
预训练大模型在油气领域的价值场景、挑战及未来方向
2024-09-19 00:00:00陈宏志宫本儒王笑妍林秀峰孙加峰
现代信息科技 2024年13期


摘 要:对机器学习、深度学习、知识工程等为代表的判别式人工智能和以GPT、Sora等为代表的生成式人工智能的特点、技术现状和应用能力边界进行了研究,系统地比较了判别式人工智能与生成式人工智能的背景、技术原理、技术特点,分析了当前AIGC的技术现状、瓶颈,总结了生成式人工智能(AIGC)进一步推动AI赛道进入快速发展期的原因,并对未来一段时间内,AIGC在油气工业领域的应用趋势、难点进行了分析预测。
关键词:生成式人工智能;油气纵深;潜在应用需求
中图分类号:TP391;TP38;TE9 文献标识码:A 文章编号:2096-4706(2024)13-0129-07
Value Scenarios and Challenges and Future Directions of Pre-trained AI Big Model in the Oil and Gas Field
CHEN Hongzhi1, GONG Benru1, WANG Xiaoyan1, LIN Xiufeng1,2, SUN Jiafeng3
(1.Research Institute of CNPC Kunlun Digital Intelligence Technology, Co., Ltd., Beijing 102206, China; 2.School of Information, Renmin University of China, Beijing 100872, China; 3.Inner Mongolia Branch of China Mobile Communications Group Co., Ltd., Hohhot 010000, China)
Abstract: This paper researches the characteristics, current technological status, and application capability boundaries of Discriminative Artificial Intelligence represented by Machine Learning, Deep Learning, and Knowledge Engineering, as well as AIGC represented by GPT and Sora. It systematically compares the backgrounds, technological principles, and technological characteristics of Discriminative Artificial Intelligence and AIGC, analyzes the current technological status and bottlenecks of AIGC, and summarizes the reasons for Artificial Intelligence Generated Content (AIGC) to further promote the rapid development of the AI industry. Furthermore, it analyzes and predicts the application trends and difficulties of AIGC in the oil and gas industry in the near future.
Keywords: AIGC; oil and gas depth; potential application need
0 引 言
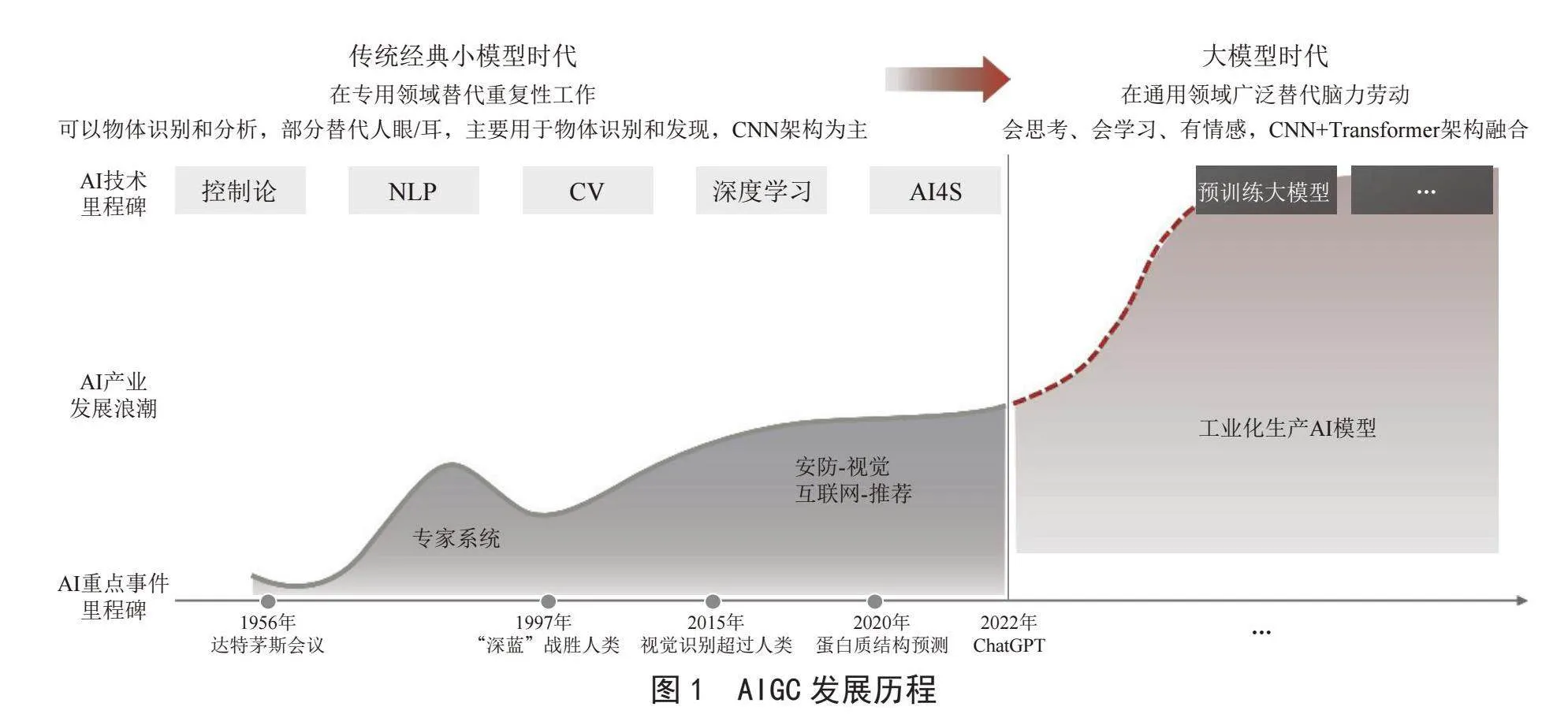
过去数十年间,基于机器学习、深度学习、知识工程等在内的判别式人工智能(AI)技术,以可训练、可持续提升等类脑行为能力,在自动化数据采集、状态监测、模式分类与识别、预测/预防性维护、协同优化求解等工业领域场景中,得到了更广泛的应用[1]。同时,在油气工业应用方面,通过开放式创新和产学研深度融合的模式[2],建立了诸如“道达尔+谷歌云”“雪佛龙+微软”等跨界组合,聚焦协同工作环境、智能井、生产实时优化、智能油藏管理等,加速了人工智能在油气工业纵深领域的应用探索,形成了上下游决策自动化、井筒钻探数据处理、智能化地震成像处理、智能压裂等贯穿油气纵深的AI应用,为油气工业的数据分析效率提升、勘探评价能力升维、实时预测与决策、开放生态环境构建等方面,实现了价值创造。
2022年末,随着OpenAI发布ChatGPT,基于Transformer架构的大规模预训练模型的生成式人工智能(AIGC)技术,进一步推动了人工智能从点状应用进一步向具备多场景泛化能力的通用人工智能(AGI)发展[3]。从基于键盘-鼠标的人机交互向基于自然语言的人机交互模式发展,使能更多非专业用户可参与到模型的训练、调优和应用建设中,进一步加快了普通终端用户对人工智能的接纳。同时,基于大规模数据对模型的预训练,形成在自然语言与语义理解、上下文衔接、多轮对话、动机和意图分析、内容生成等方面能力的强化,使基于大模型生成内容的数据服务在搜索、客服、机器翻译、代码编写、情感计算、流程自动化等应用场景的表现,得到了更为显著的提升[4]。从ChatGPT [5]的发布开始,国内生成式大模型(LM)的数量快速增长,模型更新速度缩短至每月级别[6],百余家企业和知名学术机构包括文心一言、通义千问、星火等百余家不同规模的企业、学术机构发布了自己的LLM [7]。同时,通过引入思维链(COT)[8]、提示工程[8]、LoRa [9]、LangChain [10]等创新的模型训练方法和微调框架,结合LLM带来的人机交互模式的转变,一方面进一步简化了LLM的训练和微调程序;另一方面,也使能更多的低阶开发者具备调试与应用LLM的能力。这进一步加速了AIGC大模型产业的迭代速度。
2024年初,OPENAI发布视频生成大模型Sora [11],支持通过自然语言人机交互,生成最长60 s的视频,实现了生成式人工智能从支持图片、语言等单一模态,向基于语音、文字、图像、视频流融合的多模态交互的变革,模型能力和应用想象空间实现了跃迁。
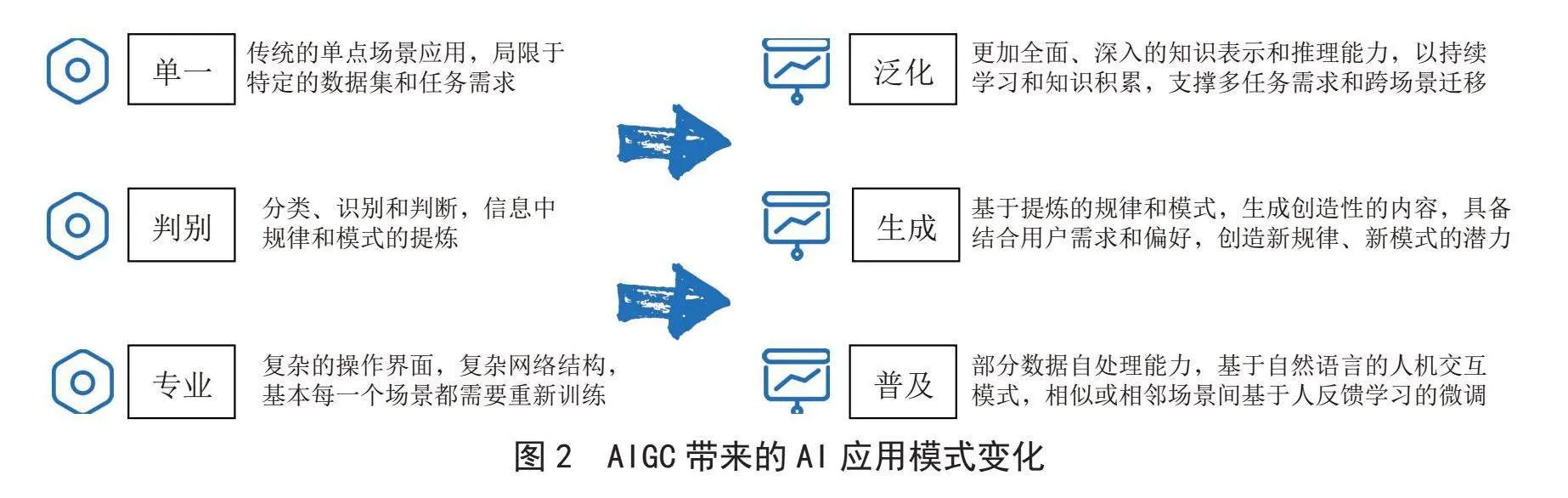
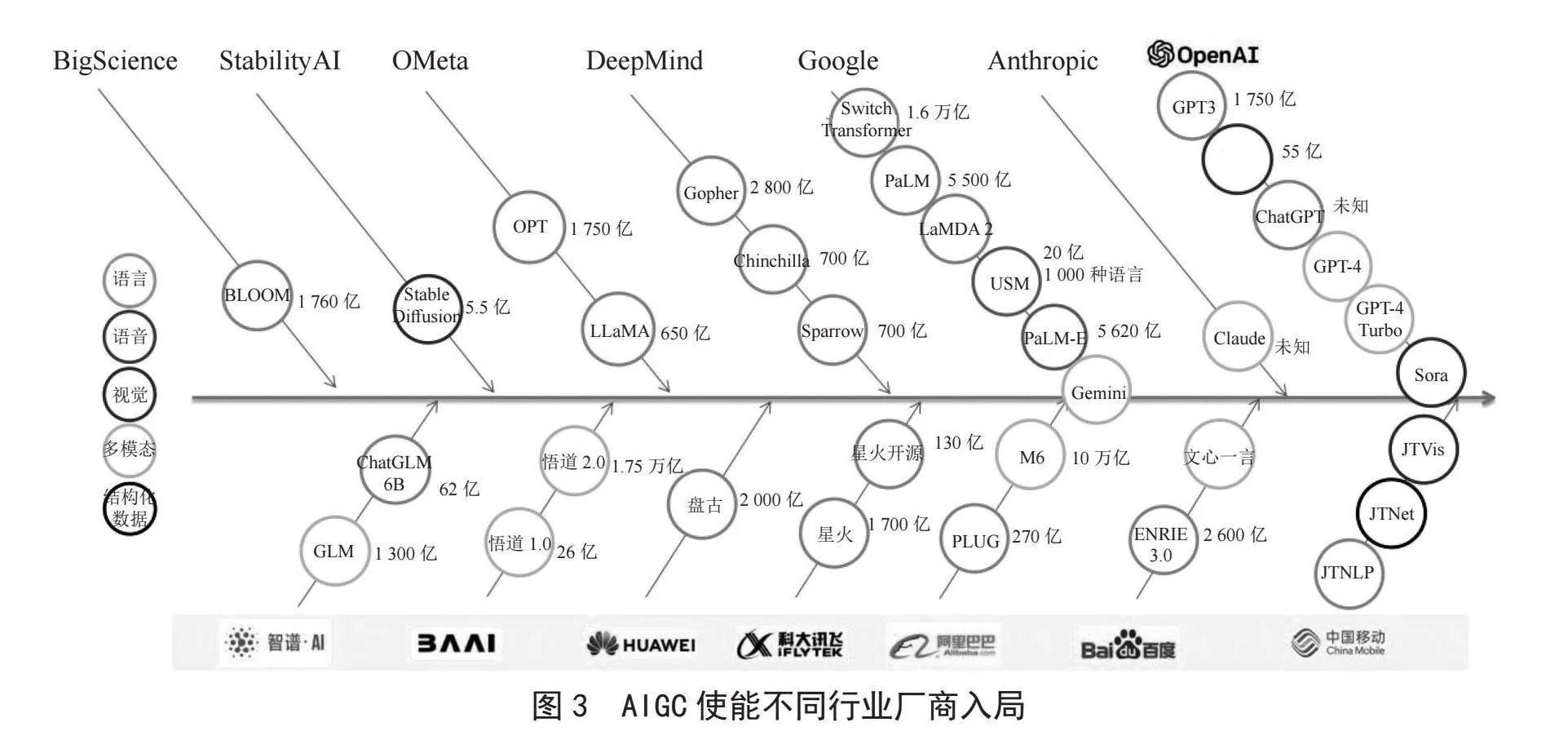
如图1~3所示,人工智能技术经历了典型的“厚积薄发”过程,从早期的单一场景、小数据,到AIGC时代的多场景可泛化,呈现出了迭代时间逐渐缩短;应用模式更加普及;准入门槛逐步降低,竞争快速进入“红海”的态势。
结合预训练生成式人工智能大模快速发展趋势,文章从LM的特点,当前的应用现状,典型应用场景,应用难点以及未来能源工业人工智能应用展望等几个方面,分析了LM与油气行业数智化的结合点、应用模式以及未来的发展潜力。文章主要分为下述6个章节:第1节讨论预训练大模型的技术特点,人工智能技术在油气工业领域的现状及局限;第2节阐述预训练大模型的特点、背景和截至目前的能力边界;第3节结合油气行业数智化需求,从数据、算力、算法、应用层面讨论大模型在油气行业的应用场景和实现大模型落地应用的关键约束。第4节结合应用现状,展望如何通过大模型与各类数智化应用技术结合,进一步提升油气行业数智化水平。第5节结合当前应用情况,讨论LM在油气工业应用中的主要挑战。在第六节,结合全文讨论与分析,给出了作者团队对未来AIGC应用的展望。
1 判别式人工智能在油气工业的应用现状及局限
人工智能以其对声,光,电,图,表,文等多模态数据可学习,可提炼,可迭代的特点,近年来为能源工业界的测录井解释,钻井安全风险识别,过程工艺协同优化,装备及过程工业数字孪生,数据采集与数据处理等场景中,实现了高效数据采集与内容提取,多模态数据融合,特征工程与模式分类,过程控制与决策自动化,为能源工业的增储上产,降本增效、“双碳”转型、客户引流与促销增收以及数智技术国产化替代提供了新的探索[1-2,12-16]。但判别式机器学习与深度学习存在的应用点单一,训练过程烦琐,不具备泛化能力,部署工程量大[17],后服务投入成本高,对每个单一场景互斥等局限,导致AI应用难以实现标准产品化和原生化,具体表现在:
1)对任何场景,在初始阶段,均需从数据准备开始,经历完整的模型训练,测试,部署过程,跨场景不可复制,迁移训练过程的工作量不亚于重新训练。
2)对于每一个孤立的场景,需要大量针对细节详细标注的优质数据作为训练和测试集,以确保所提供的模型,符合该场景的需求。这带来了大量的前期工作量,且该工作量对于跨场景、私域应用而言,实际上具有不可复用性。
3)在模型完成训练后,其部署过程需要专业的工程人员完成,现阶段,主要厂商为加速推动AI能力在垂直场景中的落地,均配套推出了对应的工程化训推一体平台,如华为Modelart [18],用友BIP-AIWorkshop [19],亚马逊AWS-Sagemaker [20],阿里PAI和Modelscope [21]等,但现阶段,其作用局限于降低工程部署工作量,对工程师的专业度要求并未降低。
4)在模型正式上线后,由于使用者多为非专业人员,随场景数据的细微变化,模型易出现参数漂移,对于需要完全在自有IDC中进行私有部署的企业用户而言,其后服务运营的时效性也难得以有效保障,特别是对于油气生产经营等典型的连续流程工业,在工作流程不可轻易中止的前置条件下,对AI应用解决方案的植入带来了更高的门槛。
5)上述因素综合作用下,判别式AI在现阶段的落地应用,更多地聚焦在数据采集、数据组织、模式识别等具有确定解、不侵入具体工作流程的场景,对于决策优化、多轮人机交互等具备一定模糊或灰度属性的场景应用相对较少。
2 预训练大模型背景、技术特点
预训练大模型指基于大量预先标注数据(PB级别数据量,或万亿级别自然语言token,或超过千亿像素的图像数据集,或以上三者联合),训练的具有亿级以上参数规模的深度网络。现阶段,基于Transformer架构[22]的大参数预训练深度神经网络成为当前生成式人工智能大模型(LM)采用的主要骨架。得益于Transformer提出的基于注意力机制的创新架构,当模型参数达到或超过一定规模后,LM具备信息采集和组织、语义理解、内容生成等涌现技能[23],上述技能使LM可在多轮人机交互、上下文语义理解、自动化意图拆解、基于问答的增强式信息检索(RAG)、多模态内容创作[11]等方面,更好地理解人类意图、扩展情感计算深度,实现更好的人机交互。此外,基于海量预处理数据,围绕多类场景问题求解,训练的具备场景泛化、内容生成、人机交互等能力的大规模预训练模型,具备在原有基础上进行增量训练和通过少量数据微调后,满足特定场景需求的能力。这不仅使LM具备了一定的持续学习和积累能力,而且为AI落地应用过程中的持续运营问题,提供了进一步的可行性。
此外,通过引入前述基于思维链的提示工程(如图4所示),一方面进一步简化了LM的训练和微调程序;另一方面,也使能更多的低阶开发者具备调试与应用LM的能力,这进一步加速了AIGC大模型产业的迭代速度。
但与此同时,生成式人工智能带来的幻觉,推理和预测过程的不可解释问题,导致LM的生成内容不稳定,易出现错误答案,甚至出现类似图5所示“幻觉”等具有一定逻辑性的错误引导,从而带来系列次生的隐私、安全及道德伦理风险[24]。
3 大模型在垂直行业的应用现状
在ChatGPT发布后,生成式LM在多个不同的场景中得到了落地实践,Miranda [25]等通过AIGC实现复杂音乐生成,基于自研的DisCoCat框架,结合LM实现了可解释的音乐合成,并尝试了在量子芯片上的部署。在通信领域,国内主要通信运营商与学术机构及头部互联网公司合作,围绕通信行业的开发、运维、营销、计费、客服、客户关系管理和商业智能等直观的价值场景,建设通信行业大模型TelecoGPT,实现智能网络规划、智能网络维护,智能网络优化与运营,显著降低人员工作负载[26]。在司法领域,LM被证实可用于图像识别、法律援助助手生成以及法律文案生成方面可为人工工作提供较大的帮助[27]。在搜索推荐和销售转化领域,针对推荐与搜索领域最核心的用户标签问题,通过多智能体系统,提示工程与GPT3.5的结合,建设了自动标签系统[28],进一步降低了推荐系统用户打标的业务门槛,为众创模式的应用提供了可行性。
综上,现阶段,生成式人工智能大模型更多聚焦在系统容错较好、C端场景或2B的客服、销售等外围类场景进行系列先导应用[29]。同时,为确保提供可信安全的生成式数据服务,可解释的内容生成,成了现阶段各类研究和应用的重点突破方向。为进一步降低AIGC的应用门槛,通过结合多智能体系统、分布式融合策略框架[30]等外挂框架,融合预训练基础大模型已积累的能力,实现AIGC与真实应用场景更迅速地融合。
4 在油气工业应用大模型的主要挑战
油气工业数智化应用,具有低容错、强机理、极限工况、连续生产、跨学科交叉幅度大等流程工业的共性特点,这些特点,对LM在该领域的应用,也带来了一定的挑战,具体表现有以下几点。
4.1 场景洞察难
石油天然气工业数智化场景覆盖了从采集、分析、控制、呈现、决策等产业链,但在实际场景应用上,是否真正具备价值机会,以及如何实现可量化的商业价值评判,是技术、经验、商业模式、交付能力、生态等方面共同作用的结果,洞察难度大,试错成本高。
4.2 数据获取与治理难
能源工业具有典型的自然垄断特性,在多个场景下,支撑多种大模型应用,需要足量的高品质数据资产支撑。这些数据资产覆盖范围广、数量大、质量不一致,需要完备的数据存储、治理、传输、表征和应用链路,以保证数据资产的全链路可靠。但此类数据资产,多为私域,存在数据获取渠道和获取可行性上的限制。
4.3 跨专业语言对齐难
在油气等垂直领域应用大模型,涉及勘探、开发、生产、营销、运营等多种不同专业。不同专业之间的知识体系和价值逻辑均不尽相同,跨专业间的术语、专业知识、业务模式等复杂体系,亟须统一模式进行对齐。此外,对于同类专业内部,终端用户的业务专业语言与开发者之间技术语言之间的对齐,同样也存在需平复的沟壑。这些现象,对系统设计和应用开发,都带来了大量技术以外的挑战。
4.4 应用构建与集成难
企业业务信息系统,包括ERP、MES、SCM、SRM、CRM、HRM等,均以“流程驱动为主、数据和模型驱动为辅”。仅依靠大模型独立提供服务,需与现有业务系统及流程难以实现对接。对于不同系统之间、诸如API、中间件、数据库、消息队列、安全等各类不同接口均需要予以考虑,集成交付难度大。此外,跨多个分布式系统,带来的组织、角色、权限统一管理与数据资产安全应用问题,为大模型应用的嵌入,带来了不确定性。
4.5 结论解释难
在技术方面,生成式人工智能目前仍基于transformer架构,典型黑盒编解码架构使推理预测过程不可解释。在业务方面,AIGC提供的数据服务,存在生成幻觉、错误引导等风险,需要通过具有业务属性的结果解释,以满足终端用户的理解与使用要求。
4.6 工程部署难
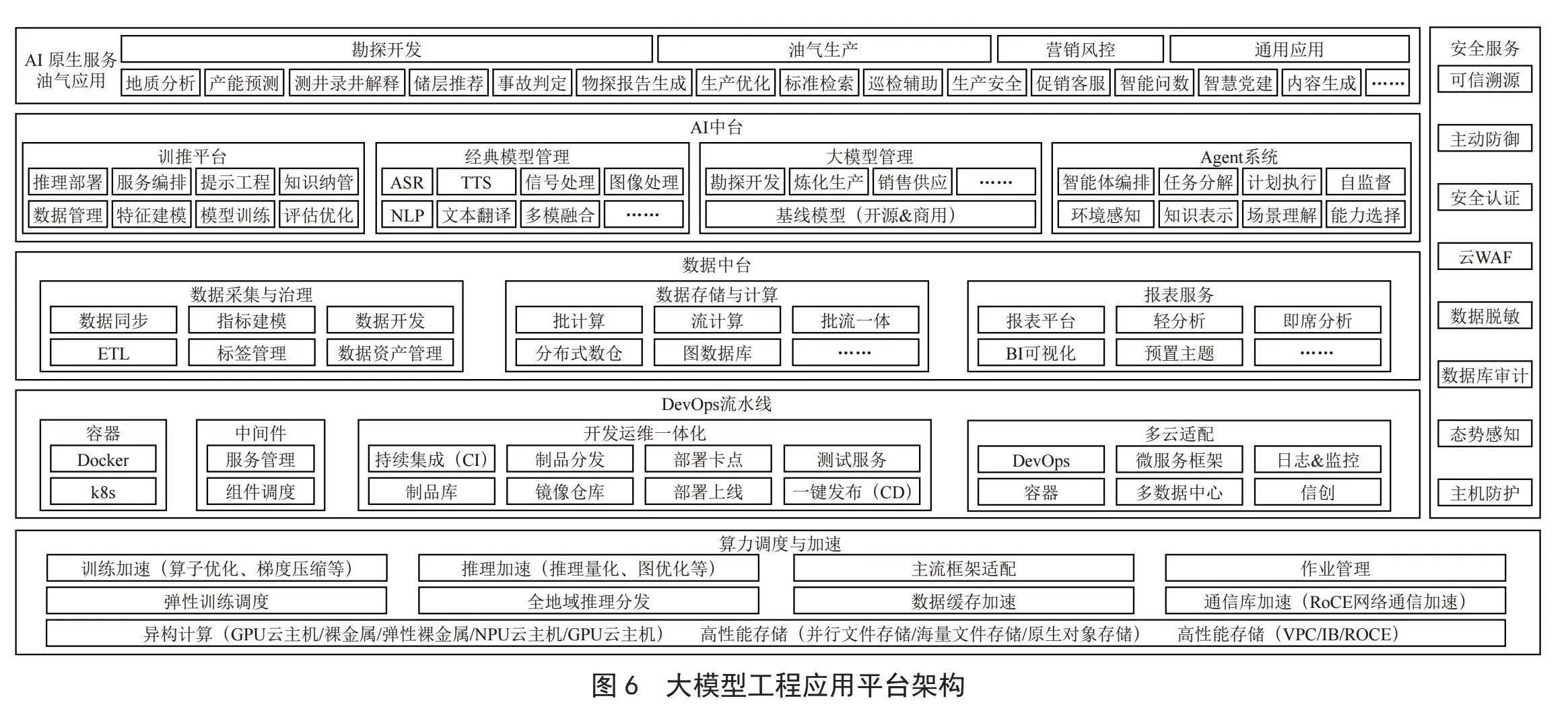
如图6所示,LM的部署需要完整的CI/CD和DevOps流水线进行支撑;统一数据治理平台,实现全链路数据开发与治理一体化;训推一体化AI中台支持模型训练、推理和持续优化;针对AIGC模型与业务系统的衔接,需要基于Agent的智能体集群,实现承上启下和基于提示工程的持续优化。以上几方面的能力建设,需要跨组织、跨学科、跨领域的协作执行。
5 大模型在油气领域未来应用方向的思考
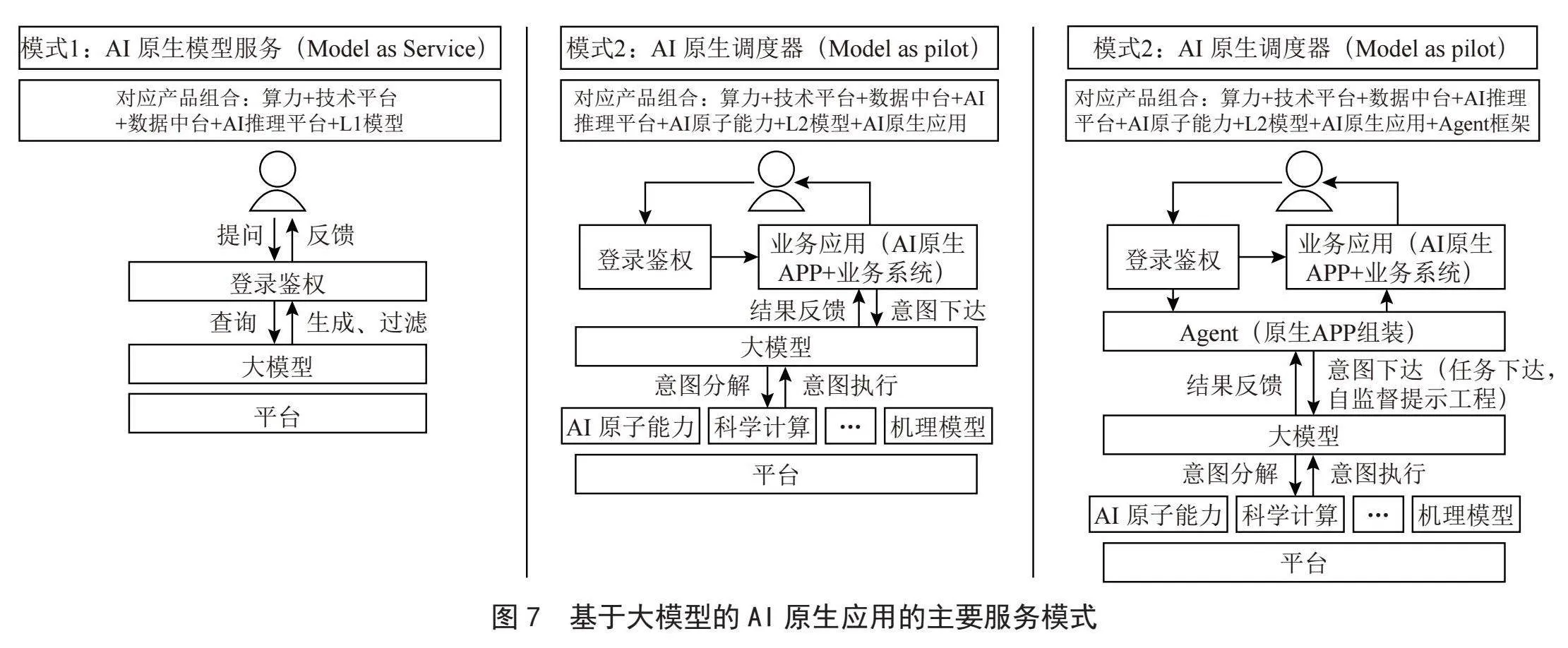
在流程工业场景中,基于大模型的主要应用形态如图7所示,包括AI模型原生服务(Model as Service(MAS)),AI原生调度器(Model as pilot (MAP)),可组装应用(Model as applications (MAA)),三种模式与业务系统的嵌入逐级加深,理论上,其对油气行业数智化的潜在价值也是逐级加深。三种模式分别定义如下:
1)MAS。以大模型现有能力,提供精细意图理解,提供面向千人千面意图的生成式数据服务,显著提升信息获取命中率和效率。其典型应用包括:安全生产方案生成、标准检索、个性化报表分析、AIGC-chatbot等基础工具应用。
2)MAP。现有各SOTA级AIGC模型难以直接覆盖油气全纵深。应用AIGC的自然语言交互能力,利用大模型作为调度器,调度现有能力完成用户意图,简化人机交互,提升效率。其典型应用包括:通过自然语言实现测井曲线重构、岩性物性预测、潜力层推荐、采集方案生成等能力唤起。
3)MAA。结合具象场景,AIGC与已有业务系统实现更友好地组装和人机交互,AIGC作为统一人机交互入口,实现意图与系统工作流间的转化,形成“数据+流程”双驱动的“乐高”式企业应用。其典型应用包括:智能化工作流执行、场景应用组装、数字员工等。
通过引入LM,充分应用其在信息采集和组织、语义理解、内容生成等方面相较于机器/深度学习的优势,适当应用上述的三种不同交互模式,预期将在以下方面,更好地加速油气工业数智化进程:
1)安全生产辅助决策:针对钻完井、催裂化生产等勘探开发、生产制造过程中的封闭场景,结合专家经验和历史语料对大模型进行增量训练后,将使之具备结合异常征象,进行事故预判的能力,为实现智能系统对推理结果的可解释性,通过LM与先验知识图谱的联合应用,可为上述涉及地下工况环境或装置内封闭式场景异常征象的业务视角可解释。
2)搜索与精准问答:现阶段、包括油气销售、系统运维、生产操作辅助、财务对账等场景下,都已部署了VPA虚拟机器人助手(Virtual Personal Assitant)[31],但既往的应用中,多是通过穷举问答对和人工穷举意图的形式,持续丰富VPA的技能集合,并实现在闭环场景中的应用。LM具有更好的语义理解、意图分析、多轮和情感计算能力,信息检索、多轮对谈、情感判断、外呼询证等场景中,针对开环意图的销售、询证、投诉处置、建议生成、标准信息检索等具备更好地解析能力。
3)基于大模型的多模型调度及联合应用:测井录井、业财一体化模拟测算等设计决策辅助类型的场景,具有强可解释性、容错性差等特点,需通过LM与浅层机器学习、深度学习、知识图谱融合应用,以LM作为调度器,联合应用知识机理和各类模式识别工具,在勘探侧,可实现对测井录井曲线重构、岩性预测、测井录井解释、潜力层推荐;在业财一体方面,实现不同经营策略下,财务健康度、经营指标的可解释数字孪生预测与测算,实现更高的置信度。
4)文案和内容生成助手:数智化环境下的协同办公、信息检索、数据分析、逻辑观点提炼和自然语言表达需求,例如文案内容辅助生成、美化及资料组织等,可基于LM的内容生成能力,检索并协助组织更多一手资料,提升文案生成和更迭效率,降低出错的可能性。
6 结 论
本文系统性地调研和总结了经典判别式人工智能和新一代生成式人工智能的背景、发展现状、技术特点,并展望了AIGC技术未来的应用方向。不同于经典判别式人工智能的业务场景单一、点状、泛化能力差等短板,AIGC通过基于海量数据、大算力预训练的大参数Transformer网络,产生了一定程度的智能涌现,实现了更好地上下文记忆、用户意图理解、信息检索、知识生成和信息分发。上述能力使用户可基于少量数据的参数微调、RLHF强化学习、提示工程、与外挂Agent联合应用等方式,使能更低门槛的模型调优、迭代以及应用嵌入,为AI技术从专业应用到普及应用提供了潜在可行性。
对于油气工业为代表的典型流程工业而言,如何应用AIGC涌现出的上述新能力,突破价值场景提炼、数据获取与治理、结论解释、应用构建与集成、跨专业语义对齐、跨云/跨IDC适配与应用集成等瓶颈问题,在安全生产辅助决策、精准问答与检索、内容生成、多模型调度与联合应用方面,形成有价值的AI原生应用,仍将是未来一段时间,探索的重点。
参考文献:
[1] 肖立志,宋先知.油气人工智能理论与应用场景(第一辑)[M].北京:电子工业出版社,2023.
[2]匡立春,刘合,任义丽,等.人工智能在石油勘探开发领域的应用现状与发展趋势[J].石油勘探与开发,2021,48(1):1-11.
[3] WU J Y,GAN W S,CHEN Z F,et al. AI-Generated Content (AIGC): A Survey [J/OL].arXiv:2304.06632 [cs.AI].(2023-03-26).https://arxiv.org/abs/2304.06632.
[4] DEVLIN J,CHANG M W,LEE K,et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding [J/OL].arXiv:1810.04805 [cs.CL].(2018-10-11).https://arxiv.org/abs/1810.04805.
[5] OpenAI. Introducing ChatGPT [EB/OL].[2024-01-15].https://openai.com/blog/chatgpt.
[6] OpenAI,ACHIAM J,ADLER S,et al. GPT-4 Technical Report [J/OL].arXiv:2303.08774 [cs.CL](2023-03-15).https://arxiv.org/abs/2303.08774.
[7] 王祺,李冬露,张云,等.2023年中国AIGC产业全景报告 [EB/OL].(2023-08-22).https://www.idigital.com.cn/report/
4227?type=0.
[8] WEI J,WANG X Z,SCHUURMANS D,et al. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models [J/OL].arXiv:2201.11903 [cs.CL].(2023-01-10).https://arxiv.org/abs/2201.11903v6.
[9] HU E J,SHEN Y L,WALLIS P. LoRA: Low-Rank Adaptation of Large Language Models [J/OL].arXiv:2106.09685 [cs.CL].(2021-06-17).https://arxiv.org/abs/2106.09685.
[10] Langchain. Langchain: Get Your LLM Application From Prototype to Production [EB/OL].[2024-01-15].https://www.langchain.com.
[11] LIU Y X,ZHANG K,LI Y. Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models [J/OL].arXiv:2402.17177.(2024-02-27).[cs.CV].https://arxiv.org/abs/2402.17177.
[12] 邹文波.人工智能研究现状及其在测井领域的应用[J].测井技术,2020,44(4):323-328.
[13] 蒋希文.钻井事故与复杂问题:第2版 [M].北京:石油工业出版社2006.
[14] 陈宏志,马鹏程.一种设备状态监测方法及系统:CN201910704324 [P].2019-11-01.
[15] 陈宏志,马鹏程.一种数据处理方法及电子设备:CN201910912792 [P].2020-01-10.
[16] 陈宏志,马鹏程.一种数据处理方法、系统及电子设备:201910789677 [P].2019-11-26.
[17] 用友云平台团队.数字化中台 [M].北京:电子工业出版社,2021.
[18] 田奇,白小龙.ModelArts人工智能应用开发指南 [M].北京:清华大学出版社,2020.
[19] 陈宏志,金基勇,裴芝林,等.模型构建方法、系统、电子设备和可读存储介质:CN202011337071 [P].2021-02-05.
[20] WU C,SONG Y,MARCH D. Learning from Drivers to Tackle the Amazon Last Mile Routing Research Challenge [J/OL].arXiv:2205.04001 [cs.AI].(2022-05-09).https://arxiv.org/abs/2205.04001.
[21] LI C L,CHEN H H,YAN M,et al. ModelScope-Agent: Building Your Customizable Agent System with Open-source Large Language Models [J/OL].arXiv:2309.00986 [cs.CL].(2023-09-02)https://arxiv.org/abs/2309.00986.
[22] VASWANI A,SHAZEER N,PARMAR N,et al. Attention is All You Need [C]//NIPS'17:Proceedings of the 31st International Conference on Neural Information Processing Systems.Red Hook:Curran Associates Inc,2017:6000-6010.
[23] WEI J,TAY Y,BOMMASANI R,et al. Emergent Abilities of Large Language Models [J/OL].arXiv:2206.07682 [cs.CL].(2022-06-15).https://arxiv.org/abs/2206.07682.
[24] HUANG X W,RUAN W J,HUANG W,et al. A Survey of Safety and Trustworthiness of Large Language Models Through the Lens of Verification and Validation [J/OL].arXiv:2305.11391 [cs.AI].(2023-05-19).https://arxiv.org/abs/2305.11391.
[25] MIRANDA E R,YEUNG R,PEARSON A,et al. A Quantum Natural Language Processing Approach to Musical Intelligence [J/OL].arXiv:2111.06741v2 [quant-ph].(2021-11-10).https://arxiv.org/abs/2111.06741.
[26] 亚信科技,清华大学智能产业研究院.AIGC(GPT-4)赋能通信行业应用白皮书 [R/OL].(2024-01-15).https://www.doc88.com/p-27039239698517.html.
[27] LAI J Q,GAN W S,WU J Y,et al. Large Language Models in Law: A Survey [J/OL].arXiv:2312.03718 [cs.CL].(2023-11-26).https://arxiv.org/abs/2312.03718v1.
[28] WANG J J,YANG D,HU B B,et al. Know Your Needs Better: Towards Structured Understanding of Marketer Demands with Analogical Reasoning Augmented LLMs [J/OL].arXiv:2401.04319 [cs.CL].(2023-01-09).https://arxiv.org/abs/2401.04319.
[29] 中国信息通信研究院华东分院,中国信息通信研究院人工智能研究中心,上海人工智能实验室开源生态发展中心.大模型落地应用案例集2023 [R/OL].(2024-01-15).https://max.book118.com/html/2024/0112/8047141060006025.shtm2023.
[30] WANG L,MA C,FANG X Y,et al. A Survey on Large Language Model based Autonomous Agents [J/OL].arXiv:2308.11432 [cs.AI].(2023-08-22).https://arxiv.org/abs/2308.11432.
[31] AL-AMIN M,ALI N S,SALAM A,et al. History of Generative Artificial Intelligence (AI) Chatbots: Past, Present,and Future Development [J/OL].arXiv:2402.05122 [cs.GL].(2023-02-04).https://arxiv.org/abs/2402.05122.
作者简介:陈宏志(1986—),男,汉族,福建人,高级工程师,博士,研究方向:人工智能与垂直领域的交叉学科应用;宫本儒(1985—),男,汉族,辽宁人,工程师,硕士,研究方向:石化信息化系统与应用;王笑妍(1997—),女,汉族,河北人,工程师,硕士,研究方向:能源行业数字孪生与人工智能应用;林秀峰(1985—),男,汉族,北京人,高级工程师,高级经济师,博士,研究方向:大数据与人工智能应用;通讯作者:孙加峰(1981—),男,汉族,内蒙古乌兰察布人,研究方向:算力管理、算力网络、算网融合。
