
遥感解译在影像质量检查中的应用
2024-12-04 00:00:00邱姝月何奕萱陈柏行秦畅郭红操
中国新技术新产品 2024年11期
关键词:质量检查



摘 要:亚米级卫星影像为“实景三维成都”建设项目中地形级实景三维的数据基础,多个部门共享、共用,因此对其质量严格把控十分重要。采用人工目视方式对单景影像(约576 km2)进行外观符合性检查,时间约为1 h。以2023年11月成都市域亚米级卫星影像为例,将SegFormer网络模型内嵌在遥感AI解译监测系统中,对成都市域卫星影像中的不良区域进行快速识别,其平均分类精度达到81.0%,单景影像提取时间约为15 min,该系统为成都市域卫星影像质量检查工作的高效实施提供有力支撑。
关键词:卫星影像;质量检查;影像外观符合性;遥感解译;SegFormer
中图分类号:P 23" " " " " " 文献标志码:A
随着遥感和深度学习技术的发展,卷积神经网络在遥感影像特征的自动化提取中广泛应用。卷积神经网络模型过分关注局部特征,忽略整体信息,因此Dosovitskiy提出多层Transformer结构的Vit模型,在影像识别中结合了整体信息。SegFormer网络模型将Transformer编码器与轻量级解码器相结合,避免由于位置编码改变导致模型性能下降。牛玉珩[1]、杨靖怡[2]在农业、医学等领域进行研究。本文将SegFormer网络模型内嵌于遥感AI解译监测系统中,提取目标图斑。将该系统应用于成都市域卫星影像中,对不良区域进行识别,当检测影像外观时范围大、效率高,符合检验要求,缩短影像质量检验周期,减轻影像检查工作强度。
1 研究区介绍
成都市地处四川盆地西部的岷江中游地段、青藏高原东缘,位于东经102°54'~104°53',北纬30°05'~31°26',境内地势平坦,河网纵横,东界龙泉山脉,西靠邛崃山。成都市属于平原亚热带季风性湿润气候,雨热同期,四季分明。大部分地区常年云雾天气多,日照时间少,空气湿度大。
2 数据源及预处理
本次试验数据为2023年10月成都市BJ3和BJ2影像,其空间分辨率为0.5 m~0.8 m,共6景。对其进行遥感影像预处理,为使模型适用于不同类型不良区域(云雾、阴影、高亮和色彩溢出),选取相对集中区域作为样本。云雾、阴影区域普遍面积较大,高亮、色彩溢出区域普遍面积较小,如果将其构建为1个样本库,那么由于样本库数量失衡,高亮、色彩溢出影像精度会降低,因此分别构建2个样本库。样本库一为高亮、色彩溢出的单要素样本,样本库二为云雾、阴影的双要素样本,如图1所示。样本库一共选取110个区域遥感影像,并将其划分为413个512 ppi×512 ppi的样本。高亮、色彩溢出区域面积较小,为避免模型过拟合,对其进行随机缩放、翻转等数据增强操作,将其样本数扩充至826个。样本库二共选取17个区域遥感影像,将其划分为793个512 ppi×512 ppi的样本。
3 研究方法
3.1 研究流程
遥感AI解译监测系统集样本库构建、模型训练、精度评估和影像自动解译等功能于一体。对卫星影像(分辨率为0.5 m~
0.8 m)中的感兴趣(不良)区域进行人工标注,得到与影像数据相对应的标注矢量数据,并将其裁剪为512 ppi×512 ppi,完成样本库构建。将样本库一和样本库二分别按照7∶2∶1的比例划分为训练集、测试集和验证集。将训练集输入基于语义分割的SegFormer网络模型进行训练,根据样本数据集情况调整学习率、训练批次、样本数和优化方法等超参数,将网络模型提取的不良区域与验证集进行比较。根据模型在训练过程中反馈的Loss损失、训练精度等信息重新调整模型结构、参数,再次进行训练,最终获得精度最佳的模型。调动训练阶段得到的深度学习算法模型,对检测的遥感影像进行不良区域提取。
3.2 基于语义分割的SegFormer网络模型
SegFormer网络模型由2个模块组成。1)分层Transformers编码器,可产生高分辨率粗特征和低分辨率细特征。2)轻量级的A11-MLP解码器,可融合多层次特征并预测语义分割掩码,使模型鲁棒性、准确性更高。SegFormer网络模型结构如图2所示。
3.2.1 分级Transformer编码器
SegFormer采用Mix Transformer(MiT)编码器,该编码器由4个Transformer块组成,每个Transformer块包括高效自注意力机制(Efficient Self-Attention)、图像重叠块融合(Overlapped Patch Merging)和混合前馈网络(Mix-FFN)结构3个部分。
3.2.1.1 分层特征表示
基于原始分辨率为H×W×3的图像进行块处理(Transformer block),得到1个多层次化的特征图Fi,其分辨率为××Ci,C为通道数,i∈{1,2,3,4}。
3.2.1.2 图像重叠块融合(Overlapped Patch Merging)
基于1个图像块(image patch),将2×2×Ci的图像块转为1×1×Ci+1的向量,获得层次图。再将层次特征F1(××C1)收缩为F2(××C2)。如果采用非重叠的图像块或特征块,就无法保证块周围的局部连续性,因此须进行图形重叠块融合。定义K(块大小)、S(2个相邻块之间的步幅)和P(填充大小)。在本试验中,设置K=7,S=4,P=3以及K=3,S=2,P=1,将重叠的块合并,产生与非重叠过程大小相同的特征。
3.2.1.3 高效自注意力(Efficient Self-Attention)
在高效自注意力机制中,编码器主要的计算瓶颈是自注意力层,其复杂度为O(N2)。注意力层根据Q(查询)、K(键)和V(值)3个参数进行计算,Q、K和V都包括同样的维度N×C,序列长度为N=H×W,Softmax为归一化指数函数,KT为K的转置,dhead为Q、K矩阵的列数,自注意力为attention(),计算过程如公式(1)所示。
(1)
式中:为更适应分辨率较大的图像,Reshape(,C·R)(K)将K变形为×(C·R),Linear(C·R,C)()将输入通道数为C·R变为输出通道数为C的线性层,×C为K的输出维度。自注意力的复杂度从O(N2)降为O(),R为[64,16,4,1],如公式(2)、公式(3)所示。
=Reshape(,C·R)(K)" " " (2)
K =Linear(C·R,C)()" " " " " (3)
3.2.1.4 混合前馈网络(Mix-FFN)
将利用高效自注意力机制获得的结果输入Mix-FFN模块中,Mix-FFN在前馈网络(FFN)中直接使用3×3卷积来传递位置信息,避免在训练过程中以零填充导致缺失位置泄露,运用深度卷积减少参数,提升计算效率,xin为高效自注意模块的输出特征,Conv为卷积,GELU为激活函数,如公式(4)所示。
Xout=MLP(GELU(Conv3×3(MLP(xin))))+xin " " " " " " (4)
将Mix-FFN模块输出特征xout进行重叠块合并,保证像素块周围的连续性。
3.2.2 轻量级解码器
SegFormer只有一个多层感知器(MLP)组成的轻量级解码器,与传统的CNN编码器相比,模型的分层Transformer编码器有效感受野更大。
轻量级解码器利用MLP层统一不同层特征Fi的通道维度,再将特征上采样至1/4分辨率,完成拼接,MLP层融合堆叠,得到特征,利用另一个MLP解码器的融合特征预测具有H/4×W/4×Ncls 分辨率的分割掩膜M,Ncls为分类个数,Linear(Ci,C) 为以Ci和C作为输入和输出向量维数的线性层。计算过程如公式(5)~公式(8)所示。
=Linear(Ci,C)(Fi),i" " "(5)
(6)
F=Linera(4C,C)(Contact()) i" (7)
M=Linear(C,Ncls)(F)" nbsp; " " " " " " " " " " " "(8)
4 结果与分析
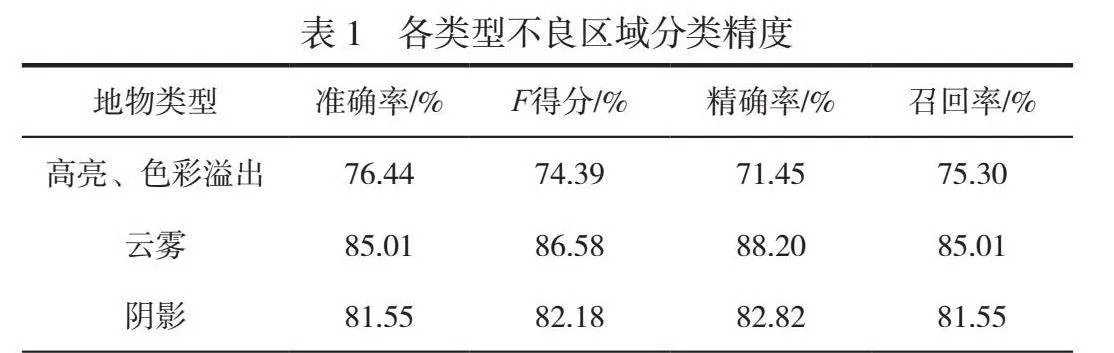
本试验基于遥感AI解译监测系统对2023年10月成都市影像的云雾、阴影、高亮和色彩溢出等不良区域进行提取,单景遥感影像(面积约为567 km2)解译仅需15 min,效率远高于人工目视判读。经多次超参数调整测试,每间隔50次迭代进行一次评估,最终确定迭代次数为6 800,批大小为4,当学习率为0.001时得到准确率最高的模型。测试数据整体精度较高,各类型不良区域分类精度见表1,模型的平均准确率为81.00%,平均召回率为81.05%。
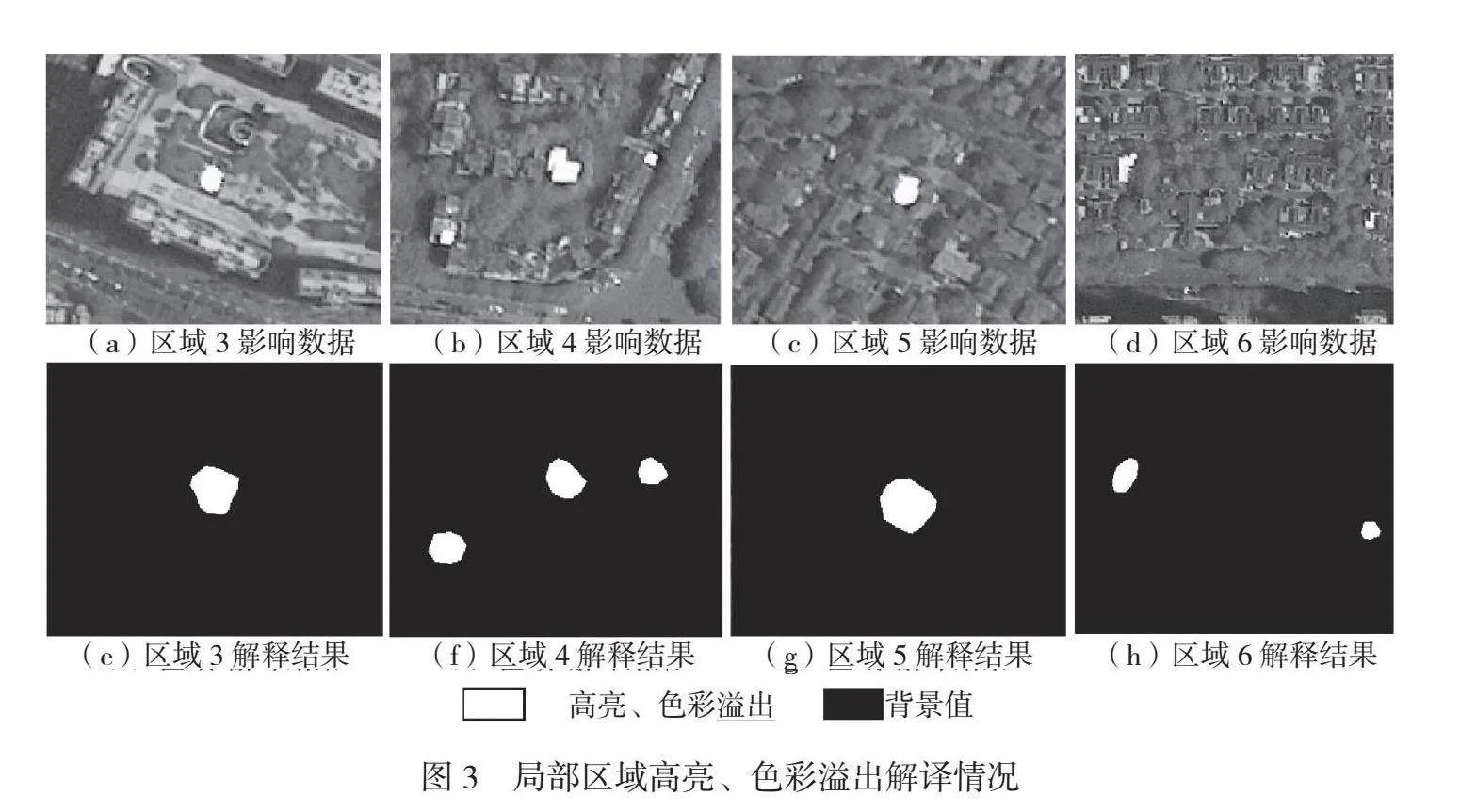
高亮、色彩溢出精度相对较低,为76.44%,整体漏检情况较少,存在少量误检情况,局部区域高亮、色彩溢出解译情况如图3所示。在采样过程中须将高亮及其周围色彩溢出区域全部采集为样本,该类不良区域特征边界并不清晰,因此模型将色彩饱和度较高区域识别为不良区域,导致其精度受限。云雾、阴影的精度分别为85.01%和81.55%,漏检、错检情况较少,局部区域云雾、阴影解译情况如图4所示。阴影区域和水体区域色调较暗,较难区分其边界,但是图4(d)模型能够准确识别阴影区域。不良区域具有范围大、边界不规则等特点,存在小面积碎斑,经批处理后能够满足助影像外观符合性检查的要求,与目视检查相比效率更高。
5 结语
以前通常采用抽查方式检查卫星影像质量,采用目视方法检查影像外观符合性,因此不仅难以掌握样本外影像外观符合性的质量情况,还会耗费大量人力资源。为解决卫星影像质量检查难题,本文基于遥感AI解译监测系统对成都市典型特征不良区域(云雾、阴影、高亮和色彩溢出)进行识别,不良区域图斑提取的总体精度为81.0%,解译时间为15 min。试验结果表明基于SegFormer模型的遥感解译系统能够学习局部和整体特征,解译准确性较高,模型迁移性能较好。SegFormer网络模型在影像不良区域中中识别效果良好,云雾、阴影以及高亮区域边界不清晰,导致模型精度受限,因此针对边缘的精确识别以及较小识别目标的识别精度仍然有待提升。
参考文献
[1]牛玉珩,李永可,陈燕红,等.基于改进SegFormer模型的棉田地表残膜图像分割方法[J].计算机与现代化,2023(7):93-98.
[2]杨靖怡,李芳,康晓东,等.基于SegFormer的超声影像图像分割[J].计算机科学,2023,50(增刊1):414-419.
猜你喜欢
通化师范学院学报(2023年11期)2023-11-23 01:52:32
审计与理财(2020年10期)2020-11-03 03:31:00
中国注册会计师(2017年7期)2017-12-09 18:46:32
科技视界(2017年12期)2017-09-11 21:47:41
科技资讯(2017年18期)2017-07-19 07:51:33
中国注册会计师(2016年8期)2016-09-20 10:53:34
当代经济(2016年26期)2016-06-15 20:27:18
商(2014年45期)2015-06-01 23:24:23
中国高新技术企业(2015年16期)2015-04-30 22:11:49
大观周刊(2013年5期)2013-04-29 21:13:55
