
基于改进注意力机制与VGG⁃BiLSTM的暴力行为检测
2024-11-02 00:00:00李金成闫睿骜代雪晶
现代电子技术 2024年21期



摘 "要: 为解决单一深度卷积神经网络VGG特征提取的局限性,以及单一循环神经网络RNN在记忆历史信息方面的困难,提出改进注意力机制与深度时空网络的深度学习模型VBA⁃net的暴力行为检测方法。首先,通过VGG的深层神经网络提取关键局部特征;其次,运用改进后的注意力机制捕捉和优化最显著的特征;最后,利用双向长短期记忆网络处理过去和未来的时序数据。仿真实验结果表明,VBA⁃net在规模较小的HockeyFight和Movies数据集上的准确率分别达到了97.42%和98.06%,在具有多样化内容和复杂环境数据集RWF⁃2000和RLVS上准确率分别达到89.00%和95.50%,因此其在复杂环境的综合鲁棒性优于同类算法,可有效提升暴力行为检测任务中的准确率。
关键词: 暴力行为检测; 深度卷积神经网络; 双向长短期记忆网络; 注意力机制; VBA⁃net; 特征提取
中图分类号: TN919⁃34; TP391.41 " " " " " " " " 文献标识码: A " " " " " " " " " "文章编号: 1004⁃373X(2024)21⁃0131⁃08
Violence behavior detection based on improved attention mechanism and VGG⁃BiLSTM
LI Jincheng, YAN Ruiao, DAI Xuejing
(College of Public Security Information Technology and Intelligence, Criminal Investigation Police University of China, Shenyang 110854, China)
Abstract: In view of the limitations of feature extraction in a single deep convolutional neural network VGG (visual geometry group) and the challenges of historical memory in a single recurrent neural network (RNN), an improved deep learning model for violence behavior detection, known as the visual geometry group network⁃bidirectional long short⁃term memory network⁃improved attention mechanism (VBA⁃net), has been proposed. This model is based on improved attention mechanism and deep spatio⁃temporal network. The approach begins by extracting key local features with the deep neural network (DNN) of the VGG. Subsequently, an improved attention mechanism is employed to capture and optimize the most significant features. Finally, the bidirectional long short⁃term memory network (Bi⁃LSTM) is used to process temporal data of both past and future contexts. Simulation results demonstrate that the VBA⁃net achieves accuracy rates of 97.42% and 98.06% on the smaller HockeyFight and Movies datasets, respectively, and accuracy rates of 89.00% and 95.50% on the more diverse and complex RWF⁃2000 and RLVS datasets, respectively. Thus, it exhibits superior comprehensive robustness in complex environment in comparison with the similar algorithms. To sum up, it can improve the accuracy of the tasks of violent behavior detection effectively.
Keywords: violence behavior detection; DCNN; Bi⁃LSTM; attention mechanism; VBA⁃net; feature extraction
0 "引 "言
近年来,随着计算机视觉领域的快速发展,暴力行为识别已成为研究热点之一,并且在校园安全管理、城市监控系统以及家庭安全等方面具有应用价值。随着深度学习技术的发展,这一领域的研究方法呈现快速发展的趋势。与传统技术相比,深度学习能够自动地提取低层次到高层次的抽象特征,特别是卷积神经网络(CNN)和循环神经网络(Recurrent Neural Network, RNN)成为处理此类问题的主流技术,吸引众多学者构建新的模型。文献[1]采用3D SE⁃Densenet模型提取视频中的时空特征信息,但未充分考虑暴力行为的时序性。文献[2]将前景图输入到网络模型中提取视频特征。首先利用轻量化EfficientNet提取前景图中的帧级空间暴力特征;然后利用卷积长短时记忆(ConvLSTM)网络进一步提取视频序列的全局时空特征。文献[3]提出一种改进R⁃C3D网络的暴力行为时序定位方法,将残差模块的直接映射分支结构进行优化,减少时空特征丢失,同时将残差分支进行时空特征密集拼接,减少梯度弥散。文献[4]使用卷积长短期记忆网络来学习检测暴力视频的方法,通过使用ConvLSTM网络结构,利用视频序列的时空信息进行暴力行为检测,但缺乏数据处理的灵活性和泛化能力。
注意力机制已经被证实是一种有效的策略,通过对不同模块的自动加权,关注输入序列中的特定部分。文献[5]提出一种基于注意力机制的BiLSTM模型,该模型通过注意力机制对行为序列中的重要部分进行自动加权,有效地分析行为前后关系,从而实现高精度的行为识别。
综上所述,我国在计算机科学领域已取得一系列重要成就,但在模型分类和仿真技术方面仍存在一定的缺陷。因此,本文提出一种改进注意力机制与深度时空神经网络的暴力行为检测模型——VBA⁃net(Visual Geometry Group Network⁃Bidirectional Long Short⁃Term Memory Network⁃Improving Attention Mechanism)。该模型结合VGG网络(Visual Geometry Group Network)和双向长短期记忆(BiLSTM)神经网络的优势来提取视频序列中的时空特征。在VGG网络中引入一种基于格拉姆矩阵运算的残差自注意力机制,进一步增强模型对于关键特征的识别能力,从而提升模型在暴力行为检测任务中的准确率和鲁棒性。
1 "方法及原理
1.1 "VGG⁃19网络
VGG⁃19网络主要由卷积层、池化层和全连接层构成。卷积层通过卷积运算来处理输入数据,捕捉局部特征;池化层则对卷积层的输出进行下采样,降低特征维度,增强模型的泛化能力;全连接层在网络末端将前面提取和筛选过程中的特征进行加权组合。这种结构安排使得VGG网络在视频识别任务中表现出卓越的性能。VBA⁃net对于每个视频帧,提取“FC2”层的输出作为帧的特征表示。VGG⁃19网络结构如图1所示。
卷积核与输入数据先相乘再对应求和的过程称之为卷积运算,具体运算过程为:
[G×ω=k=1Cj=1Wi=1H[Gk(i,j)ωk(i,j)]] (1)
式中:[G]为卷积层的输入数据;[ω]为卷积核的权重参数;[C]、[W]、[H]分别为卷积核的通道数、宽、高。
在VGG模型卷积层中改变激活函数,完成非线性运算,选用PReLU(Parametric Rectified Linear Unit)函数作为激活函数,解决ReLU在[x]lt;0部分导致神经元死亡的问题,其公式为:
[PReLU(x)=x,x≥0ax,xlt;0] (2)
PReLU函数旨在解决传统激活函数的零梯度问题,通过给负值输入引入一个微小的线性成分,即应用[ax](其中[a]是一个较小的正系数)来调整,从而保持网络在负值区域的学习能力。
1.2 "BiLSTM网络
BiLSTM是长短期记忆(LSTM)网络的一个变体,通过将两个LSTM层并行排列实现,其中一个LSTM层负责处理正向的序列信息(从开始到结束),另一个LSTM层则处理反向的序列信息(从结束到开始)。这种结构允许BiLSTM同时捕获序列中的前向和后向的上下文信息,使其能够在某一点上同时考虑前面和后面的数据,最终,这两个方向上的信息被组合在一起,以做出更加全面和准确的预测[6]。
BiLSTM网络结构如图2所示。
在时间步[t]的网络输出预测值为:
[ylt;tgt;=g(Wy[alt;tgt;;alt;tgt;]+by)] (3)
式中:[alt;tgt;]、[alt;tgt;]分别为时间步[t]的正向LSTM隐藏状态和反向LSTM隐藏状态;[t]代表时间;[Wy]代表输出层的权值向量,用于将BiLSTM网络的隐藏状态转换为输出;[by]代表输出层的偏置向量,用于激活函数之前的线性变换;[g]代表激活函数sigmoid,值域为[0,1]。
1.3 "基于格拉姆矩阵运算的残差自注意力机制
自注意力机制(Self⁃Attention)常用于建模序列数据、图像或空间数据中的内部关系。自注意力机制能够学习到输入序列内部元素之间的依赖关系,并动态地分配不同的注意力权重。自注意力机制的核心思想是通过将输入序列映射到查询(query)、键(key)和值(value)的特征表示,然后计算查询与键之间的相似度,得到注意力分数。注意力分数可以通过归一化处理转化为注意力权重,用于加权聚合值。最终,自注意力机制将加权聚合的结果与原始输入进行线性组合,得到自注意力机制的输出[7],运算流程如图3所示。
通过将特征表示矩阵(已通过注意力得分进行加权)与值相乘,得到格拉姆矩阵,其表达式为:
[Gram_matrix=value×attentionT] (4)
该过程实际上是计算一个加权特征表示,并不是传统意义上的格拉姆矩阵。加权特征表示捕获了输入特征内部的全局依赖性,提高了模型对数据结构的理解能力。
[γ]参数是一个可学习的缩放因子,通过对自注意力层的输出进行缩放,[γ]参数为模型提供了灵活性,使其能够在训练过程中学习到何时依赖原始特征,何时依赖经注意力机制加工后的特征。该机制有利于模型动态地调整自身对注意力信息的依赖程度,提升模型处理复杂数据时的准确性和泛化能力。
残差连接是深度学习中一种常见的技术,用于缓解深层网络训练过程中可能出现的梯度消失或梯度爆炸问题。残差连接将自注意力机制的输出与原始的输入特征图相加,有助于维持信息流的顺畅,同时允许模型在必要时利用原始特征,确保深层网络模型也能有效学习。[γ]参数和残差连接的数学公式为:
[out=γ×out+x] (5)
在这三个元素共同作用下,能够提升模型对数据的理解和表达能力。格拉姆矩阵提供了一种加权特征表示机制,通过这种机制模型能够捕捉和利用输入数据的内部依赖性;[γ]参数提供调节注意力机制影响程度的手段;残差连接确保深层网络中能保持信息的流动和梯度的传播。这种设计使得自注意力机制能够有效地集成到深度学习模型中,增强其性能和泛化能力。带有改进注意力机制(Gram⁃based Weighted Self⁃attention Mechanism, G⁃WSA)与层规范化(Layer Normalization, LN)的卷积模块如图4所示。
1.4 "VBA⁃net网络
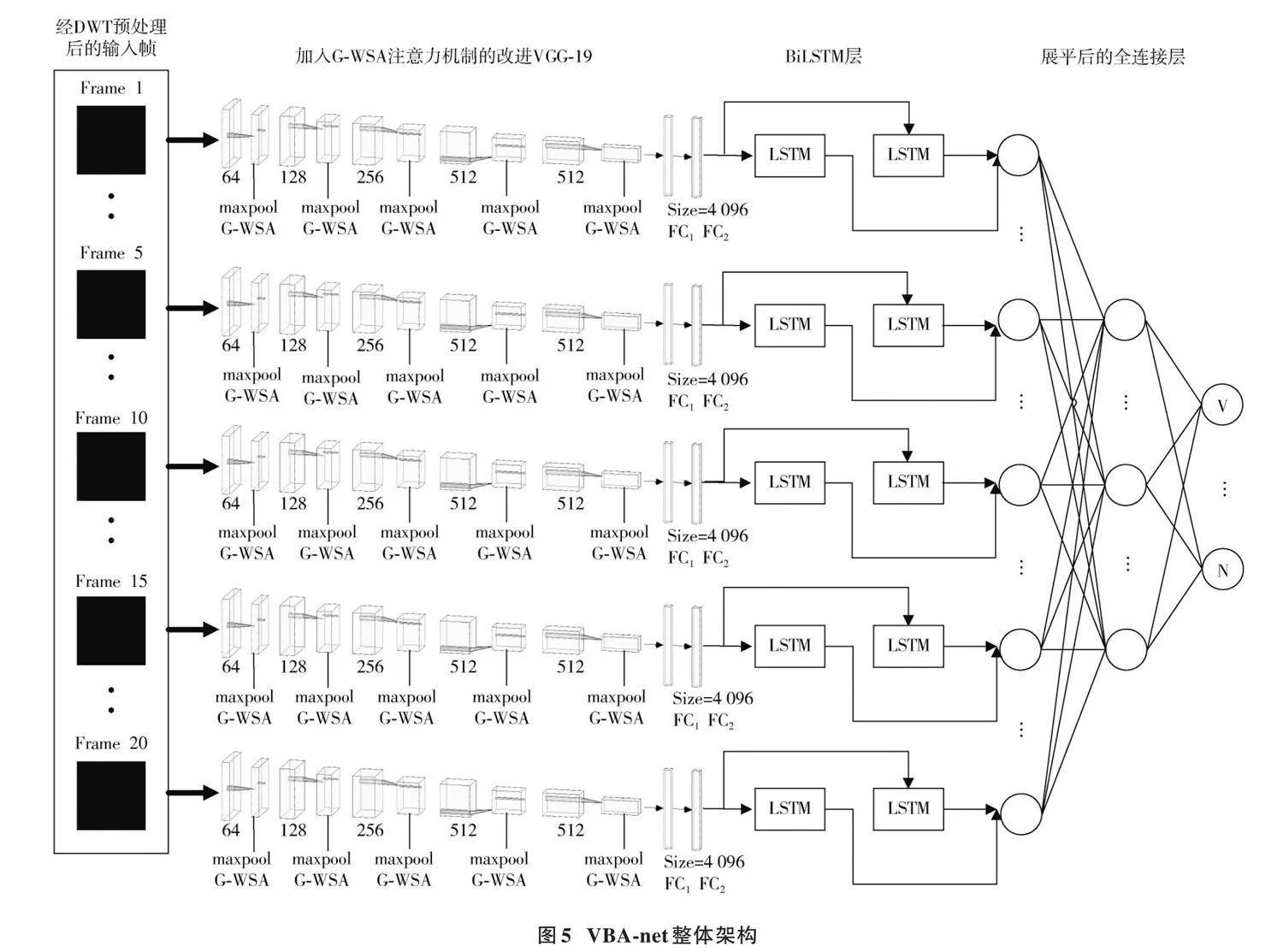
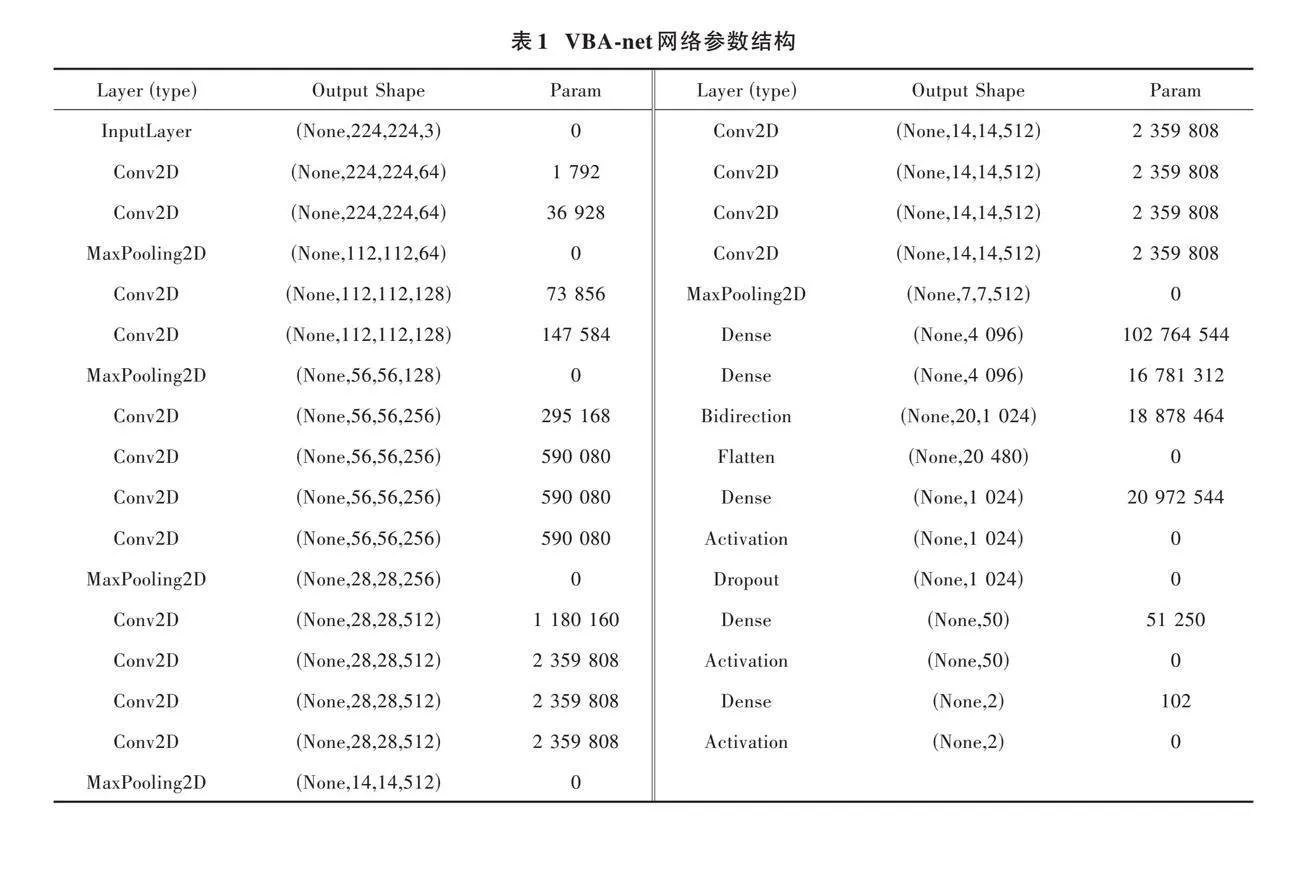
深度神经网络VGG⁃19在图像空间特征提取方面具有优势,而BiLSTM神经网络在处理时间序列数据方面具有优势。因此,本文结合基于格拉姆矩阵运算的残差自注意力机制和时空网络(VGG⁃BiLSTM),提出一种新型的暴力行为识别方法,有效分类识别人体某些部位在三维空间中的加速度、角速度和角度等时空特征。VBA⁃net模型主要由四个部分组成:离散小波变换(Discrete Wavelet Transform, DWT)预处理、卷积神经网络(CNN)、双向长短期记忆(BiLSTM)网络和改进注意力机制。该模型的整体架构如图5所示。VBA⁃net设置的网络参数结构如表1所示。
该模型首先利用DWT预处理技术对输入的视频帧进行处理,以增强其表现力并减少冗余信息,从而为深度学习模型提供更加清晰和有区分力的特征[8];然后采用VGG⁃19网络作为特征提取器,从每个预处理后的视频帧中提取潜在特征,提升模型对视频帧中重要特征的关注度。在VGG⁃19网络的每个池化层后引入改进后的注意力机制(G⁃WSA),使模型能够自动识别并聚焦分类任务中的重要部分。
从VGG⁃19网络的“[FC2]”层中提取每个视频帧的关键特征,其输出的高维特征向量包含了视频帧中的关键信息。然后,这些特征向量被送入双向长短期记忆网络(BiLSTM)中,处理时间序列数据。BiLSTM网络能够有效捕捉视频序列的时间动态信息,通过学习视频帧之间的前向和后向依赖关系,从而提供视频内容随时间变化的深层信息。
2 "实验设置
2.1 "软硬件平台配置
基于Ubuntu 22.04.4 LTS操作系统的计算机硬件进行深度学习模型训练。具体配置包括Intel[Ⓡ] CoreTM i7⁃13700H处理器、16 GB内存以及两块RTX 3090显卡。
2.2 "实验数据集介绍
深度学习技术的发展依赖于大规模数据集的支撑,缺乏足够的数据集进行模型训练,将无法进行深度学习算法的性能比较。表2为常用的4个数据集参数对比情况。
2.3 "实验相关参数
由上文可知,VBA⁃net卷积核个数分别为64、128、256、512、512,BiLSTM隐藏单元的个数为1 024。添加Flatten层将多维输入展平为一维向量,并且防止过拟合使用dropout正则化技术,每次训练迭代中概率[p]设置为0.5。另外,卷积核大小为(3,3),步长(stride)为1,填充(Padding)为“same”,且在每个池化层后添加注意力机制,设置最大池化层的窗口长度为(2,2),池化步长为(2,2)。在神经网络正向传播的过程中,采用二元交叉熵作为模型的损失函数。神经网络反向传播时,使用Adam优化方法更新神经网络的权重与偏置,学习率的初值为0.001,迭代次数为200次,设置模型训练的批次大小为64。其中二元交叉熵的计算公式为:
[Binary Cross⁃Entropy=-1Ni=1N[yilog(yi)+ " " " " " " " " " " " " " " " " " " " " " " "(1-yi)log(1-yi)]] (6)
3 "实验结果与分析
3.1 "评价标准
实验结果的评价主要采用准确率(Accuracy)和[F1]两个指标。[F1]是精确率(Precision)与召回率(Recall)的调和平均值。
为了关注所有类别中正确分类的样本比例,引入微平均指标(Micro [F1])以及加权平均指标(Weighted [F1]),具体的计算公式为:
[Micro F1=2×Micro Precision×Micro RecallMicro Precision+Micro Recall] (7)
[Weighted F1=Num SamplesiTotal Samples×F1] (8)
3.2 "VBA⁃net模型实验结果
表3为本文提出的VBA⁃net模型在四种数据集中测试的各项参数指标。RLVS数据集准确率为95.50%,Micro [F1]为95.49%,Weighted [F1]为95.50%,其识别结果表现出较高的准确率和[F1],显示出相对稳定的整体性能;RWF⁃2000数据集准确率为89.00%,Micro [F1]为88.80%,Weighted [F1]为88.90%,其识别结果表现出较高的精确率和[F1]得分,显示出准确率和召回率之间存在一种权衡,模型表现出良好的鲁棒性。虽然RWF⁃2000数据集模型可能存在一定的误分类,但能有效捕捉感兴趣的实例。
3.3 "消融实验
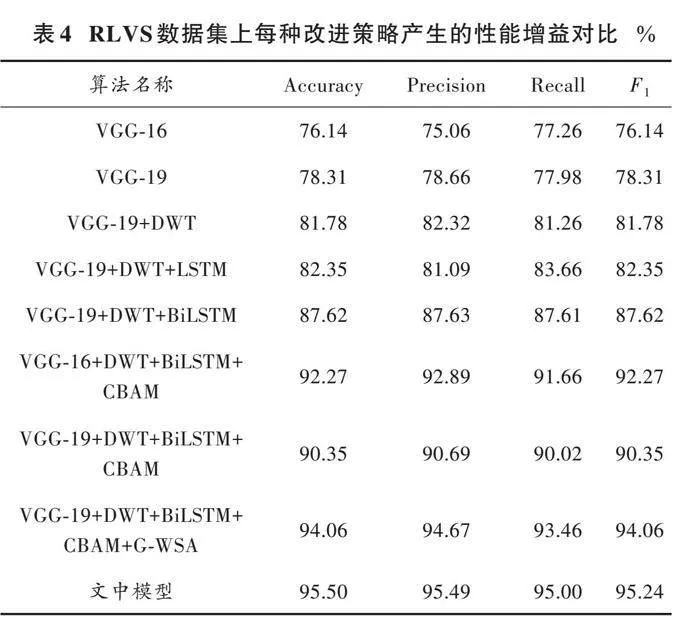
为详细研究本文算法各个模块产生的性能增益,以VGG⁃net模型为基础网络,选择添加DWT预处理、LSTM、BiLSTM、卷积块注意力模块(Convolutional Block Attention Module, CBAM)、G⁃WSA,评估算法在RLVS复杂环境数据集的性能指标,结果如表4所示。
1) 在视频预处理方面,采用常规图像增广的方式来增加数据集数量的同时,还对图像视频进行离散小波变化(DWT)预处理,选择感兴趣的小波系数进行处理,可以实现数据的压缩以及减小存储空间和传输带宽的需求。由实验数据可知,进行图像预处理是必要的,可以提高训练结果的准确率。
2) 如表4所示,模型对“[FC2]”层输出数据的处理,表现出BiLSTM的耦合性相较于LSTM更优异。BiLSTM通过充分利用序列数据中的双向上下文信息,既包括从序列起点至当前时刻的历史信息,也涵盖从序列终点回溯至当前时刻的未来信息。BiLSTM依托于两个独立运作的LSTM单元,分别对数据序列的正向和反向进行处理,并在之后将这两个方向的信息有效融合,此过程增强模型对于时间序列数据的深度理解。LSTM仅能处理当前时刻的历史信息,而无法获取及利用未来时刻的信息,从而限制其在处理具有强时序依赖特性的效能。因此,BiLSTM的设计架构对于需要深度时序分析的应用场景而言,显示出更加卓越的性能表现。
3) 基于格拉姆矩阵运算的残差自注意力机制(G⁃WSA)的添加,对整个模型的整体效能提升显著,相比CBAM注意力机制效果较好。基于格拉姆矩阵计算注意力得分,可以判断模型在做出决策时哪些输入元素起了关键作用,从而提高模型的可解释性。[γ]参数和残差连接的引入使得自注意力层可以更加有效地集成到深度网络中,有助于加速训练过程,其中[γ]参数是一个可学习的缩放因子,允许模型在训练过程中逐渐评判注意力机制的重要程度。模型在学习期间可以自适应地调整自注意力机制的影响程度,决定将多少注意力特征融合到最终的输出中。
3.4 "在复杂数据集中与其他检测方法的比较
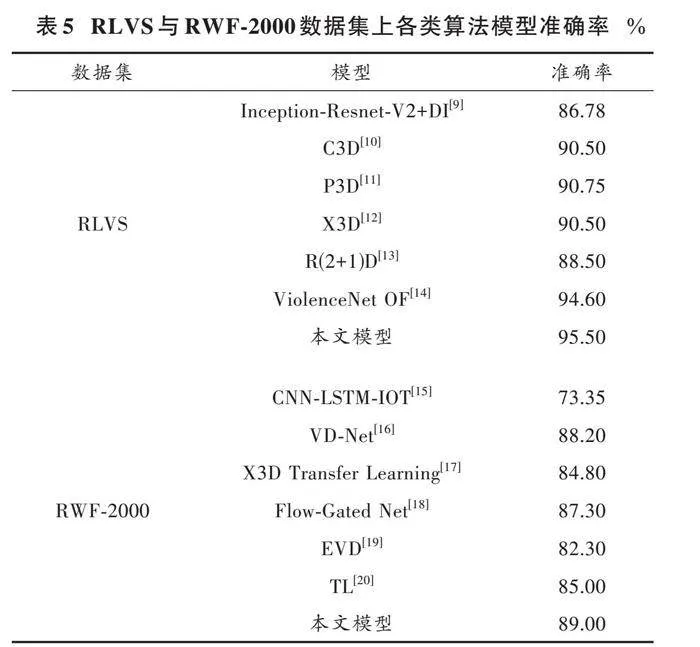
为了说明VBA⁃net模型的鲁棒性和有效性,全面评估其识别能力,分别选择了6种前沿的暴力检测模型与VBA⁃net模型在2个复杂环境数据集(RWF⁃2000、RLVS)下进行识别率对比,结果如表5所示。由表中数据可知,本文所提出的VBA⁃net模型对复杂环境下暴力行为识别综合准确率最高。
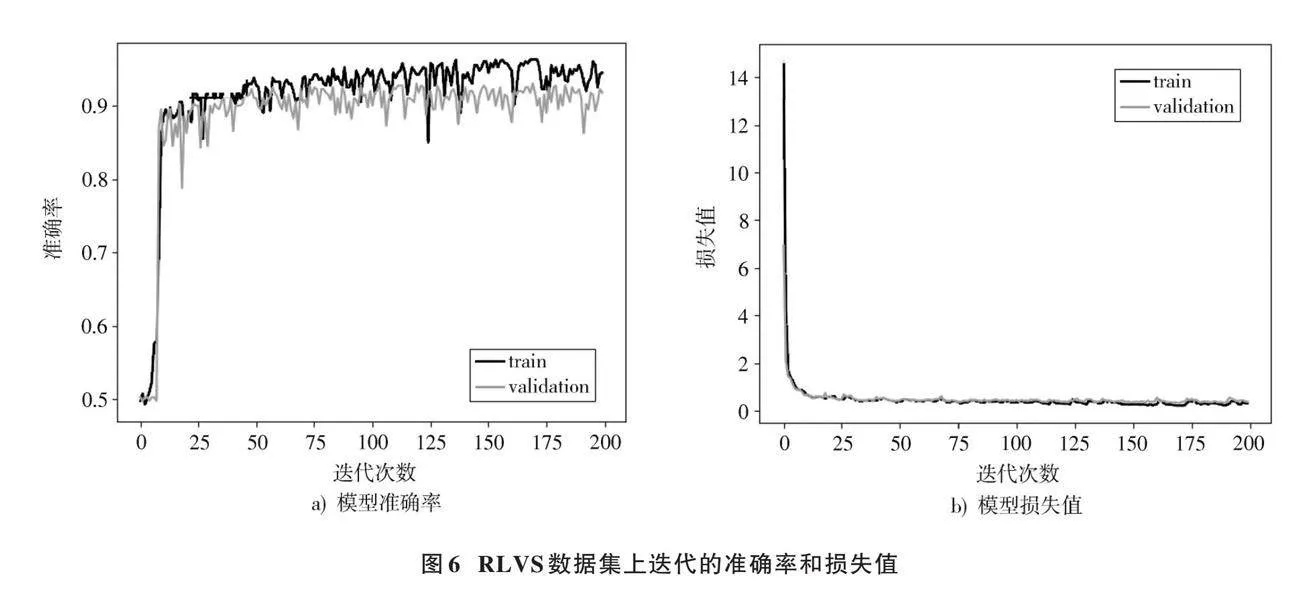
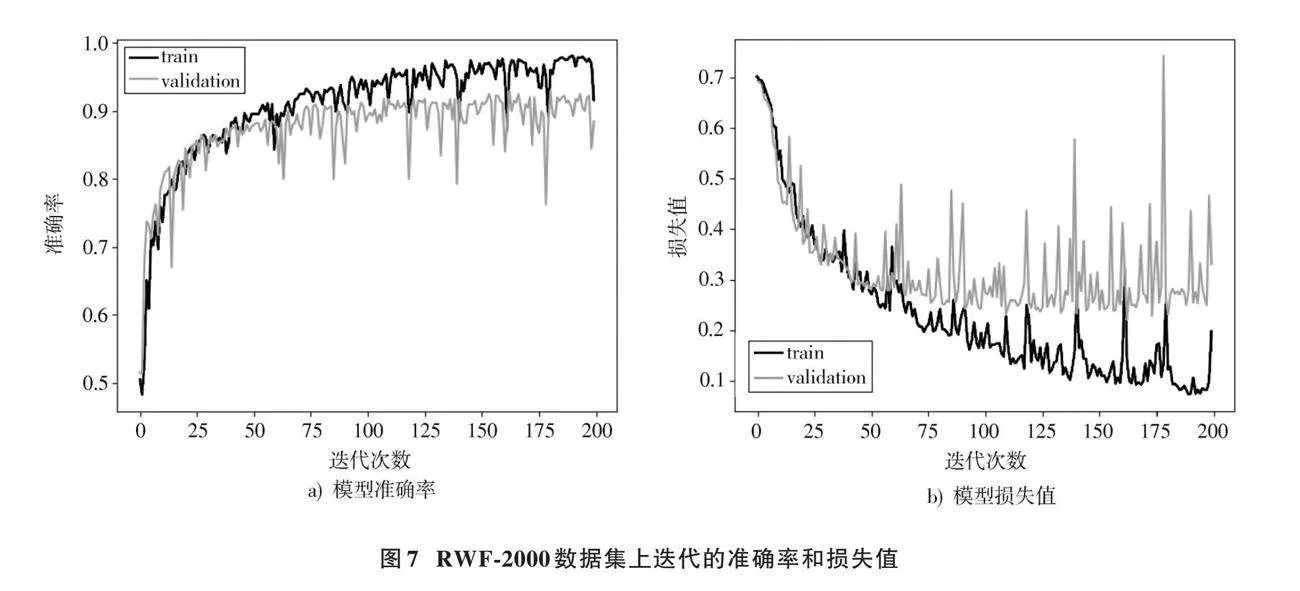
图6和图7为VBA⁃net模型在RLVS和RWF⁃2000数据集上的训练与验证过程中的准确率变化以及损失函数的迭代过程。各模型在RLVS数据集上的准确率随着训练迭代次数的增加逐渐提高,并最终趋于稳定。RWF⁃2000数据集上的准确率整体表现良好,但在后期的部分迭代过程中出现剧烈下跌,但随后迅速恢复到稳定状态,这种现象反映了模型在处理复杂数据集时部分组件的耦合性不足。本文提出的VBA⁃net网络模型在训练集上表现出较快的收敛速度,并在达到稳定后表现出较高的准确率,证明了VBA⁃net在处理动态和复杂视觉数据方面的优越性和鲁棒性。
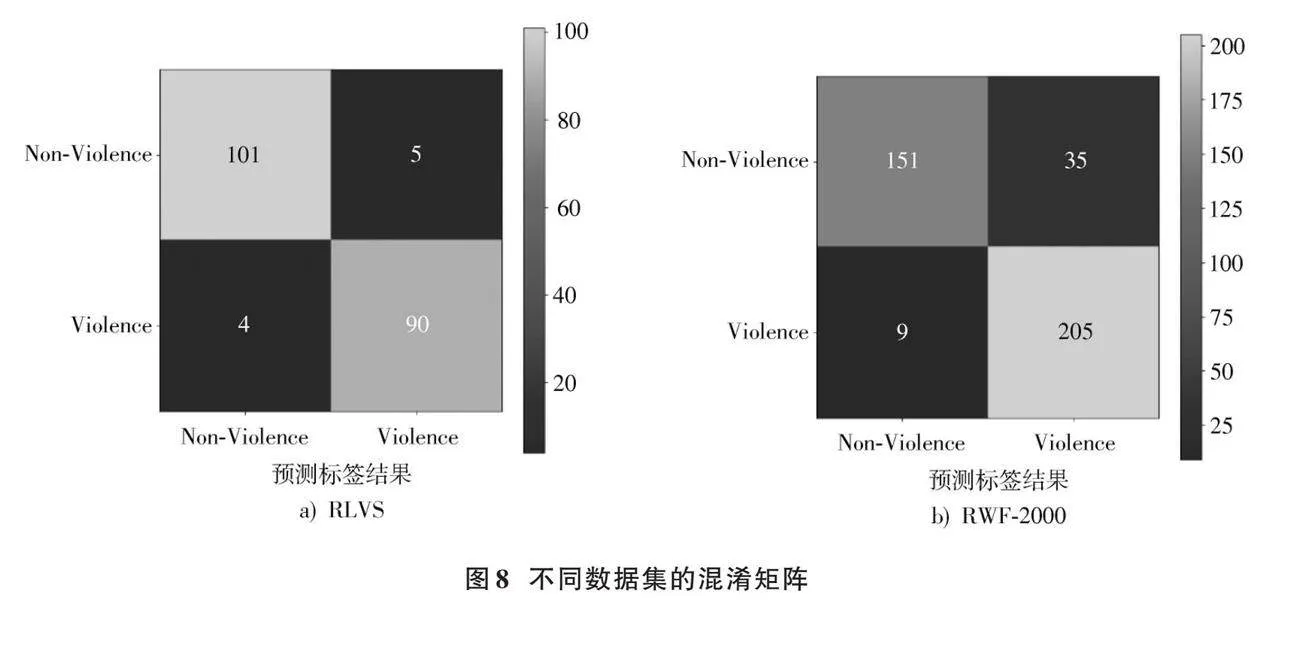
图8a)和图8b)分别为RLVS和RWF⁃2000数据集上的混淆矩阵。混淆矩阵左侧的分类代表样本的实际类别,底侧的分类代表模型的预测类别。矩阵中每个单元格的数值反映了对应类别的样本数量,主对角线上的数值表示模型正确分类的样本数量,其余单元格的数值则表示分类错误的样本数量。
在RLVS数据集中,模型将5个非暴力行为样本误分类成暴力行为,以及4个暴力行为样本误分类成非暴力行为,在非暴力行为检测上存在一定程度的误分类,但模型整体表现良好。在RWF⁃2000数据集上,模型将35个非暴力行为样本误分类成暴力行为,9个暴力行为样本误分类成非暴力行为。非暴力行为的误报数量(186个样本中的35个)表明模型可能在标记非暴力行为时过于保守;暴力行为的较低漏报率(214个样本中的9个)表现出模型在识别暴力行为方面的高准确率。
4 "结 "语
本文提出一种VBA⁃net模型,其引入了基于格拉姆矩阵运算的残差自注意力机制(G⁃WSA),从而能动态地聚焦于更具信息量的特征,同时抑制次要信息,这一特征加权机制使得该模型极大地增强了特征表示能力。VBA⁃net在HockeyFight、Movies、RWF⁃2000和RLVS等数据集上进行了广泛的训练和验证。实验结果表明,VBA⁃net对于复杂环境下的数据集,特别是RWF⁃2000和RLVS,相较于其他模型具有更高的综合识别精度,证明VBA⁃net在不同场景下暴力行为识别的有效性。尽管VBA⁃net在复杂环境中表现突出,但对于简易环境数据集的识别精度略显不足。因此,未来的研究将着重探索能在各类数据集上表现均优异的模型算法,研究出更具有鲁棒性和泛用性的暴力行为检测模型。
注:本文通讯作者为代雪晶。
参考文献
[1] 陈杰,李展,颜普,等.基于3D SE⁃Densenet网络的视频暴力行为识别改进算法[J].安徽建筑大学学报,2023,31(1):56⁃63.
[2] 蔡兴泉,封丁惟,王通,等.基于时间注意力机制和EfficientNet的视频暴力行为检测[J].计算机应用,2022,42(11):3564⁃3572.
[3] 靳伟昭.基于深度学习的暴力行为检测方法研究[D].西安:西安电子科技大学,2021.
[4] SUDHAKARAN S, LANZ O. Learning to detect violent videos using convolutional long short⁃term memory [C]// Proceedings of the 14th IEEE International Conference on Advanced Video and Signal Based Surveillance. New York: IEEE, 2017: 1⁃6.
[5] 朱铭康,卢先领.基于Bi⁃LSTM⁃Attention模型的人体行为识别算法[J].激光与光电子学进展,2019,56(15):153⁃161.
[6] CHATTERJEE R, HALDER R. Discrete wavelet transform for CNN⁃BiLSTM⁃based violence detection [C]// International Conference on Emerging Trends and Advances in Electrical Engineering and Renewable Energy. Heidelberg: Springer, 2020: 41⁃52.
[7] YANG B S, WANG L Y, WONG D F, et al. Convolutional self⁃attention networks [EB/OL]. [2019⁃04⁃24]. http://arxiv.org/abs/1904.03107.
[8] 张帅涛,蒋品群,宋树祥,等.基于注意力机制和CNN⁃LSTM融合模型的锂电池SOC预测[J].电源学报,2024,22(5):269⁃277.
[9] JAIN A, VISHWAKARMA D K. Deep NeuralNet for violence detection using motion features from dynamic images [C]// 2020 3rd International Conference on Smart Systems and Inventive Technology (ICSSIT). New York: IEEE, 2020: 826⁃831.
[10] TRAN D, BOURDEV L, FERGUS R, et al. Learning spatiotemporal features with 3D convolutional networks [C]// Proceedings of the IEEE International Conference on Computer Vision. New York: IEEE, 2015: 4489⁃4497.
[11] QIU Z F, YAO T, MEI T. Learning spatio⁃temporal representation with pseudo⁃3D residual networks [C]// Proceedings of the IEEE International Conference on Computer Vision. New York: IEEE, 2017: 5534⁃5542.
[12] SANTOS F A O, DURAES D, MARCONDES F S, et al. Efficient violence detection using transfer learning [C]// Procee⁃dings of the Practical Applications of Agents and Multi⁃agent Systems. Heidelberg: Springer, 2021: 65⁃75.
[13] TRAN D, WANG H, TORRESANI L, et al. A closer look at spatiotemporal convolutions for action recognition [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2018: 6450⁃6459.
[14] RENDON⁃SEGADOR F J, ALVAREZ⁃GARCIA J A, ENRIQUEZ F, et al. ViolenceNet: Dense multi⁃head self⁃attention with bidirectional convolutional LSTM for detecting violence [J]. Electronics, 2021, 10: 1601.
[15] ALDAHOUL N, KARIM H A, DATTA R, et al. Convolutional neural network⁃long short term memory based IoT node for violence detection [C]// 2021 IEEE International Conference on Artificial Intelligence in Engineering and Technology (IICAIET). New York: IEEE, 2021: 1⁃6.
[16] ULLAH F U M, MUHAMMAD K, HAQ I U, et al. AI⁃assisted edge vision for violence detection in IoT⁃based industrial surveillance networks [J]. IEEE transactions on industrial informatics, 2022, 18(8): 5359⁃5370.
[17] SU Y K, LIN G S, ZHU J H, et al. Human interaction learning on 3D skeleton point clouds for video violence recognition [C]// Proceedings of 16th European Conference on Computer Vision. Heidelberg: Springer, 2020: 74⁃90.
[18] CHENG M, CAI K J, LI M. RWF⁃2000: An open large scale video database for violence detection [C]// 2020 25th International Conference on Pattern Recognition (ICPR). New York: IEEE, 2020: 4183⁃4190.
[19] VIJEIKIS R, RAUDONIS V, DERVINIS G. Efficient violence detection in surveillance [J]. Sensors, 2022, 22(6): 2216.
[20] HUSZÁR V D, ADHIKARLA V K, NEGYESI I, et al. Toward fast and accurate violence detection for automated video surveillance applications [J]. IEEE access, 2023, 11: 18772⁃18793.
[21] 朱光辉,缪君,胡宏利,等.基于自增强注意力机制的室内单图像分段平面三维重建[J].图学学报,2024,45(3):464⁃471.
作者简介:李金成(2001—),男,湖北宜昌人,硕士研究生,研究方向为步态识别技术。
闫睿骜(2000—),男,内蒙古赤峰人,硕士研究生,研究方向为步态识别技术。
代雪晶(1970—),女,辽宁凤城人,博士研究生,教授,硕士生导师,研究方向为声像资料技术。
猜你喜欢
数字技术与应用(2019年2期)2019-05-14 08:25:10
电子制作(2018年19期)2018-11-14 02:37:08
现代电子技术(2018年8期)2018-04-13 06:36:32
软件工程(2017年11期)2018-01-05 08:06:09
智能计算机与应用(2017年5期)2017-11-08 12:11:51
自动化学报(2017年11期)2017-04-04 02:52:58
噪声与振动控制(2015年4期)2015-01-01 07:08:21
轴承(2010年2期)2010-07-28 02:26:12
