
基于YOLOv5的吸烟行为识别检测系统分析与实现
2024-12-20 00:00:00程策刘庆海陈永腾李晓璇
电脑知识与技术 2024年30期


关键词:目标检测;YOLO;行为识别;计算机视觉
0 引言
随着社会的发展和公共卫生意识的提升,烟草控制成为全球范围内的重要议题。公共场合禁烟政策的实施,旨在创造一个更加健康的环境。然而,传统的吸烟监测方式多依赖于人工检查,既耗时又效率低下。因此,如何科技化、自动化地检测吸烟行为,成为研究的热点。近年来,深度学习技术的迅猛发展为解决这一问题提供了新途径。特别是在计算机视觉领域,基于深度学习的目标检测算法已经显示出其强大的应用潜力[1]。
在此背景下,本文提出一种基于YOLOv5的吸烟行为识别检测系统。YOLOv5作为目前先进的目标检测算法之一,以其高效率和准确性在多个领域得到应用。人们进一步通过引入YOLOv8的C2f模块,增强了系统对吸烟行为的检测能力。本文旨在通过精确快速地识别公共场所的吸烟行为,辅助执行禁烟政策,并促进公共卫生的提升。
本研究将详细介绍吸烟行为检测的意义、研究背景,以及基于YOLOv5的检测系统的创新点。通过深入分析,旨在展现本研究的价值和实际应用前景,为后续研究提供参考。
1 研究内容概述
本研究基于OpenCV+Jupyter Notebook+Labelimg 方式将自己收集的图片和视频进行RGB转换、抽帧、保存、标注并导出符合YOLO格式DR2AW0N438rBnh9IEf3Ycg==的.txt文件和.jpg文件作为训练数据集。利用Python语言基于YOLOv5s 模型来识别吸烟行为,本系统会对进入检测区域范围的人进行信息捕捉采集,将采集到行为信息进行相应的数据处理,并将其送到YOLOv5骨干网络的深度卷积网络(CSPDarknet[2]) ,对输入图像进行特征提取。 骨干网络的输出会传递至特征融合模块(具有FPNlike结构),不同尺度的特征经过处理后融合在一起。经过融合的特征图会被送入一系列的卷积层中,这些卷积层会为每个网格点预测若干个边界框,每一个边界框包含物体的位置、尺度、类别等信息。在预测结果中,选择置信度超过一定阈值的边界框,使用非极大值抑制(Non-Maximum Suppression,NMS) 来去除重复的检测结果,最终剩下的边界框和对应的类别就是YOLOv5模型的检测结果。并将YOLOv8的block文件下的C2f[3]模块导入到YOLOv5骨干网络中改变网络结构,利用创建带有YOLOv8的C2f(Coarse to Fine) 模块的.yaml文件训练数据集。达到特征提取值、图像分类等更加快速、更加准确,来优化YOLOv5网络结构的整体性能。
2 YOLOv5模型优化
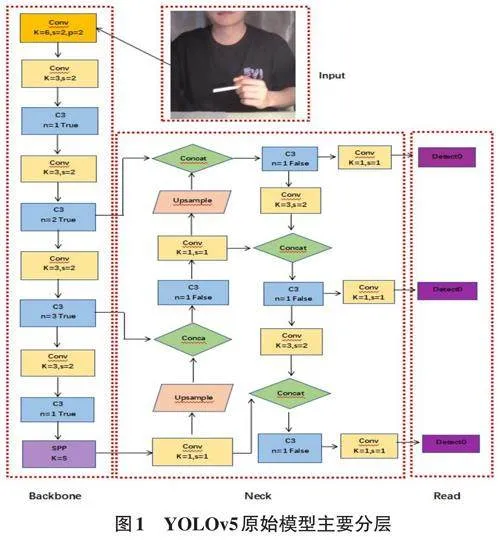
2.1 YOLOv5原始模型
YOLOv5的原始模型如图1,构成主要分为四个层次[4]:输入端(Input)、骨干网层(Backbone)、中间层(Neck) 和头层(Head)。在 YOLOv5 网络中,C3[4]模块是一个包含三个卷积层的模块,每个卷积层后都跟随着一个批量归一化层和一个激活层。C3模块以残差连接的方式接入网络,以增强模型的特征提取能力。在模型的 Head 部分,C3 模块主要负责提取图像的纹理特征,这些细节特征用于模型在执行具体任务(如物体检测、分类)时对对象的细微差别进行区分。在模型的 Backbone 部分,C3模块则担任着提取更高层次,更抽象的语义信息的任务,如物体的整体形状、物体的种类等特征。同时,由于 Backbone 部分的作用主要是提取图像中的全局和语义信息,所以在这里的C3 模块、位置信息和细节信息的比例相对较小。
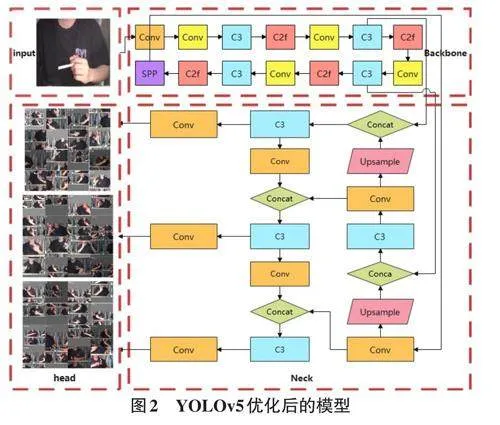
2.2 YOLOv5优化模型
本文基于吸烟行为的检测,而香烟在提取图片中属于小目标,在深度学习的目标检测模型中,小目标因其少量的像素信息和在卷积层中经多层提取后易于丢失的特性,较难检测。在YOLOv5中,C3模块[4](CSP Bottleneck with 3 convolutions) ,即带有三个卷积层的CSPNet(Cross Stage Partial Network) 瓶颈模块,要负责进行特征提取和特征的融合。但在C3的空间分辨率是有限的,在卷积神经网络中,随着层次的加深,特征图通常会经过多次下采样处理。这种设计使网络可以学习更加抽象的语义信息,但同时也可能导致小目标的空间信息丢失。用于小目标特征提取的过程中尤其是通过多层网络传递时,细微的特征可能会逐渐消散,对小目标来说这一点尤为重要。
C3模块虽然通过部分跳连设计改善信息流动,但是依然无法完全避免在深层网络中信息的逐步丢失,会导致小目标的位置和特征信息退化。为了提高对香烟检查的识别速度和精度,本文基于大量的实验求证并优化了YOLOv5结构模型,将YOLOv8的C2f模块加入YOLOv5的Backbone层中,如图2所示,这样有效地加快类似香烟的小目标检测和细致边界的划分。C2f模块可以在不同分辨率级别上提取不同大小的特征,可以提升YOLOv5目标检测的整体性能。YOLOv5 采用了卷积神经网络(CNN) 进行图像处理和特征提取。由于C2f模块首先在较低分辨率上快速识别设定的倾向区域,然后在这些区域以更高分辨率进行精细分析,因此可以减少在高分辨率下需要处理的数据量,极大地提升计算效率。通过在粗糙级别上先进行检测,然后对检测结果进行精修,增强模型对于噪声和其他干扰的鲁棒性,并有助于减小误检和漏检的情况。在粗糙到精细的过程中不断修正和优化目标的位置和大小,提高系统在香烟小目标定位的精度,特别是在复杂背景、边界模糊和手部遮挡的情况下。通过在粗糙阶段减少计算负担,C2f可在有限的计算资源下进行更高效的运算,这对于有资源限制的设备或系统非常重要。C2f模块与YOLO系列的结合在计算机检测的相关领域中取得了诸多成果。
2.3 C2f 模块
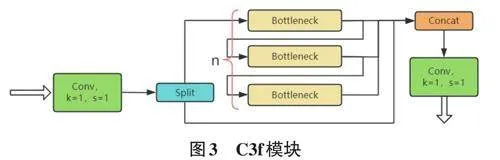
针对类似香烟的小目标,在数据处理流经太多的C3模块的深度学习目标检测模型中,小目标因其少量的像素信息和在卷积层中经多层提取后易于丢失的特性,较难检测。而基于YOLOv8的C2f模块,如图3 所示,可以在特征传递的过程中逐步集成更细粒度的信息,帮助模型更好地理解和重建图像的细节并提高YOLOv5对小目标的检测能力[3]。
C2f类是一个建立在nn.Module基础上的高级模型类,专门设计来实现CSP Bottleneck结构中的两个关键卷积层。在其初始化方法init中,这个类接收多个参数:c1代表输入特征图的通道数,c2为输出特征图的通道数,n 指定了Bottleneck 模块重复的次数,shortcut表示是否采用shortcut[3]连接以促进梯度流动和特征重用,g 为卷积操作的分组数,而e 是决定隐藏层通道数的扩展因子。
构造过程首先是依据扩展因子e来确定隐藏通道数self.c,这一步骤是为了调节模型的宽度以适配不同的运算需求。紧接着,类中设立了两个专门进行1x1 卷积操作的卷积层self.cv1和self.cv2。这两层的职能是对特征图进行有效的通道数调整和特征提取。此外,通过nn.ModuleList,我们创建了一个包含n 个Bottleneck模块的列表self.m,这个列表是CSP Bottle⁃neck结构的核心,每个模块都对特征进行深入的分析和处理。
在前向传播函数forward中,模型首先将输入的特征图x通过self.cv1卷积层进行处理,这一步不仅调整了特征图的通道数,还将信息按通道维度一分为二。
接下来,我们将其中一部分特征图作为输入,依次传递给self.m中的每一个Bottleneck[3]模块,并将各模块处理后的输出收集到列表y中。在获取到所有必要的特征输出后,最后一步是将这些特征图沿通道维度进行拼接,然后通过self.cv2卷积层进行最终的输出特征图整合与调整,生成最终的输出结果。
2.4 框的回归损失(Box Regression Loss)
用于最小化预测的边界框和真实边界框之间的误差[5]。YOLOv5 使用 CIoU 损失(Complete Intersec⁃tion over Union Loss) 来计算边界框的损失,以提升模型的定位准确性。在 YOLOv5 中,框的回归损失是指预测的边界框(Bounding Box) 和真实边界框之间的误差,这种误差用于训练模型以便更准确地定位对象。YOLOv5 使用的是完整的IoU(Intersection over Union) 损失[1],又称为 CIoU Loss。CIoU 损失的计算公式如下:
式中, b 代表预测的边界框,b_GT 是标注的真实边界框,ρ 是两个边界框中心之间的距离,c 是对角线长度,v 是边界框的宽高比之间的差异。传统的 IoU 损失仅考虑了预测边界框和真实边界框之间的交集和并集,而 CIoU 损失则更进一步,同样考虑了边界框的中心点距离以及宽高比例之间的差异。使用CIoU 损失的优点是,模型可以在训练过程中同时考虑到目标的位置,形状以及大小,进一步提高了定位的准确性。
3 仿真实验
3.1 搭建模型测试平台
YOLOv5模型的训练需要针对实际训练的物理环境,进行相应的调整,使训练效果达到最大化。所以综合各种因素--weights权重文件选用官方预训练完成的yolov5s.pt 文件。--epochs 设置为100 轮,--batch-size调成一次16张。随后,模型训练过程采纳了余弦退火[5](Cosine Annealing) 策略来动态地调整学习率。这种方法模仿了退火过程中温度的周期性变化,将学习率随着每一次迭代缓慢降低,类似于温度在一个周期中逐渐减小直至接近零的过程。通过这样的策略,学习率能够在训练过程中实现更加精细的调节,从而在初期快速下降探索优化方向,在后期则更细致地进行搜索,避免过早陷入局部最优。这不仅提升了训练的效率,同时也增强了模型在未知数据上的泛化能力。搭建模型测试平台配置如表1所示。
3.2 数据集预处理
数据集收集分为两部分,其一是将网络中1 866张吸烟图片,使用LabelImg标注工具来图像数据。对于每一个目标,绘制一个紧密围绕目标的边界框(Bound⁃ing Box) 并标注其类别。保存标注信息为YOLO格式,即每个图像文件生成对应一个同名的.txt文件,其中包含类别索引和归一化的边界框坐标( ) 。其二利用摄像机分别录制向阳处、背光处、近处和远处的视频,利用openCV对视频进行切割提取,按照从0帧开始,每间隔2帧抽取1帧进行抽帧。并用Jupyter Notebook 将录像中每帧呈现的图片进行RGB的颜色转换。将两部分的数据集去除自动生成图像中不清晰的图像,确认所有图像都符合YOLOv5要求的格式和色彩空间。将数据集中的images文件夹的图像和labels文件夹中的标签按照比例7:3的方式划分为训练集(train) 和验证集(val) 。按照YOLOv5的要求创建datasets数据集,并创建两个子文件夹一个images文件夹和一个labels文件夹,并在这两个文件夹中保持相同的目录结构。最后编辑YOLOv5的.yaml配置文件,指明训练集、验证集的路径,以及类别的名称和数量[1]。
3.3 实验结果分析
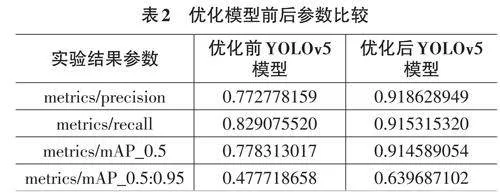
为验证本文章被提到的优化后的YOLOv5模型的性能,本实验通过该模型与优化前的YOLOv5模型进行了对比实验[6,7]。为了实验结果尽最大可能的准确,在实验中应尽可能地将一系列的参数保持统一。其中两者的--epochs均设置为100轮,--batch-size均调成一次16张。实验结果参数如表2所示,两者在pre⁃cision(准确率),recall(召回率),mAP_0.5(IoU阈值被设置为0.5),mAP_0.5:0.95(IoU 阈值从0.5 到 0.95,以0.05为步长增加)均相差较大。优化后YOLOv5模型相较于优化前YOLOv5模型在precision提升约0.15,在recall提升约0.09,在mAP_0.5提升约0.13,在mAP_0.5:0.95提升约0.16。说明优化后的模型可以使边界框的回归更加理想化,预测的准确率也使之提高。
接着让优化前后两个模型分别运行645张shape 为(1,3,640,640) 的吸烟行为图片,根据终端实时显示的结果分别如图4所示,明显可以看出优化后(图4b) 的推理时间为9.6ms比优化前(图4a) 的10.3ms降低0.7ms,并且优化后的模型运行NMS算法对结果进行优化去除重叠的预测框,只保留最佳的预测框花费的时间为1.3ms比优化前模型降低了0.8ms。可见优化后的YOLOv5模型相比于之前的模型在准确率、召回率、执行效率、检测精度和实时性能均表现出了明显的优势。
3.4 优化前后模型实验效果对比
截取了如图5所示的两种模型针对某段实验视频部分实验识别结果进行对此参考,直接生动地展示优化的提升效果。第一行为优化前模型截图,第二行为优化后模型截图。通过对比截图优化后的模型检测精确度明显提高。
4 结束语
本文利用YOLOv5基础上对吸烟行为识别与检测进行了相关研究,并在此基础上提出了一种关于YO⁃LOv5骨干网络的改进方法。向YOLOv5网络结构中添加YOLOv8中的C2f模块改变网络结构,优化YO⁃LOv5网络结构的整体性能。C2f模块工作时,更高层的特征会通过上采样扩大到与下一层相同的空间维度,然后与下一层的特征进行融合,这通常通过特征图的逐元素加法或者卷积操作来完成。这样逐层向下,最终形成一个融合了多尺度信息的特征图,提高了模型对不同尺度目标的检测能力。相比于原始YOLOv5 模型无论是在precision,recall 还是在mAP_0.5,mAP_0.5:0.95 都得到了一定提升。在mAP_0.5:0.95的实验结果达到了63.97%,这很大程度上提高模型检测香烟的准确性,完成了该研究的指定目标,达到了预期效果。该研究通过解决吸烟行为检测这一具体问题,对YOLOv5模型的适应性、精度及实时性进行了深入分析和优化,为相关领域的学者提供了有价值的研究参考和新的研究方向。
本实验研究过程中,尚且存在一定的不足,比如对CSPDarknet网络结果掌握度欠缺,在数据集收集过程中还是缺少对像恶劣天气等综合环境的考虑,导致在实验设计中部分模块与实际环境结合较难实现。接下来,本项目将深入了解并研究环境对吸烟行为数据采集的影响,逐渐完善该系统模型,并进一步提高该模型的综合性能。
