
基于YOLOv5的婴儿睡姿识别
2025-01-19 00:00:00巢梓涵黄小杰黄明韩振华巢渊
物联网技术 2025年2期









摘 要:针对婴儿不正确睡眠姿势对婴儿身体健康的危害,提出了基于YOLOv5的睡姿识别方法。利用YOLOv5的Mosaic数据增强和自适应图片缩放技术处理图片的局部和全局信息,使模型拥有更好的泛化能力。在卷积模块中引入CSP结构,解决推理过程中计算量大的问题,提升检测模型的准确度,并使用坐标损失、目标置信度损失和分类损失来更新梯度损失,进一步提高识别精度。实验结果表明,该模型可高效检测、识别多种婴儿睡姿,精度高达99%,具有较为广阔的应用前景。
关键词:YOLOv5;图像识别;婴儿睡姿;智能看护;Mosaic数据增强;深度学习
中图分类号:TP242 文献标识码:A 文章编号:2095-1302(2025)02-00-05
0 引 言
近年来,婴儿看护越来越引起每个父母的高度重视,婴儿在初期阶段,由于其行为意识未充分形成,因此婴儿在睡眠期间会转换多种姿势,甚至保持有害于身体健康的姿势,所以父母需要及时纠正和调整婴儿的睡眠姿势。文献[1]研究表明,相较于仰卧位,侧卧位和俯卧位会明显增加猝死综合征(SuddenInfant Death Syndrome, SIDS)的发生率;与此同时,在人工智能迅速发展的时代,利用机器学习和图像处理技术可以有效识别婴儿睡眠姿势,助力婴儿健康成长。
随着机器学习、深度学习与图像处理技术的不断发展,姿势识别成为当前社会的研究热点。文献[2]提出了双向长短时记忆网络(Long Short-Term Memory, LSTM),解决了复杂环境下的人体识别问题。文献[3]基于BP神经网络模型采用Adaboost迭代学习方法,相比CNN卷积模型算法精度有较高的提升。文献[4]提出了一种基于注意力机制融合时空特征的深度学习睡姿检测模型,提高了睡姿检测的实时性和有效性。文献[5]提出了一种基于OpenPose的姿态估计算法,通过对人体各部位关节点的定位判断睡眠姿势,该算法适应于复杂背景下的姿势检测。文献[6]基于心冲击(BCG)信号,提出了一种睡眠姿势识别算法,非接触和无干扰采集BCG信号后通过预处理提取基于J波的特征值,识别睡眠姿势,相较于传统的神经网络和KNN网络,识别准确率有了明显的提高。
本文提出了基于YOLOv5模型的婴儿睡姿检测算法,构建了婴儿数据集,训练通过自适应锚框计算,在初始锚框的基础上输出预测框,与真实框比较,计算两者差距,再反向更新,迭代网络参数,采用路径聚合网络(PANET)增强模型的检测精度,加强模型的识别效果,提高模型的泛化能力和识别准确率。
1 数据集构建
1.1 数据采集
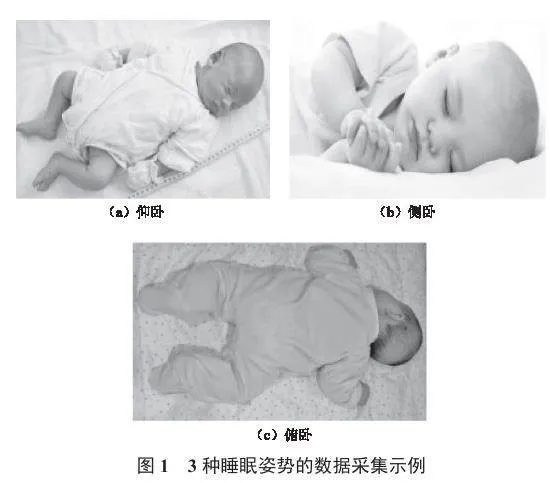
通过网络爬虫技术爬取数千张婴儿图片,经过筛选与过滤后,整理出合理有效的婴儿睡眠图片,以构建数据集。本文主要构建了单个婴儿数据集和多个婴儿数据集两大类。其中,针对单婴儿数据集,有3种睡眠姿势:仰卧、侧卧和俯卧。
1.2 数据增强
数据增强主要通过增加训练的数据量,提高模型的泛化能力,通过增加噪声数据,提升模型的鲁棒性。利用已有的数据进行翻转、平移或旋转,创造出更多数据,使神经网络具有更好的泛化效果。本文搜集了1 500幅图像,选择1 200幅图像作为训练集,300幅图像作为测试集。其中,训练集又分出400幅图像作为验证集,每幅图都通过平移、旋转等操作变成4幅图。需要注意的是,需要对训练集和测试集进行Mosaic数据增强,并确保每幅图的大小被固定为256×256。
1.3 数据预处理
数据预处理是数据建模前的重要环节,其直接影响所有图片数据处理时的质量和输出效率。图2所示为婴儿图像数据集的预处理示意图。其中,彩色图片的信息量过大,进行图片识别时,需要将彩色图片转换成灰度图(图2(a)),从而简化矩阵,提高训练时的运算速度。有些图片在进行灰度处理后仍旧很大,可以采用二值化方法减少图像中的数据量(图2(b)),从而凸显目标的轮廓,得到能反映图像整体和局部特征的二值化图像,并对图像进行归一化处理(图2(c))。
为了增强神经网络的收敛性,通常将读取图片转为张量并归一化处理。将数据集预处理完后,使用图像标注软件LabelImg注释,并以VOC格式保存为XML文件。
2 YOLOv5模型
2.1 算法简介
机器视觉的主要处理任务为分类、检测、分割。YOLO算法[7]擅长检测且能够兼顾精度和速度,YOLOv5算法[8]是一种更高效的目标检测模型,共有5个版本:YOLOv5n、YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x。5个版本的结构基本相似,且改进后的版本更小,速度更快,但在模型深度和模型宽度方面各有不同,其中,YOLOv5s版本的深度和特征图宽度是5个版本中最小的,其他4个版本依次在此基础上不断加深加宽。
2.2 模型训练
实验中使用的计算机硬件设备包括:Intel®CoreTM i5—8300 CPU、NVIDIA GeForce GTX 1050 GPU、8 GB 内存。操作系统为Window 11,在Pycharm上使用与Pytorch框架对应的CUDA Version搭建深度学习框架[9],设置的参数有epoch和batch size,分别为200和4。
2.3 模型网络结构
YOLOv5主要分为输入端、Backbone、Neck和Head。Backbone、Neck分别为New CSP-Darknet53、New CSP-PAN网络结构。
输入端主要参照CutMix数据增强方法,使用Mosaic数据增强方法将图片进行拼接、随机缩放、随机裁剪和随机排列,以丰富数据集,提高鲁棒性,减少训练参数,提高检测能力[10]。
Backbone采用CSP网络结构(图3),其包含3个标准卷积层,具体数量由配置文件yaml和depth_multiple参数共同决定。该模块分为两部分,一部分进行卷积操作,另一部分和上一部分卷积操作张量进行拼接(Concat),从而降低计算量,增强CNN的学习能力。
Neck采用FPN+PAN结构,与之前版本的不同之处在于使用了CSPNet设计的CSP2结构,加强了网络特征的融合能力,Neck结构如图4所示。
Head部分主要用于检测目标,目标框回归计算如下:
(1)
(2)
(3)
(4)
式中:(bx, by)表示预测框的中心坐标;bw和bh分别表示预测框的宽度和高度;(cx, cy)表示预测框中心点所在网格的左上角坐标;(tx, ty)表示预测框的中心点相对于网格左上角坐标的偏移量;(tw, th)表示预测框的宽高相对于anchor宽高的缩放比例;(pw, ph)表示先验框anchor的宽高。
3 实验结果和分析
YOLOv5训练结果如图5所示。横坐标表示训练的epoch;train/box_loss表示训练集bounding box的损失,越小则表示检测的方框越准确;val/obj_loss表示验证集目标检测的损失均值,越小则表示目标检测越准确;cls_loss表示分类loss均值,越小则表示分类越准确;precision和recall分别表示检测精度和召回率,即在训练时判断婴儿睡姿正例样本的比重和判断婴儿睡姿时正确睡姿中真正正例样本的比重;mAP_0.5和mAP_0.5:0.95分别表示阈值大于0.5的mAP平均值和在不同IoU阈值(从0.5到0.95,步长0.05)上的mAP平均值。
YOLOv5的损失主要由定位损失、置信度损失和分类损失组成。其中,定位损失表示预测框与标定框之间的误差(GIoU),总损失的计算如下:
(5)
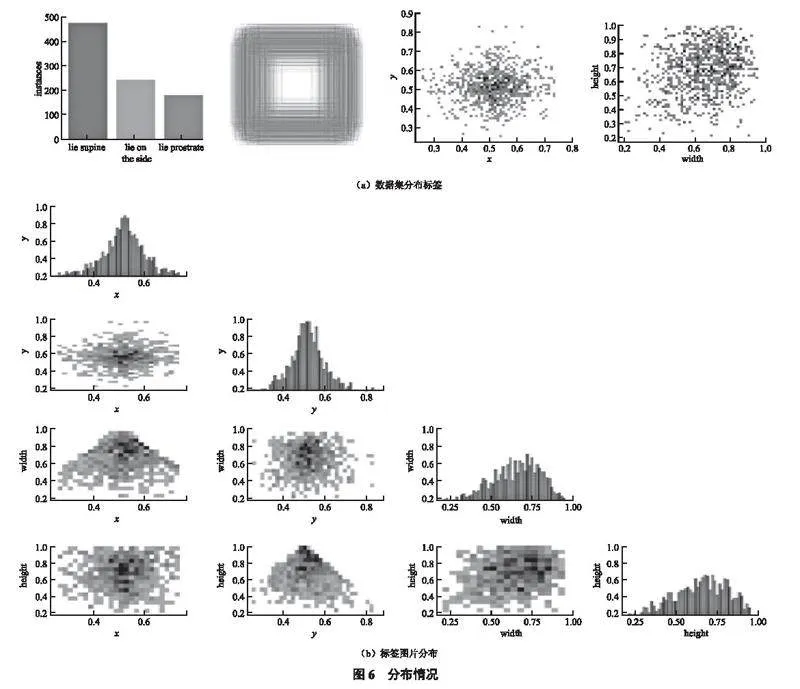
图6为数据集(图6(a))和标签图片(图6(b))的分布情况,具体分析如下:数据集分布情况的主要内容包括训练集的数据量、框的尺寸和数量、中心点相对于整幅图的位置、图中目标相对于整幅图的高宽比例。标签图片分布情况中每一行最后一张图片分别表明中心点横坐标的分布情况、中心点纵坐标的分布情况、图片框宽的分布情况和图片框高的分布情况,中心点的横纵坐标集中在整幅图的中心位置,大部分图片框的宽高超过了整幅图宽高的一半。
使用精度、召回率和均值平均精度作为模型的评估标准,来衡量算法的识别准确性。P_curve表示精度和置信度的关系,当置信度越大时,婴儿姿势识别越准确,理想值接近1。
R_curve表示召回率和置信度的关系,当置信度越小时,婴儿姿势识别检测越全面。PR_curve表示精度和召回率的关系,mAP为均值平均精度,精度越高,召回率越低,所以尽可能在精度更高的情况下检测到全部类别,曲线越接近(1, 1)模型则其精度越高。
精度Pr计算如下:
(6)
召回率Re计算如下:
(7)
平均精度AP计算如下:
(8)
采用插值法计算平均精度,均值平均精度mAP计算如下:
(9)
训练完成后,在测试集得到检测结果,Pr为99.8%,Re为99.8%,mAP为99.5%。
将婴儿训练集睡眠姿势分为3类,标签0、1、2分别对应仰卧、侧卧和俯卧,图7为训练集可视化结果。
使用训练完成的模型在测试集上进行预测,评估模型的学习能力,测试模型的性能。图8为测试集可视化结果,结果显示YOLOv5在自制的数据集中有着突出的检测识别能力,能准确判断婴儿的睡眠姿势,具有较高的可靠性。
4 结 语
本文构建了婴儿睡眠姿势数据集,搭建了婴儿睡姿检测识别YOLOv5模型,使用Mosaic数据增强方法和自适应图片增加数据集的容量,提高了模型的泛化性和鲁棒性;在卷积神经网络中引入CSP模块,大大减少了运算量;采用了3个损失函数优化模型,提高了模型的准确率,在测试集中准确率高达99%。实验结果表明,该模型可以高效准确地实现婴儿睡眠姿势的识别。
注:本文通讯作者为韩振华。
参考文献
[1]周意乔,徐昱琳.基于双向LSTM的复杂环境下实时人体姿势识别[J].仪器仪表学报,2020,41(3):192-201.
[2]祝睿,薛文华,李汶艾,等.基于Adaboost-BP神经网络模型的姿势识别研究[J].数字通信世界,2022(6):52-54.
[3]石用伍,李小勇,石用德,等.基于注意力机制的空时融合深度学习睡姿监测算法研究[J].中国医疗设备,2022,37(7):39-44.
[4]杨明健,黎镜林,郭锐坤,等.基于OpenPose的人体睡姿识别实现与研究[J].物理实验,2019,39(8):45-49.
[5]张艺超,袁贞明,孙晓燕.基于心冲击信号的睡姿识别[J].计算机工程与应用,2018,54(17):135-140.
[6] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection [C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016: 779-788.
[7] YAN P C, SUN Q S, YIN N N, et al. Detection of coal and gangue based on improved YOLOv5.1 which embedded scSE module [J]. Measurement, 2022, 188: 110530.
[8]邱天衡,王玲,王鹏,等.基于改进YOLOv5的目标检测算法研究[J].计算机工程与应用,2022,58(13):63-73.
[9]蒋文斌,刘湃,陈雨浩,等.基于CUDA流技术的深度学习系统优化[J].华中科技大学学报(自然科学版),2020,48(7):107-111.
[10]王玲敏,段军,辛立伟.引入注意力机制的YOLOv5安全帽佩戴检测方法[J].计算机工程与应用,2022,58(9):303-312.
作者简介:巢梓涵(2001—),男,研究方向为机械电子工程。
韩振华(1986—),男,博士,讲师,研究方向为机电测控系统设计、精密传动与驱动。
收稿日期:2024-01-19 修回日期:2024-03-07
基金项目:2022年江苏省大学生创新创业训练计划立项项目:基于机器视觉的婴儿异常行为检测(202211463005Z)
猜你喜欢
电子制作(2019年16期)2019-09-27 09:34:50
中国交通信息化(2019年4期)2019-07-13 05:51:34
电子制作(2018年19期)2018-11-14 02:37:04
电子制作(2018年14期)2018-08-21 01:38:16
新教育时代·教师版(2016年23期)2016-12-06 06:02:38
法制与社会(2016年32期)2016-12-01 15:25:53
软件导刊(2016年9期)2016-11-07 22:20:49
软件工程(2016年8期)2016-10-25 15:47:34
