
基于机器学习的运动损伤风险预测模型构建与比较
2024-10-08 00:00:00毛顿开
文体用品与科技 2024年19期



摘要:随着人们对竞技体育关注度的提升,运动员健康成为管理焦点。本研究应用机器学习预测运动员受伤风险,优化健康管理。基于1000样本数据,分析六大特征,通过统计方法确认训练强度为核心因素。对比七种机器学习模型,采用十折交叉验证,衡量多种性能指标,证实随机森林模型预测准确度最高。本研究不仅建立了损伤预测模型,还深入分析其效能与潜在改进空间,为模型跨领域应用奠定科学基础,对预防运动损伤具有重要理论与实践意义。
关键词:机器学习 数据分析 模型预测 运动损伤因素
中图分类号:G804 文献标识码:A 文章编号:1006-8902-(2024)-19-107-3-TBB
引言
在现代体育界,运动员健康至关重要,关乎着运动员的比赛成绩及职业寿命。体育运动的高强度和风险性导致频繁伤病,影响训练与竞赛。2021东京奥运会见证了11315名运动员的竞技,其中1035人在赛事中受伤,438人染病。尤其是拳击、小轮车竞速、自由式小轮车、滑板、空手道项目受伤率高达19%-27%,凸显高危性质。但得益于损伤预测和康复技术进展,伤病发生率已大幅降低。
面对运动损伤的普遍挑战,有效管理和预防成为体育领域的优先任务。机器学习与数据科学的融合为伤病风险预测带来新曙光,为解决这一难题提供新途径。本文核心在于分析运动员受伤关键因素,并介绍如何应用机器学习建立模型,科学预测伤病风险,旨在保护运动员健康,确保其竞技生涯的长久成功。
1、文献综述
现代体育竞技高度依赖运动员健康,高强度训练易致伤病,影响运动员表现与职业生涯。有效管理和预防伤病成为必须。张家骁在研究中指出,大数据能提升运动健康领域的效率。现今,借助机器学习与数据科学发展,运动健康领域正利用这些技术预测伤病风险,为减少伤害开拓新途径。
运动员受伤因素复杂多样,涵盖技术失误、过度训练、生理条件及个人属性等。研究揭示,不当技术、肌肉疲劳(疲劳性损伤)、营养不足等均为常见致伤原因。特定群体中,刘同为等人在《武术套路优秀运动员的身体形态特征》中利用测试指标、派生指标等来判断运动员是否受韧带病、关节脱位等疾病折磨。如足球运动员易遭遇拉伤、关节脱位等问题;田径选手则常受踝关节、大腿后肌群及腰背伤害。FMS功能性动作筛选等方法被用于识别致伤动作,而体操研究强调了教练的专业认知对制定合理训练计划、防止伤害的重要性。
机器学习作为AI分支,利用数据洞察模式,自动决策与预测,极大推动运动损伤预测预防。研究广泛应用决策树、随机森林等模型精确诊断伤病风险。李欣海等指出随机森林因分类回归能力强、能评估变量重要性,成为减少预测误差的首选。赵金超等强调,其通过多决策树集成,增强分类效率,提升模型性能。技术进步与数据增长促使AI在运动健康领域发挥更关键作用,深化健康理解,揭示伤病规律,支持个性化训练策略,引领科学高效训练新趋势。近年来,大数据与机器学习融合加速了医疗数据在体育和康复领域的应用。运动损伤与疾病预测技术逻辑相通,模型互转潜力大。如岳海涛等用XGBoost建冠心病预测模型,并借数据平衡技术增强模型。因运动损伤原因复杂且数据类型多样,非线性问题突出,促使研究采用神经网络等AI解法。周支瑞等提出的四阶段模型构建流程(问题定义、特征选择、模型建构、效果测评),旨在优化特征选取,改善运动损伤预测中机器学习应用的复杂性。
现有研究局限性在于针对特定运动,损伤预测模型通用性不足。本研究旨在揭示普遍性损伤规律,结合运动员生物特征与训练模式,开发广适性预测模型,旨在通过简化应用范围和扩大大数据技术应用,提升多领域运动员的健康管理水平。
2、数据与经典统计计量方法
2.1、数据集概览:来源、规模与预处理方法
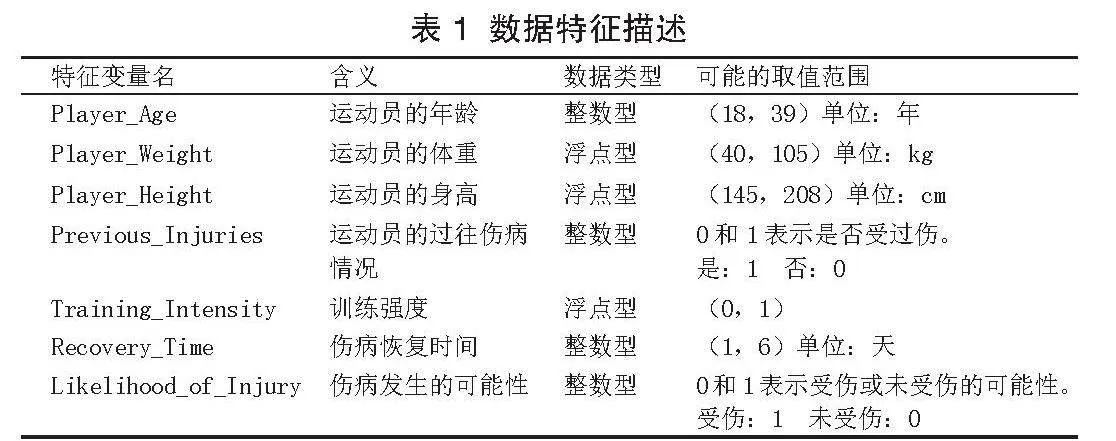
Kaggle来源的“injury_data.csv”数据集含1000条记录,涵盖7个关键特征(年龄、体重、身高、过往伤病等),目标是预测运动员受伤概率。数据全面,整合生物、训练及历史健康信息(表1),为建模提供坚实基础,便于个性化监控与策略调整。预处理涉及均值填补缺失值及数据标准化(均值0,方差1),保障分析精确高效。
2.2、相关性分析
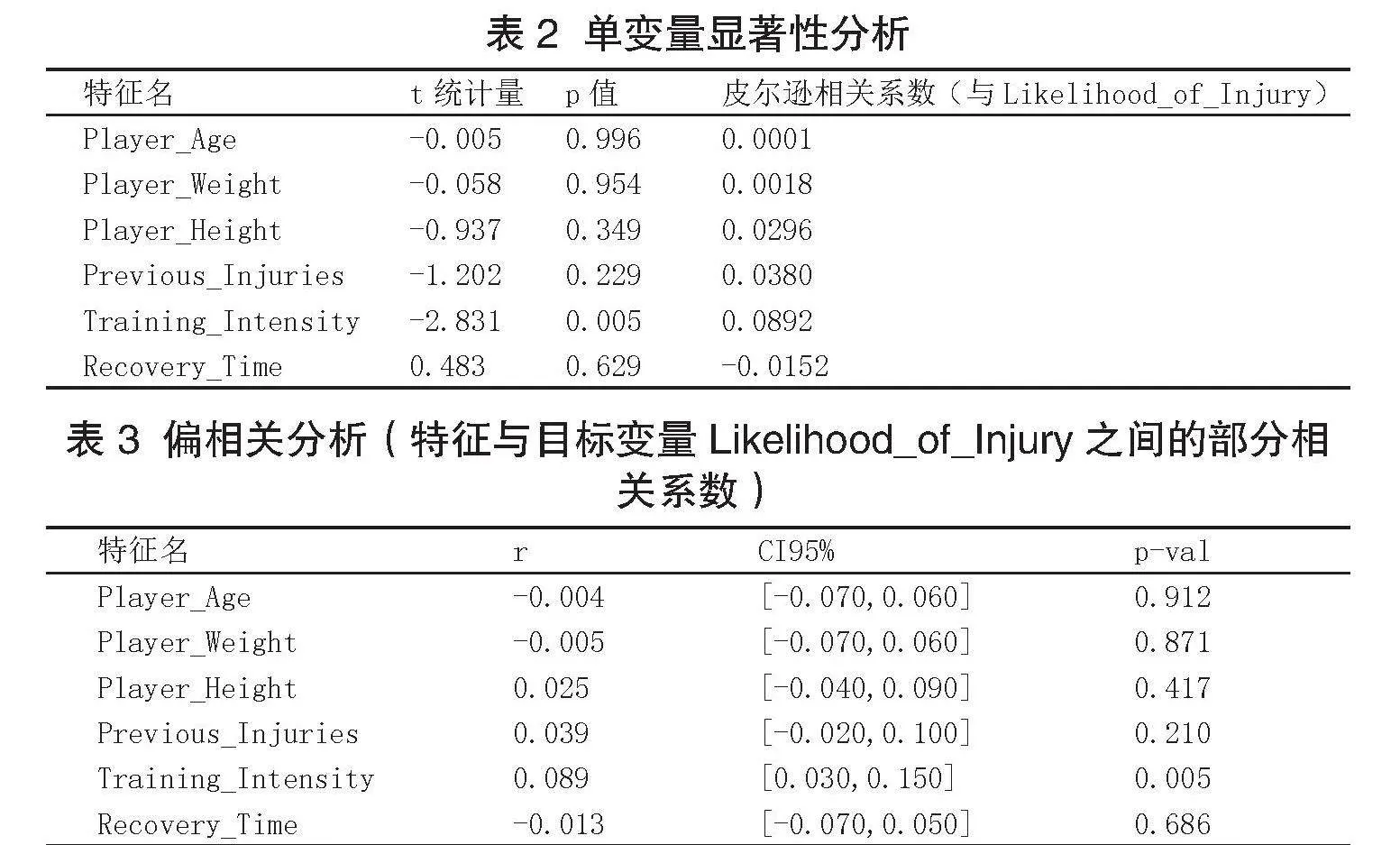
t检验分析显示,仅训练强度在不同受伤可能性组间有显著差异,依据是得到的p值小于0.05(表2)。偏相关分析进一步排除其他变量干扰,确认训练强度与受伤可能性间的显著线性关联,呈现于表3,其中包含各特征的偏相关系数及95%置信区间,强调训练强度的独立重要性。
基于上述相关性分析,初步断定训练强度是与受伤可能性最相关的因素。
3、机器学习模型建立与评价
3.1、机器学习模型建立
预处理后,依据探索性分析选定特征,初始化7种模型(逻辑回归、决策树、随机森林、XGBoost、SVM、Bagging、KNN)并设定配置:1000样本、6特征、随机种子42以确保复现性。采用十折交叉验证,数据分十份轮流作为测试与训练集,全面评估模型性能,详情参考图1流程图。
3.2、评价指标与模型对比
(1)评价指标。
评估七个模型性能时,采用十折交叉验证并记录精确率、召回率、F1 Score及训练时间(表4)。鉴于数据集含1000样本、6个特征变量及固定的随机种子42,规模适中,十折交叉验证策略尤为适合,既能有效缓解过拟合风险,又提升了模型泛化能力。
具体实施中,数据集被随机均匀分为十份,确保各份间保持原数据特性。每轮验证选取一份作测试集,其余九份联合构成训练集,以此训练模型并测试,完成一轮性能评估。历经十轮迭代,平均各轮结果即得模型整体性能指标,并通过ROC曲线直观反馈模型性能(图2)。
(2)模型对比。
逻辑回归快速(0.146s),AUC佳(0.932),但精确度、召回率及F1分数稍低。决策树训练迅速(0.322s)但易过拟合。XGBoost与SVM性能强,但训练耗时多(0.918s和0.434s)。Bagging平衡了各项指标(精度、召回、F1:0.9828、0.893、0.909;时间:2.348s),唯抗噪及防过拟合能力一般。KNN不适大规模数据,对异常值敏感。
图1中,XGBoost的ROC曲线位居顶点,显著优于随机猜测,性能最优。随机森林紧随其后,亦表现出色。逻辑回归、支持向量机、Bagging及决策树虽优于随机水平,但整体次于前两者。KNN表现最末,仅微高于随机线。综合来看,XGBoost与随机森林表现卓越,KNN和决策树相对较弱,其余三者表现中等。
(3)最优模型选择。
通过实验和数据对比,随机森林和XGBoost表现较好,最后随机森林在精确率、召回率、F1 Score和AUC面积上都表现得相当不错,且训练时间相对较短,比XGBoost略好,虽然XGBoost的ROC曲线略高于随机森林,但是综合选择随机森林模型作为预测模型相较于其他模型更优。
3.3、随机森林因子重要性计算与分析
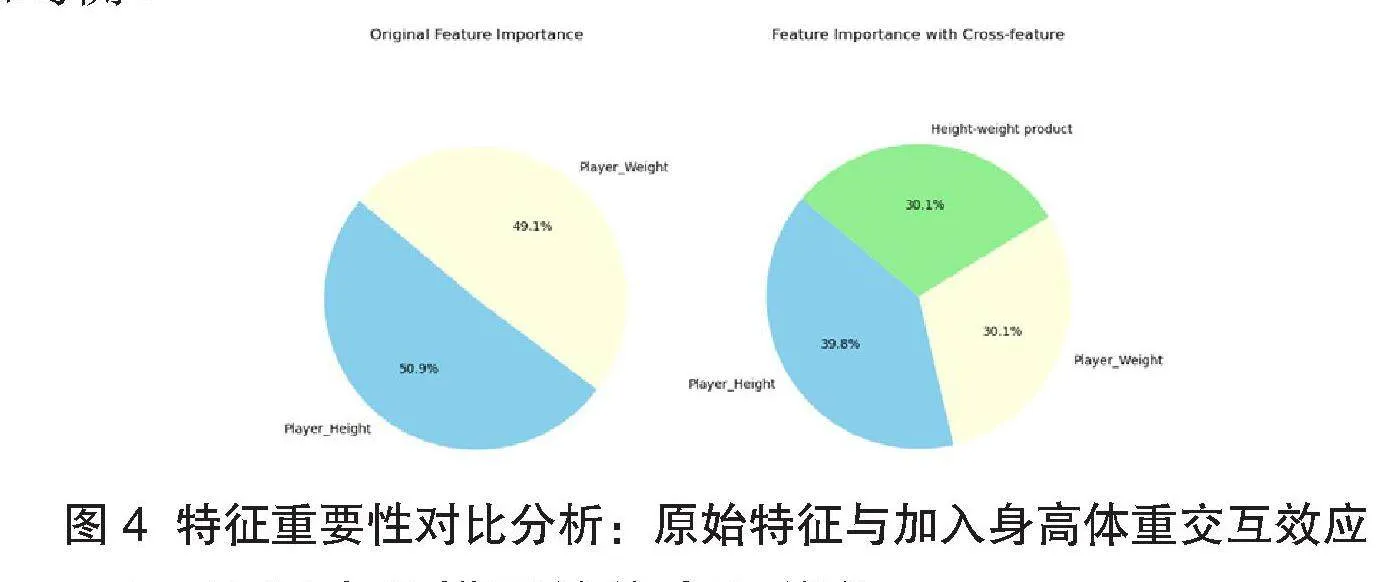
随机森林被确认为最优模型,特征重要性分析突出运动员身高、体重及训练强度为伤害预测最关键因素,影响权重均超0.235(图3)。该结果强调了训练强度的重要性,并揭示了身高、体重的显著效应及其与训练强度组合形成的高风险场景。模型凭借捕捉非线性和交互效应的能力,提供了更深层的分析见解。
原始分析指出,身高和体重对训练强度的影响各半,约50%(图4)。但加入身高—体重交叉项后,二者重要性分别调整为39.8%和30.1%,交叉项重要性达30.1%,显示二者的交互效应对训练强度有重要影响,并促使特征重要性分配更加均衡。
3.4、随机森林模型的优点和优化
随机森林模型展现卓越预测效能,特别是在精确率、召回率、F1 Score及AUC方面,擅长处理类别预测,虽训练耗时8.812s,但仍高效适应大数据。作为集成学习模型,它凭借多决策树集成强化了稳定性和抗噪声、过拟合能力。相比黑箱模型,随机森林结构明晰,易于理解与解读,通过决策树和特征重要性揭示预测逻辑。
本研究在控制变量环境下,优化随机森林超参数与特征选择,全量特征纳入。初始参数设为:树100棵、最大深度5、最小分割数2。通过逐步调整树数(100-1000)、最大深度(5-30)、最小分割数(2-10),最终确定最佳配置为:树200棵、深度10、分割数4。此优化使模型性能大幅提升,精确率0.939、召回率0.910、F1 Score 0.919,验证了优化策略的有效性与实用性。
4、研究结果及讨论
4.1、研究结果及优势
本研究运用单变量及偏相关分析,确立训练强度为伤害风险主要影响因子。通过机器学习,尤其是随机森林模型的优化,不仅强化了训练强度的关键作用,还辨识出身高、体重的显著性。模型优化后,预测性能最优。结合精细数据分析与算法,确保模型既贴近现实又具普适性,有效指导损伤防治,并为后续研究奠定数据与方向基础,推动领域深入前行。
4.2、研究对当下体育运动和运动损伤领域的现实意义
本研究优化的随机森林模型成为运动损伤预测的有效工具,助力运动员健康管理。教练和医疗团队借此能监控健康,根据身高、体重、训练强度等关键因素的变化预警伤害风险,实施个性化训练策略以预防和减轻伤痛。通过统计分析强调训练强度的关键角色,促进训练计划个性化调整,确保与运动员状态相符,实现理论到实践的转化,为运动损伤预防提供科学数据支撑。
4.3、研究的未来实际应用
本研究专注于运动员损伤预测,利用机器学习减少运动伤害,推广至多领域:医疗健康早期疾病干预、工业安全工伤预防、交通风险管理,及应对老龄化社会、个性化分析老年人生活习惯与医疗记录、预测健康风险、指导健康管理。此模型跨界应用广泛,不仅革新运动安全,亦为公共健康、工业与交通等领域提供安全与健康管理的新工具,展现跨学科技术的巨大潜力和社会价值。
4.4、讨论及总结
本研究分析运动员损伤的个体因素,如生物属性、训练管理及健康史,确认训练强度为首要影响。通过比较七种机器学习模型并十折交叉验证,证明随机森林因高预测性能适合损伤预测。研究虽侧重个体因素,但也认识到环境因素的作用,提示未来模型需综合考量。建议模型融合以提高预测效率,并强调随机森林在医疗、工业安全及交通等领域的广泛应用潜力。此研究不仅创建了运动损伤预测模型,还推动了其在多个领域的应用探索,为运动损伤的预防和治疗提供科学指导,并具有重要的科研价值与实践意义。
参考文献:
[1]张家骁.关于大数据在运动及健康领域的应用研究[J].科技资讯,2019,17(36).
[2]代威.田径运动损伤预防方法[J].田径,2024(03).
[3]于丙煊.皮划艇运动的损伤规律及预防策略研究[D].江西师范大学,2020.
[4]刘同为,丁丽萍,崔永胜,等.武术套路优秀运动员的身体形态特征[J].体育学刊,2004(03).
[5]吕志刚,杨从麝,杨次榆,等.足球运动员的损伤研究[J].成都体育学院学报,1998(02).
[6]樊玲.田径运动中常见运动损伤的原因分析及预防[J].昌吉学院学报,2005(03).
[7]姚磊.我国优秀田径运动员的运动损伤流行病学调查与分析[J].北京体育大学学报,2007(03).
[8]封旭华,杨涛,孙莉莉,等.功能性动态拉伸训练对男子足球运动员功能动作测试(FMS)和运动损伤患病率的影响[J].体育科研,2011,32(05).
[9]孙永生.国家队男子体操运动员损伤的物理诊断及受伤因素分析[J].中国学校体育(高等教育),2015,2(09).
[10]张磊.面向运动损伤预防的机器学习预测模型与实践策略[C]//国际班迪联合会(FIB),国际体能协会(ISCA),中国班迪协会(CBF).2024年第二届国际体育科学大会论文集.华南理工大学体育学院,2024.
[11]李欣海.随机森林模型在分类与回归分析中的应用[J].应用昆虫学报,2013,50(04).
[12]赵金超,李仪,王冬,等.基于优化的随机森林心脏病预测算法[J].青岛科技大学学报(自然科学版),2021,42(02).
[13]岳海涛,何婵婵,成羽攸,等.基于机器学习的冠心病风险预测模型构建与比较[J/OL].中国全科医学,1-11[2024-05-20].http://kns.cnki.net/kcms/detail/13.1222.R.20240418.1001.010.html.
[14]黄元琦.基于机器学习的非接触性损伤风险预测模型构建与分析[D].福建师范大学,2022.
作者简介:毛顿开(2002-),男,汉族,江苏苏州人,本科,研究方向:体育与大数据的交叉融合。
