
基于大数据的审计案件线索分类研究
2024-11-06 00:00:00庄晓明
数字通信世界 2024年10期
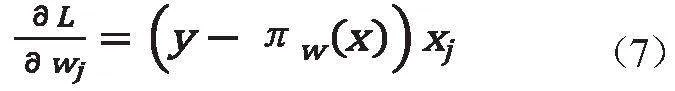
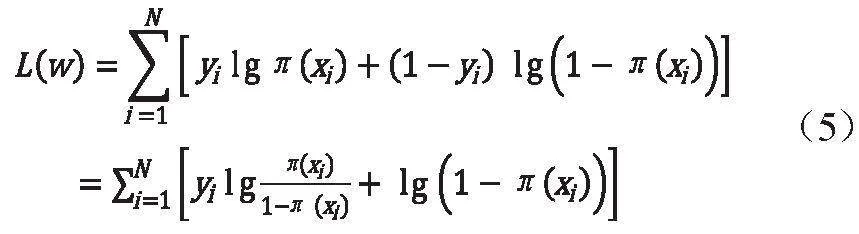


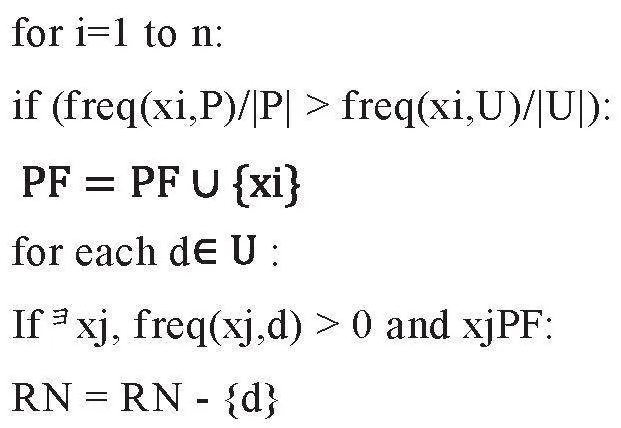

摘要:随着大数据技术的迅速发展与应用,审计案件线索分类面临着诸多挑战,如数据质量与准确性不高、数据处理与分析难度增加、数据隐私与保密性需强化、缺乏标准与规范等。针对这些问题,该文提出了相应的策略,旨在提高审计案件线索分类的效率与准确性。同时,本文也可以为其他领域的数据分析提供一定的借鉴与参考。
关键词:大数据;审计案件线索;分类策略
doi:10.3969/J.ISSN.1672-7274.2024.10.014
中图分类号:F 239;TP 3 文献标志码:A 文章编码:1672-7274(2024)10-00-04
Research on the Classification of Audit Case Clues Based on Big Data
Abstract: With the rapid development and application of big data technology, the classification of audit cas+4dTfC3n6nO/QR3SwPGjHUpriYT1IBeqJCB2Sz4mSOg=e clues faces many challenges, such as low data quality and accuracy, increased difficulty in data processing and analysis, need to strengthen data privacy and confidentiality, and lack of standards and norms. In response to these issues, this article proposes corresponding strategies aimed at improving the efficiency and accuracy of audit case clues classification. At the same time, this article can also provide some reference for data analysis in other fields.
Keywords: big data; audit case clues; classification strategy
在当今社会,大数据技术的迅速发展与广泛应用为各个领域带来了巨大的机遇与挑战。审计作为一项涉及大量数据与复杂分析的经济监督活动,如何有效利用大数据技术进行审计案件线索分类,提高审计效率与准确性,是当前审计行业面临的重要问题[1]。通过本研究,我们希望能够为审计行业提供有益的参考,推动审计技术的创新与发展,提高审计工作的效率与准确性。
1 审计案件线索分类相关技术发展现状
1.1 数据质量与准确性不高
在大数据环境下,数据的来源与类型多种多样,这使得数据的质量与准确性成为一个重要的问题。由于数据可能包含各种主观与客观的错误,如遗漏、误解与错误,这可能导致审计线索的误导与不准确[2]。此外,不同数据源之间的数据差异也可能导致审计线索分类的不准确。
1.2 数据处理与分析难度增加
大数据的规模与复杂性要求审计师具备更高的数据处理与分析能力。他们需要使用更高级的技术工具与算法来处理与分析这些数据,以便准确地识别与分类审计线索[3]。然而,目前许多审计机构缺乏这方面的技术与人才,这限制了1Ycw0ViFupgHdBTvXvLYSqSpkFcgU1S2smIXtC1TBO8=大数据在审计中的应用与发展。
1.3 数据隐私与保密性需强化
在大数据背景下,数据的隐私与保密性成为一个重要的问题。审计师需要采取措施保护个人与企业的敏感信息,防止数据泄露与滥用。然而,如何在保护数据隐私与保密性的同时,有效地利用大数据技术进行审计案件线索分类,是一个亟待解决的问题。
2 基于大数据的审计案件线索分类策略
2.1 提高数据质量与准确性
第一,建立数据质量标准:根据审计需求,建立一套完善的数据质量标准,包括数据的完整性、准确性、一致性与真实性等方面。通过数据清洗、验证等手段,提高数据的准确性与质量。第二,定期评估数据质量:定期对数据进行质量评估,发现数据中存在的问题与错误并及时进行纠正与修复。同时,通过评估数据质量,可以发现数据来源与数据采集等方面存在的问题,进一步优化数据采集与数据处理流程。第三,强化数据质量监控:在数据处理与分析过程中,需要不断监控数据质量,及时发现与处理数据异常与错误。通过建立数据质量监控机制,可以实时监测数据的质量与准确性,保证数据的准确性与可靠性。
2.2 优化数据处理与分析流程
首先,数据预处理:在进行数据处理与分析之前,需要对数据进行预处理。数据预处理包括对数据进行清洗、去重、填充缺失值等操作,以保证数据的准确性与可靠性。其次,数据分组与分类:根据数据的特征,将数据进行分组与分类。通过分组与分类,能够将数据划分为不同的类别与组别,以便后续的数据分析与挖掘。再次,数据聚合与汇总:将数据进行聚合与汇总,将分散的数据整合成整体的数据。通过数据聚合与汇总,可以发现数据中隐藏的规律与趋势,为审计案件线索的分类提供有力的支持。最后,数据可视化与分析:通过数据可视化与分析工具,将数据进行可视化展示与分析。通过可视化展示,能够更加直观地展示数据的分布与特征,便于发现数据中存在的问题与异常。
2.3 强化数据隐私与保密性
首先,建立数据隐私与保密性政策:制定明确的数据隐私与保密性政策,对数据的采集、存储与使用等方面进行规范与管理。同时,加强对数据使用人员的监管与教育,防止数据泄露与滥用。其次,数据加密与加密存储:采用数据加密技术,对敏感数据进行加密处理。同时,将加密数据存储在加密存储设备中,防止数据被非法获取与利用。再次,数据访问权限控制:对数据的访问权限进行严格控制,只有经过授权的人员才能访问敏感数据。同时,采用多层次的安全审计机制,对数据的访问与使用进行实时监控与记录。最后,数据备份与恢复:对数据进行定期备份与恢复操作,以防止数据丢失与损坏。同时,采用灾备恢复机制,确保备份数据的可用性与完整性。
3 审计案件标签管理系统设计方案
3.1 案件线索标签设计及重要性计算
使用种子线索覆盖率作为标签重要性的量化指标,基本步骤如下:
①获得种子线索CID列表CID_SEED,共计N个CID。
②将标签案件线索表与种子线索CID列表内关联,获得种子线索标签案件线索表TAG_SEED。
③设当前标签管理系统中基础标签个数为M,在TAG_SEED中对每个标签的最新业务版本计算CID个数CNT(i),i=1…M。
④每个标签在种子群体上的覆盖率为X(i)=CNT(i)/N,i=1…M,覆盖率越高,重要性越高。
将标签按照重要性进行可视化,即确定从标签覆盖率图像尺寸空间的一个单增映射,以体现重要性和覆盖率正相关的关系。
典型的映射F有线性函数AX+B(A>0,B>0)、指数函数AX(A>0)和N次函数XN(N>1)等。最终上线版本可考虑提供多种函数接口,呈现不同分布种类的云图(映射的梯度越大,标签重要性的区分度越大)。
3.2 模型设计
3.2.1 模型定义
采用带正例的无标记样本学习(PU Learning),正例即种子线索。可定义,种子线索(记为P,即Postive)相对于未标注的对照案件线索群体(记为U,即Unlabled)来说,规模要小得多。PU学习的主要步骤有:
①根据P线索在U中找出可靠的负样本集合RN(Reliable Negative),以便将PU问题转换为经典的二分类问题。
②使用P和RN分别作为正负样本,训练分类模型。
3.2.2 确立可靠负样本
常用的算法有朴素贝叶斯、Rocchio、SPY、1-DNF等。综合考虑基础标签定义形式和当前标签管理系统存储结构,优先考虑1-DNF算法。
1-DNF算法基本思想是:对于每个特征,如果其在P集合中的出现频次大于N集合,记该特征为正特征(Positive Feature,PF),所有满足该条件的特征组成一个PF集合。对U中的每个样本,如果其完全不包含PF集合中的任意一个特征,则该样本应加入RN。算法步骤描述如下:
①PF置空,RN=U。
②设的特征集为。
实现方法及主要问题。从上一步做完独热编码的模型宽表出发进行上述算法操作,一个可行的通过基本数据转换(查询语句)实现的步骤如下:
①设宽表字段为CID,X1,…,XN,IS_P。其中X1到XN为N个0-1特征,IS_P为是否正例的0-1标记。生成如下2N个新列:Pi=Xi*IS_P, Ui=Xi*(1-IS_P),i=1 to N。
②对P1,…,PN和U1,…,UN字段全表Group By求和得到一个维度为1*2N的横表,结构为SUM_P1,…,SUM_PN,SUM_U1,…,SUM_UN。
③使用宽转长操作将上表转成N*3维的竖表,字段为FEATURE_INDEX,SUM_P,SUM_U,其中FEATURE_INDEX值为“X1,…,XN”。
④对竖表通过条件SUM_P/|P|>SUM_U/|U|进行过滤,留下的FEATURE_INDEX用来表征PF特征集,假设剩下n个特征。
⑤将上一步的FEATURE_INDEX做长转宽操作变为维度为1*n的宽表,列名为Xa1,Xa2,…,Xan。其中a1到an为1到N的一个子集,n≤N。表的值为常数0。
将原始宽表和第c229a2df00bd77be5fa52c86f6084266cfb1269e6ccdd0c083f463c313d13471⑤步中的横表用(Xa1,Xa2,…,Xan)组合键做内关联,关联所得的CID即为RN集合。
与特征集转换过程一样,该步骤的主要问题还是需要确保编码的参数泛化问题,如上述过程中的N。
3.2.3 模型训练及算法选择
确定可靠负样本之后,将其作为负样本与种子线索所代表的正样本合并即可使用分类器训练模型。我们分别尝试逻辑回归和Xgboost算法。最终上线版本(或者均上线提供模型选项)取决于平台实际情况和后续测试结果。
3.2.3.1 逻辑回归
逻辑回归属于经典的广义线性模型,我们的问题属于二项逻辑回归模型:
式中,X∈R是自变量;Y∈0,1是输出;w为权值向量;b为偏置;w·x是w和的内积。
设训练集中有N个样本。假设:
则似然函数为:
对其求对数似然函数有:
从而对求得极大值,得到w的估计值。求极值的方法可以是梯度下降法、梯度上升法等。
主要实现步骤有:
(1)生成训练数据。将正样本集P与上一步中获得的可靠负样本集RN合并,统计正样本率,即Target Rate。如果Target Rate过于不平衡(<1%或>99%)则应考虑重新抽样使得正、负样本平衡——当RN过大,则对RN集进行抽样;当P过大则对P进行抽样。逻辑回归效果不受轻度样本不均的影响,因其损失函数不是由正确率来决定的,而是计算最大似然值。这一步最终生成训练数据。
将逻辑回归算法进行编码。一般的做法是将开源的算法包接入大数据平台对训练数据使用算法获得模型参数,如spark的MLlib包即提供逻辑回归的算法功能。
由于逻辑回归模型参数计算的最大似然问题较为简单,开发者直接使用编程语言也能轻易实现。例如,可采用随机梯度上升法最大化,迭代函数为
其中为梯度向量,分量为的偏导,即
故随机梯度上升迭代算法为
重复下面直到收敛
3.2.3.2 Xgboost
Xgboost是适用于大规模并行运算的提升树开源工具包,大量数据挖掘竞赛选手采用它,展现了强大的威力。同时该算法包的扩展性和可移植性强,便于工业界大规模问题的解决。在当前问题中的实现步骤与逻辑回归方法类似,包括:
(1)生成训练数据。由于Xgboost是多个回归树的“加法”,故对于样本不平衡的处理方法与逻辑回归类似。在极度不平衡的情况下需要进行重抽样处理。
使用Xgboost算法包对训练数据运行模型算法,生产成模型框架Object。使用何种语言编码取决于大数据平台的版本,并且需要仔细进行测试,保证算法包使用正确、结果可靠。无须算法层面的编码,因为Xgboost包提供多种接口,包括C++、R、Python、Julia和Java。甚至,许多开源工作者开发了在多种分布式计算系统上直接能够使用的API,通过正确的流程控制和API5CSKRcP4MPtNAcljfFof4A==使用编码,能轻松地实现Xgboost算法快速和高效的功能。例如,Xgboost4J是一个能同时在Spark、Flink和Dataflow等JVM平台上使用的便携式API。通过它即可引用Xgboost包中的各种功能。
(2)模型打分。使用上一步生成的模型object对测试集上的样本点进行打分。
之后投产的步骤需要在U集线索上进行打分,输出的正例概率值可作为同P正例线索相似度的度量衡。
4 模型评估
由于该问题是半监督问题,只有正例的实际结果,无法在全量数据上进行模型和实际结果的对比验证。不过,依然可以从以下两方面入手,评估模型效果:
(1)评估带“可靠负样本”标签的分类模型本身的效果。使用传统的ROC曲线、AUC、KS值及混淆矩阵等。根据实际需求可以考虑在系统中开放相关指标的可视化接口,供业务人员参考。
(2)可以单纯研究模型在“正例”上的分数分布。正例上的分布越一致地接近1,说明正例的统一性以及同其他样本的区分度越高。
5 审计案件标签管理系统技术效果
审计案件标签管理系统使用了半监督的机器学习及算法来实现案件、线索的智能分类,随着时间的推移和使用次数的增多,该分类模型将越来越精细,越来越准确。同时,该发明可协助企业廉政部门快速对案件进行分类,并能协助客户系统快速罗列出历史案件信息,并展示出历史优秀案件办理过程,提升案件办理效果和线索采纳效率。
总之,通过对大数据技术的深入分析与应用,我们提出了一系列策略与方法,旨在提高审计案件线索分类的效率与准确性。我们针对一系列问题,提出了相应的解决策略。然而,尽管我们在基于大数据的审计案件线索分类方面取得了一定的成果,但仍有许多问题需要深入研究与探讨。总的来说,本文的研究为审计行业提供了有益的参考与指导,为推动审计技术的创新与发展、提高审计工作的效率与准确性做出了贡献。同时,本研究也可以为其他领域的数据分析提供一定的借鉴与参考。
参考文献
[1] 周海鹰.基于协同治理视角的审计案件线索移送机制研究[J].财会通讯,2021(19):120-124.
[2] 谢秋玲.审计证据链在经济案件中的司法运用[J].审计文摘,2022(11):92-95.
[3] 王阳,杜霞.高校审计线索分析方法探究[J].审计与理财,2022(3):14-16.
