
数据挖掘技术在保险客户理赔分析中的应用
2010-05-22 08:06:26李迪安谢邦昌
统计与决策 2010年4期
陈 希 ,李迪安 ,高 星 ,陈 帅 ,谢邦昌
(1.厦门大学 经济学院,福建 厦门 361005;2台湾辅仁大学 统计资讯学系,台北)
0 引言
随着人们收入水平的提高和消费意识的改变,保险产品日益增多,公众对购买保险的热情越来越高,保险行业也随之迅速发展。与此同时,决策者在获取利益时应注意到行业存在的巨大风险。保险业与其他行业相比,最大的差异在于它是以多样化的风险为经营对象的特殊服务业。不同的客户有着完全不同的需求,也为保险公司提供不同的收益率。在保险业,通常根据客户价值、客户贡献、客户理赔风险、保险市场、保险产品等进行细分。本文掌握的是保险公司的客户资料,主要针对客户的理赔索取这类保险业面临的主要风险进行阐述。另外,高风险客户的索赔直接造成保险公司的理赔支出,而理赔是关乎保险公司盈利的重要事宜。
在保险行业过去的客户理赔的研究中,少有涉及数据挖掘的领域,多半利用传统统计方法或是单纯的专业分析,这些方法虽然能够发现“发生理赔”的一些表面特征,如重复投保、高额投保、频繁投保等,但可能都忽略了海量数据中隐含、尚未被挖掘出的宝贵信息,而数据挖掘为另一种从不同角度切入的新方法。保险公司可以利用数据库中多年来收集起来却没有实际运用到的宝贵数据,通过数据挖掘的技术,了解所拥有的客户的特征,以及其中具有何种特征的客户存在着高风险。根据数据挖掘的结果,也可以更清楚知道未来目标的客户群在哪里,针对目标客户群推行保险理赔产品进而获得更大的效益。
本文利用数据挖掘技术对客户理赔概率进行预测,按理赔概率高低将客户分成若干等级,从而有针对性地对理赔概率高的客户增加保险金额度或提高保险费率,或者将这部分客户群作为非重点营销对象,达到了运用“针对不同理赔风险等级的保户销售有差异的保险产品”的营销战略,从而最大程度地分散非系统性风险同时降低公司保险投资风险,避免经济损失。
1 研究目的及数据挖掘流程
本文借助数据挖掘分类算法,对高风险保户的理赔风险建立一个科学的分析与预测模型,在模型基础上设定未来客户“是否发生理赔”的最适分割点,帮助决策者做出适当的营销策略。
按照CRISP-DM(跨行业数据挖掘方法论)的标准,数据挖掘在保险业中的应用可以划分为以下六个步骤:商业理解、数据理解、数据准备、建立模型、模型评估与模型发布。第一,商业理解:明确挖掘目标,即找出高风险理赔客户特征,指导公司进行营销决策;第二,数据理解:本文使用的数据来自中国台湾某著名保险公司,数据集共29个变量,变量类型有类别型、布尔型和顺序类别型,不同类型的变量对应于所要解决的不同问题;第三,数据准备:一方面对庞大而复杂的数据进行预处理,剔除缺失数据,并区分目标变量与解释变量,另一方面从描述统计角度筛选出高风险客户数据集;第四,建立模型:针对不同的数据挖掘目标和数据特性,采用不同的挖掘算法建立模型;第五,模型评估:对产生的模型结果需要进行比对验证、准确度验证、支持度验证等检验以确定模型的价值,文中除了用增益图和分类矩阵进行评估之外,还利用验证集考查模型的泛化能力;第六,模型发布:只有把模型发布到决策者手中,才能真正通过数据挖掘降低保险公司发生理赔业务的概率与成本。
2 高风险保户理赔概率建模分析
2.1 数据准备
本研究使用的数据来自中国台湾某著名保险公司自1981年至2002年间投保伤害险和健康险的客户资料。该资料共包含65535个客户样本,共29个字段(依次编号为Q1至Q29):客户基本信息(Q1~Q6)、投保数据基本资料(Q7~Q24)和理赔信息(Q25~Q29)三个资料组。
(1)数据预处理。①属性概化。将存在缺失值以及可用其他同类属性来代替它的较高层概念的那些属性删除。比如:保额与保额组别、缴费年期指示与缴费年期、投保年龄与年龄组别、已缴保费与已缴保费组别等含义重复,仅保留“组别”字段;而理赔总金额可以通过理赔件次和理赔金组别进行推断,故删之。②相关分析。一方面要减少输入变量之间的冗余度,保证计算的效率和输出的简捷;另一方面,与输出变量无关的输入可能会延误甚至误导挖掘进程,因此要保证输入变量与输出变量(有无理赔)之间有一定的相关度。此外有些属性可以根据逻辑上直观的判断决定取舍。在相关分析基础上,又把理陪件次、投保件次、理赔金组别等字段删去。预处理后变量的详细说明见表1。
(2)数据准备。本分析主要关注高风险客户是否会发生理赔。在65535条客户记录中,无理赔客户占96.77%,有理赔客户只占3.23%。因此,首先需要界定“高理赔风险客户群”:将17个解释变量与因变量(有无理赔)做交叉频数分析,通过各个解释变量对理赔情况的发生概率找出对有无理赔分布产生重要影响的因素,界定出一个特殊的客户群体。经分析,把具有表2中属性特征的保户界定为高理赔风险保户。
依据以上的特征,把具有以上特征的保户从总体中分离出来,共有19335个保户,该人群中受理赔的比例为10.96%,远高于总体比例受理赔3.23%。因为所有的理赔记录都发生在这一人群中,其所具有的理赔风险是远高于其它保户的,因此对高理赔风险保户群体是否会发生理赔进行建模将更有现实意义。
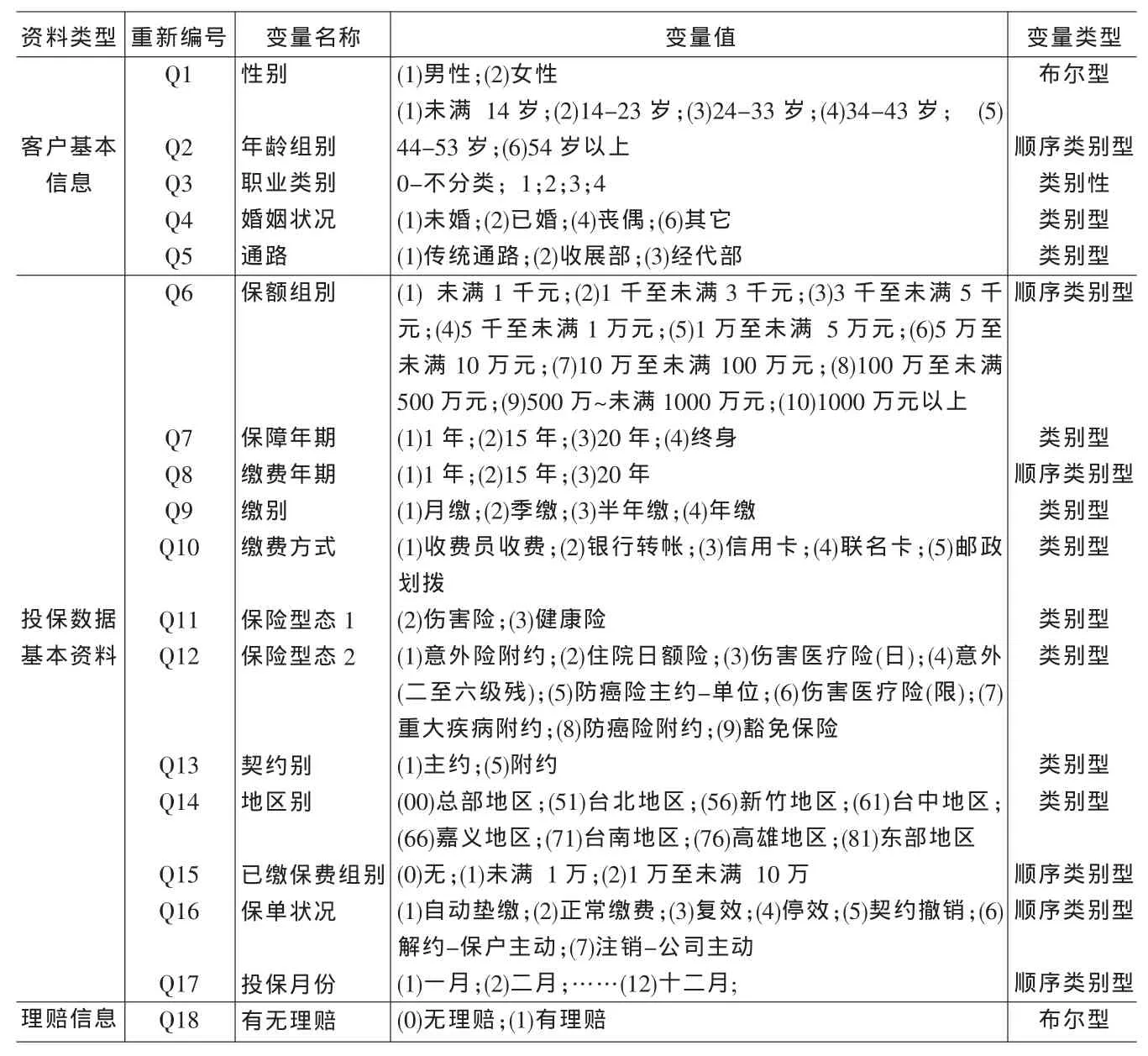
表1 变量预处理及其编号

表2 高理赔风险保户具有的属性特征
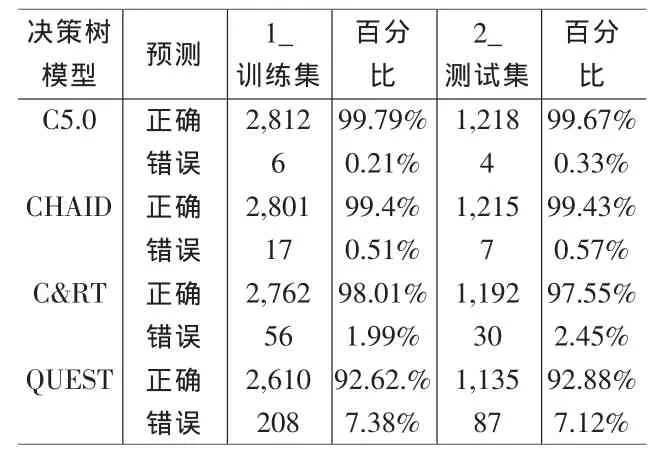
表3 四种决策树算法在两类数据集上的预测准确率
2.2 高理赔风险保户建模分析
在分离出的高理赔风险客户群中,无理赔客户的占比仍高达89.04%。由于分类算法对存在有偏数据的处理效果是相当不理想的,因此在进行决策树挖掘算法前,应对高理赔风险客户数据再次预处理,使得有无理赔客户分布基本平衡。在SPSS-Clementine软件中,通过设置平衡节点,就能使数据分布均衡。经处理,无理赔客户占比46.77%,有理赔客户占比53.23%,代价是样本量的下降。在此基础上,使用分类算法对高理赔风险客户做深入挖掘。
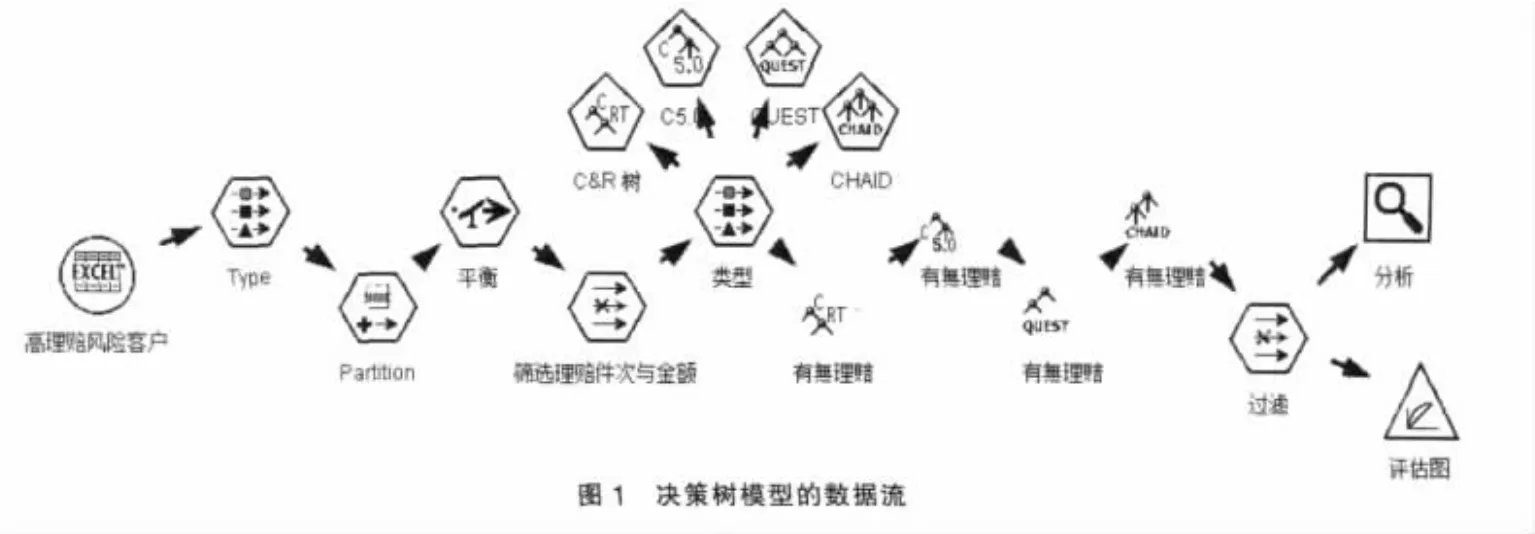
2.2.1 决策树模型。Clementine12.0提供四种决策树算法:C5.0、CHAID、C&RT和Quest。利用Type节点设置输出输入变量,再通过Partition节点将数据集分成70%测试集和30%训练集,使用训练集建立分类模型,再将模型运用于测试集,利用混淆矩阵度量模型的性能。决策树模型的数据流如图1所示。
对四种算法分别建立起模型之后,再透过Analysis节点可以得到表3所示,关于四种算法在两类数据集中的预测准确率。分析得出C5.0模型在两大数据集的预测效果是最好的,再取C5.0模型结果来分析高风险理赔保户共有的一些个人信息特征。
(1)分类规则。表4是由C5.0模型使用推进方法产生“有理赔”结果的部分规则集,各规则集的估计精确度在88%以上。由规则集,可归纳出“发生理赔”的客户主要具有以下特征:已婚,女性,老年人居多,职业类别为0,主要集中在台北、新竹及台中地区,以月缴或年缴方式,投保月份主要是下半年。
(2)树模型。对C5.0模型使用推进方法得到的树模型如图2所示,每个节点位置显示的直方图为在该节点中的观测值在因变量(有无理赔)上的取值分布情况,在非末端的节点方框下方的变量名,表示其子节点的划分变量,而具体取值则在其子节点上方均有标示。
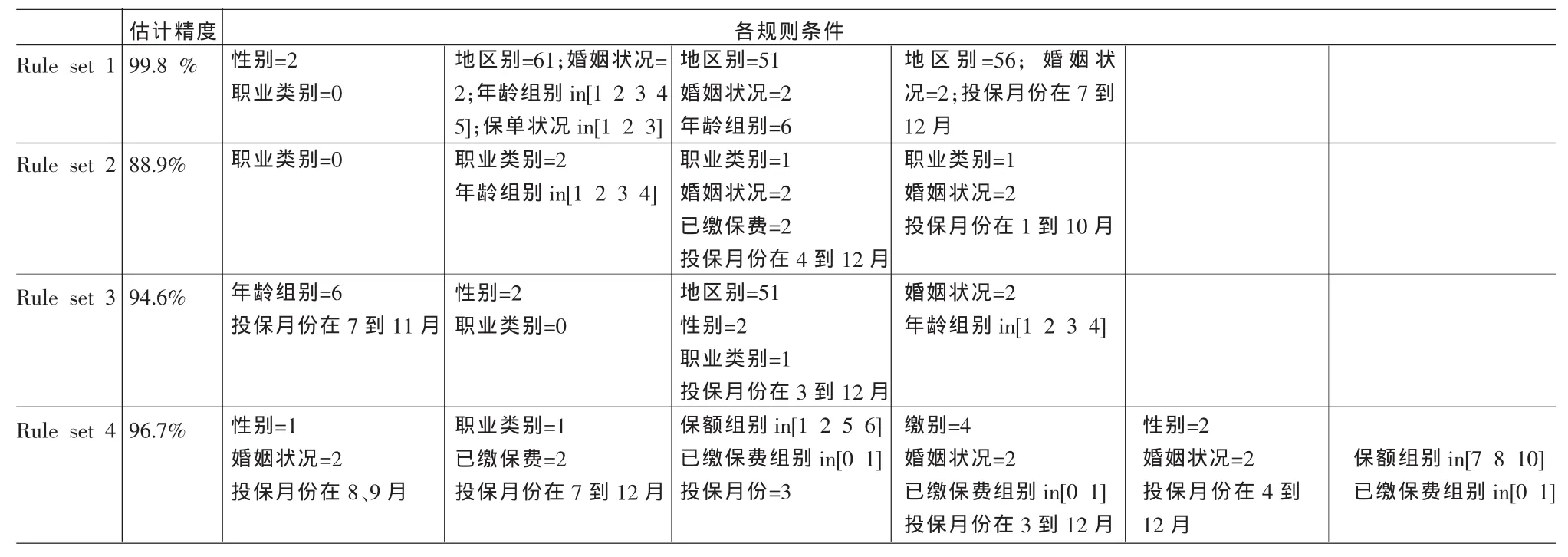
表4 产生有理赔结果的规则条件(仅取其中4条)

在C5.0决策树上,第二层右侧的节点29有理赔很少,仅有53例,所占比例不到测试集中理赔总数的0.04%。这些客户的保单状况为停缴,契约撤销,解约-保户主动和注销-公司主动。事实上,当契约取消、解约或注销都看成保户与保险公司的合同中止,因而保险公司也就没有了理赔义务,故对这部分的保户可基本忽略。而相应左侧的节点1下的子树很大,覆盖了大量的有理赔客户信息。由于分析有理赔客户的相关信息是本研究的主要目的,因此,我们特别关注有理赔多的节点。从图中可以清晰看到,已婚的客户群(节点8)的样本数最多,有1518个,占53.735%,同时也是发生有理赔事件最多的一类,因此有必要进一步考察该节点。模型以投保月份为是划分变量对节点8进行分类,虽然各个月份下都有一定的理赔事件发生,但第四层右侧的节点16(即投保月份在7月份后)所含的有理赔保户比左边的多700多个,且主要集中在新竹和台中两个地区;模型将新竹地区的597个有理赔保户归为月缴投保一类。同时,台北地区也有16个理赔的,主要是老年人。跟踪节点9(投保月份在上半年)到叶节点14这条子链可以发现,节点9中204个有理赔保户被完全分到节点14,其客户特征为:正常缴费,已婚,4月投保且购买的是健康险。此外,对于最左侧的节点4,有理赔客户仅为217个,也产生了相应的分类规则,即正常缴费,职业类别为0,女性。
综合分析C5.0模型产生的分类规则及树模型,发现影响“有无理赔”的主要解释变量是:婚姻状况,职业类别,性别,投保月份,保险形态1,地区别,年龄组别,缴别。此外,在以投保月份为属性进行分类时,下半年投保的有理赔客户要明显比上半年的多,为后面模型处理方便,可考虑将投保月份分为上半年和下半年。
2.2.2 支持向量机、贝叶斯网络以及logistic回归。首先,在C5.0模型对输入变量进行属性约减的基础上,即在接下去的分类算法模型建立过程中,只将约减后的八个重要变量作为输入,以有无理赔作为因变量,训练出新的分类模型,从而得到相应的高风险保户的理赔概率预测模型;最后根据各个分类预测结果的准确性评估模型。整个建模数据流如图3所示。
模型建立完毕,此时要估计不同性能的模型,以便选出最好的模型。评估模型优劣的准则有:整体精确性、ROC曲线下方面积、利润、提升等指标。在此,选用“整体精确性”作为评估模型的准则;由表5和表6判断出,支持向量机模型优于其他两个模型。所以选择支持向量机模型作为最终模型。


表5 三种分类模型的评估准则得分

表6 分类矩阵表

表7 无理赔概率分布表
2.3 模型实施
根据上述模型评价结果,选择SVM模型来构建“全体高风险保户”发生理赔概率的评分模型。先将全体高风险保户带入训练得到的SVM模型中,估计出每一个样本不发生理赔的概率。保险公司可以根据自身所能承担的风险状况,来决定适当的概率分割点,作为保险客户是否发生理赔的一个预测标准,若新客户不发生理赔的SVM模型预测值高于该分割点,则认为此保户将不会要求理赔,此时可按照已制定的保险金额度接受其投保申请;反之若低于该分割点,则应该对其提高保险金额度或者保费率。如果保险公司想以客观的统计方法来确定分割点,则可以通过计算最大的K-S值来获得SVM模型的最适分割点。
定义“K-S值”:各分数下对应的累计“坏”客户百分比与累计“好”客户百分比之差的最大值。在数据挖掘中或信用评分中,K-S值越大,表示评分模型能够越理想地区分 “好”、“坏”客户。另外,该评分模型还能绘制出K-S曲线:将所有申请者的信用评分由小到大排列,分别计算每一个分数之下“好”、“坏”客户累计所占的百分比,再将这两种累计百分比与评分做在同一张图形上,得到K-S曲线。
针对高风险客户发生理赔的概率预测模型,K-S值是由SVM模型估计得到全体样本的无理赔概率值后,发生理赔的累积百分比减去无理赔的累积百分比所得到的绝对值,计算公式:K-S=sup|Fr-Fn|。K-S 值越大,表示“无理赔”与“有理赔”的累积百分比在该分割点或区间的差异越大,该分割点或区间就越能有效地分辨出高风险保户发生理赔概率的高低,故可用来决定最适分割点,以判断无理赔的概率要大于多少时才能被保险公司视为不发生理赔的高风险保户。计算结果如表7、图4所示。
模型建立后,需要对模型的预测能力、稳定性进行检验后才能运用到实际业务中去。国际上用K-S指标来衡量验证结果是否优于期望值,具体标准是,如果模型的K-S值达到30%,则该模型是有效的,若K-S值超过30%,则模型区分度越高。
由表4可以发现,SVM模型的K-S值达到68.98%,说明SVM模型具有较好的预测功能,发展的模型具有成功的应用价值。同时,KS达到最大值36.84%的无理赔概率区间为0.99~0.992,因此本研究设定0.99为高风险保户是否发生理赔模型的最适分割点,即无理赔概率大于0.99的客户风险相对较低,保险公司可按照已有的保费标准接受其投保申请。

3 结论
本文利用分类算法对台湾某保险公司的健康险和伤害险保户进行了高风险理赔特征发掘和高风险保户识别,帮助保险公司控制和分散理赔风险,同时为它们针对不同风险等级的保户销售相应的保险产品和制定差别保险费率提供依据。综合全文,我们得出如下结论:
(1)从保户的个人基本信息来看,婚姻状况、年龄和性别是区分保户理赔风险高低的关键因素。综合本文各种模型的实证结果,对于保户具有“已婚,女性,未满14岁和老人”特征的当属高风险理赔人群。因此,对于这部分群体,保险公司应该给予特别关注,并可以适当提高保险费率以分散非系统性风险。
(2)从投保相关信息来看,地域分布、保险形态(或险种)和缴费方式成为划分保户风险等级的重要变量。其中,台北、新竹和台中是理赔事件的高发地区;健康险业务的开展将使保险公司承担较之伤害险更大的理赔风险;按月缴纳保险费的缴费方式同样也是高风险理赔客户具有的典型特征之一。
(3)依据SVM模型实施的结果,无理赔概率0.99是高风险保户是否发生理赔的最佳分割点处的概率值,即:无理赔概率大于0.99的保户将被视为 “基本无理赔风险保户”或“基本不发生理赔保户”,保险公司可按照一般标准的保费额度或保险费率接受该类客户的投保申请。对于无理赔概率小于0.99的保户,保险公司应该“按级”销售差异产品,即越远离最佳分割点概率值的保户,其理赔额度越低,理赔资格审查越严格,保费额度越大,保险费率越高。
[1]田今朝,戴稳胜,谢邦昌.保险业的数据挖掘应用[J].中国统计,2005,(02).
[2]王星,谢邦昌,戴稳胜.数据挖掘在保险业中的应用[J].北京统计,2004,(04).
[3]毕建欣.数据挖掘技术在保险领域中的应用[J].华南金融电脑,2004,(08).
[4]吉根林,孙志挥.基于数据挖掘技术的保险业务风险分析[J].计算机工程,2002,(2).
[5]田金兰.用决策树方法挖掘保险业务数据中的投资风险分析[J].小型微型计算机系统2000,(10).
[6]鲍观健.台湾保险业发展之研究[D].广州:暨南大学,2003.
[7]李玉泉.大陆保险市场开放对台湾保险业的机遇与挑战[J].中国保险,2005,(3).
[8]Jiawei Han,Micheline Kamber.数据挖掘概念与技术[M].北京:机械工业出版社,2001.
猜你喜欢
核安全(2022年2期)2022-05-05 06:55:32
中国民间疗法(2021年18期)2021-11-02 08:20:26
金桥(2021年12期)2021-08-26 12:30:55
公民与法治(2020年10期)2020-07-25 01:41:38
瞭望东方周刊(2018年8期)2018-03-08 18:41:46
外语教学理论与实践(2016年1期)2016-06-11 05:51:40
中国工程咨询(2015年8期)2015-02-16 06:38:56
当代工人(2014年21期)2015-01-19 14:33:19
当代工人(A版)(2014年21期)2014-04-21 07:45:30
法人(2014年4期)2014-02-27 10:44:17
