
基于改进YOLOv8s的交通标志检测算法
2024-12-20 00:00:00张京淇李超李晓磊
电脑知识与技术 2024年30期


关键词:交通标志检测;YOLOv8;感受野卷积;空间金字塔池化;Focal-EIOU
0 引言
随着智能交通系统的快速发展,交通标志检测已成为其中不可或缺的一环。高效准确的检测算法对于提高道路安全、辅助自动驾驶以及优化交通管理具有重要意义。传统的交通标志检测方法往往依赖于手工设计的特征和复杂的分类器,其性能受到特征提取的准确性和分类器泛化能力的限制。
针对这一问题,众多研究者提出了不同的实时交通标志检测方法。例如,Daniel Castriani Santos 等人使用更快的R-CNN,提出了一种基于神经网络的实时交通标志检测和识别算法[1];张建明等人提出了一种基于自适应图像增强和显式客体分支的单级特征无锚交通标志检测器,以在野外环境中平衡鲁棒性、实时性和准确性的要求[2]。李旭东等人则针对智能驾驶过程中对交通标志自动检测的实时性和鲁棒性要求,提出了一种基于YOLOv3-tiny的嵌套残差结构交通标志快速检测算法[3]。李大湘等人在YOLOv4算法基础上引入注意力驱动的尺度感知特征提取模块,以解决在复杂场景中交通标志因尺度变化显著而引发的识别精度下降问题[4]。此外,张荣云等人将卷积块注意力模型与YOLOv5中的CSP1_3模型融合,增强了YOLOv5 的特征提取能力,提高了交通标志的准确性[5]。石镇岳等人引入坐标注意力机制和空洞空间金字塔池化技术,优化了YOLOv7算法对小目标的检测性能,显著减少了误检和漏检现象[6]。熊恩杰等人对YOLOv8n进行改进,设计了全新的C2fGhost模块,并添加了小目标检测层,从而在一定程度上解决了传统网络模型在交通标志识别精度低和检测不准确的问题[7]。张建明等人则提出了一种新的中国交通标志检测基准CCTSDB 2021,该基准在CCTSDB 2017的基础上进行了改进,以适应复杂多变的检测环境[8]。
近年来,YOLO系列算法因高效准确而广泛应用于物体检测领域。作为新一代YOLO算法,YOLOv8 优化了模型架构和训练过程,为提升检测速度和准确率提供了新的可能。然而,交通标志检测仍面临多样性、尺寸变化、遮挡及光照变化等挑战。本文旨在深入研究YOLOv8算法在交通标志检测领域的应用,从而为智能交通系统的进一步发展和完善提供坚实的技术支持。
1 YOLOv8相关理论
YOLOv8是Ultralytics公司推出的新一代目标检测算法,它在YOLO系列的基础上进行了全面的优化与升级,在图像分类、物体检测和实例分割等任务中均展现出了卓越的性能。该算法提供了包括YOLOv8n、YOLOv8s、YOLOv8m、YOLOv8l 和YOLOv8x 在内的五种不同大小的模型,以满足不同场景和性能需求。
YOLOv8的架构采用了深度学习领域的最新研究成果,包括改进的骨干网络、特征融合策略以及损失函数优化等。在Backbone部分,YOLOv8把YOLOv5 中使用的C3模块替换为更为轻量级的C2f模块,这一举措有效提升了模型的效率。同时,YOLOv8继承了YOLOv5等经典架构中广泛应用的SPPF模块。
在Head 部分,YOLOv8 摒弃了传统的Anchor-Based方法,转而采用Anchor-Free的思想。这一转变使得模型在目标检测过程中不再依赖于预设的锚框,从而大大简化了检测流程,并提升了模型的灵活性和适应性。
在特征融合方面,YOLOv8充分利用了多尺度特征融合技术。通过有效整合不同层次的特征信息,模型能够更好地捕捉目标的局部细节和全局结构,从而显著提高了对不同尺度目标的检测能力。
YOLOv8 对损失函数进行了深入的优化,采用VFL Loss 作为分类损失,使用DFL Loss 结合CIOULoss作为回归损失。在正负样本匹配方面,YOLOv8 摒弃了传统的IOU匹配或单边比例分配方式,转而采用Task-Aligned Assigner匹配方式[9]。
2 改进的YOLOv8网络结构
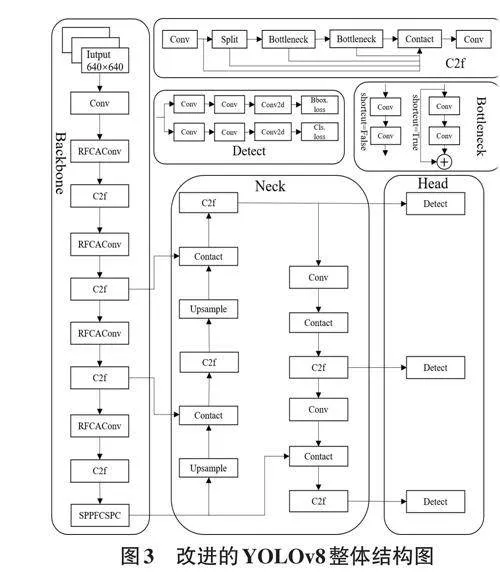
基于改进YOLOv8s的交通标志检测算法,算法引入了RFCAConv以替代部分卷积操作,通过赋予不同感受野以不同的注意力权重,使模型能够更加专注于目标区域的细节信息。同时,采用SPPFCSPC模块替代了SPPF模块,以提高特征融合的效率,使得模型能够更准确地捕获不同尺度交通标志的特征。在锚框回归过程中,放弃了原有的CIOU损失函数,采用了Focal-EIOU损失函数,以更好地处理边界框与真实框之间的不匹配问题。
2.1 RFCAConv 感受野注意力卷积
在传统的卷积神经网络(CNN) 中,卷积核在处理不同区域的图像时共享相同的参数,这可能限制了模型对于复杂模式的学习能力。感受野注意力卷积通过引入注意力机制,能够更灵活地调整卷积核的参数,针对不同区域提供定制化的处理,从而解决卷积核参数共享的问题。一些具有空间注意力机制性质的注意力模块,如CA,已被前人设计为RFCA,并将其与卷积结合得到新的RFCAConv,如图1所示。
2.2 SPPFCSPC 空间金字塔池化
空间金字塔池化(Spatial Pyramid Pooling,简称SPP) 是一种有效处理不同尺寸输入图像的技术。它通过将图像划分为不同层级、不同大小的空间金字塔区域并进行池化操作,从而实现对任意大小图像的固定长度特征表示,增强了模型的鲁棒性和泛化能力,这对于交通标志检测等任务具有重要的应用价值[10]。SPPFCSPC是结合了SPPCSPC和SPPF优点的新模块,如图2所示。
2.3 Focal-EIOU 损失函数
YOLOv8中使用的CIoU损失函数虽然考虑了边界框回归的重叠面积、中心点距离及长宽比,但其仅反映了长宽比的差异,未能准确体现宽高与其置信度之间的真实差异。为了克服CIoU的这一局限,采用Focal-EIOU 损失函数替代CIoU 损失函数。Focal-EIOU损失函数的公式如下:
式中,Cw 和 Ch 分别是两个矩形的宽和高,LIOU 为IOU损失,Ldis 为距离损失,Lasp 为边长损失,γ 是一个用于控制曲线的超参数[11]。
改进后的YOLOv8算法结构如图3所示。
3 实验与结果分析
3.1 数据集
CCTSDB,即中国交通标志检测数据集(CSUSTChinese Traffic Sign Detection Benchmark) ,是由长沙理工大学相关学者及团队制作而成的[8]。本次实验使用的是CCTSDB 2021 数据集,其中包含17 856 幅图像,包括训练集和测试集。训练集图像有16 356幅,测试集图像有1 500幅,标注了常见的指示标志、禁令标志及警告标志等三大类交通标志[8]。数据集中既有未经任何修饰的原始图片,也有通过横向拉伸或缩小来改变尺寸的图片,添加了椒盐噪声以模拟图像传输中可能产生的失真效果的图片,以及调整亮度以展示不同光照条件下图像表现的图片。此外,还对一段真实的行车视频进行了逐帧抽取,并将这些帧转化为图片,以此模拟实际驾驶环境中可能遭遇的各种挑战。
3.2 评价指标与实验参数
本文采用均值平均精度(mean Average Precision,mAP) 作为模型的评价指标,包括mAP@0.5与mAP@0.5:0.95。计算方式如下:
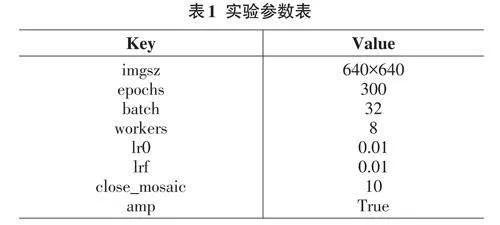
其中,TP 为检测正确的目标数量,FP 为检测错误的目标数量,FN 表示漏检数量。Precision衡量正确识别的比例(准确率),Recall衡量找到所有正例的能力(召回率)。AP 是precision-recall曲线与X轴包络的面积,衡量整体性能。K 代表类别数量。mAP@0.5是在IoU(Intersection over Union) 阈值为0.5时计算的平均精度,而mAP@0.5:0.95 则是在IoU 阈值从0.5 到0.95的范围内,计算所有类别的平均精度均值。本次实验所使用的部分参数如表1所示。
3.3 实验结果及分析
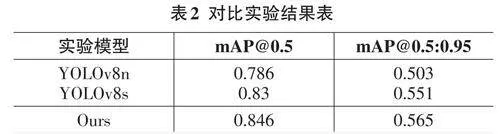
在上述条件下,使用YOLOv8s模型进行实验,训练并测试模型性能。对YOLOv8n、YOLOv8s以及改进的YOLOv8s算法进行比较,结果如表2所示。
通过对比试验可以得出,在CCTSDB 2021数据集上,mAP@0.5和mAP@0.5:0.95的数值相比于原模型均有所增长。从图4中可以直观且清晰地体现检测效果,改进后的模型在检测准确率方面相较于原模型有了显著提升。
4 结束语
针对当前道路交通标志识别所面临的难题,提出了一种基于改进YOLOv8s的交通标志识别算法。在Backbone网络中,引入RFCAConv,有效提升了模型对交通标志特征的提取能力;采用SPPFCSPC模块替代传统的SPPF模块,进一步提高了特征融合的效率;摒弃原有的回归损失函数,转而采用Focal-EIOU损失函数,从而提升了网络的收敛速度和检测精度。通过在CCTSDB 2021数据集上的实验验证,效果指标均有所提高。然而,改进后的网络结构在计算量和对计算机资源的占用上相较于原结构略有增加,仍有进一步优化的空间。
