
基于数据增强的藏语拉萨方言语音识别研究
2024-12-15 00:00:00巴果高定国尼琼
电脑知识与技术 2024年35期
关键词:语音识别




摘要:藏语属于低资源语言,其语音识别模型的训练面临数据稀缺的挑战。为了解决这一问题,文章研究了数据增强技术在藏语拉萨方言语音识别中的应用。首先,文章比较了DeepSpeech2、Conformer和Squeezeformer等3种主流语音识别模型在藏语拉萨方言语音识别任务中的性能。随后,在表现最佳的Conformer模型上,对速度扰动、音量扰动、移动扰动、SpecAugment和SpecSubAugment等5种数据增强方法的效果进行了对比分析。实验结果表明,5种数据增强方法均能有效提升模型性能,其中SpecAugment方法表现最佳,将字符错误率(CER)降至13.1%。
关键词:藏语拉萨方言;语音识别;数据增强;端到端模型;SpecAugment
中图分类号:TP391.4文献标识码:A
文章编号:1009-3044(2024)35-0001-05开放科学(资源服务)标识码(OSID):
0引言
信息技术的迅猛发展,语音识别技术在人工智能领域占据了举足轻重的地位。它通过将人类语音转化为文本形式,极大地促进了人机交互的自然性和智能化进程。语音识别技术自20世纪50年代起发展迅速[1],现已广泛应用于智能家居、车载设备、智能穿戴设备等领域,如Siri、GoogleNow等。
近年来,随着人工智能技术的进步和社会对多语言信息处理需求的增加,少数民族语言的语音识别技术日益受到关注。藏语作为中国少数民族语言中使用人数较多的语言之一,具有深厚的历史文化底蕴。其语音识别技术的发展不仅能够推动藏语的数字化进程,加强民族文化交流,还能帮助藏族人民更好地融入现代社会,享受科技进步带来的便利。
尽管英语、汉语等语言在语音识别领域取得了显著成就,但藏语语音识别技术的发展起步相对较晚。藏语虽然与汉语同属汉藏语系,但发音差异较大,且由于地理位置、历史条件等因素,藏语语音识别研究基础相对薄弱,语料资源匮乏,导致其技术发展滞后,识别率较低[2]。
目前,研究者们通过引入不同的技术和模型,不断优化藏语语音识别的准确率。例如:
CTC-Attention模型,在藏语拉萨方言测试WER达到38.64%。2020年,乐建建[4]引入空洞卷积,使用WaveNet-CTC模型,在藏语拉萨方言测试WER达到28.83%;郭龙银[5]等结合卷积网络和循环神经网络,提出CNN-BLSTM-CTC模型,藏语拉萨方言测试WER达到35.51%。2021年,高飞[6]将视频特征与语音特征融合,提出AV-WaveNet-CTC模型,在藏语拉萨方言测试WER达到42.7%;侯苗苗[7]融合多种语音特征,提出基于CNN的多特征声学模型,在藏语拉萨方言测试WER达到24.64%;算太本[8]提出CNN-CTC模型,在藏语拉萨方言和安多方言混合数据集上测试WER达到19.26%。2022年,贡保加[9]引入多尺度特征融合思想,提出MRDCNN-CTC模型,在藏语安多方言测试WER达到18.67%。2023年,朱小军[10]基于LAS网络结构提出MHLAS模型,结合迁移学习,在安多藏语方言测试WER达到35.78%;王超[11]提出基于Conformer-CTCBi-Transformer的模型,在藏语安多方言测试WER达到6.98%。
在数据增强方面,研究者也取得了一定进展:2021年,杨晓东[12]采用Transformer模型并引入Spe⁃cAugment进行数据增强,在藏语拉萨方言测试WER达到25.8%。王伟喆[13]提出基于语谱特征的端到端藏语语音识别模型,并通过添加不同信噪比的自然场景噪声实现数据增强,在藏语拉萨方言测试WER达到28.53%。
由上述研究可知,尽管藏语语音识别领域已有一定成果,但要进一步提升性能,仍依赖于大量数据集的支持。此外,目前针对藏语语音识别任务的数据增强研究相对较少。因此,本文研究了数据增强技术在藏语拉萨方言语音识别任务上的应用,以提升藏语拉萨方言语音识别性能。这项研究不仅能够推动藏语语音识别技术的发展,还对保护和传承藏语文化具有重要意义。
为了确保实验结果的可比性和可复现性,本文选用了西北民族大学发布的公开藏语语音识别数据集①作为实验数据。通过使用公开数据集为不同研究者提供统一的实验平台,为后续研究者提供参考基准,使其能够在此基础上进一步探索和优化适用于藏语语音识别的模型和数据增强方法,促进学术交流,推动藏语语音识别技术的发展。
1数据增强方法
在语音识别领域,尤其是针对藏语这种低资源语言,收集大量标签数据是一项挑战,因为它需要大量的人力和物力资源。为了解决这一问题,本文探讨了数据增强技术在藏语拉萨方言语音识别任务中的应用。
数据增强是一种通过增加训练数据的多样性来扩充训练集的方法,这有助于防止模型过拟合并提高其鲁棒性。本文采用了5种数据增强技术,分别为速度扰动[14]、音量扰动[15]、移动扰动、SpecAugment增强[16]和SpecSubAugment增强[17]。
1.1速度扰动
速度扰动是一种直接作用于原始音频的语音增强技术,它利用时间伸缩的方法。具体来说,通过应用不同的速度扰动系数对原始信号进行速度调整,以此生成一系列新的音频样本。然而,如果速度变化过大,可能会导致语音失真或语义丢失,因此在实际应用中需要仔细选择速度扰动的范围。
本文采用的扰动因子将在0.9到1.1的范围内均匀采样3个速度率,对音频进行扰动。这种技术模拟了不同说话人可能具有的不同语速,提高模型对不同语速的适应能力。
1.2音量扰动
音量扰动是通过改变音频信号的增益来实现,即对信号的振幅进行缩放,使其在不同的分贝级别上进行变化。音量扰动通过随机选择一个增益值,该值位于最小增益和最大增益之间,但需合理设置增益范围以避免潜在的缺陷。
本文设置的最小增益和最大增益分别为-15dBFS和15dBFS,选定的增益被应用到音频片段上,改变其音量。通过这种技术,模型在训练过程中接触到不同音量水平的音频数据,从而提高其在实际应用中对音量变化的适应能力。
1.3移动扰动
移动扰动是通过在时间维度上对音频进行随机平移或位移。对于每个音频片段,随机选择一个位移值,将音频信号在时间轴上向前或向后平移。然而,如果位移过大可能会导致音频片段的开始或结束部分被截断,从而丢失重要的信息。
本文设置的最小位移为-5ms,最大位移为5ms。通过这种技术,可以模拟真实世界中可能遇到的信号延迟或时间偏移问题,从而提高模型的性能。
1.4SpecAugment增强方式
SpecAugment是一种直接对音频的特征进行操作的增强技术,能够增强模型对各种噪声和变化的鲁棒性,使模型可以学习到更加泛化的特征表示,从而提高在实际应用中的性能。该方法通过三种主要的扰动方式进行数据增强:时间扭曲、频率掩蔽和时间掩蔽。
时间扭曲:通过对频谱图进行局部的时间轴扭曲,模拟音频信号中可能发生的时间变化。具体操作是随机选择一个中心点,并在该点周围随机扭曲一定范围。
频率掩蔽:随机选择一定比例的连续频率通道,将这些通道的值替换为零或频谱图的平均值,模拟信号在这些频率上的缺失。
时间掩蔽:随机选择一定比例的连续时间步,将这些时间步的值替换为零或频谱图的平均值,模拟信号在这些时间段内的缺失。
本文中,时间扭曲的最大扭曲幅度设置为5个时间步;频率掩蔽执行两次,每次掩蔽操作覆盖最多15%的频率通道;时间掩蔽执行两次,每次掩蔽操作覆盖最多5%的时间步。
1.5SpecSubAugment增强方式
SpecSubAugment是一种新型的数据增强方法,通过“频谱替换”的技术来增强训练数据。这种方法随机将当前的一段频谱特征替换为之前某段相同长度的频谱特征。替换操作是随机进行的,并且可以在训练过程中多次应用,以增加模型对不同语音片段之间变化的适应性。
本文中,替换的最大宽度为30帧,每个音频片段将进行3次替换操作,每次替换的起始点、长度和来源位置均为随机选择。
2模型
2.1编码器
本文探索了3种主流模型——DeepSpeech2、Con⁃former和Squeezeformer,作为编码器在藏语拉萨方言语音识别任务中的性能表现。
2.1.1DeepSpeech2
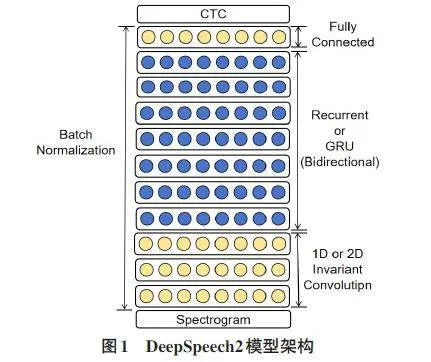
DeepSpeech2是由百度AI研究院提出的一种端到端深度学习语音识别模型。该模型结合了深度卷积神经网络(CNN)和循环神经网络(RNN)来提取语音信号的特征,并利用连接时序分类(CTC)算法进行高效的语音识别[18]。其整体架构如图1所示。
输入数据首先通过CNN层进行卷积和池化操作,以降低数据维度并提取关键特征,例如声音的频率和时间信息。接下来,RNN层进一步处理这些特征,利用其记忆功能捕捉语音信号中的序列信息。每一层RNN的输出都会经过批归一化(BatchNormalization,BN)处理,以加速网络的收敛并提升识别的准确度。
最终,通过全连接层将RNN的输出映射到字或音素的概率分布上,并通过束搜索算法(BeamSearch)确定最可能的单词或音素序列,经过后处理得到最终的识别结果。
2.1.2Conformer
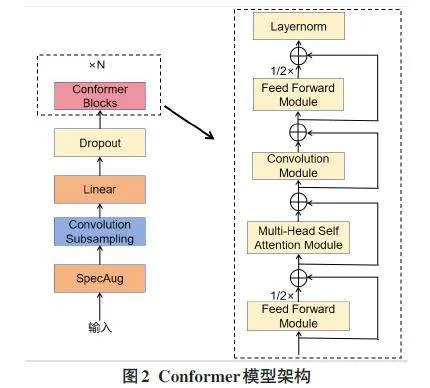
自Transformer模型问世以来,它在自然语言处理(NLP)领域取得了显著成就。同时,卷积神经网络(CNN)技术在图像处理领域也得到了广泛应用。Transformer在提取长序列依赖方面表现更为高效,而CNN则擅长捕捉局部特征。为了在语音识别任务中实现更优的性能,Gulati等人[19]提出了一种名为Con⁃former的模型,该模型有效地结合了Transformer和CNN的优势。Conformer模型的整体架构如图2所示。
Conformer模块由4个子模块依次叠加构成,包括一个前馈网络、一个多头自注意力网络、一个卷积网络和另一个前馈网络。在前馈网络中,引入了Swish激活函数和dropout技术,其具体流程如图3所示。卷积网络部分采用了预归一化残差连接、逐点卷积和线性门控单元,如图4所示。多头自注意力机制通过将输入向量分割成多个头,分别进行注意力计算,并将这些计算结果合并,从而生成输出向量。这种机制使模型能够同时关注输入序列的多个不同区域,从而提升模型性能,如图5所示。在Conformer的多头自注意力模块中,还应用了相对位置编码、dropout和预归一化残差连接。相对位置编码是一种可训练的位置编码方法,它将位置信息整合到输入向量中,帮助模型理解输入序列内不同位置间的相互关系[19]。
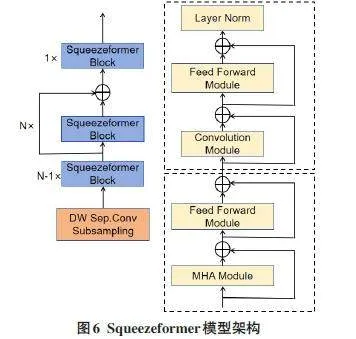
2.1.3Squeezeformer
Squeezeformer[20]通过减少注意力头数和隐藏层的维度,大大降低了模型的参数量和计算复杂度,使其在相同资源下能够处理更长的输入序列。同时,由于减少了注意力头数和隐藏层的维度,Squeezeformer的模型大小较小,所需的存储空间更少。此外,Squeeze⁃former引入了自适应正则化机制,从而提高了模型的泛化能力,使其在处理不同领域和任务的数据时表现更为出色。
Squeezeformer还引入了自注意力机制,可以更好地捕捉输入序列中的关键信息,从而使模型的预测结果更具可解释性。Squeezeformer模型的框架图如图6所示。
2.2解码器
解码器是语音识别中非常重要的组成部分。在语音识别任务中,模型输出的结果需要通过解码器才能转换为文本结果。常见的解码器包括贪心解码策略和集束搜索解码策略。
贪心解码策略是在每一步选择概率最大的输出值,然后删除连续相同的字符,从而得到最终解码的输出序列。接着,在词汇表中查找字符,将序列转换为文本,得到最终的语音识别结果。然而,贪心解码方法在性能上存在局限性,因为它没有考虑到一个输出可能对应多个不同的结果,仅选择概率最高的路径。在某些情况下,发音相似的错误字符可能会被错误地识别为最有可能的选项。
相比之下,集束搜索解码策略通过同时考虑概率相近的字符,生成多个可能的解码路径。集束搜索会扩展当前最有潜力的几条路径,而不是仅仅选择单一最优路径。这样,即使某些发音相似的字符被错误地识别,集束搜索也能够通过比较不同路径的整体概率来减少这种错误。
通过使用更优的解码器,可以有效提高模型的准确率。因此,本文采用了集束搜索解码策略。
3实验与分析
3.1实验设置
实验语料库包含三大方言的数据集,但在本实验中仅使用拉萨方言的数据集。
本文基于藏字构件作为建模单元,采用80维fbank作为声学特征,使用Adam优化器进行训练,初始学习率设置为0.0001,训练轮次(epochs)为200。
实验设计的平台为Anaconda,其他实验环境配置参数见表1。
评价指标采用字符错误率(CharacterErrorRate,CER),它通过计算识别结果与标准文本之间的字符差异来进行评估。具体来说,CER是替换、删除或插入字符的总次数与标准文本中字符总数的比率。CER比率越低,说明语音识别系统的准确性越高,因为这表示系统生成的文本与实际文本之间的差异较小。CER的计算公式如下:
CER=(S+D+I)/N
式中:S代表替换的个数,D代表删除的个数,I代表插入的个数,N代表总字符数。
3.2实验结果与分析
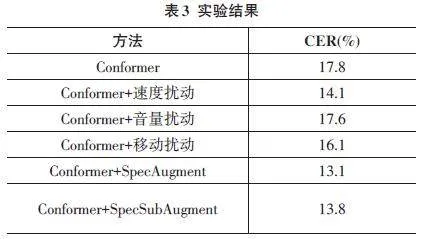
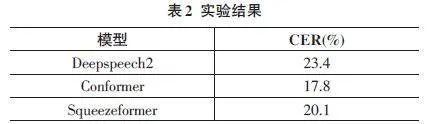
本文对比了3种主流模型DeepSpeech2、Con⁃former和Squeezeformer在藏语拉萨方言语音识别上的效果,如表2所示。其中,为了验证数据增强对藏语拉萨方言语音识别的有效性,在性能最优的Conformer模型上,使用了速度扰动、音量扰动、移动扰动、Spe⁃cAugment和SpecSubAugment等5种数据增强方法进行了对比实验,如表3所示。
从表2的实验结果可以看出,Conformer、Squeeze⁃former和DeepSpeech2等3种不同架构的语音识别模型在藏语拉萨方言数据集上均表现出良好的识别性能,其中Conformer模型表现最佳,其CER低至17.8%。
表3的实验结果表明,本文采用的5种数据增强方法对藏语拉萨方言语音识别均具有显著效果。与原始的Conformer模型相比,这些增强方法使其字符错误率进一步降低。其中,SpecAugment增强方式的字符错误率低于其余4种方法,表现最佳。
4总结与展望
本文首先探讨了3种主流的端到端语音识别模型在藏语拉萨方言公开数据集上的识别效果,其次在其中性能最优的Conformer模型上,采用了五种数据增强方法进行对比实验。
实验验证了3种模型在藏语拉萨方言语音识别任务中均具有良好的字符错误率表现,同时证明了数据增强对藏语拉萨方言语音识别具有显著的促进作用。在5种数据增强方法中,SpecAugment增强方式在该任务中表现出最优效果。
实验验证了3种模型在藏语拉萨方言语音识别任务中均具有良好的字符错误率表现,同时证明了数据增强对藏语拉萨方言语音识别具有显著的促进作用。在5种数据增强方法中,SpecAugment增强方式在该任务中表现出最优效果。
注释:
①藏语语音识别数据集.(V1).西北民族大学[创建机构],2022-08-23.国家基础学科公共科学数据中心[发布机构],https://cstr.cn/16666.11.nbsdc.ertz0y0o.
参考文献:
[1]DAVISKH,BIDDULPHR,BALASHEKS.Automaticrecogni⁃tionofspokendigits[J].TheJournaloftheAcousticalSocietyofAmerica,1952,24(6):637-642.
[2]边巴旺堆,王希,王君堡.藏语语音识别研究进展综述[J].高原科学研究,2022,6(4):76-84.
[3]周刚.藏语拉萨方言语音识别的研究[D].兰州:西北师范大学,2019.
[4]乐建建.藏语多任务多方言语音识别[D].北京:中央民族大学,2020.
[5]郭龙银,扎西多吉,尚慧杰,等.基于LSTM的藏语语音识别[J].电脑知识与技术,2020,16(4):154-155.
[6]高飞.藏语拉萨话音视频语音识别研究[D].北京:中央民族大学,2021.
[7]侯苗苗.基于CNN多特征融合的藏语语音识别的研究[D].兰州:西北师范大学,2021.
[8]算太本.基于深度学习的安多藏语语音识别技术研究[D].西宁:青海师范大学,2021.
[9]贡保加.基于MRDCNN_CTCamp;Transformer的安多藏语语音识别技术研究[D].西宁:青海师范大学,2022.
[10]朱小军.藏语安多方言语音增强和识别研究[D].西宁:青海师范大学,2023.
[11]王超.基于深度学习的端到端藏语语音识别研究[D].拉萨:西藏大学,2023.
[12]杨晓东.在线藏语语音识别系统的研究[D].兰州:西北师范大学,2021.
[13]王伟喆.基于语谱特征的藏语语音识别的研究[D].兰州:西北师范大学,2021.
[14]KOT,PEDDINTIV,POVEYD,etal.Audioaugmentationforspeechrecognition[C]//Proceedingsofthe16thAnnualConfer⁃enceoftheInternationalSpeechCommunicationAssociation(INTERSPEECH2015).Dresden:ISCA,2015:3586-3589.
[15]WANGYX,GETREUERP,HUGHEST,etal.Trainablefron⁃tendforrobustandfar-fieldkeywordspotting[C]//2017IEEEInternationalConferenceonAcoustics,SpeechandSignalPro⁃cessing(ICASSP).March5-9,2017,NewOrleans,LA,USA.IEEE,2017:5670-5674.
[16]PARKDS,CHANW,ZHANGY,etal.SpecAugment:asimpledataaugmentationmethodforautomaticspeechrecognition[EB/OL].[2023-10-20].2019:1904.08779.https://arxiv.org/abs/1904.08779v3
[17]WUD,ZHANGBB,YANGC,etal.U2++:unifiedtwo-passbi⁃directionalend-to-endmodelforspeechrecognition[EB/OL].2021:2106.05642.https://arxiv.org/abs/2106.05642v3
[18]AMODEID,ANANTHANARAYANANS,ANUBHAIR,etal.Deepspeech2:end-to-endspeechrecognitioninEnglishandmandarin[C]//Internationalconferenceonmachinelearning.PMLR,2016:173-182.
[19]GULATIA,QINJ,CHIUCC,etal.Conformer:convolutionaugmentedtransformerforspeechrecognition[EB/OL].2020:2005.08100.https://arxiv.org/abs/2005.08100v1.
[20]KIMS,GHOLAMIA,SHAWA,etal.Squeezeformer:aneffi⁃cienttransformerforautomaticspeechrecognition[J].Ad⁃vancesinNeuralInformationProcessingSystems,2022(35):9361-9373.
【通联编辑:唐一东】
基金项目:拉萨市科技计划项目(项目编号:LSKJ202405)
猜你喜欢
科技创新与应用(2017年3期)2017-02-18 15:47:14
中国新通信(2016年21期)2017-01-06 13:55:48
电脑知识与技术(2016年12期)2016-06-14 00:01:51
智富时代(2015年9期)2016-01-14 06:26:40
电脑知识与技术(2015年25期)2015-12-08 13:10:12
物联网技术(2015年9期)2015-09-22 09:34:29
现代电子技术(2015年11期)2015-07-28 12:23:40
现代电子技术(2015年8期)2015-07-09 21:40:50
电子技术与软件工程(2015年6期)2015-04-20 17:21:52
无线互联科技(2015年2期)2015-04-02 14:23:43
