
档案开放智能审核中的敏感词识别与控制技术研究
2024-12-16 00:00:00卞咸杰
档案管理 2024年5期
摘 要:随着档案法律法规的日趋完善和信息技术的迭代进步,档案开放智能审核工作面临越来越多的挑战。敏感词的识别与控制在防止敏感信息泄露中起着关键作用。通过分析敏感词识别技术与方法,构建基于大模型与多模态训练的敏感词库,包括敏感词库的构建、敏感词库的动态更新机制,选择合适的开发工具和技术平台,进行系统架构设计、数据库设计、界面设计等,实现档案开放智能审核中敏感词的自动化、智能化处理,以增强档案信息的安全性和可靠性。
关键词:档案开放;开放审核;敏感词识别;控制技术;大模型;多模态;监督学习;智能审核
2020年,新修订的《中华人民共和国档案法》将县级以上各级档案馆的档案的封闭年限从30年缩短为25年,[1]加快了档案开放的进程,同时也将各级档案馆的开放审核工作提上了重要的议事日程。[2]在档案开放过程中,敏感词的识别与控制是确保档案信息安全的重要措施。传统的敏感词识别方法往往依赖于人工定义和手动更新,这种方式不仅效率低下,而且难以满足档案开放审核的复杂需求。现有的人工智能辅助档案开放审核系统中,2016年,福建省档案馆引入敏感词辅助开展档案开放审核工作,在开放审核的质量和效率方面取得一定突破。并于2022年研发基于数字档案的人工智能档案开放审核系统,将目录及全文运用“敏感词”过滤进行智能分级分库,并按初审、复审、终审流程进行逐级审核。[3]2019年,潍坊市档案馆主导开发了综合档案管理系统中的档案审核程序,将敏感词全文比对技术应用到审核工作中,实现了档案开放审核工作在技术上质的提升。[4]2021年,四川省档案馆围绕档案开放审核中的各个维度和要素,利用关键词提取、敏感词标注等辅助技术,对其原理、设计及应用实践进行研究,以达到提高档案开放审核速度和精准度、赋能档案开放审核工作的目的。[5]构建一个高效、准确的敏感词库,是档案开放审核工作亟待解决的问题。
1 敏感词识别技术与方法
1.1 敏感词识别技术。敏感词是一类被定义为敏感信息的关键词,如IP地址、身份证号、手机号、密钥、数据库连接密码等。[6-11]敏感词识别技术是一种用于检测文本、语音、图片等媒体中是否包含敏感词汇或内容的技术手段,主要依赖于自然语言处理、机器学习、深度学习等人工智能技术,通过训练大量的文本数据,实现敏感词的机器学习和识别。技术上通常需要维护一个包含敏感词的字典,[12]用于快速匹配用户输入的文本内容。匹配算法在主串中一次性查找多个模式串(即敏感词)是否存在,结合自然语言处理技术和机器学习算法,对文本进行深度分析,以提高敏感词识别的准确率。利用深度学习模型,如循环神经网络(RNN)、长短期记忆网络(LSTM)或Transformer等,[13]对文本进行建模和预测,可进一步提高敏感词识别效果。
相比人工审核,敏感词识别技术减少了主观判断带来的误差,提高了审核的准确性。[14]敏感词识别技术允许用户根据实际需求定制敏感词库,实现对不同类型敏感信息的有效监控。
1.2 基于规则的敏感词识别方法。利用预设规则进行敏感词识别的方法是信息安全领域中常见的技术手段。从相关法律法规、行业标准、历史案例及用户反馈等多个渠道收集敏感词汇,并进行整理分类,定义完全匹配、部分匹配、模糊匹配等多种匹配方式,以适应不同档案内容的审核需求。敏感词的提取过程,首先是档案文本中的标点符号、特殊符号等无关字符;[15]其次是分词处理,将文本切分成单词或短语。敏感词的自动提取可以通过编程或使用专门的文本处理工具实现。[16]
1.3 基于统计的敏感词识别方法。基于统计的敏感词识别方法是一种利用统计学原理进行敏感词检测的技术。[17]与基于规则的敏感词识别方法不同,它更多地依赖于大量文本数据的统计特性和机器学习算法来识别敏感词。对档案数据源中的文本数据进行清洗,包括去除无关字符、特殊符号、HTML标签等,并进行分词处理。[18]将预处理后的文本转换为数值向量,基于行业标准和历史经验,构建一个初始的敏感词库,根据数据特点和业务需求,选择合适的机器学习算法,如朴素贝叶斯、支持向量机(SVM)或深度学习模型,将训练好的模型应用于实际档案开放审核中,对档案文本进行敏感词识别。
2 基于大模型与多模态训练的敏感词库构建
2.1 大模型训练。在“大模型+大数据+大算力”的加持下,ChatGPT能够通过自然语言交互完成多种任务,具备了多场景、多用途、跨学科的任务处理能力。[19]在构建敏感词库的过程中,大模型训练发挥着至关重要的作用,通过训练大规模语料库,得到一个具有强大语义理解能力的模型,该模型不仅能够准确地识别出文本中的敏感词,还能够深入理解文本内容、上下文深层含义和不断优化自身性能,提高识别的准确性和效率。[20-23]
构建敏感词库的前提是准备一个包含大量文本数据的语料库。语料库应该具有广泛的领域和类型,以便训练得到的模型能够适应不同的应用场景。在语料库中,对包含敏感词的文本进行标注,通过人工标注或自动标注的方式实现。[24]利用深度学习技术,训练一个大规模神经网络模型。该模型将学习语料库中的文本数据和标注信息,逐渐提高识别敏感词的能力。在模型训练过程中,需要不断评估模型的性能,并根据评估结果进行优化,包括调整模型的参数、结构或算法等。
2.2 多模态训练。2023年3月发布的超大规模多模态预训练大模型(GPT-4),具备了多模态理解与多类型内容生成能力。[25]在发展进程中,大数据、大算力和大算法完美结合,大幅提升了大模型的预训练和生成能力以及多模态多场景应用能力。采用多模态训练的方式来构建敏感词库利用了传统的文本数据,引入了图像、音频等多媒体数据,提高了模型对敏感词的识别能力。[26]
多模态训练涉及将不同类型的数据(如文本、图像、音频)整合到统一的模型中进行训练,这种融合可以提供更丰富的上下文信息,有助于更准确地理解和识别敏感内容。[27]通过设计一个能够处理多种数据类型的深度学习模型,结合卷积神经网络(CNN)和循环神经网络(RNN)的混合模型,在训练过程中使其学习如何从不同模态的数据中提取和整合特征,以进行有效的敏感词识别。
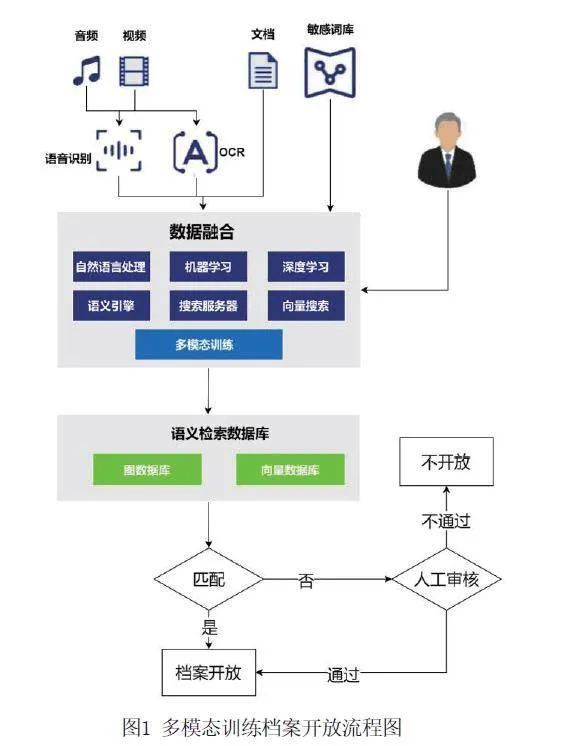
多模态训练有助于增强模型对于细微差异的敏感性,通过分析图像内容与相关文本描述之间的关联来识别敏感信息。[28-30]在档案审核中,多模态模型可以同时分析档案的文本内容、相关图片和音频记录,以全面检测敏感信息。随着多模态学习技术的不断发展,未来的敏感词识别模型将更加智能和准确。采用多模态训练的方式来构建敏感词库,是适应档案信息多样性和复杂性的有效途径。[31]这种方法通过融合不同模态的数据,提高了模型对敏感词的识别能力,为档案开放审核提供了更加全面和准确的技术支持,如图1所示。
在大模型和多模态训练的基础上,构建档案开放审核敏感词库。词库包含各种敏感词汇和短语,并且可以根据实际需要进行动态更新和扩展。同时,敏感词库设计了查询和检索机制,方便审核人员快速定位和查找敏感词。
2.3 敏感词的定义与分类。在档案开放审核中,根据词汇的敏感性程度,可以将其分为不同的级别,如低敏感、中敏感和高敏感,以便于采取不同程度的处理措施。敏感词的分类应基于国家法律法规的相关规定,确保识别工作符合法律要求,考虑社会文化的多样性和变迁,敏感词的分类应具有一定的适应性和灵活性。档案开放审核涉及的领域广泛,不同行业和领域对敏感词的定义和分类可能有所不同,需要结合具体情境进行细化。通过文本分析、专家评审和用户反馈等多种方式收集潜在的敏感词汇,包括历史档案、政府文件、公开出版物等来源,对收集到的敏感词汇进行分类标注,明确其所属的类别和敏感性级别。[32]
识别策略的实施是根据敏感词的分类和级别,制定相应的识别和处理规则,如屏蔽、替换或标记等。采用自然语言处理、机器学习等技术手段,实现自动化的敏感词识别和处理,包括关键词匹配、语义分析等方法。[33,34]对识别结果进行人工审核,确保处理的准确性和合理性。
档案开放审核中敏感词的概念和分类标准的确立是构建有效识别系统的关键基础。通过明确敏感词的定义、制定分类准则和实施识别策略,可以有效地识别和处理敏感词汇,为档案开放审核和其他内容管理系统提供支持。[35]同时,这一过程也需要应对语境变化、多义词处理等挑战,并严格遵守合规性和伦理原则。
2.4 基于大模型与多模态训练的敏感词库构建。结合大模型和多模态训练技术,以提高敏感词库的全面性和准确性。
首先,利用大数据预训练模型,如BERT及其变体,来捕捉词汇的丰富语义表示。通过这种方式,模型能够理解和预测词汇在不同上下文中的语义。
其次,引入多模态训练,将文本内容与图片、音视频等非文本数据相结合。例如,档案资料中常见的手写注释、历史照片和相关文档的图像,都可以作为额外的训练数据。这种方法可以增强模型对于档案特定内容的理解和敏感词的辨识能力。
为适应档案数据的多样性和历史性,引入领域适应性训练,使模型更好地适应档案语境中的特定表达方式。此外,考虑到档案的敏感性和历史性,采用了半监督学习或弱监督学习方法,以利用有限的标注数据进行有效训练。
2.5 敏感词库的动态更新机制。在档案开放审核中,动态更新机制是确保敏感词库能够适应不断变化的信息环境的关键,这一机制涉及对敏感词库的持续监控、定期更新和适时调整,以保持其时效性和准确性。
通过设定监控系统,实时跟踪网络环境和社会动态,及时发现新出现的敏感词汇和表达方式,制定明确的更新计划,如每季度或每半年对敏感词库进行全面的审查和更新。针对特定事件(如政治事件、社会事件等),灵活调整更新频率,确保敏感词库能够及时反映当前的敏感话题。利用自然语言处理和机器学习技术,自动识别和提取潜在的敏感词汇,提高更新效率。[36,37]通过对大量文本数据的统计分析,发现敏感性词汇的出现频率和分布规律,为更新提供数据支持。邀请法律、社会学、信息安全等领域的专家参与敏感词库的更新过程,提供专业意见,通过跨学科的合作,综合考虑不同领域的知识和需求,确保敏感词库的全面性和准确性。[38,39]
某些词汇的敏感性可能会随时间而变化,需要及时调整其分类和处理规则。对于具有多重含义的词汇,需要结合上下文进行细致判断,避免误判,通过持续的监控、专家参与和技术创新,确保敏感词库的准确性和适应性,[40,41]在全球化的背景下,敏感词库的更新可能需要考虑到跨国文化和法律的差异,国际合作将成为重要的趋势。
档案开放审核中的动态更新机制是确保敏感词库能够适应不断变化的信息环境的关键。通过实时监控、定期更新、技术手段的应用、专家参与等措施,可以有效地保持敏感词库的时效性和准确性。同时,这一机制也需要应对语境变化、多义词处理等挑战,并严格遵守透明性与可追溯性的原则。
3 系统实现
基于档案开放智能审核对敏感词的识别与控制技术需求,通过选择合适的开发工具和技术平台,进行系统架构设计、数据库设计、界面设计等,实现档案开放智能审核中敏感词的自动化、智能化处理。
3.1 开发工具和技术平台选择。前端选择Vue3框架,该JavaScript框架提供了响应式用户界面;后端使用.NETCore,该技术支持快速开发与高效的系统性能,根据数据类型和查询需求,选用MsSQL结合缓存数据库Redis,可以提升数据访问效率,采用云计算技术,如腾讯云或阿里云等,提供弹性的计算资源,可以满足系统在不同负载下的性能需求。[42]同时,利用微服务架构,将系统拆分为多个独立的服务,以提高系统的可维护性和可扩展性。
3.2 系统的架构设计。前端架构采用响应式设计,确保系统在不同设备上的良好显示和用户体验。同时,利用Vue.js、React等前端框架,实现快速、高效的界面渲染和交互。后端架构采用微服务架构,将系统拆分为档案信息管理、审核流程管理、权限控制等独立的服务。[43]每个服务负责处理特定的业务逻辑,并通过API网关进行通信。此外,利用消息队列(如RabbitMQ、Kafka)实现服务的异步通信和解耦。数据库选择关系型数据库MsSQL存储档案信息、审核记录等结构化数据。[44]同时,结合Redis作为缓存数据库提升数据的查询和存储效率。
3.3 数据库设计。数据模型设计,定义清晰的数据模型,符合档案数据的特点和审核需求。例如,档案数据模型应包括索引信息、内容摘要、敏感标识等字段。考虑数据的一致性和完整性,设计合理的数据约束和索引策略,提高查询效率和数据准确性,实施严格的数据访问控制,确保只有授权用户可以访问敏感数据,[45,46]定期进行数据备份,制定灾难恢复计划,保障数据的安全性和可靠性。
3.4 原型设计。策略配置提供一站式管控策略配置,将词库与业务巧妙融合,灵活控制影响方式、持续时间及状态,精准掌握策略召回数量,并可对策略召回内容进行深度处理。词库管理实现便捷添加敏感词,明确所属词库,添加时即可预览召回量,抽样评估后准确掌握拦截准确率。初步划分所属词库,随后评估召回量与随机样本,决定是否生效及确认词库归属。随机样本抽取数量与方式可在“样本设置”中调整,命中准确率评估则在“敏感词评估”中进行。[47]用户配置将用户与敏感词、业务、地域三维紧密关联,命中策略对应“策略配置”页相关策略,清晰展示受该策略影响的用户数,点击“处理”即可跳转至“内容处理”页面进行相应操作。内容处理方面,针对命中策略的业务或用户,实施精准处理。数据统计实现从策略、词库、用户及处理等多维度进行详尽数据统计,并以报表形式直观呈现各类数据,方便分析与决策。
本文系2024年国家社会科学基金年度一般项目《档案开放智能审核的创新研究》(项目批准号:24BTQ022);2022年国家档案局科技项目“档案开放审核流程优化和应用系统开发研究”(项目批准号:2022-X-012);中国高等教育学会“2024年度高等教育科学研究规划课题”《人工智能赋能档案管理转型发展的研究》(课题编号:24DA0303);2023年江苏省档案科技项目《人工智能在档案管理中应用的现状与前景研究》(2023-17);江苏省高校档案研究会2023年档案科研项目《基于AI技术的档案开放审核研究》(JSGDZ2023-02)阶段性研究成果。
参考文献:
[1]全国人民代表大会常务委员会.中华人民共和国档案法[N].人民日报,2020-07-16(016).
[2]卞咸杰、黄杨.“档案开放审核”与“档案开放鉴定”概念辨析[J].档案管理,2023(05):36-39.
[3]福建省档案局、档案馆项目组.基于数字档案的人工智能辅助 档案开放审核系统实现研究[J].浙江档案,2022(10):40-43.
[4]杨扬、孙广辉、韩先吉.敏感词全文比对在档案开放审核中的应用实践[J].中国档案,2020(11):58-59.
[5]“档案开放审核标准化体系研究”课题组.档案开放审核工作中的辅助技术应用研究[J].四川档案,2022(05):44-45.
[6]邓权亮.基于全文检索的敏感信息检测系统的设计与实现[D].北京:北京邮电大学,2021.
[7]谢永宪,王巧玲,刘湘娟,等.我国档案开放审核工作调研与分析[J].山西档案,2023(05):156-164.
[8]岳幸晖,杨智勇.人工智能在档案管理中的应用图景与风险防范[J].档案与建设,2023(10):36-40.
[9]马怡琳,李宗富.赋能·助力·提升:人工智能技术在档案解密与开放审核工作中的应用探索[J].山西档案,2022(04):112-118.
[10]聂云霞,陈烟然.新《档案法》背景下档案开放的优化路径[J].档案与建设,2022(05):16-19.
[11]冉朝霞.基于舆情数据的档案信息跨维度收集与分类研究[J].档案管理,2019(06):53-55.
[12]李雅静、丁海洋.基于MSER视频字幕敏感词过滤算法[J].现代信息科技,2023,7(21):80-84+89.
[13]蓝天虹、陈丹霏、郑源、徐正一.基于BERT预训练与混合神经网络的中文语义识别算法设计[J].电子设计工程,2024,32(12):91-95.
[14]姜钰棋、强子珊、卜凡亮.面向社交平台应急关联信息的文本分类综述[J].网络安全与数据治理,2024,43(05):1-10+34.
[15]杨滨瑕、罗旭东、孙凯丽.基于预训练语言模型的机器翻译最新进展[J].计算机科学,2024,51(S1):50-57.
[16]高子涵.基于语义分析的邮件分类研究[D].太原:中北大学,2023.
[17]杜勐.支持自定义的语音关键词检测技术研究[D].成都:电子科技大学,2023.
[18]李亚琪.基于威胁情报分析的APT组织攻击技术提取系统的设计与实现[D].北京:北京邮电大学,2023.
[19]范炜、曾蕾.AI新时代面向文化遗产活化利用的智慧数据生成路径探析[J].中国图书馆学报,2024,50(02):4-29.
[20]胡昊天、邓三鸿、孔玲等.生成式情报学术语自动抽取与多维关联知识挖掘研究[J].情报学报,2024,43(05):588-600.
[21]陈浩泷、陈罕之、韩凯峰等.垂直领域大模型的定制化:理论基础与关键技术[J].数据采集与处理,2024,39(03):524-546.
[22]王永威、沈弢、张圣宇等.大小模型端云协同进化技术进展[J].中国图象图形学报,2024,29(06):1510-1534.
[23]张丹.大语言模型与档案资源开发:前景、挑战与应对[J].山西档案,2023(05):108-111.
[24]赵萍、窦全胜、唐焕玲.融合词信息嵌入的注意力自适应命名实体识别[J].计算机工程与应用,2023,59(08):167-174.
[25]刘聪、李鑫、殷兵等.大模型技术与产业:现状、实践及思考[J].人工智能.2023(04):32-42.
[26]朱学芳.图博档数字化服务融合理论、方法、技术与实证[M].南京:南京大学,2023.11.
[27]刘树锋.大数据时代AIGC与多模态知识图谱的思考与展望[J].互联网周刊,2023(15):49-51.
[28]张慧玲、许海云、王超.弱信号环境下情报感知方法框架研究[J].情报理论与实践,2023,46(11):9-19.
[29]许剑颖,冯桂珍.ChatGPT赋能档案服务:技术特征、应用场景与实现路径[J].山西档案,2023(06):111-120.
[30]佟淑玲,王越文,李泽坤.基于本体的声像档案知识图谱构建研究[J].档案管理,2022(06):52-56.
[31]刘哲雨.深度学习的探索之路[M].天津:南开大学出版社,2018.05.
[32]潘新美.政府规制网络言论研究[D].厦门:厦门大学,2015.
[33]胡百精.公共传播与社会治理[M].北京:中国人民大学出版社,2020.01.
[34]王楠,丁原,李军.语义层次网络在文书档案开放审核中的应用[J].档案与建设,2022(06):55-60.
[35]周耀林、张晓娟、肖秋会.档案学研究进展[M].武汉:武汉大学出版社,2018.06.
[36]刘奕.5G网络技术对提升4G网络性能的研究[J].数码世界,2020(04):24.
[37]聂云霞,范志伟.AI技术在档案开放审核中的SWOT分析[J].山西档案,2023(04):35-45+88.
[38]张良.面向舆情要素的在线社交网络舆情分析关键技术研究[D].长沙:国防科技大学,2021.
[39]马怡琳,李宗富.赋能·助力·提升:人工智能技术在档案解密与开放审核工作中的应用探索[J].山西档案,2022(04):112-118.
[40]张燕飞.数字化转型重塑业务流程管理[M].北京:中国铁道出版社,2022.11.
[41]岳靓,王芹,相明洁,等.数据治理下的档案开放鉴定现状及优化策略研究—以苏州市为例[J].档案与建设,2023(05):57-60.
[42]李易壮.基于图神经网络的文档情感分类系统的设计与实现[D].北京:北京邮电大学,2021.
[43]陈露露、李志龙、张民等.行政数据管理分析系统的设计与实现[J].数字技术与应用,2023,41(12):155-157.
[44]黄静、朱旭.基于Spring Cloud的人才智库遴选系统的设计与实现[J].软件工程,2023,26(02):54-58.
[45]胡晨、蔡博阳、项文新.开发区档案数据归集平台技术架构设计[J].兰台世界,2024(02):62-68.
[46]任志勇,梅启梁,徐柯.基于量子密码技术的电子档案离线状态下安全防护实现[J].山西档案,2022(04):141-146.
[47]刘绍涛.新闻长文本检索方法的设计与实现[D].成都:电子科技大学,2022.
[48]张康康.基于机器学习的Android恶意代码静态检测方法研究与应用[D].南昌:南昌大学,2023.
[49]卞咸杰.基于智能工作流技术的档案开放审核系统设计与实现[J].档案管理,2023(06):84-87.
(作者单位:盐城师范学院历史与公共管理学院 卞咸杰,教授,硕士生导师 来稿日期:2024-06-20)
