
路局站别应卸车系统的数据库设计
2010-05-12 08:01陈小红陈晓东
铁道运营技术 2010年4期
陈小红,陈晓东
(1.西安铁路职业技术学院,助教,陕西 西安 710014;2.西安铁路局新丰镇车站,助理工程师,陕西 西安 710608)
路局站别应卸车计划的编制在货运工作计划的编制中占有重要地位〔1〕。目前,该计划的编制仍停留在手工编制的水平,效率低,工作量大。采用计算机编制路局站别应卸车系统可以极大地减少工作强度,提高数据的精确性,而数据库的设计在路局站别应卸车系统(简称应卸车系统)的设计中占有重要的地位。为此,重点对应卸车系统开发过程中数据库部分的设计环节进行讨论。
1 需求分析
在计算机应用系统中,数据库是管理信息系统(MIS)的核心,它的性能与管理是涉及MIS各方面的全局性问题,是保证MIS高效运行及安全的关键。数据库的设计要充分考虑应用系统的功能,而应用系统的功能又决定于用户各个方面的需求,包括现有的以及将来可能增加的需求。为此,下面分别进行分析。
人工编制路局站别应卸车计划,主要是根据运货4上的数据来完成当日18:00在站的管内工作车、次日自装管内工作车及其有效车数、次日局(地区)间分界站接入的管内工作车及其有效车数等3部分卸车资源的推算。如果通过计算机来实现编制,应卸车系统应满足用户如下需求:
1)能够对卸车资源的基础数据进行系统录入,存入数据库。
2)根据站标准停留时间,标准接续时间及列车到站、发站时间推算接续车。
3)能对现有管重、自装卸及接入管重卸车资源中有效车及整个卸车资源的推算。
4)能够对基本数据进行查询、删除、修改、插入及命令的下达等操作。
5)方便用户对于系统的维护。
为了满足用户的上述需求,应卸车系统应有3部分功能:
1)数据输入功能。主要包括:①多个卸车资源基础数据的输入,主要包括预确报数据(当日15:00车流、各站间转运车、列车挂运车、次日邻局预报资源)的导入、转运车以及用户基础数据的输入等。②在站标准停留时间及标准接续时间的输入。③列车到站、发站时间的输入。
2)数据处理功能。主要包括:①根据站标准停留时间,标准接续时间及列车到站、发站时间推算接续车。②现有管重、自装卸及接入管重卸车资源中有效车的推算。
3)数据输出功能。主要包括:①现有管重、自装卸及接入管重卸车资源中有效车的输出。②现有管重、自装卸及接入管重卸车资源(有效车和无效车之和)的输出。③接续车的输出。
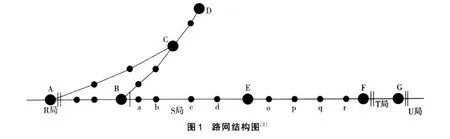
另外,由于路局站别应卸车计划涉及的站点、分界站、中间站等数据特别多,所以数据库仅根据假设的路网结构进行设计,以简化设计难度。在假定的路网结构中,全路有R,S,T,U等4个铁路局,A站和F站分别为S局与R局、T局的分界站,T局和U局在G站分界。如图1所示。
基于上述分析,采用PB开发工具和SQL2005数据库系统,分别对数据库系统进行概念设计、逻辑设计和物理设计。
2 数据库概念设计
2.1 数据库总体概念设计概念结构设计就是将用户需求抽象为概念结构模型的过程。概念结构设计是整个数据库设计的关键,它通过对用户需求进行综合、归纳与抽象,形成一个独立于具体数据库管理系统(Database Management System,简称 DBMS)的概念模型〔3〕。
从需求分析中的应卸车系统输入、处理、输出3部分功能可知,该系统数据库中应包括如下实体:
1)基础数据实体。包括当日15:00车流确报资源、各站间转运车预报资源、列车挂运车预报资源、次日邻局预报资源、邻局预报数据自预测资源(这是由于次日邻局预报资源的不准确性,采用邻局预报数据自预测资源来提高次日局间分界站接入的管内工作车的精确性)。这些基础实体中的数据需要用户进行手工输入或导入。
2)推算条件实体。包括站标准停留及接续时间、列车到发时间和接续车次。用来判断18:00在途管内工作车、次日自装管内工作车、临局接入管重的工作车是否有效,临站作业车是否已装好。推算条件实体中的数据是实现次日应卸车有效车的关键,也需要用户输入。
3)输出实体。包括现有管重资源、现有管重无效资源、自装卸及接入管重资源、自装卸及接入管重无效资源、总数据输出资源,这些实体用来存放对前2部分实体数据进行推算处理后得到的数据。
4)用户实体。即用户信息资源,用来进行用户的登录和验证。
2.2 数据库具体概念设计由于应卸车系统数据库涉及的实体众多,且基础数据实体和输出实体的数据结构基本一致,下文只给出具有代表性的数据设计实体及其属性。
1)当日15:00车流确报资源。用来存储当日15:00~18:00间管内各站已有车及输送车流情况,其实体属性:站或列车编号、站a、站b、站c、站d、站E、站o、站P、站q、站r、站F、合计。属性1表示某站或某列车15:00具有车流确报资源,属性“站a”表示该站或列车到站a的15:00车流确报数。合计一列用来存储某站所具有的总15:00车流确报数。
2)站标准停留时间及接续时间。在次日站别卸车计划资源的推算过程中,多次用到标准站停及接续时间表。其实体属性包括站编号、站标准停留时间、站标准作业时间及标准接续时间。
3)列车到发时间。列车到发时间全面反映了列车在运行图上的准确到站、离站时间。为卸车资源有效性推算提供了重要的依据,其实体属性包括:列车编号、站编号以及站的到达和开出时间。
4)接续车次。在次日站别卸车资源的推算过程中,有一部分车次需要在技术站中转,在中转时有效性推算需根据接续时间表和接续车次表。接续车次表主要包括列车编号、站编号和接续列车编号。
5)现有管重资源。现有管重资源全面反映了次日在站管内工作车和18:00在途管内工作车的资源。根据运货4,现有管重资源为在站管内工作车和在途管内工作车之和。其实体属性:站或列车编号、站a、站b、站c、站d、站E、站o、站P、站q、站r、站F、合计。属性1表示某站或某列车具有现有管重资源,属性“站a”表示该站或列车到站a的现有管重工作车数。合计一列用来存储某站或某列车所具有的现有管重总和。
3 数据库逻辑设计
3.1 数据库总体逻辑设计逻辑结构设计是将概念结构模型转换成某个DBMS所支持的数据模型,并对其进行优化。设计主要分为2个步骤进行:
1)绘制从概念结构设计出来的各实体的E—R图(实体—联系图),并对其进行合并优化。
2)将优化后的E—R图按关系模式转换原则转换成关系。虽然基础数据各实体转换成关系后具有相同的码,但在该数据库中并未对其进行合并。因为,一是表示的数据含义不一样;二是合并后属性列名之间有重复还需重新命名;三是不利于数据处理部分的操作。同理,数据输出部分的实体也是转换成各自的关系,不对其合并,方便用户操作和输出。
3.2 数据库具体逻辑设计通过数据库的总体逻辑设计得知,应卸车系统数据库总共具有14个关系模型。考虑到很多实体结构一致,在这里只给出概念结构设计中提到的实体转换成的逻辑模型,其中有下划线者为关键码。
1)当日15:00车流确报资源表:站或列车编号、站a、站b、站c、站d、站E、站o、站P、站q、站r、站F、合计。
2)站标准停留时间及接续时间:站编号、站标准停留时间、站标准作业时间、标准接续时间。
3)列车到发时间:列车编号、站编号、站到达时间、站开出时间。
4)接续车次:列车编号、站编号和接续列车编号。其中站编号为外键,与站标准停留时间及接续时间表相联系。
5)现有管重资源:站或列车编号、站a、站b、站c、站d、站E、站o、站P、站q、站r、站F、合计。
4 数据库物理设计
数据库的物理设计是根据数据库逻辑设计的结果,研制一个有效的、可实现的物理数据库结构及存储结构。该数据库采用SQL 2005数据库管理模式,主要是对上述关系的存储结构进行设计,包括对各属性的数据类型、长度、是否为空,是否为主键及相应备注信息进行设计。在这里主要对现有管重资源表、站标准时间及接续时间表、列车到发时间表及接续车次表的物理设计进行阐述,其他不再累述。
4.1 现有管重资源表现有管重资源关系表物理设计要求:
1)因为站或列车编号能唯一标识某一条记录,所以将其定义为主键。根据站及列车的实际编号长度,将其类型定义为varchar(变长字符串),最大长度为10,根据关系的范式要求其值不能为空。
2)属性“站a”至“站F”存储具体到该站的现有管重车数,将其数据类型定义为smallint(短整型),长度为5,根据关系的范式要求其值可为空。
3)最后一列属性“合计”存储某站现有管重车数之和,因数值比较大,将其定义为int(整型),其值可为空。
4.2 站标准时间及接续时间表站标准时间及接续时间关系表物理设计要求:
1)因为站编号能唯一标识某一条记录,所以将其定义为主键,并与现有管重资源表保持一致。将其类型定义为varchar(可变字符串),长度为10,其值不能为空。
2)属性列站标准停留时间、站标准作业时间和标准接续时间在系统中以min为单位,定义为varchar(变长字符串),最大长度为4,其值可为空。
4.3 列车到发时间表列车到发时间关系表物理设计要求:
1)列车到发时间关系为多对多的关系,因为列车编号和站编号的组合能唯一标识某一条记录,所以将列车编号和站编号定义为主键。将列车编号和站编号类型定义为varchar(可变字符串),长度为10,其值不能为空。
2)站到达时间和在站开出时间根据其实际含义定义为datetime(日期型),将格式设置为“yyyymmdd”,占用8字节,其值可为空。
4.4 接续车次表接续车次关系表物理设计要求:
1)因为列车编号能唯一标识某一条记录,所以将其定义为主键,与前表保持一致。数据类型设置为varchar型,长度为10,其值不能为空。
2)站编号为外键, 通过它和站标准停留时间及接续时间关系表相关联,站编号的其它设置与列车编号设置一致。
3)接续列车编号不是主键,其值可为空。
5 结束语
应卸车系统数据库通过相应的逻辑步骤进行概念设计、逻辑设计及物理设计,能很好地为路局站别应卸车系统服务。它能完整地反映卸车资源各种信息之间的联系,有效地进行数据存储,数据存储和读取的速度较快,对现实生产中应卸车计划系统的设计有很好的借鉴作用。当然,如果对数据库的访问权限进行有针对性的设计,数据库会更完善。
〔1〕齐 斌.铁路局日班卸车计划的计算机编制〔J〕.铁道运营技术,2007,13(1):36-37.
〔2〕宋建业,谢金宝.铁路运输调度指挥与统计分析〔M〕.北京:中国铁道出版社,1993.
〔3〕施威铭.SQL Server 2005中文版设计实务〔M〕.北京:机械工业出版社,2006.
猜你喜欢
小哥白尼(趣味科学)(2021年4期)2021-07-28
云南画报(2021年4期)2021-07-22
中国外汇(2019年18期)2019-11-25
小学生学习指导(低年级)(2019年6期)2019-07-22
哲学评论(2017年1期)2017-07-31
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
财经(2017年2期)2017-03-10
财经(2016年15期)2016-06-03
财经(2016年3期)2016-03-07

- 铁道运营技术的其它文章
- 岩溶地区铁路既有线路的路基病害探测研究
- 运用火灾模拟软件优化消防设计