
基于深度学习的配网无功电压线损率改善方法研究
2024-11-25 00:00唐成年
科技资讯 2024年20期
摘要:近年来,深度学习技术已经在图像识别、自然语言处理等多个领域显示出其强大的数据处理和模式识别能力。在这一背景下,运用深度学习技术优化电网中的无功电压线损率成了一项新的研究课题。从电网数据中构建包含多变量的数据集并进行预处理,采用特征提取技术确定影响线损率的因素,之后通过深度神经网络模型,学习电网数据中的复杂模式和依赖关系,预测无功电压和线损率。深度学习技术的应用可以有效改善配网无功电压线损率,同时提高了配电网的运行效率和稳定性,具有广阔的应用前景。
关键词:深度学习 配电网 无功电压 线损率 预测
Research on Improvement Method of Reactive Power Voltage Line Loss Rate in Distribution Network Based on Deep Learning
TANG Chengnian
Altay Power Supply Co. , Ltd. ,State Grid Xinjiang Power Co. , Ltd. , Altay, Xinjiang Uygur Autonomous Region, 836500 China
Abstract: In recent years, Deep Learning technology has demonstrated its powerful data processing and pattern recognition capabilities in multiple fields such as image recognition and natural language processing. In this context, using Deep Learning technology to optimize the reactive voltage line loss rate in the power grid has become a new research topic. It constructs a dataset containing multiple variables from power grid data and performs preprocessing. It uses Feature Extraction technology to determine the factors that affect line loss rate. Then, through a deep neural network model, it learns complex patterns and dependencies in power grid data to predict reactive voltage and line loss rate. The application of Deep Learning technology can effectively improve the reactive power and voltage line loss rate of distribution networks, while also enhancing the operational efficiency and stability of distribution networks, with broad application prospects.
Key Words: Deep Learning; Distribution network; Reactive voltage; Line loss rate; Improvement methods
无功电压控制不仅关系到电网的稳定运行,还涉及整体能耗和经济效益。尽管传统方法在一定程度上有效管理了无功电压和控制线损,但随着电网负荷的日益复杂和需求的多样化,这些方法面临着灵活性不足和适应性差的问题。因此,探索更高效的技术以改善无功电压和降低线损率,对提升电网的运行效率和可靠性具有重要意义。
1深度学习理论基础
深度学习是机器学习的一个分支,通过构建多层的神经网络来模拟人类大脑处理信息的方式,实现从数据中自动学习和模式识别的能力。这种技术近年来在处理高维度、大规模数据集方面表现出卓越性能,特别是在图像识别、语音处理和自然语言理解等领域。深度学习的基础是神经网络,包括多种类型的网络结构,如卷积神经网络(Convolutional Neural Network,CNN)、循环神经网络(Recurrent Neural Network,RNN)及其变体。这些网络通过模拟神经元的连接结构来处理数据,其中每一层都执行特定的数学变换,逐渐抽象出数据中的复杂结构和特征[1]。
2深度学习下配网无功电压线损率改善方法
2.1数据集构建与预处理
配电网络数据通常涉及多维时间序列数据,包括电压值、电流值、负荷情况、天气条件等。这些数据不仅量大且具有高维特性,还常伴随噪声和不完整性,因此需要经过严格的预处理流程才能用于训练深度学习模型[2]。
数据预处理的第一步是数据清洗,目的是去除明显的错误数据和异常值[3]。例如:电压值应在规定的运行范围内,超出规定范围的数据点应被视为异常值。断电事件中的数据虽然记录为0,但在模型训练中应当予以特别标记或去除,以避免引入误导性信息。
第二步是数据归一化,这一步骤对于深度学习模型尤为重要,因为它有助于加快模型收敛速度并提高模型稳定性。归一化通常采用Min-Max标准化或Z-score标准化方法。以Min-Max标准化为例,电压和电流数据将被重新缩放到0~
1的范围内,公式为:
式(1)中:和分别是该参数在整个数据集中的最小值和最大值。
2.2特征选择与提取
采用基于信息增益率(Information Gain Ratio,IGR)的特征选择方法,并结合此方法引入特定的公式来支撑数据分析和模型优化。
信息增益率是在决策树算法中用于特征选择的一种方法,它是基于信息增益的一个改进,能够平衡不同特征带来的信息量和特征取值的多样性。首先定义信息增益(Information Gain,IG),它衡量的是在知道特征的信息之后使得目标变量的不确定性减少的程度。信息增益是目标变量的熵和给定特征后目标变量条件熵之差。
式(2)中:是目标变量的熵,计算公式为:
是给定特征后的条件熵,表示为:
式(3)中:是特征在观察中取第个值的概率,式(4)中,是在取特定值时的熵。
但直接使用信息增益作为特征选择的标准可能会倾向选择具有较多取值的特征。为了克服这一点,引入信息增益率,它在信息增益的基础上考虑了特征本身的熵,从而平衡了特征取值多样性的影响。
其中,的计算公式为
使用信息增益率进行特征选择,能够有效识别出对配电网无功电压和线损率改善贡献最大的特征[4]。通过选择值高的特征,可以构建一个不仅考虑了特征信息量,同时也平衡了特征复杂性的深度学习模型。这种方法在处理高维数据时尤为重要,如在配电网络的电压和电流监测数据中,能够准确快速地识别关键的电网运行特征,从而优化模型的学习和预测性能。
2.3深度神经网络结构设计
网络的输入层设计必须能够处理从传感器收集的多维数据,如电压、电流、负载及天气条件。对于一个典型的输入,可能包括来自数百个传感器的数据,每个传感器每分钟产生多达6个数据点(电压、电流各三相)。因此,单个小时内,输入层需要处理的数据点可高达36 000个。为了有效处理这一庞大的数据量,输入层后设有一层批归一化层(Batch Normalization),用以加速网络训练过程,同时减少模型在训练初期对初始权重的依赖。
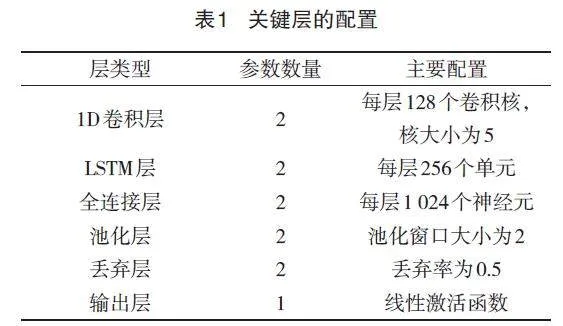
在卷积层的设计中,首先采用两层1D卷积层,每层包含128个卷积核,核大小设为5,这有助于在不同的时间尺度上提取电网数据的特征。1D卷积特别适合于处理时间序列数据,如电压和电流的波形信号。每个卷积层后跟一个最大池化层(Max Pooling),池化窗口大小为2,目的是减少数据的维度,同时保留最重要的特征信息。这种结构不仅可以增强网络的特征提取能力,还可以在一定程度上防止过拟合。
循环层的设计关键在于能够捕捉数据中的时间关联性,为此引入了两层长短期记忆网络(Long Short-Term Memory Network,LSTM),每层包含256个单元。LSTM层能够处理较长时间序列的依赖问题,对预测和控制配电网中的无功电压和线损率至关重要。每个LSTM层后接一个丢弃层(Dropout),丢弃率设置为0.5,用以进一步控制模型复杂度并避免过拟合。
最后的全连接层设计为两层,每层包含1 024个神经元,并采用ReLU激活函数以增强非线性处理能力。这些层的主要作用是将前面各层提取并汇总的特征转化为最终的输出,即无功电压调整和线损率的预测值[5]。输出层采用线性激活函数,直接输出预测的无功电压和线损率数值。
在训练过程中,采用均方误差(Mean Squared Error,MSE)作为损失函数,它能够量化模型预测值与真实值之间的误差,优化器选择Adam,因其自动调整学习率的能力,能够有效地找到损失函数的全局最小值。学习率初始设置为0.001,随着训练过程中误差的减小,通过逐步减小学习率以细化模型的权重调整,最终实现更精准的预测。
3实验测试
实验设置包括构建一个详细的电网模拟环境,该环境模拟一个中型城市的配电网络,包括多个变电站和配电点,以及连接这些节点的电缆。模型考虑了各种电网运行情况,包括高负载、低负载和典型日负载条件。实验中还模拟了不同天气条件下的电网运行,以检验模型在多变环境中的适应性和稳定性。
从实际运行的电网系统中提取大量数据,数据集包括来自过去3年的每日运行数据,总计超过1 000万条数据点,覆盖了多种操作条件,如不同季节、不同天气状况和各种负载情况。每条数据包含多达30个特征,如电压级别、电流强度、负载类型、温度和湿度等。为了提高模型的泛化能力,所有数据被分为训练集(70%)、验证集(15%)和测试集(15%)。
在模型的训练阶段,采用了深度神经网络,具体结构包括两层卷积神经网络(CNN),每层配备256个卷积核,核大小设定为3×3,步长为1。卷积层后接最大池化层,池化窗口大小为2×2,以减少数据维度和提取最重要的特征。紧接着是两层长短期记忆网络(LSTM),每层包含512个单元,用以处理和记忆时间序列数据中的长期依赖关系。全连接层包括1 024个神经元,并使用ReLU激活函数增加非线性处理能力。输出层采用线性激活函数,直接输出预测的无功电压和线损率。
为优化训练过程,选择了Adam优化器,因其自适应学习率调整机制适合处理大规模数据训练。初始学习率设定为0.001,采用指数衰减策略,每过50个epoch衰减10%。此外,为避免过拟合,引入了L2正则化项,正则化系数设置为0.01,并在每层LSTM后使用丢弃率为0.5的Dropout层。在模型训练的每个阶段,通过在验证集上评估模型的均方误差和绝对百分比误差(Mean Absolute Percentage Error,MAPE),监控模型性能。训练过程中,如果在连续10个epoch内验证集上的误差没有明显下降,则启动早停策略以终止训练,防止过拟合。整个训练过程耗时约180 min,使用了高性能计算资源,包括4个NVIDIA Tesla V100 GPU。
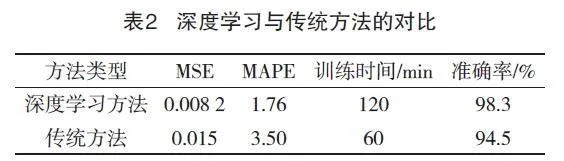
从表2对比结果来看,深度学习模型在测试集上的MSE为0.008 2,MAPE为1.76%,显示出优异的预测精度和稳定性。这些结果与传统方法相比,显示出显著的改善。例如:使用传统的回归分析方法,MSE通常在0.015以上,MAPE在3.5%以上。由此可见,深度学习模型通过学习电网数据中的复杂模式和依赖关系,能够更准确地预测无功电压和线损率,从而有效地提高了配网的运行效率和可靠性。
4 结语
基于深度学习的配网无功电压线损率改善方法能够有效提升配电网的运行效率和安全性,其应用前景广阔。通过深入研究和实践,深度学习技术有望成为未来电力系统智能化升级的重要驱动力。
参考文献
[1] 黄一腾.配电网无功电压现状及降损措施分析[J].中国设备工程,2021,(2):170-172.
[2] 刘霞,杨春.配电网无功电压现状及降损措施研究[J].通讯世界,2020,27(5):154-155.
[3] 黄菊艳.计及无功电源影响的配电网电压分区调节方法研究[D].沈阳:沈阳农业大学,2023.
[4] 刘宇骁.基于NSGA-Ⅱ和TLBO混合算法的配电网无功优化[D].哈尔滨:东北农业大学,2023.
[5] 李晋威.主动配电网无功优化的理论研究[D].济南:山东大学,2023.
