
基于Vision Transformer的车辆重识别模型优化
2025-01-01 00:00:00张震张亚斌田鸿朋
郑州大学学报(理学版) 2025年1期







摘要: 针对车辆重识别任务中样本类内差异性大和类间相似度高的问题,提出了一种Vision Transformer框架下的车辆重识别方法。设计一种关键区域选择模块,整合Transformer中注意力分数矩阵,加强车辆的具有辨别性区域的关注程度,减小局部区域过度集中的注意力权重;构建一种包含对比损失和中心损失的混合损失函数,对比损失函数的引入增强了模型捕捉和比较样本之间的差异的能力,中心损失使得同一类别的样本更加紧密地聚集在一起,增强类间样本的区分度。实验结果验证了其有效性。
关键词: 车辆重识别; 自注意力机制; 注意力权重; 区域选择
中图分类号: TP391.41
文献标志码: A
文章编号: 1671-6841(2025)01-0046-07
DOI: 10.13705/j.issn.1671-6841.2023179
Optimization of Vehicle Re-identification Model Based on Vision Transformer
ZHANG Zhen, ZHANG Yabin, TIAN Hongpeng
(School of Electrical Engineering and Information Engineering, Zhengzhou University, Zhengzhou 450001,
China)
Abstract: A vehicle re-identification method based on the Vision Transformer framework was proposed to address the challenges of large intra-class variations and high inter-class similarities in vehicle re-identification tasks. A key region selection module was designed to integrate attention score matrices from Transformers, enhancing the focus on discriminative regions of vehicles and reducing the excessive attention weights on local regions. A hybrid loss function was constructed, incorporating contrastive loss and center loss. The introduction of contrastive loss enhanced the model′s ability to capture and compare differences between samples, while center loss promoted tighter clustering of samples within the same category, thus improving inter-class sample discrimination. Experimental results validated the effectiveness of the proposed method.
Key words: vehicle re-identification; self-attention mechanism; attention weight; region selection
0引言
近年来,随着人们对智能化设备的需求越来越多,重识别问题受到广泛关注[1]。车辆的重识别任务能解决车辆识别、追踪和定位等多个难题,并提高公安监控系统的安全性和可靠性,成为计算机视觉领域的研究热点。车辆重识别任务被认为是图像检索的子任务,其技术内容主要为判断图像或视频序列中是否存在特定车辆,解决跨摄像机、跨场景下的车辆识别与搜索[2]。
车辆重识别发展可以分为两个阶段。前一阶段是Liu等[3]提出VeRi数据集前,当时缺乏大规模高质量数据集,主要以手动设计和提取特征为主,以各类探测器为辅进行车辆重识别。后一阶段是随着深度学习技术的发展,一些研究者或机构提出了大规模的车辆重识别数据集,并统一了评价指标,基于卷积的模型被广泛应用于车辆重识别任务。
基于卷积的车辆重识别方法[4-7]通常使用三维卷积神经网络来提取视频中的空间和时间特征,然后使用度量学习或注意力机制来增强鉴别性特征。这些研究都以卷积神经网络为核心,引入新的网络结构、注意力机制和局部特征表示。这类方法的优势是可以利用卷积层的局部感知能力来捕捉车辆的细节和纹理信息,以及使用池化层或下采样层来减少计算量和参数量。然而,这类方法也存在一些缺点,如无法充分利用全局信息,以及受卷积和下采样操作导致信息损失。
尽管在车辆重识别任务中,卷积神经网络一直是主流方法,然而近年来Transformer模型作为一种基于自注意力机制的新兴模型,在自然语言处理和计算机视觉领域取得了显著的成功。对于车辆重识别任务而言,Transformer模型具有独特的优势和潜力。首先,Transformer模型能够建模全局关系并捕捉图像中的长距离依赖关系,这对理解车辆的整体结构和特征分布至关重要。其次,Transformer的自注意力机制能够有效地对不同位置的特征进行加权聚合,从而提高车辆特征的判别性和表达能力。此外,Transformer模型的可解释性也为车辆重识别任务提供了便利,通过可视化注意力权重或热力图,研究人员可以更好地理解模型的决策过程和关注的区域。
当前将Transformer应用于研究车辆重识别的论文相对较少。这可能是由于车辆重识别任务的特殊性和挑战性,以及卷积神经网络在该领域的广泛应用和成熟。Yu等[8]提出了一种面向语义的特征耦合Transformer模型,通过约束网络学习更有效的特征,取得了较显著效果,但是大大提高了模型的复杂度。Pan等[9]提出一种逐步混合Transformer模型应对车辆重识别的多模态数据融合和特征学习的挑战,但需要手动设置融合配置,从而限制了不同场景下模型的鲁棒性。Du等[10]设计了一种以Visual Transformer为骨干网络的SIE模块,核心思想是将视角信息整合到位置与图像块向量中,使模型能够学习到不受视角变化影响的特征,由于视角因素在车辆重识别任务中占据的特殊地位,使整个模型的性能得到提升。这些方法都取得了非常好的效果,但对样本间具有辨别性的区域关注度不足,同时也没有考虑模型在图像局部权重过于集中的问题。
Transformer模型的一个限制是它主要依赖于自注意力机制来建模全局信息,往往无法充分捕捉到图像中的局部信息。这在车辆重识别任务中尤为重要,因为样本之间的类内差异性较大、类间相似度高。由于Transformer可能无法准确捕捉到车辆图像中的细微差异,从而导致模型在处理这些任务时表现不佳。
针对以上问题,本文提出一种基于Vision Transformer的车辆重识别模型的优化方法。首先,设计了一种关键区域选择模块,在Vision TransforATpmmpMzS8gHFyhju6K05vURmfbJUJZjydx2RPKJ5DQ=mer模型中利用多头注意力来提取特征,并计算出车辆图像中具有细微差异的关键区域,加强对车辆的具有辨别性区域的关注度;其次,设计了一种混合损失函数,其中的对比损失能够捕捉和比较样本间的差异,而中心损失对类别中心进行约束[11],缩短深层特征与相应类中心在特征空间中的距离;最后,在两个公开的车辆重识别数据集VehicleID和VeRi-776上进行实验,并显示出了其优秀的性能。
1本文方法
本文提出的模型主要包括:1) 序列化与位置编码。位于模型的第一层,该模块将车辆图片转换为一种符合Transformer结构输入的序列化向量信息。2) Transformer编码器。用以学习整张车辆图片的全局特征信息。3) 关键区域选择。能够提取出具有分辨性的区域特征,提升模型区分细微差距的能力。4) 混合损失。在标准Vision Transformer中使用的交叉熵损失基础上,构造了包括对比损失和中心损失的混合损失函数。其结构流程如图1所示。
1.1序列化与位置编码
首先,以不重叠的方式将输入的单张车辆图像X∈RH×W×C按照固定尺寸分割为图像序列xi∈RP×P×C(i=1,2,…,N),其中:H×W为原图像尺寸;C为通道数;P×P和N=HW/P2分别为分割后的图像块尺寸和图像块个数。利用一个可学习线性映射向量
E∈R(P×P×C)×D将图像块序列中的每个元素映射到一个D维特征空间,同时使用一个可学习的分类向量
x∈R1×D作为分类令牌,用以提取目标的全局特征表示。最后,使用一个位置编码信息向量
E∈R(N+1)×D与映射后的图像块序列直接相加,即
Z=(x,
x1E,
x2E,…,xNE)+
E,(1)
作为Transformer的输入序列。
1.2Transformers编码器
Transformer编码器由L个Transformer层堆叠而成,Transformer层的结构包括多头自注意力层(multi-head self attention layer,MSA)[12]、归一化(layer norm,LN)、残差连接(residual connection,RC)和多层感知机(multi-layer perceptron,MLP)。第l层的输出结果为
Z′=
MSA(LN(Z))+Z,l=1,2,…,L,(2)
Z=MLP(LN(Z′))+
Z′,l=1,2,…,L,(3)
其中:Z′和Z分别代表序列特征矩阵经过第l层MSA和MLP后的输出。MSA层的底层逻辑是基于自注意力机制,模仿了生物视觉的显著性检测和选择性注意,弥补了卷积神经网络感受野有限的问题[13]。
输入序列进入每个MSA或MLP层前,都进行归一化处理,经过每个MSA或MLP层后,又使用残差连接与归一化前的输入进行直接融合。MSA层的计算过程为
Q=ZWQ,
K=ZWK,
V=ZWV,
Z=Attention(Q,
K,V),i=1,2,…,k,
MultiHead(Q,K,V)=
Concat(Z,Z,…,
Z)Wo,(4)
其中:Attention(·)为注意力机制的计算操作;Concat(·)为连接操作;MultiHead(·)为拼接多个自注意力头的输出并线性变换操作;k为MSA层注意力的头数;Q、K和
V分别表示查询向量、键值向量和值向量;
Z表示每个注意力头的输出向量;
Wo为输出的投影矩阵;
WQ、WK和
WV为可学习的权重矩阵;
Q、K和V为单头注意力中的
Q、K、V在不同特征子空间下进行的拆分。从多个角度提取特征相关性的同时不增加额外的计算量,并将各个自注意力层提取到的信息合并。
1.3关键区域选择
虽然Transformer运用了自注意力、交叉注意力和位置编码等方法,具备比较强的全局信息交互能力,但对于车辆重识别分类任务中具有较细微但关键区域的关注度并不充分,这可能导致模型在处理需要关注局部特征的任务时表现不佳。因此,本文提出一种关键区域的选择方法。首先重新整合Transformer中注意力分数矩阵,加强对车辆的具有辨别性区域的关注程度。其次,选择性舍弃进入Transformer编码器模块最后一层的部分特征序列输入,降低了局部区域过度集中的注意力权重。
具体来说,首先,第L个Transformer层即Transformer编码器模块最后一层的序列特征输入为
Z=(Z0,
Z1,Z2,…,
ZN)。(5)
其次,MSA层会计算出一个注意力分数矩阵,该矩阵代表序列特征的每个令牌间的相似程度,前L-1的注意力分数矩阵为
A=(a0,
a1,a2,…,
ak),l∈1,2,…,L-1,(6)
ai=(b0,
b1,b2,…,
bN),i∈0,1,…,k,(7)
其中:ai代表第l层计算出的第i个注意力头的分数矩阵;
bj(j=1,2,…,N)代表第i个注意力头的分数矩阵中第j个图像块与分类令牌XSQgMXMq27/LRoUmV6Ms6Q==
x以及N个图像块令牌
xiE间的语义关联性。为整合前L-1层注意力分数矩阵信息,使用矩阵连乘,
A=
∏L-10AAT。(8)
与单层注意力分数矩阵A相比,A能捕捉到信息序列从输入层传播到高层的过程。
最后,从A中选取前k个具有最大表征的位置对应的索引
(A,A,…,A),并使用此索引在
Z中提取对应的令牌,作为新的特征序列替换原信息区域的特征序列,进入最后一层Transformer层的序列特征为
Z=(Z0,
ZA,ZA,…,
ZA)。(9)
在模型的高层,通过这样的关键区域选择模块,在保留了全局信息的同时,使最后一层Transformer层关注了不同子类之间的细微差别。
1.4混合损失函数
首先,标准的Vision Transformer模型使用的交叉熵损失函数可以捕获到比较显著的类间差异,但对类间样本的细微差异的捕获能力不足。由于对比损失使用的是样本对比较的方式,对于相似的样本对,模型在学习过程中会更加关注它们之间的微小差异,计算过程可以表示为
L=1N2
{∑Nj:y=y
[1-cos(Z,Z)]+
∑Nj:y≠y
max{[cos(Z,Z)-α],0}},(10)
其中:N为批大小;Z代表第i个图像经过整个模型后输出的向量;
cos(Z,Z)为
Z与Z的余弦相似度;α是一个超参数,只有余弦相似度大于
α的损失才能对L起作用。
其次,车辆重识别任务的主要挑战在于同一辆车在不同场景下的外观变化较大,例如光照变化、姿态变化、遮挡等,这些因素会导致同一辆车在不同场景下的图像特征发生较大的变化,从而降低识别的准确性。另一方面,Transformer模型的缺陷在于其对于长序列的处理能力较弱,同时其注意力机制可能会受到输入序列中各元素之间相似性的影响,从而影响模型的判别能力。
因此,本文引入中心损失的作用是将局部特征映射到其对应的特征中心,并将同一类别的特征聚集在一起,从而形成该类别的特征中心。通过将同一类别的特征聚集在一起,可以降低不同类别之间的特征相似性,从而增强模型的判别能力。同时,中心损失可以对不同类别之间的特征中心进行正则化,以避免特征中心之间的相似性影响模型的判别能力,计算公式为
L=12
∑Ni=1
‖Z-
C‖2,(11)
其中:y为第i个图像的类别标签;C表示类别y的特征中心。整个模型的损失为
L=L+L+βL,(12)
其中:L为类别块的真实标签与预测标签之间的交叉熵损失;β为超参数。
2实验结果与分析
2.1数据集及评价指标
本文选择在车辆重识别任务中应用较为广泛且关注度较高的两个公开数据集VeRi-776[3]和VehicleID[14],其中VehicleID有三个测试子集,ID数分别为800、1 600和2 400(Test800、Test1 600和Test2 400)。表1为两个数据集的详细信息。
使用mAP(mean average precision)、CMC@1和CMC@5三个评价指标,分别表示平均精度均值、检索结果中排名前1和前5的检索准确率,其中CMC为累计匹配特性(cumulative matching characteristic,CMC)。
2.2实验细节
本文的车辆重识别模型实验的平台为Windows操作系统、AMD Ryzen 7 6800H处理器、16 GB内存,RTX3060显存为6GB,软件环境为cuda12.1、pytorch1.12.1、python3.10.10、cudatoolkit11.3等。
在对图像的预处理部分,将所有车辆图像的像素调整为256×256,所有的训练图像都进行随机水平翻转、裁剪,实现图像的增强。Vision Transformer模型采用12层的Transformer架构,多头自注意力层的头数也为12,图像块的像素大小为16×16,再加上一个可学习的分类向量,此时图像块序列的向量维度为257×768。模型的训练阶段,采用经过加载ImageNet的预训练模型配置文件vit_base_patch16_224进行微调,总损失中中心损失的权重参数β设置为0.0005,更新模型参数的优化算法为随机梯度下降法(stochastic gradient descent,SGD),动量(momentum)为0.9,batch size设置为24,epochs为100,权重衰减(weight decay)设置为0.0001,学习率初始化为0.008,使用余弦退火(cosine annealing)动态调整学习率的变化模式。
2.3消融实验
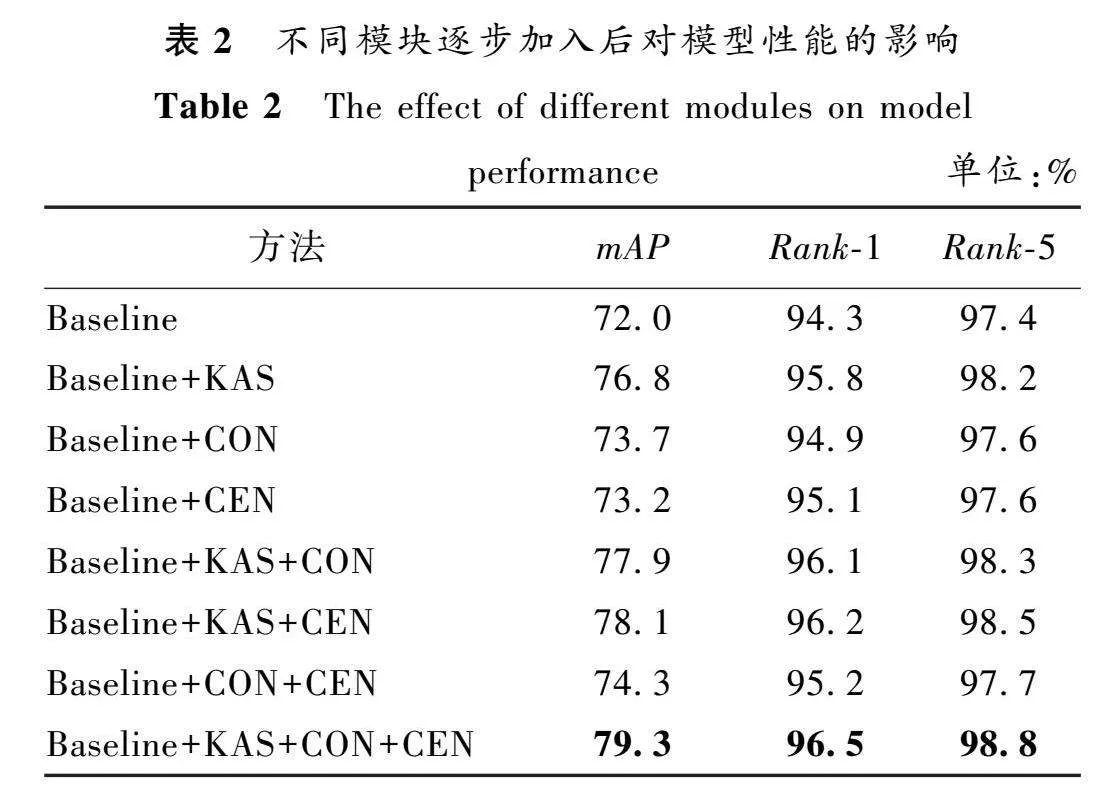
为了验证本文所提模型各个部分的有效性,以及比较网络中不同模块对整个模型的贡献,本文在以Vision Transformer作为主框架的基础上,逐步加入各改进模块在VeRi-776数据集上展开消融实验,实验结果如表2所示(黑体数据为最优值)。其中,第一行是本文的基准,基于原Vision Transformer模型,KAS(key area selection module)表示关键区域选择模块,CON(contrastive loss)表示在原来的交叉熵损失函数中引入对比损失,CEN(center loss)表示在原来的交叉熵损失函数中引入中心损失。
从表2第一行与第二行可以看出,在加入关键区域选择模块后,与原始的基准相比,mAP、Rank-1和Rank-5指标分别提高了4.8%、1.5%和0.8%;从表2第三行与第五行可以看出,基于使用交叉熵损失和对比损失的融合损失后引入关键区域选择模块,其mAP、Rank-1和Rank-5指标分别提高了4.2%、
1.2%和0.7%;从表2第四行与第六行可以看出,在使用交叉熵损失和中心损失的基础上,引入关键区域选择模块,其mAP、Rank-1和Rank-5指标分别提升了4.9%、1.1%和0.9%。这些结果都证明了关键区域辨别模块对本文提出的基于Vision Transformer的有效性。
同时可以看到在Rank-1指标上,关键区域选择模块的引入让使用了对比损失的模型比使用了中心损失的模型效果更好,而在其他两个指标上更差。主要的原因是在进行车辆图像检索时,对比损失的模型能够在捕捉和比较样本之间的差异上更有优势,而中心损失使得同一类别的样本更加紧密地聚集在一起,对类间相似性的处理结果会更好。
从表2的第一行与第三行、第四行可以看出,在单独引入对比损失与中心损失后,与原始的基准相比,mAP、Rank-1和Rank-5分别提升了1.7%、0.6%和0.2%,以及1.2%、0.8%和0.2%;从表2的第三行、第四行与第七行可以看出,使用混合损失函数比单独加入对比损失或者中心损失在指标上均有提升,证明了本文所提出的混合损失函数的合理性与有效性。
2.4对比实验
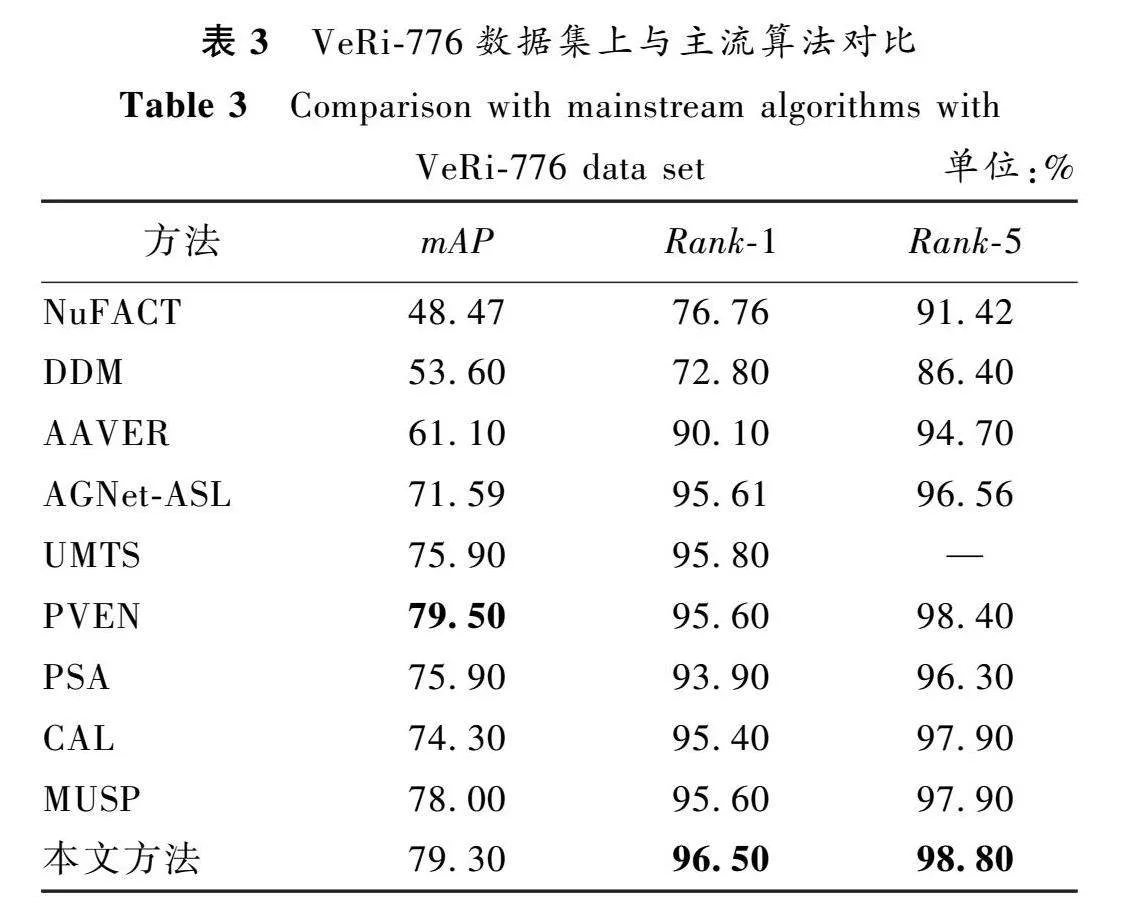
为验证本文所提模型的有效性和优势,与多种主流算法分别在VeRi-776和VehicleID数据集上进行了对比实验,选择的对比算法包括NuFACT[15]、DDM[16]、AAVER[17]、AGNet-ASL[18]、UMTS[19]、PVEN[20]、PSA[21]、CAL[22]、MUSP[23]。算法的对比结果如表3、表4所示(黑体数据为最优值)。
从表3可以看出,本文算法在VeRi-776数据集上的mAP、Rank-1、Rank-5分别达到了79.30%、96.50%和98.80%,除mAP值略低于PVEN的mAP值0.2%外,其他指标均超过了其余优秀算法。在Rank-1指标上,相比该指标性能最高的对比算法UMTS高出0.7%,在Rank-5指标上,相比该指标性能最高的对比算法高出0.4%。表4为各算法在VehicleID的三个测试子集上的结果。Test800的Rank-5和Test1 600的Rank-1指标上,本文算法略低于MUSP算法0.1%,可能的原因是VehicleID样本的分布存在差异,而MUSP中的降噪手段使Test800和Test1 600包含了该方法更擅长处理的特定场景。除此之外,其他指标均取得了最好的结果。
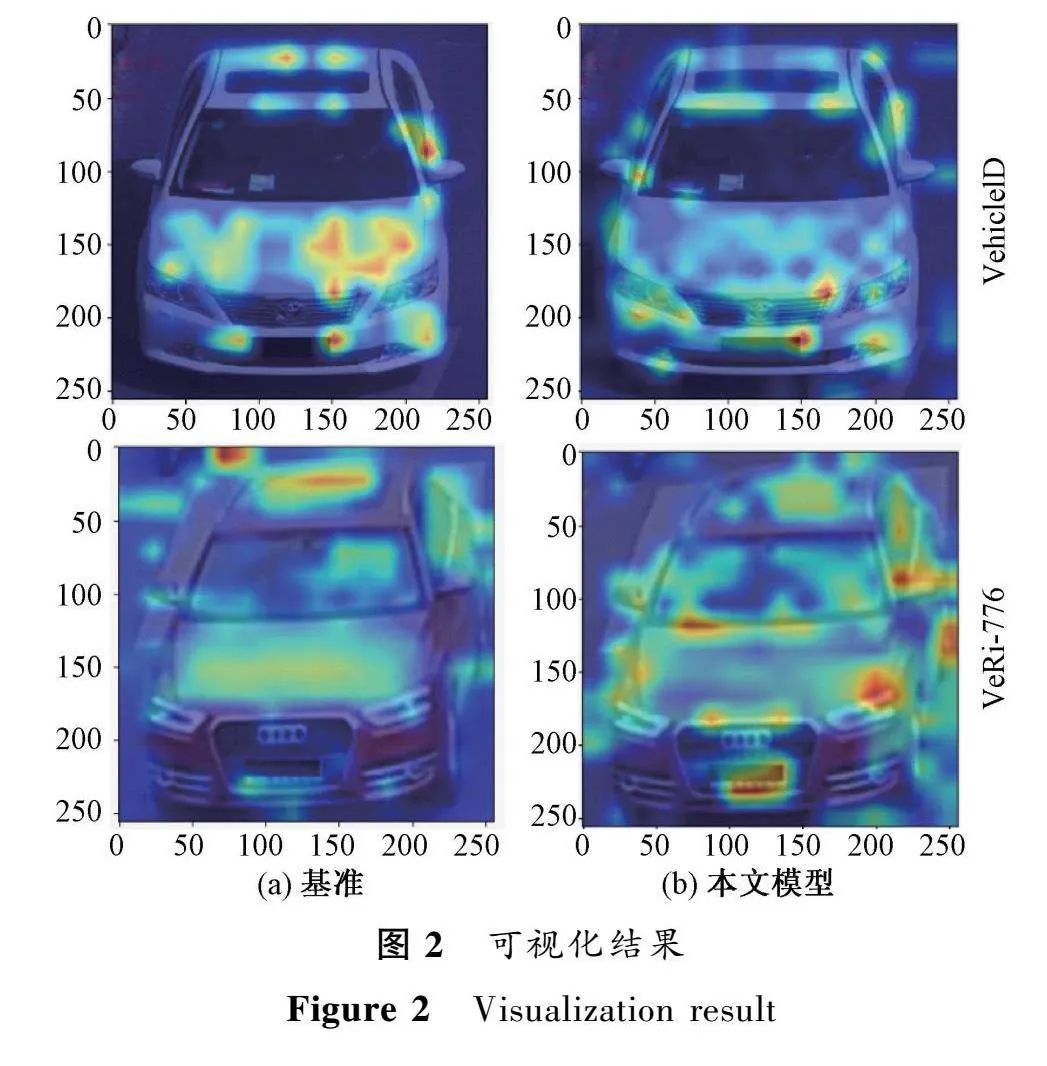
2.5可视化分析
对本文所提模型和基准进行可视化,使用Grad-CAM[24]方法来获取训练后的模型对输入车辆图像的热力图,如图2所示。输入的两张原图均调整像素尺寸为256×256,其中上方与下方的两张车辆图片分别来源于VehicleID和VeRi-776数据集,图片左边和右边分别代表基准与本文所提模型的注意力权重在车辆图像上的分布情况。可以看到,与基准相比,本文所提出的关键区域选择模块加强了对车辆的车窗周围和轮胎附近具有细微差异区域的关注度,同时减小了原模型对某一局部区域过分集中的注意力权重,从而在一定程度上解决了基准在某些训练数据集上容易学习到一些过拟合的特征,导致其泛化能力弱的问题。
3结论
本文提出了一种基于Vision Transformer的车辆重识别模型的优化方法。首先,通过设计一种关键区域选择模块,使模型在最后一层编码器前整合前L-1层注意力分数矩阵,捕捉信息序列从输入层传播到高层的过程,加强对车辆的具有辨别性区域的关注程度,同时减小了局部区域过度集中的注意力权重;其次,为促进整个网络的优化,设计了一个混合损失函数,进一步增强模型捕捉样本差异的能力;最后,在VeRi-776和VehicleID数据集上的实验结果表明,本文模型相较于其他主流算法,有着更好的综合性能。然而,本文的方法也不可避免存在一些需要改进之处,如何引入额外的视角信息并优化车辆重识别模型的决策部分是下一步工作的方向。
参考文献:
[1]张正, 陈成, 肖迪. 基于图像语义分割的车辆重识别[J]. 计算机工程与设计, 2022, 43(10): 2897-2903.
ZHANG Z, CHEN C, XIAO D. Vehicle re-identification based on image semantic segmentation[J]. Computer engineering and design, 2022, 43(10): 2897-2903.
[2]张富凯. 基于城市视频监控图像的车辆重识别关键技术研究[D]. 北京: 中国矿业大学(北京), 2020.
ZHANG F K. Research on Key Technologies of Vehicle re-Identification Based on Urban Video Surveillance Images[D]. Beijing: China University of Mining & Technology, Beijing, 2020.
[3]LIU X C, LIU W, MA H D, et al. Large-scale vehicle re-identification in urban surveillance videos[EB/OL].(2016-08-29)[2023-05-30]. https:∥ieeexplore.ieee.org/document/7553002.
[4]LIU Y C, HU H F, CHEN D H. Attentive part-based alignment network for vehicle re-identification[J]. Electronics, 2022, 11(10): 1617.
[5]SONG L P, ZHOU X, CHEN Y Y. Global attention-assisted representation learning for vehicle re-identification[J]. Signal, image and video processing, 2022, 16(3): 807-815.
[6]ZHENG Z D, RUAN T, WEI Y C, et al. VehicleNet: learning robust visual representation for vehicle re-identification[J]. IEEE transactions on multimedia, 2020, 23: 2683-2693.
[7]WANG Y F, GONG B H, WEI Y, et al. Video-based vehicle re-identification via channel decomposition saliency region network[J]. Applied intelligence, 2022, 52(11): 12609-12629.
[8]YU Z, HUANG Z Y, PEI J M, et al. Semantic-oriented feature coupling transformer for vehicle re-identification in intelligent transportation system[EB/OL].(2023-03-24)[2023-05-30]. https:∥ieeexplore.ieee.org/document/10081216.
[9]PAN W J, HUANG L H, LIANG J B, et al. Progressively hybrid transformer for multi-modal vehicle re-identification[J]. Sensors, 2023, 23(9): 4206.
[10]DU L S, HUANG K L, YAN H. ViT-ReID: a vehicle re-identification method using visual transformer[C]∥2023 3rd International Conference on Neural Networks, Information and Communication Engineering. Piscataway: IEEE Press, 2023: 287-290.
[11]YU Z, ZHU M P. Efficient but lightweight network for vehicle re-identification with center-constraint loss[J]. Neural computing and applications, 2022, 34(15): 12373-12384.
[12]李佳盈, 蒋文婷, 杨林, 等. 基于ViT的细粒度图像分类[J]. 计算机工程与设计, 2023, 44(3): 916-921.
LI J Y, JIANG W T, YANG L, et al. Fine-grained visual classification based on vision transformer[J]. Computer engineering and design, 2023, 44(3): 916-921.
[13]李清格, 杨小冈, 卢瑞涛, 等. 计算机视觉中的Transformer发展综述[J]. 小型微型计算机系统, 2023, 44(4): 850-861.
LI Q G, YANG X G, LU R T, et al. Transformer in computer vision: a survey[J]. Journal of Chinese computer systems, 2023, 44(4): 850-861.
[14]LIU H Y, TIAN Y H, WANG Y W, et al. Deep relative distance learning: tell the difference between similar vehicles[C]∥2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE Press, 2016: 2167-2175.
[15]LIU X C, LIU W, MEI T, et al. PROVID: progressive and multimodal vehicle reidentification for large-scale urban surveillance[J]. IEEE transactions on multimedia, 2018, 20(3): 645-658.
[16]HUANG Y, LIANG B R, XIE W P, et al. Dual domain multi-task model for vehicle re-identification[J]. IEEE transactions on intelligent transportation systems, 2022, 23(4): 2991-2999.
[17]KHORRAMSHAHI P, KUMAR A, PERI N, et al. A dual-path model with adaptive attention for vehicle re-identification[C]∥2019 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway: IEEE Press, 2019: 6131-6140.
[18]WANG H B, PENG J J, CHEN D Y, et al. Attribute-guided feature learning network for vehicle reidentification[J]. IEEE MultiMedia, 2020, 27(4): 112-121.
[19]Jin X, Lan C L, Zeng W J, et al. Uncertainty-Aware Multi-Shot Knowledge Distillation for Image-Based Object Re-Identification[C]∥34th AAAI Conference on Artificial Intelligence/32nd Innovative Applications of Artificial Intelligence Conference/10th AAAI Symposium on Educational Advances in Artificial Intelligence. Palo Alto: AAAI Press, 2020: 11165-11172.
[20]MENG D C, LI L, LIU X J, et al. Parsing-based view-aware embedding network for vehicle re-identification[C]∥2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 7101-7110.
[21]YANG J, XING D, HU Z, et al. A two-branch network with pyramid-based local and spatial attention global feature learning for vehicle re-identification[J]. CAAI transactions on intelligence technology, 2021(1): 46-54.
[22]RAO Y M, CHEN G Y, LU J W, et al. Counterfactual attention learning for fine-grained visual categorization and re-identification[C]∥2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE Press, 2021: 1005-1014.
[23]LEE S, WOO T, LEE S H. Multi-attention-based soft partition network for vehicle re-identification[J]. Journal of computational design and engineering, 2023, 10(2): 488-502.
[24]SELVARAJU R R, COGSWELL M, DAS A, et al. Grad-CAM: visual explanations from deep networks via gradient-based localization[J]. International journal of computer vision, 2020, 128(2): 336-359.
