
基于机器学习的个性化图书馆资源推荐系统设计
2024-12-18 00:00:00艾里亚尔·阿不都克里木陈英杰
无线互联科技 2024年23期
摘要:随着信息技术的发展,图书馆面临资源管理和个性化推荐的挑战。传统推荐方法依赖人工规则或统计模型,难以满足用户的个性化需求。文章提出一种基于机器学习的个性化图书馆资源推荐系统,结合深度学习语言模型(如ChatGPT)对用户需求进行精准建模。通过分析用户行为数据和语义信息,文章设计了一种新的推荐框架,旨在提高推荐系统的智能化水平。实验结果表明,所提出的系统在推荐精度和用户满意度方面均显著优于传统方法,能够为用户提供更加个性化和精准的图书馆资源推荐。该研究为图书馆资源推荐系统的设计与优化提供了理论支持和实践指导。
关键词:机器学习;图书馆;资源推荐;ChatGPT;用户行为分析
中图分类号:G258.3""文献标志码:A
0"引言
随着信息技术的迅猛发展,图书馆在资源管理和服务提供方面面临着前所未有的挑战。传统的图书馆服务模式往往依赖于人工经验和静态的分类系统,难以满足用户日益增长的个性化需求。用户在海量信息中寻找所需资源的过程常常耗时且低效,导致用户满意度下降。因此,如何有效地管理和推荐图书馆资源,成为当前图书馆亟待解决的问题。
近年来,机器学习和人工智能技术的快速发展为图书馆资源推荐系统的设计提供了新的思路。机器学习能够通过分析用户的历史行为、偏好和社交网络等多维度数据,识别用户的兴趣和需求,从而提供个性化的资源推荐。这种基于数据驱动的方法,不仅提高了推荐的准确性,还能显著提升用户的资源获取效率[1]。特别是深度学习技术的进展,特别是语言模型的应用(如ChatGPT),为推荐系统的智能化提供了新的可能性。通过自然语言处理,推荐系统能够更好地理解用户的查询意图,生成更符合用户需求的推荐理由。这种基于交互的推荐方式不仅有效提升了用户的使用体验,也使推荐系统具备了更高的智能性和灵活性[2]。
在此背景下,本文旨在设计一个基于机器学习的图书馆资源推荐系统,探讨其数据收集、处理及推荐算法的实现。文章将重点关注如何利用用户行为数据和先进的机器学习技术,构建一个高效、智能的推荐系统。通过对用户行为的深入分析,系统能够提供个性化的推荐,满足用户的需求,进而提升图书馆资源的利用率。
此外,本文还将探讨如何将ChatGPT等前沿的人工智能技术与推荐系统相结合,以提升推荐的智能化水平。通过生成个性化的推荐理由,用户不仅能够获得精准的书籍推荐,还能理解推荐背后的原因。这种人性化的推荐体验将进一步增强用户对图书馆服务的信任和依赖[3]。
综上所述,基于机器学习的图书馆资源推荐系统的设计,不仅是对传统图书馆服务模式的创新,也是对用户需求变化的积极响应。通过结合现代技术,图书馆能够更好地适应信息化时代的挑战,为用户提供更高效、更智能的服务。
1"机器学习的基本概念
机器学习是人工智能的一个重要分支,旨在通过数据训练模型,使计算机能够自动学习和改进。与传统编程方法不同,机器学习依赖于数据和算法,通过分析数据中的模式和规律,进行预测和决策。机器学习的应用范围广泛,涵盖了图像识别、自然语言处理、推荐系统等多个领域[4]。
机器学习主要分为3类:监督学习、无监督学习和强化学习。
(1)监督学习是一种利用已标注数据训练模型的方法。模型通过学习输入和输出之间的关系来进行预测。常见的应用领域包括分类和回归问题。以图书馆资源推荐系统为例,监督学习可以预测用户对某本书的评分[5]。通过分析用户过去的评分历史,模型能够了解用户的偏好,据此推荐他们可能感兴趣的书籍。常见的监督学习算法有线性回归、决策树、支持向量机和神经网络等。
(2)无监督学习是通过未标注的数据进行训练。模型试图从数据中发现潜在的结构和模式。常见的应用包括聚类和降维。在图书馆推荐系统中,无监督学习可以用于用户分群,通过分析用户的借阅行为,将用户划分为不同的群体,以便为每个群体提供更具针对性的推荐。例如:K-means聚类算法可以将用户根据借阅历史进行分组,从而识别出不同用户群体的兴趣特征[6]。
(3)强化学习是一种通过与环境的不断互动和反馈来学习的过程。该方法通过尝试不同的动作,根据结果调整策略,以达到最大化长期回报的目标。例如:图书馆可以利用强化学习来优化推荐策略,通过不断调整推荐内容,提高用户的满意度和资源利用率。
近年来,深度学习作为机器学习的一个重要分支,逐渐成为推荐系统研究的热点。深度学习通过构建多层神经网络,能够自动提取数据中的特征,处理复杂的非线性关系。在推荐系统中,深度学习可以用于建模用户和物品之间的复杂关系,提升推荐的准确性和个性化水平[7]。
总之,机器学习为图书馆资源推荐系统的设计提供了强大的技术支持。通过对用户行为数据的深入分析,机器学习能够识别用户的兴趣和需求,从而提供个性化的推荐。结合深度学习等先进技术,推荐系统的智能化水平将进一步提升,为用户提供更高效、更精准的服务。随着技术的不断进步,机器学习在图书馆资源管理和服务中的应用前景广阔,值得深入研究和探索。
2"数据收集与处理
数据是推荐系统的基础,优质的数据不仅能够提高推荐的准确性,还能增强用户体验。在设计基于机器学习的图书馆资源推荐系统时,数据的收集与处理是至关重要的环节。本文所使用的主要数据来源于某高校图书馆的借阅记录和用户评分数据,这些数据为推荐系统提供了必要的支持。
2.1"数据来源
(1)借阅记录是用户与图书馆互动的重要数据,通常包括用户ID、图书ID、借阅时间、归还时间等信息,能够帮助系统了解用户的借阅习惯和偏好,为后续的推荐提供基础数据。
(2)用户评分是用户对图书的主观评价,通常在1到5之间。评分数据能够反映用户对图书的喜好程度,是构建用户-物品评分矩阵的重要依据。通过分析用户评分,系统可以识别出用户的兴趣点,从而进行个性化推荐。
2.2"数据预处理步骤
在数据收集后,数据预处理是确保数据质量和完整性的关键步骤。数据预处理的主要步骤包括如下。
(1)数据清洗是指去除重复记录和无效数据,以确保数据的准确性。例如:借阅记录中可能存在重复的借阅条目,或者评分数据中可能包含无效的评分(如评分为0或空值)。通过数据清洗,可以提高数据的质量,为后续分析打下良好的基础。
(2)缺失值处理。在实际数据集中,缺失值是常见的问题。缺失值的存在可能会影响模型的训练和预测效果。常用的处理方法包括均值填充、删除缺失值或使用插值法等。在本系统中,采用均值填充的方法来处理用户评分中的缺失值,以保证数据的完整性。
(3)特征选择。特征选择是指从原始数据中选择出对模型训练有用的特征。在推荐系统中,用户ID、图书ID和评分等特征是构建用户-物品评分矩阵的关键。通过特征选择,可以减少数据的维度,提高模型的训练效率。
以下是使用Python进行数据处理的示例代码。
import pandas as pd
# 读取借阅记录和评分数据,清洗及处理缺失值
data = pd.read_csv('borrow_records.csv').drop_duplicates()
ratings = pd.read_csv('user_ratings.csv').drop_duplicates().fillna(lambda x: x.mean())
# 构建用户-物品评分矩阵
matrix = ratings.pivot('user_id', 'book_id', 'rating')
数据的可视化也是数据处理过程中不可或缺的一部分。通过可视化工具(如Matplotlib和Seaborn),可以直观地了解数据的分布情况和特征之间的关系。例如:可以绘制用户评分的分布图,帮助分析用户的评分习惯。这种可视化不仅有助于数据分析,还能为后续的模型选择和参数调整提供参考。
以下是绘制用户评分分布图的实例代码。
import matplotlib.pyplot as plt
import seaborn as sns
# 绘制用户评分分布图
sns.histplot(rating_data['rating'], bins=5, kde=True)
plt.title('Rating Distribution').set(xlabel='Rating', ylabel='Freq')
plt.show()
综上所述,数据收集与处理是构建基于机器学习的图书馆资源推荐系统的基础环节。通过有效的数据收集和严格的数据预处理,系统能够确保数据的质量和完整性,从而为后续的推荐算法提供可靠的支持。随着数据处理技术的不断进步,未来的推荐系统将能够更好地利用数据,提升推荐的准确性和用户满意度。
3"推荐算法设计
推荐算法是推荐系统的核心,决定了系统能否有效地为用户提供个性化的资源推荐。在本系统中,采用协同过滤算法作为主要的推荐方法。协同过滤算法基于用户的历史行为和偏好,通过分析用户之间或物品之间的相似性,来生成推荐结果。协同过滤算法主要分为2种类型:基于用户的协同过滤和基于物品的协同过滤。
3.1"协同过滤算法
(1)基于用户的协同过滤。该方法通过计算用户之间的相似度,识别出与目标用户兴趣相似的其他用户,然后向目标用户推荐这些相似用户喜爱的物品。具体来说,系统会分析用户的评分数据,识别出评分模式相似的用户群体,从而为目标用户提供个性化的推荐。例如:如果用户A和用户B在过去的借阅记录中有相似的评分,系统会推荐用户B喜欢但用户A尚未借阅的书籍。
(2)基于物品的协同过滤。与基于用户的协同过滤不同,基于物品的协同过滤通过计算物品之间的相似度,推荐与用户已评分的物品相似的其他物品。此方法的优势在于能够结合物品特征和用户评分历史,提供更加准确的推荐。例如:如果用户对某本书评分较高,系统会推荐与该书相似的其他书籍,帮助用户发现更多感兴趣的资源。
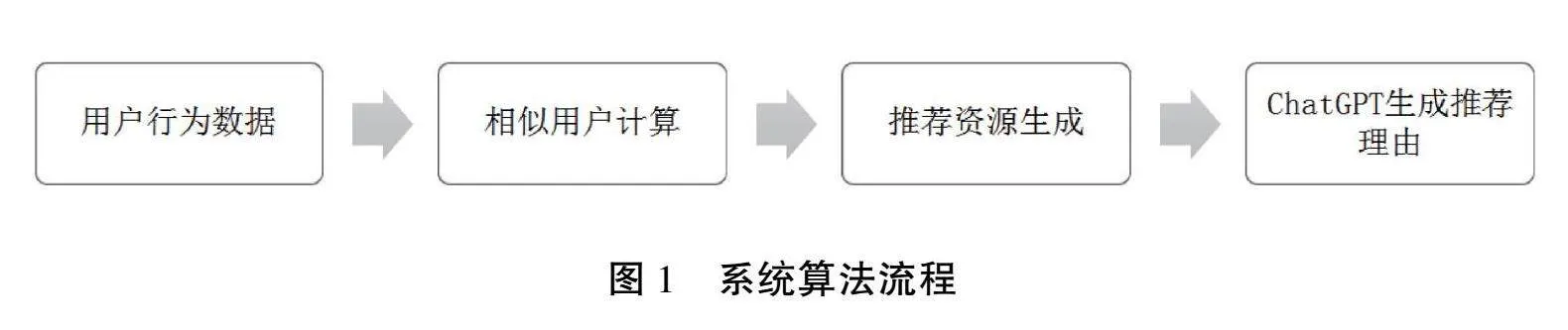
3.2"算法流程
推荐算法的工作流程如图1所示。
通过这一流程,系统能够有效地分析用户的行为数据,计算相似度,并生成个性化的推荐结果。在实现推荐算法时,使用Python编程语言及其相关库(如NumPy和Pandas)来处理数据和计算相似度。
以下是基于用户的协同过滤算法的Python实现示例。
from sklearn.metrics.pairwise import cosine_ similarity
# 计算用户相似度
sim = cosine_similarity(matrix.fillna(0))
def recommend(user, mat, sim, n=5):
# 获取相似用户的评分
return mat.T.dot(sim[mat.index.get_loc(user)]).sort_values(ascending=False).head(n)
# 排序并推荐
print(recommend(1, matrix, sim))
通过上述算法设计,推荐系统能够根据用户的历史行为和评分数据,提供个性化的书籍推荐。这种基于协同过滤的推荐方法,不仅能够提高推荐的准确性,还能增强用户的满意度和资源的利用率。随着用户数据的不断积累,推荐系统的效果将会进一步提升,为用户提供更为精准和个性化的服务。
4"ChatGPT与语言模型的应用
在现代推荐系统中,集成自然语言处理技术,尤其是基于深度学习的语言模型(如ChatGPT),为用户提供个性化的推荐理由和交互体验,极大地提升了系统的智能化水平。ChatGPT能够理解用户的查询意图,生成自然流畅的语言输出,使得推荐系统不仅限于提供书籍推荐,还能为用户解释推荐的原因,从而增强用户的信任感和满意度[8]。
4.1"个性化推荐理由生成
通过将ChatGPT集成到推荐系统中,用户在获得书籍推荐的同时,还能得到个性化的推荐理由。例如:当用户询问某本书的推荐原因时,ChatGPT可以分析用户的历史借阅记录和评分,结合推荐算法的输出,生成一段简洁而有说服力的推荐理由。这种交互式的体验使得用户能够更好地理解推荐背后的逻辑,进而提升用户对推荐系统的依赖性[9]。
4.2"用户交互的提升
此外,ChatGPT还可以用于处理用户的自然语言查询,提供更为人性化的交互方式。用户可以通过自然语言与系统进行对话,询问关于书籍的具体信息、借阅流程或其他相关问题。系统通过ChatGPT的自然语言理解能力,能够准确识别用户的意图,提供相应的反馈。这种灵活的交互方式不仅提高了用户体验,还使得图书馆的服务更加智能化。
4.3"示例代码
以下是使用OpenAI的API与ChatGPT进行交互的示例代码。
import openai
# 设置OpenAI密钥
openai.api_key = 'API_KEY'
def recommend_reason(book):
return openai.ChatCompletion.create(model=\"gpt-3.5-turbo\", messages=[{\"role\": \"user\", \"content\": f\"推荐一本书:{book}\"}])['choices'][0]['message']['content']
# 生成推荐理由
print(recommend_reason(\"机器学习\"))
通过将ChatGPT与推荐系统相结合,图书馆能够为用户提供更为个性化和智能化的服务。这种创新的应用不仅提升了用户的满意度,也为图书馆的资源推荐系统注入了新的活力。随着技术的不断进步,未来的推荐系统将更加智能,能够更好地满足用户的需求。
5"系统评估
系统评估是确保推荐系统有效性和可靠性的关键环节。通过对推荐系统的性能进行评估,能够识别其优缺点,为后续的优化提供依据。在本系统中,本研究采用多种评估指标来衡量推荐的准确性和用户满意度[10]。
5.1"评估指标
(1)准确率。准确率是指推荐的书籍中,用户实际喜欢的书籍所占的比例。高准确率意味着推荐系统能够有效识别用户的兴趣,从而提供更符合用户需求的资源。
(2)召回率。召回率是指用户实际喜欢的书籍中,被推荐的书籍所占的比例。高召回率表明系统能够覆盖更多用户感兴趣的书籍,提升用户的资源获取效率。
(3)F1-score。F1-score是准确率和召回率的调和平均值,综合考虑了推荐的准确性和覆盖率。F1-score的高低能够反映推荐系统的整体性能。
5.2"评估方法
为了评估推荐系统的性能,将用户的实际反馈与系统生成的推荐结果进行对比。通过计算上述指标,能够量化推荐系统的效果。此外,用户的主观反馈也是评估的重要组成部分,通过问卷调查或用户访谈,收集用户对推荐结果的满意度和建议,进一步完善系统。
以下是计算准确率和召回率的示例代码。
def metrics(rec, actual):
tp = len(set(rec) amp; set(actual))
return tp / len(rec) if rec else 0, tp / len(actual) if actual else 0, 2*tp / (len(rec)+len(actual)) if tp else 0
# 示例计算
rec_books, actual_books = [1, 2, 3, 4, 5], [2, 3, 6]
print(metrics(rec_books, actual_books))
通过系统评估,本研究能够不断优化推荐算法和用户交互方式,提升用户的满意度和使用体验。随着用户反馈的积累,推荐系统将不断演进,以更好地适应用户需求的变化。
6"结语
基于机器学习的图书馆资源推荐系统的设计与实现,标志着图书馆服务向智能化和个性化的转型。通过对用户行为数据的深入分析,系统能够提供精准的资源推荐,显著提升用户的资源获取效率。本文探讨了推荐系统的各个关键环节,包括数据收集与处理、推荐算法设计、ChatGPT的应用以及系统评估,形成了一个完整的推荐系统框架。
首先,数据的质量和完整性是推荐系统成功的基础。通过有效的数据收集和严格的数据预处理,系统能够确保数据的准确性和可靠性。借助用户的借阅记录和评分数据,系统构建了用户-物品评分矩阵,为后续的推荐算法提供了坚实的基础。
其次,推荐算法的设计是系统的核心。通过采用基于用户的协同过滤算法,系统能够识别用户之间的相似性,根据相似用户的偏好生成个性化的推荐。这种方法不仅提高了推荐的准确性,还增强了用户的满意度。此外,结合基于深度学习的语言模型(如ChatGPT),系统能够生成个性化的推荐理由,提升用户体验,使推荐过程更加人性化。
在系统评估方面,通过准确率、召回率和F1-score等多种指标的综合评估,系统能够量化推荐效果,为后续的优化提供依据。用户的主观反馈也为系统的改进提供了重要参考,确保推荐系统能够持续适应用户需求的变化。
未来,基于机器学习的推荐系统可以进一步结合更多的用户特征和外部数据,以提升推荐的准确性和用户满意度。例如:社交网络数据的引入可以帮助分析用户的社交关系对推荐的影响,从而提供更为精准的推荐。此外,随着深度学习技术的不断发展,基于神经网络的推荐算法(如神经协同过滤)也将成为研究的热点,进一步推动推荐系统的智能化。
总之,基于机器学习的图书馆资源推荐系统不仅提升了图书馆的服务水平,也为用户提供了更高效的资源获取方式。通过不断优化推荐算法和用户交互方式,图书馆能够更好地满足用户的需求,提升用户的满意度和使用体验。随着技术的不断进步,推荐系统的应用前景广阔,必将在未来的图书馆服务中发挥更为重要的作用。
参考文献
[1]董殿永.生成式AI在智慧图书馆中的应用探讨[J].江苏科技信息,2024(16):100-104.
[2]刘玉虎,张妮.ChatGPT赋能高校图书馆学科服务[J].文化产业,2024(20):148-150.
[3]吴正飞.ChatGPT技术融入图书馆服务的路径研究[J].数字通信世界,2024(4):25-27.
[4]傅勇.ChatGPT对终身学习的影响和启示[J].西北成人教育学院学报,2023(6):14-19.
[5]杨丹.基于人工智能赋能的图书馆数据挖掘与精准服务[J].电脑与信息技术,2024(5):48-51.
[6]王超,潘雪峰,侯辉.基于机器学习分类法的AI生成内容与学者撰写内容比较研究[J].大学图书情报学刊,2024(6):9-14.
[7]刘巧慧.人工智能在学校图书馆文化资源管理中的应用[J].数字通信世界,2024(10):151-153.
[8]杨丹.基于人工智能赋能的图书馆数据挖掘与精准服务[J].电脑与信息技术,2024(5):48-51.
[9]张诗晗.元宇宙视域下高校图书馆智慧服务创新策略研究[J].湖北成人教育学院学报,2024(5):12-18.
[10]李静,罗征,闫振平,等.基于改进机器学习的图书馆机器人自主避障控制研究[J].计算机测量与控制,2024(9):200-205,240.
(编辑"王永超编辑)
Design of a library resource recommendation system based on machine learning
Ailiyaer "Abudukelimu, CHEN "Yingjie*
(Library, Xinjiang Agricultural University, Urumqi 830052, China)
Abstract: "With the development of information technology, libraries are facing challenges in resource management and personalized recommendation. Traditional recommendation methods, relying on manual rules or statistical models, struggle to meet users’ growing need for personalization. This paper proposes a personalized library resource recommendation system based on machine learning, leveraging deep learning language models (such as ChatGPT) to accurately model user needs. By analyzing user behavior data and semantic information, a new recommendation framework is designed to enhance the intelligence of the recommendation system. Experimental results show that the proposed system significantly outperforms traditional methods in terms of recommendation accuracy and user satisfaction, providing more personalized and precise library resource recommendations. This study offers theoretical support and practical guidance for the design and optimization of library resource recommendation systems.
Key words: machine learning; library; resource recommendation; ChatGPT; user behavior analysis
猜你喜欢
小太阳画报(2018年1期)2018-05-14 17:19:25
科技创新与应用(2016年31期)2016-12-03 03:33:48
时代金融(2016年27期)2016-11-25 17:51:36
少年博览·小学低年级(2016年10期)2016-11-24 06:48:23
科教导刊(2016年26期)2016-11-15 20:19:33
科学与财富(2016年28期)2016-10-14 21:19:17
小天使·一年级语数英综合(2014年8期)2014-06-26 14:42:04
