
基于Unicode编码的蒙古文输入法研究
2010-06-05 06:31范道尔吉白凤山武慧娟
中文信息学报 2010年6期
范道尔吉,白凤山,武慧娟
(内蒙古大学 电子信息工程学院,内蒙古 呼和浩特 010021)
1 引言
蒙古文国际标准编码字符集中收录了传统蒙文的7个元音、27个辅音、11个标点符号、10个数字和4个控制字符。该标准中只按蒙古文语音收入了抽象的蒙古文字符(称为名义字符),而同一个蒙古文字符的书写(显现形式)会根据其在词语中的位置不同、单词的词性等属性不同而发生变化,即呈现在人们面前的是该字符变化后的形式(称为显现字形)。由于ISO/IEC 10646标准中没有收人蒙古文显现字符,因此在显示蒙文时需要将蒙古文的名义字符根据上下文映射到其相应的显现字形[1-2]。
微软的Vista操作系统当中已经支持了上述蒙古文的变换处理,Office2007也支持蒙古文的竖排排版。同时Vista中也提供了蒙古文输入法,但是这个输入法用起来不够方便,文字输入速度不够快。不方便之处在于文字变形时候由用户判断使用哪一个控制符号,因此必须学习蒙古文的变形原理和控制符号功能,入门比较困难。其次蒙古文单词都比较长,平均有10个左右(对一个蒙古文字典数据的统计),因此输入起来比较慢。基于上述问题本文提出了一种新型蒙古文输入法算法。
2 新输入法特点
新输入法具备如下特点:自动变形、常用特殊文字快速输入、联想输入、自动学习和网络互联。自动变形是指用户只需按变形键文字就自动变形,用户选择正确变形就可以,而不用自己输入控制符;常用特殊文字快速输入是指蒙古文有些附加成分经常用,但变形控制比较繁琐,因此把特殊附加成分集中在某个键上,按附加成分键时常用的附加成分全部显示,用户选择输入就可以;联想输入是指一个较长的蒙古文字用户输入一部分时自动补齐显示供用户选择输入;自动学习是记录用户输入到字典里,字典内容动态增长;网路互联是指字典数据通过网络进行更新和下载。
3 自动变形算法
3.1 算法原理
蒙古文Unicode定义了3个控制符:自由变体选择符1(FVS1)、自由变体选择符2(FVS2)、自由变体选择符3(FVS3)。同时还有4个特殊符号影响蒙古文的变形分别是:窄宽度不间断空格(MSP)、元音间隔符(MVS)、零宽度连接符(ZWJ)、零宽度禁止链接符(ZWNJ)。MSP输入附加成分时使用; MVS在字末元音和辅音间不连续而且字形需要发生变化时使用;ZWJ是在输入单个名义字符的各种变形时使用;ZWNJ需要强行断词时候使用[3]。
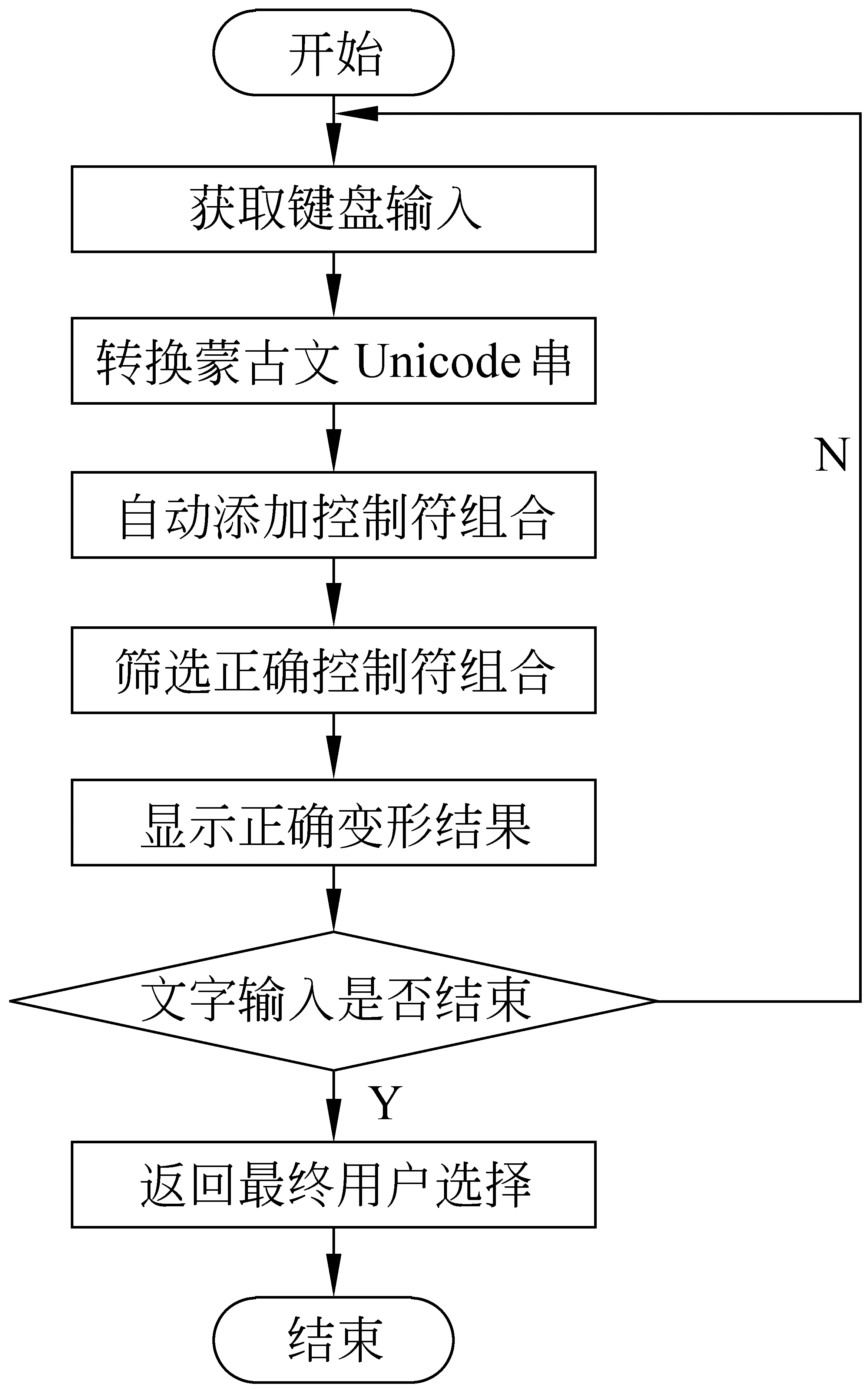
图1 算法流程图
自动变形算法基本思想:把键盘输入转换成蒙古文Unicode编码串,然后按某种规则把控制符的排列组合加到当前输入串上,计算带控制符Unicode串的字形ID串,再根据所得字形ID串筛选合理变形的Unicode文字串供用户选择输入。算法的难点在于控制符的组合方案、添加位置以及筛选算法。
3.2 单个名义字处理算法
设当前输入是[A],因为是单个名义字符,因此它的候选只能是这个名义字符相对应的所有显示字符了。[A]的前加控制符集合是{NONE,ZWJ},而且前加控制符只能是一个。[A]后加控制符集合1是{NONE,FVS1,FSV2,FVS3,ZWJ},后加控制符集合2是{NONE, ZWJ}。因为后加控制可以是FSVn和ZWJ的组合,后加控制符最多只能是两个。表1是所有可能加的组合。
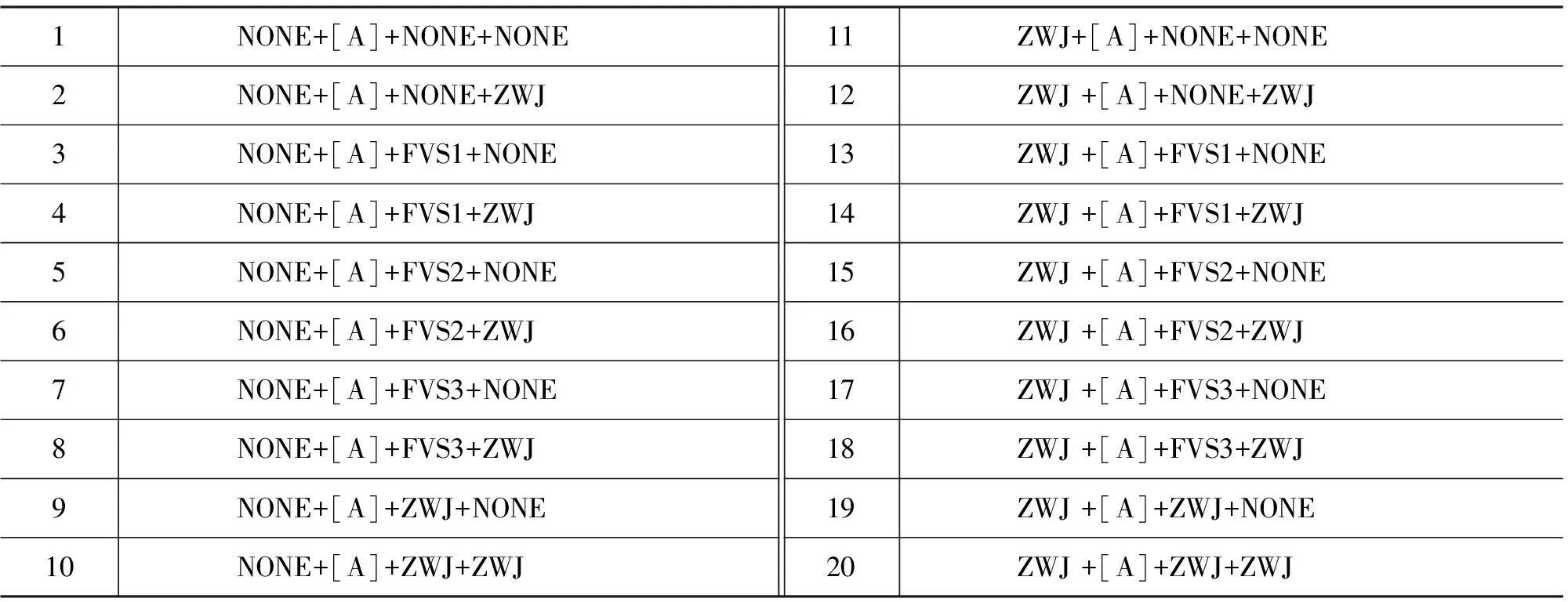
表1 单个名义字符变形控制排列组合
这样可以共生成20个组合,但是其中有些组合式是非法的,比如ZWJ+ZWJ的连续出现,可以简化成一个ZWJ。对这些简化后的组合计算对应的字形ID串,结果中可能有大部分字形ID串是形同的,因此需要对组合文字进一步筛选。如果所得字形ID串和无控制符时对应的字形ID串一致的全部删除(因为控制符没有起变形作用),不同控制符组合得出相同字形ID串的保留控制符少的串,如果控制符数量也相同则保留其中任意一个(因为字形效果是一样的,这种可能性比较少)。最后把保留下来的内容显示给用户供选择输入。这样对用户就屏蔽了变形规则和控制符的使用方法。保留下来的应该都是合法的蒙古文文字,因为他们满足变形规则。MSP、MVS和ZWNJ没有使用,因为他们对单个符号没有变形作用。
3.3 多个名义字符处理算法
输入多个名义字符时控制符加在倒数第二个字符后头和最后一个字符后头。如果倒数第二个符号是控制符则只加在最后一个字符后头。比如输入字符串是[A][B][C](B不是控制符),[B]后头可以加控制符集合是{NONE,FVS1,FVS2,FVS3,MVS},[C]后可以加的控制符集合是{ NONE,FVS1,FVS2,FVS3}。ZWJ、MSP和ZWNJ没有使用,因为ZWJ对一个文字串没有变形作用,MSP的效果是有空格作用,但是文字看做是连续,因此把它分配在蒙古文模式下的空格键上,用户可以直接输入,ZWNJ的变形效果可以用空格(0x0020)键代替,空格(0x0020)可以分配在英文输入模式下的空格键上。MSP也有输入特殊变形附加成分的作用,但是本输入中把特殊附加成分集中在TAB键上,按TAB时把已经准备好的特殊附加成分Unicode串(已经带了控制符比如MSP)列出来供用户快速输入。
自动变形算法在输入一个文字时候可以多次使用,因为一个蒙古文字当中可能需要多个控制符。比如当前输入是[A][B][C]发现[B]的形状不正确,因此使用了一次自动变形选择了正确的字形ID串,因此当前输入变成了[A][B+FVS1][C],用户接着输入[A][B+FVS1][C][D][E]结果发现[D][E]都不是想要的字形,因此再运行一次自动变形算法选择正确的字形结果变成了[A][B+FVS1][C][D+MVS][E+FVS1],每次的算法之间没有关联,相互独立。
3.4 字形ID串的计算方法
Uniscribe即Unicode文字处理程序 (usp10.dll),是用来对复杂文字进行整形和布局的系统工具。目前Uniscribe支持蒙古文、维吾尔文等我国少数民族文字。对于复杂文本语言而言, 输人的是Unicode名义字符串经过布局引擎的处理后,输出将是正确的显现字型序列及字型间正确的位置数据[4-5]。
ScriptItemize函数完成Unicode名义字符串的分割工作,把统一属性的文字分割成一个一个Items。ScriptShape函数完成Unicode名义字符串到字形ID串的转换工作,可以利用这个函数获得蒙古文的字形ID串。最后可以用ScriptPlace和ScriptTextOut函数完成字形的输出[5]。下面是在Delphi7环境下实现字形ID串计算的部分代码:
rslt := ScriptItemize(
pointer(wstr), //widestring类型的蒙古文字符串,我们自己添加控制符后的串
len,//wstr的长度
cMaxItems,//最大分割数量,如果wstr全是蒙古文,则1就够了,为了安全可以给500
@psControl, //SCRIPT_CONTROL结构体指针
@psState,// SCRIPT_STATE结构体指针
@items[0], //TScriptItem数组的地址,这里返回分割后的串,为后续处理中用到
@cItems);//items中实际返回的个数
idx := items[0].iCharPos;//开始位置
lll := items[1].iCharPos - idx;//长度计算
mx_glyph := lll * 2 + 16;//字形ID的最大长度计算
glyph_cnt := 0;
//准备缓存
setlength(clusts,mx_glyph);
setlength(glyphs,mx_glyph);//字形ID返回的缓存
setlength(sva,mx_glyph);
rslt := ScriptShape(
dc, //设备,使用mongolian baiti字体
@ssc, //TScriptCache指针,输入nil,返回值在后续输出时使用
@wstr[idx+1], //字符串开始指针
lll, //wstr中的长度
mx_glyph,//最大字形ID个数
@items[i].a, // ScriptItemize中得到的items
@glyphs[0], //存放字形ID串数组指针,字形ID在这里返回
@clusts[0],
@sva[0], // SCRIPT_VISATTR数组
@glyph_cnt);//实际得到的字形ID的个数
3.5 控制符组合有效性判断
表2是$1820的所有控制符的自由组合和变形后的字形。
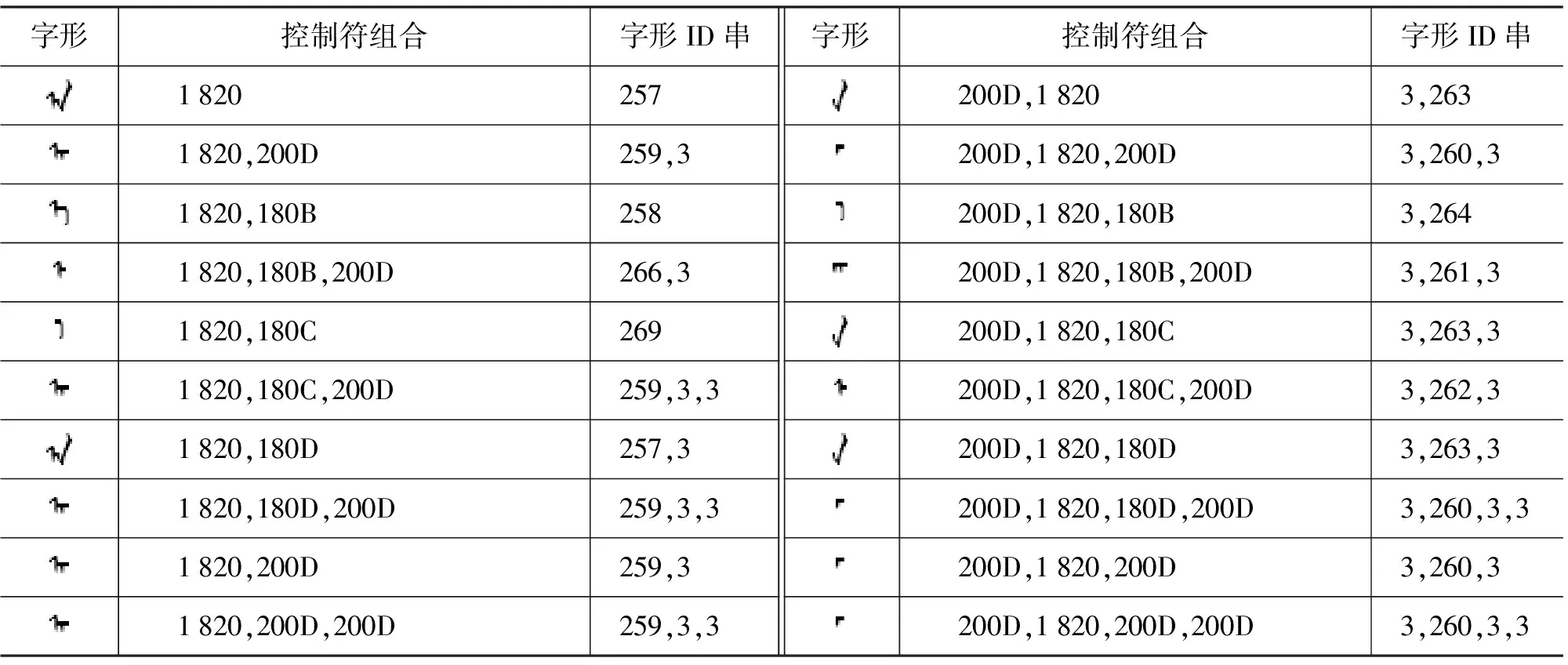
表2 编码$1820对应的所有变形和字形ID

清空有效组合集合A,A中按行记录“控制符组合、字形ID(没有空格)”
对所有得到的变形控制组合依次作如下处理:
(1) 字形ID串中的空格全部去掉(编码3去掉),只剩下蒙古文变形ID记做x;
(2) 判断x是否在集合A中,如果已经存在执行(3),否则执行(4);
(3) 和x对应的控制符组合长度是否比A中已经存在控制符组合短,如果短执行(4),否则执行(5);
(4) 把当前处理串添加到A中;
(5) 还有未处理串跳转(1)继续,否则结束。
按上述算法处理后得到如表3所示表格。

表3 编码$1820对应的合理变形筛选结果
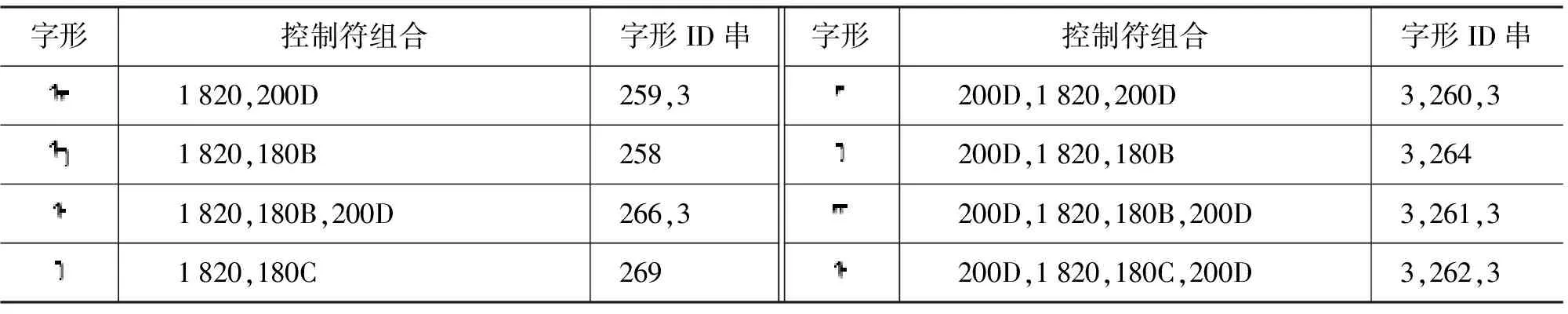
续表
表中得到就是0x1820的所有显示字符,输入法中可以把这些列出来供用户选择,因此用户没必要自己输入控制符,因此方便了用户输入。多个名义字符时上述算法也是适用的,所得结果是当前文字的所有合法变形文字。
4 字典数据的存储和检索算法
4.1 字典数据存储方法
使用字典数据可以让输入法具备联想功能,字典数据中存储Unicode编码串的蒙古文字。用户输入时实时检索字典,如果字典中存在与当前输入匹配的字(可以使用模糊匹配,头部包含的字就算匹配),直接显示在选择区域中,在输入比较长的文字就不必全部输入就可以直接选择了,省去了繁琐的文字变形。
采用树形结构存储蒙古文字典数据比较合理,这样可以节省存储空间,相同头部的文字只需要存储一份。树的根节点没有意义,其他节点由蒙古文名义字符的编码和7个控制符构成,树形存储结构如图2所示。
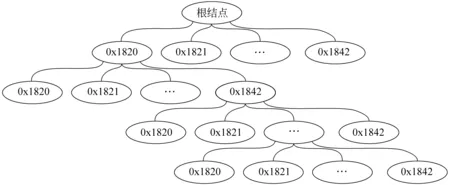
图2 树形结构
树中每个节点最多有41个子节点,从根开始到一个叶子节点是一个最长蒙古文字,但是到中间节点时也可以是一个蒙古文字。因此在每个节点上要用标记记录是否能构字。
匹配算法:假设当前如输入是[A] [B] [C] [D],当前处理编码记为x,x的初始值是[A],树中的当前节点记为r,r的初始值是根节点。
(1) 查找r的子节点中有没有和x匹配的节点,查找时可以使用简单的下表对应方法,如果找到匹配子节点继续执行(3),否则执行(2)。
(2) r的7个控制符子节点的子节点中有没有和x匹配的节点,如果有执行(3),否则算法结束没有找到匹配结果。
(3) r=匹配子节点,x是不是最后一个编码,如果是算法结束,找到匹配串,从根节点到r,以及r以后的所有子节点都是匹配结果,否则x=下一个编码,跳转(1)
如果在(2)中有多个控制符子节点匹配的话,上述算法(1)、(2)、(3)需要递归执行。
4.2 自动学习和字典共享技术
如果用户输入的完整文字在字典中找不到匹配串,可以动态加进字典中。添加算法也可以使用查找算法,在判定不匹配时把开始不匹配部分添加到当前树结构中,并保存到本地。同时可以使用网络技术,架设一个网络服务器,把用户字典定时汇总,并把最新字典数据传输给每个用户。
5 结束语
文中提出的新型蒙古文输入法算法,经试验证实是可行有效的方法,可以大大提高蒙古文输入速度和效率,用户容易掌握和使用,对促进蒙古文信息化处理有重要意义。同时本方案也非常适合在手持设备上使用,因为手持设备的资源有限,因此这种自动输入算法更加适合。
[1] 确精扎布.蒙古文编码[M].呼和浩特:内蒙古大学出版社,2000.
[2] 姚延栋,吴健,孙玉芳,呼斯勒.传统蒙古文变形显示机制研究与实现[J].中文信息学报,2005,18(5):84-89.
[3] S.苏雅拉图.传蒙古文整词编码研究[J].中文信息学报, 2001,15(2):57-64.
[4] 孟凡强,吴健,贾彦民.蒙古文显示在OpenOffice.Org办公套件中的实现[J].中文信息学报,2007,21(2):117-121.
[5] 周扬荣,贾彦民.复杂文本布局引擎机制及应用研究[J].中国科学院研究生院学报,2006,23(3):390-395.
[6] 斯·劳格劳,敖其尔. Windows环境下蒙古文复杂文本处理的研究[J].内蒙古大学学报,2007,38(5):582-585.
[7] 乌达巴拉,巩政.蒙古文OpenType字体制作技术[J].内蒙古大学学报,2006,37(5):570-573.
猜你喜欢
蒙古学问题与争论(2021年0期)2022-01-19
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
小学阅读指南·低年级版(2019年11期)2019-07-01
数字通信世界(2019年3期)2019-04-19
蒙古学问题与争论(2019年0期)2019-03-29
小天使·一年级语数英综合(2017年11期)2017-12-05
读者(2016年14期)2016-06-29
民族古籍研究(2014年0期)2014-10-27
