
基于关联规则的城市电力负荷预测模型智能推荐
2010-06-05 15:30杜柏均
天津大学学报(自然科学与工程技术版) 2010年12期
肖 峻,耿 芳,杜柏均,于 波
(1. 天津大学电力系统仿真控制教育部重点实验室,天津 300072;2. 天津市电力公司城西供电分公司,天津 300072)
基于关联规则的城市电力负荷预测模型智能推荐
肖 峻1,耿 芳2,杜柏均1,于 波1
(1. 天津大学电力系统仿真控制教育部重点实验室,天津 300072;2. 天津市电力公司城西供电分公司,天津 300072)
提出了一种基于关联规则的电力负荷预测模型智能推荐方法,解决了面对众多预测模型使决策者难以选择的问题.该方法首先建立预测模型与相关因素历史数据库,在此基础上进行关联规则挖掘,然后结合给定预测地区的相关因素条件,利用案例推理技术在挖掘出的规则中进行条件匹配,最终得出给定条件下各负荷预测模型对预测地区的适应情况并完成模型自动推荐.该方法充分利用国内42个城市预测案例积累的数据,通过数据挖掘并分析结果可以看出特定预测模型适用度与哪些相关因素有关,运用这些规则,得到合理的模型推荐结果.基于关联规则的适合模型推荐方法,不仅能自动分析模型适用度与各相关因素的内在联系,也能在一定程度上体现预测者对模型的偏好.通过我国某地区的负荷预测为例,说明了算法的正确性和可行性.
关联规则;负荷预测;模型;智能推荐
负荷预测是电网规划的基础工作,负荷预测的准确性直接影响电网规划质量.当前负荷预测更多采用计算机辅助决策系统,其核心就是利用一系列的负荷预测模型,根据已知数据进行中长期电力负荷预测[1].这些模型不仅包括各种单一模型[1],还有为提高预测精度的多种综合模型[2].当前国内开发的中长期负荷预测软件[3-5]中已经集成了大量负荷预测模型,常用的方式是尽量多地采用不同的模型预测,然后将各模型计算进行比较,最后经专家干预得到最终结果.随着模型的增多,预测者面临的问题是模型选择的困难,哪种模型更适合当前地区的负荷发展状况,实际工作中应选择哪些模型进行预测很难抉择.因此,研究负荷预测适合模型自动推荐的方法非常必要.
现有的适合模型推荐主要利用拟合精度的方法[6-7],即比较预测数据与历史数据的拟合精度,选择精度满足一定条件的模型.这种单纯依靠与历史数据的拟合精度来选择模型的方式是远远不够的.实际上,负荷发展规律是与本地区负荷特点与发展水平、产业结构、经济水平、气候条件等因素[8]密切相关的,而模型的选择与这些因素也密不可分.例如,已经趋向饱和的市中心负荷预测不适合采取那些快速增长的模型,而适合采用具有饱和特点的模型.此外,预测模型的选择还与预测者的偏好及本地习惯有关.因此,本文提出一种基于关联规则的城市负荷预测适合模型自动推荐方法.首先,积累大量城市的负荷历史数据(如电量、负荷、分类电量和分类负荷等)和相关因素历史数据(如气候、城市类型、产业比重等)以及以往规划中采用负荷预测模型的情况.其次,对各模型在各城市的预测结果进行适用性评估.然后,在此基础上建立城市负荷发展数据库,并通过数据挖掘分析相关因素与模型适用性之间关系,这些关系也能包含实际预测人员的偏好与习惯.最后,当有新的预测任务时,采用规则推理(rule-based reasoning,RBR)或案例推理(case-based reasoning,CBR)进行匹配,推荐出适合的模型.
关联规则分析的数据挖掘在电力市场营销、故障分析等研究中已有不少应用[9-10],在电力负荷预测与分析中也有应用[8],但用于负荷预测适合模型推荐方面还鲜见报道.本文首先介绍关联规则分析基本原理,再将其应用到对由城市负荷关联因素建立的数据库分析中,从而得到影响负荷的关联因素与负荷模型之间的关联关系.
1 关联规则分析的基本原理
在关联规则系统中,规则本身是“如果条件怎么样,那么结果或情况就如何”的简单形式,可以表示为“AB⇒”关联规则.
对于规则“A⇒B”,一般用支持度、可信度、期望可信度和作用度4个参数来描述一个关联规则属性.
设I={I1,I2,…,Im}是一组属性的全集,D是数据库.D中的每条记录T是一组属性,T∈I.关联规则是如下形式的一种蕴含:
1)支持度
支持度描述了A和B这2个属性集的并集C在所有事务中出现的概率有多大.

2)可信度
可信度就是指在出现了属性集A的事务T中,属性集B也同时出现的概率有多大.

3)期望可信度
期望可信度描述了在没有任何条件影响时,属性集B在所有事务中出现的概率有多大.
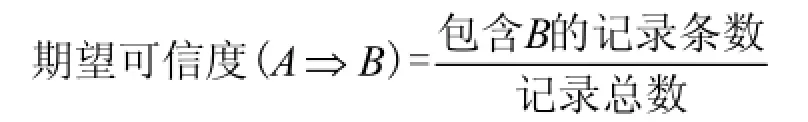
4)作用度
可信度与期望可信度的比值为作用度.
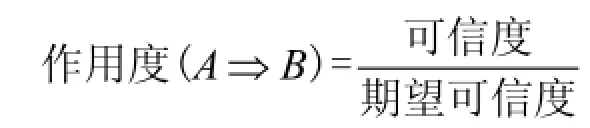
为了发现有意义的关联规则,需要给定2个阈值:最小支持度和最小可信度.前者用来描述关联规则的频繁性,如果规则的支持度大于最小支持度则认为此规则是频繁项集,否则为非频繁项集.同时满足最小支持度与最小可信度且作用度大于1的规则称为强关联规则.关联规则挖掘的目的就是从数据库中挖掘出满足用户要求的最小支持度与最小可信度的强关联规则.
2 城市负荷关联因素预测模型数据库
2.1 关联因素选取
影响城市电力负荷的相关因素有很多,目前得到的一些相关因素如表1所示.通过实际规划数据获得相关因素信息,通常有地区历史负荷数据、人口、产业比重、GDP发展水平、气候因素、预测年限、城市中心性以及城市职能等.选取相关因素时,要保证相关因素的连续性,不能出现间断,必要时要对相关因素进行补充.对于不同已有方案给定相关因素有所不同,但作为规划资料总有一些共性.为便于分析,在实际相关因素分析时通常采取的相关因素为人口数量、GDP发展水平、产业比重、温度、预测年限.
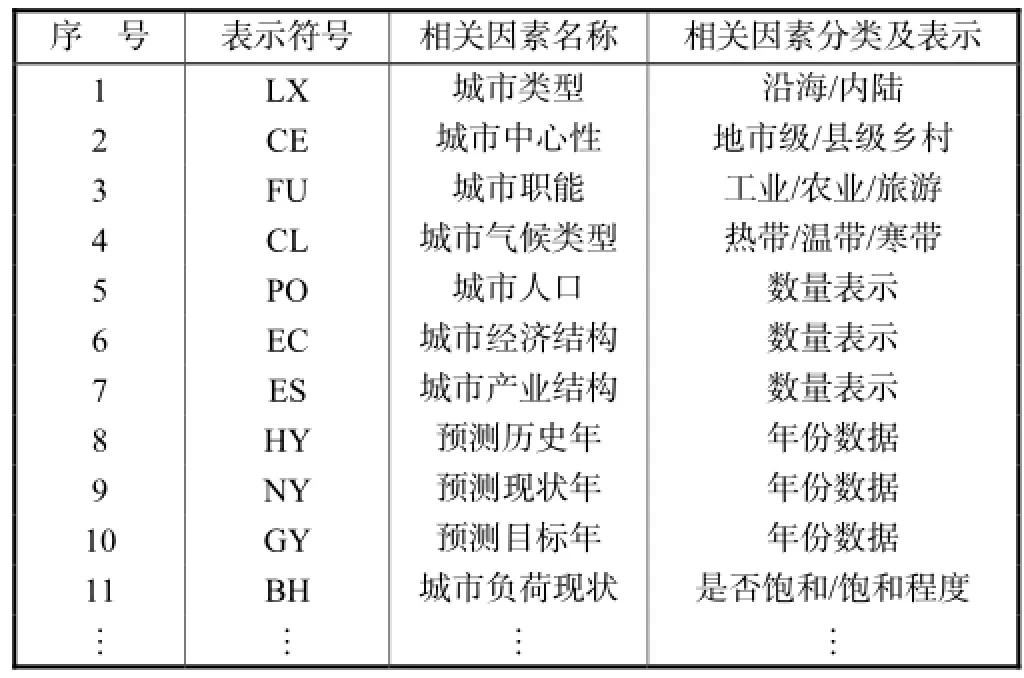
表1 城市负荷关联因素Tab.1 Correlative factors in urban power load
2.2 模型适用性评价
除上述选取的关联因素数据之外,建立预测模型数据库的另一部分数据是各模型使用情况.规划中实际使用的模型是专家根据当时预测地区特点选择的结果,并已反映了专家的偏好,这些选择结果可以作为适合模型选择的候选项.但是并非所有过去用过的模型在新的预测任务中都具有很好的预测效果,并且不能排除当时未采用过的模型.因此,在构建预测模型数据库时有必要进行模型适用性评价.
模型适用性评价首先从模型本身的要求出发,如某些模型必须要依靠相关因素才能进行预测,某些模型只适用于地区负荷已发生饱和的情况,这是模型的要求,根据预测地区现有条件能够直观地进行判断.其次,进一步采用传统的拟合精度方法.利用各模型对预测地区历史数据进行负荷预测,得到的各模型预测结果与已经发生的负荷变化趋势进行拟合,用实际发生的负荷对预测结果进行校验.再筛选出拟合精度较高的模型作为选用的预测模型,综合以上过程即完成了模型的适用性评价,得到更为准确的模型应用结论.本文中,将各模型对预测地区的适用程度进行定量划分,作为一种相关因素进行考虑.根据前述预测精度和专家干预结果,设置模型适用程度取值为0~1之间,其中0表示模型不适用于给定条件下的预测,1表示给定条件下模型适用,而设置大于0小于1的数字表示模型对该地区的适用度,可参考实际的拟合精度和经验进行设置.
综上,建立关联因素预测模型原始数据库,部分库模式见表2,表2中的横向记录和纵向记录均可以扩充.在此基础上进行相关因素与模型使用情况的关联规则挖掘,从而得到目标规则库.
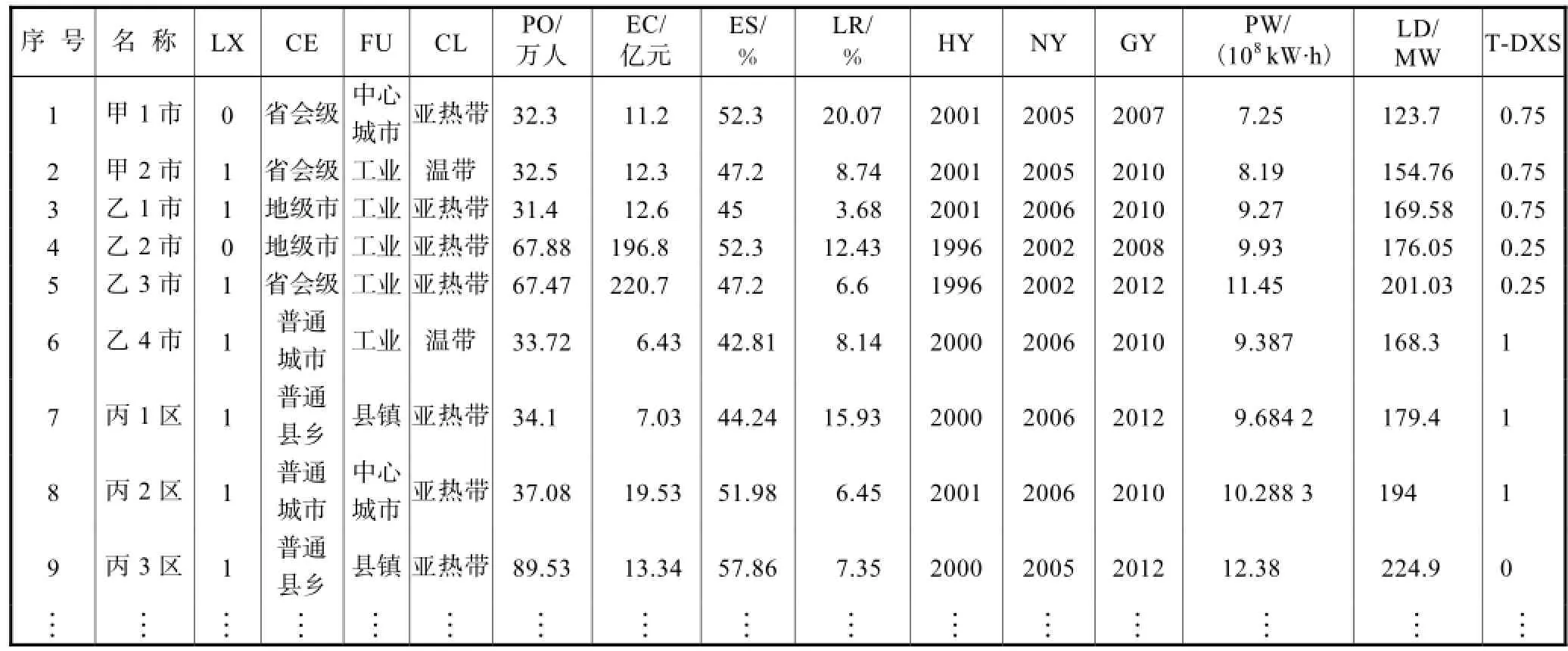
表2 城市负荷关联因素预测模型历史数据库Tab.2 History database for forecasting models of urban power load using correlative factors
3 基于关联规则的适合模型推荐
3.1 总体流程
进行适合模型推荐,首先要建立历史数据库,其中包含各相关因素数据和经过模型适用性评价后的模型适用情况,以一个模型为目标结合所有历史相关因素进行数据概化;然后进行相关因素与模型适用情况的关联规则挖掘,得到符合条件的关联规则;最终针对目标模型进行规则匹配,将给定的条件放于历史数据库中,在与历史数据相同的参考标准下进行给定条件数据概化,将已知分级数据与挖掘出的规则进行规则匹配,能够得到目标模型的适用结论.其中数据概化、规则挖掘和规则匹配在实际中均是以一种模型为目标进行研究,根据历史数据库对于其他模型进行相同的研究过程即可得到各个模型在给定条件下的适用情况.总体流程如图1所示.
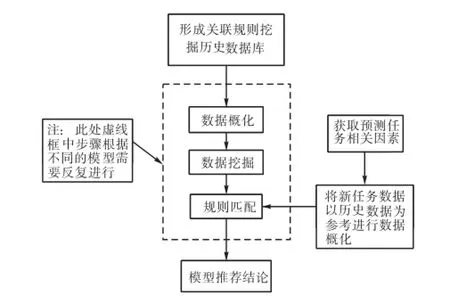
图1 总体流程Fig.1 Flow chart of the whole process
3.2 数据分析和概化
通过查阅资料,不需量化的相关因素已经有一定的划分依据;定量数据分析和数据概化主要采用kmeans聚类算法,不需要外界设定聚类中心,但需要设定聚类中心个数.本文算法设定聚类中心个数为5,根据历史数据动态计算各聚类中心,从而可将已有数据进行等级划分,得到概化后的数据库,即关联规则挖掘算法直接作用的数据库.库中各相关因素都采用不同字母表示,如表3所示.
3.3 关联规则挖掘
关联规则挖掘是针对概化后的数据,实质上是找出负荷预测模型与城市相关因素数据适用程度的关系,并形成满足最小支持度和最小可信度且其作用度大于1的关联规则库.其核心计算采用的是FPGrowth算法,基本思想是将历史数据库中的数据高度压缩到一棵树中,被压缩的数据仍然保存着原有的信息,然后用模式增长的方法生成频繁项集,进而产生关联规则.FP-Growth算法可以分为2个阶段:第1个阶段是搜索所有的频繁项集,并形成一棵树;第2个阶段是根据设定的最小支持度和最小可信度生成需要的关联规则.目前阈值设定有2种方法:一种是在规则形成的每一层设定不同阈值,另一种是整个算法设定唯一值.此处为简便起见,设定唯一的阈值标准.由于所有规则本身都存在支持度、可信度的上限和下限,这是用户进行设定的直接依据.若想得到较多的规则,则主要参考规则中支持度和可信度的下限,反之则参考上限.其中第1阶段是算法的核心.
最终得到的关联规则形如R0_E2:T4,表示对应相关因素为R0和E2的条件时,目标模型适用情况为T4.相关因素用符号“_”连接,并用冒号与模型是否应用的结论相隔,这为后续的模型匹配挖掘出最终模型使用情况奠定了基础.

表3 城市负荷关联因素预测模型数据库Tab.3 History database after data staging for forecasting models of urban load using correlative factors
3.4 规则匹配
对于新的预测任务,将其已知数据按照历史数据库中各聚类中心进行数据概化,得到各相关因素划分等级后的结论.如分别为R1和P4时表示为R1_P4,这样该地区的相关因素现状水平能够获得,并将此作为已知条件与上述数据挖掘得到的关联规则库中规则进行匹配.利用CBR原理,得出模型使用情况的结论.CBR是一种相似或类比的推理方法,它是通过访问知识库中过去同类问题的求解从而获得当前问题解决方案的一种推理模式,即利用旧的事例或经验来解决新问题,评价新问题,解释异常情况或理解新情况.本文的适合模型推荐有效地利用了这一方法.
规则匹配有以下3种情况.
(1)若规则库中只有一条相匹配的结论,则将此匹配条件对应的模型应用情况推荐出来.
(2)若规则库中含有多条与已知条件相同的匹配条件,则按照支持度和关联度由高至低排序,直接将支持度最高的规则作为最终结论.
(3)若规则库中未含有与已知条件相匹配的相关条件,则直接给出提示“当前历史方案库中无此匹配条件”.此时可以尝试用其他机制来获取推荐模型,如拟合机制等.匹配流程如图2所示.
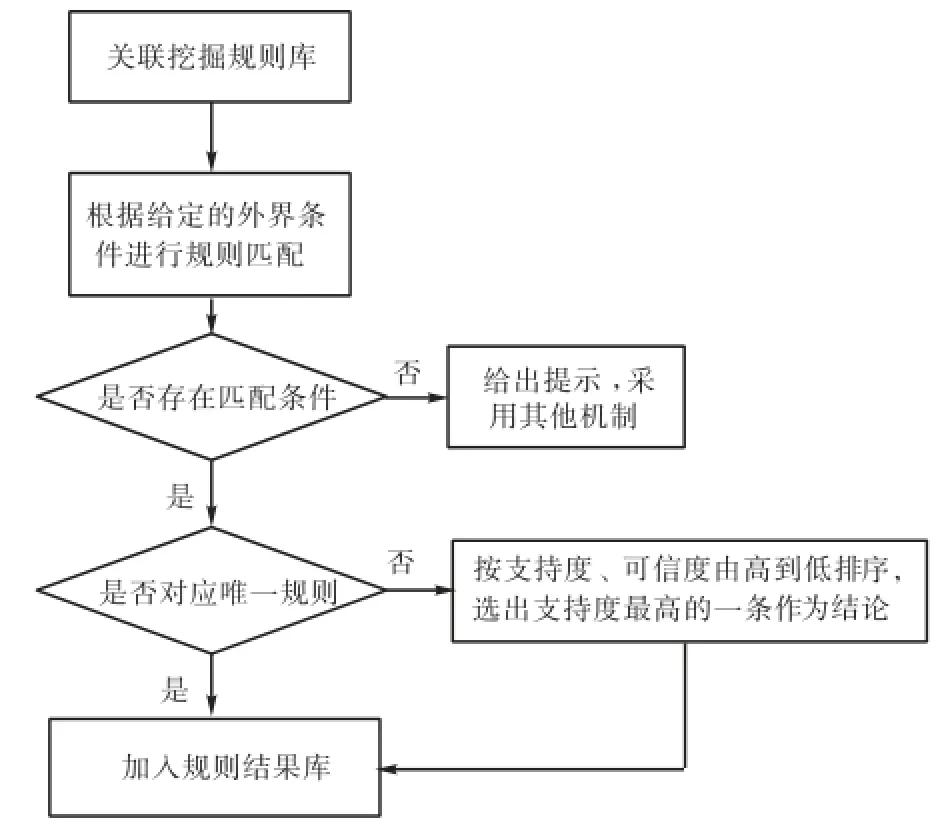
图2 CBR规则匹配流程Fig.2 Flow chart of rules matching with CBR
4 算 例
选用中国多个城市电网规划文本数据作为案例,应用本文方法对我国某地区的负荷预测进行适合模型推荐.以多项式模型的关联规则分析为例,其他模型的分析可采用相同步骤得到.
4.1 历史案例数据库建立
本文选取的城市具有一定的代表性,有的城市位于沿海,有的位于内陆;有的城市是经济发展中心,有的城市以农业生产为主;有的城市是省会级,有的是地县级.数据库中总的历史数据来自国内42个城市地区,为简化算例,选取相关因素为城市人口数量、GDP发展水平、第二产业比重,并将预测模型应用程度也作为相关因素考虑.进行模型适用性评价后,初步形成历史数据库如表4所示.
由表4可以看出,对于研究的目标模型(多项式模型)在给定的已知条件下,只有方案9所对应地区未采用目标模型,适用度为0,其余方案对应地区都采用了目标模型,但对多项式模型的依赖程度不同,方案6~8是完全应用目标模型,设置定量数据为1,方案1~3对模型的依赖程度为0.75,其余方案的依赖程度设定为0.25.这些原始数据用来作为后续关联规则挖掘的基础.
4.2 数据聚类分析和概化
对原始数据进行数据概化之后即将原始数据划分为一定的等级,并用不同的字母表示,对于表4中的数据进行数据概化之后得到关联规则挖掘直接作用的数据库,部分数据如表5所示.
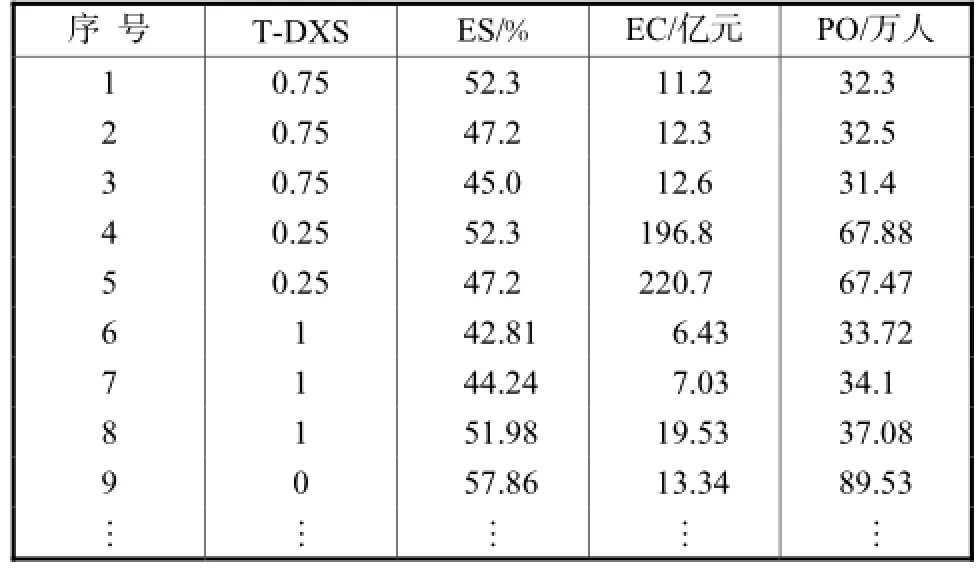
表4 城市负荷关联因素模型推荐历史数据库Tab.4 History database for demonstration for models of Tab.4 urban load using correlative factors
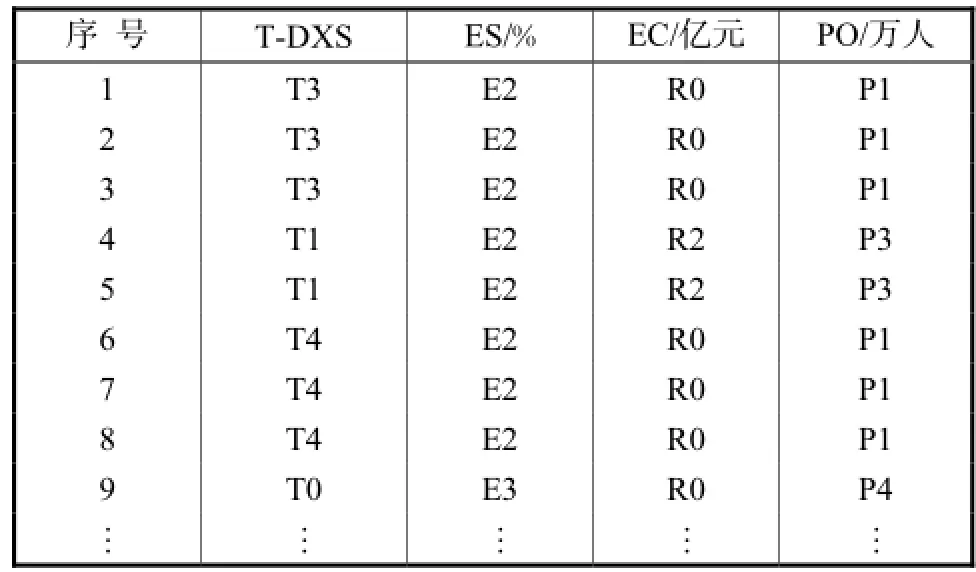
表5 数据概化后的原始数据库Tab.5 Original database after data staging for demonstra-Tab.5 tion
4.3 关联规则库建立
以数据概化后数据为目标进行关联规则挖掘.此时设最小可信度为0.1,最小支持度为0.02,加之满足作用度大于1的条件下,可以得到132条有效的强关联规则,如表6所示.
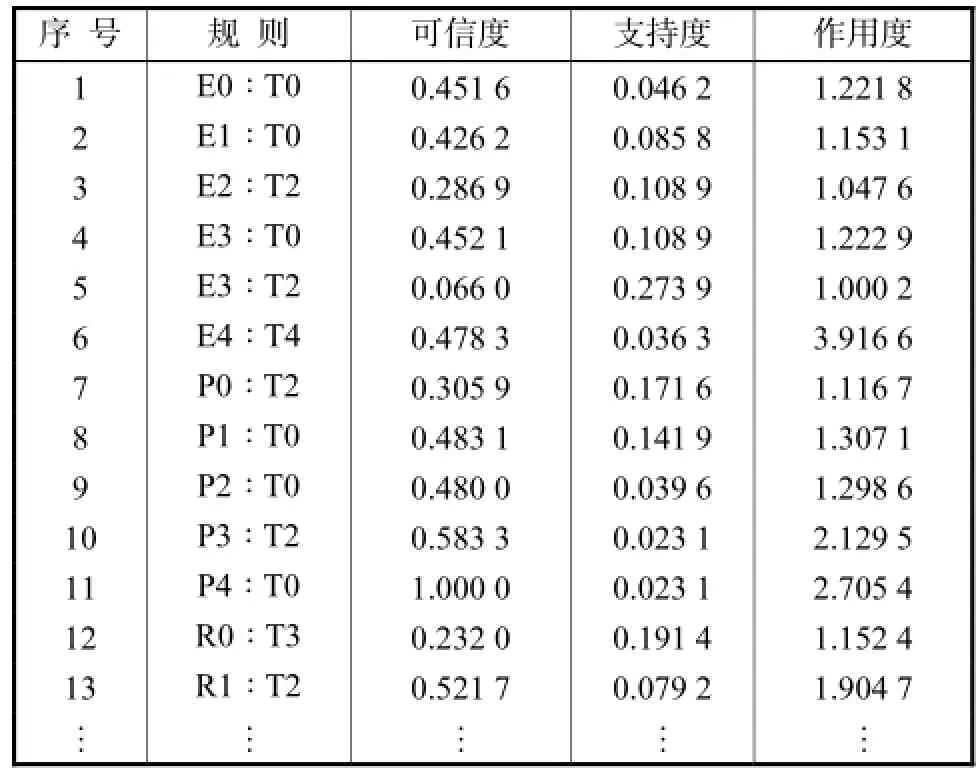
表6 关联规则库Tab.6 Database for correlation rules
4.3.1 单因素规则分析
通过对得到的132条强关联规则进行分析,可以得到第二产业比重、人口、GDP与多项式模型适用程度的关系.下面以GDP生产水平与多项式模型应用情况的关系为例进行说明.
经过挖掘分析,得到GDP生产水平与多项式模型关联规则.
(1)规则1——R0∶T3.
(2)规则2——R1∶T2.
(3)规则3——R2∶T0,支持度0.009 9,可信度1.000 0.
(4)规则4——R3∶T0,支持度0.009 9,可信度1.000 0.
(5)规则5—— R4∶T0,支持度0.003 3,可信度1.000 0.
由规则1和规则2可知当GDP生产水平较低时,多项式模型适用.为了进一步验证,规则3、4、5是降低支持度后得到的潜在规则,随着GDP水平增高,多项式模型总是处于最低的适用程度,即多项式模型更适于在GDP较低的城市进行预测.
综合各单因素分析结果可以初步看出,GDP和模型的应用有着强相关关系,在不需要滤除一些规则的情况下就有明显的规律.而第二产业比重、人口与多项式模型之间的相关关系,由于原始数据中的人口和第二产业比重数据,或多或少的有根据外来资料补充,必然会导致规则的细微偏差,需要滤除个别规则才能得到.
4.3.2 多因素规则分析
以人口和GDP与多项式模型应用情况的关系为例,经过挖掘分析,得到人口和GDP与多项式模型关联规则.
(1)规则1——R0_P0∶T3,支持度0.132 0,可信度0.263 2.
(2)规则2——R1_P0∶T2,支持度0.036 3,可信度0.611 1.
(3)规则3——R1_P3∶T2,支持度0.023 1,可信度1.000 0.
综上所述,由规则1、2可知人口不变的情况下,GDP的变化使多项式模型的适用度改变;由规则2、3可知,在GDP水平一定的条件下,人口的变化不会导致多项式模型适用程度的变化.GDP和人口2个相关因素中,GDP对多模型的适用度起主导作用,其中也暗含了单一因素的规则,GDP水平越高,多项式模型的适用程度越低.
综上分析第二产业比重、人口、GDP与多项式模型适用程度的关系可以得到,第二产业比重在决定多项式模型是否适用的过程中起关键作用,GDP次之,人口的决定作用最小.多项式模型适用于GDP较低、人口较少、第二产业比例较大的城市.
4.4 关联规则匹配与模型推荐结果
以上仅是对多项式模型的分析,当前负荷预测算法达30余种,对每种预测模型,改变数据库中模型适用度,重复上述数据概化和关联规则挖掘过程,可以得到每种模型对应的关联规则.对多项式模型,得到关联规则为E2_P1_R1∶T0.
将本算例中该地区的已知相关因素放于历史数据库中参与数据概化,得到概化条件为E2_P1_R1.用该条件在各模型关联规则结果中进行匹配,得到该地区各模型的适用度.本算例部分结果如表7所示.
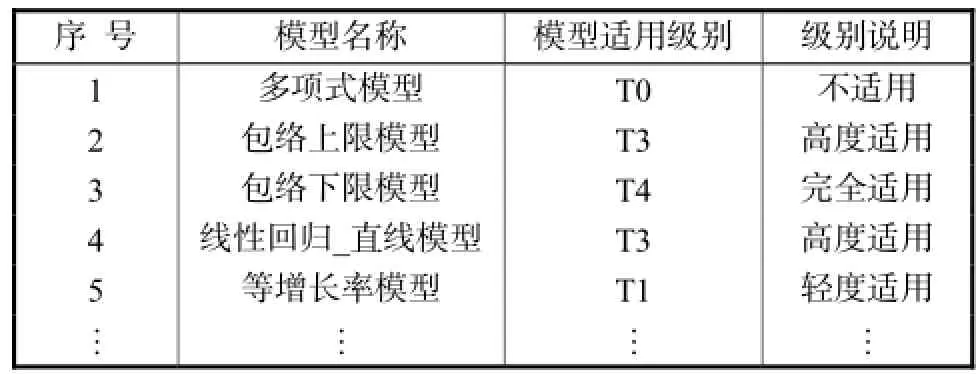
表7 算例模型推荐结果Tab.7 Results of case models for demonstration
5 结 语
结合电力行业的特殊性,将关联规则应用于负荷预测模型的选取分析中,提出了运用数据挖掘技术中的关联规则对电力负荷预测模型进行分析的基本思路和具体的解决方案.在实际预测工作中,人工可以大致判断是否采用某模型.本文方法优点在于不依赖于单个专家,能够综合大量专家的经验,并且通过大量预测数据的积累和数据挖掘,发现人直观不易发现的规则.
构造了以城市电力负荷模型适应情况及影响电力负荷相关因素为主题的历史方案库;通过分析大量城市的实际规划数据,得出具有启发性的关联规则,减少了人工工作量;构建理想数据进行预埋规则挖掘,验证本文方法的有效性和正确性.
[1] 刘晨晖. 电力系统负荷预报理论与方法[M]. 哈尔滨:哈尔滨工业大学出版社,1987. Liu Chenhui. Theory and Method of Power System Load Forecasting[M]. Harbin:Harbin Institute of TechnologyPress,1987 (in Chinese).
[2] 谢敬东,唐国庆,徐高飞,等. 组合预测方法在电力负荷预测中的应用[J]. 中国电力,1998,31(6):3-5. Xie Jingdong,Tang Guoqing,Xu Gaofei,et al. The application of the combined forecasting method in the power load forecast[J]. Electric Power,1998,31(6):3-5 (in Chinese).
[3] 黄 伟,费维刚,王炳革,等. 电力系统中长期负荷预测软件包的实现[J]. 现代电力,1999,16(1):52-56. Huang Wei,Fei Weigang,Wang Bingge,et al. Implement of power system mid-long term load forecasting software package[J]. Modern Electric Power,1999,16(1):52-56 (in Chinese).
[4] 虞 瑄,程浩忠,游仕洪,等. 中长期电力负荷预测软件包的开发与应用[J]. 电力系统及其自动化学报,2004,16(2):9-12,57. Yu Xuan,Cheng Haozhong,You Shihong,et al. Development and application of power system mid-long term load forecasting software package[J]. Proceedings of the EPSA,2004,16(2):9-12,57(in Chinese) .
[5] 余贻鑫,王成山,肖 峻,等. 城网规划计算机辅助决策系统[J].电力系统自动化,2000,24(15):59-62. Yu Yixin,Wang Chengshan,Xiao Jun,et al. Computer decision-making support system for urban power distribution network planning[J]. Automation of Electric Power Systems,2000,24(15):59-62(in Chinese).
[6] 朱成骐,孙宏斌,张伯明. 基于最大信息熵原理的短期负荷预测综合模型[J]. 中国电机工程学报,2005,25(19):1-6. Zhu Chengqi,Sun Hongbin,Zhang Boming. A combined model for short term load forecasting based on maximum entropy principle[J]. Proceedings of the CSEE,2005,25(19):1-6(in Chinese).
[7] 高 峰,康重庆,夏 清,等. 负荷预测中多模型的自动筛选方法[J]. 电力系统自动化,2004,28(6):11-13. Gao Feng,Kang Chongqing,Xia Qing,et al. Multi-model automatic sifting methodology in load forecasting[J]. Automation of Electric Power Systems,2004,28(6):11-13(in Chinese).
[8] 肖 峻,张 晶. 基于关联分析的城市用电负荷研究[J]. 电力系统自动化,2007,31(17):103-107. Xiao Jun,Zhang Jing. Analysis of urban power load based on association rules[J]. Automation of Electric Power Systems,2007,31(17):103-107(in Chinese).
[9] 鲍 文,于达仁,王 伟,等.基于关联规则的火电厂传感器故障检测[J]. 中国电机工程学报,2003,23(12):170-174. Bao Wen,Yu Daren,Wang Wei,et al. Sensor fault detection in thermal power plants based on association rule[J]. Proceedings of the CSEE,2003,23(12):170-174(in Chinese).
[10] 侯雪波,田 斌,葛少云,等. 关联规则技术在电力市场营销分析中的应用[J]. 电力系统及其自动化学报,2005,17(2):67-72. Hou Xuebo,Tian Bin,Ge Shaoyun,et al. Application of association rules techniques in electric marketing analysis[J]. Proceedings of the EPSA,2005,17(2):67-72(in Chinese).
Intelligent Recommendation of Urban Power Load Forecasting Models Based on Association Rules
XIAO Jun1,GENG Fang2,DU Bo-jun1,YU Bo1
(1. Key Laboratory of Power System Simulation and Control of Ministry of Education,Tianjin University,Tianjin 300072,China;2. Chengxi Power Supply Company,Tianjin Electric Power Corporation,Tianjin 300072,China)
A method based on association rules for intelligent recommendation of power load forecasting models is presented in this paper,which helps decision-makers in the choice of a forecasting model among many. In this method,a history database which included the forecasting models and correlative factors was first built,with which the association rules mining was conducted. Then according to the relevant factors in the designated area,factors matching of the rules mined was carried out with CBR technique and automatic recommendation of the models was achieved with the matching results of various load forecasting models with the area under the given conditions. The proposed method has taken full advantage of the abundant data accumulated of 42 cities in China,and through data mining and analysis,determines the relevant factors to suitability of certain forecasting models,on which basis rational model recommendation result can be obtained. The recommendation method of suitable models based on association rules can not only automatically analyze the suitability of models and the intrinsic relationship between relevant factors but also show,to some extent,the forecaster′s preferences on the model. Load forecasting case of a certain area in China has verified the proposed algorithm′s validity and feasibility.
association rule;power load forecasting;model;intelligent recommendation
TM715
A
0493-2137(2010)12-1079-07
2009-09-17;
2010-05-06.
国家重点基础研究发展计划(973计划)资助项目(2009CB219700).
肖 峻(1971— ),男,博士,副教授,xiaojun@tju.edu.cn.
杜柏均,duduniao4604@sina.com.
猜你喜欢
小猕猴智力画刊(2022年3期)2022-03-29
新世纪智能(数学备考)(2021年9期)2021-11-24
数学小灵通(1-2年级)(2021年4期)2021-06-09
长江大学学报(自科版)(2021年6期)2021-02-16
当代陕西(2019年15期)2019-09-02
学苑创造·A版(2018年11期)2018-02-01
Coco薇(2017年11期)2018-01-03
读者(2017年5期)2017-02-15
暨南学报(哲学社会科学版)(2016年9期)2017-01-15
东北电力技术(2016年2期)2016-05-17
