
局部Bagging方法及其在人脸识别中的应用
2010-05-05 22:55:38朱玉莲
朱玉莲
(南京航空航天大学信息科学与技术学院,南京,210016,中国)
INTRODUCTION
Ensemble algorithm trains multiple component classifiers and then combines their predictions using certain fusion rules.Since the generalization ability of the ensemble of multiple classifiers is significantly better than that of a single classifier,the ensemble algorithm has become an active area of research in pattern recognition and machine learning[1-3].In ensemble algorithm,the accuracy of component classifiers and diversity between classifiers are two key properties[4].High diversity assures that different component classifiers make different errors on the same patterns,which means that,by combining classifiers,one can arrive at an ensemble with more accurate decisions.So the diversity greatly affects the recognition performance of the classifier ensemble.Perturbing the training set and perturbing the feature set are two popular schemes to achieve the diversity[5]. Among the methods based on perturbing the training set,Bagging[6]is one of the most famous ensemble construction algorithms.Bagging firstly generates many sample sets from the original data set via bootstrap sampling,then trains a single component learner on each of these sample sets and finally forms an ensemble using certain combining way.Bagging has been achieved great successes in machine learning. However,Bagging often encounters two problems:(1)it hardly works on stable component classifiers,such as nearest neighbor classifiers due to the lack of so-desired diversity among component classifiers,notwithstanding the nearest neighbor classifiers have superior error rate fallen into the range between Bayes error and two times Bayer error[7]and are very useful in the real application;(2)Bagging is difficult to be directly applied to the face recognition task with the small sample size(SSS)[8]property since the component classifiers of Bagging are constructed just on smaller bootstrap sample sets.In this paper,the approach,termed as local Bagging(L-Bagging),is proposed to apply Bagging to nearest neighbor classifiers and face recognition.The major difference between Bagging and L-Bagging is that Bagging establishes component classifiers on different sample sets bootstrapped from the whole training face set while L-Bagging performs bootstrap sampling on each local region[1,9,10].More specifically,the original face images are firstly partitioned into local regions in a deterministic way to form local region training sets,then component classifiers are constructed on different bootstrapped sample sets from each local region,and finally a combination of all the component classifiers is formed for the final decision.Since the dimensionality of local region is usually far less than the number of samples,and the component classifiers are constructed in different local regions,L-Bagging cannot only effectively deals with SSS problem of face recognition,but also generates diverse component classifiers.
There are four major characteristics of the proposed L-Bagging. Firstly, L-Bagging constructs diverse component classifiers,so it can work well on stable classifiers such as nearest neighbor classifiers;Secondly,L-Bagging relaxes SSS problem of the face recognition,so it can be directly applied to the face recognition task;Thirdly,L-Bagging can simultaneously train a set of classifiers corresponding to different local regions and thus is quite suitable for parallel computation to greatly improve the computational efficiency;Finally,the partition of local regions in L-Bagging is independent on the dimension of the face image,therefore it can also escape the latent dimensional curse when the dimension of the images is quite large.
1 LOCAL BAGGING
In this section,L-Bagging approach is proposed by performing bootstrap sampling on different local region sets. The goal of performing bootstrap sampling on different local region sets is three-fold:(1)to constructe diverse component classifiers and adapt Bagging to nearest neighbor classifiers;(2)to solve SSS problem and further make Bagging apply to face recognition task;(3)to use as much local information hidden on face images as possible to relax the influence of local variation for recognition.The L-Bagging of structure is illustrated in Fig.1.
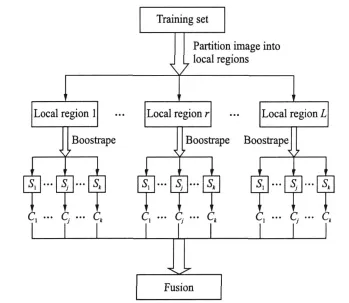
Fig.1 L-Bagging structure
From Fig.1,it can be observed that L-Bagging involves three main steps:partitioning local region,training component classifiers and classifying an unknown image.
Step 1 Partitioning local region.There are two popular techniques to implement the image partition: facial components and local regions.Since local region method usually can obtain better performance than facial component method[11],in this paper,the simplest rectangular region is selected to the partition image.Supposing that there are Mm×nimages belonging to C individuals in the whole training set,each image is firstly divided into L equally sized local regions in a nonoverlapping way which are further concatenated into corresponding column vectors with dimensionality of(m×n)/L.Then,these vectors are collected at the same position of all face images to form a specific local region training set,thus,L separating local region sets(Local1,…,LocalL)are formed.This process is illustrated in Fig.2.
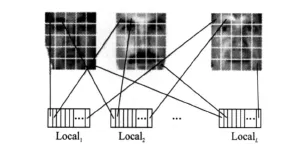
Fig.2 Construction of local region sets of face images(images from Yale face database)
Step 2 Training component classifiers.After forming the local region sets,multiple classifiers are trained on each local region set.For each local region set Locali(i= 1,…,L),a bootstrap replication is generated by random sampling from the local region set,then a nearest neighbor classifier Ci,1is constructed on the bootstrap replication. The process is independently repeated t times,so t classifiers Ci,j(j= 1,…,t)are constructed on each local region set.Since there are L local region sets for the whole train sample set,L* t the nearest neighbor classifiers are constructed.
Step 3 Classifying an unknown image.When an unknown face images A is given,it is firstly partitioned into L local regions(A1,…,AL)according to the same partition way on the training images,then each region Ai(i=1,…,L)is classified using component classifiersCi,j(j=1,…,t).Since there are t classification results for each local region Aiand A consists of L local regions,there are L* t total classification results for the unknown image A.Majority voting rule is used to combine these classification results,i.e.,if the probability of the image A belonging to the cth class is
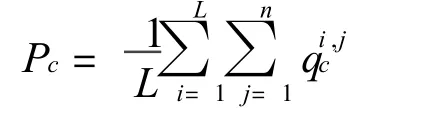
then the finalclassification resultofA is:Identity(A)=argmax(Pc).
2 EXPERIMENTAL RESULTS AND ANALYSIS
In order to evaluate the performance of LBagging,experiments are carried out on four standard face image databases:AR,Yale B,Yale and ORL.
2.1 Face image databases
The used face database AR contains 2 600 frontal face images of 100 different individuals(50 men and 50 women).Each individual has 26 different images in two different sessions separated by two week intervals and each session consists of 13 faces with different facial expressions,illumination conditions and occlusions.Fig.3 shows all samples of one person in AR.
The extended Yale face database B contains 1 920 single light source images with the frontal pose for 30 subjects(delete the 11 th-18 th individuals due to some bad or damaged images).The image size is resized to 48×42 and the same strategy in Ref.[12]is adopted to divide the images of each individual into five subsets according to the angle of the light source direction.
The Yale face database consists of 165 face images of 15individuals,each providing 11 different images.While the ORL database contains images from 40 subjects with 10 different images for each subject.
In the preprocessing step,face images in AR database and Yale database are rotated to make eyes horizontal and cropped to size 66× 48 and 50×50,respectively.In the ORL and Yale B databases,face images are resized to 56×46 and 48×42 without any other preprocessing.
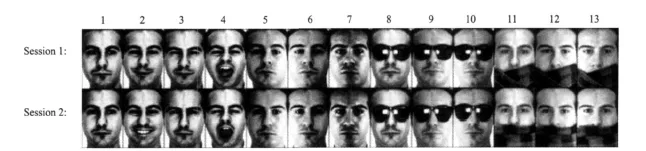
Fig.3 Example images in face database AR
2.2 Experimental results
In the experiments,for the AR database,the first seven images in Session 1 are selected for training and the rest images which are divided into six subsets according to the variation category(AR73Exp:2nd—4th in Session 2;AR73Illu:5th—7th in Session 2;AR73SungS1:8th—10th in Session 1;AR73Scarf1:11th—13th in Session 1;AR73SungS2:8th—10th in Session 2;AR73-Scarf2: 11th—13th in Session 2)are utilized to examine the performance of proposed methods under variance conditions.For Yale B database,The images in SubSet 1 are selected for training,and the images in the other four subsets are selected for testing,respectively.While for Yale and ORL databases,a random subset with five images per person is taken to form training set and the rest of the database is considered to be the testing set.In experiments,the sizes of local region for AR,Yale B,Yale and ORL databases are 6×6,6×7,5×5 and 7×2,respectively and Mahcosine[13]metric is used to construct the nearest neighbor classifiers.
To evaluate the performance of L-Bagging,L-Bagging is compared with single classifier methods including Baseline(directly use the nearest neighbor classifiers without preprocessing),Eigenfaces,Fisherfaces,M-Eigenfaces which is based on local recognition,and with the ensemble algorithms Nitesh′RS[2]and Bagging.The corresponding classification results are listed in Table 1.
From the experimental results,one can achieve several conclusions:(1)the recognition accuracy of Bagging is very similar with of Baseline,i.e.,Bagging is not superior to Baseline.It indicates that Bagging does not work well for the nearest neighbor classifier with Mahcosine distance metric;(2)on all of test sets,L-Bagging is significantly superior to all compared methods including Baseline,Bagging,Eigenfaces,Fisherfaces and Nitesh′RS(the minimal improvement is over 1.6%and the maximal one is close to 60%),especially when the test image contains serious occlusion,which indicates that L-Bagging is more effective and competitive;(3)L-Bagging is also effective to slight variations at pose angle and alignment one.Therefore,L-Bagging not only can obtain high recognition accuracy,but also is suitable to the nearest neighbor classifiers.
2.3 Comparison of computation time
In this section,experiments are performed to compare the cost time of different methods,and computation time including training and testing time is shown in Table 2.Table 2 shows that althought L-Bagging is more time-consuming than Nitesh′RS,it does not cost more time than Bagging,especially when the size of block is very small.So L-Bagging is superior to Bagging at the computation time.
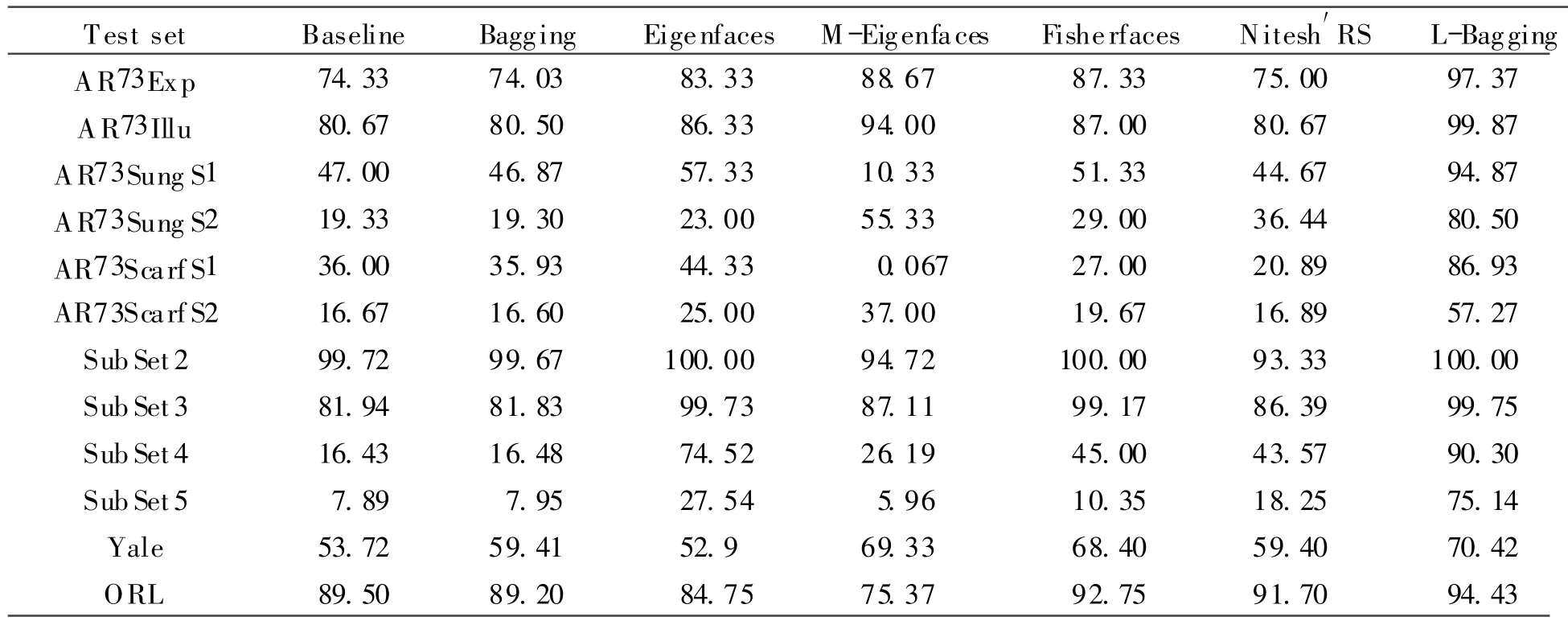
Table 1 Classification performance comparison with different methods %
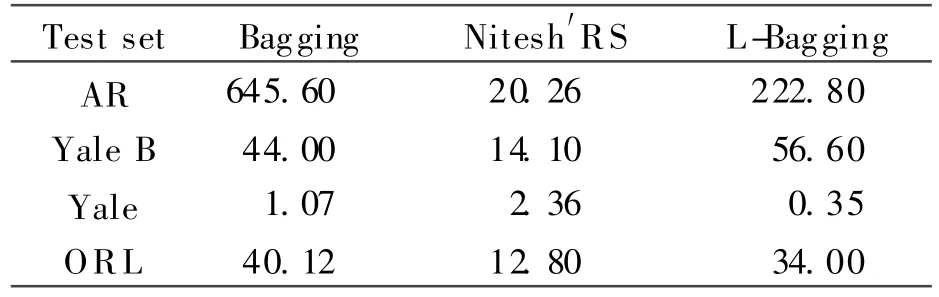
Table2 Comparison of computation time s
3 CONCLUSION
The L-Bagging approach is proposed to simultaneously make Bagging capable of applying to both nearestneighbor classifiers and face recognition.L-Bagging performs bootstrap sampling in different local region sets,as a result,it not only effectively deals with SSS problem,but also generates more diverse component classifiers.Experimental results on standard face image databases demonstrate the good classification performance and computational efficiency of LBagging.It is worth to note that,although the whole paper concentrates on Bagging,the proposed line of the research about L-Bagging is general.Through combining the spatial and geometrical information of facial components in local way,many current multi-category classifiers can also be applied on the face recognition and may obtain better recognition performance.Furthermore,tensor subspace models are one of the modern research directions in the face recognition.Many researches have showed that representing the images as tensors of arbitrary order can further improve the performance of algorithms in most cases[14,15].Consequently,how to generalize L-Bagging to tensor learning is another interesting topic for future study.
[1] Zhu Yulian,Liu Jun,Chen Songcan.Semi-random subspace method for face recognition[J].Image and Vision Computing,2009,27(9):1358-1370.
[2] Nitesh V,Chawla,Bowyer K.Random subspaces and subsampling for 2-D face recognition[C]∥IEEE Conference on Computer Vision and Pattern Recognition.[S.l.]:IEEE Computer Society,2005:582-589.
[3] Wang Xiaogang,Tang Xiaoou.Random sampling forsubspace face recognition [J].International Journal of Computer Vision,2006,70(11):91-104.
[4] Dietterich T G.Ensemble methods in machine learning[J].Lecture Notes in Computer Science,2000,1857:1-15.
[5] Kuncheva L I,Witaker C J.M easures of diversity in classifier ensembles and their relationship with the ensemble[J].Machine Learning,2003,51(2):181-207.
[6] Breiman L.Bagging predictors[J].Machine Learning,1996,24(2):123-40.
[7] Duda R O,Hart P E,Stork D G.Pattern Classification.2nd Edition ed[M].New York:Wliey-Interscience Press,2000:78
[8] Tan Xiaoyang,Chen Songcan,Zhou Zhihua.Face recogntion from a single image per person:A survey[J].Pattern Recognition,2006,39(9):1725-1745.
[9] Pentand A,Moghaddam B,Starner T.View-based and modular eigenspaces for face recognition[C]∥IEEE Computer Society Conference on Computer Vision ans Pattern Recognition,2T.[S.l.]:IEEE Computer Society,1994:84-91.
[10]Tan Keren,Chen Songcan. Adaptivelyweighted sub-pattern PCA for face recognition[J].Neurocomputing,2004,64:505-511.
[11]Zou Jie,Ji Qiang,Nagy G.A comparative study of local matching approach for face recognition[J].IEEE Transactions on Image Processing,2007,16(10):2617-2628.
[12]Lee K,Ho J,Kriegman D.Acquiring linear subspaces for face recognition under variable lighting[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2005.27(5):1-15.
[13]Beveridge J R,Bolme D,Draper B A,et al.The CSU face identification evaluation system:its purpose,features,and structure[J].Machine Vision Application,2005,16(2):128-138.
[14]Zhou Huiyu,Yuan Yuan,Sadka A H.Application of semantic features in face recognition[J].Patter Recognition,2008,41(10):3251-3256.
[15]Xu Dong,Yan Shuicheng, Tao Dacheng,et al.Marginal fisher analysis and its variants for human gait recognition and content-based image retrieval[J].IEEE Trans on Image Processing,2007,16(11):2811-2821.
猜你喜欢
中国机械工程(2022年21期)2022-11-21 11:57:48
中国机械工程(2022年7期)2022-04-20 03:24:20
作文中学版(2022年1期)2022-04-14 08:00:34
山西大同大学学报(自然科学版)(2022年1期)2022-03-17 05:56:40
中国机械工程(2021年23期)2021-12-15 13:31:00
数据采集与处理(2021年4期)2021-09-20 10:26:56
中学数学研究(江西)(2020年7期)2020-07-22 06:34:40
学生天地(2020年31期)2020-06-01 02:32:06
池州学院学报(2017年3期)2017-10-16 01:38:53
中国科技期刊研究(2016年11期)2016-04-17 07:22:28
 Transactions of Nanjing University of Aeronautics and Astronautics2010年3期
Transactions of Nanjing University of Aeronautics and Astronautics2010年3期
- Transactions of Nanjing University of Aeronautics and Astronautics的其它文章
- TRANSACTIONS OF NANJING UNIVERSITY OF AERONAUTICS&ASTRONAUTICS
- 不同温度和应变速率下7022铝合金流变应力行为
- 纳米TiC粉末改性钎料钎焊CBN磨粒的结合界面和磨损特性
- 基于变换空间近邻图的自助型局部保持投影
- 考虑不确定性因素的多学科设计优化方法