
基于NeRF算法的三维模型重建系统发展现状
2024-12-20 00:00:00陈劲松霍振浩闫琦昊龚诚信王鹏翔
电脑知识与技术 2024年30期
关键词:NeRF算法;神经网络;图形渲染;三维模型重建
0 引言
通过图像特征点对图像进行合成是一个重要问题。通过对三维物体拍摄图片,并基于特征点合成三维模型,该模型包含几何形状、颜色等特征。通过合成模型,可以观察到未拍摄到的点的特征,并经过mesh网格化处理,最终得到打印物体的模型文件。相比传统的逆向工程成型,此方法仅需少量照片即可生成较为真实的模型文件。
经过多年的研究,已有多项相关成果。最初,通过图片拼接形成三维图像,但此方法对拍摄要求高且合成效果欠佳[1]。随后,光线追踪方法出现,该方法在物体中选择大量像素点,通过像素点发射光线投影至虚拟三维空间,并通过从与几何体的交点递归投射新光线来模拟反射和折射[2]。最近,随着神经网络算法的快速发展,通过神经网络训练模型,使用训练好的模型对图像进行三维渲染[3]。通过深度学习训练的模型,提高了合成模型的准确性。NeRF是一种用于3D 重建和视图合成的深度学习方法,其基本思想是使用深度神经网络来表示场景的体积密度和颜色,然后通过这个表示来合成新的视角图像。
1 基于NeRF 算法的三维重建
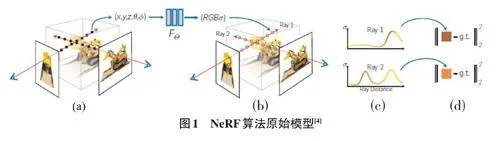
NeRF 算法的本质其实就是对图形进行三维渲染,通过将神经隐式场表示,可以对模型产生新的视角和光照效果等[4]。采用回归方法,可以将模型边缘图像化,并且通过一个距离函数对三维模型进行表示,将复杂的问题变为一个二分类问题[5]。这种方法能够连续表示三维模型的边缘,即使对于形状复杂的模型也能有效建模。利用图像边缘像素进行曲线拟合,可生成物体的轮廓模型。原始模型如图1所示。
通过将原始模型文件导入图形中,将实际模型作为训练模型的监督。通过实际与原本模型文件的误差直接对神经网络模型进行训练。NeRF通过多层感知机方法表达出了一个五维向量模型[6],可以描述模型的密度函数表示是否透光、颜色以及描述点的坐标值,最终通过输入空间某一点的位置向量,得到以位置密度以及该位置颜色的RGB数值。通过梯度下降算法,对预测图像与真实图像进行拟合[7]。
2 发展现状
鉴于NeRF算法结构简单且合成效果优良,众多研究者致力于对其进行优化与提升。通过对NeRF方法中的位置特征进行重新编码,可以显著提升原有精度。Schwarz K等人[8]通过引入基于图形特征的合成器,成功合成了高分辨率图像,仅需少数几张图片即可实现,从而增强了渲染内容的分辨率。
在生成实体模型并进行网格化处理时,模型所生成的环境模型也是一个干扰因素。Niemeyer M等人[9]通过NeRF算法,将物体与背景分别分为两个部分,这样可以随意将背景与物体随意组合,生成一个全新的训练集进行训练。这种方法能够改变场景中物体的相对位置,生成全新的图像,并允许对模型的形状和外观进行调整,从而丰富了训练集数据,提升了训练精度。
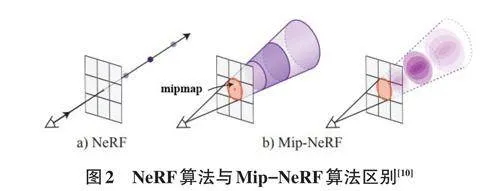
Barron J T等人[10] 针对NeRF算法在不同分辨率下观察场景内容时,单个光线采样可能导致的渲染模糊或锯齿问题进行了研究。传统解决方法通过增加每个像素的光线数量进行超采样,但渲染每条光线需多次查询多层感知器,对NeRF而言效率较低。Mip-NeRF引入了一种类似于多级渐进纹理映射(mipmap) 的方法扩展NeRF,有效处理了抗锯齿问题。该方法通过在不同尺度上表示场景,使NeRF能够更高效地处理不同分辨率下的场景内容,提高了渲染质量,减少了模糊和锯齿现象。两种的算法区别如图2所示。
苗源等人[11] 通过神经网络模型提高了光场数据的角度分辨率,进而改善了三维重建的质量,使其分辨力得到显著提升。研究中采用双平面参数化光场数据来训练NeRF模型。NeRF模型能够隐式地表达光场场景,并为高分辨率的四维光场拟合出准确的隐式函数。通过位置编码,输入变量被映射到其傅里叶特征,使模型能够有效处理场景中的高频纹理信息。该方法的主要优势在于能够通过NeRF隐式地表示光场场景,避免了图像采集过程中可能引入的误差和噪声。此外,该方法还提高了后续三维重建的准确性和质量。
范腾等人[12]发现,在多尺度视图合成任务中存在模糊和锯齿问题,这主要是由于NeRF在每个像素上仅对一束光线进行采样,导致在渲染不同尺度的场景时出现信号混叠和视觉质量问题。为此,他们提出了一种多尺度神经辐射场(MS-NeRF) 框架,利用多级小波卷积神经网络提取不同尺度目标视图的特征,并将这些视图特征作为先验信息对网络合成目标场景视图进行监督。同时,扩大视点相机发出的光线在目标视图像素点上的采样面积,以避免渲染结果产生模糊和锯齿。在训练过程中,加入不同尺度的视图特征和视点特征,提升了网络合成不同尺度视图的泛化能力,并利用渐进式结构的深度神经网络拟合视图特征和视点特征到目标视图的映射关系。
3 发展趋势
3.1 基于NeRF 的多模态融合
多模态融合是指将来自不同传感器或不同类型数据源的信息结合起来,以获得比单一模态更加丰富和准确的结果。在计算机视觉、机器学习和人工智能领域,多模态融合被广泛应用于图像识别、语音识别、自然语言处理等方面。
在NeRF的背景下,多模态融合利用不同光谱敏感性的传感器信息,获得统一的跨光谱场景表示。这种方法允许对任何单一观测点进行查询,获取跨光谱的图像信息。在利用不同光谱敏感性的传感器信息时,需要处理不同传感器间分辨率、视场(FoV) 等差异,并随时获取任意相机图像用于训练NeRF的确切相机姿态[13]。
3.2 基于NeRF 的动态场景的三维重建
由 NeRF 的原理可知,它是通过多张图像上拥有相同的特征元素来对模型进行重建。当场景是动态场景时,很难对几何物体进行合成。所以,对动态场景的表达也是一个重要的研究方向。在视频拍摄过程中,随着相机移动,场景中的物体也在移动,目标是通过视频合成得到任意时刻、任意视点的图像。最直接的方法是将视频划分为小的时间段进行处理[14]。然而,由于短时间内场景观察角度有限,理论上每小段视频都能生成重建模型,导致模型数量庞大。为此,一种解决方案是对视频每一帧进行深度估计,以此对NeRF进行约束。但这种方法依赖于显式的深度图,需先训练动态场景深度估计网络,且结果受深度图估计准确性的影响。
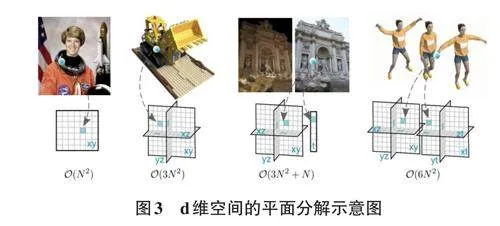
针对动态场景,Fridovich-Keil S等人[15]提出了KPlanes算法,该算法是一个在任意维度上对辐射场进行显式表示的模型。其算法利用d-choose-2平面来表示一个d-维场景,使模型能够从静态场景(d=3) 无缝过渡到动态场景(d=4) ,并且能够在空间、时间和外观上精确捕捉和表现场景的变化。K-Planes模型的特点是其平面分解方法,这种方法不仅简化了时间平滑性和多分辨率空间结构,而且还实现了场景中静态和动态成分的自然分解。所以K-Planes模型能够更有效地处理随时间变化的复杂场景外观。K-Planes 模型还通过线性特征解码器和学习到的颜色基础来产生类似的视觉效果,进一步增强了在处理空间、时间和外观变化方面的能力。K-Planes模型为辐射场的表示提供了一种新的方法,特别是在处理动态场景和复杂外观变化方面展现了极大的潜力和优势。
3.3 基于交互式和实时渲染的三维重建
基于NeRF的交互式与实时渲染是当前计算机图形学与计算机视觉领域的研究热点。为实现实时渲染,须优化NeRF算法以减少渲染时间和计算资源消耗。这包括改进神经网络结构、采用高效采样策略以及利用多尺度表示和层次细节技术来加速渲染过程。动态场景的处理是NeRF面临的挑战之一,特别是在如何实时更新和渲染动态变化的三维场景以适应实时交互需求方面。随着云计算技术的发展,将NeRF 渲染部署于云端并通过流式传输至用户设备,可减轻用户硬件负担,同时提供高质量的渲染体验。基于NeRF的交互式与实时渲染技术正朝着更快、更真实、更易于交互的方向发展。
3.4 基于NeRF 大规模场景重建发展趋势
基于NeRF(Neural Radiance Fields) 的大规模场景重建是近年来三维视觉领域的研究热点。为处理大规模场景,研究者们提出了多尺度和多分辨率的处理方法。例如,在预训练阶段使用特征网格对目标场景进行建模,捕捉场景的几何形状和外观,然后在联合学习阶段利用NeRF分支网络进行更精细的抽样和渲染。这种方法有效处理了大规模城市场景,同时保持了高保真度的渲染效果。随着硬件性能的提升和算法的优化,基于NeRF的大规模场景重建将更加注重交互式与实时渲染的能力。这将使用户能够在虚拟现实、增强现实等应用中实时与三维场景交互,提供更加沉浸式的体验。
4 结束语
随着NeRF技术的不断进步,将其与三维重建相结合,极大地加速了模型文件逆向工程的速度。借助神经网络强大的能力,通过对大量照片数据的深入分析和学习,随着输入照片数量的增加,模型的学习效果显著提升。并且,随着新算法与硬件的不断涌现,基于NeRF的三维重建技术将持续优化,为未来的三维重建领域带来更多创新与突破。
