
基于跨模态特征融合的RGB-D花椒图像显著性检测
2024-12-28 00:00:00李节孙成龙王逸涵杨前李柏林
机械制造与自动化 2024年6期











摘要:针对现有显著性检测模型无法有效地协同花椒枝干彩色图像和深度图像特征,建立基于注意力的RGB-D图像花椒枝干显著性检测模型。由两个单流卷积网络分别提取彩色和深度图像特征;设计基于空间和通道注意力机制的跨模态融合模块,用于融合多尺度的彩色流和深度流特征;研发多尺度监督机制,用于缓解由于采用最近邻域上采样的解码方式导致边缘预测不准确的问题。实验结果表明:该方法的平均精确度、平均召回率、综合评价指标和平均绝对误差均优于对比显著性目标检测方法。
关键词:花椒自动化采摘;图像处理;RGB-D显著性目标检测;跨模态融合;注意力机制;多尺寸监督
中图分类号:TP391.41文献标志码: A文章编号:1671-5276(2024)06-0211-07
Abstract:To address the inability of existing saliency detection models to utilize the features of pepper branch color images and depth images effectively, an attention-based RGB-D image pepper branch saliency detection model is proposed. Color and depth image features are extracted separately by two single-stream convolutional networks. A cross-modal fusion module based on spatial and channel attention mechanisms is designed to fuse multi-scale color stream and depth stream features. A multi-scale supervision mechanism is developed to alleviate the inaccurate edge prediction caused by the use of nearest-neighbor upsampling decoding. Experimental results show that the average accuracy, average recall rate, comprehensive evaluation index and average absolute error of the proposed method are all superior to the compared salient object detection methods.
Keywords:automated pepper harvesting; picture processing; RGB-D significance target detection; cross-mode fusion; attention mechanism; multi-dimension supervision
0引言
花椒是四川省重要经济作物,提升花椒采摘的自动化水平对于我国西部乡村振兴具有重要意义。得益于近些年来计算机软硬件的发展,基于视觉的采摘机器人被广泛地应用于苹果、柑橘和葡萄的自动化采摘。作为智能采摘机器人[1]的重要组成部分,视觉系统通常被设计用于识别并定位果实位置,从而引导机械部分完成采摘。不同于苹果、柑橘等的采摘,簇状花椒的采摘点无法直接被观测到,而采摘点的估计需要利用枝干和花椒簇的交点来确定。
如图1所示,考虑到机械臂的运动空间及复杂采摘场景中的干扰物(枝条、叶子等),合理的花椒采摘规划应为采摘明显的近景花椒,忽略远景花椒。由于近景花椒一般位于前景中较粗的主枝干上,因此前景主枝干的提取是花椒采摘点估计的重要前提。
花椒前景的主枝干提取任务是一种显著性目标检测[2](salient object detection, SOD)问题,旨在实现图像场景中感兴趣区域的快速提取并过滤背景噪声的干扰。文献[3]提出了一种RGB-SOD算法用于农田中的昆虫检测并取得了良好的效果,但易受到复杂环境的干扰,无法有效用于具有低对比度、相似前景与背景、复杂背景等特点的花椒主枝干提取。为了实现复杂农业场景中SOD,文献[4]提出了双流主干网络用于同时提取柑橘图像的彩色和深度特征,提供具有鲁棒性的显著性线索。文献[5]以跳层结构为基础提取跨模态间的多层次互补信息。为了更好地获取跨模态间的互补信息用于显著性推理,文献[6]提出了一种流体金字塔结构用于引导深度图像和彩色图像的信息融合。复杂的农作环境中采集到的彩色图像和深度图像中跨模态信息往往是非耦合的(图1),采集到的花椒深度图像中还包含了与前景相似的噪声,而现有的一些研究表明线性的跨模态融合方法无法有效地抑制相似噪声的干扰,从而影响最终的识别结果。为了抑制深度图像中的噪声对显著推理造成的影响,文献[7]利用边缘一致性、区域不确定性和模型方差来评估深度图质量,并以此指导深度图与彩色图的选择性融合。然而,该方法依赖手动设计的质量评价标准,无法应对花椒采摘场景中的各种复杂背景的干扰。
针对相似前景与背景、复杂背景中的花椒枝干提取问题,本文提出基于注意力机制[8]和多尺度监督[9]的花椒主枝干显著性检测模型。模型的编码器采用主流的双分支主干网络来提取彩色图像特征和深度图像特征。此外,在多个尺度上,本文提出特征融合增强模块(feature fusion enhancement module,FFEM)并将其嵌入到两个分支网络中,利用空间与通道注意力模式来实现跨模态特征的判别融合。在多尺度分割标签的监督下,特征融合增强模块能够自动学习空间权值图和通道权值向量。本文方法如下。
1)针对复杂的农作环境中花椒主枝干的检测问题,提出一种基于跨模态特征融合的RGB-D花椒枝干图像显著性检测模型。
2)所提模型在多个编码层级采用通道权值向量调整彩色和深度图像的串联特征,并计算调整后特征的空间权值图,提取主枝干的形状特征并抑制背景噪声。
3)采用多尺度监督的方式来缓解上采样过程中的边缘信息丢失,提高模型对主枝干的分割效果。
1所提模型
1.1网络结构
花椒主枝干的精确提取是预测花椒采摘点的重要前提。为了在复杂农作环境下完成花椒主枝干的精确提取,本文提出了一种跨模态的枝干显著性检测模型,如图2所示。模型采用花椒彩色和深度图像两种输入信息,由两个单流卷积网络获取多尺度的编码特征。单流卷积网络采用类似Unet编码器架构,通过连续地组合卷积编码层(包括卷积层、批归一化层、线性整流层和最大池化层)来编码彩色图像和深度图像特征。为了有效地利用彩色和深度编码特征,提出特征融合增强模块用于实现跨模态特征的判别融合并剔除特征中相似背景的噪声干扰。该模块借鉴了注意力机制聚焦于感兴趣区域的特性,通过在线性融合过程中嵌入非线性注意力单元来改善融合后特征的显著性表达。在上采样过程中,一个反向的解码网络被用于解码图像特征,非线性注意力单元被嵌入到网络的每一层级来进一步精炼特征表示。最终,通过多级监督的方式,显著性推理模块完成最终的预测输出。
1.2基于注意力的跨模态融合模块
彩色花椒图像中主枝干的提取会受到相似前景枝干的干扰。因此,为准确地区分主枝干还需要深度图像提供额外的显著性线索。然而,复杂的农作环境易导致深度图的深度线索缺失,使得深度图像中枝干与附近叶子、花椒等对象融为一体。从低质量的深度图像中分辨出目标枝干仍然需要借助颜色、纹理等外观信息。因此,本文设计了跨模态融合模块来同时提取彩色模态和深度模态中包含的与主枝干相关的编码信息。为了减少彩色模态和深度模态中与显著性目标相似的背景信息对主枝干提取的干扰,本文在融合模块中嵌入注意力机制来精炼融合后的编码特征。
单一层级跨模态融合模块的结构如图3所示。该模块首先接收来自同层级的彩色模态和深度模态特征XRGBi∈RCi×(H/2i)×(W/2i)和XDEPi∈RCi×(H/2i)×(W/2i),其中参数C、H、W和i分别表示编码特征的通道数量、尺度和层级系数,R表示实数空间。
针对双模态的特征,首先采用拼接操作聚合跨模态特征,并采用卷积操作对聚合特征进行非线性映射:
式中:Conv3×3表示采用3×3尺寸的卷积核进行步长为1的标准卷积操作;BN(·)和ReLU(·)分别代表批归一化和线性整流操作。
对于聚合后的跨模态特征Ffusion,分别采用通道注意模块和空间激活模块来计算该特征的通道权值图和空间权值图。最终,融合模块的编码输出将表示为输入编码在权值图上的加权映射。具体的计算过程如下:
式中:CAM表示通道注意力模块;表示对应元素相乘;通道权值图FCAM∈RCi×(H/2i)×(W/2i)。
式中:SAM表示空间注意力模块;空间权值图FSAM∈RCi×(H/2i)×(W/2i);模块最终输出的编码特征XRGB′i∈RCi×(H/2i)×(W/2i)。
通道注意力通过自适应地计算输入特征通道权值图来为判别力强的重要通道赋予较高权值,从高维冗余的特征图中选择对显著性表达更加有利的特征表示。空间注意力机制通过自适应计算来增强显著性区域的特征表示。由于显著性区域被赋予更高的空间权值,多模态特征中与主枝干相似的背景噪声能够被更好地抑制。
1.3通道注意机制和空间激活机制
卷积网络输出的中间层特征中包含反映不同内容的通道,例如彩色模态中枝干的主要形状、细节轮廓、语义信息,深度模态中主枝干与背景的深度差异性、目标的深度轮廓等。在主枝干的显著性检测中,特征图中背景的细节轮廓信息会干扰显著性目标的检测,造成分割结果中出现与主枝干结构相似的背景枝干,甚至花椒和叶子等背景对象。因此,对多通道编码特征进行差异化关注,可以增强其中与显著性预测相关的特征表达,起到抑制多模态特征中背景信息的干扰作用,有利于前景主枝干提取。因此在跨模态融合模块每个层级中,通道注意机制被嵌入用于引导网络对融合后的跨模态编码特征中与显著性预测相关的通道,进行重点关注,其结构如图4所示。
首先,对输入的串联特征Ffusion进行转置:
式中Permute(·)表示转置操作,转置后的编码特征FTfusion∈R(H/2i)×(W/2i)×Ci。
然后,采用包含一个隐含层的多层感知机对转置特征进行非线性映射:
式中MLP由两个全连接层与一个ReLU激活函数层组成。与CBAM[10]类似,本文在MLP进行特征映射时,采用reduction为r的调节通道衰减系数。MLP输出的编码FT∈R(H/2i)×(W/2i)×Ci。
随后,采用转置操作还原编码特征的维度,同时采用Sigmoid激活函数将还原后的特征映射到[0,1]并获得最终的通道权值图FCAM:
式中σ表示Sigmoid函数。
编码特征中的二维图反映了不同内容的语义激活,二维图特定的权值图能够引导网络增强相应区域的语义响应,从而抑制非感兴趣区域特征的表达。本文进一步嵌入空间激活机制到模态融合模块中。空间注意力机制依据显著性监督来自适应计算有利于枝干预测的二维权值图,从而引导枝干显著性特征的表达。
在空间激活机制中(图5),对输入的编码特征采用7×7的卷积操作,获取更大的感受野,使网络能够更加有效地利用上下文空间信息。同时,为减少较大卷积核带来的计算负担,上述卷积操作采用了reduction为r的可调节通道衰减系数:
式中:FM为卷积后的编码特征;Convr7×7表示采用7×7卷积核和通道衰减系数r的卷积操作。
随后采用7×7卷积核和通道衰减系数1/r的卷积操作将该特征映射到与输入特征相同的特征空间:
最后采用Sigmoid激活函数将编码特征中的特征值映射到[0,1]以得到最终的空间权值图FSAM:
FSAM中每个特征点的取值范围是[0,1],某个位置的权值较大则表明此处的特征被增强,否则被削弱。通过训练阶段优化卷积核参数,FSAM能够自适应地根据彩色特征XRGBi和深度特征XDEPi为分割目标区域赋予较大特征权值,增强前景主枝干区域的特征,抑制远景枝干的干扰。因此,融合跨模态特征的空间权值图FSAM能够引导模型更加关注特征图中的局部重要区域。
1.4显著性推理
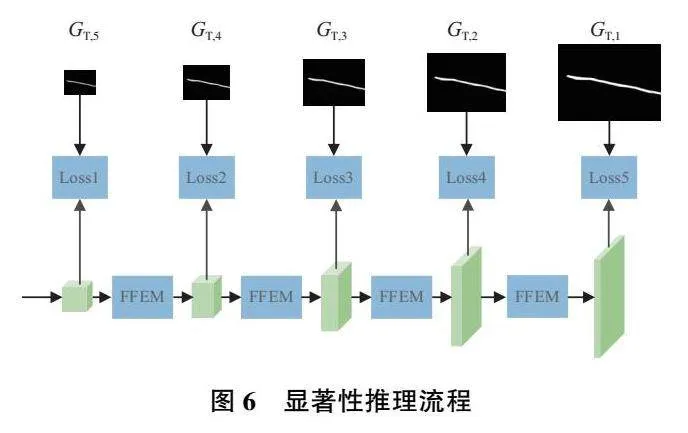
特征解码阶段采用邻域插值的上采样操作会丢失目标边缘轮廓的部分特征,使得分割结果中物体的边缘较为粗糙[11]。然而花椒采摘点的估计需要精确的枝干边缘作为依据。因此,采用多尺度监督的方式来减少上采样过程中边缘信息的丢失,如图6所示。在特征解码阶段,本文采用与Skip-Unet类似的解码网络,通过采用阶梯式的最近邻域上采样层和卷积激活操作来对融合后的跨模态特征编码进行最终的解码映射。在上采样过程中,跳跃连接被用于从编码器中获取部分特征映射来提升解码器的特征丰度,缓解因注意力机制而丢失的部分编码特征。
在上采样过程中的每一个层级,对应尺度的真实标签值GT,i被依次用于监督特征解码过程,以损失计算的方法来引导枝干特征的显著表达。其中,不同尺度的真实标签值通过下采样真实标签图获得。
2实验结果与分析
2.1实验设置
1)数据集
实验采用的花椒图像采集于四川省冕宁县,品种为红花椒,处于盛果采摘期(2021年7月2日—7月6日),果实的颜色以红色为主。采用Intel RealSence D435i深度相机采集花椒的彩色和深度图像,并将二者尺寸进行对齐。表1详细地列出了图像数据集的信息。为了保证数据的多样性,采集的图像涵盖了3种天气条件(晴天、多云、雨后)和一天中的两个时间段(上午和下午),如图7所示。从5棵不同大小的花椒树上总共收集了1 725张彩色图像和对应的深度图,其中1 042张彩色图像被标记用于识别算法的训练和验证。其中,70%(721)的标记图像被用作训练数据,剩余30%(321)的标记图像被用于实验验证,以测试识别算法的拟合性能。此外,剩余683张未标记的图像则被用来测试算法的识别效果。在数据标注方面,LabelMe软件被用于手动标注主枝干的分割掩码。
2)模型参数
实验框架基于PyTorch1.2框架搭建,训练阶段采用Adam优化器来训练网络,选取学习率、批量、迭代次数和通道衰减系数r分别设置为0.001、6、800和16。测试阶段,将模型预测概率大于0.7的像素作为分割目标。所有实验环境均采用Ubantu 18.04的设备环境,显卡为NVIDIA GeForce RTX 3090。
3)评价指标
为更好地评估模型的综合性能,采用平均精确度P、平均召回率R、Fmeasure和平均绝对误差(mean absolute error,MAE)作为评价指标。如表2所示,模型检测结果的定义主要分为真阳性(true positive,TP)、假阳性(1 positive,FP)、真阴性(true negative,TN)、假阴性(1 negative,FN)4种情况。
Fmeasure是对精确度和召回率的整体表现评估,计算公式如下:
式中β2是一个超参数,通常取0.3。P、R、Fmeasure数值越大,显著性目标检测效果越好。
MAE值用于评估显著预测图和真值图之间的平均绝对差值,代表显著性检测的整体效果:
式中:N和M分别为图像的长和宽;S(x,y)和G(x,y)分别为(x,y)处的显著预测值和真值。MAE值越小,表明模型预测的结果与真实标注图间差异越小,因此枝干的分割性能越好。
2.2对比实验
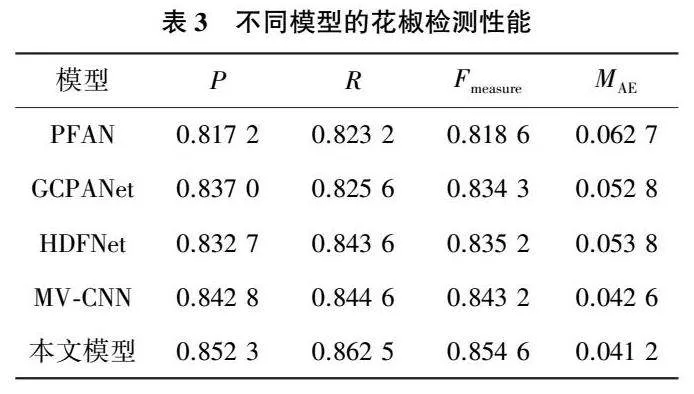
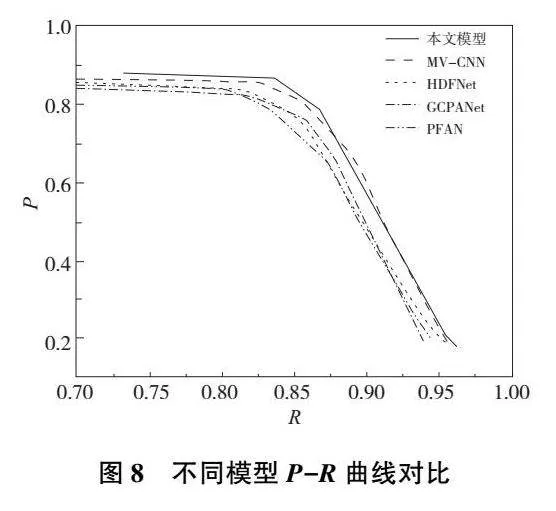
为测试本文模型的性能,本文采用主流的显著性模型进行对比,包括全局上下文感知渐进聚合显著性目标检测网络(global context-aware progressive aggregation network for salient object detection,GCPANet)[12]、金字塔特征注意力显著性检测网络(pyramid feature attention network for saliency detection,PFAN)[13]、基于CNN的跨视图转移和多视图融合RGB-D显著性检测网络(CNNs-based RGB-D saliency detection via cross-view transfer and multiview fusion,MV-CNN)[14]、基于分层动态滤波RGB-D显著性检测网络(hierarchical dynamic filtering network for RGB-D salient object detection,HDFNet)[15]。指标结果定量比较如表3所示。
从表3中可以看出:本文模型取得了最佳的显著性检测效果,其中P、R、Fmeasure和MAE指标分别为0.852 3、0.862 5、0.854 6和0.041 2。与MV-CNN网络相比,指标性能分别提升了0.95、1.79、1.14和0.14个百分点。相比于其他的3种网络,指标性能分别有1.53~3.51、1.89~3.93、1.94~3.61和1.16~2.15个百分点的提升。此外,为了清晰地观察实验结果,本文绘制了各个模型的P-R曲线。如图8所示,P-R曲线表明本文模型优于MV-CNN模型,同时明显优于HDFNet、GCPANet和PFAN模型。
为了更直观地分析结果,本文进一步展示了各个模型检测的可视化结果,如图9所示。
从图9中可以看出,本文模型能够在杂乱背景、前景和不易区分背景、多个对象等复杂场景中,准确检测到显著花椒枝干区域。如第一、第二行图片中存在较多与前景主枝干类似的背景枝干,但本文模型能够充分抑制背景枝干噪声,将前景主枝干识别出来。第三行图片中前景区域存在多个枝干对象,本文模型仍能够将前景主枝干识别出来。这表明本文模型能够有效过滤冗余信息,准确地输出识别结果。
2.3消融实验
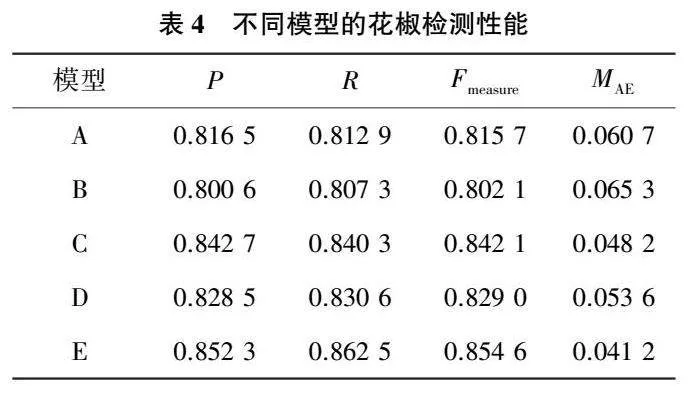
为测试本文所提不同模块对模型显著性检测的影响,设置以下模型进行对比实验:A,基础模型,经典的U-Net单模态骨干网络模型;B,双编码器模型,在U-Net模型的基础上,增加另一编码器通道提取深度图像特征,两通道在编码阶段结束后特征直接拼接进入解码阶段;C,跨模态多尺度特征融合模型,该模型同样采用双通道提取图像特征,并在编码阶段的5个层次分别加入特征融合模块进行特征融合,融合后的特征进入彩色图像通道继续编码;D,多尺度监督模型,在U-Net模型的基础上,在解码阶段进行多尺度监督;E,本文模型,同时采用跨模态多尺度特征融合模块和多尺度监督模块。上述模型的检测性能如表4所示。
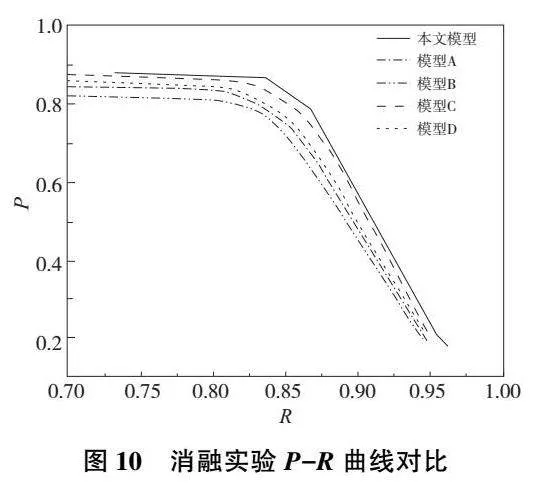
从表4中可以看出:模型B由于未采用特征融合模块对深度图像和彩色图像进行特征融合,导致被冗余的深度信息干扰,评价指标反而差于基础模型;模型C在引入多尺度特征融合增强模块后,评价指标得到了明显的提升;模型D的多尺度监督模块也促进了模型的评估性能。多尺度特征融合增强模块和多尺度监督模块的联合使用和仅使用单个模块相比,指标性能分别有0.96~2.38、2.22~3.19、1.25~2.56和0.70~1.24个百分点的提升。此外,本文绘制了5种模型检测的P-R曲线,如图10所示。从中可以看出,使用多尺度特征融合增强模块和多尺度监督模块后模型的检测曲线能够将其他曲线完全包住,这证明了其性能优于其他几种检测模型。
为了更加直观地反映出多尺度特征融合增强模块和多尺度监督模块对显著性检测的影响,本文对这几个模型的部分检测结果进行了可视化,如图11所示。从图11中可以看出:模型B增加了预测图的噪声数量,带来了负面效果;模型C又极大程度上抑制了噪声,这定性地证明了多尺度特征融合增强模块的作用;使用模型D的多尺度监督模块后,模型提取边缘信息的能力更强;同时本文模型使用了多尺度特征融合增强模块和多尺度监督模块,可以得到轮廓清晰且无噪声的前景主枝干预测图。
3结语
针对现有显著性目标检测模型难以准确定位复杂场景下花椒枝干的问题,本文提出跨模态特征融合的RGB-D花椒图像显著性检测模型。本文方法首先采用双分支主干网络来提取彩色图像特征和深度图像特征,并利用注意力机制来引导这两个模态特征的融合;最后引入多尺度监督方法用于提升模型对于显著性枝干边缘的检测性能。实验结果表明:本文模型的各项评估指标均优于其他显著性目标检测模型,能够得到更加精确的枝干检测结果。
参考文献:
[1] 杨前,刘兴科,罗建桥,等. 基于多任务上下文增强的花椒检测模型[J]. 机械制造与自动化,2023,52(1):113-118,149.
[2] LIU J J,HOU Q B,LIU Z A,et al. PoolNet+:exploring the potential of pooling for salient object detection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2023,45(1):887-904.
[3] 黄世国,洪铭淋,张飞萍,等. 基于F~3Net显著性目标检测的蝴蝶图像前背景自动分割[J]. 昆虫学报,2021,64(5):611-617.
[4] SUN Q X,CHAI X J,ZENG Z K,et al. Noise-tolerant RGB-D feature fusion network for outdoor fruit detection[J]. Computers and Electronics in Agriculture,2022,198:107034.
[5] 陈曦涛,訾玲玲,张雪曼. 采用跳层卷积神经网络的RGB-D图像显著性检测[J]. 计算机工程与应用,2022,58(2):252-258.
[6] LIU Z Y,LIU J W,ZUO X,et al. Multi-scale iterative refinement network for RGB-D salient object detection[J]. Engineering Applications of Artificial Intelligence,2021,106:104473.
[7] WANG X H,LI S,CHEN C,et al. Depth quality-aware selective saliency fusion for RGB-D image salient object detection[J]. Neurocomputing,2021,432:44-56.
[8] NIU Z Y,ZHONG G Q,YU H. A review on the attention mechanism of deep learning[J]. Neurocomputing,2021,452:48-62.
[9] WANG N,CUI Z G,SU Y Z,et al. Multiscale supervision-guided context aggregation network for single image dehazing[J]. IEEE Signal Processing Letters,2021,29:70-74.
[10] WOO S,PARK J,LEE J Y,et al. CBAM:convolutional block attention module[C]//European Conference on Computer Vision. Cham:Springer,2018:3-19.
[11] YU J,YAO J H,ZHANG J,et al. SPRNet:single-pixel reconstruction for one-stage instance segmentation[J]. IEEE Transactions on Cybernetics,2021,51(4):1731-1742.
[12] CHEN Z Y,XU Q Q,CONG R M,et al. Global context-aware progressive aggregation network for salient object detection[J]. Proceedings of the AAAI Conference on Artificial Intelligence,2020,34(7):10599-10606.
[13] ZHAO T,WU X Q. Pyramid feature attention network for saliency detection[C]//2019IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach,CA,USA: IEEE,2019:3080-3089.
[14] HAN J W,CHEN H,LIU N,et al. CNNs-based RGB-D saliency detection via cross-view transfer and multiview fusion[J]. IEEE Transactions on Cybernetics,2018,48(11):3171-3183.
[15] PANG Y W,ZHANG L H,ZHAO X Q,et al. Hierarchical dynamic filtering network for RGB-D salient object detection[C]//Vedaldi A,Bischof H,Brox T,et al. European Conference on Computer Vision. Cham:Springer,2020:235-252.
收稿日期:20230407
基金项目:四川省科技计划重点研发项目(2021YFN0020)
第一作者简介:李节(1997—),男,四川达州人,硕士研究生,研究方向为图像处理、机器视觉,lijie295195@163.com。
DOI:10.19344/j.cnki.issn1671-5276.2024.06.042
猜你喜欢
电子技术与软件工程(2019年5期)2019-06-20 10:31:23
软件导刊(2019年1期)2019-06-07 15:08:13
数字技术与应用(2019年2期)2019-05-14 08:25:10
制造技术与机床(2018年12期)2018-12-23 02:40:52
电子制作(2018年18期)2018-11-14 01:48:20
现代电子技术(2018年8期)2018-04-13 06:36:32
软件工程(2017年11期)2018-01-05 08:06:09
智能计算机与应用(2017年5期)2017-11-08 12:11:51
中国公共安全(2017年8期)2017-10-13 08:12:21
中国公共安全(2017年8期)2017-10-13 08:12:20
