
基于强化学习的数据中心能耗优化调度策略研究
2024-12-18 00:00:00杨鸥羿
无线互联科技 2024年23期




摘要:随着云计算的飞速发展,数据中心能耗问题日益突出,亟须探索更加智能高效的节能优化新方法。文章分析了数据中心的能耗问题,阐述了强化学习技术在数据中心能耗调度中的应用潜力,构建了一个涵盖服务器、制冷等关键设施的数据中心系统模型并基于该模型搭建了一个精细化的数据中心能耗评估框架,将调度问题形式化为一个马尔可夫决策过程,设计了一种融合图神经网络与长短期记忆网络的深度强化学习算法,最后搭建了仿真平台验证所提出策略的有效性。
关键词:数据中心;能耗优化;强化学习;调度策略
中图分类号:TP39""文献标志码:A
0"引言
高额的电力成本不仅增加了数据中心运营开支,也带来了巨大的碳排放,引发了环境可持续发展的隐忧。因此,如何在保障数据中心服务质量的同时最小化其能源消耗,已成为学术界和工业界共同关注的研究课题。近年来,强化学习以其从环境反馈中自主学习最优控制策略的能力,在众多序贯决策问题上取得了丰富进展。本文针对数据中心能耗优化这一挑战,基于一种多技术融合驱动的深度强化学习调度架构,提出了创新的强化学习驱动的闭环自优化调度方法,为算法评测提供了稳定的实验环境,亦期望所构建的端到端闭环自优化系统框架,能够对传统的基于模型预测或反馈控制的能效管理方法形成有益补充[1]。
1"数据中心能耗问题分析
数据中心的能耗问题主要体现在以下几个方面:(1)核心设备服务器能耗在数据中心总能耗中的占比高达50%以上,受限于服务器芯片制造工艺和材料性能,其能效提升的空间已十分有限;(2)制冷系统能耗占数据中心总能耗的比例可达30%~50%。传统的制冷方式(风冷、水冷)能效比(PUE)普遍较低,导致大量能源被浪费;(3)数据中心workload呈现显著的动态性和突发性,其负载水平常在20%~80%大幅波动,低负载下的能效比会急剧下降。
2"强化学习及其在本研究中的基本应用思路
2.1"强化学习的基本原理
强化学习是机器学习的新分支,其核心思想是:智能体感知环境状态(State)并根据当前策略(Policy)采取一个动作(Action),环境对该动作做出反馈,返回一个即时奖励(Reward)和新的状态。智能体根据奖励信号不断调整策略,最终学习到一个最优策略,使累积奖励最大化。马尔可夫决策过程(Markov Decision Process,MDP)为强化学习提供了理论基础,MDP由状态空间、动作空间、状态转移概率和奖励函数构成,满足马尔可夫性质,即下一状态仅取决于当前状态和动作[2]。
2.2"基本应用思路
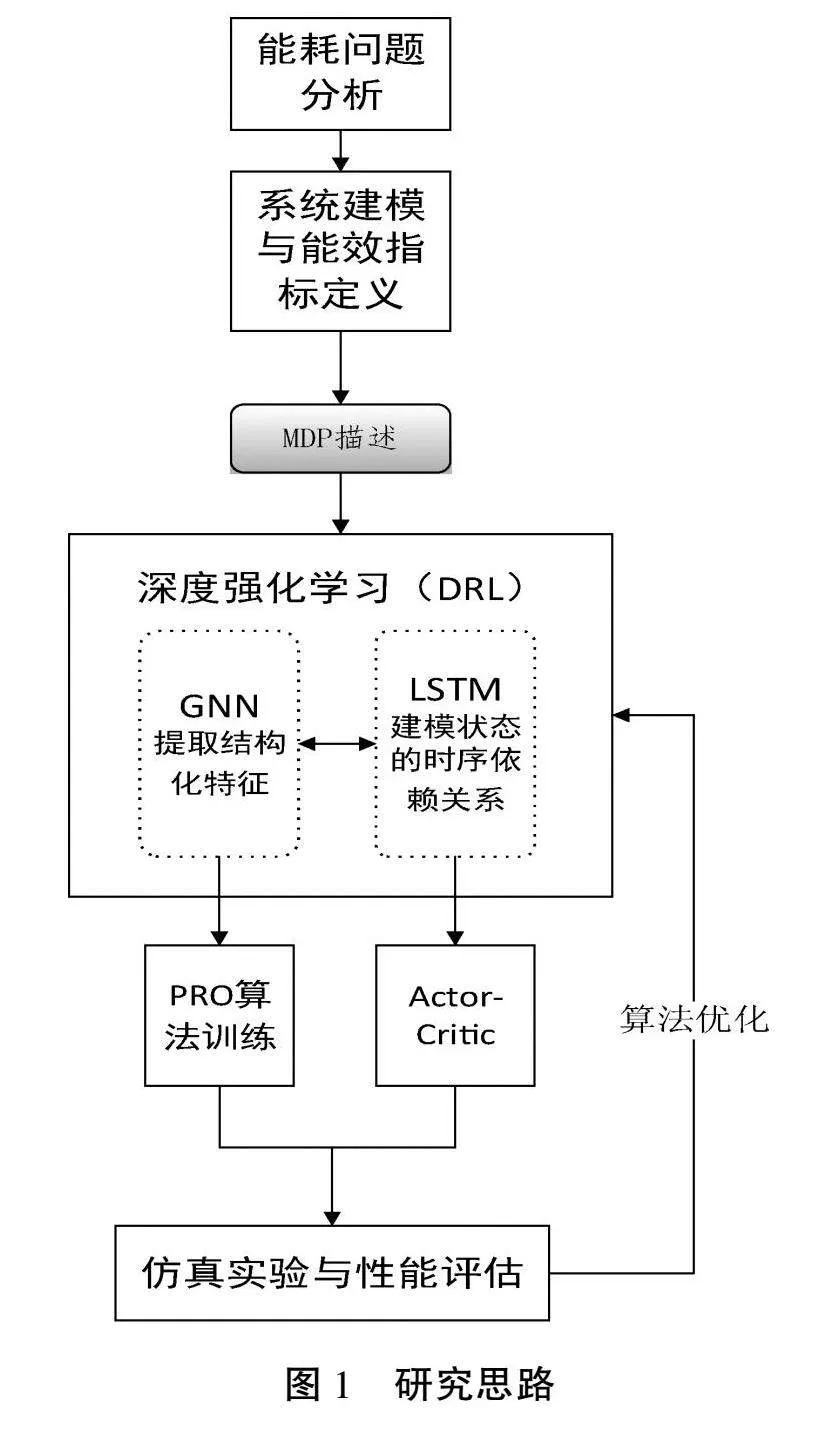
如图1所示,本文的研究思路可归纳为以下几个关键环节。
(1)数据中心能耗问题分析:深入剖析数据中心能耗问题的成因、特点及技术挑战,为后续研究奠定问题基础。
(2)系统建模与能效指标定义:针对数据中心的IT、制冷、供电等子系统,构建细粒度的系统模型,提出全面的能效评估指标体系。
(3)马尔可夫决策过程(MDP)描述:以MDP为理论框架,将数据中心能耗调度问题进行形式化描述,设计紧凑的状态空间、动作空间和奖励函数。
(4)深度强化学习(DRL)算法设计:面向MDP模型,创新性地设计融合图神经网络(GNN)、长短时记忆网络(LSTM)、近端策略优化(PPO)和Actor-Critic架构等前沿技术的DRL优化算法。其中,GNN负责提取系统状态的结构化特征,LSTM负责建模状态的时序依赖关系,PPO和Actor-Critic则保证了策略训练的高效稳定。
(5)仿真实验与性能评估:搭建逼真的数据中心仿真平台,使用真实世界的负载轨迹数据,全面评估DRL调度算法的性能,验证其在降低能耗、保障服务质量等方面的优越性。
宏观层面来看,数据中心能耗问题分析是整个研究的逻辑起点,它为系统建模、MDP描述等后续环节提供问题背景和优化目标。而仿真实验与性能评估则是研究的逻辑终点,通过定量分析论证本文所提方法的可行性和有效性。由此,在目标驱动和闭环反馈的研究范式下,本文形成了一套完整的、具有普适性的数据中心能耗优化问题求解方法。
3"数据中心能耗优化调度模型构建
3.1"系统模型的构建
为了对数据中心能耗优化调度问题进行建模和求解,首先构建一个数据中心系统模型。该模型涵盖了数据中心的各个关键组件,包括物理服务器(Physical Machine,PM)、虚拟机(Virtual Machine,VM)、制冷设备(Computer Room Air Conditioning,CRAC)等。采用一个三元组(S=lt;P,V,Cgt;)来表示数据中心系统,其中P=p1,…,pM,表示共有M台物理服务器;V=v1,…,vN,表示共有N台虚拟机;C=c1,…,cK,表示共有K台CRAC。
对于物理服务器,主要关注其多维资源容量(如CPU、内存等)和功耗特性,用分段线性函数来拟合服务器功耗Pm与CPU利用率um之间的非线性关系:
Pm(um)=P0m+P10m-P0m10%um,0≤umlt;10%
…
P90m+P100m-P90m10%(um-90%),90%≤um≤100%
对于虚拟机,借鉴通用做法,假设虚拟机请求到达服从泊松过程,持续时间服从指数分布。
对于制冷设备,假设制冷量与能耗成正比:Qk=ηkPk。其中Qk表示制冷设备ck的制冷量,Pk表示其能耗,ηk表示其能效比(COP)。COP与CRAC的工况和环境温度相关,可从设备手册或实测数据获取。在此基础上,数据中心能耗优化调度问题可形式化为一个混合整数规划模型[3],目标是在满足各类约束条件(如资源容量约束、服务质量约束、温度约束等)的前提下,最小化数据中心总能耗:
min"∑Mm=1Pm(um)+∑Kk=1Pk
3.2"能耗模型的构建
在系统模型的基础上,进一步构建数据中心能耗模型,用于准确评估不同调度策略下的能耗表现。结合前文的功耗拟合函数,物理服务器Pm的能耗表示为:
Pm=ymPm(um)=ymPidlem+∑Ll=1PBlm-PBl-1mBl-Bl-1(um-Bl-1)
其中,ym表示服务器的开关机状态(ym=1表示开机,ym=0表示关机);L表示功耗拟合函数的分段数;Bl表示第l段的利用率断点。
根据前述热平衡原理,设定制冷设备的耗电量与其抽取的热量成正比(Pk=Qk/ηk)。其中,制冷设备的制冷量Qk可通过机房的总热负荷Qtotal和该设备所占的制冷份额αk计算得到,即Qk=αkQtotal。机房的总热负荷包括IT设备的发热量和其他杂热Qother,可表示为:
Qtotal=∑Mm=1Pm+Qother
将上式代入,即可得到制冷设备ck的能耗计算公式:
Pk=αkηk(∑Mm=1Pm+Qother)
综合IT设备能耗和制冷能耗,数据中心的总能耗PDC可表示为:
PDC=∑Mm=1Pm+∑Kk=1Pk=1+∑Kk=1αkηk∑Mm=1Pm+∑Kk=1αkηkQother
实际优化时可通过调整服务器的开关机状态、CPU频率、虚拟机放置等决策变量来降低IT设备能耗,通过优化制冷设备的送风温度、送风量等参数来提高其能效比。
3.3"马尔可夫决策过程的转化
上述系统模型和能耗模型可转化为一个马尔可夫决策过程。
(1)状态空间S包含了数据中心的各类状态信息,例如物理服务器的开关机状态、资源利用率、功耗,虚拟机的放置情况、资源需求,制冷设备的工况参数,机房的温度分布等。一个状态s∈S可表示为:
s=(y,u,x,d,q,T)
其中,y=(y1,…,yM)表示物理服务器的开关机向量;u=(u1,…,uM)表示物理服务器的利用率向量;x=(x11,…,xMN)表示虚拟机的放置矩阵;d=(d1,…,dN)表示虚拟机的资源需求矩阵;q=(q1,…,qK)表示制冷设备的工况参数;T=(T1,…,TI)表示各温度区域的温度值。
(2)动作空间A包含了数据中心可采取的各种调度动作,例如开关物理服务器、调整服务器的CPU频率、迁移虚拟机、调整制冷设备的送风温度和风量等。一个动作a∈A可表示为:
a=(Δy,Δf,Δx,Δq)
其中,Δy=(Δy1,…,ΔyM)表示对物理服务器的开关机操作;Δf=(Δf1,…,ΔfM)表示对服务器CPU频率的调整;Δx=(Δx11,…,ΔxMN)表示对虚拟机放置的调整;Δq=(Δq1,…,ΔqK)表示对制冷设备工况的调整。
(3)状态转移概率P(s′|s,a)刻画了在当前状态s下采取动作a后转移到下一状态s′的概率。模型中,状态转移涉及多个随机过程,包括虚拟机的到达和离去、服务器的故障和维护等,需要根据实际数据对概率分布进行估计或拟合。奖励函数R(s,a,s′)定义了MDP优化的目标,即在状态s下采取动作a并转移到状态s′后获得的即时奖励:
R(s,a,s′)=-PDC(s,a,s′),if满足所有约束条件
-∞,otherwise
其中,PDC(s,a,s′)表示在状态s下采取动作a并转移到状态s′后数据中心的总能耗。如果新状态满足所有约束条件(如物理资源容量约束、虚拟机性能约束、机房温度约束等),则奖励等于负的总能耗;否则,给予一个大的惩罚项(负无穷)。
4"基于深度强化学习的能耗优化调度算法
4.1"状态空间、动作空间和奖励函数的定义
在将数据中心能耗优化调度问题转化为马尔可夫决策过程后,进一步设计了基于深度强化学习的调度算法。
首先,对MDP的状态空间、动作空间和奖励函数进行明确定义,提出了一种层次化的状态空间表示方法:提取服务器的开关机状态ym、CPU利用率umcpu、内存利用率ummem、功耗Pm等特征;提取虚拟机的放置情况Xn、CPU需求dncpu、内存需求dnmem等特征;提取制冷设备的送风温度Tsup、送风量Vsup、COP等特征;机房环境中提取各温度区域的实时温度Ti、湿度Hi等特征。将特征按照一定顺序排列,即得到一个高维状态向量s:
s=[y,ucpu,umem,P,X,dcpu,dmem,Tsup,Vsup,COP,Ti,Hi]
其中,y、P、Tsup等均为列向量,X为矩阵,s的维度等于各分量维度之和。
动作空间的设计需要充分考虑数据中心的可控变量和调度约束,采用一种混合连续-离散的动作空间表示,既包括连续的资源调控动作,也包括离散的开关机和迁移决策。动作向量a包含4个部分:服务器的开关机动作Δy、服务器的CPU频率调整动作Δf、虚拟机的迁移动作ΔX以及制冷设备的送风温度和风量调整动作ΔTsup和ΔVsup:
a=[Δy,Δf,ΔX,ΔTsup,ΔVsup]
其中,Δy为二值向量,Δym=1表示打开服务器m,Δym=0表示关闭服务器m;Δf为连续向量,Δfmin∈[fmmin,fmmax]表示服务器m的CPU频率调整幅度;ΔX为整数矩阵,Δxmn表示是否将虚拟机n迁移至服务器m;ΔTsup和ΔVsup为连续向量,分别表示制冷设备的送风温度和风量调整幅度[4]。奖励函数的设计采用了一种加权求和的奖励函数形式,将各优化目标量化为对应的奖励分量,再赋予适当的权重系数进行组合。奖励函数r(s,a,s′)定义为:
r(s,a,s′)=∑Ni=1wiri(s,a,s′)
其中,N为优化目标数;wi为目标i的权重系数;ri(s,a,s′)为动作a在状态s下导致状态转移至s′后获得的第i项奖励分量。
4.2"深度神经网络的设计与训练
基于上述MDP建模,设计了一种深度强化学习算法来求解数据中心能耗优化调度问题。算法采用了Actor-Critic架构,即同时学习值函数和策略函数。Actor网络(策略网络)πθ(a|s)以状态s为输入,输出在该状态下采取动作a的概率分布;Critic网络(值函数网络)Vφ(s)以状态s为输入,输出该状态下的期望累积奖励值。
将数据中心环境建模为一个异构图G=(V,E),其中节点集V包括服务器节点、虚拟机节点和制冷节点,边集E包括服务器-虚拟机边、服务器-服务器边和服务器-制冷边等。每个节点和边都有一组特征向量,分别表示节点状态和边属性。利用图卷积神经网络(GCN)来学习图结构数据中的特征,得到节点的嵌入表示[5],捕捉节点之间的相互影响和关联性,聚合不同类型节点的信息,得到隐藏状态表示ht,输入Actor网络和Critic网络,得到动作概率分布πθ(a|s)和状态值函数Vφ(s):
πθ(a|s)=softmax(Wπht+bπ)
V(s)=WVht+bV
其中,Wπ、bπ、WV、bV分别为Actor网络和Critic网络的参数矩阵和偏置项。
在训练阶段,采用基于策略梯度和时序差分(Temporal Difference,TD)的方法来更新Actor网络和Critic网络的参数。对于一个状态-动作-奖励序列(st,at,rt,st+1)t=1T,Critic网络的损失函数Lossφ(s)定义为:
LossV()=1T∑Tt=1[V(st)-yt]2
其中,yt=rt+γV(st+1),为TD目标值。Critic网络的目标是最小化预测值函数与实际回报之间的均方误差。
Actor网络的目标是最大化期望回报,其梯度为:
θJ(θ)=Eπθ[θlogπθ(a|s)Qπθ(s,a)]
其中,Q为在策略πθ下状态-动作对(s,a)的期望回报,可以用Critic网络的输出VΦ(s)来近似。
上述神经网络模型和训练算在PyTorch框架下进行,使用近端策略优化(PPO)算法稳定Actor网络的训练过程。
4.3"在线实时优化调度策略的实现
为将训练好的强化学习模型应用到实际的数据中心在线调度中,本文设计了一套完整的实时优化调度系统,主要包括如下所述。
4.3.1"数据采集与预处理模块
负责实时采集数据中心各设备的运行数据(如服务器的CPU利用率、制冷设备的送风温度等),并对其进行清洗、归一化等预处理操作,将其转化为强化学习模型可接受的状态特征。使用Zabbix、Ganglia等开源监控软件采集数据,使用Kafka、Flume等消息队列和流处理工具预处理和缓存数据。
4.3.2"强化学习决策模块
加载预训练的Actor网络和Critic网络,根据当前状态特征生成调度决策。为了适应数据中心环境的非平稳性和不确定性,在决策过程中引入了滚动更新机制,即维护一个固定长度的历史决策序列,并根据最新的状态-动作-奖励样本来更新强化学习模型的参数。
4.3.3"调度执行模块
将强化学习模型给出的决策指令转化为具体的调度动作,并通过相应的接口或协议(如IPMI、SSH等)下发到各设备。调度执行模块与设备之间通过消息总线(如RabbitMQ)进行通信,以实现调度指令的异步下发和执行状态的实时反馈。
5"实验结果与分析
5.1"平台搭建
为评估所提出的调度策略,本文研究搭建了一个数据中心能耗优化调度仿真平台,使用真实的数据中心负载轨迹作为输入。将原始轨迹数据进行了清洗和预处理,提取了任务的资源需求和性能约束等关键特征,根据任务的提交时间戳,在仿真平台中动态生成相应的任务请求事件[6]。
5.2"对比实验
本文选取了3个典型的数据中心配置:小规模(500台服务器)、中规模(5000台服务器)和大规模(50000台服务器),分别代表不同层次的数据中心。在每个数据中心配置下,分别使用了Google Cluster Trace和Alibaba Cluster Trace作为工作负载输入,测试了以下6种调度策略。
(1)Round-Robin(RR):将任务按照先来先服务的原则,轮流分配到不同的服务器。
(2)Least-Loaded(LL):总是将任务分配到当前负载最轻的服务器。
(3)Genetic Algorithm(GA):使用遗传算法搜索最优的任务放置方案,适应度函数为总能耗。
(4)MILP:使用混合整数线性规划求解器,对任务放置和服务器开关机进行联合优化。
(5)TAA:本文提出的基于深度强化学习的任务分配智能体。
(6)TAA+DVFS:在TAA的基础上,增加动态电压频率调节(DVFS)的优化维度。
5.3"实验结果与分析
在单数据中心环境下,不同调度策略的能耗优化效果对比如表1所示。可以看出,研究的TAA和TAA+DVFS调度策略在单数据中心环境下取得了最优的能耗优化效果,与最简单的RR策略相比,最高可节省20.69%的能耗。这得益于强化学习模型从数据中自主学习并挖掘出了负载模式、设备特性等隐含的规律性知识,并通过端到端的训练将其内化于最终的调度决策。相比之下,传统的启发式调度算法(如RR和LL)缺乏对系统全局状态和长期收益的考虑,优化效果有限;基于数学规划的MILP算法尽管可以求得理论最优解,但在实际复杂环境中求解效率较低,且难以建模多样化的约束条件。
6"结语
数据中心能耗优化是一个复杂的系统工程,涉及IT、热力学、控制论等多个学科领域,需要软硬件设施与管理策略的协同创新。本文在已有研究的基础上,将前沿的强化学习技术引入数据中心能耗调度领域,提出了一种数据驱动、自适应的智能调度新范式。强化学习在数据中心能耗优化调度中的应用尚处于起步阶段,未来仍需在算法泛化、模型轻量化、部署工程化等方面开展深入探索。
参考文献
[1]徐基雅.基于空间位置的高性能计算集群能耗感知调度技术研究[D]. 济南:齐鲁工业大学,2024.
[2]吴金戈.基于深度强化学习的云资源调度方法研究[D]. 贵阳:贵州大学,2023.
[3]李丹阳,吴良基,刘慧,等.基于深度强化学习的数据中心热感知能耗优化方法[J].计算机科学,2024(增刊1):738-745.
[4]王东清,李道童,彭继阳,等.面向数据中心的服务器能耗模型综述[J].计算机测量与控制,2023(11):7-15.
[5]沈林江,曹畅,崔超,等.基于策略约束强化学习的算网多目标优化研究[J].电信科学,2023(8):136-148.
[6]刘陈伟,孙鉴,雷冰冰,等.基于改进粒子群算法的云数据中心能耗优化任务调度策略[J].计算机科学,2023(7):246-253.
(编辑"沈"强)
Research on data center energy consumption optimization scheduling strategy based on reinforcement learning
YANG "Ouyi
(University of Ottawa, Ottawa K1N 6N5,Canada)
Abstract: The rapid growth of cloud computing has exacerbated data center energy consumption issues,necessitating intelligent and efficient optimization methods.This paper analyzes the problem,explores the potential of reinforcement learning in energy scheduling, constructs a comprehensive data center model, formalizes the scheduling problem as a Markov decision process,and proposes a deep reinforcement learning algorithm combining graph neural networks and long short-term memory networks.Simulations verify the effectiveness of the proposed strategy.
Key words: data center; energy optimization; reinforcement learning; scheduling
猜你喜欢
机械研究与应用(2022年4期)2022-09-15 02:21:32
电子测试(2018年11期)2018-06-26 05:56:38
电子测试(2018年11期)2018-06-26 05:56:24
软件导刊(2017年10期)2017-11-02 11:22:44
现代电子技术(2017年15期)2017-09-04 15:47:05
上海海事大学学报(2017年2期)2017-07-14 22:19:44
中学课程辅导·教学研究(2017年13期)2017-07-01 14:50:34
大经贸(2017年5期)2017-06-19 20:06:37
湖南大学学报·自然科学版(2016年10期)2016-11-30 19:02:13
中国交通信息化(2015年3期)2015-06-05 03:53:30
