
古汉语NLP研究现状综述(2009—2024)
2024-09-19 00:00:00劳斌彭瑶吕薇植思喆
现代信息科技 2024年13期
摘 要:文章综述了古汉语自然语言处理(NLP)领域的研究现状,特别是下游任务方面的进展。通过分析2009年至2024年的23篇相关论文,文章指出古汉语NLP面临的挑战,并探讨了包括断句与标点、分词、词性标注、命名实体识别等任务的研究方法和成果。研究发现,尽管古汉语与现代汉语在NLP任务上存在差异,但深度学习等技术的发展为古汉语文本处理提供了新途径。文章还讨论了多任务一体化研究的潜力,并对未来发展趋势进行了展望,强调了构建结构化数据集的重要性和对领域发展的促进作用。
关键词:古汉语;自然语言处理;下游任务;研究现状综述
中图分类号:TP391 文献标识码:A 文章编号:2096-4706(2024)13-0146-06
The Overview of Research Status for NLP Research in Ancient Chinese (2009-2024)
LAO Bin1, PENG Yao1, LYU Wei2, ZHI Sizhe1
(1.School of Information Science and Technology, Guangdong University of Foreign Studies, Guangzhou 510006, China; 2.School of Foreign Languages, Sun Yat-Sen University, Guangzhou 510275, China)
Abstract: This paper provides an overview of the current research status in the field of Natural Language Processing (NLP) of ancient Chinese, especially the progress in downstream tasks. By analyzing 23 relevant papers from 2009 to 2024, the paper points out the challenges faced by NLP in ancient Chinese and explores research methods and achievements including sentence breaks and punctuation, word segmentation, part of speech tagging, named entity recognition, and other tasks. The research finds that although there are differences in NLP tasks between ancient and modern Chinese, the development of technologies such as Deep Learning has provided new avenues for ancient Chinese text processing. This paper also discusses the potential of multi-task integration research and looks forward to future development trends, emphasizing the importance of constructing structured datasets and their promoting role in domain development.
Keywords: ancient Chinese; natural language processing; downstream task; overview of research status
0 引 言
随着自然语言处理(NLP)技术的持续进步,其研究视野逐渐扩展至古汉语这一中文语言的重要组成部分。古汉语作为中国传统文化的精华,蕴含了深厚的历史、文化与哲学价值,对其的研究不仅具有学术意义,也对传承和弘扬中华文化具有重要作用。尽管古汉语与现代汉语存在显著差异,带来了诸多研究挑战,但近年来NLP技术的发展为古汉语的研究提供了新的视角和方法。本文旨在全面综述古汉语NLP领域的最新研究进展,特别是下游任务方面的成果,以期为研究人员提供有价值的信息和启示。
通过在中国知网中使用“古汉语”及“分词、词性标注、命名实体识别”等下游任务作为关键词进行检索,文章收集了跨度从2009年至2024年的相关文献。经过精心筛选,共纳入23篇论文,并依据不同的下游任务对这些论文进行分类。文章首先对古汉语NLP的研究现状进行概述,然后基于发表年份和各类任务的论文占比两个维度对收集的论文进行分析,并探讨其背后的原因。最后,文章总结了古汉语NLP领域的现状和面临的挑战,并对其未来的发展方向提出展望,旨在为该领域的持续进步贡献力量。
1 古汉语NLP领域的研究现状
与现代汉语的下游任务相比,古汉语领域自然语言处理的下游任务与现代汉语基本相似。但由于古汉语与现代汉语存在着一些区别,如语言形式不同、语料库难以获取、字义歧义较多、文化背景不同等原因,因此在古汉语NLP领域的具体实现过程中存在一定的差异。在现代汉语NLP领域中,下游任务包括分词、词性标注、命名实体识别、句法分析、情感分析、文本分类、文本摘要、机器翻译等。而在古汉语NLP领域中,同样也存在这些下游任务。但是,相比现代汉语,古汉语则多出了一项下游任务,即古文断句与标点。下文按照古汉语NLP研究的先后顺序展开说明。
1.1 古汉语断句与标点
古汉语与现代汉语在句子结构和标点使用上存在差异。古汉语依赖口头传承,文学作品多用于朗诵,故标点使用较少,常采用主题述补结构,有时文字间无间隔。现代汉语则广泛应用标点符号,注重语法和意义的精确表达。尽管如此,古代汉语也有类似顿号、句号等标点,以及主谓宾、并列和复合等结构。这些差异主要源于不同的语言使用环境和需求,给后续的文本分析和理解带来了挑战。为了提升文本处理的效率和准确性,研究人员在处理古汉语的下游任务中添加了断句和标点这一项任务。
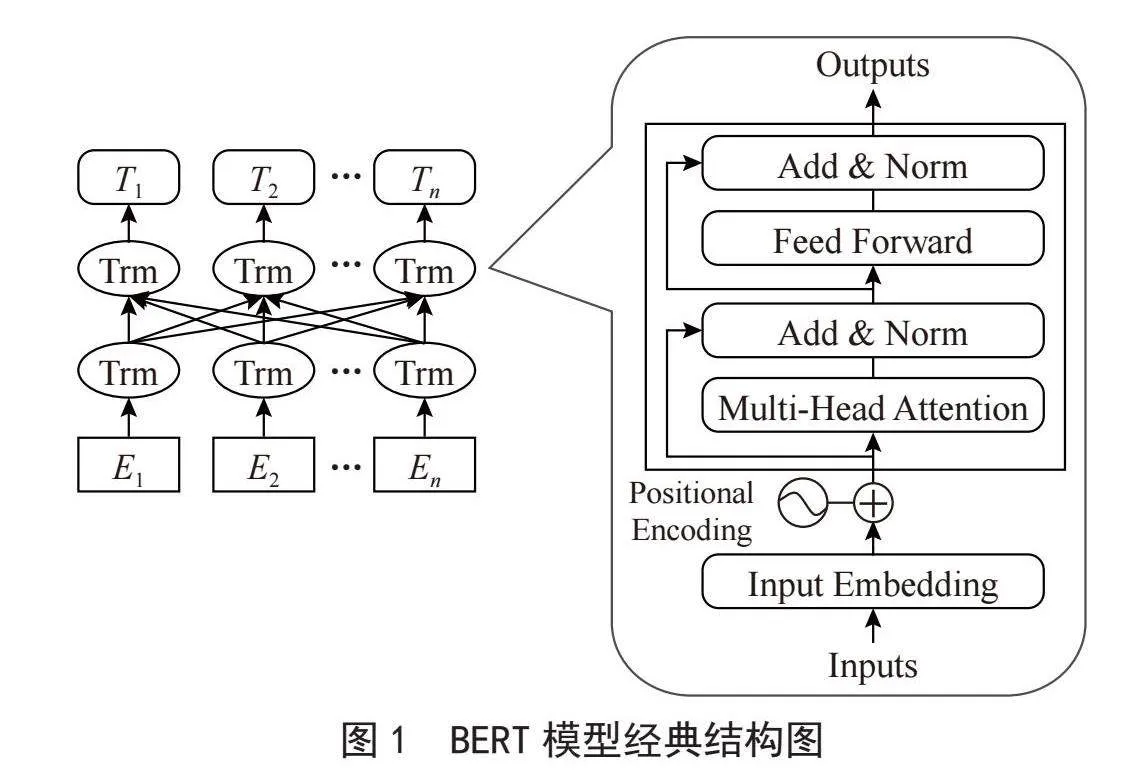
在古汉语短句与标点方面的研究中,胡韧奋等人[1]在其研究中强调断句过程中需综合语义、语境及历史文化等因素,提出了一种基于BERT预训练模型(BERT模型的经典结构如图1所示)的古汉语知识表示方法,并结合条件随机场和卷积神经网络开发了高精度的自动断句模型。王倩等人[2]利用《四库全书》作为语料库,建立了一套标注体系,并通过构建基于BERT-LSTM-CRF和多特征LSTM-CRF的层叠深度学习模型,实现了古汉语的自动断句与标点。张开旭等人[3]引入互信息和t检验作为特征,提出了一种基于条件随机场(CRF)的古汉语自动断句与标点方法。并通过在《论语》和《史记》上的实验表明,CRF方法能有效处理古文自动标点问题,且层叠CRF策略优于单层策略。
1.2 古汉语分词
中文分词是中文自然语言处理中的核心环节,其目的是将连续的文本切分成有意义的词或短语。与现代汉语分词任务相似,但古汉语具有其特殊性:古汉语中的词语多由单字或多字组成,每个字均承载特定含义。因此,在执行古汉语分词时,必须细致考量每个字的内在含义及其在文本中的关系。举例说明,现代汉语中的“可以”通常作为一个词,表示允许或可能;然而,在古汉语中,“可”与“以”是两个独立的文字,各自代表“能够”和“依靠”的意思,合在一起才构成“可以凭借”的含义。这一差异意味着,在现代汉语分词中,“可以”可能被视为一个单一词汇,但在古汉语分词中,则需将其拆分为“可”和“以”两个独立的字。因此,古汉语分词任务要求对文本进行更为细致的语义和结构分析。主要的分词方法包括基于词典、基于统计和基于理解的分词。基于词典的方法依赖于预设的词汇库,通过正向、逆向或双向匹配,并采用最大匹配、最小匹配或最佳匹配策略,以实现快速分词,但需注意歧义处理。基于统计的分词则通过大量标注数据训练模型,擅长识别未知词和处理歧义,但该方法计算成本较高,速度较慢。而基于理解的分词进一步结合了词典、统计信息和深层语义分析,以获得更高的准确度,但相应地,它在处理速度和计算资源上有更高的要求。在实际应用中,选择哪种分词算法需根据具体任务的需求和可用资源来决定。
在古汉语分词研究方面,石民等研究者[4]专注于先秦文献,尤其是《左传》的分词与词性标注研究,他们通过条件随机场模型对《左传》进行了一体化的自动分词、词性标注及分词标注实验,发现一体化分词在准确率和召回率上优于单独分词方法。高毅[5]探讨了古汉语自然语言处理技术发展缓慢的问题,并提出了一种基于双向最大匹配法则和专门训练的古汉语语料库的BERT模型,用于自动分词。唐俊等人[6]设计了一种针对古汉语的BERT预训练模型即SikuBert-CNN-CRF模型,该模型通过领域适应训练,使用大量古文语料进行无监督预训练,并结合多层CNN和条件随机场(CRF)进行古汉语分词,在实验中展现出较强的处理能力和泛化性。魏一[7]在其研究中提出一种基于大量古汉语语料的预训练模型,有效解决了句读和分词问题,还引入滑动窗口法处理连续文本,并结合无指导预训练BERT模型,实现了超越传统机器学习方法的泛化性能。刑付贵等人[8]通过整合在线古汉语资料,创建了一个含349 740个词汇的古文词典CCIDict,在对比测试中,基于此词典的分词算法比现有的甲言分词器在F值上提升了14%,验证了大型语料库构建的词典对提高古文分词准确性的效用。常博林等人[9]提出了一种融合部首信息的古汉语分词与词性标注模型,利用Radical2Vector生成部首向量,并结合SikuRoBERTa模型,通过BiLSTM-CRF结构进行实验。唐雪梅等人[10]提出了一种基于图卷积神经网络的分词框架,该框架整合预训练语言模型与图卷积网络,引入外部知识以提升分词效果。杨世超[11]对古汉语的词性和用法特征进行了细致分析,并据此创建了一套专门的词性标记系统。通过应用分布式假说理论,他实现了将古汉语文本转换为计算机可识别和处理的字词向量表示,此外,他还设计了一个高效的计算模型,显著提高了古汉语分词和词性标注任务的性能。王晓玉等人[12]通过结合CRFs模型与词典,针对中古汉语分词效率和一致性进行研究,优化了适用于史书、佛经、小说等语料的分词策略,并引入了字符分类与字典信息特征以提升分词性能。
1.3 古汉语词性标注
古汉语词性标注是将古汉语中的词汇按照其语法功能进行分类的过程,对于文本的正确解读和翻译具有基础性的重要性。鉴于古汉语中单个字可能承载多重词性,准确的词性标注显得尤为关键。古汉语的词性体系包括名词、动词、形容词、副词、介词等基本类别,其中名词用于指代人、物或概念,动词表达行为或状态的变迁,形容词描述特性或属性,副词对动词或形容词进行修饰,而介词则负责连接句子中的各个成分。此外,古汉语中还包含特殊的助动词和虚词,如“之”“乎”“矣”等,它们用于表达肯定或否定的意义,而“了”“着”等助动词则指示动作的完成或持续状态。这些词性的准确识别对于深入理解古汉语文本结构和语义具有不可或缺的作用。
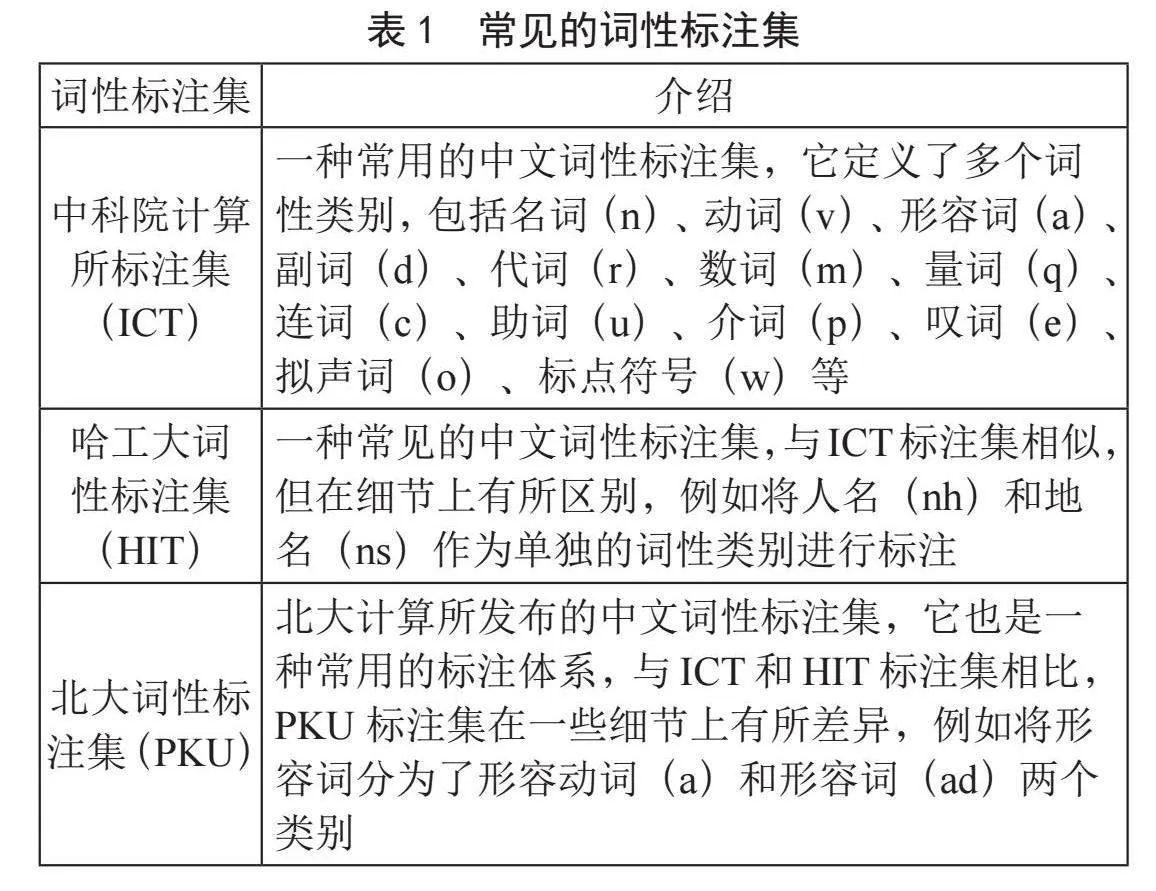
目前在词性标注集方面,现代汉语的词性标注集较为常见,如表1所示。
尽管现代汉语的词性标注集种类繁多,但它们并不适用于古汉语的词性标注任务。在广泛文献回顾的基础上,石民等人在2010年发表的论文《基于CRF的先秦汉语分词标注一体化研究》中提出了一套较为适宜的古汉语词性标注体系。近期,郑童哲恒等人[13]针对上古时期古籍的计算处理,也制定了一套古汉语分词与词性标注规范,以应对研究不足和标注规范缺失的问题,该规范涵盖7个分词原则、3个词性标注原则,并定义了14个一级词类与15个二级词类,配备了详细的标注示例。
在古汉语词性标注研究中,陈火龙[14]在其研究中针对古汉语虚词词性标注问题,构建并扩充了虚词数据集,并利用Bi-LSTM-CRF模型开发了一个标注系统。杨新生等人[15]提出了一种融合隐马尔可夫模型和维特比算法的古汉语词性标注方法,并开发了专用标记集,该方法改进了传统流程,显著提高了标注准确率,包括对未登录词的有效识别。
1.4 古汉语词法分析
古汉语句法分析旨在解析古汉语文本的语法结构及其成分间的关系。鉴于古汉语的特殊性,如文化背景和表达习惯的差异,句法分析面临诸多挑战,包括词序变化、省略、重复和修饰等复杂现象,这些都需要综合上下文信息以准确解读。目前,古汉语句法分析主要采用统计机器学习和深度学习技术,包括隐马尔可夫模型(HMM)、条件随机场(CRF)、最大熵马尔可夫模型(MEMM)、循环神经网络(RNN)等。除此之外,规则基础、图论和统计语言模型等技术也被应用于句法分析。然而,这些方法在处理特定领域或文本类型的语料库时可能存在局限,因此,需根据具体任务和需求选择合适的分析方法。
在古汉语词法分析中,程宁等人[16]在其论文中探讨了未经标点断句的古汉语文本在进行词法分析时可能遇到的多级错误传播问题,并提出了一种基于BiLSTM-CRF神经网络的一体化标注方法,通过在四个不同时代的测试集上进行实验,他们验证了该方法在古汉语断句、分词和词性标注任务上的有效性。
1.5 古汉语命名实体识别
古汉语命名实体识别技术旨在自动识别古代文本中的人名、地名和机构名等特定实体。鉴于古代汉字的命名特点,该技术通常结合规则和统计学方法进行实体初步识别与结果优化。规则方法用于识别常见部首和字词组合,而统计学方法用于处理不常见的组合和歧义纠错,同时,需考虑上下文信息和构建知识库以辅助实体的准确识别。这些方法的选择和应用需根据具体场景和需求来定。
由于古汉语命名实体识别具有很强的历史文化价值和应用前景,在自然语言处理领域得到了较为广泛的关注和研究。崔丹丹等人[17]提出了一种基于Lattice-LSTM并结合了字符和词序列信息的古汉语命名实体识别算法,并使用甲言分词工具与Word2Vec优化字词向量,相较于BiLSTM-CRF模型,识别效果有所提升。陈雪松等人[18]也发表了一种结合SikuBERT与MHA的方法,旨在解决传统方法在处理古汉语复杂结构和长序列特征时的信息损失问题。詹子依[19]则探讨了古汉语知识点自动化标注,提出了改进传统命名实体识别的新方法,结合SikuBERT和多头注意力机制,以及字词信息融合策略。李靖[20]在其研究中提出m5W9hd6NOXRohGVEc7KU3noYtGMVqVO37Otmcl4o5Zk=了SLFFN和MFFN两种模型,旨在提高古汉语命名实体识别的性能并减少标注成本。SLFFN模型融合了字-词和字结构特征,而MFFN模型在此基础上增加了字读音特征,两者均有效提升了实体识别的准确性。吴梦成等人[21]致力于挖掘先秦典籍中的植物知识,通过细致的植物词标注和分析,开发了基于CRF和深度学习的古汉语植物命名实体识别模型,旨在丰富对古代社会生活的认识。
1.6 古汉语机器翻译
古汉语机器翻译旨在将古代汉语转换为现代汉语或其他语言,面临形态、用法及含义差异等挑战。该领域主要采用结合规则和统计学方法,以及新兴的深度学习技术。基于规则的方法依赖专家规则库,具有高可解释性但覆盖面有限;统计学方法通过学习平行文本概率模型实现翻译,能自动学习但存在不确定性;深度学习方法使用神经网络处理复杂语言任务,尽管需要大量数据和计算资源,模型解释性有限,但已取得进展并有望促进文化遗产保护和历史研究。
在古汉语翻译成现代汉语的相关研究中,韩芳等人[22]开发了针对古汉语的词典模型,并整合了黎锦熙提出的句本位句法规则以构建知识库,同时应用词义消歧算法,致力于古汉语的机器翻译研究。
1.7 古诗词与古文生成
在调研的过程中,我们还注意到了一个引人入胜的领域——古诗词及古文的自动生成。这一领域利用人工智能技术,通过模拟古代诗人的创作手法,开发出能够自动生成遵循古典文学规范和形式的古诗文的自然语言处理应用。
其中,刘江峰等人[23]在其研究中针对古诗词自动生成问题,采用繁体《四库全书》及古诗词语料对gpt2-chinese-cluecorpussmall模型进行预训练,构建了SikuGPT2和SikuGPT2-poem模型。实验显示,SikuGPT2-poem在生成古诗方面取得了较低困惑度和更高BLEU评分,且人工评分优于基准模型。尽管模型通过图灵测试表现良好,但受限于预训练语料的规模,对赋、曲等体裁的适应性仍有待提高。
1.8 研究总结
在自然语言处理(NLP)的领域中,古汉语与现代汉语的比较研究由于其复杂性和边缘性,目前尚未成为研究的主流。因此,该领域各个下游任务的论文相对较少,难以直接比较优劣。导致这一现象的原因包括古汉语与现代汉语在语法、词汇和句式上的显著差异,这为直接比较分析带来了挑战。此外,古汉语的语料库不仅规模较小,而且难以获取高质量的标注数据,这对机器学习模型的训练和验证构成了障碍。尽管现代汉语作为活语言在社会、文化、经济等多个领域中应用广泛,吸引了大量的研究兴趣和资源,但古汉语的NLP技术发展还处于初级阶段。古汉语研究需要语言学家、历史学家和计算机科学家等多学科专家的合作,这种跨学科合作的难度较大。同时,NLP的下游任务在古汉语上的应用研究还不成熟,缺乏足够的实证研究来评估其效果。古汉语文本所蕴含的深厚文化内涵和历史背景,也给现代技术理解和处理这些文本带来了障碍。尽管面临诸多困难,古汉语与现代汉语的比较研究具有重要的学术价值和潜在的应用前景,随着技术的进步和跨学科合作的深入,未来有望产生更多高质量的研究成果。
2 分析与评述
本章根据收集到的文献从两个维度进行整理,分别是相关论文历年发表数量和各个下游任务的论文占比。以下将从这两个维度进行详细分析。
2.1 相关论文历年发表数量
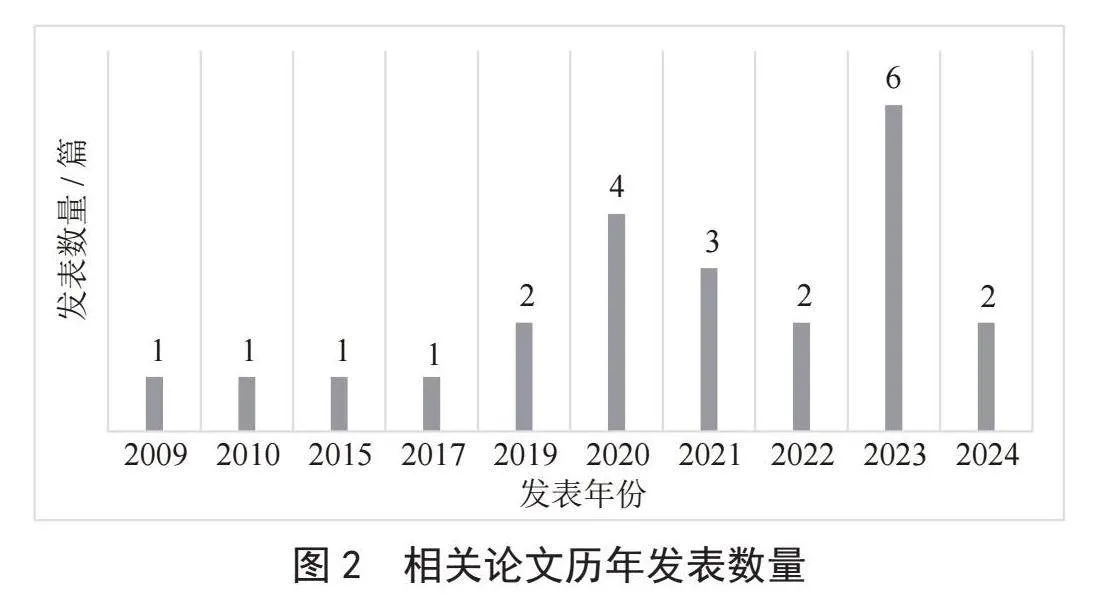
相关论文的发表年份与发表数量的关系如图2所示。通过分析图2所示的柱状图,可以清晰地看到古汉语与自然语言处理下游任务相关研究论文的发表趋势随时间的变化情况。在该柱状图中,横轴代表发表年份,纵轴代表论文发表数量,数据按非连续的年份进行展示。从图中可以明显观察到,在2020年之前,相关领域的论文发表数量较为有限。然而,进入2020年,这一领域的研究论文发表量开始急剧上升,与2009至2019年这十年间相比,研究的热度和成果产出显著增加。
图2 相关论文历年发表数量
这一显著的增长趋势可以归因于多个因素。首先,技术的进步尤其是深度学习和大数据技术的发展,为古汉语文本的处理提供了强大的技术支持,这些技术的发展极大地提高了研究者处理古汉语文本的能力,使得研究工作更为深入和精确;其次,随着数字化进程的加速,大量古汉语文献被数字化并公开,为自然语言处理模型的训练和测试提供了丰富的数据资源,从而推动了研究工作的深入;最后,跨学科合作的兴起也为古汉语智能处理研究带来了新的活力,计算机科学、语言学、历史学等多学科的融合,为研究者提供了新的视角和解决方案,促进了创新和探索。以上几个因素相互作用,共同促进了古汉语智能处理研究的发展。
2.2 各个下游任务的论文占比
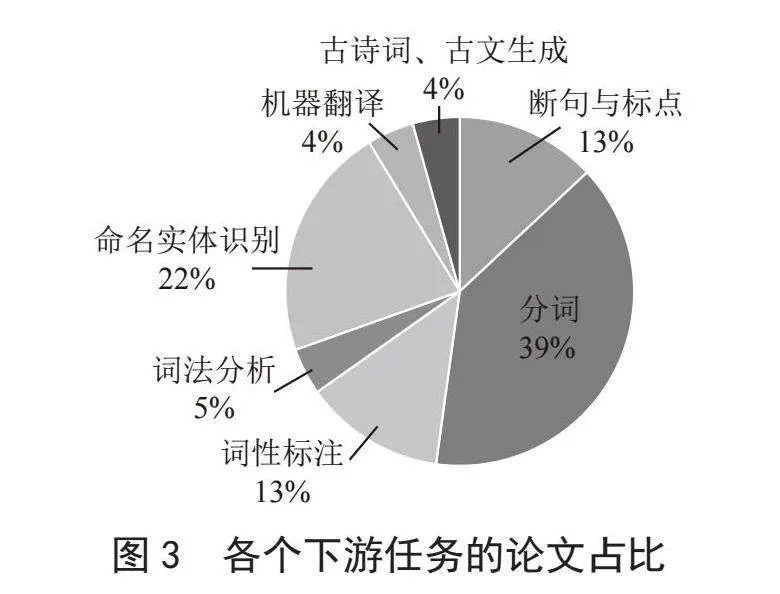
从图3数据可以清晰地看到,分词任务在古汉语研究论文中占据了显著的比重,紧随其后的是命名实体识别任务。相对而言,词法分析、机器翻译以及古诗词和古文生成等任务的论文比例较小。在古汉语领域的自然语言处理研究中,分词任务和命名实体识别(NER)相关的论文数量占据了较大比例,这主要是因为分词作为基础性任务对后续处理工作至关重要,尤其是在古汉语这种缺乏明显词间分隔的语言中,而命名实体识别则因其在提取关键信息和理解文本内容方面的实际应用价值而受到重视。相比之下,词法分析、机器翻译和古诗词古文生成任务的论文数量较少,这是由于它们在古汉语处理上的复杂性和挑战性较高,以及相对于分词和NER,它们可能获得的研究资源和学术关注较少。因此,研究者们在古汉语智能处理的研究中,更倾向于关注那些能够为理解古文本提供直接帮助的基础任务和技术。
在自然语言处理的研究中,除了对单一下游任务进行深入探讨,一些研究者开始尝试将多个任务整合,开展一体化的研究。例如,程宁等人[16]将断句和词法分析任务结合起来,进行了联合研究,而常博林等人[9]则针对分词和词性标注任务进行了类似的一体化探索。这种多任务联合的创新研究方法,在实验中已经展现出了积极的成效。展望未来,多任务一体化的研究路径无疑值得进一步探索,它有潜力为自然语言处理领域带来更为全面和高效的解决方案。
3 结 论
目前,在古汉语NLP领域中的下游任务方面,除了分词、断句与标点、命名实体识别等几个热门任务的研究成果比较多之外,其他几个下游任务的研究较少,目前还存在较多的空白。出现研究空白的主要原因是这些任务需要依赖前置任务的研究进展,而前置任务的研究还需要更多的努力和时间。在数据集方面,原始语料也并不难获取,但是根据各个具体的下游任务而做出不同处理的结构化数据集极其缺乏。因为这样的结构化数据集需要与古汉语相关专业的从事人员或研究人员进行标注,代价极大。这也是古汉语NLP领域中的科研人员需要面临的重大问题。而该问题若得不到解决,会极大地阻碍古汉语NLP领域的发展。因此,解决这些问题对于古汉语NLP领域发展来说至关重要。只有不断努力和持续投入,才能够进一步拓展该领域下游任务研究的广度和深度,并建立起更加完善和可靠的数据集等基础设施。
参考文献:
[1] 胡韧奋,李绅,诸雨辰.基于深层语言模型的古汉语知识表示及自动断句研究 [J].中文信息学报,2021,35(4):8-15.
[2] 王倩,王东波,李斌,等.面向海量典籍文本的深度学习自动断句与标点平台构建研究 [J].数据分析与知识发现,2021,5(3):25-34.
[3] 张开旭,夏云庆,宇航.基于条件随机场的古汉语自动断句与标点方法 [J].清华大学学报:自然科学版,2009,49(10):1733-1736.
[4] 石民,李斌,陈小荷.基于CRF的先秦汉语分词标注一体化研究 [J].中文信息学报,2010,24(2):39-45.
[5] 高毅.基于BERT预训练模型的古汉语自动分词方法研究 [J].电子设计工程,2021,29(22):28-32.
[6] 唐俊,高大贵,陈铭萱,等.一种基于预训练的古汉语分词模型 [C]//2022中国自动化大会.厦门:中国自动化学会,2022:730-735.
[7] 魏一.古汉语自动句读与分词研究 [D].北京:北京大学,2020.
[8] 邢付贵,朱廷劭.基于大规模语料库的古文词典构建及分词技术研究 [J].中文信息学报,2021,35(7):41-46.
[9] 常博林,袁义国,李斌,等.融合部首信息的古汉语自动分词与词性标注一体化分析 [J/OL]. 数据分析与知识发现,2024:1-17(2024-01-09).http://kns.cnki.net/kcms/detail/10.1478.G2.20240108.1326.002.html.
[10] 唐雪梅,苏祺,王军,等.基于图卷积神经网络的古汉语分词研究 [J].情报学报,2023,42(6):740-750.
[11] 杨世超.古汉语分词与词性标注方法研究 [D].唐山:华北理工大学,2018.
[12] 王晓玉,李斌.基于CRFs和词典信息的中古汉语自动分词 [J].数据分析与知识发现,2017,1(5):62-70.
[13] 郑童哲恒,李斌.上古汉语分词与词性标注加工规范——基于《史记》深加工语料库的标注实践 [J].语言文字应用,2023(4):93-104.
[14] 陈火龙.基于Bi-LSTM-CRF的古汉语虚词词性标注系统 [D].武汉:华中科技大学,2019.
[15] 杨新生,胡立生.基于隐马尔科夫模型的古汉语词性标注 [J].微型电脑应用,2020,36(5):130-133.
[16] 程宁,李斌,葛四嘉,等.基于BiLSTM-CRF的古汉语自动断句与词法分析一体化研究 [J].中文信息学报,2020,34(4):1-9.
[17] 崔丹丹,刘秀磊,陈若愚,等.基于Lattice LSTM的古汉语命名实体识别 [J].计算机科学,2020,47(S2):18-22.
[18] 陈雪松,詹子依,王浩畅.融合SikuBERT模型与MHA的古汉语命名实体识别 [J].吉林大学学报:信息科学版,2023,41(5):866-875.
[19] 詹子依.面向古汉语领域的命名实体识别 [D].大庆:东北石油大学,2023.
[20] 李靖.基于特征融合与数据增强的古汉语命名实体识别研究 [D].长春:吉林大学,2023.
[21] 吴梦成,林立涛,齐月,等.数字人文视域下先秦典籍植物知识挖掘与组织研究 [J].图书情报工作,2023,67(12):103-113.
[22] 韩芳,杨天心,宋继华.基于句本位句法体系的古汉语机器翻译研究 [J].中文信息学报,2015,29(2):103-110+117.
[23] 刘江峰,刘雏菲,齐月,等.AIGC助力数字人文研究的实践探索:SikuGPT驱动的古诗词生成研究 [J].情报理论与实践,2023,46(5):23-31.
作者简介:劳斌(1985—),男,汉族,广东广州人,讲师,博士,研究方向:数字人文;通讯作者:彭瑶(1999—),男,汉族,广东揭阳人,硕士研究生在读,研究方向:数字人文。
