
机器学习在用户行为审计中的应用
2024-11-06 00:00:00姬盈利原晓艳汤萌萌张萍
数字通信世界 2024年10期






摘要:该文通过分析运营商业务系统多年的用户操作日志数据,运用机器学习技术揭示了各应用系统在业务操作中敏感数据操作风险、业务违规操作风险及审计漏洞。针对这些问题,提出了加强数据监控、深化业务关系分析及完善事后审查等建议。希望该文可以为相关企业在用户行为审计工作中提供一定的参考,从而让智能化审计能力更好地服务于审计工作,由此实现自动化、实时化愿景,通过多维度数据分析深化风险识别,构建风险预警模型,提升应对能力,提升审计风险管理水平。
关键词:机器学习;行为审计;智能审计
doi:10.3969/J.ISSN.1672-7274.2024.10.049
中图分类号:F 239;TP 181 文献标志码:B 文章编码:1672-7274(2024)10-0-04
Application of Machine Learning in User Behavior Audit
Abstract: By analyzing the user operation log data of operator business system for many years, this paper uses machine learning technology to reveal the sensitive data operation risk, business violation operation risk and audit vulnerability of each application system in business operation. To solve these problems, some suggestions are put forward, such as strengthening data monitoring, deepening business relationship analysis and improving post-examination. It is hoped that this paper can provide some reference for relevant enterprises in user behavior audit, so that intelligent audit capability can better serve audit work, so as to realize the vision of automation and real-time, deepen risk identification through multidimensional data analysis, build risk early warning model to improve response ability, and improve audit risk management level.
Keywords: machine learning; behavior audit; intelligent audit
0 引言
数字化时代,随着企业信息化程度的不断加深,用户行为数据已成为企业运营和安全管理中不可或缺的一部分。用户行为审计作为监控和分析用户活动、确保业务合规性和安全性的重要手段,正面临着前所未有的挑战。经对比分析可知,传统的用户行为审计方法往往依赖于日志分析、规则匹配等技术,然而这些方法在处理海量、高维、复杂的用户行为数据时,却难以准确捕捉异常行为模式,及时预警潜在风险[1]。
近年来,随着人工智能技术的发展,机器学习凭借着能够深入挖掘用户行为数据中的隐藏规律和潜在风险在审计分析领域得到了一定范围的应用。为进一步展示机器学习在用户行为审计中的巨大潜力,本文以运营商某业务系统为例,将该业务系统全体用户作为审计研究对象,探讨机器学习在该机构用户行为审计中的应用,并总结其运行思路,以期为更多企业在今后的数字化转型中提供更为高效、精准的安全防护手段。
1 用户操作的数据采集及处理
1.1 数据采集
经调研可知,当前该业务系统目前主要以敏感数据查询和数据维护为主。而无论是哪种业务操作,都存在一定的敏感数据操作风险。本文针对敏感数据源的数据采集、分析、汇总,借助业务系统内部员工的系统操作日志进行数据采集并保障数据的完整性。
1.2 数据处理
1.2.1 批量业务操作识别
用户数据处理的判断依据是基于用户操作行为的一致性和连续性,以及系统日志的变化情况。具体而言,当系统日志从A切换到B时,通常意味着用户环境或操作场景发生了显著变化。在这种变化下,如果用户需要重新登录,或者即使不需要登录也需要花费较长时间(如1到2分钟),产生的数据泄露等问题[2]。基于这一用户操作原理,本文将用户操作风险主要划分为以下几种。
(1)身份验证风险:当用户登录某敏感系统从一个常用终端切换至另一个时,则存在身份验证被绕过或假冒的风险,攻击者可能利用这一时机,通过伪造身份或利用漏洞进行非法登录。
(2)数据泄露风险:用户登录敏感系统进行上传或下载数据等操作,往往需要一定的时间,此过程中数据容易被攻击者盗取或篡改,进而导致敏感数据在传输或存储过程中泄露。
(3)会话劫持风险:在系统日志切换过程中,如果会话管理不当,攻击者可能利用会话标识符(如Session ID)劫持用户的会话,从而控制用户账号进行非法操作。
(4)操作异常风险:用户操作行为的突然变化,如频繁切换系统日志、操作异常等,也可能是内部欺诈或外部攻击的征兆。
因此,本文将基于机器学习技术,将审计数据按照用户操作划分,并根据用户操作连续性对数据进行编号分组。
1.2.2 构建用户关系
经调研可知,用户之间的关系十分错综复杂,他们既有直接的关系,如上下级关系、同事关系等,同事也有间接的关系,如通过共同行为、操作记录等建立的关联。因此在业务系统审计中,识别和理解用户之间的这些关系对于发现潜在的风险和违规行为至关重要。
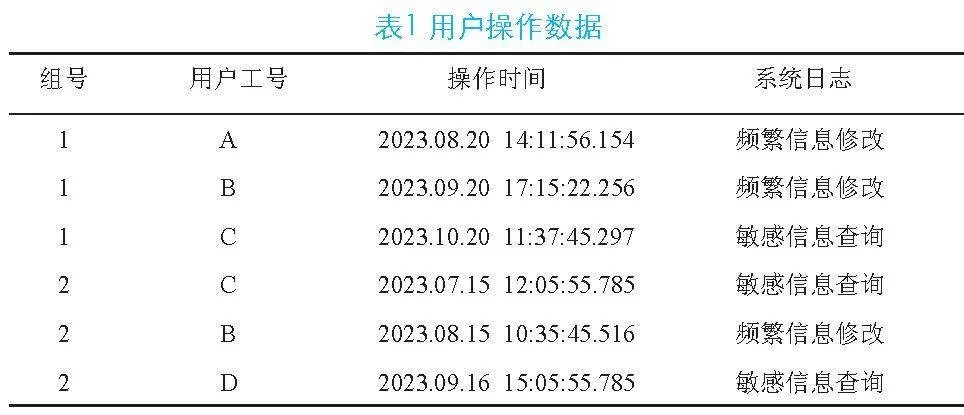
本文以该业务系统某一年典型审计案例为例,在第三季度,审计团队发现了一批敏感数据,这些数据显示某些用户频繁地进行数据修改、保存、查询操作,且这些操作与他们的日常业务活动不符。进一步分析发现,这些用户之间存在着大量的同时操作记录,这表明他们之间很可能建立了某种紧密的联系。为了更清晰地展示用户之间的关系,本文基于机器学习技术,对用户操作数据进行分组和编号,如表1所示。本文通过比较用户工号、操作时间、系统日志等信息,将具有相似操作行为的用户划分一组并赋予组号,旨在更为直观地观察哪些用户之间存在紧密联系,以及他们之间的操作行为是否具有一致性或连续性。
由表1可知,根据第一组数据(组号为1),在节点A、B、C之间构建关系,形成第一组关系图。首先,这里节点A和B都涉及了频繁信息修改的操作,而节点C则涉及敏感信息查询操作,尽管操作类型不完全相同,但由于它们在同一组内,因此本文认为节点A、B、C之间存在一定的关联;其次,根据第二组数据(组号为2),在节点C、B、D之间构建关系,形成第二组关系图。在这一组中,节点C和D都涉及敏感信息查询的操作,而节点B则再次出现在了频繁信息修改操作中。这进一步强化了节点B与其他用户之间的关联,尤其是与节点C的关联,因为C同时出现在了两个组中;最后,将这两组关系合并后,由此得到如图1所示的一个新的关系。在这个图中,节点B和C之间由于同时出现在了两个组中,因此它们之间的权重为2,这表明节点B和C之间的关系确实比它们与其他节点的关系更加紧密。这种紧密关系可能暗示着节点B和C之间有着某种共同的业务活动或利益关联,需要进一步通过审计和调查来确认。
基于思路,本文在SQLServer数据库中对该业务系统的全部数据进行梳理统计,并借助Python的NetworkX包在FR布局算法下进行可视化展示,得出图2完整用户关系图。
需要说明的是,图2中实线表示边的权重大于2,而虚线则表示边的权重小于等于2。
2 基于机器学习的客户关系分析
2.1 样本训练
为更好地识别及分析用户操作数据中的敏感数据,提取了业务系统一年的历史资料,由此构建了一套基于当年年度的历史资料的回归模型,并以过去10年的系统操作日志为研究对象,进行了滑动交叉验证的样本训练,其过程如图3所示。
2.2 数据降噪
为进一步减少数据中的噪声和异常值,提高模型的准确性和可靠性,本文首先通过数据清洗步骤,识别并去除了那些明显不符合逻辑或业务规则的数据记录,如时间戳错误、数据异常(如修改、查询过于频繁)等。其次,本文又应用基于统计学的数据平滑技术,计算了每个特征字段(如修改、查询时间等)的均值、标准差等统计量,并根据这些统计量设定了合理的阈值范围[3]。对于超出这些阈值的数据点,本文采用平滑处理的方法,如平均值替代、中位数替代或回归预测值替代,以减少其对整体数据集的负面影响。最后,为了进一步提高数据质量,本文还采用了聚类分析的方法,通过将数据集中的样本划分为若干个群组,使得同一群组内的样本之间具有较高的相似性,而不同群组间的样本则具有较大的差异性。其目的不仅可以减少噪声数据对模型的影响,而且还可以更好地理解用户行为的多样性和复杂性。如图4所示。
2.3 关系分析
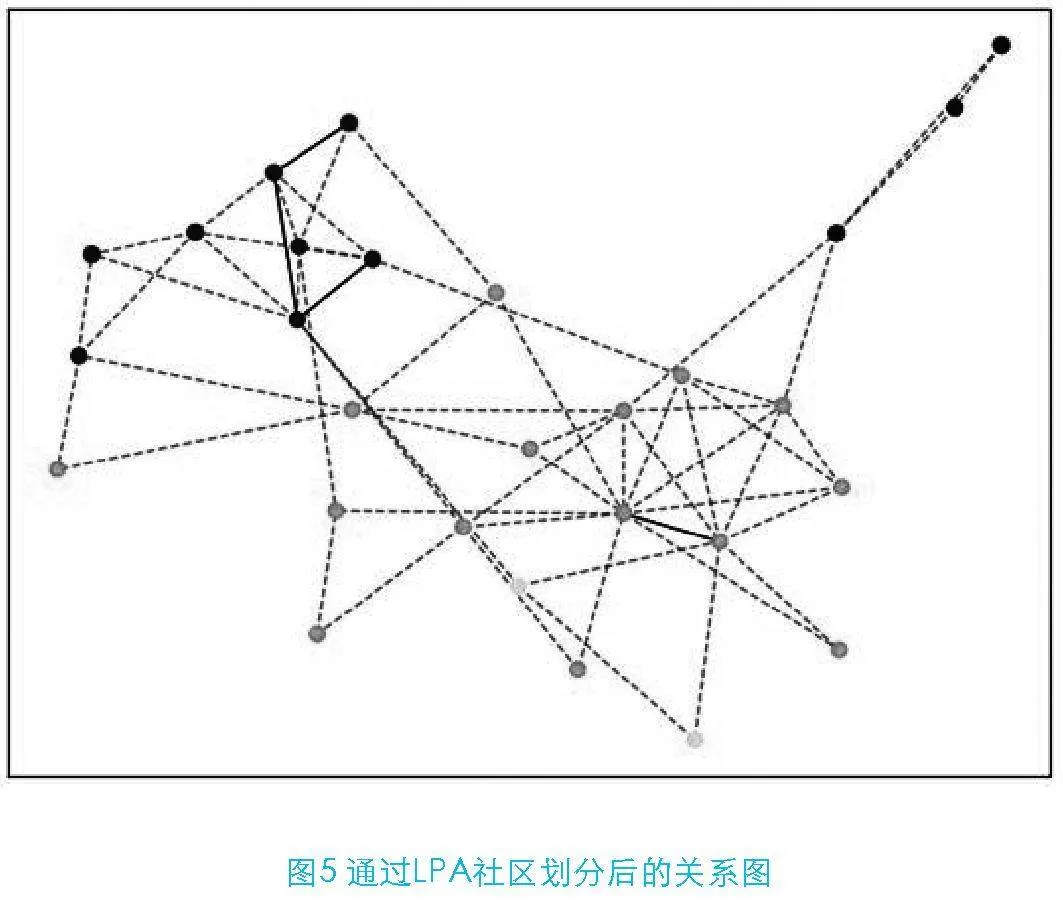
在剖析客户关系图时,虽然图4基于多个独立联通子图揭示了“客户团伙”的清晰界限,简化了初步识别的过程。但面对完整用户关系图的复杂场景,必然会将多个团伙因人员众多或偶然性关联而交织在一起。因此为应对这一挑战,本文引入了社区发现算法,旨在提升模型在复杂网络中的适用性和准确性。如图5所示,基于社区发现算法的机器学习技术,能够有效识别网络中具有高度内聚性和相似性的节点集合,即“社区”或“团伙”。
在众多社区发现算法中,笔者发现经过多轮实验与测试,其中的标签传播算法(Label Propagation Algorithm,LPA)不仅操作简单高效,而且易于实现且能够处理好大规模网络数据,因此,本文通过应用LPA算法对原有的独立团伙进行识别,以期可以解析那些因复杂关联而难以区分的节点群。最终,经算法通过运行后,对属于同一团伙的客户进行了颜色编码标注,得出了如图6所示结果。其中,节点最多的联通子图内的团伙识别尤为清晰,提供了直观的团伙结构视图。
3 人工核查的审计成果分析
完成团伙识别后,笔者对该业务系统日志中存在敏感操作数据较多的人员进行抽取,并基于全部用户关系进行划分后的关系图进行重点核查,进而得到了如图7所示的团伙作案结果。
通过本次审计,发现第三季度的个人业务操作中存在多起敏感数据,并基于这些数据进行了调研,最终确实发现了存在审计问题的不良事件,涉及敏感数据泄露。通过此次基于机器学习的用户行为审计,笔者协助该机构责令相关部门整改,很好地规避了数据泄露事件发生。
4 结束语
本文通过对运营商业务系统一年的历史操作日志数据进行深入分析,特别是在用户操作数据采集、处理及用户关系分析的基础上,发现了该机构在业务操作中存在的几大问题:一是部分用户在操作过程中存在频繁修改信息和查询敏感信息的行为,增加了敏感数据的风险;二是该机构存在多个员工利用复杂关系网络进行批量化业务操作行为,这些行为严重造成了数据泄露风险,并可能对业务系统敏感数据造成重大损失;三是部分数据修改及查询行为实际是企业所为,但名义上却由个人承担,这表明业务操作及检查存在严重漏洞,未能及时发现并阻止此类违规行为。据此,本文通过数字审计有效排查了数据数据泄露风险。
而在未来的审计工作中,建议该机构以及更多类似业务系统需要加强数据监控与分析,通过建立更加完善的数据采集与处理机制,利用先进的机器学习技术实时监控用户操作行为,继续优化用户关系分析模型,提高团伙识别和复杂关系网络解析能力,确保敏感数据用途的真实性和合规性,提高风险应对的效率。通过平台的广泛应用,或是结合大数据、云计算等先进技术,实现多维度、多层次的数据分析,发现更多隐藏的风险和问题,为审计工作提供更加全面的支持。
参考文献
[1] 崔景洋,陈振国,田立勤,等.基于机器学习的用户与实体行为分析技术综述[J].计算机工程,2022,48(2):15-30.
[2] 郭迅华,吴鼎,卫强,等.机器学习与用户行为中的偏差问题:知偏识正的洞察[J].管理世界,2023,39(5):145-159.
[3] 吴勇,方君,王尚纯,等.基于机器学习模型的审计应用:内涵,模式与风险[J].中国注册会计师,2021(9):34-40.
