
基于改进YOLOv8的路口多目标识别优化方法
2024-12-31 00:00:00唐继杰欧晓放
科技创新与应用 2024年35期







摘" 要:针对我国城市路口多目标识别效率不高,识别不够精准的问题,该文提出一种基于改进YOLOv8s模型的检测方法。对原始的YOLOv8s模型进行改进,增加了卷积分支,采用融合Diverse Branch Block模块的特征提取方式。结合城市路口场景构建数据集,实验结果表明,改进模型在精确度、召回率和平均准确度的指标上较原模型分别提升4.2%、3.1%和3.08%。改进模型表现出良好的性能,能够满足实际城市路口的多目标检测需求。
关键词:多目标检测;深度学习;YOLOv8;交通安全;优化方法
中图分类号:TP391.4" " " 文献标志码:A" " " " " "文章编号:2095-2945(2024)35-0059-06
Abstract: In view of the problem that the efficiency of multi-target recognition at urban intersections in China is not high and the recognition is not accurate enough. This paper proposes a detection method based on the improved YOLOv8s model. The original YOLOv8s model is improved, convolution branches are added, and feature extraction methods that incorporate the Diverse Branch Block module are adopted. Combining urban intersection scenarios to build a dataset, experimental results show that the improved model improves accuracy, recall rate and average accuracy by 4.2%, 3.1% and 3.08% respectively compared with the original model. The improved model shows good performance and can meet the multi-target detection needs of actual urban intersections.
Keywords: multi-target detection; deep learning; YOLOv8; traffic safety; optimization method
近年来,为了预防道路交通事故,公安部相关部门积极推进“减量控大”工作,强调“努力减少事故死亡总量,全力防控较大事故”[1]。在此背景下,交通安全研究的重点逐渐从事后分析转向事前预防。为了有效降低事故发生率,预先识别潜在危险因素成为关键。目标检测技术是智能交通领域的重要内容,通过高效、准确地识别交通环境中的各种潜在危险,可以为交通的研究和管理提供关键数据支持[2],从而实现事故“减量控大”的目标。
目标检测技术为交通事故主动预防提供了技术支撑。在深度学习的目标检测领域中,主流的方法分为两类:双阶段方法和单阶段方法。2016年,Ren等[3]引入了区域卷积神经网络(Region Proposal Network, RPN),通过与目标检测网络共享卷积特征,实现了高效、快速的目标检测。随后,为了解决Faster R-CNN 中像素对齐的问题,He等[4]对Faster R-CNN进行扩展,提出了一个兼顾目标检测实现和实例分割的Mask R-CNN。然而,不同于传统的基于回归的方法,Lu等[5]提出的Grid R-CNN模型通过网格点的定位来捕捉空间信息,与Faster R-CNN相比,Grid R-CNN设计了信息融合策略,将相邻网格点的特征进行融合,增强了定位的准确性。与之前的基于区域的检测器不同,Dai等[6]提出了基于区域的全卷积网络,模型的大部分计算都在整个图像上共享,从而降低了计算成本。除此之外,Singh等[7]通过将目标检测和分类分离,提出了R-FCN-3000模型,利用共享特征和通用目标性来实现高效的目标检测。与之相反,单阶段的目标检测算法在检测流程和处理方式上追求一步到位和密集预测。由于省去了候选区域生成的步骤,直接在特征图上进行密集预测,因此,单阶段目标检测方法具有更高的检测速度,适合实时应用。Redmon[8]在2016年提出了第一个成功的单阶段目标检测器。它的核心理念是将目标检测视为一个回归问题,将整个图像划分为S×S网格,每个网格预测固定数量的边界框以及它们的类别。同年,Liu等[9]提出了SSD(Single Shot MultiBox Detector)单阶段算法,SSD 将目标检测任务视为一个回归问题,并通过一个单一的深度神经网络直接对目标类别和边界框进行预测。该方法不需要生成候选区域,也不需要重新采样像素或特征图,实现了更快的检测速度。随着YOLO系列的不断发展,Liu等[10-11]在YOLOv5模型的基础上,使用 K-means算法为数据集计算最合适的锚框(anchor boxes),以提高边界框检测的准确性。Wang等[12]提出了YOLOv7模型,通过引入一系列可训练的优化模块和方法,在不增加推理成本的情况下显著提高了检测精度。相比于YOLOv7,YOLOv8模型对锚框的尺寸和比例进行自适应优化,使得预测的边界框能够更好地适应目标的形状和大小[13]。减少了边界框与目标真实位置之间的偏差,提高了模型定位的准确性。同时,YOLOv8使用了更先进的IoU损失函数(如CIoU、DIoU)来优化边界框的回归[14]。
尽管YOLOv8模型在许多方面表现出色,但在处理复杂背景下的多目标检测任务时,还存在一定的局限性。以上提到的研究大多只针对某一类目标进行检测,对于城市路口复杂背景下的多目标检测应用较少。因此,本文在YOLOv8s算法的基础上,增加了额外的卷积分支,采用结合了Diverse Branch Block模块的特征提取方式,以提高模型对路口监控视频下多目标的检测精度、速度与结果的可靠性。
1" YOLOv8s模型框架
YOLO系列算法自2016年被Redmon等[6]首次提出后,短短几年时间便从YOLOv1发展到YOLOv8,由于其速度快、实时性好并且兼顾较高的准确率,在目标检测领域占据了主导地位。
该模型由4个主要部分组成:输入端、主干网络、颈部网络以及输出端,图1为YOLOv8s的网络结构示意图。
输入端:这一部分的主要任务是对输入图像进行预处理。输入端将图像调整为固定尺寸(通常为 640×640或其他合适的尺寸)以适应网络的输入大小。图像预处理还包括归一化和数据增强操作,如缩放、翻转、裁剪等,以提高模型的泛化能力。相比于YOLO系列的前几代,YOLOv8使用了改进的Focus模块,通过切片和拼接操作将输入图像的空间信息集中到更深的特征中,从而减少特征丢失。
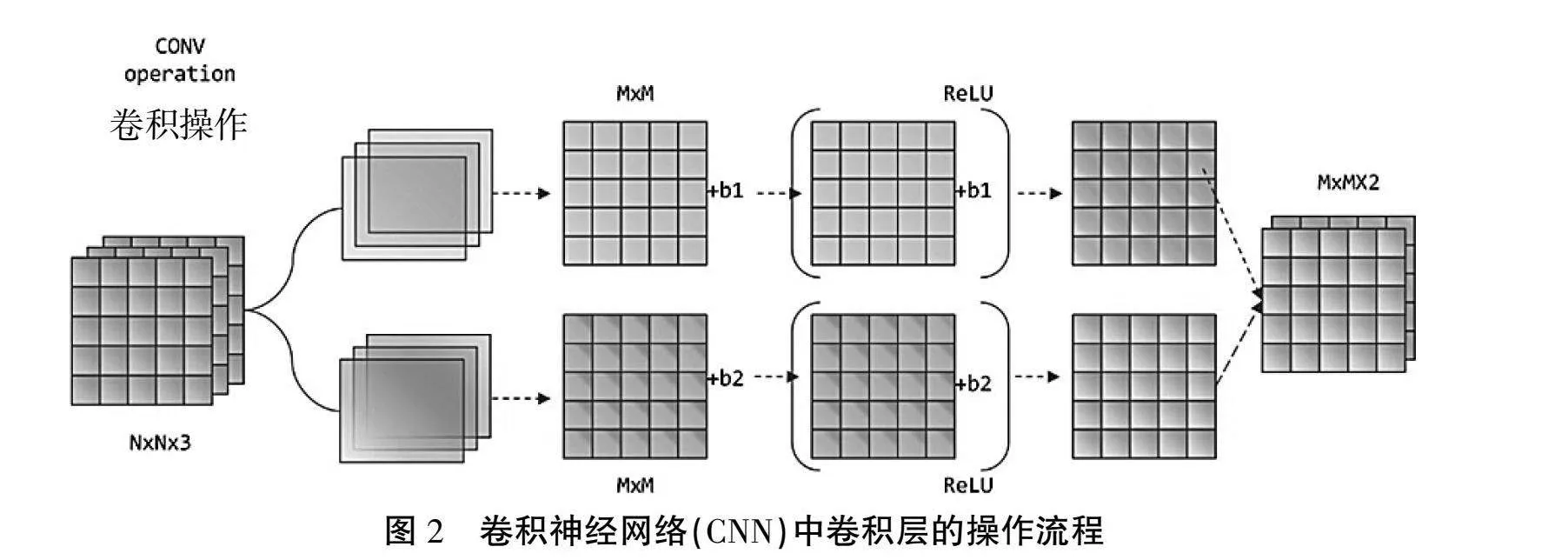
主干网络(Backbone):这一部分主要作用是特征提取。YOLOv8s主干网络采用了改进的CSP结构。CSP通过分离特征图划分为两部分并在后续阶段进行融合,实现了跨阶段连接,增强了网络的特征表达能力并减少了计算成本。如图2所示,在主干网络中,卷积操作是特征提取的核心。通过一系列卷积操作,主干网络可以将输入图像转换为一组多尺度的特征图,这些特征图包含了丰富的信息,为后续的目标检测过程提供了基础。
颈部网络(Neck):在YOLOv8s中,颈部网络主要采用了FPN(Feature Pyramid Network)和PANet(Path Aggregation Network)结构来进行多尺度特征融合。通过自顶向下和自下向上的路径,将不同尺度的特征图进行融合和传递,使得每一层特征图都包含来自其他层的上下文信息。这样,模型在预测时可以利用更丰富的特征,提高检测的鲁棒性。
输出端(Head):这个部分是目标检测模型的最后一环,它将网络提取的特征转换为人类可解释的输出。输出端利用颈部网络提供的多尺度特征图,执行具体的检测任务,并生成检测结果,包括目标的位置(边界框)、类别(分类)以及置信度(目标存在的概率)。
2" YOLOv8s模型的改进与优化
2.1" 多目标检测改进
在城市道路交叉口监控图像中往往会出现大量的交通参与者,基于深度学习的检测算法在处理多目标时检测效果不太理想,因此针对YOLOv8s模型进行优化,提升模型在路口多目标检测上的性能。
如图3所示,本文加入了额外的卷积操作路径(Extra)以丰富特征提取。通过多路径处理、特征融合和额外路径的使用,这个模块可以更好地提取多尺度、多方向的特征,从而增强模型的表达能力和对复杂图像的理解。
2.2" 融合Diverse Branch Block
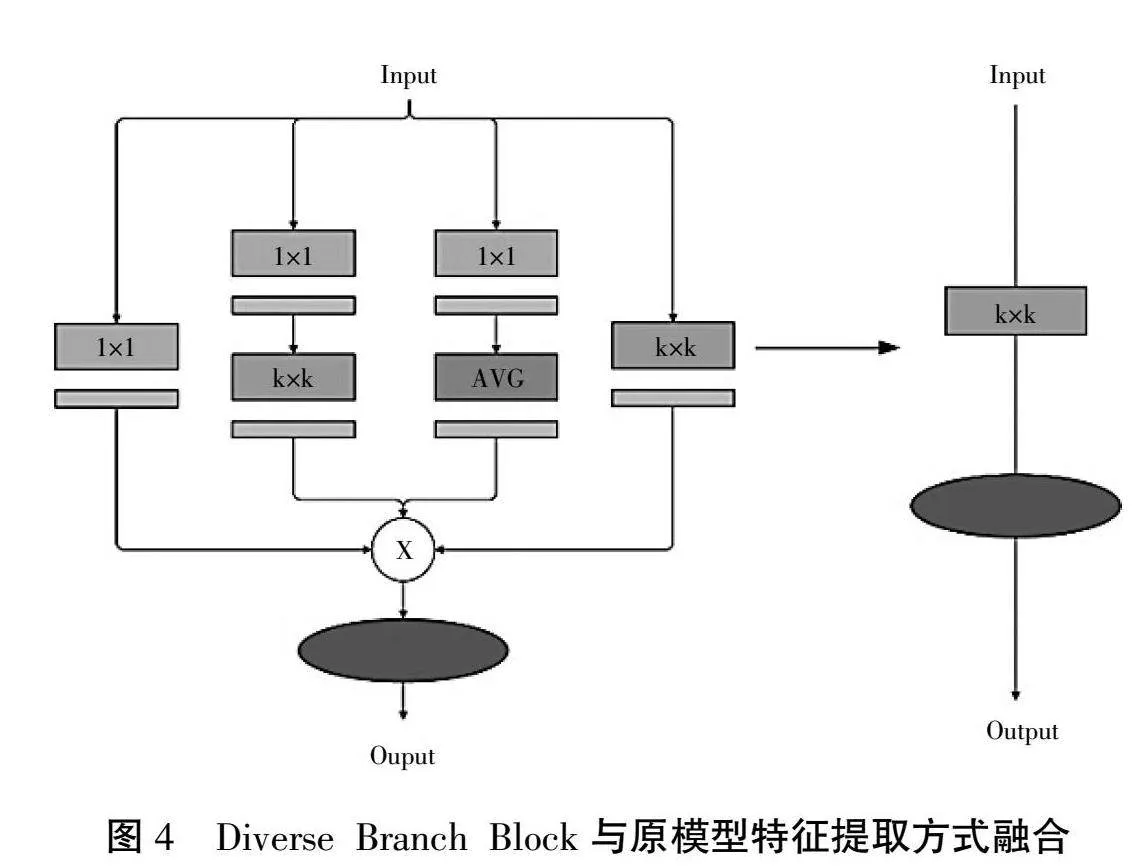
DBB(Diverse Branch Block)是一种神经网络模块,通过复杂化特征提取方式来增强卷积神经网络(CNN)的表达能力。DBB模块引入多种不同的卷积和池化操作,提供了多样化的特征提取路径,并在网络训练和推理过程中灵活地融合这些特征。
如图4所示,DBB模块通过在一个模块内整合多种特征提取方式,显著增加了网络的表达能力,使其可以适应更加复杂的模式和输入数据。同时,多分支结构可以在训练中提供更丰富的梯度流,从而加速模型的收敛。并且在推理阶段,DBB 模块可以被等效为单一卷积操作,从而提高推理效率。
3" 实验结果与分析
3.1" 实验数据集
为了使实验结果能真实反映模型在实际道路交通场景下的表现,本文采用某城市道路监控视频来构建数据集。如表1所示,本文从3个路口6段视频中截取了共计13 884张图像,并用人工标注的方式对数据集进行标注。其中,为了更好地提升模型对非机动车的检测精度,在训练过程中将非机动车分为电动自行车和电动三轮车两类,单独标注分开训练。
3.2" 实验环境
本文实验环境配置见表2,改进的模型训练过程中参数的设置情况如下:迭代次数设置为300 epochs,每轮batch为32张,输入图像的大小为640×640。
3.3" 评价指标
本文采用准确率(precision, P)、召回率(recall, R)、平均精度(average precision, AP)、平均精确度(mean average precision, mAP)、每秒处理帧数(frames per second, FPS)以及参数数量作为模型检测性能的评估标准。这些计算公式如下
式中:P为所有被预测为正的样本中,实际为正的比例;R为实际为正的样本中,被正确预测为正的比例;AP为对于单个检测类别的准确性;mAP为所有类别中AP的平均准确性;FPS为在道路目标测试集上的平均检测速度;Fi为视频总帧数;Tn为检测时间。
3.4" 实验结果
本文将Faster R-CNN、YOLOv5s、YOLOv7和YOL
Ov8s与本文改进的模型(Ours)进行对比实验,准确率(P)、召回率(R)、平均精确度(mAP)、FPS及模型参数量(Params/M)均在表3中展示。
通过表3可知,本文改进模型在路口监控视频中识别机动车、非机动车和行人方面表现良好,在准确率、平均精度、召回率方面都优于其他模型,并且具有较低的参数数量。平均精确度(mAP)高于Faster R-CNN、YOLOv7、YOLOv5s和YOLOv8s,分别提高了22.7%、10.1%、10.9%和3.08%。改进模型在预测框的准确性上也超过了其他模型,有效降低了漏检和误检的发生。FPS方面比YOLOv5s快3.2倍,比YOLOv8s快1.2倍,满足对路口多目标实时检测需求。
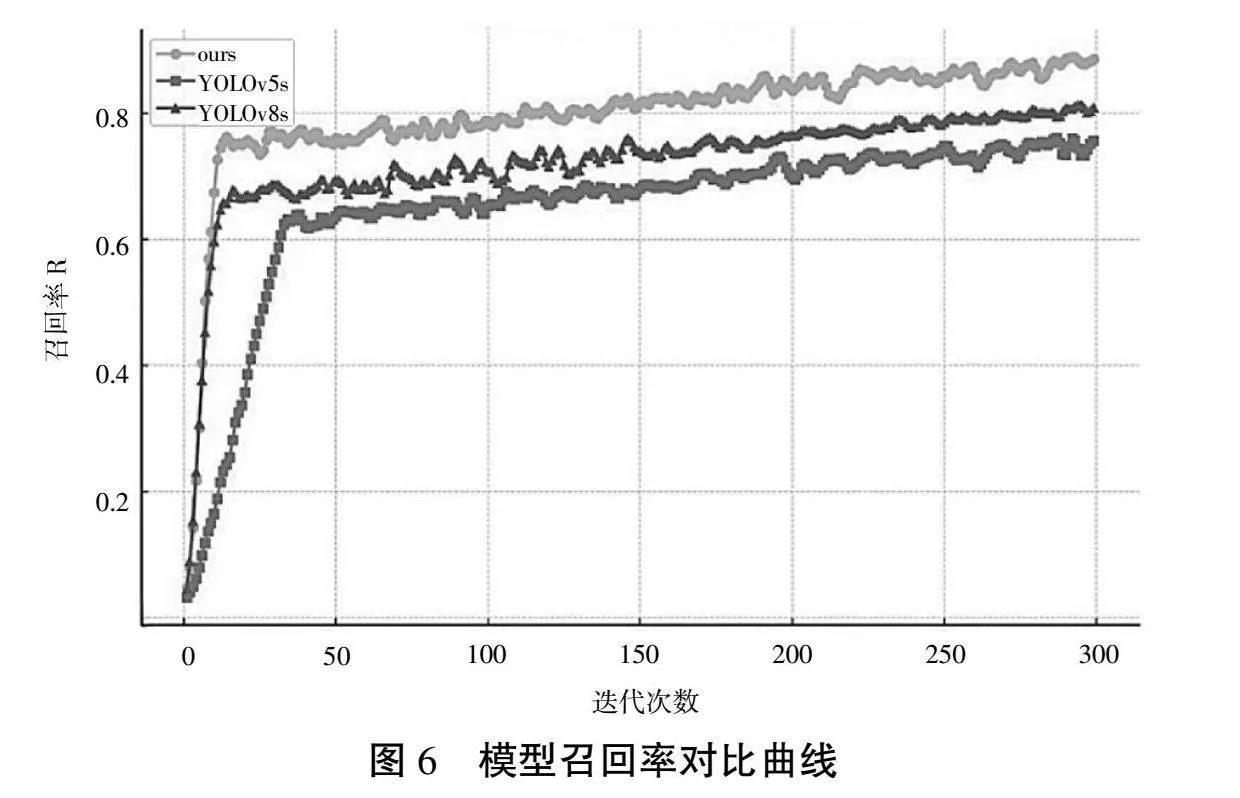
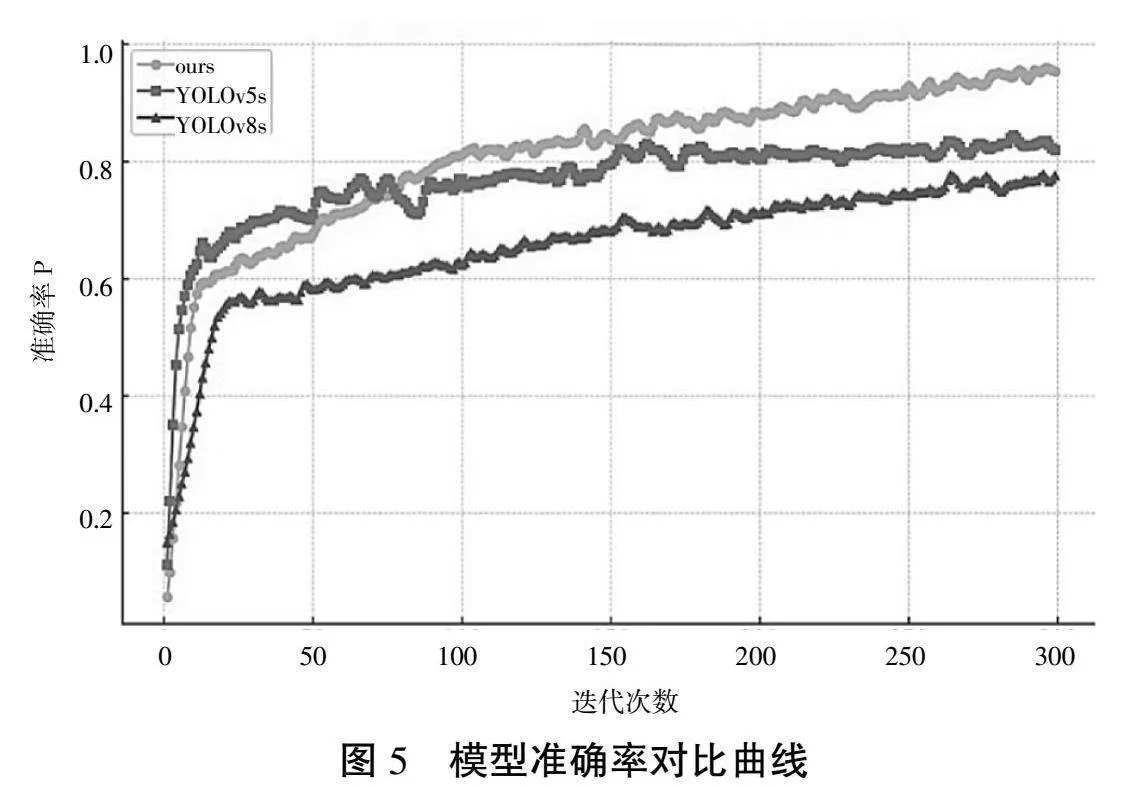
图5、图6分别展示了本文模型与YOLOv5s、YOLOv8s的准确率曲线和召回率曲线的比较。从图5中可以看到,改进模型准确率在较短的训练周期内提升迅速,并在200轮训练后仍有提升。从图6召回率曲线来看,DBB模块的特征优化使得模型能够更快地学习到有关目标的有效信息,使得模型在训练的初期阶段,召回率的提升非常迅速。这表明模型对于各类目标有着较好的识别能力,特别是在处理复杂或变化的场景时,能够有效地减少漏检数量。
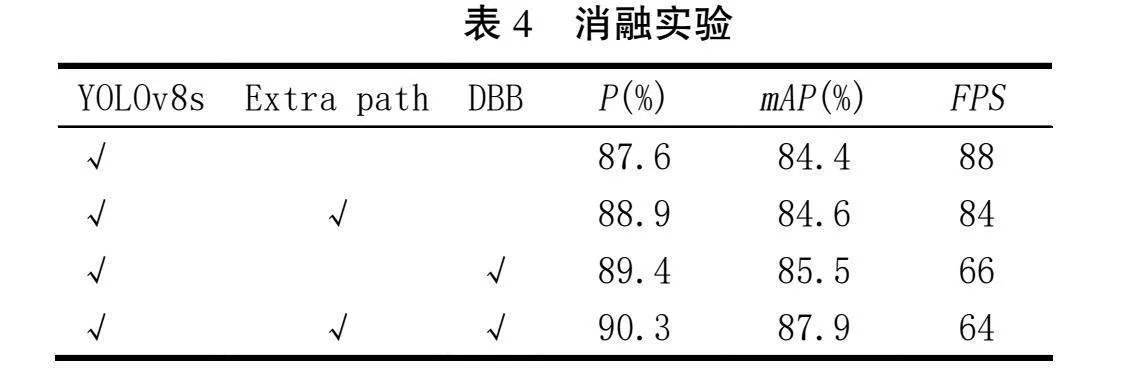
3.5" 消融实验
为了验证新增卷积操作路径和DBB模块特征融合的改进效果,本文设计了消融实验以分析并验证每个改进模块如何影响P、mAP和FPS值。实验结果见表4,其中“√”表示对应模块的应用。
由表4可知,改进模型显著提高了模型的检测精度和平均精度,但会稍微降低处理速度。模型在引入额外卷积分支之后,P有所提高,但mAP提升幅度较小,FPS略有下降。而在继续融合DBB模块特征后,模型的P和mAP均有提高,相较于原模型提升了4.2%和3.08%,但FPS降低到64。
3.6" 实际检测目标可视化验证与对比
为了更直观地进行展示模型的改进效果,本文将改进后的模型与YOLOv8s、YOLOv5s进行可视化对比,如图7所示。
图7展示了城市交叉路口场景中目标检测的结果对比。从图7中可以看出,本文改进的模型在多目标检测方面表现优越。模型在检测车辆、非机动车和行人方面表现出较高的置信度。相比于YOLOv8s和YOLOv5s,模型对非重合检测对象的检测准确性最好,且没有存在漏检和误检的情况。由图7可知,本文改进的模型的表现更出色,证实了改进模型的有效性,对路口多目标识别起到了优化效果。
4" 结论
针对城市路口多目标识别效率低、精度不足的问题,本文运用YOLO8s改进模型对路口多目标交通参与者进行了研究。通过引入额外的卷积分支和融合DBB模块的特征提取方式,优化了模型对多目标的检测能力。此外,采用某城市道路监控视频和自行采集的图像来构建数据集,提高实验结果的真实性。实验结果表明:改进的模型的准确率、召回率和平均准确度分别提升了4.2%、3.1%和3.08%。相比原模型改进有效,为进一步研究路口事故预防提供了方法支撑。
参考文献:
[1] 公安部部署2021年道路交通事故预防“减量控大”工作[J].道路交通管理,2021(3):6.
[2] 王永岗,李晓坤,宋杰,等.车辆轨迹数据驱动的急弯路段追尾冲突风险时空演化规律[J].哈尔滨工业大学学报,2024,56(3):38-45.
[3] REN S, HE K, GIRSHICK R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[J]. IEEE transactions on pattern analysis and machine intelligence, 2016,39(6):1137-1149.
[4] HE K, GKIOXARI G, DOLLáR P, et al. Mask r-cnn[C]//Proceedings of the IEEE international conference on computer vision. 2017:2961-2969.
[5] LU X, LI B, YUE Y, et al. Grid r-cnn[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2019:7363-7372.
[6] DAI J, LI Y, HE K, et al. R-fcn: Object detection via region-based fully convolutional networks[J]. Advances in neural information processing systems, 2016,29.
[7] SINGH B, LI H, SHARMA A, et al. R-FCN-3000 at 30fps: Decoupling detection and classification[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018:1081-1090.
[8] REDMON J. You only look once: Unified, real-time object detection[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
[9] LIU W, ANGUELOV D, ERHAN D, et al. Ssd: Single shot multibox detector[C]//Computer Vision-ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part I 14. Springer International Publishing, 2016:21-37.
[10] LIU Y, LU B H, PENG J, et al. Research on the use of YOLOv5 object detection algorithm in mask wearing recognition[J]. World Sci. Res. J, 2020,6(11):276-284.
[11] ZHANG Y, GUO Z, WU J, et al. Real-time vehicle detection based on improved yolov5[J]. Sustainability, 2022,14(19):12274.
[12] WANG C Y, BOCHKOVSKIY A, LIAO H Y M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2023:7464-7475.
[13] WANG G, CHEN Y, AN P, et al. UAV-YOLOv8: A small-object-detection model based on improved YOLOv8 for UAV aerial photography scenarios[J]. Sensors, 2023,23(16):7190.
[14] LOU H, DUAN X, GUO J, et al. DC-YOLOv8: small-size object detection algorithm based on camera sensor[J]. Electronics, 2023,12(10):2323.
猜你喜欢
青春岁月(2016年22期)2016-12-23 16:34:20
青春岁月(2016年22期)2016-12-23 15:58:54
中国高新技术企业(2016年31期)2016-12-22 09:16:43
新教育时代·教师版(2016年23期)2016-12-06 06:02:38
法制与社会(2016年32期)2016-12-01 15:25:53
中国新技术新产品(2016年22期)2016-11-29 06:33:02
电子技术与软件工程(2016年18期)2016-11-14 23:06:48
软件导刊(2016年9期)2016-11-07 22:20:49
软件导刊(2016年9期)2016-11-07 22:13:07
软件工程(2016年8期)2016-10-25 15:47:34
