
基于多模态对齐融合的车厢部件语义分割算法
2024-09-21 00:00:00赵梓云高晓蓉罗林
现代电子技术 2024年16期






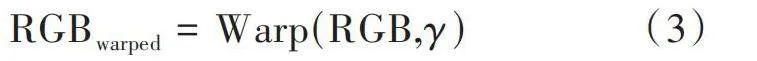



摘" 要: 车厢部件的定期情况监测是列车安全运行的重要保证之一,基于深度学习的语义分割方法可以用于相关部件的位置形态确定,以便后续进行螺栓和管线是否松动或变形的检查,但这对分割精度有较高的要求。另外,仅基于普通图像的纹理特征难以应对各种实际复杂场景,会出现分割不连续、边缘轮廓不清晰的问题。为此,提出一种基于多模态数据对齐融合的语义分割算法,额外引入车厢深度图来补充普通图像中缺失的几何特征信息,再将两种模态的特征对齐后作为互补的特征融合学习,最终达到准确分割部件的目的。通过车厢部件的RGBD语义分割数据集的建立,对所提算法在实际应用场景下的效果进行验证,得到97.2%的召回率以及87.4%的平均交并比。同时,所设计模型在NYUDV2数据集上达到了53.5%的平均交并比,与同类型算法相比处于先进水平。这些结果表明,所提算法在有挑战性的车厢部件分割任务中,可以达到良好的分割效果,也具有较好的泛化性,有助于提升车厢部件检测的自动化水平,减轻人工压力。
关键词: RGBD语义分割; 车厢部件; 多模态特征融合; 特征对齐; 螺栓; 管线; 注意力机制
中图分类号: TN911.73⁃34; TP391" " " " " " " " " " 文献标识码: A" " " " " " " " "文章编号: 1004⁃373X(2024)16⁃0150⁃07
Carriage component semantic segmentation algorithm based on multi⁃modal alignment fusion
ZHAO Ziyun, GAO Xiaorong, LUO Lin
(College of Physical Science and Technology, Southwest Jiaotong University, Chengdu 610031, China)
Abstract: Regular condition monitoring of carriage components is one of the important guarantees for the safe operation of trains. The semantic segmentation method based on deep learning can be used to determine the position and shape of relevant components so as to check whether bolts and pipelines are loose or deformed, which has higher requirements for segmentation accuracy. However, it is difficult to cope with various practical and complex scenes based on the texture features of ordinary images, and the problem of discontinuous segmentation and unclear edge contours will occur. Therefore, a semantic segmentation algorithm based on multi⁃modal data alignment fusion is proposed, and the depth map of the carriage is introduced to supplement the missing geometric feature information in the ordinary image. The features of the two modes are aligned and used as complementary feature fusion learning to realize the accurate component segmentation. By establishing the RGBD semantic segmentation data set of compartment components, the effect of the proposed algorithm in practical application scenarios is verified, and the recall rate of 97.2% and the average crossover ratio of 87.4% are obtained. The proposed model achieves an average crossover ratio of 53.5% on the NYUDV2 dataset, which is at an advanced level compared with similar algorithms. These results show that the proposed algorithm can realize the good segmentation effect in challenging compartment component segmentation tasks, and has good generalization, which is helpful to improve the automation level of compartment component detection and reduce manual pressure.
Keywords: RGBD semantic segmentation; carriage component; multi⁃modal feature fusion; feature alignment; bolt; pipeline; attention mechanism
0" 引" 言
随着我国在交通领域基础设施建设方面的不断投入,截至2023年底,铁路营业里程已经达到15.9万km。铁路交通运输承载着提升人们生活便利度以及促进社会经济发展的使命,所以铁路运输安全必须予以重视。车厢关键位置的部件状态对于列车是否能够平稳安全运行起着至关重要的作用,然而这些位置的螺栓和管线数量非常多,人工检查的方式效率低且容易出现疏漏,越来越不能适用于当前铁路事业的不断发展。故随着深度学习的兴起,基于计算机视觉的检测手段逐渐开始应用于铁路相关领域[1]。
RGB图像具有红、绿、蓝三个通道,是生活中最为常见的图像,但是仅基于RGB图像的语义分割算法由于光照不均匀、部件交错遮挡等原因,分割效果并不稳定,所以引入包含互补特征的深度图像是有必要的。RGB图像主要包含纹理信息,而深度图像则包含几何信息,两者具有较大差异性,因而RGB图像和深度图像的特征信息融合是两种不同模态之间的特征融合。早期的多模态融合网络特征结合方式简单,例如C. Hazirbas等人提出的FuseNet,该结构利用两个独立的卷积神经网络分别提取模态特征,然后直接进行特征拼接[2]。这种多分支融合的模型成为了RGBD语义分割网络的主流结构。为了更好地利用深度图像的特征,Xing Y等人提出了可塑的2.5D卷积对不同深度范围的像素进行针对性学习[3]。Jiao J等人提出通过几何感知嵌入的方式对深度信息进行推断[4]。这些方法为RGBD语义分割提供了新思路。目前大多数模型为了使特征提取阶段获得几何信息指导,倾向于以多阶段的形式将深度分支特征传播到RGB分支进行融合[5]。
然而以上方法没有考虑到实际情况中深度图像质量欠佳且存在噪声的问题。深度图像和RGB图像可能是由不同的镜头拍摄的,虽然通常会进行图像配准[6],但错位仍然不可避免,神经网络在两个不相关的模态中无法建立足够的联系。针对上述问题,本文提出了一种基于对齐融合的多模态语义分割算法。该算法利用改进的注意力机制来减少深度数据所包含的噪声影响,通过对齐模块调整两种模态的特征进行对准后再融合,从而适应实际情况,改善分割效果。
1" 基本原理
1.1" 语义分割模型框架
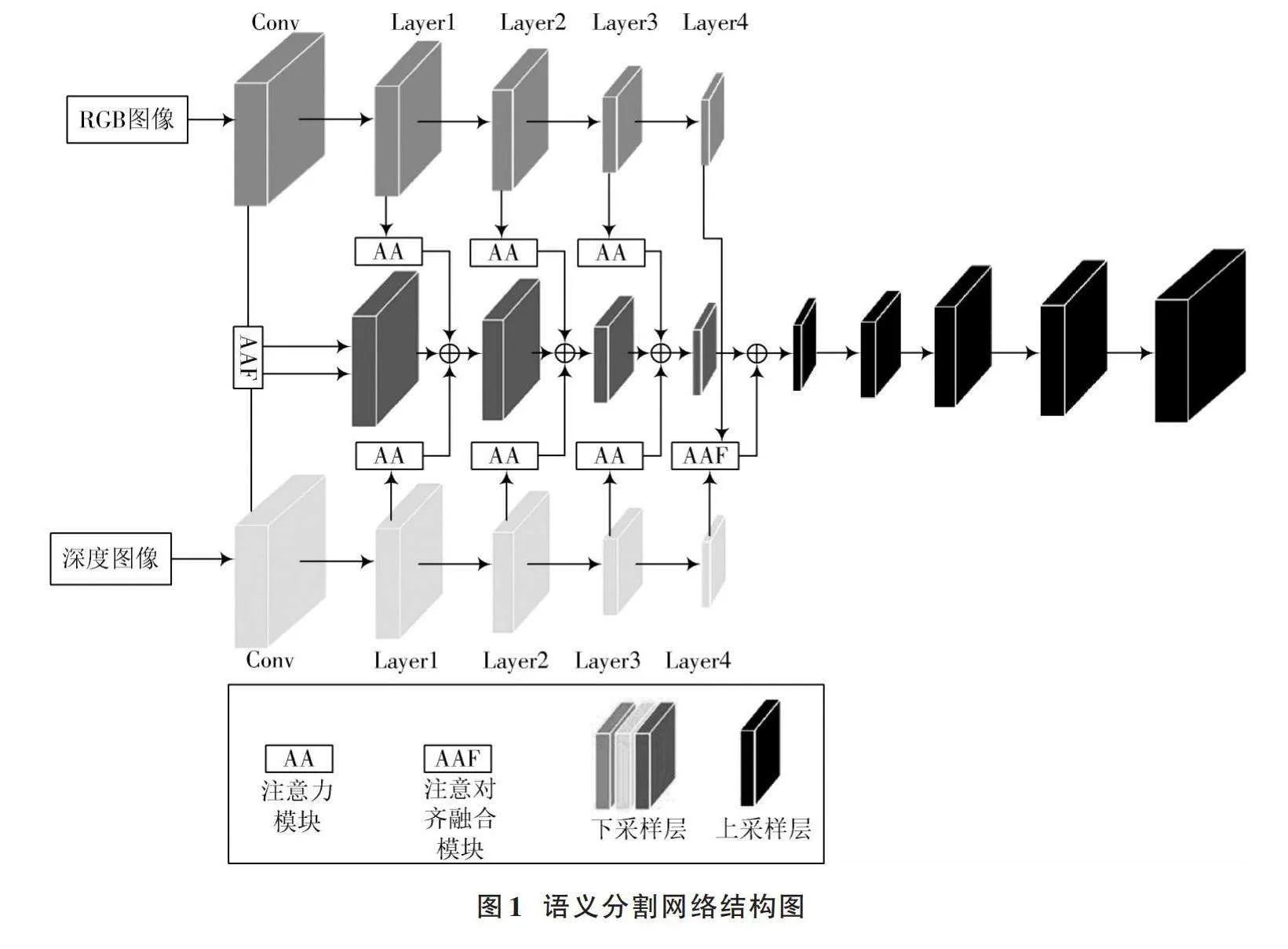
语义分割网络总体结构如图1所示。本文语义分割网络模型由编码器和解码器组成,编码器采用三个ResNet50作为独立分支[7],分别用于提取输入的RGB图像特征、深度图像特征以及处理后的融合特征;解码器用于完成分割预测,连续对特征进行上采样处理,恢复图像分辨率,产生精细的分割结果。
为进一步提高网络模型性能,本文引入注意力机制和对齐融合模块。具体做法是:在RGB图像和深度图像经过初步卷积后,将这两个特征送入如图2所示的AAF模块,借鉴光流对齐思想[8],通过定义的空间网格确定扭曲操作所需坐标,解决像素偏移和模态差异的问题,提高模型的精度和稳定性。这里扭曲对齐的RGB特征会替换为RGB分支的后续特征。RGB分支和深度分支特征经过AAF模块处理后,也作为融合分支上的初始特征输入到下一层继续进行特征提取;同时这两个分支在前三层(Layer1~Layer3)均将提取到的阶段特征送入AA注意力模块中,这样融合分支就可以在各个阶段获得优化后,携带更多有效信息的特征指导;在最后一部分网络(Layer4),两类特征再次利用AAF模块进一步去噪以及对准,三分支相加得到的最终融合特征具有丰富的语义信息。此外,三分支架构能够更好地利用深度信息和RGB信息的互补性,在有效组合RGBD特征的同时保留原始数据信息,很好地避免了特征过迟或过早融合的情况。
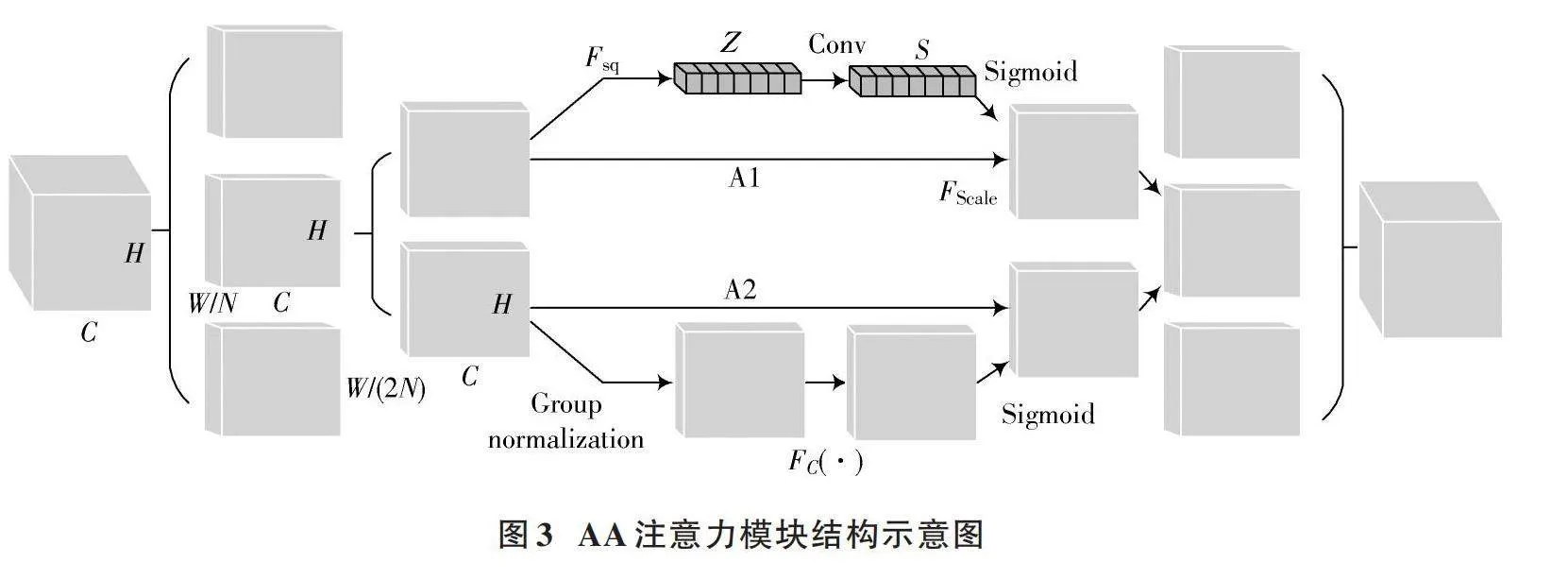
1.2" AA注意力模块
注意力机制在计算机视觉领域可以帮助模型更多地关注目标信息。考虑到在车厢部件语义分割任务中RGB图像的背景比较复杂,且深度图像存在一定程度的噪声影响,因此本文使用AA注意力模块来解决此问题,该模块的结构如图3所示。AA注意力模块首先对输入特征均分,然后对每一组特征沿同一维度再次均分,将得到的大小为[C×H×W2N]的特征在A1分支中进行Squeeze操作,对特征的通道维度全局平均池化从而获得向量Z。Conv代表卷积操作,它代替多层全连接神经网络得到对应的注意力权重,通过权重对上一步的向量Z进行处理,获得通道权重值S。本文参考了ECANet[9]中将全连接层替换为1×1卷积的操作,进行了轻量化处理。FScale代表Scale操作,是对输入特征进行按通道维度的加权,可以将注意力权重应用到输入特征中。作为A1分支的互补分支,A2分支更加关注空间信息,因此使用GN操作进行归一化,然后经过一个全连接层增强,后续的操作与A1分支基本一致。
将A1和A2分支处理后的特征拼接,最后各组特征进行通道混洗融合可得到优化特征。通过该注意力机制,模型可以同时考虑到空间和通道维度上的信息,从而更全面地理解输入数据,提高模型抵抗噪声的能力。
1.3" 对齐融合模块
错位问题需要深度图像和彩色图像之间的特征对齐,这是一个将不同模态数据转换为一个唯一坐标系的过程。光流对齐是一种广泛使用的图像配准方法,用于描述由相对于观察者的运动引起的观察目标、表面或边缘的运动。近年来,光流在计算机视觉相关任务中的应用越来越广泛,光流的概念也扩展到了语义分割中的语义流。不同在于仅依赖RGB图像的语义分割算法中只调整单模态的特征,而本文将特征对齐拓展到了RGBD语义分割网络,可以在一定程度上解决图像以及后续特征不对齐的问题。
如图4所示,对于给定的RGB和Depth特征,首先经过一个1×1的卷积层将其通道数统一,然后把两个特征图拼接到一起,再经过一个3×3的卷积提取流特征[Mflow],过程参考可变形卷积中offsets的获取[10]。[Mflow]具有两个通道,分别表示特征在坐标轴x方向和y方向上的偏移,公式如下:
[Mflow=Conv(RGB⊙Depth)," Mflow∈RW×H×2] (1)
式中“⊙”代表拼接操作。
此时就可以通过Warp操作对齐两种特征图,具体来说,首先定义[Ω]∈[RW×H×2]的空间网格,假设u、v分别是空间网格在水平和垂直方向上的整数坐标,将坐标根据输入特征图大小尺寸进行归一化处理。这里把坐标u、v归一化到[-1,1],处理后的坐标作为空间网格该位置的数值。对应关系如式(2)所示。
[Ωu,v=2u-W+1W-1,2v-H+1H-1] (2)
然后把得到的流特征偏移和定义的空间网格[Ω]相结合,可以得到新的空间网格[γ]。由于添加了流场偏移,[γ]中每个点的值均表示最终特征坐标位置。根据[γ]中坐标对应的值,最终可以生成扭曲对齐后的输出特征图,公式为:
[RGBwarped=Warp(RGB,γ)] (3)
不同模态的不对准可能导致特征在融合过程中发生不准确的特征转移,并使融合的有效性大大降低。通过将对齐融合模块集成到该模型中,减少了不同模态之间的不对齐问题,并避免了特征不均匀[11]。后续两种模态的特征可能会因为卷积、下采样和残差连接等操作导致差异扩大,对齐融合模块将按照式(1)~式(3)方法再次校准特征,以便它们可以较好地对齐。
2" 实" 验
2.1" 实验环境
本文所采用的实验平台信息如表1所示。
2.2" 数据集介绍
为了验证所提模型实际效果,制作了有关列车车厢部件的数据集,首先使用RGBD相机获得了分辨率为1 944×1 200的RGB图像和深度图像;得到两种数据后,使用Labelme对RGB图像进行标注。该数据集共包含两大类,分别是螺栓和管线,螺栓又根据形态进一步细分。自制数据集示例如图5所示。
在该研究中,确定螺栓位置、形态是为下一步松动检测做准备,确定管线位置是为了监测管线健康情况。图5最后一列图像是真值标签的图像可视化示例,框选部分分别为一类螺栓、二类螺栓、管线,黑色区域代表其他物体。
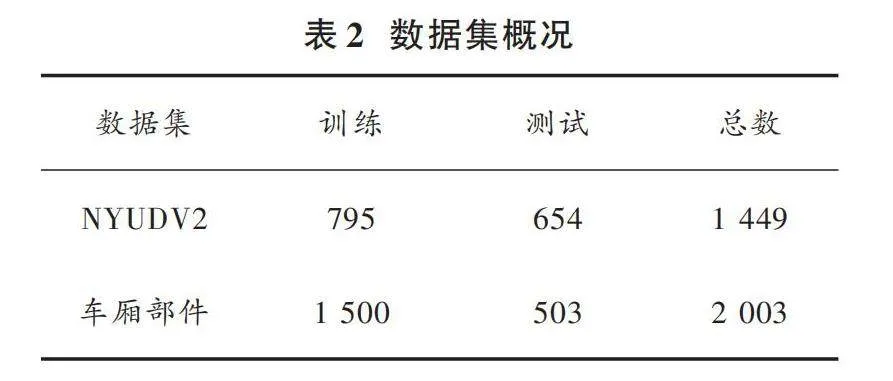
自制数据集包含2 003张已经标注的RGB图像和深度图像,其中1 500张用来训练,503张用于测试,所有图像均按照PNG格式保存。在拍摄时希望数据集里的图像尽可能还原真实现场,所以在不同角度和光照条件下进行采集。图5车厢部件数据集的部分示例,从左至右依次为RGB图像、深度图以及标签。
实验所用的公共数据集[12]为NYUDV2,该数据集包含40个小类别,由微软Kinect[13]的RGB和深度摄像机记录的各种室内场景的视频序列组成,有1 449张标注的 RGB图像和深度图像,407 024张没有标注的图像,且每个对象都对应一个类和一个实例号。实验所用数据集概况如表2所示。
2.3" 结果分析与讨论
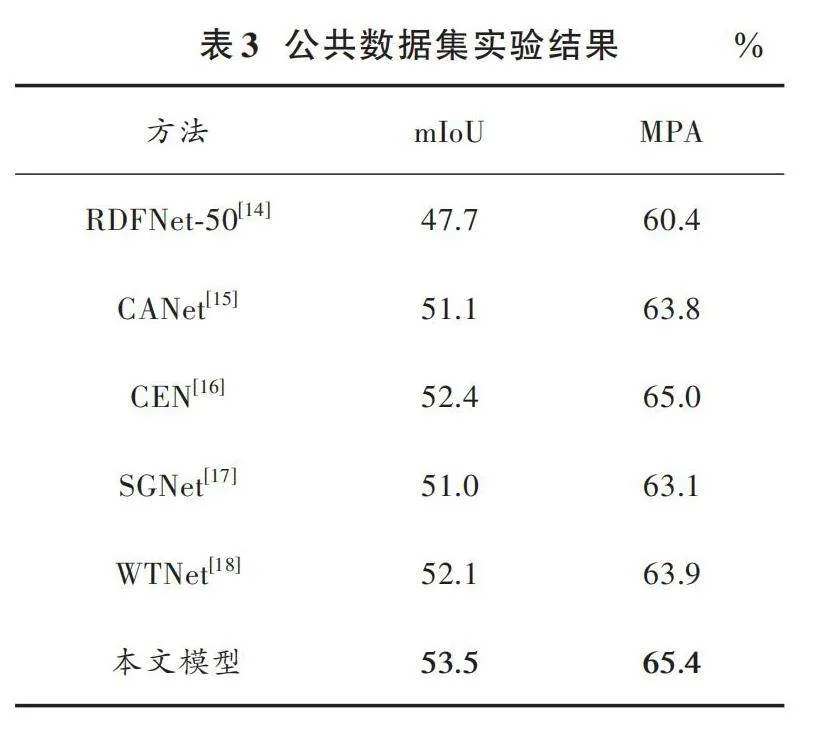
在实验环境保持一致的情况下,分别在公共数据集以及车厢部件数据集上对本文提出的方法和现有其他语义分割方法进行了比较。不同方法比较结果如表3所示。
由表3可以看出,本文所提网络在NYUDV2数据集上的指标优于大部分RGBD语义分割模型,其中使用多分支ResNet152作为主干特征提取网络的模型,例如CEN,MPA值与本文模型相近,但是本文模型采用ResNet50作为主干特征提取网络,模型参量更少、运行速度更快。
图6从左至右分别是3种不同模型在卧室、厨房、卫生间环境下的分割对比图,模型从下至上分别为RDFNet⁃50、CEN和本文模型。从这三处较有代表性的场所分割图来看,简单的融合确实无法充分利用深度图所携带的几何信息,这导致了分割的混乱,分割效果甚至有可能低于部分仅基于RGB图像的语义分割模型。本文网络提高了深度特征以及RGB特征质量,分割混乱的情况消失,被正确分类的类别增加,图6中橱柜、马桶、床铺表面的分割细节有明显改善,卧室中相框的边缘分割更加流畅精细。
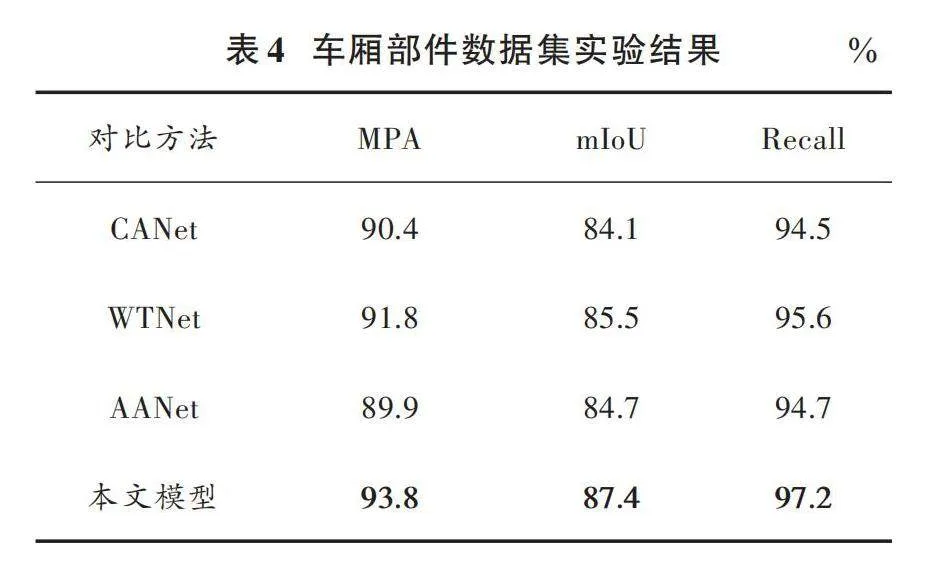
为了验证模型在实际应用环境中的表现,在车厢部件数据集上进行了相关实验,并与其他RGBD语义分割方法进行比较,结果如表4所示。由表4可知,本文方法在各项指标上均取得了最好的成绩。
图7展示了不同场景下各模型的分割效果,第1列到第4列分别为CANet、WTNet、去除对齐模块的本文模型(AANet)以及本文模型的分割可视化图像。可以看出,在车厢部件数据集中,本文方法对于实际环境里的螺栓管线分割效果良好,分类正确率高,检测到的螺栓数量更多,边缘细节也优于其他方法,分割结果更加贴合真值。本文模型在该数据集上的指标,如mIoU、MPA以及召回率均明显高于主流模型。上述结果证明了本文方法在实际任务中的有效性。
以深度数据的有无为变量,在车厢部件数据集上进行实验,证明深度分支的作用,得到的结果如表5所示。表中RGB+RGB表示将深度分支输入换成相同的RGB图像后模型不做其他改动的分割结果。通过实验可知,包含深度数据的实验组别各项指标均为最高。具体分割结果比较可视化示例如图8所示,当光线较好时,两种方法只在边缘细节上有少许差异;当光线较暗时,RGB+RGB的方法出现了分割不连续的错误情况,而本文方法取得了良好的分割效果,这是因为深度图像提供了额外的几何信息。
3" 结" 语
针对车厢部件中大量螺栓和管线难以实现高效率人工检测,且单纯基于RGB图像的深度学习算法无法适应实际任务环境的问题,本文提出了一种基于多模态数据对齐融合的语义分割算法。该算法三分支的结构可以保留原始的RGB以及深度特征,更好地指导后续的特征融合,提高模型的性能。引入的AAF模块包括注意力机制以及对齐融合模块,可以提高相关特征质量并缓解不同模态间的特征差异,增强特征对齐融合效果,实现更加精细的分割。
本文模型在NYUDV2数据集上,mIoU达到53.5%;在自制车厢部件数据集上,可以达到87.4%的mIoU以及97.2%的召回率;在实际环境尤其是较暗的环境中,该模型也可以获得良好的分割细节。
综上所述,本文模型在有挑战性的实际分割任务中具有优秀的分割效果和较好的泛化性,能够满足工业场景下的应用任务要求,有助于提升车厢部件检测的自动化水平,保障列车安全运行。
参考文献
[1] 赵冰.基于深度学习的铁路图像智能分析关键技术研究与应用[D].北京:中国铁道科学研究院,2020.
[2] HAZIRBAS C, MA L, DOMOKOS C, et al. Fusenet: incorpo⁃rating depth into semantic segmentation via fusion⁃based CNN architecture [C]// Computer Vision⁃ACCV 2016: 13th Asian Conference on Computer Vision. [S.l.]: Springer, 2017: 213⁃228.
[3] XING Y, WANG J, ZENG G. Malleable 2.5D convolution: learn⁃ing receptive fields along the depth⁃axis for RGB⁃D scene parsing [C]// European Conference on Computer Vision. Cham: Springer, 2020: 555⁃571.
[4] JIAO J, WEI Y, JIE Z, et al. Geometry⁃aware distillation for indoor semantic segmentation [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, CA, USA: IEEE, 2019: 2869⁃2878.
[5] ZHANG H Y, SHENG V S, XI X F, et al. Overview of RGBD semantic segmentation based on deep learning [J]. Journal of ambient intelligence and humanized computing, 2023, 14(10): 13627⁃13645.
[6] DESHMUKH M, BHOSLE U. A survey of image registration [J]. International journal of image processing (IJIP), 2011, 5(3): 245.
[7] HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV, USA: IEEE, 2016: 770⁃778.
[8] CHAN K C K, WANG X, YU K, et al. Understanding deform⁃able alignment in video super⁃resolution [EB/OL]. [2023⁃04⁃12]. https://www.xueshufan.com/publication/3085056143.
[9] WANG Q, WU B, ZHU P, et al. ECA⁃Net: efficient channel attention for deep convolutional neural networks [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, WA, USA: IEEE, 2020: 11534⁃11542.
[10] DAI J, QI H, XIONG Y, et al. Deformable convolutional net⁃works [C]// Proceedings of the IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017: 764⁃773.
[11] LI X, YOU A, ZHU Z, et al. Semantic flow for fast and accurate scene parsing [C]// Computer Vision⁃ECCV 2020: 16th European Conference. Glasgow, UK: Springer, 2020: 775⁃793.
[12] SILBERMAN N, HOIEM D, KOHLI P, et al. Indoor segmen⁃tation and support inference from RGBD images [C]// Computer Vision⁃ECCV 2012: 12th European Conference on Computer Vision. Florence, Italy: Springer, 2012: 746⁃760.
[13] ZHANG Z. Microsoft kinect sensor and its effect [J]. IEEE multimedia, 2012, 19(2): 4⁃10.
[14] PARK S J, HONG K S, LEE S. RDFNet: RGB⁃D multi⁃level residual feature fusion for indoor semantic segmentation [C]// IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017: 4980⁃4989.
[15] ZHOU H, QI L, HUANG H, et al. CANet: coattention network for RGB⁃D semantic segmentation [J]. Pattern recognition, 2022, 124: 108468.
[16] WANG Y, HUANG W, SUN F, et al. Deep multimodal fusion by channel exchanging [J]. Advances in neural information processing systems, 2020, 33: 4835⁃4845.
[17] CHEN S, XIANG Z, QIAO C, et al. SGNet: semantics guided deep stereo matching [C]// Proceedings of the Asian Conference on Computer Vision. [S.l.]: Springer, 2020: 106⁃122.
[18] FAN R, LIU Y, JIANG S, et al. RGB⁃D indoor semantic segmentation network based on wavelet transform [J]. Evolving systems, 2023, 14(6): 981⁃991.
猜你喜欢
中国特种设备安全(2022年5期)2022-08-26 09:19:28
四川建筑(2020年1期)2020-07-21 07:26:08
数字技术与应用(2019年2期)2019-05-14 08:25:10
减速顶与调速技术(2018年1期)2018-11-13 01:09:30
现代电子技术(2018年8期)2018-04-13 06:36:32
软件工程(2017年11期)2018-01-05 08:06:09
智能计算机与应用(2017年5期)2017-11-08 12:11:51
石油化工建设(2017年2期)2017-06-05 08:52:52
电子制作(2017年10期)2017-04-18 07:23:00
电子制作(2017年9期)2017-04-17 03:01:06
