
深度融合内容和隐式反馈的跨域推荐算法
2024-10-18 00:00:00陆永倩於跃成生佳根李慧许梦瑶
江苏科技大学学报(自然科学版) 2024年1期








摘" 要: 针对现有的大多数跨域推荐方法仅仅使用了源域的评分信息和部分辅助信息,并未充分使用包括隐式反馈信息在内的其它辅助信息,文中提出了一种融合多种辅助信息的跨域推荐算法,以充分使用隐式反馈信息和内容信息来提升跨域推荐方法的性能.在对堆叠降噪自动编码器(stacked denoising autoencoder,SDAE)进行扩展的基础上,结合矩阵分解(matrix factorization,MF)方法,同时融合了源域的评分信息、用户和项目的内容信息以及隐式反馈信息,丰富了用户和项目潜在特征的语义信息.采用基于密码本的知识迁移方法和非完备正交非负矩阵三分解方法,设计了适用于评分信息和多类型辅助信息综合运用的跨域协同过滤框架.实际数据集上的实验结果表明,该方法在改善推荐性能,减少用户厌恶推荐结果方面有着良好的效果.
关键词: 辅助信息;隐式反馈;矩阵分解;跨域推荐
中图分类号:TP391""" 文献标志码:A""""" 文章编号:1673-4807(2024)01-075-07
DOI:10.20061/j.issn.1673-4807.2024.01.012
收稿日期: 2021-08-18""" 修回日期: 2021-04-29
基金项目: 国家自然科学基金项目(61806087);江苏省研究生创新项目(SJCX20_1475)
作者简介: 陆永倩(1995—),女,硕士研究生
*通信作者: 於跃成(1971—),男,教授,研究方向为数据挖掘、推荐系统.E-mail:zhjyuyuecheng@163.com
引文格式: 陆永倩,於跃成,生佳根,等.深度融合内容和隐式反馈的跨域推荐算法[J].江苏科技大学学报(自然科学版),2024,38(1):75-81.DOI:10.20061/j.issn.1673-4807.2024.01.012.
Cross-domain recommendation algorithm based ondeep fusion of content and implicit feedback
LU Yongqian, YU Yuecheng*, SHENG Jiagen, LI Hui, XU Mengyao
(School of Computer, Jiangsu University of Science and Technology, Zhenjiang 212100, China)
Abstract:Most of the existing cross-domain recommendation methods use only the rating information and some side information from the source domain, and the other side information including implicit feedback information can not be adopted. Therefore, a cross-domain recommendation algorithm which integrate multiple side information including implicit feedback information and content information is proposed to improve the performance of cross-domain recommendation methods. Based on the expansion of stacked denoising autoencoder (SDAE), combing with matrix factorization (MF) method and fusing the rating information of the source domain, the content information of users and projects and implicit feedback information are also integrated in the method. On this basis, the cross-domain collaborative filtering framework suitable for the comprehensive application of rating information and multi type side information is designed. In order to effectively transfer the source domain information, both the codebook-based knowledge transfer method and the incomplete orthogonal nonnegative matrix tri-factorization method are adopted in this framework. The experimental results on the actual data set show that this method has a good effect in improving the recommendation performance and reducing users′ aversion to the recommendation results.
Key words:side information, implicit feedback, matrix factorization, cross-domain recommendation
在当今信息爆炸增长的时代,推荐系统受到了越来越多的关注.经典的推荐算法大致可以分为两类[1]:基于内容的方法和基于协同过滤(collaborative filtering,CF)的方法.基于内容的方法利用用户的个人资料和项目的内容信息进行推荐,而CF方法则忽略了内容信息,转而利用用户过去的行为活动或偏好进行推荐.然而,推荐系统通常面临两个主要问题:冷启动和数据稀疏性.
为了解决这些问题,将协同过滤与辅助信息相集成,以获取更多的有效特征.除了评分信息可以直观显示用户的喜好外,大多数如用户和项目的内容信息、标签、评论等辅助信息中往往隐含着用户的个性偏好.此外,隐式反馈信息[2](如购买历史,浏览信息等)也反映了用户对项目的偏好.传统的协同过滤推荐中评分信息和各种辅助信息由于过于稀疏而无法有效利用.深度学习能够从原始数据中学习有效的特征表示,和传统推荐算法相结合,更是能从稀疏的历史信息中挖掘用户的偏好特征,应用十分广泛.
跨域推荐[3]则是利用辅助信息来改善推荐性能,通过将知识从信息较为稠密的相关领域(称为源域)迁移到信息相对稀疏的当前领域(称为目标域),以达到提高目标域的推荐性能的目的.深度跨域模型能从稀疏数据中深度挖掘潜在特征,进而缓解目标域中的数据稀疏性提高推荐的准确性.然而,现有的跨域推荐方法大都仅利用用户的评分进行推荐,受限于评分矩阵固有的稀疏性,无法实现知识的有效迁移.
文中将内容信息和隐式反馈信息视为重要的可用辅助信息,并将其与跨域推荐模型相融合,提出了一种深度融合内容和隐式反馈的跨域推荐算法,即SICDR.该算法首先扩展标准的堆叠降噪自动编码器(stacked denoising autoencoder,SDAE)[4]模型,使其适合跨域推荐中的特征学习场景,以在源域中学习更有效的用户和项目潜在特征.同时将矩阵分解和隐式反馈信息相集成,来减少用户不喜欢项目的推荐.然后采用非完备正交非负矩阵三分解[5]方法生成连接两个域的公共潜在因子,从而实现从源域向目标域的知识迁移.
1" 相关工作
1.1" 隐式反馈信息
隐式反馈主要有两种形式:正反馈和负反馈.设pij为第i个用户对第j个项目的隐式反馈,fij为动作频率,即用户实际观看电影的时长,t是持续时间阈值.如果用户i观看电影j的时长超过t,则pij为1,否则为0.
pij=1" if" fijgt;t0" if" fijlt;t(1)
对于隐式反馈模型,例如电影数据集,一般来说,看电影的时间越长,用户的偏好度就越高.对于没有看过的电影,可能是因为用户不知道这部电影,或者没有访问过该电影,无法确定用户对该电影的偏好.因此通过引入置信度[6]的概念,将更受用户信任的项目赋予更大的权重,没有反馈的项目则被赋予较小的权重.随着越来越多的正向反馈信息的积累,置信度也会增加.置信度计算为:
cij=1+αfij(2)
式中:cij为置信度,1表示最低信任度;α为置信度系数;fij为动作频率.
用户-项目评分矩阵Rm×n可以通过m×k维的用户潜在特征矩阵J和k×n维项目潜在特征矩阵F的乘积来近似,即Rm×n=Jm×kFTk×n.隐式反馈分解的损失函数为:
L(J,F)=∑ijcij(pij-uTivj)2+γ(∑i‖ui‖2+
∑j‖vj‖2)(3)
式中:ui为用户的隐式反馈偏好特征向量;vj为项目的隐式反馈偏好特征向量;用户偏好pij为用户和项目隐式反馈偏好特征向量的内积,即pij=uTivj;γ为防止过拟合的正则化参数;cij为置信度.训练的目标是在评分矩阵R中通过最小化损失函数来求解特征向量ui和vj.由于ui和vj耦合在一起不容易求解,因此采用加权正则化交替最小二乘法[7]来训练模型,在求解式(3)时,首先固定F来求解J,然后再将得到的J固定来求解F.交替执行上述过程,直到误差满足阈值条件或达到迭代次数上限,具体表示如下:
ui=(Fk×nCin×nFTk×n+δE)-1Fk×nCin×npi(4)
vj=(Jk×mCjm×mJTk×m+δE)-1Jk×mCjm×mpj(5)
式中:Ci和Cj分别为用户i的置信度矩阵的对角矩阵和项目j的置信度矩阵的对角矩阵;pi和pj分别为用户i和项目j的置信度向量;δ为正则化参数;E为单位矩阵.
1.2" 堆叠降噪自动编码器
降噪自动编码器(denoising autoencoder,DAE)是一种前馈神经网络,其目的是利用加入噪声的输入数据来重构原始数据,以学习得到更为鲁棒的映射函数.DAE由编码器组件和解码器组件构成,其中编码器g(·)采用给定输入s并将其映射到隐藏层表示,而解码器f(·)将隐藏层表示映射回s的重构版本,使得f(g(s))≈s.文献[8]表明,将多个DAE堆叠在一起可以构成一个深度网络,即堆叠降噪自动编码器(stacked denoising autoencoder,SDAE),其具有多层神经网络,可以实现更丰富的表示,进一步提升模型提取特征的能力.SDAE采用深度网络来重建输入,并最大程度地减少输入与其重构之间的平方损失.文献[9]提出了一种SDAE的变体,即附加堆叠降噪自动编码器(additional stacked denoising autoencoder,aSDAE),既可以从辅助信息中提取有效的潜在特征,也能捕获用户和项目之间的隐含关系.若以L表示aSDAE模型的网络层数,那么网络的前L / 2层便充当模型的编码器,而后L / 2层则充当模型的解码器.aSDAE的原始输入是用户或项目的评分向量和基本描述性信息.其中,基本描述性信息包括用户个人信息和项目内容信息.通过one-hot编码,这些描述信息被表示为二进制向量.对于源域中aSDAE模型来说,其隐藏层l的用户所对应输出h(u)l可以通过以下方式获得:
h(u)l=g(W(u)lh(u)l-1+Z(u)lX(u)i+b(u)l)(6)
R︿(u)k=f(W(u)kh(u)k+b(u)k)(7)
X︿(u)k=f(Z(u)kh(u)k+b(u)k)(8)
式中:l∈{1,2,…,k-1},k为网络总层数;g(·)和f(·)表示激活函数;X(u)i为加噪后的用户辅助信息;b(u)k为在第k层的偏置值;R︿(u)k为在第k层重构输入评分向量;X︿(u)k为输出层重构用户辅助信息X;W1,…,Wk和Z1,…,Zk为权重矩阵;(u)为所处理的信息为用户信息.
1.3" 跨域协同过滤和CBT模型
跨域推荐利用源域稠密评分矩阵中的相关信息,并通过共享其潜在的通用评分模式来预测用户对稀疏目标域的项目评分,以此来提高目标域的推荐性能.文献[10]提出的基于密码本的知识迁移(codebook-based knowledge transfer,CBT)模型是跨域协同过滤中广泛使用的模型.借助迁移学习方法,CBT模型通过扩展密码本的方式来重构目标域的评分模式,改善了目标域评分模式的稀疏性.
CBT的整体学习过程是一个基于两步的跨域协同过滤算法,即源域学习和目标域适配.在第一步源域学习中首先基于正交非负矩阵三分解(orthogonal nonnegative matrix tri-factorization,ONMTF)方法学习评分模式[11],然后使用评分模式来构建密码本.CBT模型在源域学习阶段输出的是密码本,也是第二阶段迁移学习时进行目标域适配的输入数据. 第二步目标域适配则利用目标域中已有的评分,通过最小化重构误差来完成源域密码本的扩充.这样,CBT模型借助于源域评分模式聚类得到的密码本在目标域中的扩展,实现了源域和目标域在特征空间中的评分模式共享.
CBT使用ONMTF方法来构造密码本.用户-项目评分矩阵可以分解为3个因子的乘积,即 R=UHVT,其中U是用户的聚类指标,V是项目的聚类指标,H是聚类级别的用户项目评分模式.分解近似可以通过矩阵范数优化来实现:
minU≥0,V≥0,S≥0‖R-UHVT‖2F
s.t." UTU=I,VTV=I(9)
式中:R为评分矩阵;‖·‖F为Frobenius范数;I为单位矩阵.
2" SICDR算法
2.1" SICDR算法框架
文中提出了一种深度融合辅助信息的跨域推荐方法,以提高目标域的推荐精度并减少用户反感项目的出现.如图1,类似于已有的协同过滤跨域推荐方法[12],提出的SICDR算法的基本框架包括源域潜在特征提取和目标域评分矩阵重构两个部分.为了有效利用源域的评分信息和两种辅助信息,即用户和项目的内容信息以及隐式反馈信息,在源域中将矩阵分解和SDAE相集成,以提取更有效的用户和项目潜在特征,进一步丰富源域信息.采用非完备正交非负矩阵三分解(incomplete orthogonal nonnegative matrix tri-factorization,IONMTF)方法建立源域和目标域之间的关联,从而将源域中提取到的评分模式迁移到目标域中,以提高目标域的推荐准确性.与已有的协同过滤跨域推荐方法相比,SICDR模型实现了多源信息的融合,同时利用了评分、内容信息以及隐式反馈信息,丰富了用户和项目潜在特征的语义信息,通过从非完备的源域迁移评分模式,有效缓解了目标域中的数据稀疏问题.
2.2" 潜在特征提取
对于源域中给定评分矩阵Rs,矩阵的每一行表示每个用户的评分向量,每一列则表示各项目的评分向量.假定以X和Y分别表示辅助信息中的用户和项目基本描述性信息,这些评分向量以及辅助信息特征向量构成了SDAE的基本输入.用户或项目的内容信息被视为一个整体,通过直接导入到除输出层之外的所有层来集成,并在每一层中都与评分向量一同处理,两者的融合构成了最后一层的重构输入向量.
文中同时训练两个不同的SDAE模型,分别处理用户和项目信息,中间层的输出即为所要提取的用户和项目的潜在因子.式(6~8)表示的是用户信息的重构方法.类似地,可以将这些公式中的(u)替换为(v),将用户描述性信息X替换为项目属性信息Y,可以对物品的SDAE获得类似的结果.以这种方式,学习到的潜在因子不仅反映了项目的固有特征(从评分信息中提取),而且还反映了用户偏好特征(从用户和项目的内容信息中提取).
两个SDAE的中间层是深度学习模型和矩阵分解之间连接的桥梁,同时这两个中间层也是使深度协同过滤模型学习有效潜在因子并挖掘用户和项目之间的相似性和关系的关键,因此通过SDAE中间层所提取的用户和项目潜在特征与融合隐式反馈信息的矩阵分解相结合.由于要将两个模型所提取的特征进行融合,文中使用特征加权进行特征融合,即在对两个模型输出信息加权后,取并集并使用权重来缩小两个模型因子之间的差别.将SDAE和矩阵分解相集成得到的源域稠密评分矩阵R′s为:
R′s=(δh(u)k/2+(1-δ)ui)(δh(v)k/2+(1-δ)vj)T(10)
通过分别加权的方式对两个模型所获得的信息赋予不同的权重,然后将两者以联合的方式进行组合,以获得最终的预测稠密评分矩阵R′s,其中δ表示权重.
2.3" 目标域重构
文中采用IONMTF方法来构造码本,通过在原有损失函数中加入指示矩阵,松弛了原有方法对输入数据的完备性限制,将评分模式学习的应用场景从完备域扩展到非完备域.IONMTF松弛了对源域矩阵的原始完整评分限制,极大地增加了源域可用数据集的数量.此外,它扩大了源域数据的可选范围和可用数据规模,并获得比以往表示能力更强的码本.文中用s表示源域,t表示目标域,为了便于描述,将域的索引表示为d∈s,t.因此,IONMTF分解评分矩阵的损失函数为:
minUd≥0,Vd≥0,H≥0‖M°(R′d-UdHVTd)‖2F
s.t." UTdUd=I,VTdVd=I(11)
式中:Ud和Vd非负正交矩阵,分别为用户和项目的类别索引矩阵;H为簇层次的用户项目评分模式.添加矩阵M作为指示矩阵,当Rd≠0时Mij=1,否则Mij=0.操作符°表示指示矩阵M和后面损失公式的哈达玛积操作,它有助于在求解公式时避免矩阵中没有评分项目的影响.
从源域提取评分模式后,通过将评分模式进行聚类得到密码本B为:
B=UTsRsVsUTs11TVs(12)
式中:为矩阵点除;1为Us,Vs对应的全1矩阵.
目标域基于已有评分对来自源域的密码本进行适配,目标域中的缺失评分R′t为:
R′t=M°Rt+[1-M]°[UtBVTt](13)
式中:Rt为目标域评分矩阵.
为了使预测值尽可能接近真实值,通过最小化SICDR目标函数,以使得用户预测评分与原始评分之间的误差平方尽可能小.
SICDR模型的总体损失包括3部分:源域输入信息的重构损失;深度学习特征向量和矩阵分解特征向量融合的近似误差;源域和目标域中对评分矩阵进行非完备正交非负矩阵三分解的损失.
首先,源域中所有输入信息的重构损失Ls为:
Ls=∑i,jN(Rs-UsVTs)2+α∑i(R(u)-R︿(u))2+
(1-α)∑i(X-X︿)2+β∑j(R(v)-R︿(v))2+
(1-β)∑j(Y-Y︿)2+∑ijcij(pij-uTivj)2(14)
其中第一项为评分矩阵的分解项,N是指示矩阵.第二项和第三项是SDAE模型的损失函数,α,β是权重参数,用于平衡重构误差.最后一项表示矩阵分解中融入隐式反馈信息的损失函数.
深度学习特征向量和矩阵分解特征向量融合的近似误差La为:
La=∑sρ∑i(Us-h(u)l,i)2+∑sφ∑j(Vs-h(v)l,j)2(15)
式中:ρ,φ为惩罚参数.
此外,源域和目标域中对评分矩阵进行非完备正交非负矩阵三分解的损失Lm为:
Lm=∑d∈{s,t}‖M°(Rd-UdHVTd)‖2(16)
式中:H为源域中提取的评分模式.如果Rd(i,j)有评分,则M=1,否则M=0.
因此,SICDR模型的整体损失函数L为:
L=Ls+La+Lm+γ·freg(17)
式中:γ为正则化参数,freg为防止过拟合的正则化项,即
freg=∑l(W(u)l2F+V(u)l2F+b(u)l2F+W(v)l2F+
V(v)l2F+b(v)l2F)+∑uUs2F+∑vVs2F+
∑i‖ui‖2+∑j‖vj‖2(18)
式中:W(u)l,V(u)l,W(v)l,V(v)l为l层的权重矩阵;b(u)l,b(v)l为对应的偏置向量.
2.4" SICDR算法实现机制
文中提出的SICDR模型包括两个阶段.在第一阶段,首先在源域中使用深度学习模型SDAE提取潜在特征,然后将深度学习模型所学到的特征与矩阵分解所学到的特征集成在一起,以生成一个更加稠密的源域评分矩阵.在第二阶段,采用IONMTF将源域中的密集的用户和项目评分矩阵共同聚类到一个公共评分模式,生成密码本.接着,通过迭代方式更新Ut和Vt,将源域中学习到的评分模式迁移到目标域中进行适配,以实现评分模式近似和目标域评分矩阵的重构,从而实现协同过滤跨域推荐.协同过滤跨域推荐的详细过程如算法1.
算法1 SICDR算法
输入:源域评分矩阵Rs,源域评分矩阵Rt,用户辅助信息X,项目辅助信息Y,迭代次数Iter,用户簇和项目簇的维度n
输出:目标域预测评分矩阵R′t
1:" for it = 1 to Iter do
2:" for 用户i对项目j的评分:
3:" 组合R(u),Y(u)作为项目特征网络提取的输入
4:" 组合R(v),Y(v)作为项目特征网络提取的输入
5:" 根据式(4,5)得到用户和项目的隐式反馈向量
6:" 由式(6)得到SDAE提取的用户和项目特征
7:" end for
8:" 利用反向传播算法优化两个SDAE参数
9:" R′s←(δh(u)k/2+(1-δ)ui)(δh(v)k/2+(1-δ)vj)T预测源域评分矩阵R′s
10:end for
11:根据式(11)将预测评分矩阵R′s分解为Us,H,Vs,通过式(12)计算得到N维密码本B
12:for n←1…N do
13:为Ut 和 Vt分配存储空间,并初始化Vt
14:end for
15:minU≥0,V≥0,H≥0‖M°(Rs-UsHVTs)‖2F" 迭代更新
16:R′t←M°Rt+[1-M]°[UtBVTt]获得目标域预测评分矩阵
3" 实验结果及分析
3.1" 数据集
文中使用3个公共数据集来评估SICDR模型的性能.MovieLens-100K(MLK)数据集包括943个用户和1 682部电影的100K评分,MovieLens-1M(MLM)数据集包含6 040个用户和3 706部电影的约100万个评分,它们是从不同年份收集的,每个评分是1(最差)到5(最好)之间的整数.用户的辅助信息包括用户的性别、年龄和职业等,项目的辅助信息包括电影名称、类别以及发行日期等.BookCrossing(BC)数据集包含1 149 780本书和278 858个用户,其中评分是0~10的整数,它还包含用户和书籍的一些属性信息,并将其作为辅助信息加以利用.由于这些数据集中没有评论信息,文中利用元数据集中的电影名来匹配亚马逊数据集上的相应评论信息,在电影名和图书名上应用词嵌入技术而不是对评论信息进行处理.
将数据集分为两对,即MLK(s)与MLM(t),MLK(s)与BC(t),其中一个充当源域(s),另一个充当目标域(t).训练4种基线模型时,均使用不同百分比(60%,80%和95%)的评分来训练.首先从整个数据集中随机选择训练数据集,然后将其余数据用作测试数据集.使用随机选择的不同训练数据进行重复训练以评估模型性能,并报告平均表现.
3.2" 评估指标
文中使用均方根误差(root mean square error,RMSE),平均绝对误差(mean absolute error,MAE)以及召回率(Recall@K)作为评价指标,分别定义为:
RMSE=" 1T∑Rij∈T(Rij-R︿ij)2(19)
MAE=1T∑Rij∈T|Rij-R︿ij|(20)
式中:Rij为用户i在项目j上的实际评分;R︿ij为其相对应的预测评分;T为测试集;T是测试集中的评分总数.
Recall@K=NumberofHits@K|Ts|(21)
式中:NumberofHits@K为列表中的测试项的数量;Ts为用户喜欢的项目总数.将所有用户的平均召回率作为最终的度量结果.
3.3" 基准算法
为了评估SICDR模型的性能,文中选择以下方法作为基线进行比较.
PMF-概率矩阵分解[13]是将用户-项目矩阵分解为用户和项目因子的有效模型,该模型通过高斯分布对用户和项目的潜在因素进行建模.
CMF -集体矩阵分解[14]通过同时分解多个矩阵来合并不同的信息源,以共享实体潜在因子的方式实现推荐.
aSDAE-附加堆叠降噪自动编码器[9]是一个单域模型,其中辅助信息和评分信息都通过使用自动编码器进行融合.
RC-DFM -深度混合模型[15]首先利用堆叠降噪自动编码器提取用户项目潜在因子,然后利用MLP将潜在因子从源域映射到目标域.
3.4" 实验比较和分析
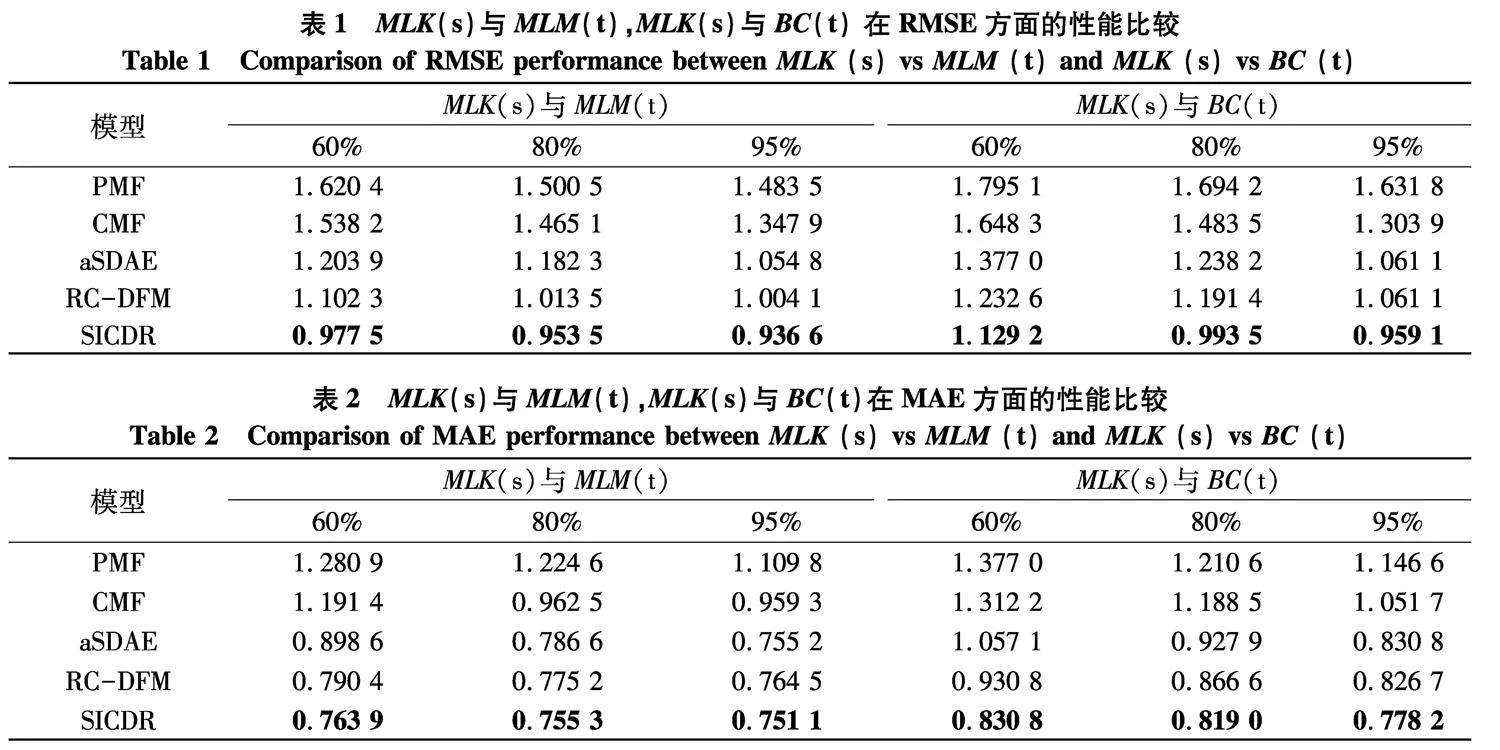
表1,2分别显示了在两对数据集上PMF,CMF,aSDAE,RC-DFM和SICDR模型的平均RMSE和MAE,其中每对数据集上的实验结果最低值以粗体突出显示.
从表1,2中可以看出,与PMF和CMF相比使用深度学习模型提取潜在特征的aSDAE,RC-DFM和SICDR模型的性能更好,证明了融合辅助信息的有效性以及深层结构可以更好地提取辅助信息中的潜在特征.跨域推荐RC-DFM和SICDR较单域推荐PMF和aSDAE而言,性能得到显著提升,表明跨域推荐可以更好的解决相关领域的数据稀疏性问题.SICDR和RC-DFM的RMSE和MAE较为接近,两者同为跨域推荐且融合了辅助信息,而SICDR结果略优于RC-DFM,表明跨域推荐中融入隐式反馈可以提高推荐的准确性,验证了特征提取对缓解高度稀疏评分的有效性.与其他模型对比,文中提出的SICDR模型取得了较好的优势,这证明了深度学习模型和正交非负矩阵三分解集成的有效性.
此外,就RMSE和MAE而言,SICDR模型在MLK(s)与MLM(t)数据对上的性能优于MLK(s)与BC(t).这表明源域MovieLens-100K与目标域MovieLens-1M之间具有比目标域BookCrossing更多的共同特征,也就是说BookCrossing数据集和MovieLens-100K数据集之间相差较大,而迁移学习能从更相近的领域中传输更多的信息.
图2显示了在MovieLens-100K数据集上60%和80%训练数据下的Recall@K结果,可以看出PMF是性能最差的模型,因为它缺乏额外的辅助信息,无法做出较为合理的推荐.
此外,CMF的性能比aSDAE、RC-DFM和SICDR略差,这是因为当它的辅助信息较为稀疏,CMF可能无法正常工作.而SICDR模型比aSDAE和RC-DFM实现了更好的性能,它将融合辅助信息的SDAE模型与矩阵分解相结合,可以更好地处理稀疏的评分信息和辅助信息,并学习有效的用户和项目的潜在因子,从而提供更准确的推荐.
一般来说,在分析Recall@K结果时,从RMSE 和MAE得出的结论基本保持不变.此外,观察到 aSDAE和RC-DFM有很大的重叠,因为它们在 Recall@K方面属于同一类.发生重叠是由于模型的影响小于数据结构的影响.尽管如此,无论K在10~50发生什么变化,SICDR模型在所有情况下都优于基线.
综上所述,与几个相关模型的性能相比,文中提出的SICDR模型具有明显的优势,证明了其有效性.同时,当训练数据的百分比减少时,下降变得显著,这表明使用迁移学习进行跨域推荐的有效性.
4" 结论
(1) 提出了一种深度融合辅助信息的跨域推荐模型,称为SICDR.它将矩阵分解和深度学习模型SDAE相集成,并实现了跨域推荐.SICDR模型可以从用户-项目评分矩阵和辅助信息中学习有效的潜在因子,通过这种方式学习的潜在因子可以保留更多的语义信息,并且通过从不完备的源域迁移评分模式来缓解目标域中的数据稀疏问题.
(2) 以协同过滤和迁移学习相结合的评分模式,逼近目标域并预测目标评分矩阵缺失值.SICDR模型一方面利用反馈信息降低了用户厌恶信息在推荐列表中出现的概率,另一方面通过非完备正交非负矩阵三分解在相关领域进行知识迁移,扩大了辅助信息的使用,改善了信息的稀疏性,提升了用户体验.
参考文献(References)
[1]" SHI Y , LARSON M , HANJALIC A . Collaborative filtering beyond the user-item matrix: A survey of the state of the art and future challenges[J]. ACM Computing Surveys (CSUR), 2014, 47(1):1-45.
[2]" CHEN S, PENG Y. Matrix factorization for recommendation with explicit and implicit feedback[J]. Knowledge-Based Systems, 2018, 158:109-117.
[3]" HU G , YU Z , QIANG Y . MTNet: A Neural Approach for Cross-Domain Recommendation with Unstructured Text[C]∥KDD Deep Learning Day.USA:ACM,2018:1-10.
[4]" LI S, KAWALE J, FU Y. Deep collaborative filtering via marginalized denoising auto-encoder[C]∥In Proceedings of the 24th ACM International on Conference on Information and Knowledge Management.USA:ACM,2015:811-820.
[5]" MING H, ZHANG J, PENG Y, et al. Robust transfer learning for cross-domain collaborative filtering using multiple rating patterns approximation[C]∥The Eleventh ACM International Conference. USA:ACM, 2018:225-233.
[6]" HU Y , KOREN Y , VOLINSKY C . Collaborative filtering for implicit feedback datasets[C]∥ Eighth IEEE International Conference on Data Mining.USA: IEEE, 2009: 10472159.
[7]" XIAO X , YAN R , TAN D . Recommendation algorithm based on explicit and implicit feedback matrix factorization[C]∥ 2019 4th International Conference on Mechanical, Control and Computer Engineering (ICMCCE). USA:IEEE, 2019:903-906.
[8]" VINCENT P, LAROCHELLE H, LAJOIE I,et al. Manzagol. stacked denoising autoencoders:learning useful representations in a deep network with a local denoising criterion[J]. Journal of Machine Learning Research,2010, 11(12):3371-3408.
[9]" DONG X, YU L, WU Z H, et al. A hybrid collaborative filtering model with deep structure for recommender systems[C]∥Proceedings of the AAAI Conference on Artificial Intelligence. USA:AAAI, 2017:1309-1315.
[10]" LI B , YANG Q , XUE X . Can movies and books collaborate? Cross-domain collaborative filtering for sparsity reduction[C]∥ Proceedings of the 21st International Joint Conference on Artificial Intelligence. USA: IJCAI, 2009,38(4):2052-2057.
[11]" JI K,SUN R Y, LI X,et al. Improving matrix approximation for recommendation via a clustering-based reconstructive method[J]. Neurocomputing, 2016,173(3): 912-920.
[12]" MING H , ZHANG J , ZHANG S Z . ACTL: Adaptive codebook transfer learning for cross-domain recommendation[J]. IEEE Access, 2019,7:19539-19549.
[13]" SALAKHUTDINOV R, MNIH A. Probabilistic matrix factorization[C]∥ Proceedings of the Twenty-First Annual Conference on Neural Information Processing Systems.USA:NIPS, 2007:1257-1264.
[14]" SINGH A P, GORDON G J. Relational learning via collective matrix factorization[C]∥ ACM Sigkdd International Conference on Knowledge Discovery amp; Data Mining. USA:ACM, 2008:650-658.
[15]" FU W J, PENG Z H, WANG S Z, et al. Deeply fusing reviews and contents for cold start users in cross-domain recommendation systems[J].Proceedings of the AAAI Conference on Artificial Intelligence, 2019,33(1):94-101.
(责任编辑:曹莉)
