
基于文本挖掘的ISO标准术语自动识别与标准术语知识图谱构建研究
2024-12-31 00:00:00方思怡
标准科学 2024年8期



关键词:ISO,国际标准,术语自动识别,标准数字化,文本挖掘
0 引言
术语(Ter m)是蕴含特定学科领域核心概念的专用名词,与特定学科的领域知识密切相关[1,2]。术语识别(Terminology recognition,TR)是指从语料中抽取具有领域代表性的词汇或短语的过程,被视为信息抽取和命名实体识别(Naming entityrecognition,NER)领域的重要分支[3]。近年来术语自动识别(Terminology automatic recognition,TAR)逐渐引起各界研究者的关注。标准是领域技术情报的重要来源,标准术语也是领域技术信息的核心载体,具有较强的专业性与系统性。在标准文本中,ISO国际标准是推进国际贸易与合作的重要准绳,其地位和影响力不言而喻。在标准数字化转型下,ISO术语自动识别将为标准语料库、标准知识图谱、标准智能检索、标准自动标引、标准智能翻译、标准本体、相关产业画像和知识体系构建等标准知识服务奠定重要的数据基础[4,5]。
1 标准术语自动识别的研究现状
1.1 术语自动识别的相关研究进展
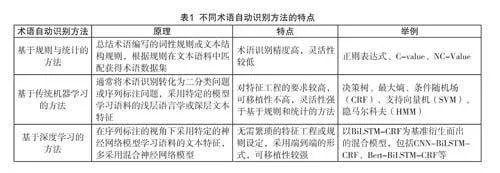
纵观已有的研究,术语识别技术历经多个发展阶段,迄今为止已形成了基于专家人工、基于规则与统计、基于传统机器学习以及基于深度学习的识别方法。
受限于技术水平,早期的术语识别研究多通过专家人工模式进行,该方法能确保术语抽取的质量,但人力和时间成本较高,可推广性不强。随着计算机技术的发展,术语自动识别逐渐取代了专家人工识别,成为各领域术语识别的主流发展方向。术语自动识别的具体技术取决于其所针对的文本语料特性。本研究系统梳理了术语自动识别研究的技术方法,表1概括了不同术语自动识别方法的原理、特点及案例。
1.2 标准术语自动识别的现状与发展趋势
当前国内外标准数字化转型正处于起步阶段。2021年发布的《国家标准化发展纲要》明确指出要加快标准的数字化、网络化和智能化转型,由此对标准数字化文本的知识自动抽取与加工技术提出了全新的要求[6]。与专利、科技论文等领域相比,标准术语自动识别研究尚存在大量的提升空间。作为标准的基本要素之一,标准术语是标准文本技术信息的重要组成,也是标准知识自动抽取的对象之一。近来涉及标准实体识别的国内外研究大多针对标准起草单位、标准提出单位、标准指标和标准规范性引用文件[7-9],尚未对国际和国内外标准进行术语自动识别的深入探索。
尽管标准术语自动识别尚存在大量研究空白,在标准数字化转型的驱动下,随着标准知识服务对细粒度和深层次的需求日益增加,国际和国内外标准的术语自动识别方法将成为大势所趋。作为国际标准的重要品种,ISO标准术语自动识别技术也存在迫切的发展和应用需求。
2 ISO标准术语自动识别的研究方法
2.1 研究思路
本研究以上海市质量和标准化研究院“标准文献发行系统”中现有的ISO文本为数据来源,结合ISO文本编写的相关要求[10]和对ISO文本结构特性的深入分析,形成相应的研究思路。经过分析可知,当前ISO国际标准的载体为PDF格式的数字化文本,通常以英语语种为主,可能存在多语种的情况,ISO术语条目的编写也遵循较为明确的规则。综上所述,本研究选取基于规则的文本挖掘技术作为ISO标准术语的自动识别方法,由此制定相应的技术路径。
2.2 研究流程
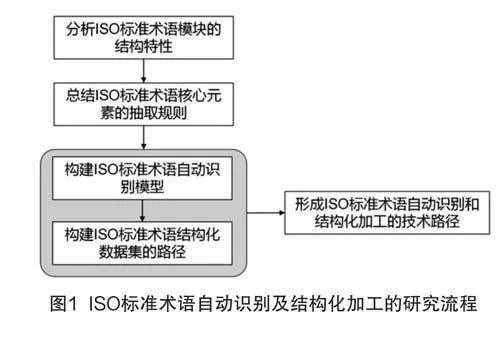
本研究基于研究思路,制定了如图1所示的研究流程框架。
2.2.1 分析ISO标准术语模块的结构特性
研究流程的第一步为分析ISO标准术语模块的结构特性,以ISO的编写指南为依据,结合现行ISO文本术语数据的实际情况,明确ISO术语自动识别的研究范畴,并概括研究范畴内ISO术语模块核心元素的文本结构特性。
经过系统分析可知,I S O标准术语模块可以囊括的元素有术语介绍(Introductory wording)、术语编号(Term number)、首选术语(Prefer redterm)、首选术语的缩略语、可接受的术语同义词(Accepted term)、弃用术语(Deprecated term)、术语领域(Te r m d o m a i n)、术语定义(Te r mde f i n it ion)、术语示例(Ter m ex a mple)、术语条目注释(Note to ent r y)以及术语来源(Ter msource)。本研究坚持以应用到导向,重点关注ISO术语中与技术密切相关的信息,故将研究范畴界定为术语编号、首选术语、首选术语缩略语、可接受的术语同义词、弃用术语、术语定义、术语示例、术语条目注释和术语来源。结合现有的ISO文本数据,将上述核心要素的定义、结构特性和示例概括见表2。
2.2.2 总结ISO标准术语模块中核心元素的抽取规则
在此基础上开展研究流程的第二步,也即根据文本结构特性,从文本表述形式、在术语条目中的所在位置等几个方面总结ISO标准术语模块中核心元素的抽取规则。以术语元素中的术语编号为例,其抽取规则可以概括为两点,其一是通常位于术语模块的第一个位置,其二是由阿拉伯数字和间隔点构成,且间隔点位于两个阿拉伯数字之间。
2.2.3 构建ISO标准术语自动识别模型
研究流程的第三步为针对ISO标准术语模块的各个核心元素,采用Python构建基于规则的ISO标准术语自动识别模型,本研究首先将ISO标准术语模块中各核心元素的抽取规则转化为伪代码,进而通过Python编写程序,形成适用于ISO术语各核心元素的自动识别算法,再将上述算法整合成为统一的算法模块,完成ISO术语自动识别模型的构建。
2.2.4 构建ISO标准术语结构化数据集的路径
研究流程的第四步为采用Python构建ISO标准术语结构化数据集的实现路径,主要包括设定结构化数据集的数据表达框架和结构化数据集的转化算法。该步骤旨在将ISO标准术语自动识别模型中获得的ISO术语各核心要素的抽取结果自动转化为结构化数据集的形式,为后续的ISO标准数据深度挖掘和加工奠定一定的技术基础。
2.2.5 形成ISO标准术语自动识别和结构化加工的技术路径
在完成上述步骤后,采用Python将ISO标准术语自动识别模型和结构化数据集的技术路径相结合,完成上述两者的代码模块的顺利链接,形成ISO标准术语自动识别和结构化加工的完整技术路径。
2.3 模型设计
ISO标准术语自动识别模型是实现ISO标准术语自动抽取的关键所在。
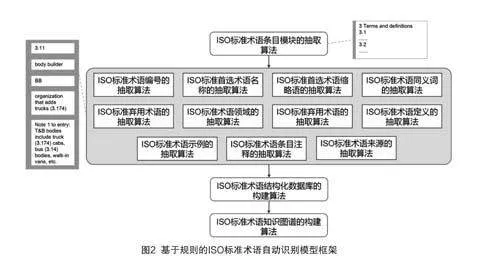
本研究采用基于规则的文本挖掘方法,通过Python编写了提取ISO标准术语条目模块与核心元素的抽取算法以及结构化和可视化加工的算法,形成了基于规则的ISO标准术语自动识别模型,模型框架详如图2所示。
由图2可知,该模型主要由ISO标准术语条目模块的抽取算法、ISO标准术语核心元素的抽取算法、I SO标准术语结构化数据库的构建算法以及ISO标准术语知识图谱的构建算法组成,其中ISO标准术语条目模块的抽取算法、ISO标准术语核心元素的抽取算法旨在实现ISO标准术语核心元素的自动抽取,ISO标准术语结构化数据库的构建算法旨在完成自动抽取结果的结构化加工,形成可适用于标准数字化平台的ISO文本结构化数据集,而ISO标准术语知识图谱的构建算法的目的在于对ISO标准术语的自动识别结果进行可视化展现并形成可供深度挖掘的数据集,为标准智能决策奠定数据基础。
3 ISO标准术语自动识别的研究结果
3.1 ISO标准术语结构化数据库的文献计量学分析
本研究在完成ISO标准术语自动识别及结构化和可视化加工的技术路径后,在特定的I SO标准文本上开展实证研究。本研究选取ISO 26262作为ISO术语自动识别技术的应用对象。ISO 26262针对汽车安全相关的电子电气系统,与汽车功能安全密切相关,其所涉及的汽车芯片也是近年来集成电路产业的热点方向之一。
经文本切词后统计可知,ISO 26262共计10篇标准文本,含有194.42万个字符与66.89万个单词。在上述文本中应用ISO标准术语自动化识别及结构化和可视化加工的模型,最终抽取获得的ISO标准术语条目的字符数为6.2万,单词数为2.1万;所涉及的ISO标准术语核心元素有术语编号、首要术语名称、首要术语缩略语、术语同义词、术语定义、术语条目注释和术语示例,其标准术语核心元素的数量分布情况如图3所示。
为了掌握ISO 26262标准术语数据的词频分布概貌,通过构建ISO标准术语条目干扰词库,剔除ISO术语条目常见的无关词,并采用Python描绘词云图,所得结果如图4所示。
3.2 ISO标准术语知识图谱
本研究基于ISO标准术语编写的文本特性,初步设计了ISO标准术语知识图谱的模式层,由此明确了标准术语的实体和关系类型。I SO标准术语知识图谱的模式层框架主要以ISO标准术语核心元素为实体类型,以核心元素的名称指向形式也即“ISO标准术语核心要素+是”的英文表述形式为关系类型。
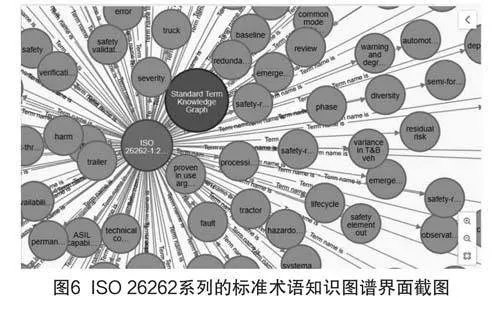
采用Python编写了ISO标准术语知识图谱的可视化路径,在Neo4j平台中实现相关应用,图谱的示例和界面截图分别如图5与图6所示。该图谱共含有547个不同的标准实体和7种不同的标准关系类型。
4 总结与展望
4.1 总结
本研究针对ISO标准的文本特性,构建了适用于ISO的术语自动识别模型及结构化和可视化加工路径,在ISO 26262标准上完成验证与应用,形成了ISO 26262的标准术语知识图谱。
4.2 展望
本研究为ISO标准的标准术语自动识别提供了一定的技术参考,在后续工作中将继续深化ISO标准实体抽取模型的研究,将其应用在标准数字化平台中,以期能够实现细粒度和深层次的ISO标准知识抽取与自动加工,推动标准数字化转型下标准知识服务的发展。
猜你喜欢
纺织科学研究(2021年1期)2021-03-19 05:18:24
纺织科学研究(2017年7期)2017-07-25 07:48:51
软件导刊(2016年12期)2017-01-21 15:55:21
电子技术与软件工程(2016年22期)2016-12-26 20:29:58
商(2016年34期)2016-11-24 16:28:51
中国远程教育(2016年9期)2016-11-19 12:26:00
语文教学之友(2016年5期)2016-06-15 12:15:44
电脑知识与技术(2016年5期)2016-04-14 13:51:02
中国质量与标准导报(2015年2期)2015-02-28 22:27:11
中国质量与标准导报(2015年2期)2015-02-28 22:27:09
