
基于语义分割的乡村道路识别
2025-01-17 00:00:00曹新宇张太红赵昀杰姚芷馨
现代电子技术 2025年2期
关键词:图像处理
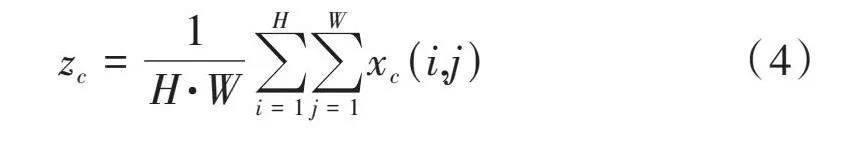






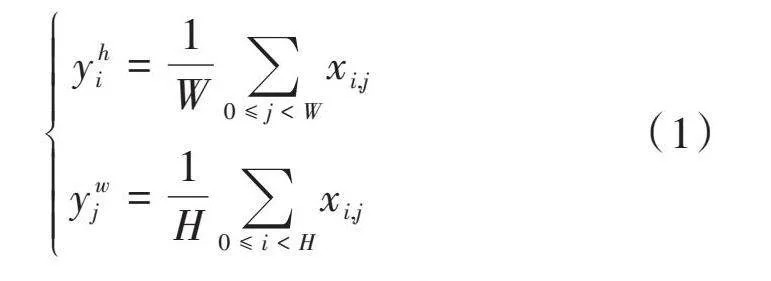


摘" 要: 针对目前智能农机在乡村复杂环境下行驶时对周围特征识别精度不足的问题,以乡村道路场景为研究对象,提出一种改进PP⁃LiteSeg模型。首先使用STDC对图像特征进行提取,在保证轻量化的同时确保特征信息完整;然后将条形池化引入简单金字塔模块,加强特征的提取能力,并将坐标注意力加入统一注意力融合模块,进一步加强多尺度特征的融合,捕获更为丰富的信息,从而提高模型对乡村复杂场景识别的准确率。实验结果表明,在不同场景下,所提模型可以达到较好的分割效果,建筑物、柏油路、障碍等单个类别的准确率均达到80%以上,能够有效地分割乡村道路场景。改进模型可为智能农机在乡村道路场景下的安全行驶提供技术参考。
关键词: 语义分割; 乡村道路; 特征识别; 条形池化; 坐标注意力; 场景分类; 图像处理
中图分类号: TN911.73⁃34; TP391.41" " " " " " " "文献标识码: A" " " " " " " " " "文章编号: 1004⁃373X(2025)02⁃0179⁃08
Rural road recognition based on semantic segmentation
CAO Xinyu1, ZHANG Taihong1, 2, 3, ZHAO Yunjie1, 2, 3, YAO Zhixin1, 2, 3
(1. College of Computer and Information Engineering, Xinjiang Agricultural University, Urumqi 830052, China;
2. Engineering Research Center of Intelligent Agriculture Ministry of Education, Urumqi 830052, China;
3. Xinjiang Agricultural Informatization Engineering Technology Research Center, Urumqi 830052, China)
Abstract: In allusion to the problem of insufficient recognition accuracy of surrounding features when intelligent agricultural machinery drives in complex rural environments, an improved PP⁃LiteSeg model is proposed based on rural road scenes as the research object. The STDC is used to extract features from the image, which can ensure the completeness of the feature information while ensuring the lightweight. The strip pooling is introduced into a simple pyramid module to enhance feature extraction capabilities. The coordinate attention is integrated into the unified attention fusion module to further enhance the fusion of multi⁃scale features and capture richer information, thereby improving the accuracy of the model in recognizing complex rural scenes. The experiments show that the model can realize better segmentation results in different scenes, and the accuracy rate of individual categories such as buildings, asphalt roads, and obstacles can reach more than 80%, which has can effectively segment the rural road scene. The improved model can provide technical references for the intelligent agricultural machine to drive safely in the rural road scene.
Keywords: semantic segmentation; rural road; feature recognition; strip pooling; coordinate attention; scene classification; image process
0" 引" 言
农村地区的交通基础设施是实现城乡一体化、促进农业发展和改善农民生活的重要组成部分。其中,乡村道路作为联系农村社区与城市的纽带,承载着农产品运输、农民出行等关键功能。提高农业生产过程的机械化、自动化、智能化水平,降低农业生产对农业劳动力的强依赖性,对于促进农业现代化建设、加速农业生产方式供给侧结构改革具有重要作用[1]。智能农机的特点是安全和自主,农业作业可以自主完成,精度较高,同时效率也非常高。该智能农机系统已在播种、施肥、除草、收获等领域广泛应用[2⁃5]。
道路的语义分割技术[6⁃7]是现实农机自动驾驶的关键。其中一个重要部分就是计算机视觉,其特点是检测范围广、特征获取丰富,是智能农机获取乡村道路信息的重要方式之一。目前,自动驾驶行驶的道路场景可分为两大类别:一类是城市主干道、高速公路等边界清晰、形状规则的结构化道路,对于这类道路,相关的分割技术已经相对成熟[8⁃9];另一类就是乡村道路、城市非主干道等,这些道路的边界模糊、形状不规则,甚至存在部分损坏,属于非结构化道路。这类非结构化道路场景的分割难度较大,其他问题也较多。因此,对乡村道路的有效分割意义重大。
在当前道路场景识别解析的研究中,文献[10]提出了一种基于颜色特征的机场道路语义分割方法,该方法采用超像素块对图像进行分割,并利用训练好的基于颜色的贝叶斯分类器对每个分割聚类进行语义类别标注,从而实现对飞机跑道上引导线的识别。另外,文献[11]通过组合颜色、纹理、深度等低层级特征,利用随机决策森林法实现了街区场景的像素级语义分割。文献[12]采用了将道路影像转换到HIS颜色空间的方法分割出道路灰度一致性区域,并结合空间梯度信息对分割结果进行细化。尽管这些方法在处理结构化道路场景时表现出色,但它们还存在一些局限性。具体而言,上述方法主要依赖于人工设计的表层特征,如颜色、纹理和形状等,缺乏对图像深层特征和高级语义信息的充分利用,导致在复杂乡村道路场景的识别中面临一系列挑战,包括道路的状态、路面上物体的干扰,所以这类方法对于复杂的乡村道路场景很难直接应用。
近年来,深度卷积神经网络在计算机视觉领域取得了显著的进展,尤其在图像分类、目标检测和语义分割等任务上展现出卓越性能[13⁃14]。深度学习的引入为解决复杂图像场景识别和解析问题提供了有效的手段[15]。文献[16]设计了轻量化非结构化道路语义分割神经网络,取得了较好的分割结果;不过其使用了分组卷积进行替换,数据信息只在组内,通道之间没有信息交互,导致分割不够精细。文献[17]设计了一种融合注意力机制与轻量化的非结构化道路识别方法,将骨干网络的特征送入并行的空洞卷积模块,再将特征输入至注意力结构,在一定程度上提高了对非结构化道路预测的准确性,但并行的空洞卷积模块会提高计算量,而且空洞卷积会产生间隙,使得部分特征信息丢失。文献[18]基于DABnet提出的融合多尺度信息的道路场景实时语义分割网络,实现了较高的分割精度。以上这些研究都是采用卷积神经网络对图像进行语义分割,然而还是存在一些不足,如参数多、计算负载大以及推理速度不理想等。与此同时,在处理图像时对于上下文信息的利用也并不充分,对于全局信息的利用也不够全面,从而影响对复杂场景的分割精度。
本文以乡村道路作为研究对象,提出一种改进PP⁃LiteSeg语义分割模型,采用STDC提取图像特征,将条形池化(Strip Pooling, SP)加入简单金字塔来加强特征的提取能力,并且将坐标注意力(Coordinate Attention, CA)加入统一注意力融合模块,进一步加强多尺度特征的融合,获得较为完整准确的特征,从而能够完成对乡村道路这类复杂场景的精细分割。
1" 网络结构
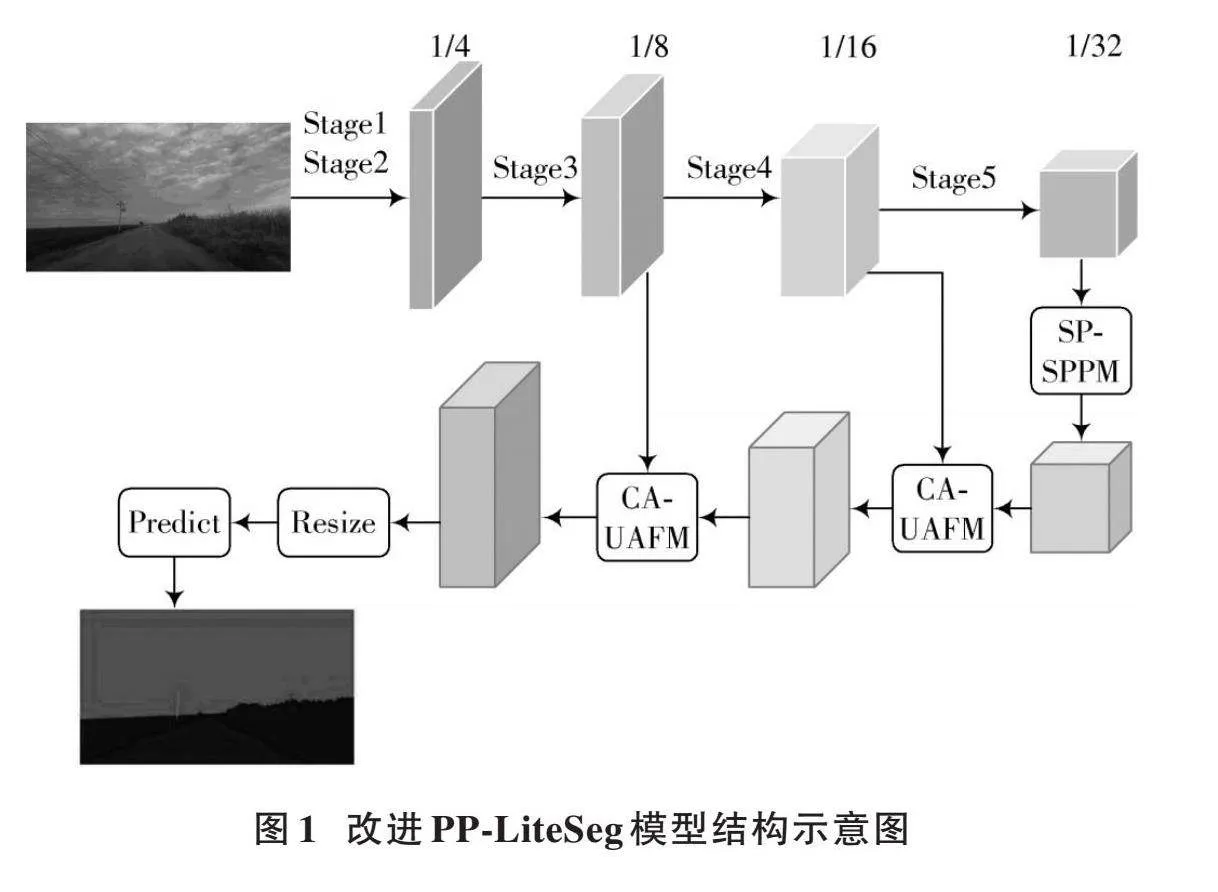
1.1" 改进乡村道路场景语义分割模型
目前,很多模型都采用编码器和解码器的结构。编码器一般包括卷积、池化和激活函数等一系列操作,能够提取特征;解码器使用上采样或反卷积操作将编码器的低分辨率特征恢复到高分辨,输出最后的预测结果。原始的PP⁃LiteSeg模型是一个典型的编码器⁃解码器结构。编码阶段使用STDC对特征进行提取,然后将特征输入至一个简单金字塔池化模块进行特征细化;解码阶段使用统一注意力融合模块将深层特征和编码阶段特征进行融合,最后通过上采样得到预测图像。本文改进模型在编码阶段将提取特征输入至一个条形池化简单金字塔模块,以获取更为有效的全局上下文信息,增强模型的性能;解码阶段将条形池化金字塔模块输出的特征,与通过带有坐标注意力的统一注意力融合模块和编码阶段的中间特征进行融合,获取更为丰富的特征,最后通过上采样得到预测结果。图1为改进PP⁃LiteSeg模型结构示意图。
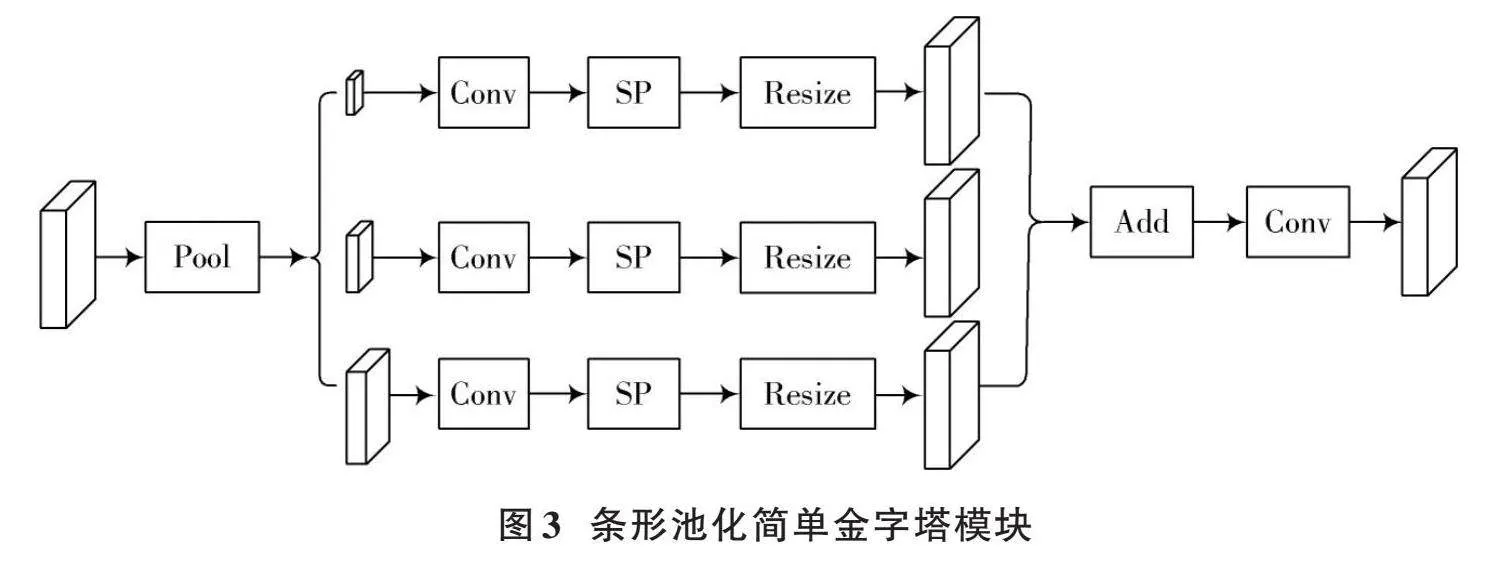
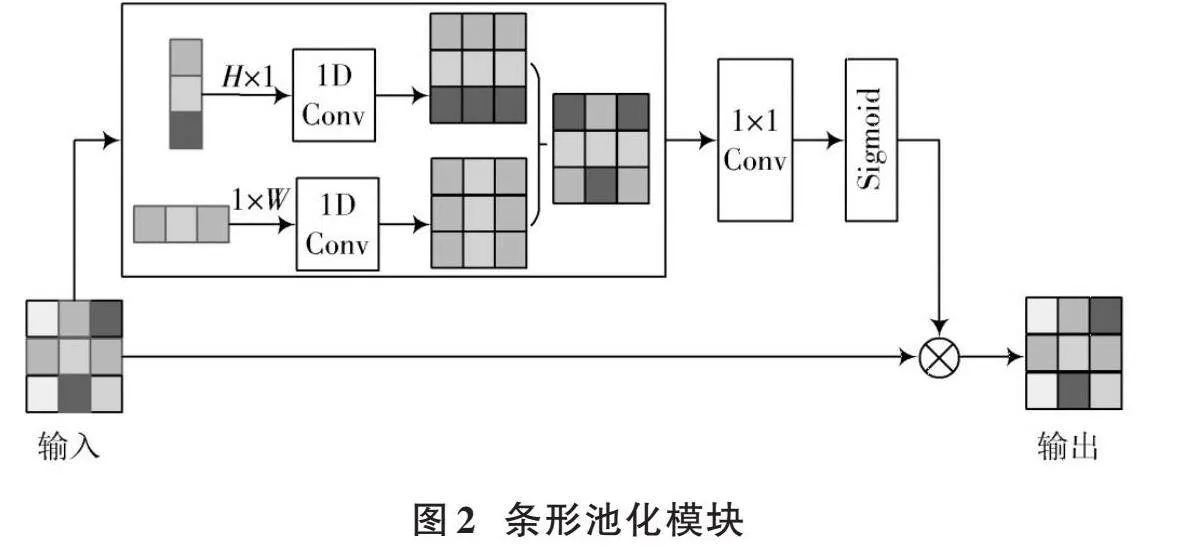
1.2" 条形池化简单金字塔模块
标准的池化操作在处理不规则形状的物体时,很多相关区域都会出现合并的现象。为了能够解决这个问题,引入条形池化这个概念,条形池化操作是针对输入的二维张量执行的一种池化操作,它可以沿水平或竖直方向移动,如图2所示。输入的二维张量为[x∈RH×W],则在进行条形池化操作时,池化窗口的大小为[H,1]或[1,W]。与二维平均池化不同的是,条形池化是对每一行或每一列中的所有特征进行平均。因此,经过条形池化后的输出张量[yh∈RH],其表达式为:
[yhi=1W0≤jlt;Wxi,jywj=1H0≤ilt;Hxi,j]" " " " " " " (1)
该条形池化模块使用水平和竖直的条形池化操作,捕获来自不同空间维度的上下文信息,从而能够很好地进行信息交互。假设输入张量为[x∈RC×H×W],其中[C]表示通道数量。首先,[x]同时输入至2条平行路径,每个路径包含一个竖直或水平的条形池化操作,然后跟随一个内核大小为3的一维卷积操作,其目的是调整当前位置及相邻位置的特征。给定[yh∈RC×H]和[yw∈RC×W],为了获得更为有效的全局特征,先将[yh]和[yw]进行组合,得到[y∈RC×H×W],其表达式为:
[yc,i,j=yhc,i+ywc,j]" " " " " " " " (2)
最后输出[z]表达式为:
[z=Scale(x,σ(f(y)))] (3)
式中:[Scale(⋅,⋅)]表示逐元素相乘;[σ]表示Sigmoid函数;[f]表示[1×1]卷积。
本文所提出的条形池化简单金字塔模块如图3所示。首先对主干网络输出的特征进行3个全局平均池化操作和1个单独条形池化操作,3个全局平均池化窗口分别为[1×1]、[2×2]和[4×4];然后将特征进行卷积,并进行条形池化操作和上采样,将得到的3个特征进行相加和[3×3]卷积操作;最后输出特征。
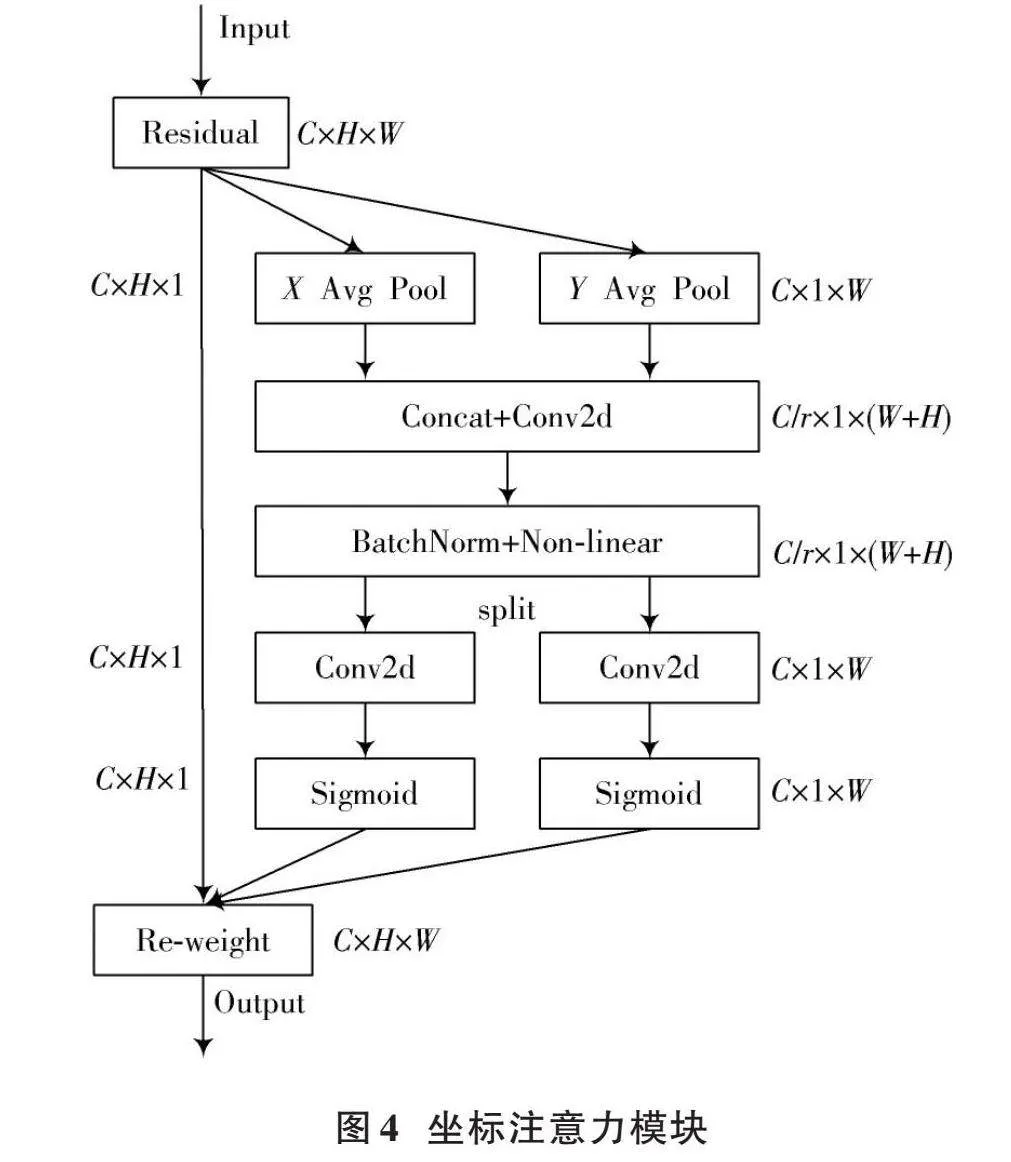
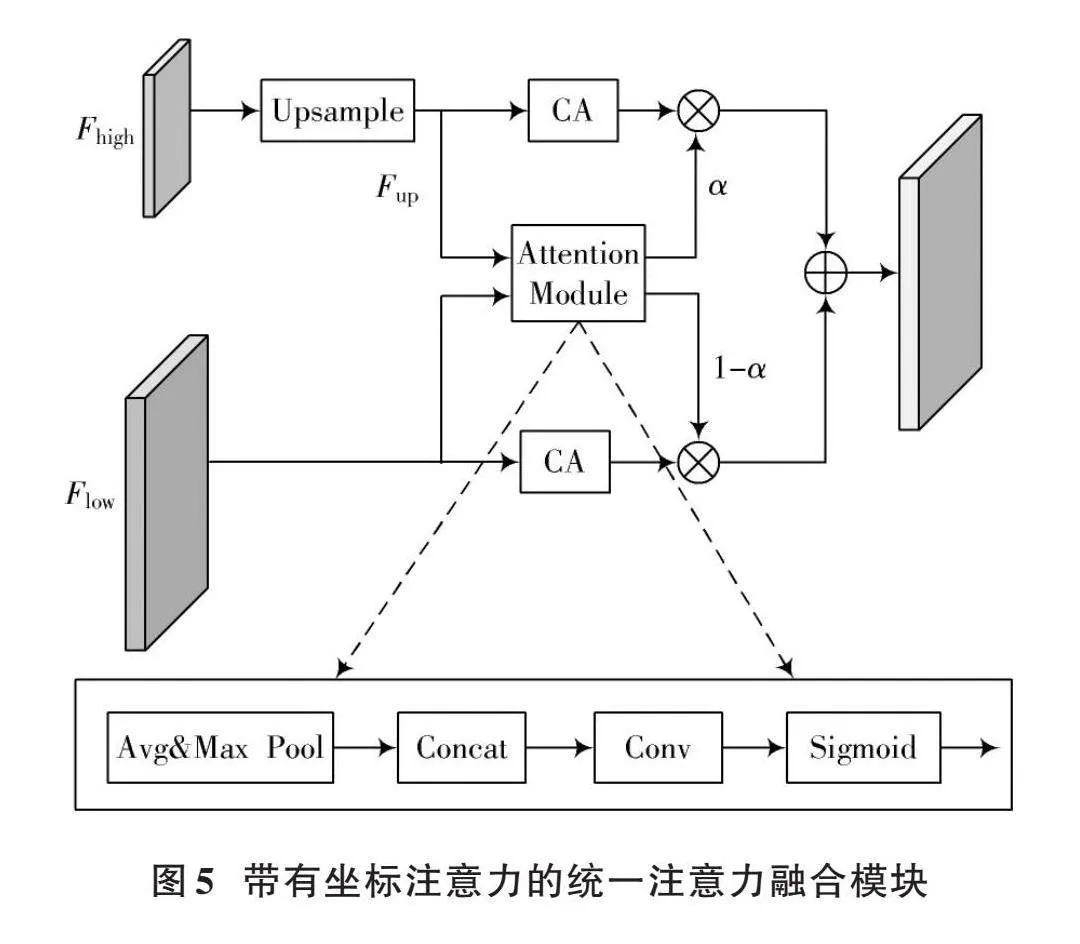
1.3" 带有坐标注意力的统一注意力融合模块
坐标注意力通过坐标信息嵌入和坐标注意力生成两个步骤对通道关系和远程依赖进行精确的位置信息编码。坐标注意力模块如图4所示。
1) 坐标信息嵌入。全局池化的作用是对全局空间信息进行编码,由于它是将全局空间信息压缩到通道的维度,所以对于位置信息的保留较为困难,但是对于视觉任务中空间结构的捕获而言,保留位置信息至关重要。为了确保注意力模块在空间上用精确的位置信息捕获远程交互的信息,本文使用式(4)对全局池化进行分解,将一维特征转换成编码操作。
[zc=1H·Wi=1Hj=1Wxc(i,j)] (4)
具体来说,给定输入[x],使用窗口为[(H,1)]或[(1,W)]的池化分别沿着横坐标和竖坐标对每个通道进行编码,其输出可表示为:
[zhc(h)=1W0≤ilt;Wxc(h,i)zwc(w)=1H0≤jlt;Hxc(j,w)] (5)
2) 坐标注意力生成。通过上述变换能够获得较好的全局感受野,并且能够编码准确的位置信息。具体而言,首先使用卷积操作对编码后的特征图降维,减少计算成本;再通过一个卷积操作降维后得到一个特征图的注意力图。这个过程实际上就是对特征图的每个位置进行处理,其中的权重就是根据位置坐标进行计算得来的。其最后的输出可表示为:
[yc(i,j)=xc(i,j)·ghc(i)·gwc(j)]" " (6)
本文所提出的带有坐标注意力的统一注意力融合模块如图5所示,图中输入特征为[Fhigh]和[Flow],[Fhigh]是深层模块的特征,[Flow]是编码器输出的特征。首先利用双线性插值操作将[Fhigh]上采样到同样大小,记为[Fup];然后,将[Fup]和[Flow]输入至注意力模块,产生权重[α];再将[Fup]和[Flow]分别输入至坐标注意力机制模块,随后将二者的输出进行逐元素相乘;最后,对两个特征进行逐元素相加,并输出融合后的特征。[Fup]、[α]、[Fout]具体的表达式如下:
[Fup=Upsample(Fhigh)α=Attention(Fup,Flow)Fout=CA(Fup)⋅α+CA(Flow)⋅(1-α)] (7)
2" 实验数据集
2.1" 乡村道路场景特点与对象分类
乡村道路的语义分割是对乡村道路图像中的对象分类出对应的标签,然后给出信息,进而实现场景理解。目前在自动驾驶中,一般可以分为两类道路:结构化道路和非结构化道路。结构化道路路面标记清晰,道路的边界也更为清晰,一般包括城市道路和高速公路。非结构化道路具有道路标志线模糊或者没有、边界很难界定、背景较为复杂等特点,一般是指非主干道和乡村道路。乡村道路呈现出以下非结构化特点:
1) 道路边界界定困难、路面环境变化大、道路形状多变;
2) 路面不够平整,会有遮挡物以及很多障碍物;
3) 当环境发生变化时,图像中的道路可能会出现不同的特征。
这些不确定的条件给乡村道路场景下的语义分割带来很多挑战,如模型需要有一定的泛化能力,也要更加鲁棒。
本文数据集根据具体的乡村道路环境进行划分,如建筑物、柏油路、非硬化路、天空、障碍、汽车、塔、电线杆、植物(树木、杂草、作物)、栅栏、水泥路、摩托车、农机、广告牌、人、卡车、交通标识。除了上述这些类别之外,还设置了背景类别。因此,乡村道路图像中的类别共有19类。
2.2" 图像采集与处理
图像采集于新疆沙湾、阜康、南山、乌鲁木齐县地区,选用设备为单目运动视频相机(GoPro HERO9),其像素为3 840×2 160,帧速为30 f/s。该相机具有支持4K视频和2 000万像素照片、超强防抖3.0视频稳定功能和摄像机内置地平线修正功能及超长续航时间等优点,保证可采集到连续清晰的图像。辅助采集设备为具有4K和30 f/s高清摄像头的智能手机。采集大量不同天气及道路环境下的乡村道路图像,保证个体种类具有多样性,以确保能更好地反映乡村道路场景的特点。为取得更宽的道路景象,本研究将图像采集设备固定到汽车车内后视镜上,以30 km/h速度匀速驾驶,共采集90 min时长视频,使用抽帧技术选取图像,共计1 490张。将原始图像尺寸缩放为1 280×720,以确保网络的训练和减小特征提取时对硬件的压力。图6为获取的乡村道路图像示例。
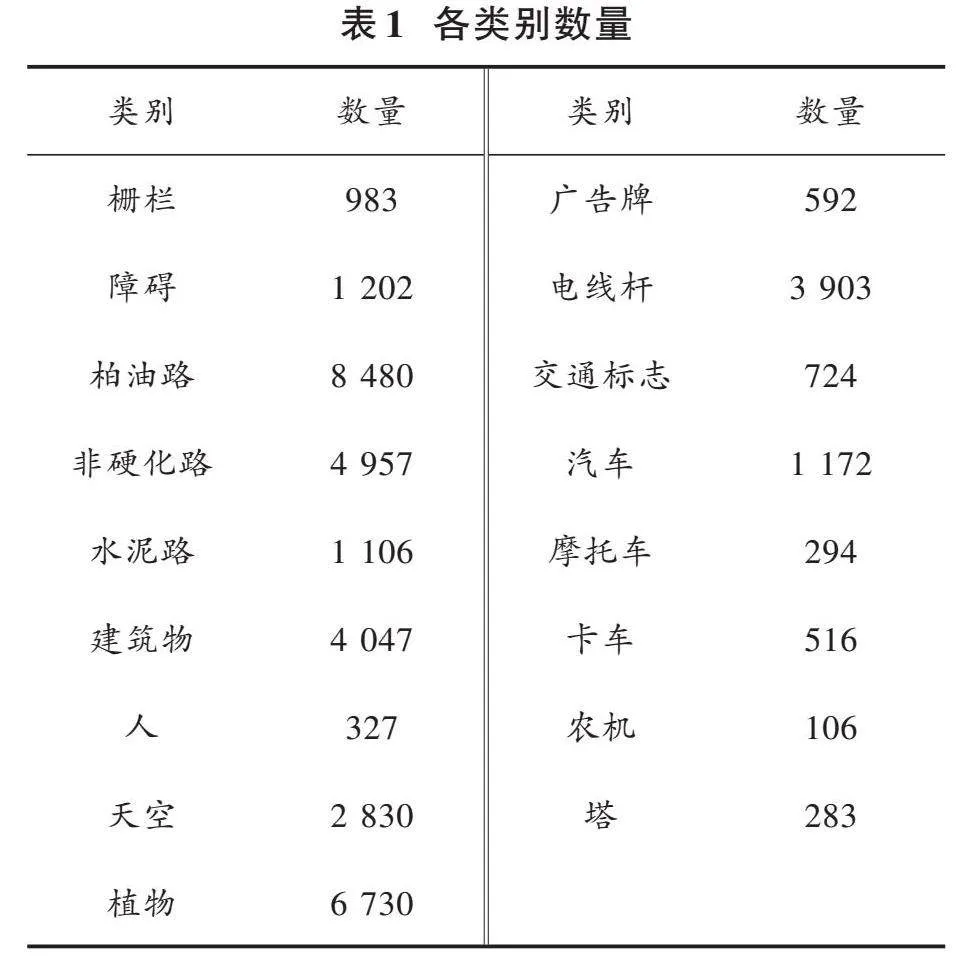
由于图像的获取场景有限,并且图像数据种类也存在不平衡的现象,因此在后续的训练过程中使用随机缩放、随机裁剪、随机水平翻转以及颜色变换等数据增强方法,对图像数据按照8∶1∶1比例进行划分。表1为各类别数量。
本文的乡村道路场景语义分割模型属于全监督学习,对图像需要进行大量人工标注,标注完成后获取训练所要的图像数据。由于采集完成后的图像是没有任何标签的,所以通过搭建CVAT平台对采集后的图像进行标注,标注完成后导出为.json格式的文件。最后使用程序将这些文件进行批量转换,输出.png格式的标签图像。
3" 实验结果与分析
3.1" 环境配置
本文所用实验设备:计算机CPU为Intel Core i7⁃10870H,16 GB显存,1 TB固态硬盘,NVIDA RTX3070Laptop显卡,8 GB显存;基于Windows 11操作系统,采用Python语言在Paddle深度学习框架下进行编程;统一计算设备架构选择CUDA11.6,深度神经网络加速库版本为CUDNNv8.4。
3.2" 模型训练及参数设置
本文模型训练采用ImageNet的预训练权重,ImageNet数据集是一个包含135万张图像、1 000个类别的图像分类数据集。在对模型进行训练时,初始学习率为0.000 5,BatchSize设置为4,最大迭代次数为40 000,优化器为随机梯度下降(SGD),动量(Momentum)为0.9,权重衰减(Weight Decay)为0.000 05,学习率衰减策略为多项式衰减(Polynomial Decay)。损失函数采用OhemCrossEntropyLoss,其表达式如下:
[Loss=-1Ni=1Nlog pi," " " " " " " yi=1log(1-pi)," "yi=00," " " " " " " " " " "其他] (8)
3.3" 客观评价指标
为了准确地评价模型对于乡村道路的分割效果,采用准确率和参数数量进行性能评价。准确率是模型的预测图像与标注图像之间的误差,假设类别总数为a,[bii]表示属于第[i]类并且预测也为第[i]类,[bij]表示属于第[i]类但是被预测为第[j]类。相关衡量标准定义如下。
1) 单类别像素准确率[Pi]是第[i]类且被预测为第[i]类的像素数与第[i]类的像素总数之间的比值。
[Pi=biij=0abij×100%] " " (9)
2) 平均交并比(MIoU)是指每个类别的预测结果与真实标签类别之间的交集与并集的比值,然后将所有类别的比值求和,并取平均值。
[MIoU=1a+1i=0abiij=0abij+j=0abij-bii] (10)
3) Dice系数表示预测区域与真实标签区域的重叠程度。
[Dice=2⋅X⋂YX+Y]" " " " " (11)
式中:[X]和[Y]分别代表预测区域和真实标签区域。
4) Kappa系数表示模型预测的结果与实际标签值是否一致。
[Kappa=po-pe1-pe] (12)
式中:[po]表示每一类正确分类的样本数量的和除以样本总数,就是总体分类精度;[pe]表示预测值与实际值的乘积再除以总体样本的平方。
3.4" 实验结果分析
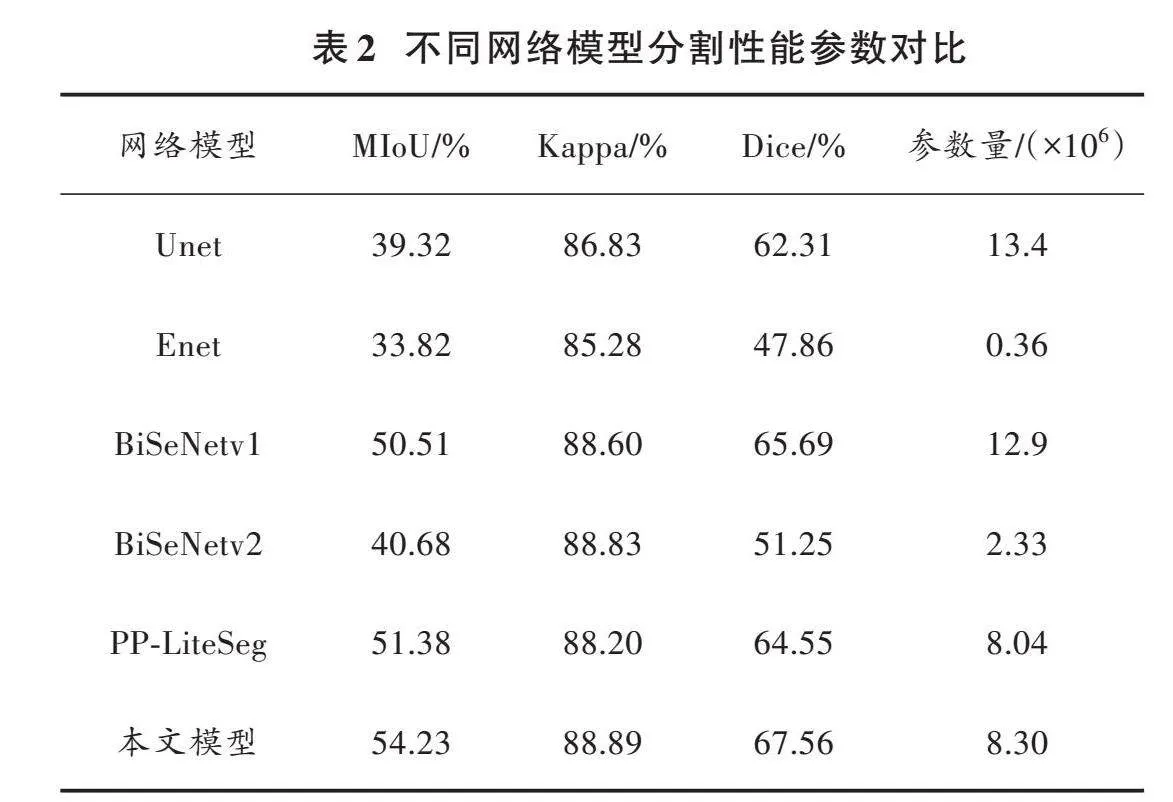
选择Unet、Enet、BiSeNet等模型与本文模型进行对比,通过MIoU、Kappa、Dice、参数量这些指标对模型性能做出评价。上述模型均采用乡村道路数据集进行训练,在测试集上计算相关指标。表2是不同网络模型分割性能参数比较。
由表2可以看出,在模型的准确率方面,本文模型的MIoU和Dice分别为54.23%和67.56%,比Unet分别高14.91%和5.25%,比Enet分别高20.41%和19.7%,比BiSeNetv1分别高3.72%和1.87%,比BiSeNetv2分别高13.55%和16.31%,比原始模型分别高2.85%和3.01%。主要原因是本文模型分别引入了条形池化简单金字塔模块和带有坐标注意力的统一注意力融合模块,能够加强模型对各阶段特征的提取,聚合不同尺度的池化特征;同时加强条形区域特征的提取以及上下文信息之间的交互,提高了模型的分割精度。在参数量方面,本文模型的参数量是8.30×106,相较于原始模型有3.1%的增加。通过对各个模型性能指标的分析可以得出,本文模型在分割任务中表现出较高的精度,并具备良好的分割性能。图7是不同网络模型语义分割结果对比。从图7可观察到,本文提出的模型能够有效地对乡村道路场景中的语义分割目标进行准确分割。相比之下,由于Unet模型多次下采样导致许多细节信息丢失,因此其在小物体分割方面表现不佳,也出现了误分割的现象,如图7第1行的非硬化路面就出现了错误分割和第4行的人没有被分割识别;此外,第2行图像中的广告牌也出现了分割混乱的现象。
Enet模型存在分割结果模糊、边界连续性差和错误分割的问题,如图7第3行图像中柏油路和非硬化路面的交界处不仅不连续而且分割模糊,并且广告牌区域也识别错误。出现上述情况的原因是Enet模型并未考虑到图像的整体信息,对图像信息的捕获能力较差。BiSeNetv1、BiSeNetv2模型由于感受野受限,对于图像的上下文信息考虑不够充分,导致对于小物体分割较为困难并且整体的分割效果也较为粗糙,如图7的第2行远处的卡车被错误分割为背景。
原始模型同样存在对小物体和边界的细节分割困难的问题,如图7第3行图像中的广告牌分割有明显错误,并且电线杆也不是连续的;第4行图像中的摩托车分割混乱;第5行图像中的电线杆、交通标志和骑摩托车的人分割都很困难。
3.5" 消融实验
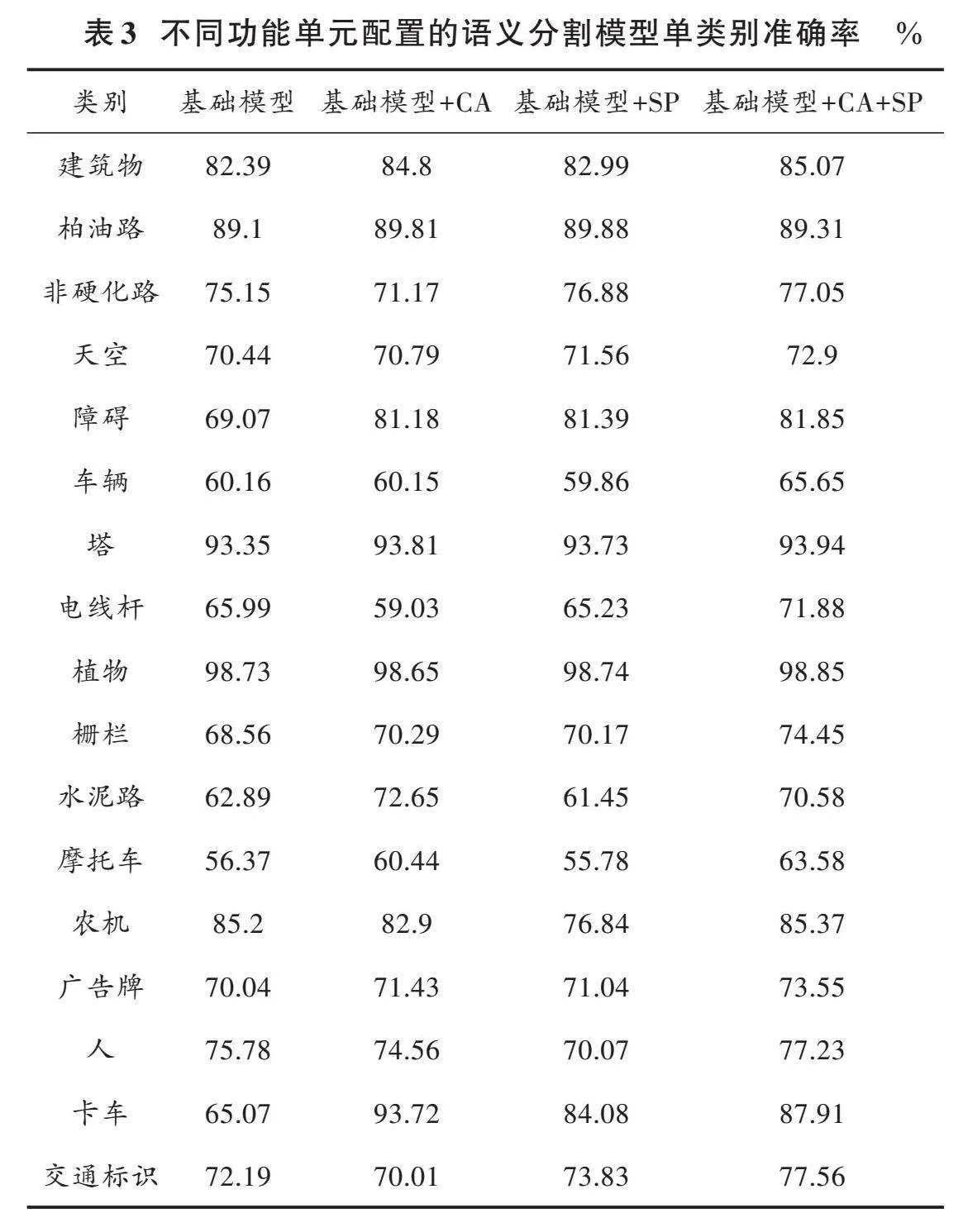
为了评估本文提出的语义分割模型的有效性,进行了消融实验以分析各个模块对模型性能的影响。在原始模型的基础上,逐步引入了带有坐标注意力的统一注意力融合模块和条形池化简单金字塔模块。通过评估单类别像素准确率、MIoU、Kappa、Dice等指标,并考虑模型的参数量,对模型进行性能分析。表3和表4是模型在测试集上的运行结果。
由表3可知:建筑物、柏油路、塔、植物、农机等对象具有较为清晰的形状、颜色、轮廓特征,识别的准确率较高;车辆、栅栏、水泥路等,这类物体都会受到距离的远近、分布情况的影响,因此相比于前几类准确率偏低;由于摩托车和电线杆在图像中的覆盖面积较小,加上图像分辨率较低,且在进行多次下采样操作后,特征图的分辨率进一步降低,从而导致许多细节信息丢失。再者,上采样恢复过程相对困难,因此在分割时可能出现不完整或误分割的情况,特别是对于这些类别,其准确率往往较低。由表4可知,在只添加CA注意力模块后,能使模型的MIoU、Kappa、Dice提升到51.84%、88.39%、64.59%,表明CA注意力模块能够在一定程度上捕获更多的空间位置信息,并提高模型的预测性能;在简单金字塔池化模块加入SP模块后,模型的MIoU、Kappa、Dice提升到53.10%、88.60%、66.39%,表明当不同区域的信息集合在一起,再进行条形区域特征的提取是有效的,对于模型效果的提升是显著的;当两个模块同时加入模型中时,模型的MIoU、Kappa、Dice提升到54.23%、88.89%、67.56%,表明这两个模块能够使模型获取到更为丰富的特征,对最后的预测也能更加的精细。随着各个功能模块的加入,模型的参数量也在逐渐提高。其中,基础模型的参数量最低,而最终加入两种模块的参数量仅增加了3.1%。不同功能单元语义分割对比图如图8所示。从图8可以看出本文改进模型有更好的分割效果。其中:基础模型在小物体分割上效果并不好,如图8第2行中的交通标志和第4行远处的人都没有被分割出来,通过添加SP模块,这类情况能得到一定程度的缓解;此外,图8第1行中的卡车和第4行中柏油路都存在错误分割的情况,通过添加CA模块能正确分割图中的场景;通过添加两种不同的模块,图8第3行中的建筑物和第4行中的行人都得到了正确的分割,整体的边界也更加连续,充分考虑到了图像的整体信息。
4" 结" 论
1) 本文改进PP⁃LiteSeg语义分割模型,其由条形池化简单金字塔模块和带有坐标注意力的统一注意力融合模块构成,加强了对图像特征的提取,能够实现较好的分割结果。
2) 构建了一个乡村道路数据集,根据环境中的对象将其划分为19种类别。通过构建乡村道路数据集并对不同环境下的图像进行测试,实验结果显示,模型的MIoU达到了54.23%,Kappa达到了88.89%,Dice达到了67.56%。此外,在建筑物、柏油路、障碍、植物等类别中,单类别准确率均达到了80%以上,表现出较高的准确性和良好的泛化能力。
3) 采用MIoU、Kappa、Dice和参数量作为性能指标,选择Unet、Enet、BiSeNetv1、BiSeNetv2和原始模型与本文模型进行对比测试。结果表明,本文模型的MIoU为54.23%,分别比Unet、Enet、BiSeNetv1、BiSeNetv2和原始模型高出14.91%、20.41%、3.72%、13.55%、2.85%;本文模型参数量为8.30×106,相较于原始模型仅增加了3.1%。
实验结果证明,本文模型有较好的分割性能,可以实现较好的分割效果。
注:本文通讯作者为张太红。
参考文献
[1] 刘成良,林洪振,李彦明,等.农业装备智能控制技术研究现状与发展趋势分析[J].农业机械学报,2020,51(1):1⁃18.
[2] CHATTHA H S, ZAMAN Q U, CHANG Y K, et al. Variable rate spreader for real⁃time spot⁃application of granular fertilizer in wild blueberry [J]. Computers and electronics in agriculture, 2014, 100: 70⁃78.
[3] 杨武,胡敏,常鑫,等.改进的DeepLabV3+指针式仪表图像分割算法[J].国外电子测量技术,2024,43(1):10⁃19.
[4] 徐晓龙,俞晓春,何晓佳,等.基于改进U⁃Net的街景图像语义分割方法[J].电子测量技术,2023,46(9):117⁃123.
[5] 孟庆宽,张漫,杨晓霞,等.基于轻量卷积结合特征信息融合的玉米幼苗与杂草识别[J].农业机械学报,2020,51(12):238⁃245.
[6] 徐国晟,张伟伟,吴训成,等.基于卷积神经网络的车道线语义分割算法[J].电子测量与仪器学报,2018,32(7):89⁃94.
[7] 曹文卓,王太固,徐兵,等.基于语义分割的船闸水位检测方法研究[J].仪器仪表学报,2023,44(2):238⁃247.
[8] DONG G, YAN Y, SHEN C, et al. Real⁃time high⁃performance semantic image segmentation of urban street scenes [J]. IEEE transactions on intelligent transportation systems, 2024(99): 1⁃17.
[9] PAZ D, ZHANG H, LI Q, et al. Probabilistic semantic mapping for urban autonomous driving applications [C]// 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Las Vegas, NV, USA: IEEE, 2020: 2059⁃2064.
[10] COOMBES M, EATON W, CHEN W H. Colour based semantic image segmentation and classification for unmanned ground operations [C]// International Conference on Unmanned Aircraft Systems (ICUAS). Arlington, VA USA: IEEE, 2016: 858⁃867.
[11] SCHARWACHTER T, FRANKE U. Low⁃level fusion of color, texture and depth for robust road scene understanding [C]// 2015 IEEE Intelligent Vehicles Symposium (IV). Seoul, South Korea: IEEE, 2015: 599⁃604.
[12] DUONG L T, NGUYEN P T, SIPIO C D, et al. Automated fruit recognition using EfficientNet and MixNet [J].Computers and electronics in agriculture, 2020, 171: 105326.
[13] CONNOR J T, MARTIN R D, ATLAS L E. Recurrent neural networks and robust time series prediction [J]. Neural networks, 1994, 5(2): 240⁃254.
[14] JIANG H, ZHANG C, QIAO Y, et al. CNN feature based graph convolutional network for weed and crop recognition in smart farming [J]. Computers and electronics in agriculture, 2020, 174: 105450.
[15] ADRINARAYANAN V, KENDALL A, CIPOLLA R. SegNet: a deep convolutional encoder⁃decoder architecture for image segmentation [J]. IEEE transactions on pattern analysis and machine intelligence, 2017, 39(12): 2481⁃2495.
[16] 金汝宁,赵波,李洪平.一种轻量化非结构化道路语义分割神经网络[J].四川大学学报(自然科学版),2023,60(1):66⁃73.
[17] 龚志力,谷玉海,朱腾腾,等.融合注意力机制与轻量化DeepLabv3+的非结构化道路识别[J].微电子学与计算机,2022,39(2):26⁃33.
[18] 王俊,蒋自强,别雄波.融合多尺度信息的道路场景实时语义分割[J].激光杂志,2023,44(6):137⁃142.
猜你喜欢
网络安全与数据管理(2022年2期)2022-05-23 13:25:30
电子制作(2019年15期)2019-08-27 01:12:12
制造技术与机床(2018年12期)2018-12-23 02:40:52
电子制作(2018年18期)2018-11-14 01:48:20
电子测试(2018年6期)2018-05-09 07:32:01
电子测试(2017年11期)2017-12-15 08:57:08
中国公共安全(2017年8期)2017-10-13 08:12:21
中国公共安全(2017年8期)2017-10-13 08:12:20
辽宁省博物馆馆刊(2016年0期)2016-05-17 10:00:56
电气化铁道(2016年4期)2016-04-16 05:59:46
