
基于Web挖掘的学术热点发现模型的设计与实现
2010-05-09 06:00余洋刘宇宏
网络安全技术与应用 2010年8期
余洋 刘宇宏
1上海海事大学商船学院 上海 200135
2上海航天测控通信研究所 上海 201109
0 前言
本文的目的在于借助文本挖掘及其相关技术,对Web上的航海领域科技论文进行文本挖掘,从而发现近期科学研究的热点问题,为用户提供有益的信息与帮助。现有的Web文本挖掘及其相关技术为课题的研究提供了可行性。此外,通过本文的研究,也可以再文本表示方法、自然语言处理方法和聚类算法等方面对Web文本挖掘技术起到一定的促进作用。建立海事案例的存储和学习机制,有效的利用以往海事案例的宝贵经验。
1 基于自然语言处理的科技论文特征提取
建立相关领域词典,分别开发基于词典的前后向相结合的中文自动分词算法和基于句式结构的中文自动语义分析算法,对样本集中论文的题目进行分词、消歧、句法分析和语义分析等处理,从而获得论文的描述特征和语义特征,并结合论文所提供的关键词,确定出论文的主题属性、支撑属性和参考属性以及它们之间的语义关系。
1.1 领域词典的建立
分词的前提就是建立领域词典,本文需要建立的是航海领域词典,将航海领域的专用词尽量全面地收入词典,词典的建立过程中需要注重词语的粒度,可以考虑将经常同时出现的词语或专业术语合成为一个较长的词语,比如“船舶自动识别系统”这一词语。词典同时应该包括论文题目可能会用到的动词、形容词和连词,如“实现”、“基于”等这些词语都将成为特征提取中区别主体属性和支撑属性的标志。对于一些经常出现如“研究”、“分析”等词,因为他们并不包含与论文题目语义内容相关的信息,并且因为出现频率很高,可能对聚类结果产生误导,可以考虑不加入词典。词典的词语最终用写字板存储。形式如图1所示。
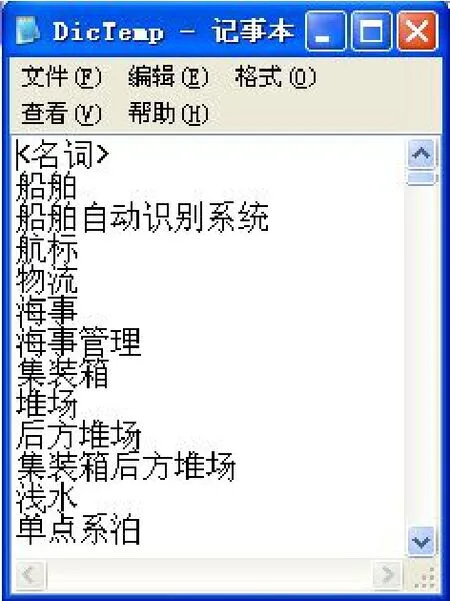
图1 词典部分图
1.2 中文自动分词
分词的目的就是将论文题目中语义内容进行分割,为下一步的特征提取做准备。本文使用的基于领域词典的正向最大匹配法(FMM)并使用逆向最大匹配法(RMM)对分词的记过进行歧义的检验。例如对“集装箱后方堆场”一词进行分词时,尽管词典中有“集装箱”和“后方堆场”两个词语,但进行最大匹配后得到“集装箱后方堆场”一个词语。逆向最大匹配法的原理和正向的原理相同,只是方向相反。分词方法在Visual C++环境下实现,分词流程图如图2所示。
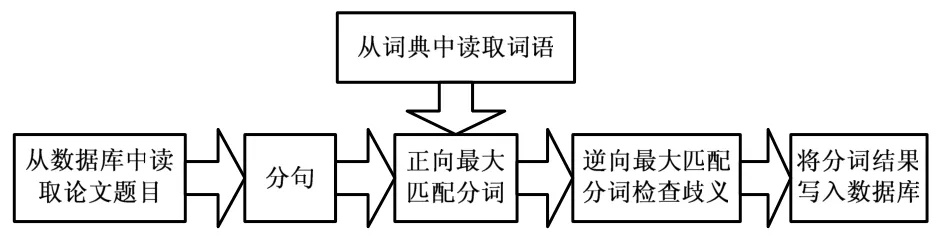
图2 分词流程图
根据分词流程设计读如词典函数、分句函数、正向最大匹配分词函数、逆向最大匹配查歧函数、分词结果写入函数。读词函数将记事本中的词语读入,分句函数有两部分功能,首先将数据库中存放的论文题目读入程序,再次将读入的论文题目中的汉字、数字和英文等特殊符号分隔开,分别存放在不同的char数组中。正向最大匹配函数实现基于词典的分词,逆向最大匹配函数用来进行歧义检验,比如有些词语,可以和前后的文字组合,从而形成不同的两个词语,而这样两种的分词结果必定有一种是违背改句的正确语义的,这种因为机械分词而产生的歧义正是逆向最大匹配函数的作用所在,逆向最大匹配函数用来从后向对论文题目和词典中词语进行比对,并且和正向分词的结果比较,对出现不同的分词进行报错,必须由人对这些歧义分词加以选择,从而得到真正符合语义的分词结果。
1.3 特征提取
本文采取的是基于语义的特征提取方法,和普通的特征提取方法相比更能突出论文的主体属性和支撑属性。论文题目的命名都有一定规则可循,“基于FTA方法降低涡轮增压器失效风险的研究”这一论文题目,人可以直接的理解这一论文的主题是涡轮增压器,而支撑属性就是研究主题使用的方法和技术,在这里就是FAT方法,再比如“采用不同湍流模型对带自由面船舶粘性流场计算的分析比较”这一论文题目,主题属性就是船舶粘性流场,支撑属性就是湍流模型。从这题目中我们可以发现一些规律,就是“基于”、“采用”等词语在题目中起着划分主题属性和支撑属性的作用,通过对这些词语的定位,可以将这些词语之前和之后的词语分别归入论文的主题属性和支撑属性。同样,根据对大规模论文题目的归纳和分析,进一步的发现了更多的可以对主题属性和支撑属性加以区分的定位词,把这些定位词总结成七种论文题目句式,它们分别是:
(1)“基于”+主题+“方法技术的”+支撑属性,例如“基于Multi-Agent的散货供应链管理系统”、“基于ActiveX的雷达模拟器的Web实现”;
(2)“利用用采用”+支撑属性+“实现”+主题属性,例如“利用VB的MSComm控件实现GPS数据采集”、“利用Polmon实现Polaris航海模拟器的管理”;
(3)支撑属性+“在”+主题属性+“中”,例如“迭代滑模变结构PID控制及其在船舶航向控制中的应用”、“第四方物流在集装箱多式联运中的运用”;
(4)主题属性+“中”+支撑属性,例如“航海雷达模拟中的海杂波建模及仿真”、“航海职业教学中系统应用航海模拟器之探讨”;
(5)支撑属性+“对”+主题属性+“影响”,例如“船首破波对兴波阻力系数影响的实验研究”;
(6)支撑属性+“关于”+主题属性,例如“博弈论方法来测量关于集装箱船竞争的大型船舶的生存能力”;
(7)主题属性+“的”+支撑属性,例如“船舶输流管道系统的振动特性研究”,“甲板上浪和冲击载荷的数值模拟”;
如果不符合以上的格式,就将论文题目中的分词全部归入主题属性,例如“浅谈船舶压载水处理及其认可标准”。
通过将论文题目与定义的句式模型进行比对,提取论文的主体属性和支撑属性,将主题属性和支撑属性分别存放在数据库中与论文题目对应的列中,如果论文题目的主体属性和支撑属性不只一个词语,将各个词语之间用自定义的符号加以分隔,这样可以解决因为不同论文主题属性和支撑属性个数不同而带来的存储问题。
2 基于语义相似度目标函数的模糊聚类算法
确定论文各特征值间的中文语义相似度(基于语义场),并依此建立目标函数(即样本与聚类原型之间的距离度量函数)和模糊聚类算法,对语义网数据集进行划分,由划分结果可以得到航海领域的研究热点。
文本聚类算法的核心就是语义相似度的计算,语义相似度的计算现今有两种途径其一是基于语义场,利用同义词词典(Thesaurus)等计算相似度。Princeton大学的WordNet就是一部树状的英语语义字典。树状图上两片树叶之间的距离,就是这两个概念的语义距离,由语义距离可进一步得出语义相似度。其二是基于大规模的本体库统计信息,利用词语的相关性来计算相似度。通常选取一组特征词,利用在实际大规模本体库中上下文的出现频率得到相关性的特征向量,用向量的夹角余弦来计算相似度。本论文使用语义场的方法,模仿WordNet构建一本航海领域词语的语义词典,通过语义词典的查询,配合相应的计算公式,确定连各词语之间的相似程度。由于WordNet是一本英文词典,其中词语的粒度也较小,不包含复杂的词汇,而本文需要的是中文相似度的计算,而且航海领域有很多事专业词汇并不包含在WordNet词典中,因此需要构建航海领域的中文专用词典时。本文中对航海类词语进行归纳,将词语分为船舶装置、航海技术、航海环境、航海工具四个基本的大类,然后根据航海专业知识将这四个大类继续进行细分,从而形成一个一个树状的语义词典,图3展示的就是船舶装置类词典的结构图的部分。
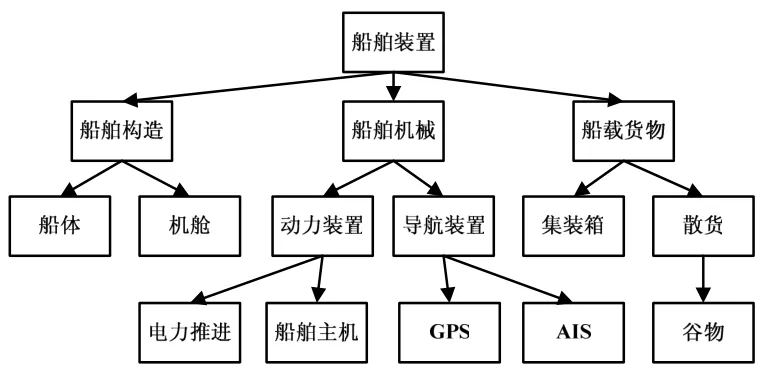
图3 船舶装置类词典的部分结构图
同理可以构造其他三类的树状词典,从而形成一个语义词典。语义相似度的计算方法采用WU和Palmer的方法,Wu所提出的概念语义相似度算法是基于is-a关系的,考虑了两个概念在树中的最近的公共父节点的深度以及两个概念之间的距离。对于同一个父节点,两个概念之间的距离越大,得到的相似度值越小;对于距离相同的两个概念,如果父节点的深度越大,则语义相似度越大。
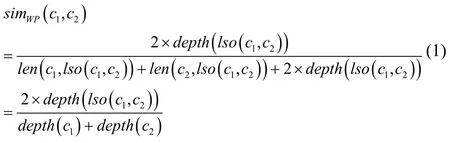
3 结论
Web文本挖掘属于新兴的前沿领域,网络上日益丰富的文档资源及其潜在的商业价值已经吸引了越来越多的研究者。本文的研究内容就是这方面的一次尝试,但这一热点发现模型当然也有待完善之处,若要进行深入的研究必须构建更为庞大的领域词典,涵盖更丰富的专业名词,希望本文能对愿意研究Web文本挖掘的学者提供一些参考。
[1]秦鹏.基于WordNet的本体匹配关键技术研究与实现.华东师范大学硕士论文.2009.
[2]王箐华.语义网络下的词义消歧.北京邮电大学学报.2006.
[3]颜伟.基于Wordnet的英语词语形似度计算.北京语言大学.2003.
猜你喜欢
校园英语·月末(2021年13期)2021-03-15
小哥白尼(神奇星球)(2020年4期)2020-07-27
文苑(2019年24期)2020-01-06
文苑(2019年24期)2020-01-06
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
英语文摘(2019年5期)2019-07-13
作文大王·低年级(2017年10期)2017-10-28
中关村(2014年5期)2014-05-15
中华海洋法学评论(2013年2期)2013-03-11
