
基于三维文档向量的自适应话题追踪器模型
2010-06-05 03:23周敬民赵莉萍
中文信息学报 2010年5期
张 辉,周敬民, 王 亮,赵莉萍
(北京航空航天大学 软件开发环境国家重点实验室, 北京 100191)
1 引言
随着计算机和通信技术的高速发展,互联网上的信息开始爆炸式地增长,大量信息扑面而来,人类进入一个信息极度丰富的社会,人们常常借助搜索引擎在信息海洋中方便地获取自己感兴趣的信息。然而,对于一些常挂在人们嘴边的新闻话题,如“今天发生了什么大事?”、“某某事件进展如何了?”等等,由于这些新闻话题往往具有连续报道多、时效性强、动态演变快的特点,“此一时而彼一时”,人们很难对其进行准确定义和描述,单一基于关键词匹配的搜索引擎已难以适应人们检索新闻并追踪新闻演变的需求。
话题检测与追踪[1](Topic Detection and Tracking,以下简称TDT)技术就是在这种情况下应运而生的。通过话题的自动检测与追踪,人们可以将分散的信息有效地汇集和组织起来,帮助人们快速发现新闻事件各种因素之间的相互关系,从而在整体上了解一个事件的来龙去脉以及与该事件相关的其他事件。话题追踪(Topic Tracking,简称TT)是TDT的子任务,它能够自动地从后续报道流中识别出与给定样例报道(种子报道)属于同一话题的其他报道并及时追踪特定话题,为新闻事件的追踪报道、事态追踪及判断决策提供辅助支持。
本文针对新闻话题追踪展开研究并提出了一种自适应的新闻话题追踪器模型。文章结构组织如下:第1节是引言;第2节介绍TT技术的基本概念和研究现状;第3节提出了一种基于三维文档向量的话题模型;第4节设计了一种自适应的KNN话题追踪器模型;第5节是实验和相关分析;最后一节对全文进行了总结。
2 相关研究
对话题检测与跟踪技术的研究起源于早期面向事件的检测与跟踪[2]。在TDT领域中,事件(Event)是指由某些原因、条件引起,发生在特定时间、地点的具体事件,涉及某些对象,并可能伴随某些必然结果[3];一个话题(Topic)则包括了一个核心事件以及所有与之直接相关的事件和活动,或者说话题就是若干对某事件相关报道的集合;报道(Story)是指一个与话题紧密相关的、包含两个或多个独立陈述某个事件的子句的新闻片断。TT就是监控新闻报道流,发现与某一已知话题有关的新报道的过程。
作为TDT的子任务,TT的研究主要分为基于知识和基于统计两个方向。前者的核心问题是分析报道内容之间的关联与继承关系,通过特定的领域知识将相关报道串联成一体(比如Watanabe[4],面向日语新闻广播开发的TT系统)。后者则主要借鉴基于内容的信息过滤技术,根据特征的概率分布,采用统计策略判断报道与话题模型的相关性。其中,最有代表性的方法是基于分类策略[5-6]的话题追踪研究,比如,CMU[7-8]在TT评测中采用了两种分类算法,分别是KNN和决策树;UMass[9]采用了二元分类方法追踪话题的相关报道;James Allan[10]和Michael[11]采用了Rocchio算法实施追踪,其核心思想是话题模型经验性的构造策略,即假设相关报道中的特征有助于话题的正确描述,因此这些特征在话题模型中的权重被加强,而不相关报道中的特征则趋向于错误地引导话题描述,因此权重被削弱[2]。Rocchio反馈方法被认为是较好的学习方法之一。
通常情况下,TT任务的初始话题仅通过极少量的相关报道来构造,往往导致其结果不够准确,因此具备自学习能力的话题追踪(Adaptive Topic Tracking,简写为ATT)逐渐成为TT领域新的研究趋势。Dragon[12]和 UMass[13]最早尝试了无指导ATT的研究,但对话题漂移[8,14]问题没有很好的解决;LIMSI[15]比较了基于静态和动态两种方式的特征权重更新策略,证明了动态策略的有效性;清华大学的贾自艳等借鉴Single-Pass聚类思想,结合新闻要素提出了一种基于动态进化模型的TDT算法[16],能够有效地改善TDT系统的效率;东北大学的王会珍等[17]基于增量学习的思想,采用反馈学习的自适应方法对话题追踪模型进行了修正,能将多个弱话题组合成一个强话题,提高了话题TT系统的性能。
基于统计的话题追踪方法可以分为两个过程:训练过程与测试过程。该方法首先对种子文档进行训练,得到话题模型;然后比较话题模型与后续报道的相关度,从而判断后续报道是否属于此话题。两个过程分别对应了话题追踪的两个核心问题:话题/文档(报道)模型的建立,以及追踪器的构建。本文针对这两个问题进行了研究,提出了一种完整的话题追踪器模型,并通过实验验证了该模型的有效性。
3 三维文档向量模型
话题/文档模型用于统一抽象表示同一话题的一篇或几篇新闻报道,由文档模型(表示单篇新闻报道)和话题类别模型(表示新闻报道集合)两部分组成。话题/文档模型的建立首先需要提取文档特征,建立文档模型,然后根据文档模型建立类别模型。
向量空间模型(简称VSM)[18]是文档建模中被广泛采用的经典模型。在VSM中,一篇文档可以用一个向量表示:设有文档集合D,则D中的每一个报道di均被表示为一个范化的矢量{wi1,wi2,…,win},其中wij是第j维对应的特征词tj在di中的权重。该文档模型在应用于新闻报道时,并没有对不同类别的特征词进行区分,而在新闻报道中,不同类别的特征词其重要性是不同的,例如表示事件发生时间的特征词和表示事件内容的特征词其权重应该是不同的。为此,我们将新闻报道的特征词分为三类:第一类是出现在新闻标题中的特征词;第二类是新闻内容中出现的特征词;第三类是实体特征词,包含了新闻中的人名、地名、机构团体名或者其他专有名词等主题词。基于此分类,本文提出了一种突出特征词类别的新闻报道向量空间文档模型,称之为三维文档向量模型(3-Dimension Document Vector Model,简称3DVM):
定义1三维文档向量模型,是一种针对新闻报道特点的文档模型,它将每篇报道分解为新闻标题特征、内容特征、实体特征三个维度,用三个向量分别表示三个维度上的文档特征。
例如,对于报道集合D中的报道di,可形式化表示为:
di={dit,dic,din}
(1)
其中,dit是标题特征分量,dic是内容特征分量,din是实体特征分量。每一个分量dik,k∈{t,c,n}={wik1,wik2,…wikn},wikj表示di的k分量特征词tj的权重。
在计算wikj时,我们采用了自适应IDF[15]取代TF-IDF计算中传统的IDF:
(2)
其中,p表示当前的时间点,Np表示到当前时间为止已有的文档(报道)数量,nik,p则表示在时间p时已有文档中k分向量包含tj的文档数量。由式(2)得:
wikj,k∈{t,c,n}=tfikj×idfik,p
(3)
在3DVM中,文档间的相似度是标题特征词分向量、内容特征词分向量与实体特征词分向量的距离加权和,如下:
(4)
+(1-α-β)×sim(din,djn)
其中,α、β为加权因子,通过训练或者遗传算法确定,sim(dit,djt),sim(dic,djc),sim(din,djn)分别为三个维度分向量之间的相似度,其相似度由公式(5)得出。
,
其中k∈{t,c,n}
(5)
3DVM对特征词出现的位置及其意义进行了区分,在计算文档相似度时,所有特征词只能与同类特征进行比较,突出了新闻报道中不同类别特征之间的相似度关系,这样可使相似度计算更加精确。
在3DVM的基础上,构建话题类别模型。一个话题包含了若干文档,所以一个话题T是由若干3DVM向量组成的集合,即T={d1,d2,…dn},其中di={dit,dic,din}。本文利用离散点模型来表示T,即利用T中的若干个3DVM向量表征T。区别于中心点模型,这些3DVM向量相互独立,每一个向量都体现了T的特征,共同表明了T的覆盖范畴。实验证明在表示话题模型时,离散点模型要优于中心点模型。
此外,在利用本文构建的追踪器进行追踪过程中,本文采用增量学习的方法对话题模型进行动态修正,使之能够自动适应话题的演变,这在一定程度上解决话题漂移现象,并降低了系统的漏报率。具体内容将在下一节进行介绍。
4 自适应追踪器
话题追踪的本质是一个二值分类问题,即对给定的一个话题,判断当前报道是否与该话题相关。因此,话题追踪器的功能,就是输入已有话题模型与待追踪报道,输出对该报道是否属于该话题的判断结果。
本文的追踪器以KNN为基础进行构建。KNN[7]是一种基于机器学习的分类算法,本身不需要训练过程,被称为基于记忆的算法,在话题追踪过程中比较适合种子文档个数少、话题模板不精确的情况。
首先构造初始的KNN事件追踪器,称之为KNN.sum,其计算公式如下:
(6)
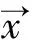
(7)
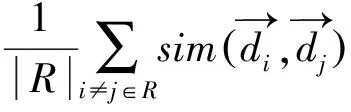
(8)
在上述追踪器中,设定一个时间窗口TimeWindow,如果要处理的新闻报道发布时间与种子文档最近时间的距离超过了TimeWindow,则直接判定其为不相关报道,因为实际生活中关于一个热门话题的新闻发布时间与发生时间很临近。统计表明,一个话题在新闻报道中通常只存在1~6周的时间[19]。
结合自适应的阈值策略,KNN.avg就成为了一种自适应的话题追踪器。在话题追踪开始时,先对初始的种子文档进行训练,得到初始话题模型,然后使用KNN.avg追踪器对待分类报道进行判定,并根据阈值策略选出与话题模型高度相关的报道,挖掘新的类别特征,修正话题模型。这样,话题模型能够依靠对新报道的判定结果得到反馈从而更新自身特征,使传统模式中相对独立的训练过程和追踪过程结合起来,从而克服了对初始文档的完全依赖,具有不断优化的自适应性。该模型更符合新闻事件不断变化发展的特点,参数和话题模型能够在无监督情况下自主学习。以下实验验证了本追踪器的可用性。
5 实验及分析
本文进行了4组不同的实验。实验使用LDC(Linguistic Data Consortium)提供的TDT2 Multilanguage Text Version 4.0(LDC2001T57)数据集中的中文数据作为语料集。选取与数据集中的9个话题相关的共823篇报道构建实验数据,将数据集合划分为训练集合和测试集合,训练集合用于构建初始话题,由每个话题的前4篇报道组成,测试集合由剩余所有报道组成。
为能够准确评测不同系统的性能,本文使用TDT的评测方法。实验采用所有话题的宏平均漏报率与宏平均误报率作为TT效果的评测指标。漏报率是指系统没有识别出来的关于某话题的新闻报道数目与语料中描述该话题的新闻报道的总数之比,而误报率是指对某个话题来说判断错误的新闻报道数目与语料库中所有没有描述该话题的新闻报道的总数之比。漏报率F与误报率M是TDT领域除查准率、查全率、F-Measure等传统指标之外常采用的度量指标,一个好TDT系统应该同时具有偏低的F和M值。F和M的计算公式如下。
(9)
(10)
其中,NUMdetected,related、NUMdetected,unrelated、NUMundetected,related、NUMundetected,unrelated分别表示检测到的话题相关文档数、检测到的话题不相关文档数、未检测到的话题相关文档数以及未检测到的话题不相关文档数。在此基础上,计算宏平均[1]M和F:首先计算各个话题的M/F值,然后进行加权平均得到宏平均值Macro-M/F。
实验中具体的参数设置为:公式(4)中α=0.1,β=0.5;公式(7)中,kn=2×kp;公式(8)中γ=1.0;反馈阈值δ和分类阈值θ关系为δ=2×θ。
5.1 话题/文档模型比较实验
本组实验在简单距离向量追踪策略下比较了三种话题/文档模型,结果如图1所示。
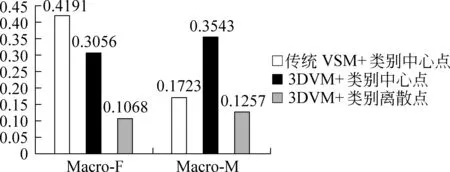
图1 话题/文档模型比较实验结果
可以看到,3DVM+类别离散点模型系统的宏平均漏报率与误报率都是最小的,因为3DVM区分标题关键词、内容关键词和实体关键词,更加突出了文档的细节,计算文档相似度更加准确,使正确追踪到的文档数目增加;类别离散点模型将话题的中心平均分配到各个种子报道,能更好地排除噪声,保证了系统较低的误报率,而类别中心点模型中3DVM对细节的重视导致系统对噪音数据不敏感,使误报率增加。由于传统的文档向量模型不区分重要的事件主旨词,将所有的关键词都作为事件特征同样对待,而实验过程中话题模型是由有限的初始种子文档向量得到,导致传统VSM模型在实验中的漏报率较高。
5.2 话题模型自适应性实验
本组实验在简单距离向量追踪策略下比较了固定话题模板和自适应话题模板两种模型,结果如表1所示。

表1 话题模型自适应性实验结果
可以看出,在自适应的话题进化策略下,系统的漏报率大约降低了8%,只有大约3%的相关文档没有被追踪到,说明话题模板的自我学习能够适应事件发展变化,并且把这种发展变化及时反馈到话题模型中,很大程度上降低了漏报的可能;误报率有约为1.5%的轻微上升,主要是因为在自我学习的过程中存在误反馈,导致话题模板中包含的特征会有失实,但系统的类别离散点模型可以削弱这种话题偏移的程度。而在话题追踪过程中,更注重减少信息遗漏,漏报率相对误报率更加重要,所以总体来看,自适应的话题模型效果要好于固定话题模型。
5.3 3DVM与自适应KNN追踪器实验
本组实验比较了在相同自适应KNN追踪器下3DVM与传统VSM的性能,KNN的自适应常数c取2。实验结果如表2所示。
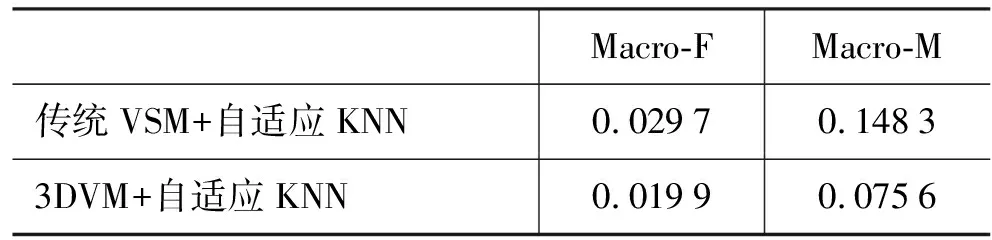
表2 3DVM与自适应KNN追踪器实验结果
实验中3DVM的宏平均漏报率和宏平均误报率较之传统的VSM分别减低了大约1%与7%。事件报道具有篇幅较短、能提取的关键词较少,且话题类似的报道大多使用相同的关键词等特点,而传统的VSM将事件的时间、地点、人物和内容等重要区分因素压缩到一个向量中进行表示,对事件的表示不够形象直观,难以表示出事件的细微差别。实验结果表明3DVM提高了KNN追踪器的性能,同时也说明了自适应KNN追踪器的合理性,因为此时系统的漏报率与误报率较低,属于人们可接受范围。
5.4 三种追踪器的对比实验
本组实验在相同的自适应策略下对三种常用追踪器进行了比较,分别是简单向量距离追踪器、Rocchio追踪器以及本文介绍的KNN追踪器。实验结果如图2所示。
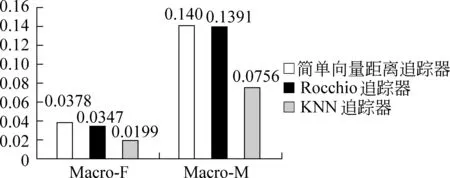
图2 追踪器比较实验结果
实验中自适应KNN追踪器的宏平均漏报率和宏平均误报率均比其他两种自适应追踪器低,因为KNN不仅考虑了简单向量距离和Rocchio中相关新闻报道的反馈,也考虑了不相关报道的影响。Rocchio追踪方法选择的是与话题中心最不相关N个文档,注重的是话题模板的正确性与准确性,然后根据文档与话题模板的相似度进行判断;KNN选择的是与当前要处理文档最相近的K个文档,由两部分组成,一部分是话题中心的kp个相关文档,另一部分是最相近的不相关的kn个文档,注重的是当前文档的类别归属问题,减少了Rocchio中因为由唯一的话题中心来判断所造成的误报率。
上述四组实验验证了本文提出的话题追踪模型在中文类新闻话题追踪应用中的实用性和有效性,该模型在描述新闻话题、避免话题漂移方面具有一定优势。
6 总结
本文提出的三维文档向量模型,在一定程度上改进了传统向量空间模型的不足,突出了新闻报道的重要特征(时间、人物、地点或者其他专有名词),有利于区分相似主题报道。在此基础上建立了基于三维文档向量模型与类别离散点的话题模型;同时,本文设计了一种自适应的KNN追踪器,该追踪器基于KNN算法,具有话题模型的自我学习、追踪器算法参数的自行调整和阈值策略的自我更换等自适应特点。最后通过实验对整个追踪器模型进行了分析和验证。实验结果表明,本文提出的话题追踪器在中文类新闻话题追踪应用中效果良好,并在描述新闻话题、避免话题漂移方面具有一定优势。
[1] Allan J., 2002a.Topic Detection and Tracking: Event-based Information Organization[M]. Dordrecht: Kluwer Academic.
[2] 洪宇, 张宇, 刘挺,等. 话题检测与跟踪的评测及研究综述[J]. 中文信息学报, 2007, 21(7): 71-87.
[3] Fiscus J, Doddiongton G., Topic Detection and Tracking Evaluation overview[M]. Dordrecht, London:Kluwer Academic Publishers, 2002:17-30.
[4] Watanabe Y Okaxta, K Kaneji, and Y Sakamoto. Multiple Media Database System for TV Newscasts and Newspapers[C]//Technical Report of IEIGE. Japan, 1998, 47254.
[5] C Buckley and G Salton. Optimization of relevance feedback weights[C]//Proceedings of SIGIR ’95. Washington, United States: Seattle, 1995, 351-357.
[6] B Masland, GLinoff, and D Waltz. Classifying news stories using memory based reasoning[C]//Proceedings of SIGIR ’92. Denmark: Copenhagen, 1992: 59-65.
[7] Y. Zhang, J. G. Carbonell, J. Allan. Topic Detection and Tracking: Detection Task[C]//Proceedings of the Workshop of Topic Detection and Tracking, 1997.
[8] J Carbonell, Y Yang, J Lafferty, R D. Brown, TPierce, and X. Liu. CMU Report on TDT2: Segmentation, Detection and Tracking[C]//Proceedings of the DARPA Broadcast News Transcription and Understanding Workshop. San Francisco: Morgan Kauffman, 1999: 117-120.
[9] J Kupiec and J Pedersen. A trainable document summarizer[C]//Proceedings of the 18th Annual In ACM SIGIR Conf on Research and Development in Information Retrieval (SIGIR ’95). Seattle, Washington, USA: ACM Press, 1995: 68-73.
[10] James Allan, Ron Papka, Victor Lavrenko. Online New Event Detection and Tracking[C]//the proceedings of SIGIR ’98. University of Massachusetts: Amherst, 1998: 37-45.
[11] J M Schultz and Mark Liberman. Topic detection and tracking using idf-weighted cosine coefficient[C]//Proceedings of the DARPA Broadcast News Workshop. San Francisco: Morgan Kaufmann, 1999, 189-192.
[12] J P Yamron, S Knecht, and P V Mulbregt. Dragon’s Tracking and Detection Systems for the TDT2000 Evaluation[C]//Topic Detection and Tracking Workshop. USA: National Institute of Standard and Technology, 2000: 75-79.
[13] J Allan, V Lavrenko, D Frey, V Khandelwal. UMass at TDT 2000[C]//Proceedings of Topic Detection and Tracking Workshop. USA: National Institute of Standar and Technology, 2000, 109-115.
[14] W Lam, S Mukhopadhyay, J Mostafa, and MPalakal. Detection of Shif t s in User Interest s for Personalized Information Filtering[C]//Proceedings of the 19th Annual International ACM SIGIR Conference on Research and Development in Information Ret rieval. Konstanz: Hartung Gorre Verlag, 1996: 317-325.
[15] Y Lo, J L Gauvain. The L IMSI Topic Tracking System for TDT 2002[C]//Topic Detection and Tracking Workshop. Gaithersburg, USA, 2002.
[16] 贾自艳, 何清, 张海俊,等. 一种基于动态进化模型的事件探测和追踪算法[J]. 计算机研究与发展, 2004, 41(7): 1273-1280.
[17] 王会珍, 朱靖波, 季铎,等. 基于反馈学习自适应的中文话题追踪[J].中文信息学报,2006,20(3):92-98.
[18] G. Salton, A. Wong, C. S. Yang. A vector space model for automatic indexing[C]//Communications of the ACM. 1975, 18(11): 613-620.
[19] Y. Yang, J. Carbonell, R. Brown, T. Pierce, B. T. Archibald, X. Liu. Learning Approaches for Detection and Tracking News Events[C]//IEEE Intelligent System: Special Issue on Application of Intelligent Information Retrieval. 1999, 14(4): 32-43.
计算语言学与语言科技原文丛书
本丛书由北京大学—香港理工大学汉语语言学研究中心、北京大学计算语言学研究所和北京大学出版社合作,引进剑桥大学出版社的“自然语言处理研究”丛书,并组织相关领域专家学者撰写导读。旨在沟通各学科成果,打破学科界限,加速知识共享,推动计算语言学更快发展。丛书的读者对象包括以下领域研究者:语料库语言学、心理语言学、信息提取、机器学习、人机互动、机器人科学、语言学习、本体论、数据库。
语音语言处理导论 Introducing Speech and Language Processing
作者:John Coleman
导读:常宝宝(北京大学)
书号:ISBN 978-7-301-17153-0/H·2495
自然语言生成系统的建造 Building Natural Language Generation Systems
作者:Ehud Reiter,Robert Dale
导读:冯志伟(教育部语言文字应用研究所)
书号:ISBN 978-7-301-17154-7/H·2494
对话的逻辑——篇章解读的动态语义理论 Logics of Conversation
作者:Nicholas Asher,Alex Lascarides
导读:曾淑娟(中国台北“中研院”)
书号:ISBN 978-7-301-17158-5/H·2492
词义的语言——词意理论的跨学科讨论 The Language of Word Meaning
编者:Federica Busa, Pierrette Bouillon
导读:黄居仁(香港理工大学)
书号:ISBN 978-7-301-17157-8/H·2491
口语机器翻译 The Spoken Language Translator
作者:Manny Rayner, David Carter, Pierrette Bouillon, Vassilis Digalakis, Mats Wirén
导读:宗成庆(中国科学院自动化研究所)
书号:ISBN 978-7-301-17156-1/H·2493
文字书写系统的计算理论 A Computational Theory of Writing Systems
作者:Richard Sproat
导读:陆勤(香港理工大学)
书号:ISBN 978-7-301-17155-4/H·2496
猜你喜欢
黑龙江工业学院学报(综合版)(2022年7期)2022-08-29
湖南文理学院学报(自然科学版)(2022年2期)2022-05-06
计算机系统应用(2021年9期)2021-10-11
煤气与热力(2021年6期)2021-07-28
计算机技术与发展(2018年8期)2018-08-21
中国机械工程(2017年22期)2017-12-02
中国医药指南(2017年20期)2017-09-03
中国质量监管(2016年10期)2016-07-10
现代电子技术(2015年21期)2015-11-09
中文信息学报(2015年4期)2015-04-21
