
垂直搜索引擎爬虫系统的设计
2010-04-21 05:18长江大学计算机科学学院湖北荆州434023
长江大学学报(自科版) 2010年7期
李 敏,赵 君 (长江大学计算机科学学院,湖北荆州434023)
在某些专业领域,如房地产、电子商务领域等,传统搜索引擎已经无法满足用户的需求,为解决该问题,研究者提出垂直搜索引擎的设计构想。垂直搜索是针对某一行业的专业搜索引擎方式,其对互联网海量信息中的某类专门信息的搜集和整合。爬虫系统负责获取互联网中的海量数据,是垂直搜索引擎的核心,对整个引擎的运行效率有着重大影响。为此,笔者就如何设计高效率的垂直搜索引擎爬虫系统进行了详细探讨。
1 垂直搜索引擎的工作模式
垂直搜索引擎首先委派爬虫系统到目的网站下载相应信息,并将这些信息存入网页库,然后由索引模块对网页库进行索引结构化处理,形成相应的索引文件 (索引库)[1]。当用户在网页终端查询信息时,系统会检索索引文件,并将最终结果呈现给用户,其工作模式如图1所示。
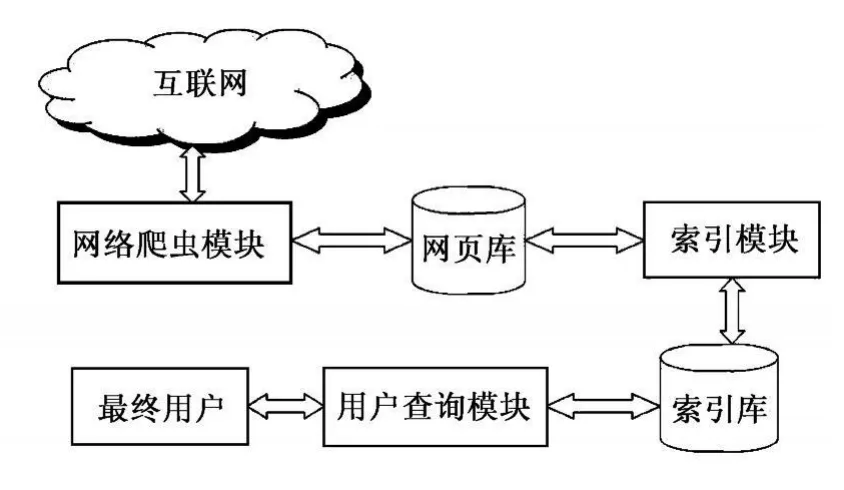
图1 垂直搜索引擎的工作模式图
2 爬虫系统的运行流程
因为爬虫系统的运行和管理是整个系统的核心,所以,对抓取庞大数据的爬虫系统而言,设计一个科学的运行流程至关重要,因为该流程直接影响着整个搜索引擎的工作效率。在爬虫系统的运行过程当中,要充分考虑共享资源的互斥访问和运行效率之间的矛盾,应尽量减少爬虫在访问队列中的等待时间,并适当地运用缓冲区 (如队列缓冲区或栈缓冲区)[2]。根据效率优先的设计原则,笔者所设计的该爬虫系统的运行流程图如图2所示。
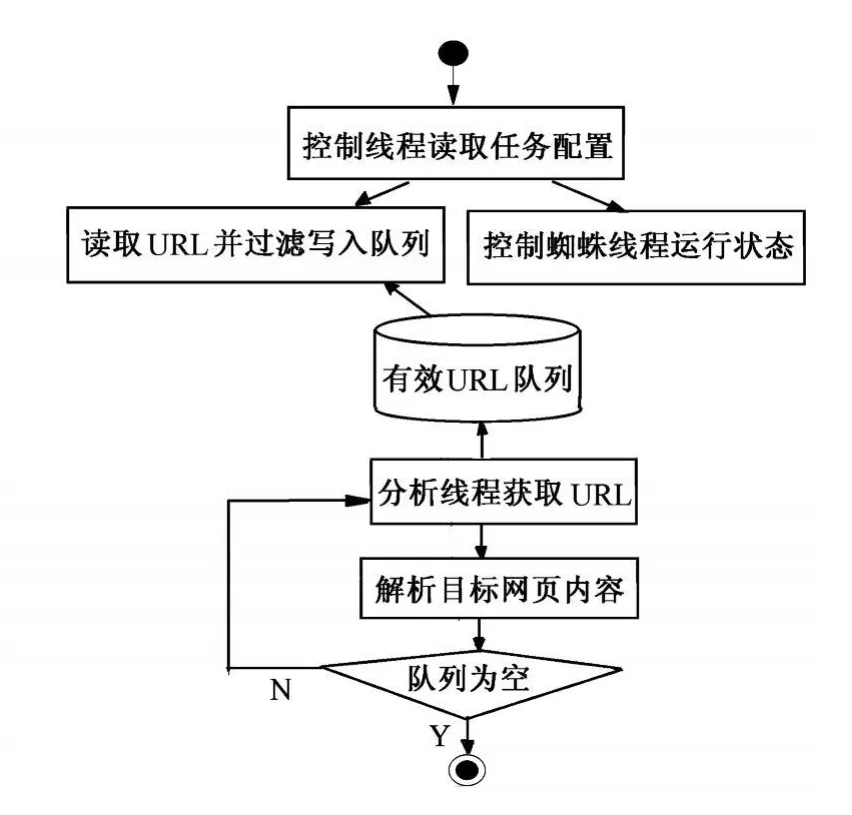
图2 爬虫系统运行流程图
3 爬虫系统的主要业务逻辑
爬虫系统的主要业务逻辑包括爬虫运行过程当中的配置参数及其数据结构,笔者仅就配置参数的相关内容加以阐述。
爬虫运行过程当中的配置参数包括授权参数、频道配置参数、数据库配置参数、任务配置参数和爬虫抓取参数[2]。其中授权参数包括频道数量、单个频道数据量上限、总数据量上限、频道内任务数上限、工作线程数上限、深度上限、是否启用抓图功能、是否启用视频批量抓取功能、是否启用任务调度功能。
为了用户操作方便,一般将数据库配置参数集成到频道配置参数中。因此,频道配置参数包括频道数量、频道名、频道字段属性 (字段名、字段是否为空)、频道数据库连接配置、数据表配置和任务基本信息配置。频道数据库连接配置中,根据目前的业务需要,数据库类型暂时设置为 SqlServer、MySql和Oracle,并预留好接口,以便随时增加数据库类型。用户在此设置服务器地址、用户名、密码和数据库。在数据表配置里,用户可以进行如下操作:①定义多个信息储存表和每个表的最大记录数,以分散单个表的访问负荷;②设定每个字段的字段名和长度,根据其需要设置去重字段和增加从表;③根据预先设置的字段定义字段的名称和长度 (为保证容错性,字段的类型均为字符串型),对某个大容量字段设定从表 (如视频采集中的URL地址)。此外,任务基本信息配置包括任务的ID和任务名,用于树形菜单的显示。
任务配置参数包括任务基本属性、路径配置、抓取规则配置和任务调度配置。软件启动后,将读取频道配置信息和任务配置信息。任务基本属性选项卡中可以配置任务名称、所属频道、爬虫抓取延迟[3](为避开大网站反抓取机制,需要设置延迟)、工作线程数、爬行深度 (入口页面的深度为1)、有效数据抓取深度[3](为提高爬虫抓取效率,可以设定目标数据所在页面的深度,以避开无效页面的干扰)。爬虫抓取延迟有3项选择:没有延时、固定延时和随机延时,用户可以根据实际情况选择。在路径配置和抓取规则配置中,将动态路径规则、静态路径规则和固定字段值等功能放在同一个窗口里,以减少操作步骤,从而增加操作友好性。同时增加数据抽取测试页面,让用户可以实时查看配置的正确性。爬虫系统还可对抓取后的数据进行分析和处理,即添加数据分析功能,用户能够根据实际需要对每个字段对应的抽取值进行替换、筛选和补充。任务调度配置的内容包括用户可以设置是否启用任务调度以及调度起始时间、调度终止时间。如果起始时间小于当前时间,则当前时间为起始时间;如果终止时间小于当前时间,则调度无效,此外,还可以设置调度频率。
爬虫抓取参数为非可视化技术内核,是爬虫抓取功能的实现部分,将根据各块配置进行数据抓取。爬虫抓取参数包括主控制台和分析爬虫。该模块可实现如下功能:①主控制台线程负责抓取全站URL,并根据用户的设置过滤掉无效的和重复的URL,同时控制分析线程的运行状态。根据用户的配置,将符合要求的URL记录到文件或数据库中,已记录者不再记录。当所有URL读取完成,自动按用户定义的规则处理还没有内容抽取的URL。②根据用户配置可以采集JavaScript中的网址。③采集需要登录后才能查看的信息。④入口网址规则中可设定多个变化参数,如Test.aspx?param1=a¶m2=b,其中参数值a和b都可以设为动态参数;⑤用户可以使用可视化正则规则生成器 (动态路径生成器)。⑥通过加入代理 (自定义代理,采集过程中可自动定时切换成代理模式)等功能突破网站防采集机制,代理的配置放在入口URL中。⑦设定网址读取上限时间,如超过5s读取不成功的网址,自动丢弃该网址。
4 爬虫系统用到的主要设计模式
在该系统设计中,使用的模式有单件模式、观察者模式、工厂模式和抽象工厂模式。在上述模式中,观察者模式最为常用,其目的是降低各个对象之间的耦合度,使各个组件更利于维护。观察者模式包括观察者接口IObserver、被观察主体接口IObservable、被观察主体抽象类SubjectBase,其模型图分别见图3和图4。凡是需要抛出事件的对象 (即被观察的对象)均继承IObservable接口或SubjectBase抽象类;凡是根据外部事件更新的对象 (即观察者)均继承IObserver接口,并实现Update方法,这样就形成了一种松散耦合的方式,降低了观察者对被观察对象的依赖。

图3 观察者接口的类模型图
5 爬虫系统的项目信息及其关系图
该设计模块 (解决方案)包含7个子项目,从低层到高层分别是 DevHelper、Common、Kernel、DataProvider、Components、 Configuration(Controls)和 App。其中,DevHelper为第三方开源工具项目,包含众多功能强大的第三方工具源代码。
Common为通用项目,包含各种通用功能,各种通用模式均定义在这个项目中。该项目中还包括线程管理器接口IThreadManager,任务状态枚举 TaskStateEnum,通用参数类CommontArgs(解决方案中被观察对象抛出的数据均为CommontArgs的对象),线程管理器抽象工厂类 AbsThreadManagerFactory(用以制造线程管理器对象),同步队列类SyncQueue,同步字典类SyncDictionary,运行时错误处理委托RuntimeErrorEventHandler(用以定义运行时错误处理事件,是一种特殊的观察者模式,和普通观察者模式有所区别),通用事件处理委托CommonEventHandler(用以定义普通事件)。可视化XPath生成器模块也在该项目中定义和实现。

图4 被观察对象的类模型图
Kernel为爬虫系统的业务核心项目,所有的接口和核心业务类,包括配置文件的数据结构、数据读取和保存函数的实现,此外,还包括配置类ConfigData的定义、多线程中线程池管理器CrawlerThreadManagerPool、多线程管理器CrawlerThreadManager的实现、线程运行类CrawlerWork的定义、页面信息类PageInfo、页面信息管理器类PageInfoManager和运行时信息处理类 RuntimeSaveInfo。爬虫运行时RuntimeSaveInfo类只有一个对象,爬虫每解析一条合格数据,都要通知该对象,以记录运行时的信息。
DataProvider为数据访问模块,其功能是将采集到的数据写入到数据库中 (包括数据处理接口IDataProvider的实现);Components为与运行时有关的通用功能模块;Configuration为控件模块,所有与配置相关的用户控件均定义在该项目中;App为运行项目。7个项目的逻辑依赖关系如图5所示。
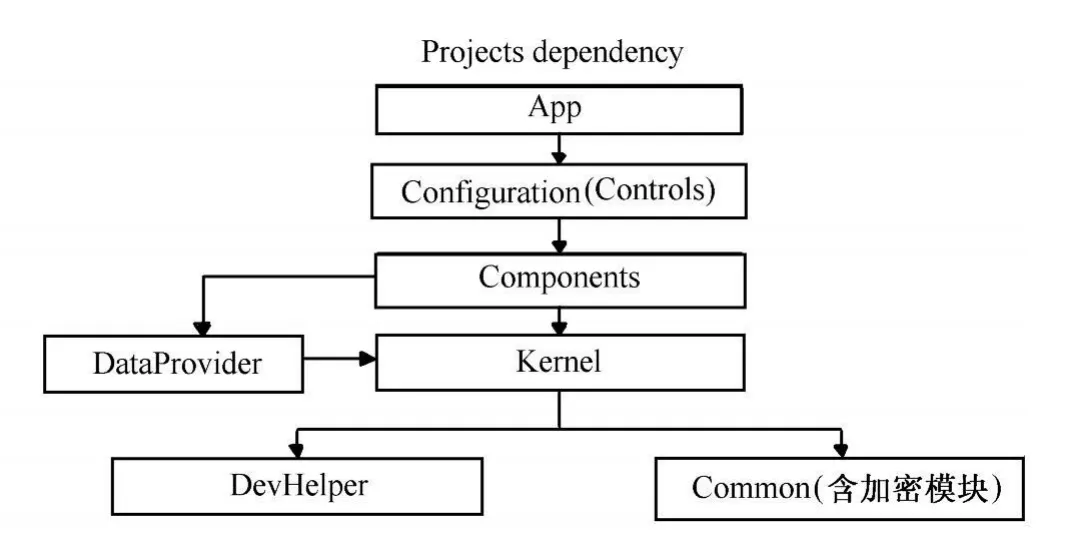
图5 项目逻辑依赖关系图
6 结 语
从垂直搜索引擎的工作模式入手,根据搜索效率优先和功能模块之间高内聚低耦合的原则,对如何设计高效率的爬虫系统的进行了详细探讨,并论述了该方案的业务逻辑和主要设计模式,进而在此基础上构建了爬虫系统项目逻辑依赖关系图。经测试,在网络不拥堵的情况下,单日24h可采集并分析40万条数据,因而该系统具有非常好的运行效率。此外,该设计方案还具有良好的可维护性和伸缩性,为今后进一步开展再编程和扩展的研究工作提供了方便。
[1]胡燕.基于Web信息抽取的专业知识获取方法研究[D].武汉:武汉理工大学,2007.
[2]杨坚争,李朝平.垂直搜索引擎及其应用 [J].遥感信息,2005,(10):23~25.
[3]吕林涛,陈丽萍,周红芳.面向垂直搜索引擎的主题提取算法[J].计算机工程,2009,35(15):24~26.
猜你喜欢
房地产导刊(2022年10期)2022-10-18
现代信息科技(2021年21期)2021-05-07
语言与文化论坛(2019年4期)2019-03-29
电子制作(2017年9期)2017-04-17
中国卫生(2015年12期)2015-11-10
电子设计工程(2015年6期)2015-02-27
新疆大学学报(自然科学版)(中英文)(2014年2期)2014-11-06
微处理机(2013年4期)2013-07-20
科学导报·学术论坛(2013年5期)2013-06-26
通化师范学院学报(2013年4期)2013-02-15
