
基于YOLOv8s的道路坑洼检测技术研究
2024-12-31 00:00:00罗伟解威威侯凯卢鹏欧晨丰
西部交通科技 2024年11期





摘要:文章从YOLO的部署、数据集的构建、模型的训练到模型的应用全过程,研究了基于YOLOv8s目标检测算法的道路坑洼检测技术在城市道路坑洼检测中的应用,以实现对道路的各种类型和尺寸坑洼的准确检测。实验结果表明,该技术在准确性、速度和稳定性方面都具有显著优势,与传统人工方法相比,检测效果明显提升,为道路维护和安全提供了更为可靠和高效的解决方案。
关键词:目标检测;YOLOv8s;道路检测;深度学习
中图分类号:U495" " " "文献标识码:A" " " DOI:10.13282/j.cnki.wccst.2024.11.009
文章编号:1673-4874(2024)11-0028-03
引言
道路病害对经济发展和通行安全的影响应得到广泛关注,道路病害的及早发现与治理可以提升道路使用寿命[1-4]。同时,道路坑洼对行车安全有直接而重要的影响。坑洼可能导致车辆失去稳定性,增加交通事故的风险,尤其是在高速行驶时更为危险;坑洼还会损坏车辆悬挂系统和轮胎,增加车辆维护成本,甚至可能导致严重的机械故障。此外,驾驶员为了避免坑洼往往需要进行突然的转向或刹车动作,这增加了驾驶员的疲劳和应激,降低了行车的舒适性和安全性。因此,针对早期裂缝进行及时有效的维护,对后续道路养护工作及行车安全等方面具有重要意义[5-7]。传统人工路面检测效率低、成本高,且有一定的危险性,而YOLO作为新兴的目标检测技术[8-10],相比人工检测,YOLO算法具有显著的优势。其速度快,能够实时进行图像检测,减少了人力成本和时间开销;具有自动化的特点,不需要人为干预,减少了主观因素的影响,提高了检测的一致性和可靠性;此外,YOLO具有良好的扩展性和适应性,可以应用于各种不同场景,并且能够通过大规模数据集学习到各种目标的特征,具有更好的泛化能力。
1YOLOv8目标检测算法
YOLOv8是一种目标检测模型,其设计由三个关键部分组成:骨干网络(Backbone)、颈部(Neck)和检测头(Head)。
骨干网络部分,主要进行特征信息的提取工作,相比于YOLOv5,YOLOv8使用全新的C2f结构替换了C3结构,可以提取不同尺度的特征信息。
颈部部分,主要负责特征融合工作,同样使用了C2f模块替换C3模块,并采用了PAN-FPN的思想,实现了自上而下和自下而上的特征金字塔。与此同时,去除了上采样前的1×1卷积,直接对不同阶段输出的特征进行上采样操作。
检测头部分,与YOLOv5相比,采用了Anchor-Free的解耦头结构,将分类和回归分开,不再依赖先验的锚框。此外,还使用了DFL(Distribution Focal Loss)的回归分支,取代了传统的Focal Loss,以更好地处理类别不平衡和难易样本的问题。
2试验测试
2.1YOLOv8的环境搭建
本文试验在Windows10的PyCharm平台上实现。需要安装PyTorch,PyTorch是一个开源的机器学习框架,主要用于构建深度学习模型,YOLO可以在PyTorch框架中实现和部署。接着下载YOLOv8的源码,进行pip源码安装。
2.2构建用于模型训练的数据集
本文采用的数据集来自RDD(Road Damage Detector)2022版本。RDD是一个用于道路损害检测的数据集,旨在支持计算机视觉领域中相关研究和应用的发展。该数据集包含了大量的道路图像以及与之对应的标注信息,用于训练和评估道路损害检测算法,其中图像为JPG存储格式,图像分辨率为720 dpi×720 dpi。由于RDD的标注文件格式与YOLO要求的标注文件格式不符,本文选择重新对道路图像中的坑洼进行标注,步骤如下:
(1)进入数据集标注网站,上传包含坑洼的道路图像。
(2)新建标签,由于本文只对道路坑洼进行训练和检测,这里只创建一个名为pothole的标签。
(3)[JP3]选取目标,框出道路图像上的坑洼,网站会自动生成该图像的标注文件,框选过程和坑洼类型如图1所示。
(4)导出标注文件,makesence网站支持导出适合YOLO框架的标注文件,最后得到和图像文件名一样的txt格式的标注文件。
2.3训练道路坑洼检测模型
本文标注了150幅包含坑洼的道路图像,将其中88幅作为训练集,用于训练模型参数;43幅作为验证集,用于调整超参数和模型结构;19幅作为测试集,用于评估模型的性能和泛化能力。试验的CPU型号为AMD Ryzen 5600x,GPU型号为NVIDIA GeForce GTX 1080ti,内存16 g。CUDA版本为11.6,编程语言为Python。
网络训练参数设置如下:选择YOLOv8s版本,总迭代次数为300次,每次输入模型的图像数量(batch size)为32,初始学习率(Learning Rate)为0.01,学习率动量(Learning Rate Momentum)为0.95,权重衰减系数(Weight Attenuation Coefficient)为0.000 5。
2.4测试训练后的检测模型
模型训练结束后得到.pt格式的模型文件,利用该模型文件,对测试集上的道路图像进行坑洼检测,对模型的输出结果进行后处理操作,如过滤掉置信度低的边界框、非极大值抑制(NMS)等。
3实验结果分析
3.1训练结果分析
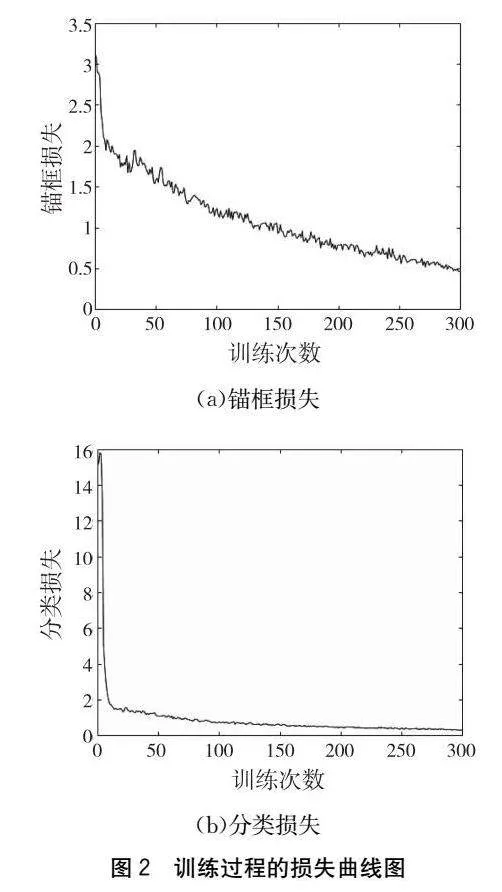
观察图2,发现随着训练次数增加,锚框损失率和分类损失率不断减小,[JP]这是因为模型在训练过程中逐渐学
习到了更好的特征表示和参数调整,随着迭代次数的增加,模型会不断地调整权重和参数,以最小化训练数据的损失函数。损失曲线随着迭代次数的增多而减小,表明模型训练正在有效进行,并且模型在学习过程中逐渐提高了对目标的检测能力。
进一步观察图2发现,分类损失曲线在训练中后期已经接近水平,锚框损失曲线也趋于平稳,当损失曲线接近水平时,通常表明模型的训练已经收敛到一个稳定的状态。这表明模型已经学习到了数据的特征,并且在当前参数设置下,进一步训练只会造成时间和计算成本的损失,即意味着模型已经能够准确地对目标进行分类和定位。
3.2测试结果分析
测试结果选取部分展示如图3所示。观察图3,可以发现模型准确地定位和识别出了道路图像上的坑洼。
为了定量评估模型的准确性,引入如下指标,包括精确率(Precision)和召回率(Recall),公式如下:
P=TPTP+FP(1)
R=TPTP+FN(2)
式中:P——精确率;
R——召回率;
TP、FP、FN——真正例、假正例和假负例,其对应了混淆矩阵中的三种情况。真正例即为判断正确的预测框,假正例即为类别预测错误的误判,假负例即应检但未能检测出的漏判。
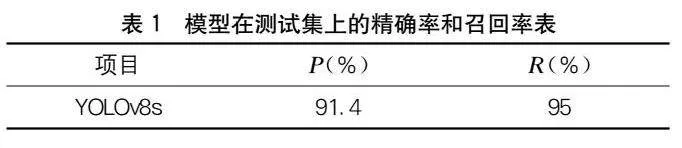
精确率是指模型检测到的物体中真正被正确检测到的比例,召回率是指真正被检测到的物体与总共需要检测到的物体的比例。测试集中包含22处坑洼,模型检测到21处真正例、2处误判、1处漏检。精确率和召回率如表1所示。
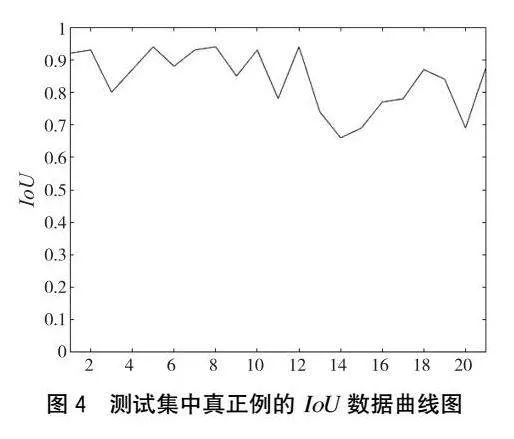
下页图4展示了测试集上21处真正例的IoU(Intersection over Union)数据,IoU是模型检测结果的重叠度量,表示模型检测到的目标区域与实际目标区域之间的重叠程度,IoU越接近1,表示模型检测的准确性越高。
4模拟雾天环境检测图
4.1模型雾天环境
雾天影响行车安全,为了模拟雾天导致的视野不清晰,本文采用标准光学模型[11]来模拟雾气。标准光学模型是基于光线与水滴或悬浮微粒之间相互作用的理论框架,用于模拟雾气效果。在这个模型中,当光线穿过含有水滴或微粒的大气时会发生散射和吸收现象。散射使光线的传播路径发生偏转,而吸收则减弱了光线的强度。这些过程导致了在雾气中看到物体时的模糊效果,远处物体的轮廓变得不清晰。通过调整散射和吸收参数,可以控制雾气的密度和强度,进而模拟不同条件下的雾气效果,使图像更加真实和逼真。对测试集的图像添加雾气,部分模拟结果如图5所示。
4.2雾天环境下的检测
在对测试集的图像增加雾气模拟后,再次用本文训练后的坑洼检测模型进行检测,以测试模型抗雾天环境干扰的鲁棒性。部分结果如图6所示,可以发现,即使有一定的雾气存在,YOLOv8s训练的模型依然能准确检测出坑洼。
5结语
本文提出的基于YOLOv8s的道路坑洼检测方法在实验中展现了出色的性能。通过构建适用于道路坑洼检测的数据集,并利用YOLOv8s进行训练,本文实现了对道路中各种类型和尺寸的坑洼的准确检测,并模拟了雾天环境下的坑洼检测。试验结果表明,本文的方法在准确性、速度和稳定性方面都具有显著优势。与传统人工方法相比,检测效果明显提升,为道路维护和安全提供了更为可靠和高效的解决方案。
参考文献:
[1]Asher S,Novosad P.Rural roads and local economic development[J].American economic review,2020,110(3):797-823.
[2]De Soyres F,Mulabdic A,Murray S,et al.How much will the Belt and Road Initiative reduce tradecosts[J].International Economics,2019(159):151-164.
[3]Chen S,Kuhn M,Prettner K,et al.The global macroeconomic burden of road injuries:estimates andprojections for 166 countries[J].The Lancet Planetary Health,2019,3(9):390-398.
[4]牛为华,殷苗苗.基于改进YOLOv5的道路小目标检测算法[J].传感技术学报,2023,36(1):36-44.
[5]王钲棋,邵洁.基于先验显著性信息的道路场景目标检测[J].计算机工程与应用,2023,59(21):251-257.
[6]郭克友,王苏东,李雪,等.基于Dim env-YOLO算法的昏暗场景车辆多目标检测[J].计算机工程,2023,49(3):312-320.
[7]岳晓新,贾君霞,陈喜东,等.改进YOLOv3的道路小目标检测[J].计算机工程与应用,2020,56(21):218-223.
[8]Bochkovskiy A,Wang C Y,Liao H Y M.YOLOv4:Optimal Speed and Accuracy of Object Detection[J].Computer Science,2020(4):216080778.
[9]Redmon J,Farhadi A.YOLOv3:An Incremental Improvement[J].arXiv e-prints,2018(4):180402767.
[10]Redmon J,Farhadi A.YOLO9000:better,faster,stronger[C].Proceediof the IEEE Conference on Computer Vision and Pattern Recognition,2017.
[11]汪昱东,郭继昌,王天保.一种改进的雾天图像行人和车辆检测算法[J].西安电子科技大学学报,2020,47(4):70-77.
作者简介:罗伟(1988—)硕士,工程师,主要从事公路工程信息化研究工作。
收稿日期:2024-05-16
猜你喜欢
软件(2016年4期)2017-01-20 09:38:03
科教导刊·电子版(2016年28期)2017-01-10 22:25:23
江苏教育·中学教学版(2016年11期)2016-12-21 11:36:29
现代情报(2016年10期)2016-12-15 11:50:53
新教育时代·教师版(2016年23期)2016-12-06 06:02:38
法制与社会(2016年32期)2016-12-01 15:25:53
软件导刊(2016年9期)2016-11-07 22:20:49
软件工程(2016年8期)2016-10-25 15:47:34
科学与财富(2016年28期)2016-10-14 23:45:18
电脑知识与技术(2016年5期)2016-04-14 13:48:16
