
基于国产CPU的雷达信号处理设计和实现
2023-10-12 07:22游英杰
火控雷达技术 2023年3期
王 岩 杨 刚 游英杰
(西安电子工程研究所 西安 710100)
0 引言
近年来,随着雷达系统技术的快速发展和应用需求的不断增加,传统以FPGA+DSP为硬件架构的雷达信号处理系统面临着极大的挑战[1-2]。FPGA具有强大的运算能力和传输带宽,但算法设计复杂且不够灵活,软件调试周期长。DSP开发灵活度高,但单片DSP计算能力较弱,对于运算量高的大型阵列雷达系统需要多片DSP才能完成检测处理,复杂的任务划分导致程序调试和维护困难。近些年,雷达信号处理系统开始尝试使用进口CPU完成处理功能,基于CPU实现雷达信号处理系统便于实现复杂的算法流程,可以大幅度缩短软件调试周期,软件模块易于复用和移植[3-4]。然而长期依赖于进口CPU面临着严重的信息安全隐患以及随时可能被禁用的风险。在我国大力发展电子信息软硬件技术自主可控的趋势下,国产CPU和操作系统在近些年得到迅速发展,其中较为成熟的飞腾FT2000+/64 CPU和银河麒麟Linux操作系统已在各研究领域尝试使用[5-6]。
本文基于国产飞腾FT2000+/64 CPU和银河麒麟Linux操作系统设计了并行雷达信号处理算法,以雷达信号处理中常用的动目标检测(Moving Targets Detection,MTD)和恒虚警率(Constant-False-Alarm Rate,CFAR)处理为例,介绍了国产CPU上雷达信号处理的设计流程、计算误差和使用不同CPU核时的处理时间。
1 信号处理算法
动目标检测(Moving Targets Detection,MTD)是一种提高雷达在杂波背景下检测运动目标的能力的技术,一般使用FFT或多普勒滤波器组抑制杂波,本文使用FIR滤波器的方式进行MTD处理[7]。
恒虚警率(Constant-False-Alarm Rate,CFAR)处理是雷达目标检测中常用的一种手段,目的是在干扰下保持信号检测时的虚警率恒定。CFAR处理时需要先根据检测单元内的噪声和干扰确定一个门限,然后用此门限和检测单元信号比较后判断是否有目标[7]。常用的CFAR处理技术包括CA(Cell Averaging)-CFAR、GO(Greatest of)-CFAR、OS(Order Statistics)-CFAR等,本文中的测试程序使用GO-CFAR完成恒虚警检测。
2 软硬件平台选择
硬件平台使用国产飞腾FT2000+/64 CPU处理器,该CPU集成64个自主开发的兼容ARMv8指令集的处理器核,采用基于数据亲和的多核处理器体系结构,计算能力和访存带宽在国内处于领先水平。
操作系统使用银河麒麟Linux操作系统,该操作系统支持飞腾、龙芯、海光等国产CPU平台,并且稳定易用,支持Qt和Eclipse等开发环境,提供配套的编译、测试和调试工具,本文中的程序均使用Eclipse编译和调试。
计算中间件使用OpenBlas函数库,OpenBlas是一个开源的线性代数运算函数库,该函数库对于高性能计算有需求的应用提供支持。OpenBlas支持FT2000+/64 CPU的ARMv8架构,在编译时会根据所使用的硬件进行优化,生成针对所使用硬件效率很高的函数库[8]。
并行编程框架使用Pthread编程模型,Pthread是一套基于共享内存的线程库,该线程库为用户提供了创建和使用线程的一系列API,用户在创建线程时可以设置线程优先级、调度策略和堆栈大小等参数,根据需要分配每个线程完成的任务[9]。
3 软件设计架构
本文软件设计的处理流程如图1所示,各模块间的并行处理采用流水线的方式实现,各处理模块接收上一级模块输出的数据,上一级模块的数据保存在全局内存中,后一级模块直接从全局内存地址上获取数据。为了保证各模块处理时间的稳定性,首先对使用到的CPU核进行核隔离,然后在创建线程后,绑定各处理模块的线程到指定的CPU核上。线程间使用信号量和全局变量等方式通信,读写全局变量时使用互斥锁防止内存冲突。各处理模块使用全局内存在线程间共享数据,使用各模块独立的数据循环队列容忍处理时间的抖动。MTD和CFAR处理模块使用参数化设计,可以根据需要灵活配置使用的核数和各线程需要计算的数据。
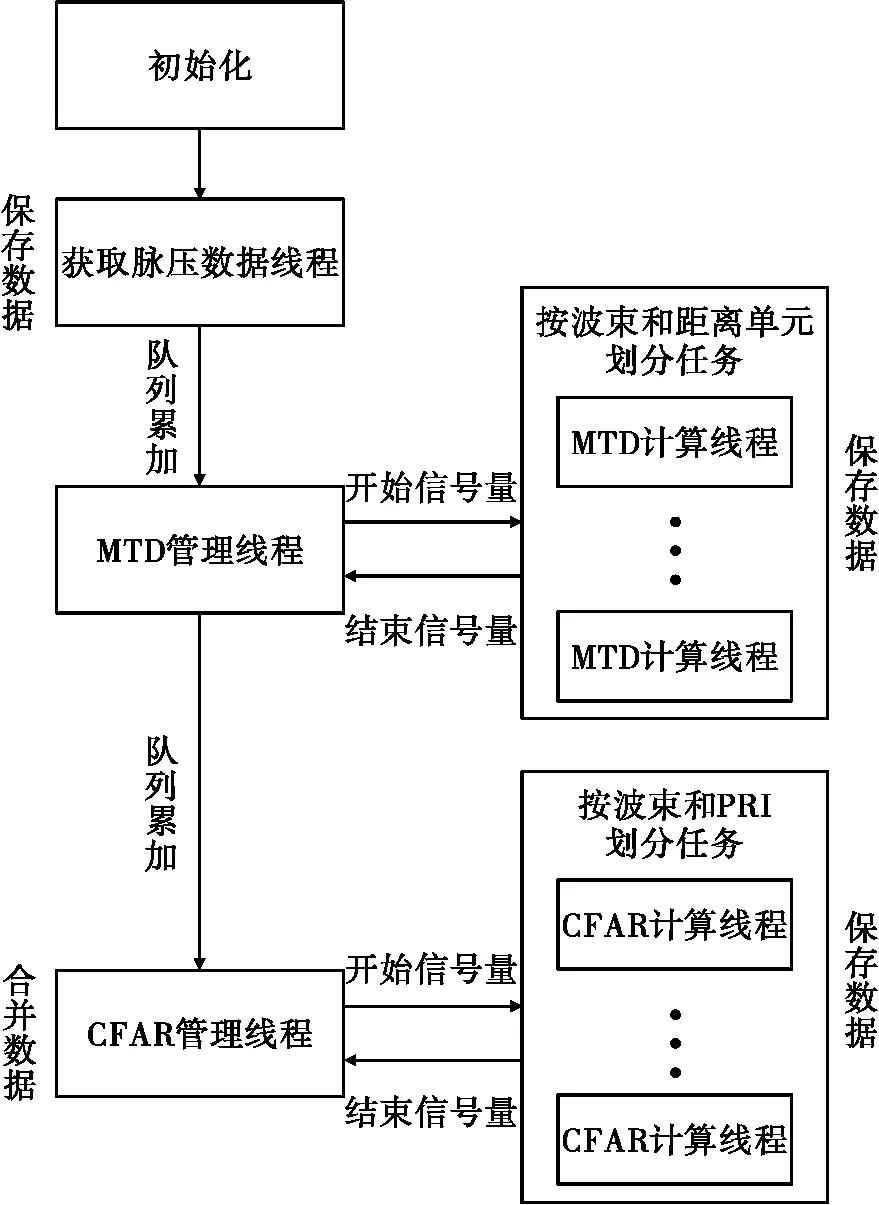
图1 软件设计架构
脉冲压缩数据获取模块需要创建1个脉压数据获取线程,并将线程绑定到指定CPU核上。该线程将数据保存在一个使用全局内存的脉冲压缩数据循环队列中,通过累加队列计数值全局变量的方式通知MTD模块处理,使用全局变量的过程中使用内存互斥锁防止冲突。
MTD处理模块需要创建1个MTD管理线程和多个MTD计算线程,并绑定线程到指定CPU核上。MTD管理线程通过循环查询脉压数据队列计数值全局变量的方式等待脉压数据到达,读取脉压数据队列计数值的过程中,使用互斥锁防止内存冲突。获取到脉压数据后,MTD管理线程释放所有MTD计算线程对应的计算开始信号量,并等待所有MTD计算线程结束信号量。完成计算后,累加MTD数据队列计数值全局变量,通知CFAR模块处理。MTD计算线程按照波束数和距离单元划分每个线程的任务。例如,每个PRI包含两个波束的脉压数据,使用4个CPU核时,创建4个MTD计算线程,任务划分为每两个核计算1个波束,每个核计算1/2距离单元的数据。使用8个CPU核时,创建8个MTD计算线程,任务划分为每4个核计算1个波束,每个核计算1/4距离单元的数据。使用16和32个CPU核时,任务在线程间的划分方式类似。MTD处理模块使用FIR滤波器的方式实现,每个MTD计算线程将需要计算的数据从脉冲压缩数据全局内存队列复制到临时内存中,通过调用OpenBlas的复数矩阵乘法函数完成对应数据段的计算,然后将计算结果保存在MTD数据全局内存循环队列中,用于后续的CFAR处理。
CFAR处理模块需要创建1个CFAR管理线程和多个CFAR计算线程,并绑定线程到指定CPU核上。CFAR管理线程通过循环查询MTD数据队列计数值全局变量的方式等待MTD数据到达,读取MTD数据队列计数值的过程中,使用互斥锁防止内存冲突。获取到MTD数据后,CFAR管理线程释放所有CFAR计算线程对应的计算开始信号量,并等待所有CFAR计算线程结束信号量。所有CFAR计算线程完成计算后,将多个CPU核计算的CFAR结果汇总,并累加CFAR数据队列计数值全局变量,用于通知后续处理任务。CFAR计算线程按照波束数和积累点数划分每个线程的任务。例如,对于积累点数为32并且每个PRI含两个波束的数据,使用4个CPU核时,创建4个CFAR计算线程,任务划分为每两个核计算1个波束,每个核计算16个PRI的数据。使用8个CPU核时,创建8个CFAR计算线程,任务划分为每4个核计算1个波束,每个核计算8个PRI的数据。使用16和32个CPU核时,任务在线程间的划分方式类似。CFAR模块使用GO-CFAR的方式处理,每个CFAR计算线程将需要计算的MTD数据求模值后保存在MTD模值数据临时内存中,依次循环码片和距离单元完成CFAR检测,将计算结果保存在CFAR数据全局内存循环队列中,最后由CFAR管理线程合并每个CPU核的检测结果。
4 测试结果
本文中使用到的测试数据每个CPI的积累点数为39,每个PRI两个码片,每个码片含两个波束脉冲压缩后的数据,第1个波束的脉冲压缩数据如图2所示。

图2 第1个波束脉压数据
图3为FT2000+ CPU上并行执行MTD处理的结果,图4为CPU和Matlab对相同的脉冲压缩数据完成MTD处理后结果的差值。如图4所示,CPU和Matlab MTD处理结果的差值在10-4左右,满足雷达信号处理检测的误差要求。

图3 第1个波束MTD结果

图4 第1个波束MTD差值
图5为FT2000+ CPU上并行执行GO-CFAR处理后得到的MTD平面图,图6为CPU和Matlab对相同的MTD数据完成GO-CFAR处理后得到的MTD平面的差值,结果显示,CPU和Matlab GO-CFAR通过检测的目标点一致。

图5 第1个波束GO-CFAR结果

图6 第1个波束GO-CFAR差值
表1是在FT2000+ CPU上并行执行的MTD和CFAR模块使用不同CPU核时的处理时间和加速比。由于软件中MTD和CFAR处理模块使用参数化设计,测试时可以灵活配置使用的CPU核数。程序编译时仅对MTD和CFAR处理模块的关键计算函数进行O3优化,分别统计使用不同数目CPU核时完成100次处理的平均时间,时间单位为ms,括号中的数值为并行处理的MTD和CFAR模块相对于串行程序的加速比。测试结果如表1中所示,CPU上32核并行的MTD处理程序相对于单核串行程序达到了13倍的加速,32核并行的GO-CFAR处理程序相对于单核串行程序达到了19.5倍的加速。对于常规的雷达信号处理系统,FT2000+ CPU可以满足处理性能的要求。

表1 FT2000+/64 CPU上MTD和CFAR并行处理时间和加速比
表2是在进口的Intel Xeon D2183 CPU上并行执行的MTD和GO-CFAR模块使用不同CPU核时的处理时间,时间单位是ms。Intel Xeon D2183 CPU的单核性能强于国产的FT2000+ CPU,但是该处理器只有16个CPU核,而FT2000+ CPU有64个CPU核,通过增加CPU核数,在FT2000+ CPU上并行执行的MTD和CFAR模块可以达到和Intel Xeon D2183 CPU接近的处理性能。

表2 Intel Xeon D2183 CPU上MTD和CFAR并行处理时间
5 结束语
随着雷达系统技术的快速发展,雷达信号处理的灵活性和国产化需求逐步提高。本文基于国产FT2000+ CPU和银河麒麟操作系统设计了并行雷达信号处理算法,测试结果显示,国产FT2000+ CPU上并行处理的MTD和CFAR模块满足计算精度和处理时间要求。MTD和CFAR处理模块使用参数化设计,可以根据雷达信号处理系统的需要灵活配置核数和任务分配策略。对于有国产化需求的雷达系统,使用FT2000+ CPU完成雷达信号处理功能是一种可行的方案。
猜你喜欢
小学生学习指导(低年级)(2020年4期)2020-06-02
软件(2020年3期)2020-04-20
军营文化天地(2018年2期)2018-12-15
信号处理(2018年5期)2018-08-20
信号处理(2018年5期)2018-08-20
信号处理(2018年8期)2018-07-25
信号处理(2018年8期)2018-07-25
产品可靠性报告(2017年7期)2017-09-05
环球市场(2017年36期)2017-03-09
计算机工程与科学(2013年2期)2013-06-07
