
基于深度学习的森林移动机器人树干检测
2024-10-19 00:00胡峻峰朱昊黄晓文李柏聪赵亚凤
森林工程 2024年4期






摘 要:基于视觉导航的森林移动机器人具有机器人作为边缘设备算力有限、导航效果受光照影响较大的问题。为此,提出一种轻量化的树干检测方法,该方法基于YOLOv7-tiny模型,采用可见光图像与热成像图像作为输入,导航效果受光照影响较小;同时采用基于部分通道卷积(Partial Convolution,PConv)的特征提取模块-部分通道卷积高效层聚合网络(Partial Efficient Layer Aggregation Networks,P-ELAN),对基准模型进行轻量化改进;在训练阶段用alpha-CIoU损失函数替换原始的CIoU损失函数,提高边界框回归的准确性。结果表明,所提出的森林移动机器人树干检测方法相较于原始YOLOv7-tiny模型参数量减少31.7%,计算量减少33.3%,在图形处理器(Graphics Processing Unit,GPU)和中央处理器(Central Processing Unit,CPU)上的推理速度分别提升了33.3%和7.8%。修改后的模型在保持对树干检测精度基本不变的基础上更加轻量化,成为部署在机器人等边缘设备上的理想选择。
关键词:树干检测; 森林移动机器人; 目标检测; 热成像; 轻量化
中图分类号:S762;TP391.4 文献标识码:A DOI:10.7525/j.issn.1006-8023.2024.04.012
Trunk Detection for Forest Mobile Robots Based on Deep Learning
HU Junfeng, ZHU Hao, HUANG Xiaowen, LI Baicong, ZHAO Yafeng*
(College of Computer and Control Engineering, Northeast Forestry University, Harbin 150040, China)
Abstract: Forest mobile robots based on visual navigation face the problem of limited computational power as edge devices and the navigation performance is greatly affected by illumination. To address this, a lightweight trunk detection method is proposed. This method uses visible and thermal image as inputs, minimizing the impact of illumination on navigation performance it also employs a feature extraction module based on Partial Convolution (PConv) and a Partial Efficient Layer Aggregation Network (P-ELAN) to achieve lightweight improvements to the baseline model. During training, the alpha-CioU loss function is used to replace the original CIoU loss function, increasing the accuracy of bounding box regression. The results show that the proposed tree trunk detection method for forest mobile robots reduces the parameter count of the original YOLOv7-tiny model by 31.7%, decreases computation by 33.3%, and improves inference speeds on Graphics Processing Units (GPU) and Central Processing Units (CPU) by 33.3% and 7.8%. The modified model maintains comparable accuracy while being more lightweight, making it an ideal choice for deployment on edge devices such as robots.
Keywords: Trunk detection; forest mobile robots; object detection; thermal image; lightweight
0 引言
森林移动机器人在森林管理和保护中发挥着重要作用,广泛应用于森林资源监测、野生动物追踪、森林火灾预防和监测和环境数据收集等任务。然而,要想完成这些任务,有效且可靠的导航必不可少。因此,研究森林移动机器人的视觉导航问题具有重要意义。
孙上杰等[1]提出一种森林消防机器人路径规划方法,通过建立二维网格地图,对复杂的环境进行模拟,之后分别对强化学习和深度强化学习算法进行仿真研究。杨松等[2]将蚁群算法引入森林防火移动机器人的路径规划中,实现更强的全局搜索能力和较好的应用价值。但这2种方法都基于全局环境信息已知这一前提条件,因此存在局限性。
森林环境本质上是复杂且不可预测的[3]。如何进行实时的环境判别成为一个重要的主题。一种做法是采用激光雷达(Light Detection and Ranging,LiDAR)系统对周围环境进行实时扫描,并根据激光的往返时间进行精确距离测量。Malavazi等[4]通过点云处理激光雷达数据进行农作物和杂草检测,取得了不错的成果。然而,激光雷达提供的信息有限,因为其仅捕获距离和角度数据,不能从中对感知到的物体进行分类。另一种做法是使用相机作为导航系统的输入设备。相机具备成本低且易于安装的优势,同时能提供丰富的信息。基于此,相机在导航系统中得到了广泛的应用。Takagaki等[5]使用相机提供的颜色信息,以及阴影和土壤纹理,成功区分可通行区域(犁沟)和不可通行区域(山脊)。森林移动机器人全天候的工作内容对应着不同的光照条件,这对开发高效的机器人视觉系统提出重大挑战[6]。而普通RGB相机对光照敏感,弱光照下其拍照精度可能降低[7]并导致目标识别受损。与普通RGB相机不同,热成像仪具有不受光照条件阻碍的检测能力。Beyaz等[8]使用热成像仪检测树干的内部损坏,从而评估树干的健康情况。因此将热成像仪应用于森林移动机器人的导航是可行的。此外,人工智能和深度学习也被用于林业移动机器人的视觉导航。Itakura等[9]将YOLOv2和ResNet-50用于使用城市街道图像自动检测树木。Xie等[10]提出利用Faster R-CNN进行树木检测的注意力网络。
为实现复杂光照环境下森林移动机器人的视觉导航,本研究在强光照环境下使用可见光图像,在弱光照或无光照条件下使用热成像图像来进行树干检测,使森林移动机器人在各类光照条件下都能执行自动化任务。由于森林移动机器人作为边缘设备算力有限,提出一种改进的YOLOv7-tiny模型,引入部分通道卷积并构建轻量化的特征提取模块P-ELAN,减少模型的参数和计算要求,使模型轻量化且硬件友好;同时引入alpha-CIoU损失函数,提升边界框预测的鲁棒性,同时提高模型检测的准确性。
1 数据与方法
1.1 数据采集
本研究使用的数据最初来源于开源数据集ForTrunkDet,之后通过新采集的部分数据对该数据集进行补充。
1.1.1 开源数据集ForTrunkDet
Da silva等[11]提供一个包含2 895个可见光图像和热成像图像的数据集。该数据集收集葡萄牙 3个不同森林地区的图像:瓦隆古(41°11′22.09″ N,8°29′55.54″ W)、孔迪(41°21′14.22″ N,8°44′30.66″ W)和洛邦(40°59′05.10″ N,8°29′17.41″ W)。这3个林区主要由2种树种组成,分别为桉树和松树。使用4台摄像机进行图像采集,GoPro Hero6、FLIR M232、ZED Stereo 和 Allied Mako G-125。数据集结构的详细信息见表1。
1.1.2 自采数据
本研究使用iPhone14相机和海康威视LH15热成像模组,采集东北林业大学城市林业示范基地(45°43'25.50″ N, 126°37'51.05″ E)的图像并进行人工标注,对上述开源数据集进行补充。补充数据集包括200张可见光图像与100张热成像图像。
1.2 数据集预处理
根据对森林树干检测这一任务的适用性进行筛选,消除存在缺陷的图像,例如过度模糊的图像或过度曝光的图像。然后使用标注工具LabelImg进行人工标注。
预选产生的原始数据集由3 195张图像组成,其中包含2 229张可见光图像,966张热成像图像,按9∶1的比例划分为训练集和验证集。由于深度学习模型需要大量数据才能达到更高的准确性,本研究通过模糊图像、水平翻转、更改色调和饱和度、更改图像的对比度、向图像添加高斯噪声、将图像旋转-10°、将图像旋转+10°、缩放图像的方法对原始训练集进行增强。
1.3 树干检测方法
1.3.1 改进的YOLOv7-tiny模型
作为目标检测领域经典的网络框架之一,YOLO算法已经过多次迭代,实现精度和速度之间的最佳平衡。考虑到森林移动机器人作为边缘设备并不适合搭载高算力硬件,本研究选择在YOLOv7算法[12]的轻量化分支YOLOv7-tiny的基础上加以改进。改进后的YOLOv7-tiny算法由骨干网络、颈部和检测头3大部分组成。
骨干网络主要负责特征提取。本研究构建算力友好的特征提取模块(Partial Efficient Layer Aggregation Networks,P-ELAN),降低了特征提取时所需要的参数量和计算量。之后,提取到的特征在颈部通过空间金字塔池化模块(Spatial Pyramid Pooling,SPP)和改进的金字塔注意力网络(Pyramid Attention Network,PAN)进行融合。SPP模块取代卷积层之后的常规池化层,可以增大感受野并获得多尺度特征,且训练速度较为理想。PAN结构有效地整合不同层次的特征图,生成新的特征表示并增强检测性能。检测头负责预测图像特征、构建边界框、输出用于检测的特征图,完成检测过程的最后阶段。
此外,在训练过程中,本研究放弃原始模型中所用的CIoU损失函数,改用alpha-CIoU损失函数来提高边界框回归的准确性。
1.3.2 改进的特征提取模块P-ELAN
ELAN模块是一种高效的网络结构,由多个卷积层组成,并控制梯度路径以增强特征学习能力并增强鲁棒性。其中每个卷积层都包括1次卷积、1次批量归一化与1次激活。ELAN由2个分支组成:第1个分支通过一个1×1卷积改变通道数;第2个分支依次通过1个1×1卷积和2个3×3卷积。每通过1个卷积便产生1个输出,最终使用1个1×1卷积调整这些分支的4个输出。
Chen等[13]提出部分通道卷积。该方法通过仅在选择的输入通道上执行卷积运算并直接传输剩余通道特征来减少特征图中的计算冗余。为使模型更加轻量化从而便于部署,本研究基于最初的ELAN块,使用部分通道卷积替换了2个标准3×3卷积,通过仅在部分输入通道上执行卷积运算并保留其余通道的特征来减少特征图中的计算冗余。改进的特征提取模块P-ELAN结构如图1所示。
1.3.3 改进的损失函数alpha-CIoU
在训练过程中,引入了alpha-CIoU替换了原本的CIoU,其推导过程如下。
交并比(Intersection over Union,IoU,式中记为IoU)用于评估预测边界框和真实边界框之间的匹配程度。IoU仅考虑二者的位置重叠,而不考虑其位置和尺度偏差。因此,Zheng等[14]提出一种更精确的评估指标,称为完备交并比(Complete Intersection over Union,CIoU,式中记为LCIoU)。其表达式为
L_CIoU=S+D+V。 (1)
式中:S为重叠区域;D为距离;V为长宽比。
S为原始IoU损失函数,公式为
(S=1-I_oU )。 (2)
D通过计算预测框和真实框中心点之间的欧氏距离来测量边界框之间的位置偏差,公式为
(D=(ρ^2 (p_p,p_t ))/c^2 )。 (3)
式中:ρ(pp,pt)为预测框中心点pp和真实框中心点pt之间的欧氏距离;c为目标框与预测框最小包裹框的对角线长度。
V测量边界框之间的纵横比偏差,是通过比较预测框和真实框的纵横比获得的,公式为
(V=4/π^2 ⋅(arctan(h_t/w_t )-arctan(h_r/w_r ) )^2 )。 (4)
式中:wt、ht、wr和hr分别为目标框与预测框的宽与高。
最后,CIoU损失函数(LCIoU)可以表示为
(L_CIoU=1-I_oU+(ρ^2 (p_p,p_t ))/c^2 +β⋅V)。 (5)
式中,β取决于IoU。
He等[15]提出alpha-CIoU。计算公式(6)为
(L_(α-CIoU)=1-I_oU^α+(ρ^2α (p_p,p_t ))/c^2α +(β⋅V)^α )。 (6)
式中:α为超参数,alpha-CIoU通过添加α超参数,对原始的CIoU进行了推广。当α=1时,alpha-CIoU被还原为CIoU;当α>1时,相较于原始CIoU损失函数,alpha-CIoU加重了高IoU值对象的损失和梯度,从而提高了边界框回归的准确性;当0<α<1时,效果则相反,边界框回归的准确性降低了。过往试验证明,α对于不同的模型或数据集并不太敏感,因此,本研究中α超参数取经验值为3。
1.3.4 评价指标
在本研究中,使用参数量和浮点运算数(Floating Point Operations,FLOPs)来评估模型大小;使用平均精度均值(Mean Average Precision,mAP,式中记为mAP)在不同IoU阈值(0.5~0.95,步长0.05)下的平均数即mAP@.5:.95来评估模型检测精度;使用单张图片推理时间来评估检测速度。mAP被认为是评估目标检测模型整体精度的重要指标,是其性能的可靠指标,计算公式为
m_AP=1/M ∑_(k=1)^M▒〖A_P (k)〗×100%。 (7)
式中:AP为平均精度;M为类别总数。
2 结果与分析
2.1 试验环境搭建
试验选用Intel® Core™ i7-13700K 3.4 GHz CPU,内存128 G,显卡为GeForce RTX 4090 24 G。使用Ubuntu 22.04系统搭建基于Python 3.10和Pytorch 2.0.0的深度学习框架。在训练过程中设置输入分辨率为512×512,学习率为0.01,批量大小为128,训练迭代次数设置为100。
2.2 树干检测试验结果与分析
使用处理以后的数据集对改进的YOLOv7-tiny模型进行训练和验证,为验证各模块对网络性能的影响,进行消融试验,并与经典网络进行对比。每轮训练后都进行一次评价指标和损失值的计算,经过100轮训练后,得到以下试验结果。
2.2.1 消融试验
为验证引入的alpha-CIoU损失和改进后的P-ELAN模块对改进YOLOv7-tiny模型的影响,在本研究数据集中进行消融试验来分析每个成分的贡献。为保证试验结果的可靠性,对每个模型重复试验3次,并选取3次试验结果的平均值作为最终结果,试验结果见表2,其中“√”代表该模块被乘用。
在本研究中,alpha-CIoU首先单独替换到原本使用CIoU的基线模型中,成功使mAP@.5:.95增加1.4%。随后,单独添加P-ELAN模块导致mAP@.5:.95降低3.5%,同时模型参数量减少31.7%,计算量减少33.3%。当两者结合起来时,模型的参数和计算成本减少了三分之一,而mAP@.5:.95仅减少1.9%。消融试验结果表明,P-ELAN模块虽然可能导致检测精度下降,但大大降低模型的计算复杂度,提高检测速度。同时,alpha-CIoU损失函数强化模型的训练过程,在不增加任何负担的情况下获得更好的精度。
由表2可知,虽然改进后的YOLOv7-tiny模型在CPU和GPU上都比原始YOLOv7-tiny模型实现了更快的推理速度,但并不能确定本试验所提算法是否能够在低功耗边缘设备上保持或在多大程度上保持其推理速度优势。这是未来研究中可以进一步探讨的一点。
2.2.2 对比试验
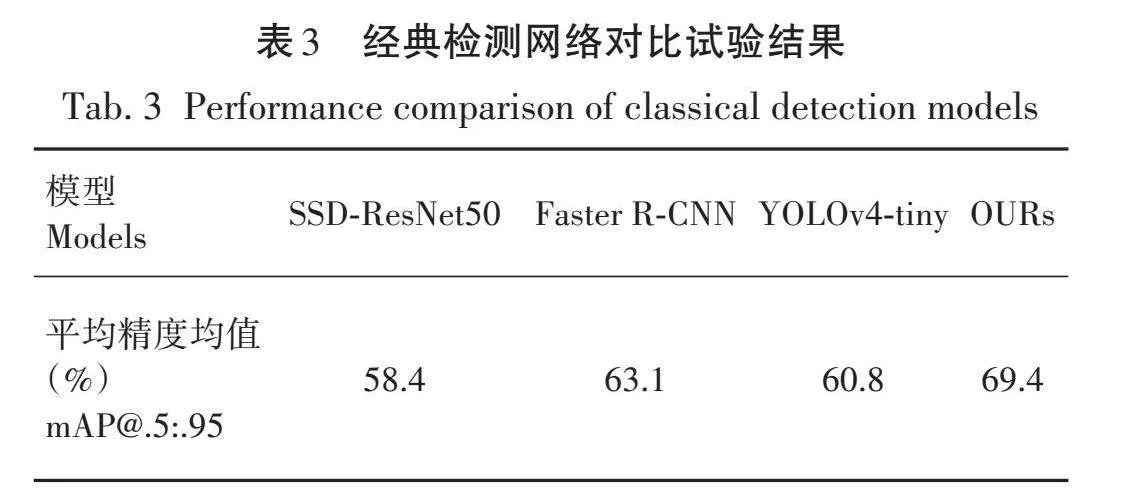
为进一步验证改进YOLOv7-tiny算法在树干检测中的效果,在本研究数据集上将改进YOLOv7-tiny与YOLOv4 tiny、SSD-ResNet50[16]、Faster R-CNN[17]进行对比,试验结果见表3。
本研究提出的方法相对于其他经典的目标检测算法,检测精度提高6.3%~11.0%。试验结果表明,本研究方法在树干检测中表现出色,检测精度很高。
2.2.3 可视化
图2为一组验证集图像,显示本研究模型在识别树干方面的识别效果。其中,图2(a)和图2(b)是可见光图像,图2(c)和图2(d)是热成像图像。尽管图2(d)图背景中的塔与树干相似,但本研究模型仍然成功地区分树干和塔。但与此同时,图2(b)中的一些小树干没有被识别出来,这表明本研究模型在对小目标的识别方面仍有提升空间。
3 结论
森林移动机器人的视觉导航是林业自动化过程的重要要求。因此,提出一种改进森林移动机器人直立树干检测方法。该方法引入部分卷积技术来创建独特的P-ELAN块,并通过alpha-CIoU损失函数增强YOLOv7-tiny。试验结果表明,改进后的模型比未修改的YOLOv7-tiny更轻量化,参数量和计算量从6.0×106和13.2×109减少到4.1×106和8.8×109。因此,修改后的模型更适合机器人等边缘设备,为开发森林移动机器人视觉导航系统提供了强有力的支持。对比试验结果也表明,该方法优于其他检测器。
未来的工作将包括通过添加深度图像来增加数据集,这些图像对于影响探测器性能的森林中频繁的光线变化具有鲁棒性,并且除了树干图像之外还包括更多的森林物体图像。此外,也会将这些模型集成到现有的森林机器人中,以执行依赖于模型检测的自主导航和其他任务。
【参 考 文 献】
[1] 孙上杰,姜树海,崔嵩鹤,等.基于深度学习的森林消防机器人路径规划[J].森林工程,2020,36(4):51-57.
SUN S J,JIANG S H,CUI S H,et al.Path planning of forest fire fighting robots based on deep learning[J].Forest Engineering,2020,36(4):51-57.
[2] 杨松,洪涛,朱良宽.改进蚁群算法的森林防火移动机器人路径规划[J].森林工程,2024,40(1):152-159.
YANG S,HONG T,ZHU L K.Forest fire prevention mobile robot path planning based on improved ant colony algorithm[J].Forest Engineering,2024,40(1):152-159.
[3] BERGERMAN M,BILLINGSLEY J,REID J,et al.Robotics in agriculture and forestry[J].Springer Handbook of Robotics,2016:1463-1492.
[4] MALAVAZI F B P,GUYONNEAU R,FASQUEL J B,et al.LiDAR-only based navigation algorithm for an autonomous agricultural robot[J].Computers and Electronics in Agriculture,2018,154:71–79.
[5] TAKAGAKI A,MASUDA R,IIDA M,et al.Image processing for ridge/furrow discrimination for autonomous agricultural vehicles navigation[J].IFAC Proceedings Volumes,2013,46(18):47-51.
[6] ZHANG Y,CHEN H,HE Y,et al.Road segmentation for all-day outdoor robot navigation[J].Neurocomputing,2018,314:316-325.
[7] GUO Z,LI X,XU Q,et al.Robust semantic segmentation based on RGB-thermal in variable lighting scenes[J].Measurement,2021,186:110176.
[8] BEYAZ A,ÖZKAYA M T.Canopy analysis and thermographic abnormalities determination possibilities of olive trees by using data mining algorithms[J].Notulae Botanicae Horti Agrobotanici Cluj-Napoca,2021,49(1):12139-12139.
[9] ITAKURA K,HOSOI F.Automatic tree detection from three-dimensional images reconstructed from 360° spherical camera using YOLO v2[J].Remote Sensing,2020,12(6):988.
[10] XIE Q,LI D,YU Z,et al.Detecting trees in street images via deep learning with attention module[J].IEEE Transactions on Instrumentation and Measurement,2019,69(8):5395-5406.
[11] DASILVA D Q,DOSSANTOS F N,SOUSA A J,et al.Visible and thermal image-based trunk detection with deep learning for forestry mobile robotics[J].Journal of Imaging,2021,7(9):176.
[12] WANG C Y,BOCHKOVSKIY A,LIAO H Y M.YOLOv7:Trainable Bag-of-freebies Sets New State-of-the-art for Real-time Object Detectors[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.2023:7464-7475.
[13] CHEN J,KAO S,HE H,et al.Run,Don′t Walk:Chasing Higher FLOPS for Faster Neural Networks[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.2023:12021-12031.
[14] ZHENG Z,WANG P,REN D,et al.Enhancing geometric factors in model learning and inference for object detection and instance segmentation[J].IEEE Transactions on Cybernetics,2021,52(8):8574-8586.
[15] HE J,ERFANI S,MA X,et al.Alpha-IoU:A family of power intersection over union losses for bounding box regression[J].Advances in Neural Information Processing Systems,2021,34:20230-20242.
[16] LIU W,ANGUELOV D,ERHAN D,et al.Ssd:Single Shot Multibox Detector[C]//Computer Vision-ECCV 2016:14th European Conference,Amsterdam,The Netherlands,October 11-14,2016,Proceedings,Part I 14.Springer International Publishing,2016:21-37.
[17] REN S,HE K,GIRSHICK R,et al.Faster r-cnn:Towards real-time object detection with region proposal networks[J].Advances in neural information processing systems,2015,39(6):1137-1149.
