
基于语音信号时频特征融合的帕金森病检测方法
2025-01-01 00:00:00王晨哲季薇郑慧芬李云
郑州大学学报(理学版) 2025年1期






摘要: 发音障碍是帕金森病的早期症状之一。近年来,基于语音信号的帕金森病检测的研究大多采用梅尔刻度下的相关语音特征与深度神经网络模型相结合的方法。然而,现有的模型无法充分关注语音信号的全局时序信息,且梅尔刻度特征在准确表征帕金森病的病理信息方面效果有限。为此,提出了一种基于语音时频特征融合的帕金森病检测方法。首先,提取语音的梅尔频率倒谱系数,并将其作为模型的输入。接着,在已有的S-vectors模型中引入Conformer编码器模块,以提取语音的时域全局特征。最后,将与帕金森病语音检测相关的频域全局特征嵌入时域特征中进行时频信息融合,以实现帕金森病语音检测。在公开帕金森病语音数据集和自采语音数据集上验证了方法的有效性。
关键词: 帕金森病; 梅尔频率倒谱系数; S-vectors; Conformer; 时频特征融合
中图分类号: TP391.4
文献标志码: A
文章编号: 1671-6841(2025)01-0053-08
DOI: 10.13705/j.issn.1671-6841.2023118
Parkinson′s Disease Detection Method Based on Time-frequency
Feature Fusion of Speech Signals
WANG Chenzhe1, JI Wei2, ZHENG Huifen3, LI Yun1
(1.School of Computer Science, Nanjing University of Posts and Telecommunications, Nanjing 210023, China;
2.School of Communications and Information Engineering, Nanjing University of Posts and Telecommunications,
Nanjing 210003, China; 3.Geriatric Hospital of Nanjing Medical University, Nanjing 210009, China)
Abstract: Dysphonia is one of the earliest symptoms of Parkinson′s disease (PD). In recent years, many studies on the detection of PD based on speech signals used deep neural network models combined with Mel Scale features. However, existing models could adequately focus on the global time-series information of speech signals. And Mel Scale features had limited effectiveness in accurately characterizing the pathological information of PD. To solve the above problems, a speech detection method for PD was proposed based on time-frequency feature fusion. Firstly, Mel frequency cepstrum coefficients (MFCC) were extracted from speech signals and used as the input data for subsequent models. Then, encoder module of Conformer was introduced into the S-vectors model to extract speech global features in time domain. Finally, global features in frequency domain, related to speech detection of PD, were embedded into the time-domain features to fuse the time-frequency information for PD detection ultimately. The effectiveness of the proposed model was verified respectively on a public PD dataset and a self-collected speech dataset.
Key words: Parkinson′s disease; Mel frequency cepstrum coefficient; S-vectors; Conformer; time-frequency feature fusion
0引言
帕金森病(Parkinson′s disease, PD)是仅次于阿尔茨海默病的第二大神经退行性疾病。已有研究表明,该病和发音障碍之间有一定的病理联系。帕金森病患者临床上大多存在一定程度的语音损伤症状,且语音损伤在发病早期就已经出现不同程度的症状,表现为讲话缓慢、声音嘶哑、音量低和发音震颤等[1]。这些语音损伤是帕金森病患者喉部发音以及呼吸肌肉的控制损失引起的。基于此,可考虑利用语音信号,结合机器学习技术进行帕金森病的检测[2-3]。基于语音的帕金森病检测方法具有非介入式、采集方便和成本较低等优点,可以有效缓解医疗资源紧张的问题,提高诊疗阶段的效率[4]。然而,现有的帕金森病语音检测方法难以很好地表征帕金森病语音中的病理信息,准确性也有待提高。因此,研究准确高效的帕金森病语音检测方法,具有重要的社会意义和研究价值。
随着深度学习在说话人识别、语音识别等语音信号处理领域的广泛应用[5],越来越多的研究者开始利用深度学习技术开展基于语音的帕金森病检测工作[6]。Vasquez-Correa等[7]考虑现实应用场景,使用智能手机采集语音数据,并利用梅尔声谱图结合ResNet18模型进行帕金森病检测。Er等[8]依然以梅尔声谱图作为输入特征,提出了预训练卷积神经网络(convolution neural network, CNN)模型并结合长短期记忆网络的方法,得到了更好的帕金森病分类性能。Karaman等[9]利用DenseNet深度CNN模型,基于迁移学习方法从语音信号中自动检测帕金森病。季薇等[10]利用掩蔽自监督模型来掩蔽部分梅尔声谱图特征并对其进行重构,从而学习帕金森病患者语音的更高级特征表示。上述方法存在的问题在于:1) 模型无法充分关注语音信号的全局时序信息;2) 作为语音识别领域的通用特征,梅尔刻度特征在准确表征帕金森病的病理信息方面有一定的局限性;3) 从数据集的使用方面看,在已有研究中研究者大多使用持续元音数据集,这是因为持续元音能够反映基频变化特征[11],且发音简单、采集方便;然而,持续元音难以表征帕金森病患者语音中存在的清音平均时长较短、浊音起始时间较短、塞音呈现擦音化等时序特点[12]。与之对比,使用情景对话或文本朗读等长句语料则可以更好地提取帕金森病语音中的时序病理信息。
研究表明,基于自注意力机制的Transformer技术可有效提高模型的时序特征提取能力,在语音信号处理领域已取得了很好的效果。Dong等[13]基于Transformer技术提出一种非递归的语音识别模型,得益于自注意力机制的融入,该模型在获得性能提升的同时极大地减少了训练成本。Gulati等[14]认为Transformer可以更好地对基于内容的全局相关性进行建模,而卷积擅长提取局部特征,因此将卷积应用于Transformer的编码层,提出了应用于语音识别的Conformer架构,其编码器模块将Transformer和CNN结合起来,更好地对语音序列的全局特征和局部特征进行了统一建模。
值得注意的是,在时序信息的学习上,X-vectors模型也是一个很好的工具,并在说话人识别领域得到有效应用[15]。该模型中的语音帧级特征提取模块可利用时延神经网络(time delay neural network, TDNN)结构提取帧级特征学习语音信号的时序信息,话语级特征提取模块则利用统计池化层将TDNN提取的帧级特征过渡到话语级的全局特征。Moro-Velazquez等[16]考虑帕金森病语音检测与说话人识别的相似性,从文本语料语音数据中提取梅尔频率倒谱系数(Mel frequency cepstrum coefficients, MFCC),利用X-vectors模型提取帕金森病语音的时序信息,实现了帕金森病的检测。为更好地提取语音信号的全局特征,Mary等[17]将自注意力机制和位置编码引入X-vectors模型,提出S-vectors网络结构。该结构在语音帧级特征提取模块采用Transformer的编码器层,能够学习更多的说话人信息,在说话人识别领域获得了优于X-vectors的性能。然而,S-vectors结构只关注语音的全局特征,对细粒度的局部特征提取效果有限。
为充分关注帕金森病语音中的时序信息,提高语音特征对帕金森病病理信息的表征能力,本文针对帕金森病患者的长句语料,提出一种基于语音信号时频特征融合的帕金森病语音检测方法。首先,提取长句语音信号的MFCC特征,并将其作为后续模型的输入数据。然后,在S-vectors模型的基础上,将其原有的编码层替换成Conformer架构中的编码器模块,并提取时域语音特征。最后,将与帕金森病语音检测相关的频域全局特征嵌入到时域特征中,利用多层全连接层融合时频信息,最终实现帕金森病语音检测。在MDVR-KCL公开帕金森病语音数据集和自采语音数据集上的实验结果表明,本文所提方法的性能明显优于基线模型。
本文主要贡献在于:1) 对传统的S-vectors模型进行了编码层的替换,Conformer编码器模块的引入使得改进后的模型可以利用自注意力机制和卷积神经网络更好地提取时域全局特征和细粒度局部特征;2) 频域全局特征的嵌入,促进了时频域信息的融合,有效弥补了单一的梅尔刻度特征在特征表征上的局限性,提高模型对帕金森病语音病理信息的学习能力,提升帕金森病语音检测模型的性能。
1本文方法
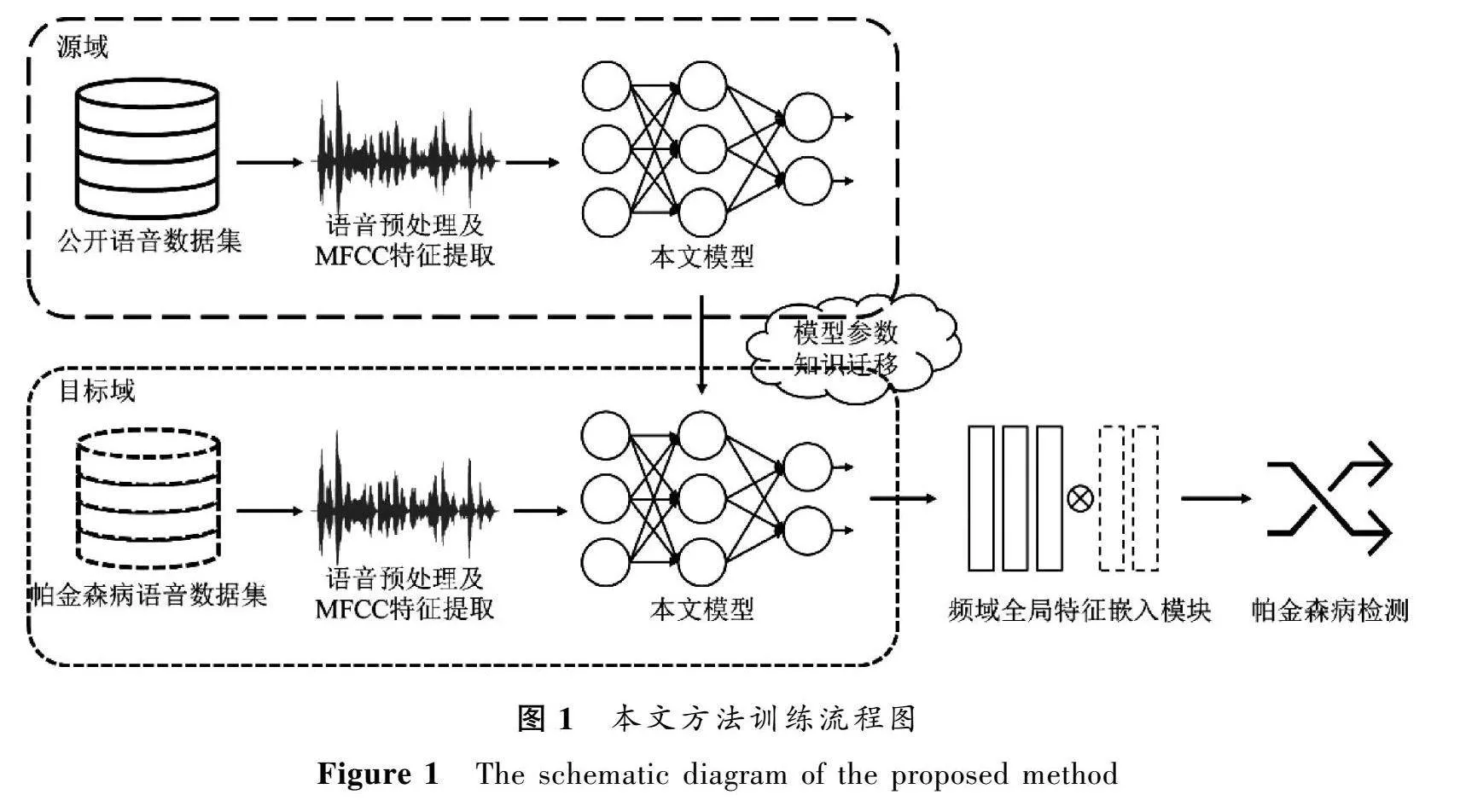
为更好地提取帕金森病患者语音中的病理信息,提高语音检测的效果,本文提出一种基于语音信号时频特征融合的帕金森病检测方法。如图1所示,基于语音信号的时频特征融合模型及其训练流程包括源域预训练和目标域微调两个过程。
首先,在预训练阶段使用公开的Common Voice多语言语音数据集[18],数据集中的语料为多种语言的长句语料。对Common Voice数据集的语音数据提取MFCC特征后,输入本文所提模型进行预训练。然后,将预训练模型参数迁移至目标域,并增加频域全局特征嵌入模块,利用帕金森病语音数据集重新微调模型以更新模型参数。最终得到适用于帕金森病语音信号的检测模型。
1.1基于语音信号的时频特征融合模型
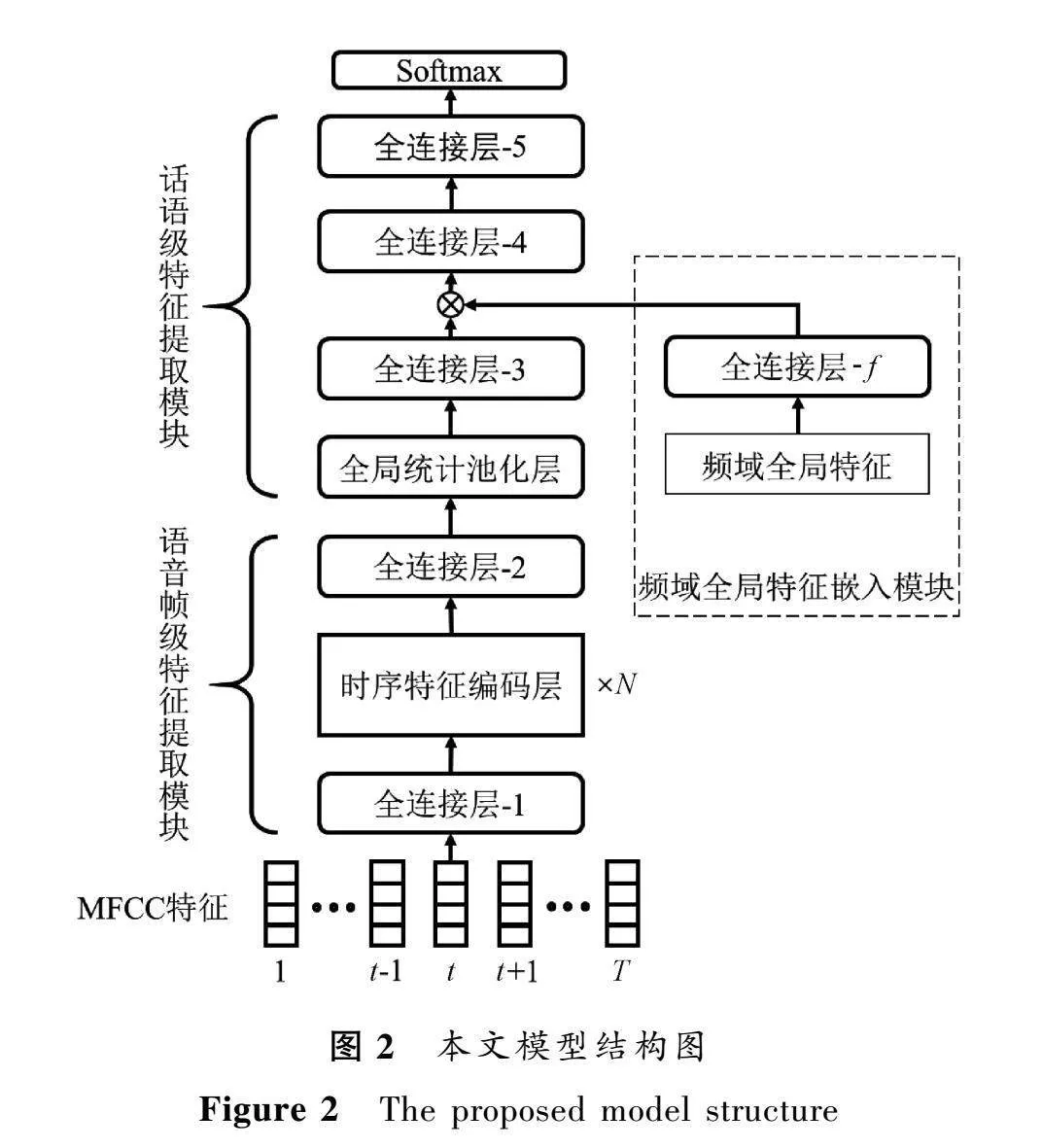
本文所提的基于语音信号的时频特征融合模型如图2所示,同样分为语音帧级特征提取模块和话语级特征提取模块。为充分关注全局时序信息,所提模型基于S-vectors网络结构,将其原有的编码层替换成Conformer架构中的编码器模块。Transformer和CNN相结合的时序特征编码层的引入,可使本文所提模型具有同时捕捉语音的全局特征和局部特征的能力。时序特征编码层中特有的多头自注意力机制和相对位置编码等,可使本文所提模型关注帕金森病患者语音存在的响度降低、语速较快、元音平均时长较短、浊音起始时间较短等时序特性,能够提取更多的帕金森病语音特征。
由于提取的特征主要包含帕金森病语音的时域信息,而帕金森病语音信号也存在基频变化较小,清、浊音能量存在差异性等频域特性。为充分挖掘帕金森病患者语音中的各种时频变化,在对预训练模型进行微调时,本文将与帕金森病语音检测相关的频域全局特征嵌入生成的时域特征中,采用多层全连接层进行时频域信息融合,以提高模型对帕金森病语音的检测效果。
1.2时序特征编码层
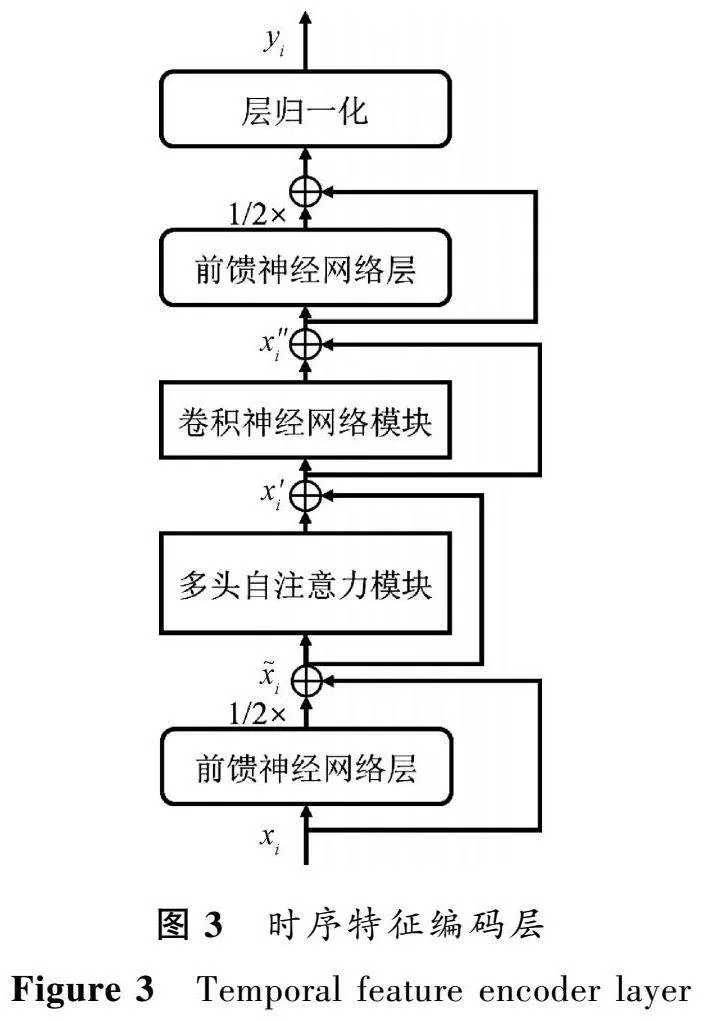
与传统的S-vectors不同的是,本文所提模型中引入的时序特征编码层采用Conformer的编码器结构[14],该结构由多头自注意力模块和卷积神经网络模块以及两层半步前馈神经网络组成,如图3所示。其中,两层前馈神经网络层采取夹层的方式,分别置于自注意力模块前后。
该编码层的输入、输出可以表示为
x~=x+12FFN(x),
x′=x~+MHSA(x~),
x″=x′+Conv(x′),
y=Laynorm(x″+12FFN(x″)),(1)
其中:FFN表示前馈神经网络层;MHSA表示多头自注意力模块;Conv表示卷积神经网络模块;Laynorm表示层归一化;x是时序特征编码层的输入;x~是FFN的输出;x′是MHSA的输出;x″是Conv的输出;y是时序特征编码层的输出。
1.2.1多头自注意力模块
为更好地提取语音信号的全局特征,采用多头自注意力模块,同时引入相对位置编码。其核心部分是多头自注意力网络,将输入特征序列映射到多个特征子空间,提取时序相关的多种语音特征。多头自注意力机制可以表示为
MultiHead(Q,K,V)=Concat(h,h,…,h)×WO,(2)
其中:Q、K、V表示自注意力机制中由语音特征学习的特征表示;投影矩阵WO是通过学习获得的参数;n表示多头自注意力的头数;Concat(h,h,…,h)表示拼接所有自注意力机制的输出h,i=1,2,…,n。h表示为
h=Attention(QWQ,KWK,VWV)=
softmax(QWQ(KWK)Td)VWV,(3)
其中:WQ、WK、WV是可学习的参数。得益于自注意力机制跨越语音上下文的特征提取能力,编码层可以提取更多的语音特征。
Quan等[19]的研究表明,帕金森病患者和健康人的清浊音转换次数和波形轮廓平稳性存在显著差异。为了在模型中考虑语音信号的发音转换特征信息,该编码层使用相对位置编码[20]。传统的Transformer将绝对位置编码嵌入特征向量中[21],如式(4)所示。该模块将相对位置编码引入自注意力模块的注意力分数中,如式(5)所示,
Aabs=ETWTWE(a)+ETWTWU(b)+
UTWTWE(c)+UTWTWU(d),(4)
Arel=ETWTWE(a)+ETWTWR(b)+
uTWE(c)+vTWR(d),(5)
其中:Aabs表示引入绝对位置编码的注意力分数;Arel表示引入相对位置编码的注意力分数;E为语音序列的特征向量;U为语音序列中位置i的绝对位置编码;R为位置i与j的正余弦相对位置编码。
该模块采用R替代绝对位置编码U,并且对于语音特征向量和位置编码分别使用不同的参数矩阵W和W表示基于内容和基于位置的线性变化。此外,用u∈Rd替代UTWT,用v∈Rd替代UTWT,这是因为键向量对于自身的位置编码信息应保持一致。相对位置编码可以提高模型对不同长度的语音序列的泛化性和鲁棒性。
1.2.2卷积神经网络模块
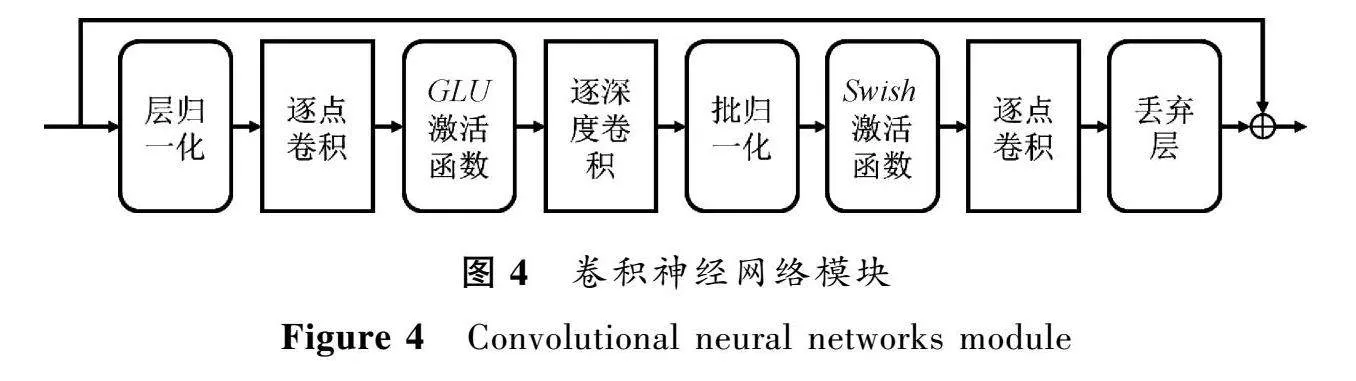
卷积神经网络模块采用深度可分离卷积替代传统卷积神经网络,可以有效降低网络的参数量,提高计算效率,如图4所示。Conformer 的卷积神经网络模块考虑先采用门控机制对特征进行非线性变换,以有效过滤噪声以及无关信息,提高模型对语音信号的特征提取能力[22]。然后采用深度可分离卷积(depthwise separable convolutions)替代传统卷积神经网络,能够在有效降低网络参数量的前提下获得相近的卷积效果,提高模型的计算效率[24]。其中,逐深度卷积只关注每个通道内序列之间的依赖关系,不关注不同通道之间的依赖;而逐点卷积关注了不同通道之间的依赖关系,不关注通道内的依赖。通过两种卷积的组合,可以在减少参数量的同时,实现传统卷积的效果。
1.3频域全局特征嵌入模块
自注意力机制能够在时域提取语音信号的相关性,关注语音的全局时序信息。考虑帕金森语音的频域信息,采用语音信号处理算法提取相关特征也是帕金森语音诊断领域的重要方法[25]。基于此,本文利用时频信息融合方法[26],结合时域和频域两个维度的特征,提高模型对帕金森语音的特征提取能力。
帕金森病患者在发音时,往往无法很好地控制清、浊音的转换,且存在基频变化较小的特点,本文利用DisVoice语音特征提取库[27],引入多种相关特征,包括:基频包络、浊音段的基频、基频扰动Jitter、频率微扰商(pitch perturbation quotient, PPQ)、清浊音段的对数能量等。对于上述特征,分别在一段语音中计算其均值、标准差、偏度和峰度四种统计度量,最终得到103维的频域全局特征。将频域特征进行归一化处理,经过特征映射全连接层嵌入本文模型生成的256维时域特征表示中,得到长度为320维的时频融合特征。采用多层全连接层对时频域特征进行信息融合,提高模型对语音信号的特征提取能力,如图5所示。
2实验及结果分析
2.1数据集
本文使用了2个语音数据集,包括公开的MDVR-KCL帕金森病语音数据集[28]和本课题组自采的帕金森病中文语音数据集。
MDVR-KCL数据集是由伦敦国王学院(King′s College London, KCL)医院在2017年使用智能手机与受试者进行语音通话采集的帕金森病语音数据集,并且保证所有通话均在安静的室内环境中进行。受试者包括16名帕金森病患者(PD)和21名健康人(healthy controls, HC)。采集内容包括朗读一段内容确定的文本,以及与研究人员进行自发的对话。本文采用文本数据集,包含16条帕金森病患者语音和21条健康人语音。
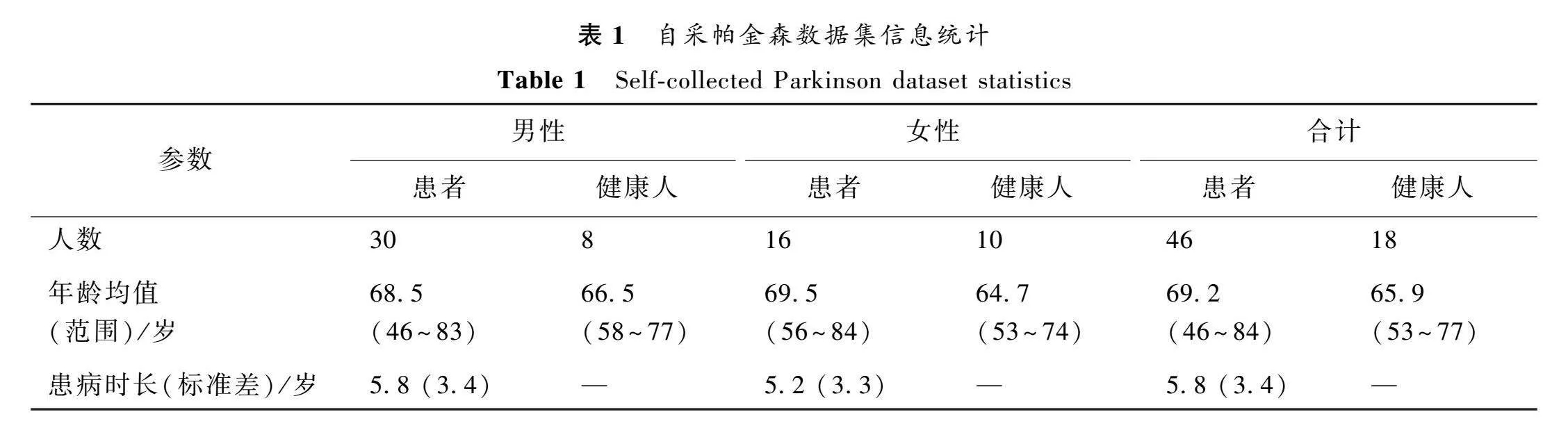
自采帕金森数据集是由本课题组与南京医科大学附属老年医院的帕金森诊疗中心合作采集。受试者包含46位帕金森病患者(30位男性,16位女性)和18位健康人(8位男性,10位女性)。对未患有帕金森病的年龄匹配的受试者进行其他疾病的询问评估,以避免声带病变对实验结果造成影响。该数据集的统计信息如表1所示。数据采集均在安静的室内环境进行,要求受试者以正常语速和说话响度朗读一段固定内容的文本。最终得到46条帕金森病患者语音和18条健康人语音。
2.2实验条件及过程
本实验使用Python语言基于PyTorch深度学习框架实现所有算法。在本实验中,对所有的帕金森病语音数据经剪辑后得到5s左右的语音片段,并提取30维的MFCC特征,采用帧长为25ms和帧移为10ms的滑动窗口对语音信号进行分帧,同时使用Librosa音频处理库去除语音首尾的静音帧。此外,对所有语音样本均进行下采样到16 kHz。实验采用五折交叉验证方法,基于预训练模型,微调模型5个epoch。取5次交叉验证的结果求均值,作为最终的实验结果。
为验证算法的有效性,本文使用准确率(acc)、敏感度(sen)、特异度(spe)和AUC(area under ROC curve)作为实验结果的评估准则,其中加粗数字表示在该度量指标上呈现最优的结果。
2.3实验结果
为验证本文方法的有效性,分别在MDVR-KCL数据集和自采帕金森数据集上进行对比实验,并采用S-vectors模型、X-vectors模型以及ResNet18模型作为基线模型。其中ResNet18基线模型将语音信号的梅尔声谱图作为模型输入[7],且ResNet18为公开预训练的深度图像处理模型。其余模型均将30维MFCC特征作为输入,且先在Common Voice数据集上进行预训练。实验结果如表2和表3所示。其中本文-fc3表示将频域特征嵌入到全连接层-3输出的特征向量中,本文-fc4表示将频域特征嵌入到全连接层-4输出的特征向量中。
从表2和3中可以看出,本文方法在多数度量指标上明显优于基线模型,并且在两个不同的数据集上的结论具有一致性,由此可以验证方法的有效性。实验结果表明,相较于传统的S-vectors和X-vectors模型,所提模型能够利用自注意力机制和卷积神经网络更好地提取语音的全局特征和细粒度局部特征,且时频域信息融合能够从两个语音特征维度提高帕金森病语音检测的效果。而S-vectors仅采用Transformer编码器提取语音的全局特征,可能难以捕捉短时变化的细粒度信息。此外,可以看出,将频域特征嵌入全连接层-3输出的特征向量中,能够更好地提高语音检测的效果。这是因为双层全连接层可以更好地拟合时频域融合特征与标签间可能存在的非线性关系。
表4对比了不同模型参数设置下在MDVR-KCL数据集上的对比结果。从表中可以看出,相较于三层编码层,编码层数设置为2时模型具有更好的性能。这是因为两层以上的编码层会导致模型参数规模过大,容易造成过拟合,最终影响语音检测性能。此外,注意力头数设置为4时能够学习更多维度的特征信息。
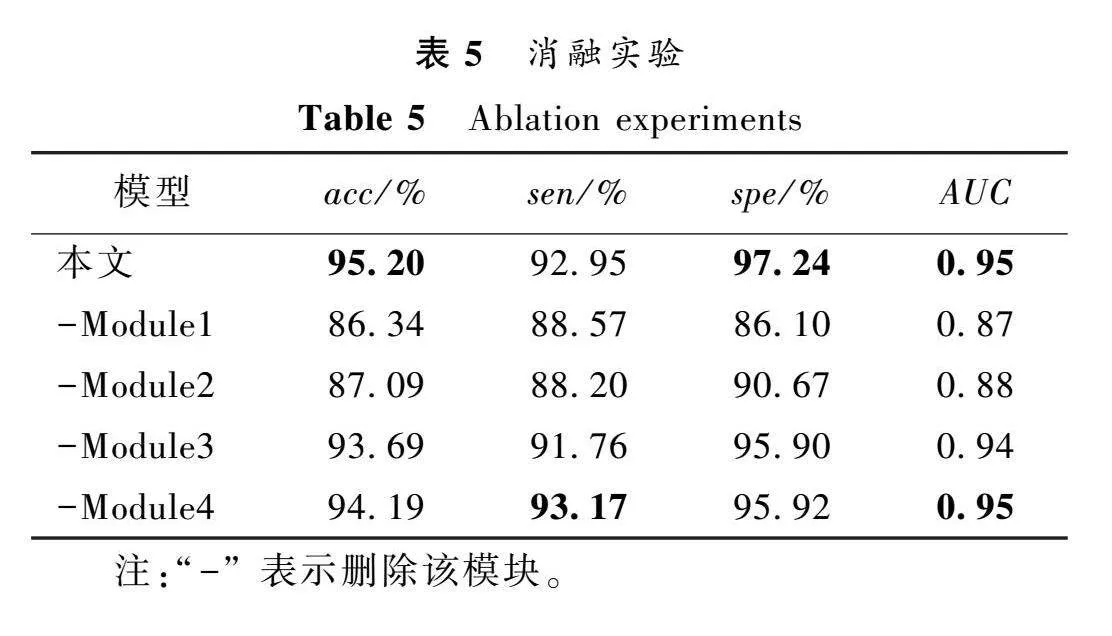
为进一步验证本文方法的有效性,在MDVR-KCL数据集上进行消融实验,评估自注意力机制(Module1)、相对位置编码(Module2)、卷积模块(Module3)以及频域全局特征嵌入模块(Module4)对帕金森病语音检测的效果。实验结果如表5所示。
从表5中可以看出,在分别去除自注意力机制和相对位置编码的情况下,模型的性能受到了较大的影响,此时模型仅依赖卷积模块提取细粒度局部特征,难以学习浊音起始时间较短且清、浊音转换次数变化等全局时序信息。此外,卷积模块及频域全局特征嵌入模块的去除,均在一定程度上降低了帕金森病语音检测的效果。
3结论
本文提出了一种基于语音信号时频特征融合的帕金森病检测方法,针对帕金森病患者的长句语料,将Conformer的编码器模块引入S-vectors模型提取时域特征。并且将与帕金森病语音检测相关的频域全局特征嵌入时域特征中,通过时频信息融合提高了模型对语音信号的特征提取能力。最后在两个数据集上验证了方法的有效性。下一步的研究工作将关注利用时频特征融合结合多任务学习进行帕金森病的病情严重程度的评估。
参考文献:
[1]BENBA A, JILBAB A, SANDABAD S, et al. Voice signal processing for detecting possible early signs of Parkinson′s disease in patients with rapid eye movement sleep behavior disorder[J]. International journal of speech technology, 2019, 22(1): 121-129.
[2]NARENDRA N P, SCHULLER B, ALKU P. The detection of parkinson′s disease from speech using voice source information[J]. IEEE/ACM transactions on audio, speech, and language processing, 2021, 29: 1925-1936.
[3]张小恒, 张馨月, 李勇明, 等. 面向帕金森病语音诊断的非监督两步式卷积稀疏迁移学习算法[J]. 电子学报, 2022, 50(1):177-184.
ZHANG X H, ZHANG X Y, LI Y M, et al. An unsupervised two-step convolution sparse transfer learning algorithm for parkinson′s disease speech diagnosis[J]. Acta electronica sinica, 2022, 50(1):177-184.
[4] TSANAS A. Accurate telemonitoring of parkinson′s disease symptom severity using nonlinear speech signal processing and statistical machine learning[D]. Oxford: Oxford University, 2012.
[5]彭涛, 郑传锟, 张自力, 等. 基于时空特征融合的语音情感识别[J]. 郑州大学学报(理学版), 2022, 54(4):42-48.
PENG T, ZHENG C K, ZHANG Z L, et al. Speech emotion recognition based on spatio-temporal feature fusion[J]. Journal of Zhengzhou university (natural science edition), 2022, 54(4):42-48.
[6]SHABAN M. Deep learning for parkinson′s disease diagnosis: a short survey[J]. Computers, 2023, 12(3): 58.
[7]VASQUEZ-CORREA J C, ARIAS-VERGARA T, KLUMPP P, et al. End-2-end modeling of speech and gait from patients with parkinson′s disease: comparison between high quality vs. smartphone data[C]∥IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE Press, 2021: 7298-7302.
[8]ER M B, ISIK E, ISIK I. Parkinson′s detection based on combined CNN and LSTM using enhanced speech signals with Variational mode decomposition[J]. Biomedical signal processing and control, 2021, 70: 103006.
[9]KARAMAN O, AKN H, ALHUDHAIF A, et al. Robust automated Parkinson disease detection based on voice signals with transfer learning[J]. Expert systems with applications, 2021, 178: 115013.
[10]季薇, 杨茗淇, 李云, 等. 基于掩蔽自监督语音特征提取的帕金森病检测方法[J]. 电子与信息学报, 2023, 45: 1-9.
JI W, YANG M Q, LI Y, et al. Parkinson′s Disease detection method based on masked self-supervised speech feature extraction[J]. Journal of electronics & information technology, 2023, 45: 1-9.
[11]SAKAR B E, ISENKUL M E, SAKAR C O, et al. Collection and analysis of a parkinson speech dataset with multiple types of sound recordings[J]. IEEE journal of biomedical and health informatics, 2013, 17(4): 828-834.
[12]范萍, 顾文涛, 刘卫国. 汉语帕金森症患者的语音声学特征分析[J]. 中国语音学报, 2018(1): 19-25.
FAN P, GU W T, LIU W G. Acoustic analysis of mandarin speech in patients with parkinson′s disease[J]. Chinese journal of phonetics, 2018(1): 19-25.
[12]范萍, 顾文涛, 刘卫国. 汉语帕金森症患者的语音声学特征分析[J]. 中国语音学报, 2018(1): 19-25.
FAN P, GU W T, LIU W G. Acoustic analysis of mandarin speech in patients with parkinson′s disease[J]. Chinese journal of phonetics, 2018(1): 19-25.
[13]DONG L H, XU S, XU B. Speech-transformer: a no-recurrence sequence-to-sequence model for speech recognition[C]∥IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE Press, 2018: 5884-5888.
[14]GULATI A, QIN J, CHIU C C, et al. Conformer: convolution-augmented transformer for speech recognition[EB/OL]. (2020-05-16)[2022-12-10].https:∥arxiv.org/abs/2005.08100.pdf.
[15]SNYDER D, GARCIA-ROMERO D, SELL G, et al. X-vectors: robust DNN embeddings for speaker recognition[C]∥IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE Press, 2018: 5329-5333.
[16]MORO-VELAZQUEZ L, VILLALBA J, DEHAK N. Using X-vectors to automatically detect parkinson′s disease from speech[C]∥IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE Press, 2020: 1155-1159.
[17]MARY N J M S, UMESH S, KATTA S V. S-vectors and TESA: speaker embeddings and a speaker authenticator based on transformer encoder[J]. IEEE/ACM transactions on audio, speech, and language processing, 2022, 30: 404-413.
[18]ARDILA R, BRANSON M, DAVIS K, et al. Common voice: a massively-multilingual speech corpus[EB/OL]. (2019-12-13)[2022-12-10]. https:∥arxiv.org/abs/1912.06670.pdf.
[19]QUAN C Q, REN K, LUO Z W. A deep learning based method for parkinson′s disease detection using dynamic features of speech[J]. IEEE access, 2021, 9: 10239-10252.
[20]DAI Z H, YANG Z L, YANG Y M, et al. Transformer-XL: attentive language models beyond a fixed-length context[EB/OL]. (2019-01-09)[2022-12-10]. https:∥arxiv.org/abs/1901.02860.pdf.
[21]VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]∥Proceedings of the 31st International Conference on Neural Information Processing Systems. New York: ACM Press, 2017: 6000-6010.
[22]WU Z H, LIU Z J, LIN J, et al. Lite transformer with long-short range attention[EB/OL]. (2020-04-24) [2022-12-10]. https:∥arxiv.org/abs/2004.11886.pdf.
[23]DAUPHIN Y N, FAN A, AULI M, et al. Language modeling with gated convolutional networks[C]∥Proceedings of the 34th International Conference on Machine Learning. New York: ACM Press, 2017: 933-941.
[24]CHOLLET F. Xception: deep learning with depthwise separable convolutions[C]∥IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2017: 1800-1807.
[25]SAKAR B E, ISENKUL M E, SAKAR C O, et al. Collection and analysis of a parkinson speech dataset with multiple types of sound recordings[J]. IEEE journal of biomedical and health informatics, 2013, 17(4): 828-834.
[26]姜振宇, 黄雁勇, 李天瑞, 等. 基于时频融合卷积神经网络的股票指数预测[J]. 郑州大学学报(理学版), 2022, 54(2):81-88.
JIANG Z Y, HUANG Y Y, LI T R, et al. Fusion of time-frequency-based convolutional neural network in financial time series forecasting[J]. Journal of Zhengzhou university (natural science edition), 2022, 54(2):81-88.
[27]OROZCO-ARROYAVE J R, VSQUEZ-CORREA J C, VARGAS-BONILLA J F, et al. NeuroSpeech: an open-source software for Parkinson′s speech analysis[J]. Digital signal processing, 2018, 77: 207-221.
[28]JAEGER H, TRIVEDI D, STADTSCHNITZER M. Mobile device voice recordings at King′s college london (MDVR-KCL) from both early and advanced Parkinson′s disease patients and healthy controls[EB/OL]. (2019-05-17)[2022-12-10].https://zenodo.org/records/zenodo.2867216.
