
基于并联残差膨胀卷积网络的短文本实体关系联合抽取
2025-01-17 00:00:00曾伟奚雪峰崔志明
现代电子技术 2025年2期
关键词:语义特征


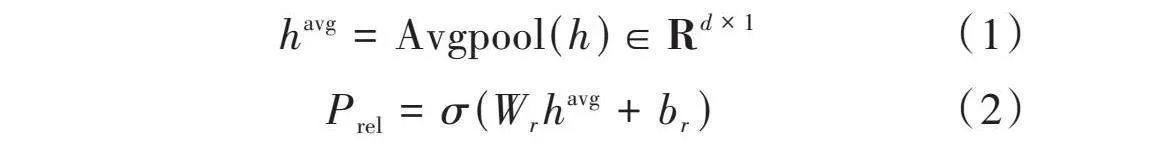



摘" 要: 关系抽取旨在从文本中提取出实体对之间存在的语义关系,但现有的关系抽取方法均存在关系冗余和重叠的不足,尤其是对于短文本,会因上下文信息不足而出现语义信息不足和噪声大等问题。此外,一般流水线式的关系抽取模型还存在误差传递问题。为此,文中提出一种基于并联残差膨胀卷积网络的短文本实体关系联合抽取方法。该方法利用BERT生成语义特征信息,采用并联残差膨胀卷积网络来捕获语义信息,从而提升上下文信息的捕获能力并缓解噪声。联合抽取框架通过抽取潜在关系来过滤无关关系,然后再抽取实体以预测三元组,从而解决关系冗余和重叠问题,并提高计算效率。实验结果表明,与现有的主流模型相比,所提模型在三个公共数据集NYT、WebNLG和DuIE上的F1值分别为90.9%、91.3%和73.5%,相较于基线模型均有提升,验证了该模型的有效性。
关键词: 实体关系抽取; 短文本; 残差膨胀卷积网络; 语义特征; 联合抽取; BERT编码器
中图分类号: TN919⁃34; TP391.1" " " " " " " " "文献标识码: A" " " " " " " " " " " 文章编号: 1004⁃373X(2025)02⁃0169⁃10
Short text entity relation joint extraction based on parallel residual expansion convolutional network
ZENG Wei1, 2, XI Xuefeng1, 2, 3, CUI Zhiming1, 2, 3
(1. Suzhou University of Science and Technology, Suzhou 215000, China;
2. Suzhou Key Laboratory of Virtual Reality Intelligent Interaction and Application Technology, Suzhou 215000, China;
3. Suzhou Smart City Research Institute, Suzhou 215000, China)
Abstract: Relationship extraction aims to extract semantic relationships between entity pairs from text, but existing relationship extraction methods suffer from the shortcomings of relationship redundancy and overlap, especially for short texts, which may result in insufficient semantic information and loud noise due to insufficient contextual information. Moreover, conventional pipeline based relation extraction models face error propagation issues. A method of short text entity relation joint extraction based on parallel residual expansion convolutional network is proposed. In this method, BERT (bidirectional encoder representations from transformers) is used to generate semantic feature information, and the parallel residual dilated convolutional network is employed to capture semantic information, thereby enhancing the ability to capture context information and alleviate noise. The joint extraction framework can be used to filter out irrelevant relationships by extracting potential relationships, and extract entities to predict triplets, thus solving the problems of relationship redundancy and overlap, and improving computational efficiency. The experimental results demonstrate that, in comparison with existing mainstream models, the F1 values of the proposed model on the three public datasets NYT, WebNLG and DuIE are 90.9%, 91.3% and 73.5%, respectively, which are improved compared with the baseline model, which verifies the effectiveness of the model.
Keywords: entity relationship extraction; short text; residual expansion convolutional network; semantic features; joint extraction; BERT encoder
0" 引" 言
关系抽取(Relation Extraction)是自然语言处理领域的重要任务,其目标是从文本中自动识别和提取出实体之间的语义关系,并使用三元组(头实体,关系,尾实体)来表示实体之间的关系。目前,关系抽取主要面临着实体关系重叠问题。SEO表示多个实体与同一实体存在关系,例如“Zhang and Li live in China”对应三元组包括(Zhang, live in, China)和(Li, Live in, China);EPO表示同一对实体存在多种关系,例如“Beijing is the capital of China”对应三元组包括(Beijing, capital, China)和(Beijing, location, China);SOO表示主体和客体重叠,例如“Lebron James is a good basketball player”对应三元组包括(Lebron James, first name, Leborn)。
随着社交媒体的普及和互联网信息的爆炸性增长,短文本在网络上得到了广泛的应用,如社交媒体评论、微博消息、短信等。短文本具有信息密度高、表达形式简洁的特点,但同时也存在着语言不规范性和上下文信息不完整的挑战。因此,如何从中文短文本里快速准确地提取出重要的关系特征成为短文本关系抽取任务的关键。
本文针对以上短文本存在的关系重叠和上下文信息不丰富的问题,提出了一种基于并联残差膨胀卷积网络的短文本关系抽取模型PRDC(Parallel Residual Dilated Convolution)。该模型采用实体关系联合抽取框架,以缓解误差传递和实体关系重叠问题。同时,模型使用BERT预训练模型作为嵌入层来生成文本表示,并利用残差膨胀卷积网络来提取特征信息。本文方法主要的创新点在于:构建的并联残差膨胀卷积模块能有效捕获上下文信息,融合了残差网络和膨胀卷积的优势,缓解深层网络带来的梯度消失或爆炸问题。实验结果表明,相较于其他模型,本文提出的模型表现出了较好的效果。代码地址:https://github.com/hubufeng/joint⁃entity⁃and⁃relation⁃extraction。
1" 相关工作
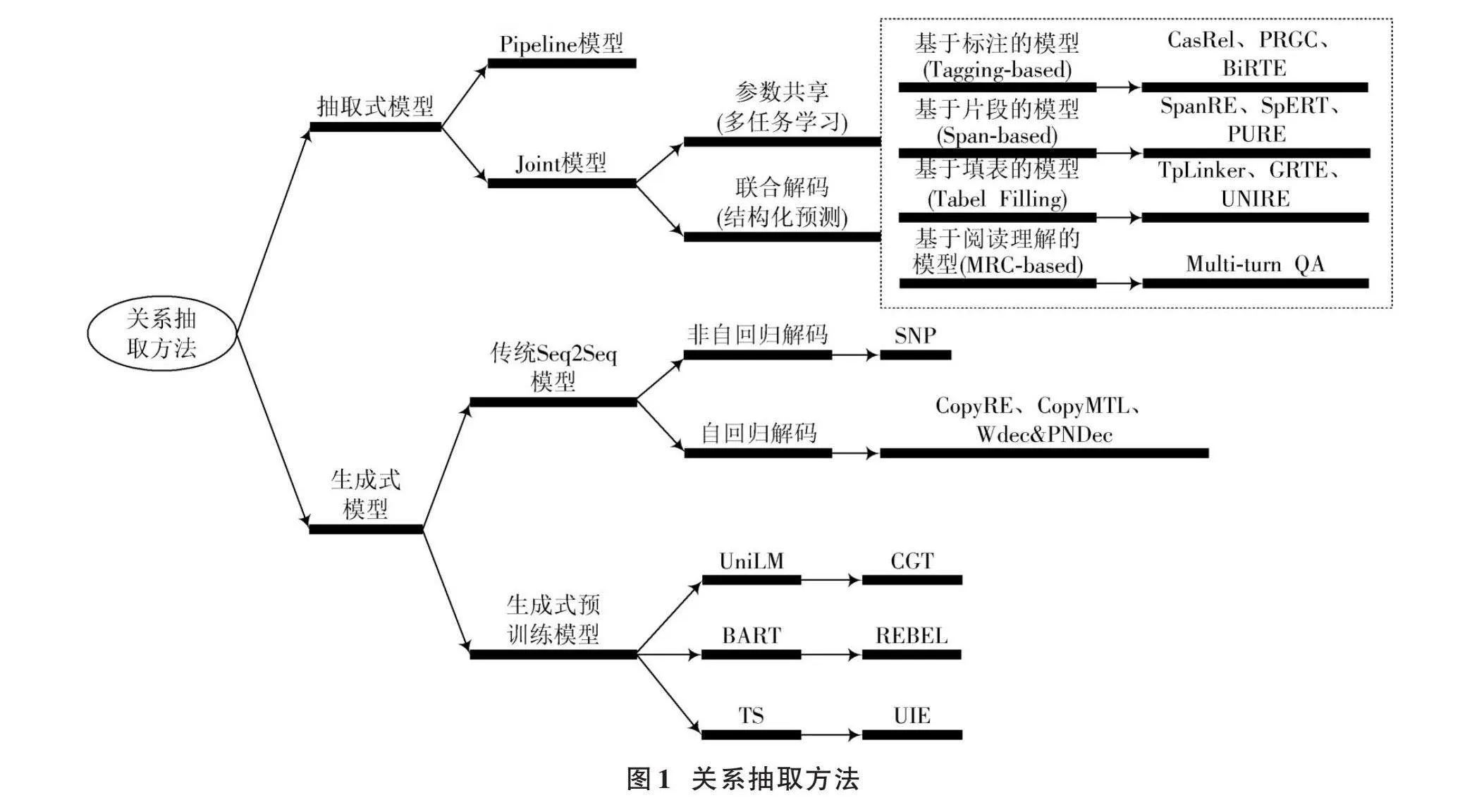
关系抽取模型按照结构可分为流水线模式(Pipeline)和联合抽取(Joint)两种。流水线模式先抽取实体,后抽取关系。然而,这种模型存在明显的误差传递问题,因为实体抽取和关系分类任务相互独立,无法相互纠正错误,导致实体抽取阶段的误差直接影响关系分类效果。
联合模型为了减少误差传递和整合实体识别与关系抽取任务,主要分为两类:参数共享和联合解码。参数共享实质上是多任务学习,两个任务共享Encoder,但使用不同的Decoder,并构建联合loss来进行训练优化。然而,这种方式仍然未能解决误差传递问题,同时还存在暴露偏差的问题。许多学者研究提出了联合解码模型,特别是以TPLinker为代表的Table Filling系列方法。但PURE[1]模型证明了联合模型不一定比Pipeline模型更好,实际效果取决于具体任务和数据。各类方法汇总如图1所示。
基于标注的方法通常使用二分标注序列来确定实体的起止位置或确定实体之间的关系,例如,CasRel[2]先抽取subject实体,然后在此基础上同时抽取关系和对应的object实体。尽管这种方法能够解决重叠问题,但仍属于Pipeline模式,存在误差传递和暴露偏差的问题。同时,因为需要计算subject每个关系下可能对应的object,导致计算量过大,存在关系冗余问题。PRGC[3]针对关系冗余问题,将联合抽取分成三个子任务,并通过过滤无关关系来提升计算效率。BiRTE[4]则改进了CasRel,使用双向提取框架,并通过互补减少实体抽取遗漏。
基于片段的方法SpanRE[5]分为4个阶段。首先,该方法列举了所有可能的片段[start(i), end(i)],即从i个tokens中任选2个作为片段的起止;其次,对这些片段进行编码,生成span向量表示;然后,预测每个片段是否为实体;最后,对提取的所有Span实体进行两两配对,预测它们之间的关系。SpERT[6]对SpanRE进行了改进,采用了BERT编码文本,并学习了width embeddings来表示Span的长度。在实体分类阶段,该方法会过滤掉none标签的Span,并限制Span的长度。PURE模型虽然在输入层引入了Typed Makers以整合实体位置和类型信息,但仍然存在Pipeline模型的通病,且对每个实体对进行关系预测时会存在很多噪声。此外,Span方法需要对每个实体对进行判断和预测,这可能会引入很多噪声。与此不同,CasRel模型先寻找subject,然后再匹配object,从而过滤掉很多噪声。
基于填表的方法通常为每个关系维护一个表,表中每项表示实体对是否具有此类关系。TPLinker[7]提出了握手标记方案来记录实体对tokens的边界,从而解决了关系重叠和误差传递问题。然而,该方法标注的复杂度较高,解码效率也不够高。GRTE[8]认为TPLinker填充关系表时仅依赖于局部特征,忽略了全局信息,因此提出了更高效的填表策略。UNIRE[9]将实体和关系两个任务标签整合到统一联合标签空间,并设计了简单快速的解码方法来增强实体和关系的交互。OneRel[10]则类似于TPLinker,减少了关系矩阵数量以减少冗余信息,并增强了实体和关系的交互。
基于阅读理解的方法[11]将实体关系抽取看成多轮问答问题,从文本中识别答案片段,通过分阶段抽取头实体、关系和尾实体来实现。此外,还有基于图卷积[12]和端到端[13]的实体关系联合抽取模型。文献[14]忽略三元组序列而直接输出最终的三元组集合,关注关系类型和实体,为网络提供了更准确的训练信号。另外,还有基于语言模型增强[15]的中文关系抽取方法来进行轻量化学习。注意力机制[16⁃18]在关系抽取任务中也逐渐得到应用,用于捕捉句级和空间依赖关系。最后,远程监督方法利用外部知识丰富实体和关系信息,但同时会引入大量噪声,并需要手工设计特征,而文献[19⁃22]缓解了远程监督方法带来的问题。文献[23]提出基于跨度的方法,将联合抽取定义为一个条件序列生成问题,采用具有指向机制的编码⁃解码结构。文献[24]引入BART模型。文献[25]首次提出将多模态实体识别和多模态关系抽取联合执行,并用边缘增强图对齐网络来辅助对象和实体间的对齐。上述方法各有优缺点,需根据具体任务和数据选择合适的模型。
2" 模型设计
为了更好地从非结构化文本中表征信息并抽取关系信息,本文提出基于并联残差膨胀卷积网络模型PRDC,结构如图2所示,由BERT编码器、PRDC模块和关系抽取层三个主要组件构成。在关系抽取层中,包含潜在关系预测模块、特定关系序列标注模块和全局对应模块三个关键部分。
模型首先通过BERT编码文本信息,有助于缓解短文本可能带来的一词多义问题;然后,利用PRDC提取文本特征并进行降噪;接着,将提取的特征信息与BERT编码的信息进行结合,以丰富语义信息,从而缓解短文本语义不够丰富的问题;最后,实体关系联合抽取缓解关系重叠和误差传递问题,通过潜在关系预测得到潜在关系,以此过滤掉无关关系。特定关系序列标注模块结合句子表示和得到的关系表示来标注头尾实体,以识别实体信息。关系和实体的组合形成了三元组,但其中的一些组合是不合理的。因此,全局对应模块使用矩阵表示来判断字对之间是否存在关联,从而进一步过滤不合理的三元组。
2.1" BERT编码器
自然语言文本无法直接被神经网络编码,因此需要将其转换为向量形式,通常使用BERT预训练模型生成文本表示。BERT编码层负责将输入序列中的每个词汇转换成其对应的向量表示,在这个过程中,每个词汇的向量表示会受到序列中其他词汇的影响,故使用多头自注意力(Multi⁃head Self⁃Attention)机制来捕捉词汇之间的语义关联。BERT的编码层扮演着将文本序列映射到向量空间的角色,使得模型能够理解文本中的语义信息,并且为下游任务提供良好的表示。
2.2" PRDC模块
PRDC模块的核心结构是残差块(Residual Block)和膨胀块(Dilated Block)。典型的ResNet由多个残差块组成,每个残差块内部可以包含若干卷积层、批量归一化层和激活函数层。整个网络以及残差块的设计主要遵循“跳跃连接”的思想,即将输入信号绕过一个或多个层,直接传递给后续的层,从而解决梯度消失问题。膨胀块通过在卷积核之间插入间隔来增加卷积核的有效大小,从而扩大感受野。这意味着膨胀卷积可以捕捉更广大范围内的上下文信息,有助于提高特征提取的能力。
由于短文本句子长度不同,且涉及关系抽取的重要信息可能分布在任何位置,因此需要从句子中抽取不同的局部特征。卷积操作能够捕获局部特征,使用滑动窗口与句子向量进行卷积运算。由于需要抽取句子的多个局部特征,因此需要设计不同的过滤器来完成特征抽取,通过并联各卷积网络特征来丰富句子特征信息。此外,残差网络除了能解决梯度消失问题,还能提高网络收敛速度和模型泛化能力。
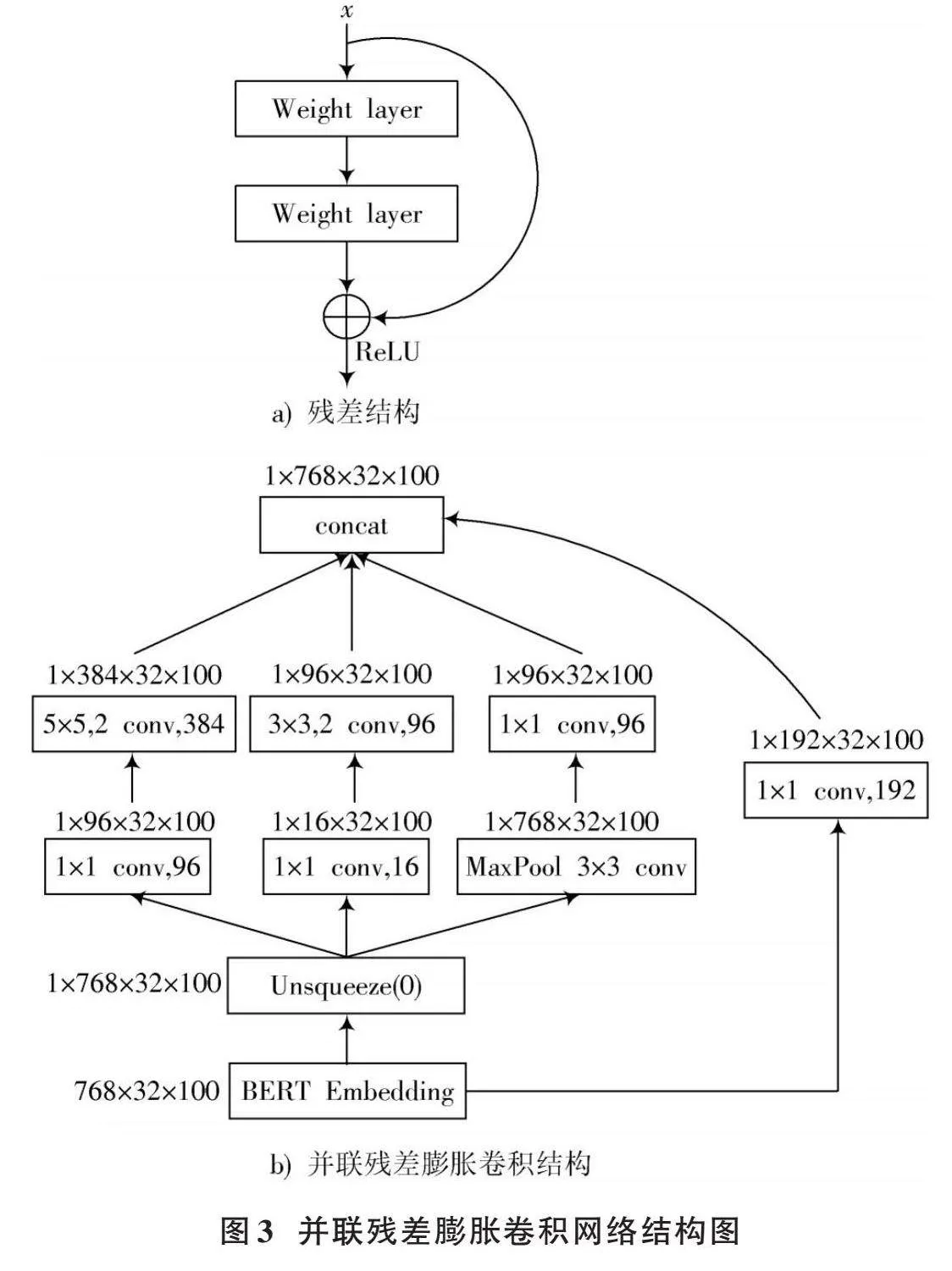
本文设计的并联残差膨胀卷积网络的基本结构如图3所示。示例中BERT输出假设为(786,32,100),其中第一维表示embedding大小,第二维表示批处理大小,第三维表示句子长度,经过维度扩展后进入卷积网络。本文使用二维卷积作为基本单元,词向量维度作为通道数,批处理大小和句子长度作为卷积操作的二维矩阵,用于挖掘句子内部与句子之间的信息。不同大小的卷积核的卷积允许并行学习多尺度特征,其中卷积核大小为5和3的卷积为膨胀卷积,经过并联的卷积层后,在第二维度上进行拼接得到最终输出。
卷积网络中使用逐点卷积(Pointwise Conv, PW),用卷积核大小为1的卷积进行压缩降维,减少参数量,从而让网络更深、更宽、更好地提取特征。此外图3b)中的(1×1 conv,192)卷积可看作是卷积的残差连接。
2.3" 关系抽取层
2.3.1" 潜在关系预测
进行潜在的关系预测可避免冗余关系预测,假设经过句子表示和PRDC特征提取后的输出为[h∈Rn×d],进行平均池化操作和潜在关系预测过程的公式如下:
[havg=Avgpool(h)∈Rd×1] (1)
[Prel=σ(Wrhavg+br)] (2)
式中:[Wr∈Rd×1]为可训练权重;[σ]为sigmoid激活函数。将潜在关系预测建模为一个多标签二进制分类任务,如果概率超过某个阈值[λ1],则为对应关系分配标签1,否则将对应的关系标签置为0。接下来只需要将特定关系的序列标签应用于预测关系,而不用预测全部关系。
2.3.2" 特定关系序列标注
通过潜在关系获得了描述潜在关系的几个特定关系的句子表示,然后模型执行两个序列标注操作来分别提取主体和客体。为解决实体重叠问题,采用两个BIO序列标注方式进行实体抽取,然后对构成的三元组进行评估,筛选出最终的三元组。过程对应公式如下:
[Psubi,j=softmax(Wsub(hi+uj)+bsub)] (3)
[Pobji,j=softmax(Wobj(hi+uj)+bobj)] (4)
式中:[uj∈Rd×1]是[U∈Rd×r]关系集合矩阵中第[j]个关系表示,[r]表示全部关系数量;[hi∈Rd×1]是处理后的第[i]个token的输出;[Wsub,Wobj∈Rd×3]是可训练权重。标注集合{B,I,O}大小为3。
2.3.3" 全局对应
将标注得到的实体与预测的关系构成三元组,此时的三元组中包含subject和object构成的所有可能的组合,需要进一步筛选去除无用三元组。利用全局对应模块过滤三元组,该模块可与潜在关系模块同时学习,且会生成全局矩阵,矩阵中每个元素表示对应的token pair是否存在关联,使用阈值[λ2]进行过滤,存在关联则用1表示,无关则用0表示。矩阵中元素获取方式如下:
[Pi,j=σ(Wg(hsubi;hobjj)+bg)] (5)
式中:[hsubi,hobjj∈Rd×1]表示句子第[i]个token和第[j]个token对应的实体与预测的向量表示,作为头尾实体对;[Wg∈Rd×1]是可训练权重。
整体的损失由关系预测、特定关系序列标注、全局对应三个模块组成。各部分损失计算公式如下:
[Lrel=-1nri=1nryilogPrel+(1-yi)log(1-Prel)] (6)
[Lseq=-12×n×npotrt={sub,obj}j=1npotri=1nyti,jlogPti,j] (7)
[Lglobal=-1n2i=1nj=1nyi,jlogPi,j+(1-yi,j)log(1-Pi,j)] (8)
式中:[nr]是所有关系集合大小;[npotr]是预测的潜在关系集合大小;[n]是句子长度。模型总的联合损失是式(6)~式(8)损失的总和,表示为:
[L=Lrel+Lseq+Lglobal] (9)
3" 实" 验
3.1" 数据集和评估指标
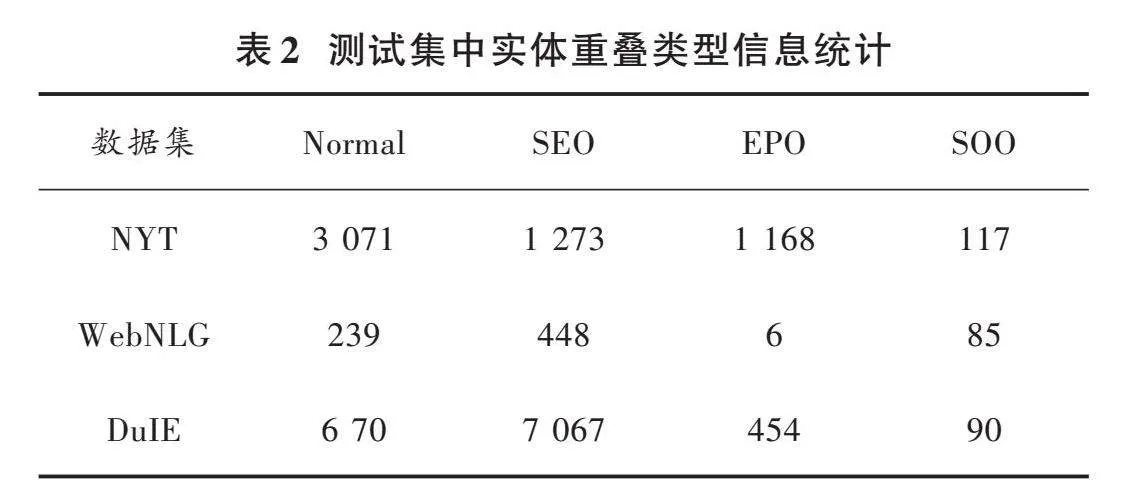
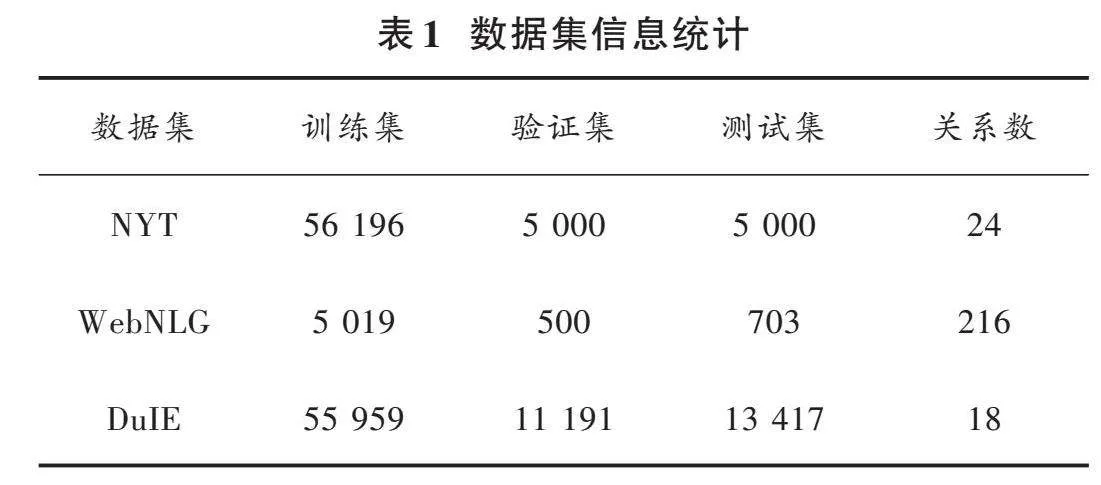
本文使用了三个公共数据集,包括WebNLG、NYT和DuIE数据集。其中,WebNLG和NYT属于常规数据集,而DuIE则属于短文本数据集。通过在这两类数据集上的实验,验证模型的有效性和泛化能力。WebNLG数据集来源于DBpedia,而NYT数据集则来自纽约时报。DuIE数据集由百度提供,是一个用于中文短文本关系抽取任务的数据集,旨在推动自然语言处理领域中相关研究的进展,解决传统方法在处理短文本关系抽取任务时所面临的挑战,包括语义表达受限、噪声和歧义等问题。该数据集包含了一系列中文短文本对,每个文本对都包含两个实体以及它们之间的关系,这些关系可以是各种各样的,例如人物关系、实体属性等,共涵盖了18种实体关系类别。数据集的详细划分情况如表1所示,测试集中实体关系重叠情况和三元组数目的统计如表2、表3所示。
本文采用准确率P、召回率R和F1值作为评价指标,计算公式如下所示:
[P=TPTP+FP×100%] (10)
[R=TPTP+FN×100%] (11)
[F1=2×P×RP+R×100%] (12)
3.2" 实验设置
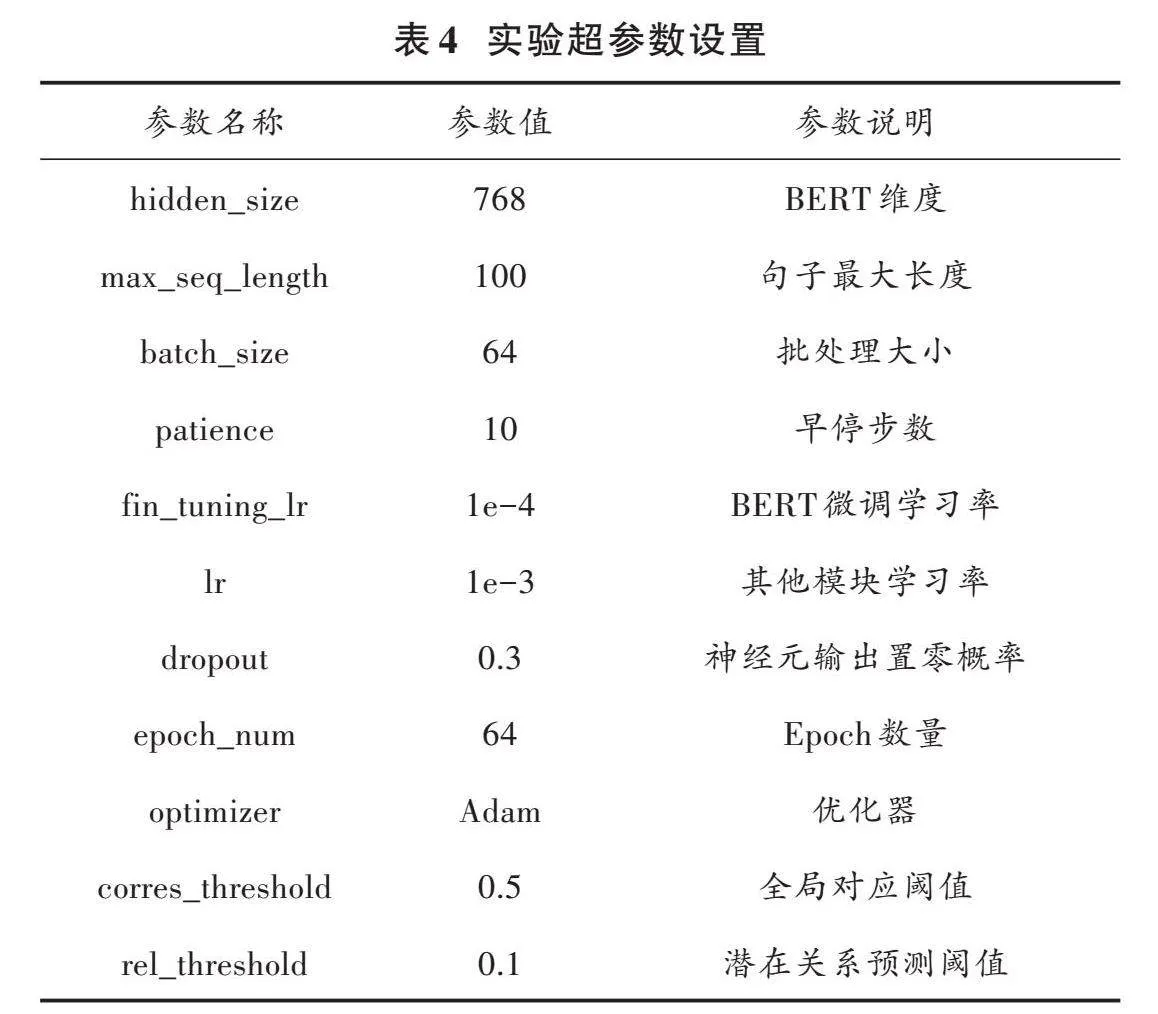
运行环境Python版本为3.8.18,PyTorch版本为2.1.2,Transformer版本为4.36.2,Tpdm版本为4.66.1。模型训练时,采用Dropout和早停策略来防止模型过拟合。各参数设置详情如表4所示。
3.3" 对比实验
为了验证基于残差网络和注意力的实体关系联合抽取模型的效果,将其与以下基线模型进行实验对比。
GraphRel[26]:先使用图卷积网络建立关系图,再整合关系图上的实体。
OrderCopyRE[27]:考虑三元组提取顺序,引入强化学习。
ETL⁃Span[28]:先识别头实体,再识别实体和关系,使用span标注方法。
CasRel[2]:先抽取主实体,再同时抽取关系和对应客体,使用二元级联标注。
DualDec[29]:改进CasRel模型,使用双解码器解决实体关系重叠问题。
PRGC[3]:先抽取关系再识别实体,最后使用全局对应模块过滤三元组。
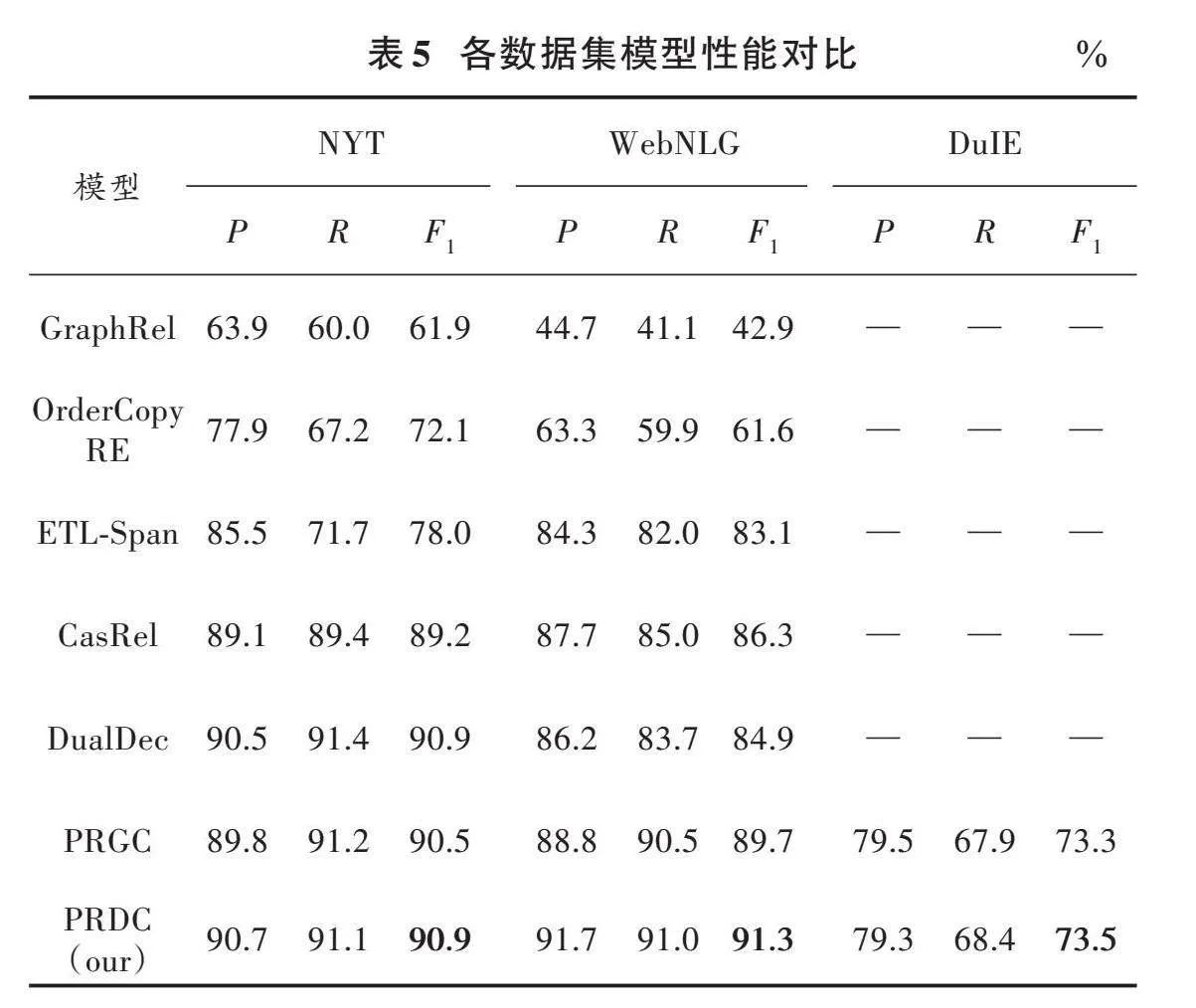
根据表5的性能数据分析,本文所提出的方法在三个数据集上相较于其他基线模型表现出更优异的效果。在NYT和WebNLG数据集中,OrderCopyRE模型的F1值比GraphRel模型分别高出10.2%和18.7%,这表明考虑三元组提取顺序对抽取效果有显著提升。ETL⁃Span和CasRel模型采用了分步抽取信息的策略,相较于简单考虑三元组顺序的方法,其性能提升较为显著。然而需要注意的是,两者的标注方式存在差异,采用二元级联标注方式的效果比Span标注方式更为优越,F1值分别高出11.2%和3.2%。
在NYT数据集中,DualDec模型通过使用双解码器解决了重叠问题,性能进一步提升1.7%;然而在WebNLG数据集上,其效果略微下降1.4%。PRGC模型通过过滤冗余关系,在解决重叠问题的同时降低了模型复杂度,进而提高了其性能。最后,本文所提出的模型在数据集NYT和WebNLG上的F1值分别为90.9%和91.3%,相较于PRGC模型分别提高了0.4%和1.6%,相较于经典模型CasRel分别提高了1.7%和5.0%。相较于DualDec模型,本文模型的F1值在NYT数据集上不变,在WebNLG数据集上提升6.4%,总的来说还是有所提升,在泛化能力上优于DualDec模型。本文方法在短文本数据集DuIE上F1值为73.5%,与PRGC模型相比高出0.2%。通过对比实验结果可以看出,本文所提出的模型在关系抽取能力和泛化能力上均优于基线模型,有效提升了关系抽取的性能。
3.4" 消融实验
3.4.1" 模型对关系重叠的影响
为了验证模型在处理重叠问题和提取多重关系方面的能力,在三个数据集上将其与基线模型进行了对比。
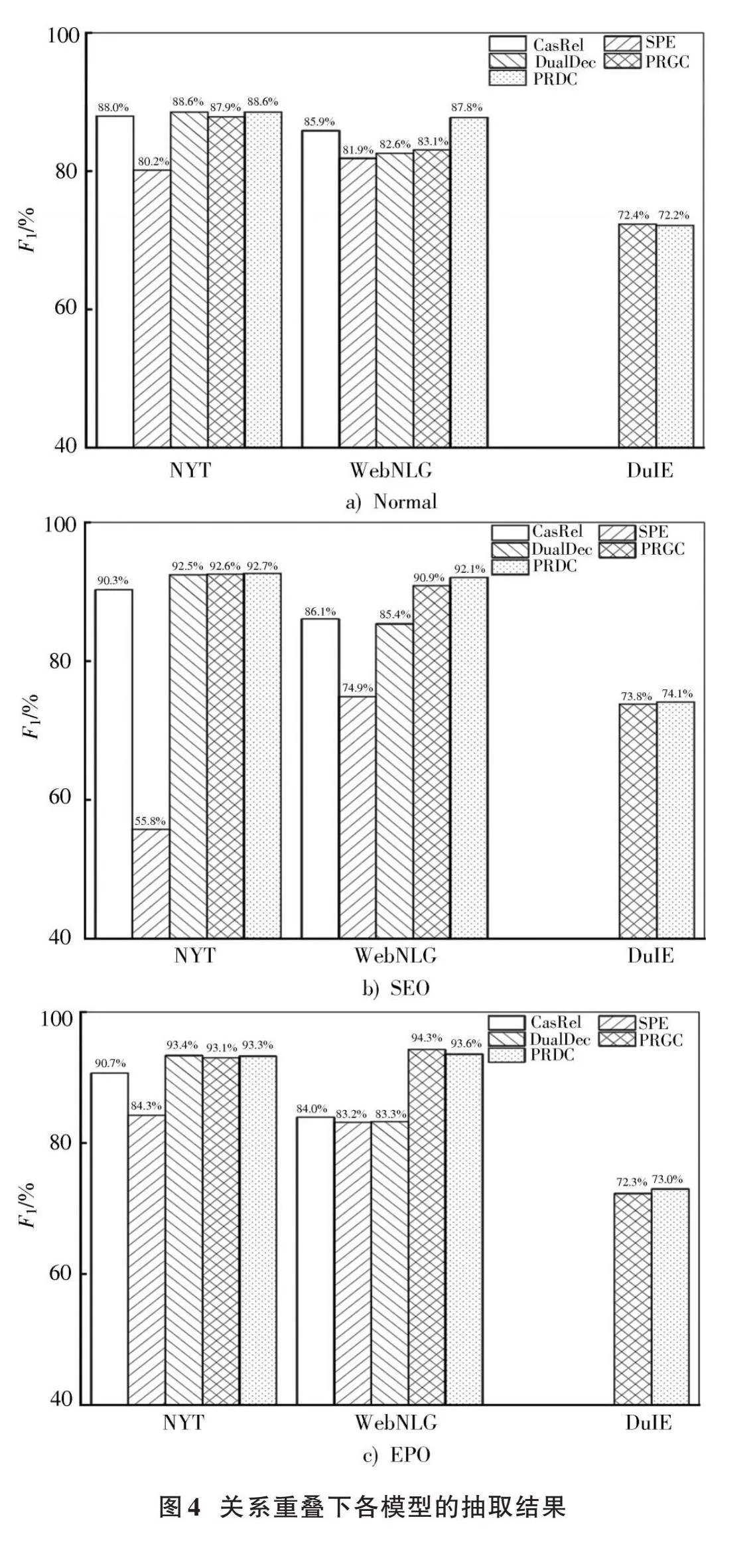
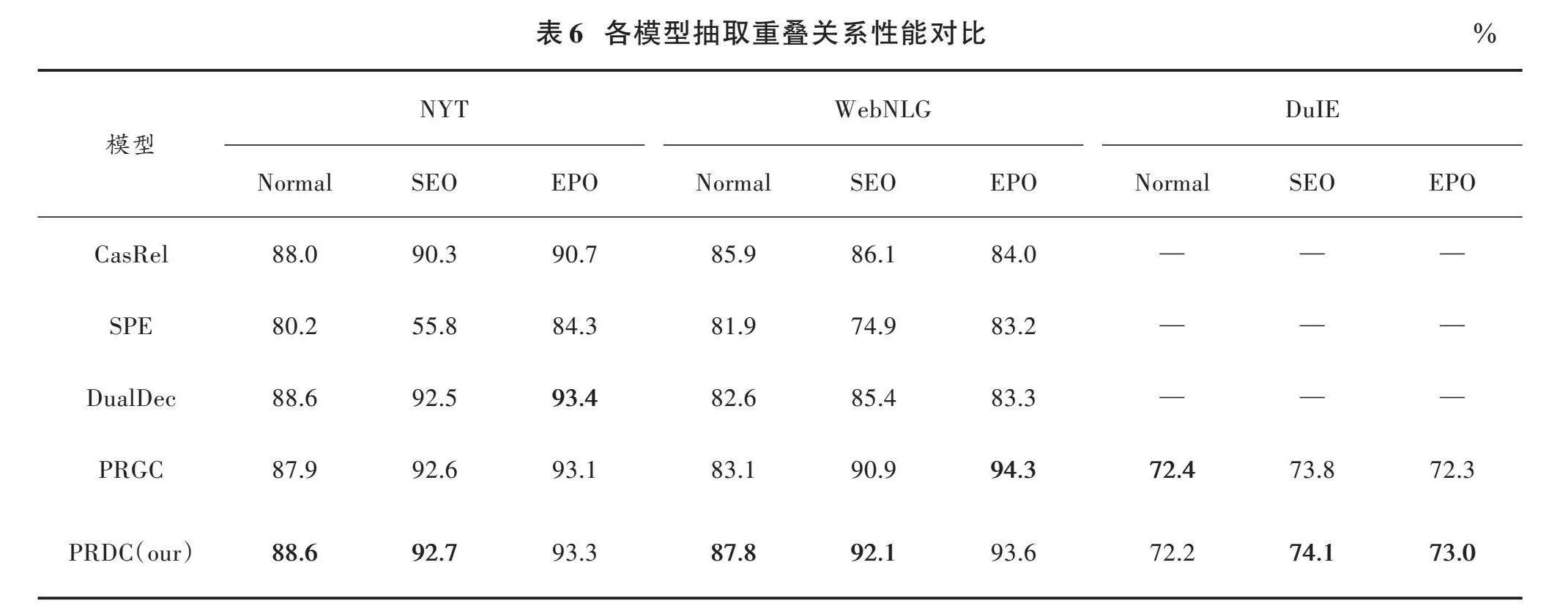
表6所示为各模型对重叠关系的抽取结果,对应图4中可以明显看出,本文提出的模型在多种情况下均表现出最佳效果。在NYT和WebNLG数据集上,本文模型相比于目前较好的模型PRGC,在Normal情况下,性能分别提高了0.7%、4.7%;在SEO情况下,性能分别提高了0.1%和1.2%;EPO情况下,在NYT数据集上性能提升0.2%,在WebNLG数据集上性能降低0.7%,说明模型在NYT上对重叠关系都能很好的抽取,在WebNLG上抽取普通关系性能更佳。最后,在DuIE数据集上本文模型相比PRGC抽取SEO和EPO重叠关系分别提升0.3%和0.7%。总的来说,本文所提出的模型在处理重叠关系问题上相较于其他模型能更好地提取三元组。这是因为本文的联合抽取框架不仅有效减少了误差传播抽取信息,而且能够过滤掉无用的关系,从而提高性能。
3.4.2" 模型对三元组数目提取的影响
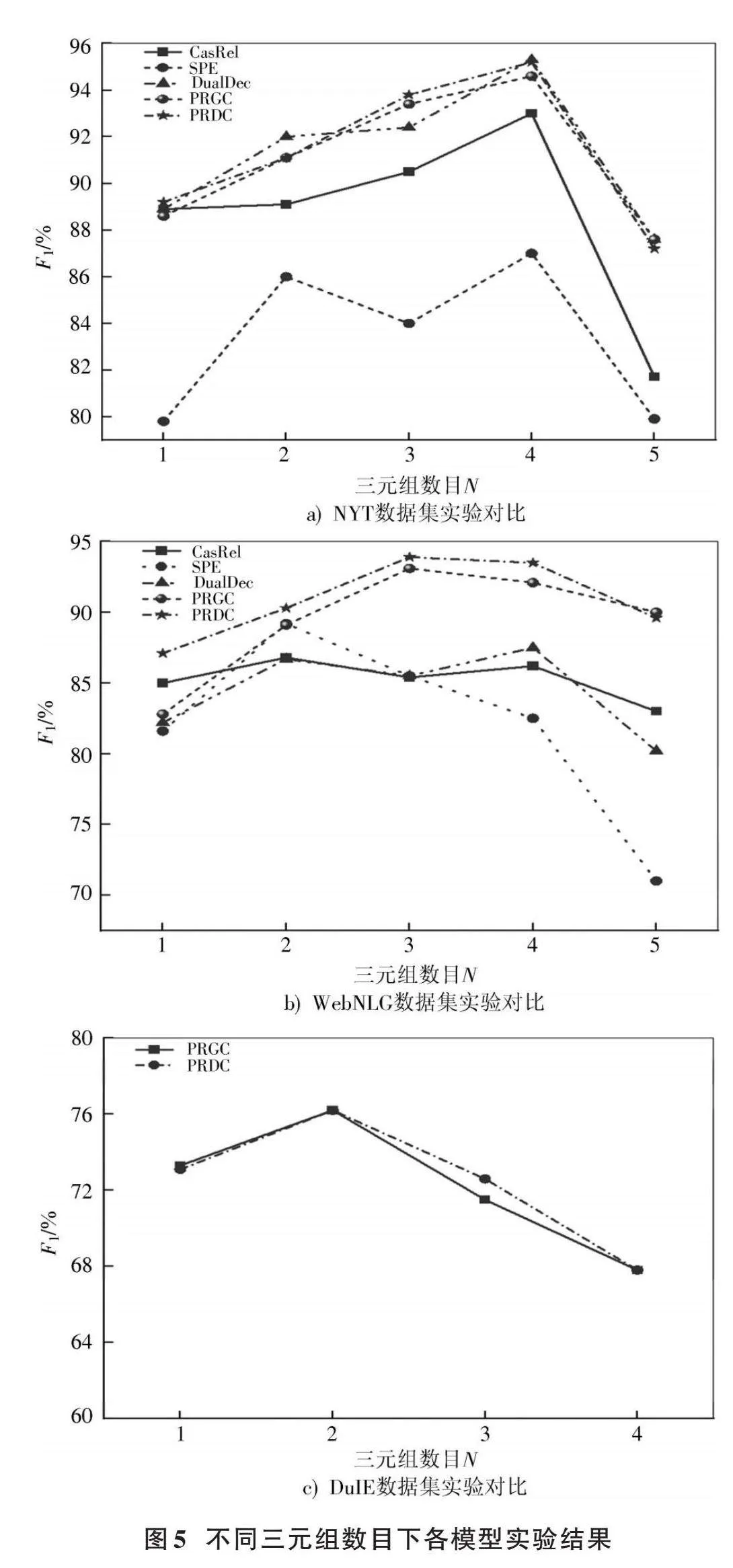
为了验证模型在提取三元组数量方面的能力,将数据集按照句子中包含的三元组个数划分为5个不同的类别,并进行实验,实验结果如图5、表7所示。
本文提出的模型相较于其他基线模型在两个数据集上均展现出显著优势。
本文模型相较于性能较好的PRGC模型,在WebNLG数据集上普遍效果很好,三元组数量分别为1、2、3、4时,F1值分别提升4.3%、1.2%、0.8%和1.4%;在NYT数据集上,三元组数量分别为1、3、4时,F1值分别提升0.6%、0.4%和0.6%;N≥5时在NYT和WebNLG较于PRGC均略微下降0.4%,但数据集中三元组数量高于5组的占比较低。在DuIE数据集上当三元组数量为3时,F1值较PRGC提升1.1%。总体来说,PRDC模型能更好地处理大部分三元组。
3.4.3" PRDC对模型的影响
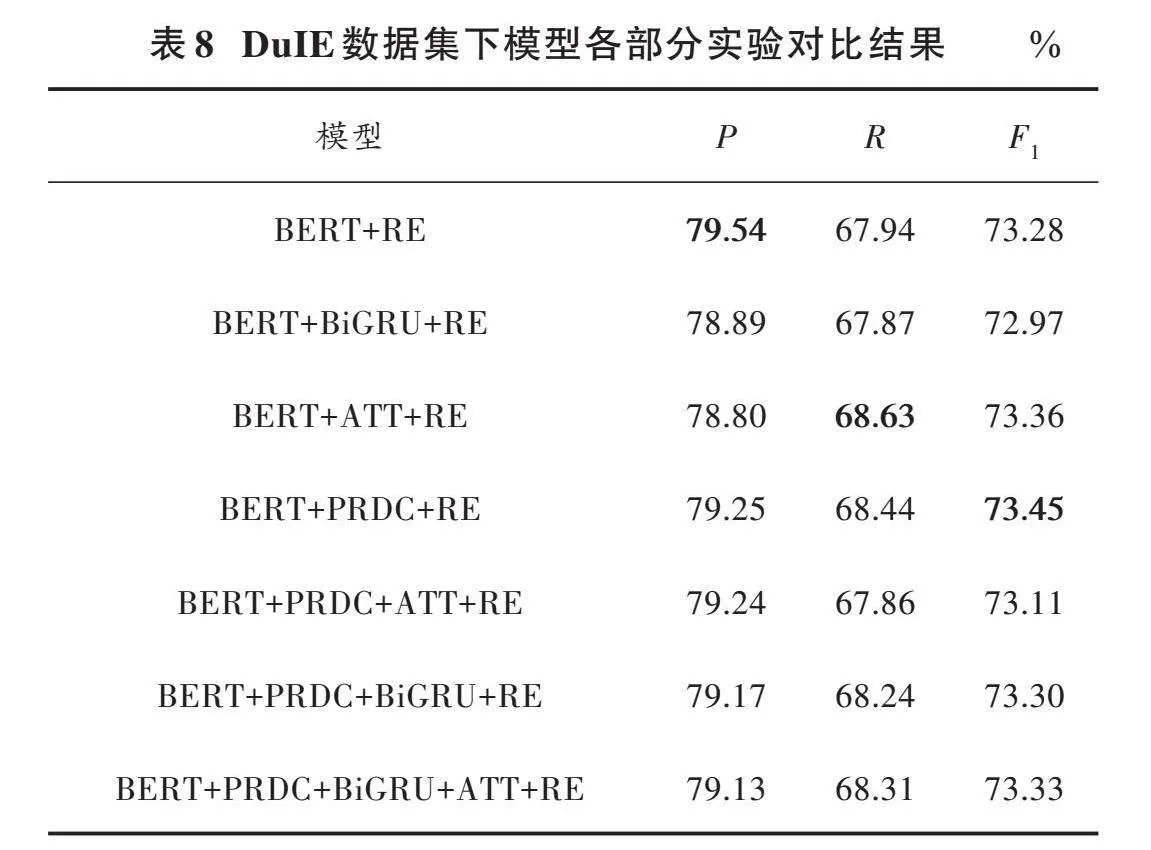
为了验证PRDC对模型抽取关系特性的有效性,设计了消融实验进行验证。各模型的对比结果如表8所示。
表8中每个模型都具有相同的关系抽取层RE,相比于BERT+RE基线模型,添加BiGRU、ATT和PRDC模块在DuIE短文本数据集上进行验证。由表8可知,单独添加PRDC模块的模型效果最好,为73.45%,这可能归因于短文本的长度通常较短,信息密度较高,而CNN能更好地捕获局部特征。
此外,添加BiGRU后模型性能反而下降0.31%,可能是因为BiGRU对于长序列数据的处理效果通常更好,但如果序列长度过短或过长,会导致BiGRU的性能下降。
添加多头注意力机制后模型性能提升0.08%,但多个模块的串联组合效果低于单独添加PRDC,甚至有的低于BERT+RE的基线模型,这可能是因为PRDC和ATT都涉及到对输入序列进行关注或增强,因此它们可能会在某种程度上重叠或冲突,导致模型学习到冗余的信息,造成模型性能下降。
4" 结" 语
关系抽取旨在从文本中提取出实体对之间存在的语义关系,但现有的关系抽取方法均存在关系冗余和重叠的不足,尤其是对于短文本,会因上下文信息不足而出现语义信息不足和噪声大等问题。此外,一般流水线式的关系抽取模型还存在误差传递问题。为此,文中提出一种基于并联残差膨胀卷积网络的短文本实体关系联合抽取方法。本文提出的基于并联残差膨胀卷积网络的短文本实体关系联合抽取方法在实验中取得了令人满意的结果。通过在公开数据集上进行实验,验证了该方法在解决短文本关系抽取任务中的有效性。本文方法能够有效地应对短文本语义表达受限、噪声和歧义性等挑战,提高了关系抽取任务的准确性。
实验结果显示,在联合抽取框架中引入设计的并联残差膨胀卷积网络,能够更好地捕获关键信息并提高模型性能。
但是,对于具有大量主客体重叠特点的数据集来说,该模型还有待完善和提高。未来,将进一步研究该模型应用于其他领域关系抽取任务,优化模型并让其更好地应对主客体重叠的情况。
注:本文通讯作者为奚雪峰、崔志明。
参考文献
[1] ZHONG Z, CHEN D. A frustratingly easy approach for entity and relation extraction [C]// In 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. [S.l.]: ACL, 2021: 50⁃61.
[2] WEI Z, SU J, WANG Y, et al. A novel cascade binary tagging framework for relational triple extraction [C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. [S.l.]: ACL, 2020: 1476⁃1488.
[3] ZHENG H, WEN R, CHEN X, et al. PRGC: potential relation and global correspondence based joint relational triple extraction [C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing. [S.l.]: ACL, 2021: 6225⁃6235.
[4] REN F, ZHANG L, ZHAO X, et al. A simple but effective bidirectional framework for relational triple extraction [C]// Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining. San Francisco, CA, USA: ACM, 2022: 824⁃832.
[5] DIXIT K, AL⁃ONAIZAN Y. Span⁃level model for relation extraction [C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. [S.l.]: ACL, 2019: 5308⁃5314.
[6] EBERTS M, ULGES A. Span⁃based joint entity and relation extraction with transformer pre⁃training [EB/OL]. [2023⁃01⁃17]. https://www.xueshufan.com/publication/3090302425.
[7] WANG Y, YU B, ZHANG Y, et al. TPLinker: single⁃stage joint extraction of entities and relations through token pair linking [C]// Proceedings of the 28th International Conference on Computational Linguistics. Barcelona, Spain: ACM, 2020: 1572⁃1582.
[8] REN F, ZHANG L, YIN S, et al. A novel global feature⁃oriented relational triple extraction model based on table filling [C]// Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Cambridge, Massachusetts: ACM, 2021: 2646⁃2656.
[9] WANG Y, SUN C, WU Y, et al. UniRE: a unified label space for entity relation extraction [C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing. [S.l.]: ACM, 2021: 220⁃231.
[10] SHANG Y M, HUANG H, MAO X. OneRel: joint entity and relation extraction with one module in one step [J]. Computation and language, 2022, 36(10): 11285⁃11293.
[11] LI X, YIN F, SUN Z, et al. Entity⁃relation extraction as multi⁃turn question answering [C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. [S.l.]: ACM, 2019: 1340⁃1350.
[12] 乔勇鹏,于亚新,刘树越,等.图卷积增强多路解码的实体关系联合抽取模型[J].计算机研究与发展,2023,60(1):153⁃166.
[13] 贾宝林,尹世群,王宁朝.基于门控多层感知机的端到端实体关系联合抽取[J].中文信息学报,2023,37(3):143⁃151.
[14] SUI D, ZENG X, CHEN Y, et al. Joint entity and relation extraction with set prediction networks [J]. IEEE transactions on neural networks and learning systems, 2023, 35(9): 12784⁃12795.
[15] 薛平,李影,吴中海.基于语言模型增强的中文关系抽取方法[J].中文信息学报,2023,37(7):32⁃41.
[16] 宁尚明,滕飞,李天瑞.基于多通道自注意力机制的电子病历实体关系抽取[J].计算机学报,2020,43(5):916⁃929.
[17] 李志欣,孙亚茹,唐素勤,等.双路注意力引导图卷积网络的关系抽取[J].电子学报,2021,49(2):315⁃323.
[18] 葛艳,杜坤钰,杜军威,等.基于混合神经网络的实体关系抽取方法研究[J].中文信息学报,2021,35(10):81⁃89.
[19] ZENG D, LIU K, CHEN Y, et al. Distant supervision for relation extraction via piecewise convolutional neural networks [C]// Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Lisbon, Portugal: EMNLP, 2015: 1753⁃1762.
[20] 冯建周,宋沙沙,王元卓,等.基于改进注意力机制的实体关系抽取方法[J].电子学报,2019,47(8):1692⁃1700.
[21] 唐朝,诺明花,胡岩.ResNet结合BiGRU的关系抽取混合模型[J].中文信息学报,2020,34(2):38⁃45.
[22] ZHOU K, QIAO Q, LI Y, et al. Improving distantly supervised relation extraction by natural language inference [J]. Proceedings of the AAAI conference on artificial intelligence, 2023, 37(11): 14047⁃14055.
[23] ZARATIANA U, TOMEH N, HOLAT P, et al. An autore⁃gressive text⁃to⁃graph framework for joint entity and relation extraction [EB/OL]. [2024⁃01⁃08]. https://arxiv.org/abs/2401.01326?context=cs.LG.
[24] CHANG H, XU H, VAN GENABITH J, et al. JoinER⁃BART: joint entity and relation extraction with constrained decoding, representation reuse and fusion [J]. IEEE/ACM transactions on audio, speech, and language processing, 2023(31): 3603⁃3616.
[25] YUAN L, CAI Y, WANG J, et al. Joint multimodal entity⁃relation extraction based on edge⁃enhanced graph alignment network and word⁃pair relation tagging [J]. Proceedings of the AAAI conference on artificial intelligence, 2023, 37(9): 11051⁃11059.
[26] FU T J, LI P H, MA W Y. Graphrel: modeling text as relational graphs for joint entity and relation extraction [EB/OL]. [2023⁃12⁃07]. https://www.xueshufan.com/publication/2949212908.
[27] ZENG X, HE S, ZENG D, et al. Learning the extraction order of multiple relational facts in a sentence with reinforcement learning [C]// 2019 Conference on Empirical Methods in Natural Language Processing and 9th International Joint Conference on Natural Language Processing. Hong Kong, China: NLP, 2019: 367⁃377.
[28] YU B, ZHANG Z, SHU X, et al. Joint extraction of entities and relations based on a novel decomposition strategy [C]// European Conference on Artificial Intelligence. [S.l.]: IOS, 2020: 2282⁃2289.
[29] MA L, REN H, ZHANG X. Effective cascade dual⁃decoder model for joint entity and relation extraction [EB/OL]. [2023⁃11⁃07]. https://www.xueshufan.com/publication/3176985211.
[30] 张鲁,段友祥,刘娟,等.基于RoBERTa和加权图卷积网络的中文地质实体关系抽取[J].计算机科学,2024,51(8):297⁃303.
[31] 成全,蒋世辉,李卓卓.基于改进CasRel实体关系抽取模型的在线健康信息语义发现研究[J].数据分析与知识发现,2024,8(10):112⁃124.
猜你喜欢
教育教学论坛(2017年10期)2017-03-20 20:20:02
青年文学家(2016年17期)2016-12-17 20:31:17
青年文学家(2016年29期)2016-11-23 18:04:23
北方文学·中旬(2016年8期)2016-11-10 16:25:01
北方文学·下旬(2016年7期)2016-11-10 11:01:44
考试周刊(2016年52期)2016-07-09 19:12:11
青年文学家(2016年15期)2016-05-06 22:31:28
中国石油大学学报(社会科学版)(2015年2期)2015-06-15 00:27:07
文教资料(2014年18期)2014-11-13 05:12:20
文教资料(2014年3期)2014-08-18 03:46:53
