能处理的参考帧数目也易于扩展(并行扩展并不改变FME的运算速度)。部分模块复用的FME结构对于2个参考帧的H.264/AVC视频编码系统,完成FME只需要1824个时钟周期。如果把它使用到H.264/AVC 基本档次(level 3,4 个参考帧)、CIF 图像格式(352×288)的实时(30 f/s)视频编码系统中,要求的最低时钟频率降低到22 MHz,这一点对降低芯片动态功耗是比较有利的。
3.3 流水处理的FME结构
FME中的1/2像素运动估计和1/4像素运动估计虽然在整体上来说是要求顺序执行的,但是具体到每一个参考帧内部41个子块的1/2像素运动估计和1/4像素运动估计又可以安排成流水的处理结构 (子块之间的流水处理),分成1/2像素运动估计和1/4像素运动估计两级流水线完成。这样可以很好地提高FME模块的数据吞吐能力,但是整个流水线的控制比较困难,如图3所示,在1/4像素运动估计流水级需要不定的等待时钟周期(出现流水线气泡)。

图4的流水FME结构和图2的FME结构相近,只是把图2中复用的分数像素运动估计部分替换成了基于流水的1/2像素运动估计和1/4像素运动估计。这样的结构可以使FME的使用周期数进一步缩短,对于2个参考帧的H.264/AVC视频编码系统,完成FME只需要1070个时钟周期。如果把它使用到H.264/AVC基本档次(level 3,4 个参考帧)、CIF 图像格式(352×288)的实时(30 f/s)视频编码系统中,要求的最低时钟频率降低到了13 MHz。这种设计结构会要求更高的硬件实现代价,对参考像素存储器(局部存储器)的访问带宽也会进一步加大,而且由于1/4像素运动估计需要有不定时钟周期数的等待时序(如图3所示),使得分数像素运动估计流水线控制变得比较困难。
3.4 基于数据缓存的FME结构
图4所示的FME流水结构中,1/2像素运动估计、1/4像素运动估计和帧间运动补偿都有独立的分数像素插值单元,但是从理论上讲,1/2插值像素可以在1/4像素运动估计中复用(1/4插值是在1/2插值数据的基础上进行的),1/4插值像素也可以在帧间运动补偿中复用。如果在FME设计中实现插值像素数据的复用,就可以降低参考像素存储器的访问带宽和插值单元的数目[8],图5是基于插值像素缓存的FME结构。
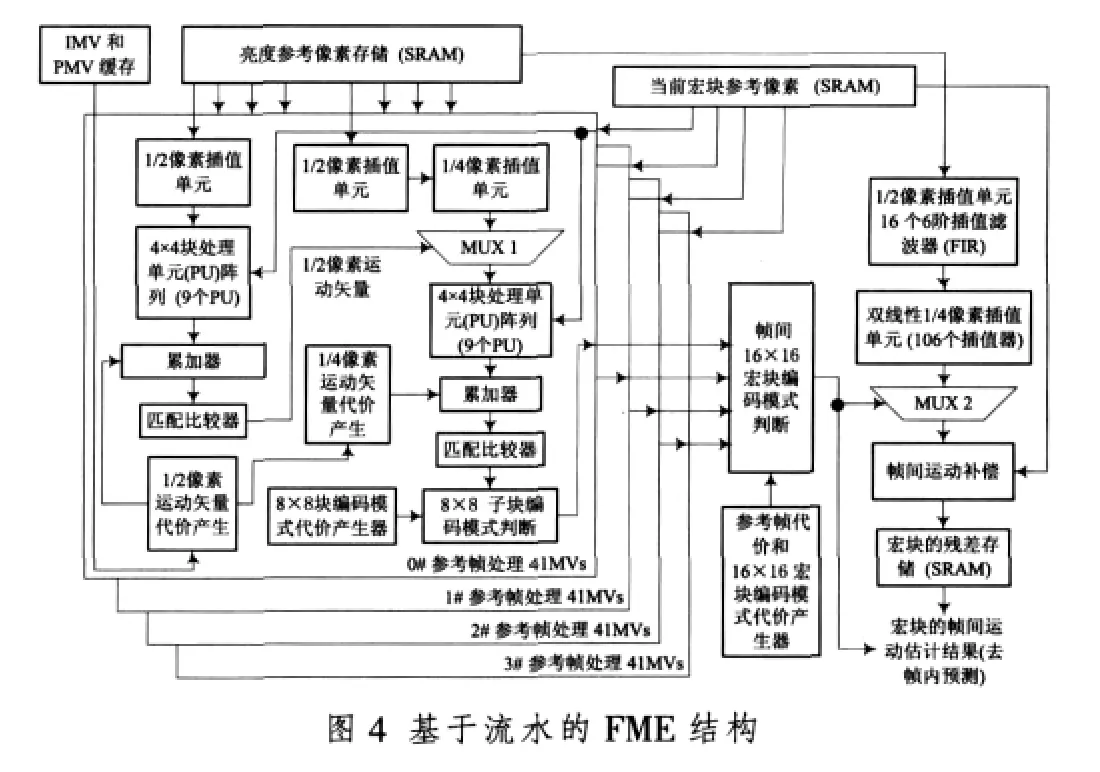

基于数据缓存的FME结构中,在1/2像素运动估计的同时要对1/2插值像素进行缓存;1/4像素运动估计的同时要对1/4插值像素进行缓存。1/2像素缓存数据的取出是要根据1/2像素运动估计的结果进行选择取出的;同样,1/4缓存数据也是要根据宏块编码模式的选取结果进行选择取出的,很明显这两个存储器的存储数据有很大的冗余;并且存储器的读写地址产生也是比较复杂的,但是这样的结构比较适合用FPGA来实现 (FPGA内部的内嵌RAM单元可以得到充分的利用)。从理论上讲,图5的FME结构的数据处理能力和图4的结构是一样的,它对于2个参考帧的H.264/AVC视频编码系统,完成FME也只需要1070个时钟周期。如果把它使用到H.264/AVC基本档次 (level 3,4个参考帧)、CIF图像格式(352×288)的实时(30 f/s)视频编码系统中,要求的最低时钟频率也降低到了13 MHz。
4 小结
笔者提出了全复用、部分模块复用、流水处理和数据缓存的4种FME的VLSI设计结构,其中全复用的FME处理结构硬件利用率最高,但数据吞吐量最小、速度最慢,只适合于参考帧比较少的低档次的H.264/AVC视频编码系统。基于流水处理和数据缓存的FME结构都属于高速并行处理的结构,都是以较高硬件代价来获得较高的数据处理能力,而前者需要复杂的流水线控制时序、后者需要更大的片内存储器。部分模块复用FME结构是高速和低代价之间的折中设计方案,整体结构中既有每一参考帧数据处理的复用,同时又有不同参考帧数据处理上并行特点,是一种中速的FME设计方案。
[1]Joint Video Team,Draft ITU-T Recommendation and Final DraftInternational Standard of Joint Video Specification,ITU-T Rec.H.264 and ISO/IEC 14496-10 AVC[S].2005.
[2]王庆春,何晓燕,曹喜信.H.264/AVC帧间宏块编码模式选择的VLSI设计[J].电视技术,2007,31(12):17-19.
[3]LIN Yu-kun,LIN Chia-chun,KUO Tzu-yun,et al.A hardware-efficient H.264/AVC motion-estimation design for high-definition video[J].IEEE Trans.Circuits and Systems,2008,55(6):1526-1535.
[4]王洪强,郝军.H.264帧间模式快速判决[J].电视技术,2006,30(6):10-12.
[5]OKTEM S,HAMZAOGLU I.An efficient hardware architecture for quarter-pixel accurate H.264 motion estimation[C]//Proc.the 10th Euromicro Conference on Digital System Design Architectures,Methods and Tools.Washington.DC.,USA:IEEE Computer Society,2007:444-447.
[6]CHEN T C,HUANG Y W,CHEN L G.Fully utilized and reusable architecture for fractional motion estimation of H.264/AVC[EB/OL].[2010-01-20].http://ieeexplore.ieee.org/Xplore/login.jsp?reload=true&url=http%3A%2F%2Fieeexplore.ieee.org%2Fiel5%2F9248%2F29347%2F01327034.pdf%3Farnumber%3D1327034&authDecision=-203.
[7]ZHAI Haihua,XI Zhiqi,CHEN Guanghua.VLSI implementation of subpixel interpolator for H.264/AVC encoder[C]//International Symposium on High Density packaging and Microsystem Integration,2007.Shang hai,China:[s.n.],2007:1-3.
[8]CHENTC,FANGHC,LIANCJr,etal.Algorithmanalysisandarchitecture design for HDTV applications:a look at the H.264/AVC video compressor system[EB/OL].[2010-01-20].http://ntur.lib.ntu.edu.tw/handle/246246/141460.
猜你喜欢
智能计算机与应用(2022年10期)2022-11-05
现代计算机(2021年36期)2021-03-14
西南石油大学学报(自然科学版)(2019年1期)2019-01-28
计算机应用(2018年12期)2019-01-07
电测与仪表(2016年10期)2016-04-12
电测与仪表(2016年14期)2016-04-11
化工学报(2015年11期)2015-09-08
电子设计工程(2015年24期)2015-08-26
电测与仪表(2014年11期)2014-04-04
郑州大学学报(理学版)(2013年3期)2013-03-11
