
基于改进YOLOv5的陶瓷表面缺陷检测算法
2024-09-19 00:00:00潘金晶曾成张晶李再勇耿雪娜
现代信息科技 2024年13期
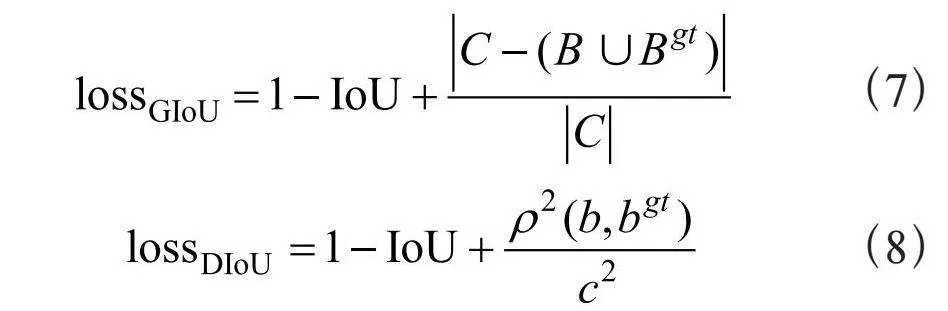
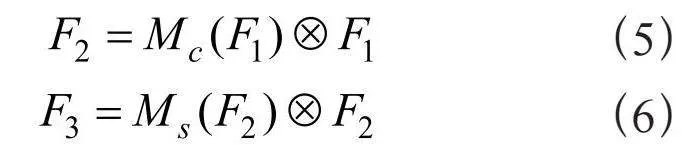
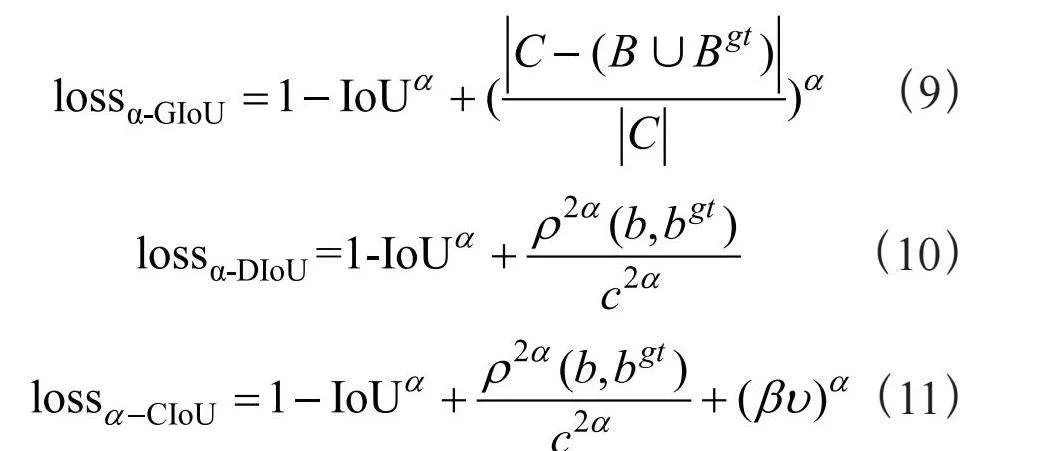


摘 要:提出一种陶瓷表面缺陷检测算法YOLOv5-G。该算法在YOLOv5框架的基础上,将全局注意力机制(GAM)引入主干和颈部网络中,该机制能够在减少信息弥散的情况下放大全局交互特征,增强了网络的特征表达能力;使用α-CIoU作为改进算法的边界框回归损失函数,自适应地向上加权高IoU对象的损失和梯度,使得模型可以更加关注IoU高的目标,从而帮助提高定位精度。在工业相机成像的陶瓷表面缺陷数据集上进行测试,结果表明,与YOLOv5模型相比,基于α-CIoU的YOLOv5模型的平均精度均值(mAP50)和召回率(Recall)分别提升了2.3%、4.6%;改进算法的平均精度均值(mAP50)、精确率(Precision)、召回率(Recall)分别提升了3.9%、1.7%、5.1%。
关键词:陶瓷表面缺陷;全局注意力机制;α-IoU;YOLOv5
中图分类号:TP183;TP391.4 文献标识码:A 文章编号:2096-4706(2024)13-0070-06
Ceramic Surface Defect Detection Algorithm Based on Improved YOLOv5
PAN Jinjing1, ZENG Cheng1, ZHANG Jing1, LI Zaiyong1, GENG Xuena2
(1.CYG Vision Technology (Zhuhai) Co., Ltd., Zhuhai 519085, China; 2. School of Computer Science and Technology, Changchun University of Science and Technology, Changchun 130013, China)
Abstract: It propose a ceramic surface defect detection algorithm YOLOv5-G. This algorithm introduces the Global Attention Mechanism (GAM) into the backbone and neck networks based on the YOLOv5 framework. This mechanism can amplify the global interaction features while reducing the information dispersion, and enhances the feature expression capability of the network. Taking α-CIoU as the bounding box regression loss function of the improved algorithm, the loss and gradient of high IoU objects are adaptively weighted upward, so that the model can pay more attention to the targets with high IoU, thus helping to improve the positioning accuracy. The test is carried out on the ceramic surface defect data set of the industrial camera imaging, and the results show that compared with the YOLOv5 model, the Mean Average Precision (mAP50) and Recall rate of the YOLOv5-G model based on α-CIoU are increased by 2.3% and 4.6% respectively. The Mean Average Precision (mAP50), Precision and Recall of the improved algorithm are all significantly improved by 3.9%, 1.7% and 5.1% respectively.
Keywords: ceramic surface defect; GAM; α-IoU; YOLOv5
0 引 言
陶瓷的表面质量直接影响到其外观和使用寿命。因此,准确、有效的陶瓷表面缺陷检测方法是非常重要的。目前,陶瓷表面缺陷检测仍然主要依赖于人工检测。该方法效率低下且评价标准过于主观,不能满足工业生产的需求。为了提高检测的效率和准确性,越来越多的学者采用不同的技术进行陶瓷表面缺陷检测。目前陶瓷缺陷检测方法主要包括超声波检测[1]、机器视觉检测、X射线检测法[2]等。超声波检测依赖于陶瓷表面的反射和折射,其检测精度和灵敏度与缺陷的深度有关,对于陶瓷表面颜色缺陷的检测效果较差。X射线扫描陶瓷采用透射成像原理,可以检测出小的内外缺陷。但该方法成本高、效率低,不适用于大规模陶瓷缺陷检测。机器视觉检测方法主要分为传统方法和基于深度学习的检测方法。
传统方法主要依据缺陷颜色、形状等特征,利用图像处理方法或结合传统机器学习方法进行检测[3]。传统方法依赖于经验丰富的专家手工制作的特征,这些特征往往是有限的,有高度针对性的。由于陶瓷表面缺陷种类繁多,形态多样,背景复杂,一旦产品材料或生产环境发生变化,传统方法中的有限特征模板将难以应用。
基于深度学习的代表性检测算法主要包括Faster R-CNN [4]和YOLO系列[5-8]。Faster R-CNN通常具有较高的检测精度,但处理速度较慢;YOLOv5模型具有准确性、快速性、高效性优点,已被应用于不同场景下的智能缺陷检测。蒋亚军等[9]在YOLOv5s的骨干网络中加入CBAM模块,并增加一个检测头,有效提高了纸杯缺陷的检测能力,对小尺寸和特征不明显纸杯缺陷的检测效果有明显提升;王恩芝等[10]在YOLOv5骨干网络中加入卷积注意力模块,并在颈部引入自适应空间融合方法,提高了对织物缺陷的检测精度;王旭等[11]在YOLOv5的骨干网络中引入CBAM模块,并用CARAFE算子替换原YOLOv5中最近邻上采样算子,有效地提高了对陶瓷环缺陷的检测精度。
综上,本文提出了一种改进YOLOv5的陶瓷表面缺陷检测算法YOLOv5-G。首先,在YOLOv5的骨干网络和颈部中引入全局注意力机制(Global Attention Mechanism, GAM)[12],使模型在通道、高度及宽度这三个维度上进一步提取缺陷特征,降低漏检率。其次,引入α-IoU [13]作为改进算法的边界框损失函数,自适应地向上加权高IoU对象的损失和梯度,使得模型可以更加关注IoU高的目标,加速了预测框的收敛,提高了预测框的回归精度。本文在工业相机成像的陶瓷表面缺陷数据集上进行改进前后模型的验证。结果表明,相较于YOLOv5模型,改进算法的检测精度有明显提升,可以较好地应用于陶瓷表面缺陷检测任务中。
1 YOLOv5基本原理
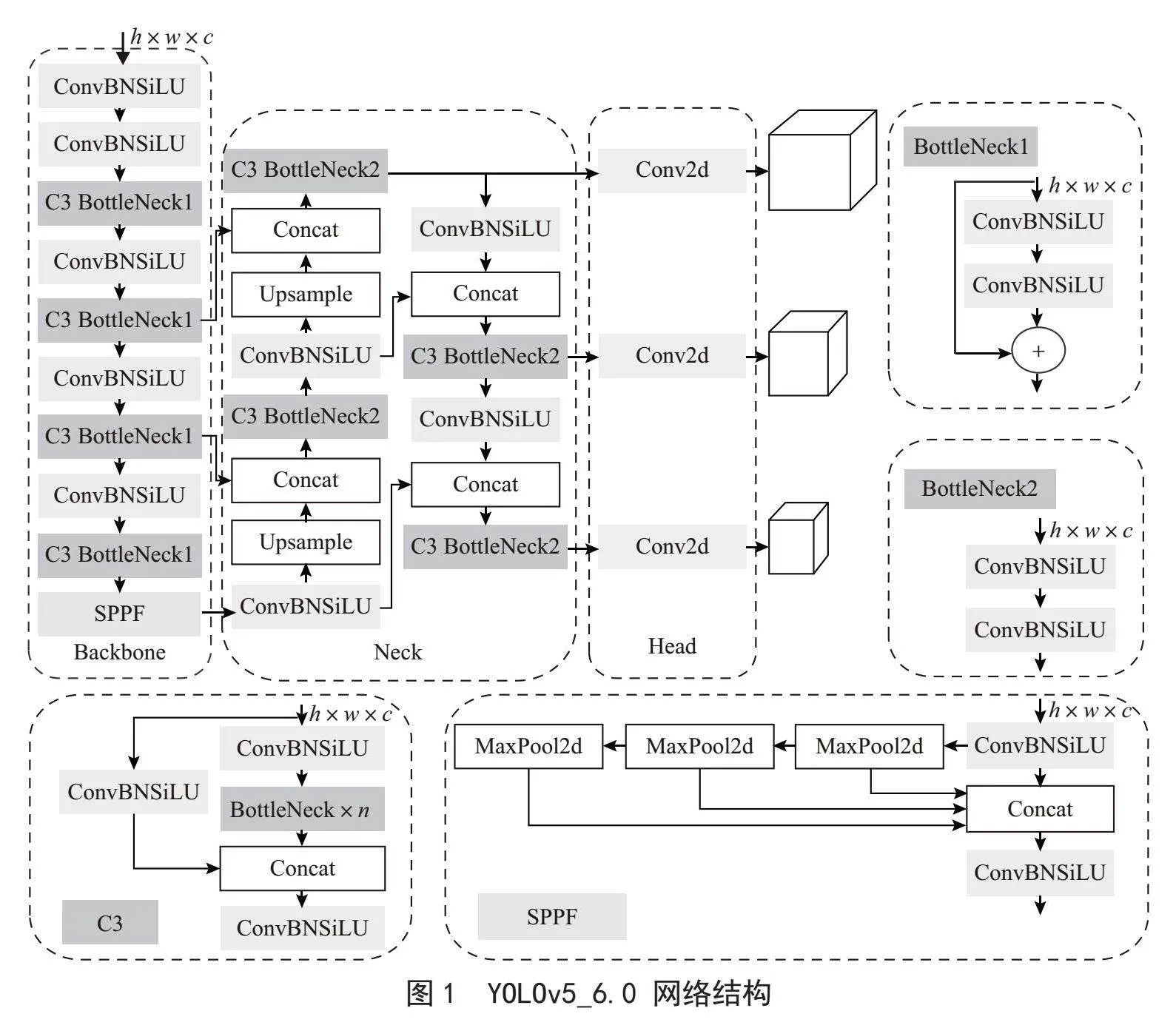
YOLOv5作为单阶段目标检测算法的SOTA(State-of the-Art),包括输入端(Input)、骨干网络(Backbone)、颈部(Neck)和头部(Head)四部分。YOLOv5通过width_multiple和depth_multiple两个参数来控制模型的宽度和深度,对应s、m、l、x这4种规模的网络。其中,YOLOv5s的深度及特征图宽度最小,其余网络在此基础上不断加深、加宽,复杂度与精度也随之提升。本文为了满足工业场景下检测速度与精度的权衡,选择了YOLOv5s_6.0为基础模型。图1展示了YOLOv5_6.0的网络结构。
1.1 输入端
输入端通过自适应图片缩放将原始图片统一缩放到一个标准尺寸,进行填充后,送入主干网络中。使用Mosaic数据增强,随机地将4张图片进行缩放裁剪并拼接成新的图片,该方法可以丰富检测数据集,让网络的鲁棒性更好。不同于传统目标检测算法需要手动设置锚框的大小和高宽比等参数,YOLOv5在训练代码中嵌入自适应锚框计算功能,自动获取训练数据集所对应的最佳锚框值,实现更精准的目标检测。
1.2 主干网络
主干网络能够从图像中提取特征。如图1所示,YOLOv5的主干网络主要包括ConBNSiLU、C3及SPPF模块。其中,ConBNSiLU是由2D卷积层、BN层及SiLU激活函数组成,其作用是进行特征提取,减少计算量和参数量,达到提速效果。C3由n个Bottleneck、3个ConBNSiLU及Concat模块构成,C3减少了梯度信息的重复,增加网络的深度和感受野,提高了骨干网络的特征提取能力。YOLOv5_6.0用SPPF结构代替空间金字塔池化结构SPP [14],将输入串行通过3个5×5大小的最大池化层,在输出与SPP相同的条件下,速度更快。SPPF可以在一定程度上融合多尺度特征。
1.3 颈部网络
颈部由特征金字塔(Feature Pyramid Network, FPN)[15]及路径聚合网络(Path Aggregation Network, PANet)[16]构成。FPN采用上采样的方式将深层的强语义特征传达到浅层,而PANet则通过下采样的方式向深层传达强定位信息,二者联合,从不同的主干层对不同的检测层进行参数聚合,生成具有多尺度信息的特征图,以提高目标检测的准确率。
1.4 输出端
Head部分主要为检测模块,由3个1×1卷积构成,对应3个检测特征层。当输入图片大小为640×640时,三个尺度上的特征图大小分别为80×80、40×40、20×20,相对于输入图像分别做了8、16及32倍下采样,分别适合检测小目标、中等目标以及大目标。三个特征层对应的通道数为(类别数量+5)×每个检测层上的锚框数量,其中5分别对应目标置信度和预测框坐标。
1.5 损失函数
损失函数主要由3部分组成:分类损失、置信度损失及定位损失。其中,分类损失和置信度损失采用二元交叉熵来计算,定位损失采用CIoU [17]损失来计算。CIoU考虑了3个重要的几何因素:目标框与预测框的重叠面积、中心点距离及宽高比,保证了预测框和目标框的宽高比的一致性,提高了预测框的定位精度,加快了网络的收敛速度。CIoU公式为:
其中,ρ2(⋅)表示欧式距离,b、bgt分别表示预测框和目标框的中心点,c表示能够包含两框的最小闭包区域的对角线距离。α为惩罚参数, 用来衡量高宽比的一致性,α和 的计算式为:
CIoU损失函数公式为:
2 改进的YOLOv5模型
2.1 GAM引入Backbone和Neck
注意力机制是计算机视觉中的一个重要概念,它是指模型能够在处理输入数据时,集中关注某些重要的部分,忽略其他无关的部分。在计算机视觉任务中,注意力机制可以帮助模型更好地理解输入图像或视频,从而提高模型的性能。注意力机制在图像任务中的性能改进已有很多研究。Squeeze-and-Excitation Networks(SENet)[18]首次使用通道注意和通道特征融合来抑制不重要的通道,但效率较低。卷积注意力模块(CBAM)[19]同时考虑了通道和空间维度,但忽略了通道-空间的相互作用,从而失去了跨维信息。考虑到跨维度交互作用的重要性,三重注意模块(TAM)[20]利用每一对通道、空间宽度和空间高度的三维信息来提高效率。但每次操作仅应用于两个维度,而不是全部三个维度。GAM注意力机制能够放大跨维度的交互作用,同时获取通道,空间高度及宽度三个维度的特征,避免信息丢失,从而提高检测的精度。
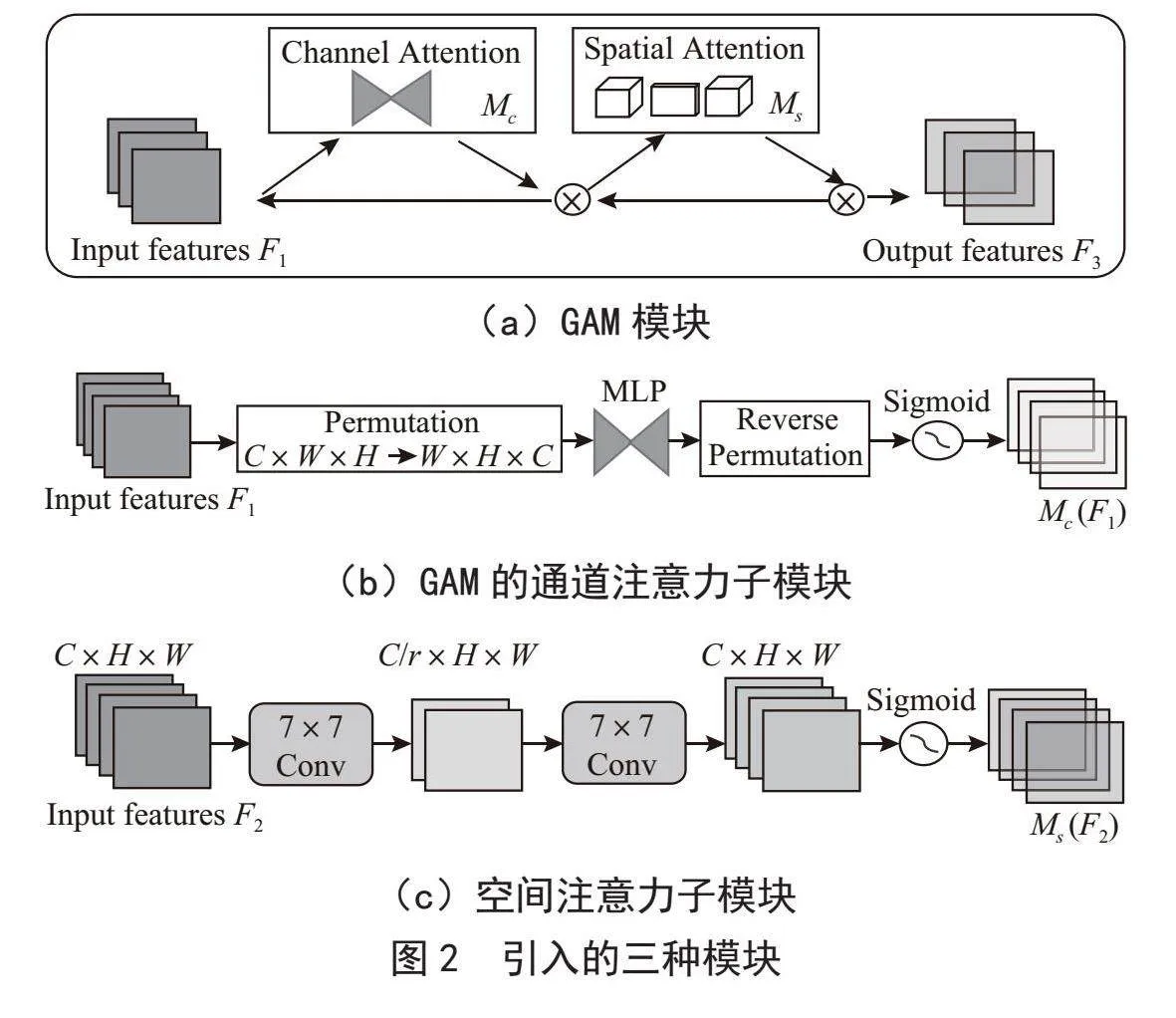
本研究在YOLOv5的骨干网络及颈部引入GAM注意力模块,如图2(a)所示,给定输入特征F1 ∈ RC×H×W,中间状态和输出如式(5)(6)所示:
其中,Mc和Ms分别表示通道和空间注意力图,表示按元素进行乘法操作。GAM中的通道注意子模块使用三维排列来保留三个维度上的信息,如图2(b)所示。通过一个两层的MLP(多层感知器)放大跨维的通道-空间依赖性。在空间注意力子模块中,如图2(c)所示,为了关注空间信息,使用两个7×7卷积层进行空间信息融合。
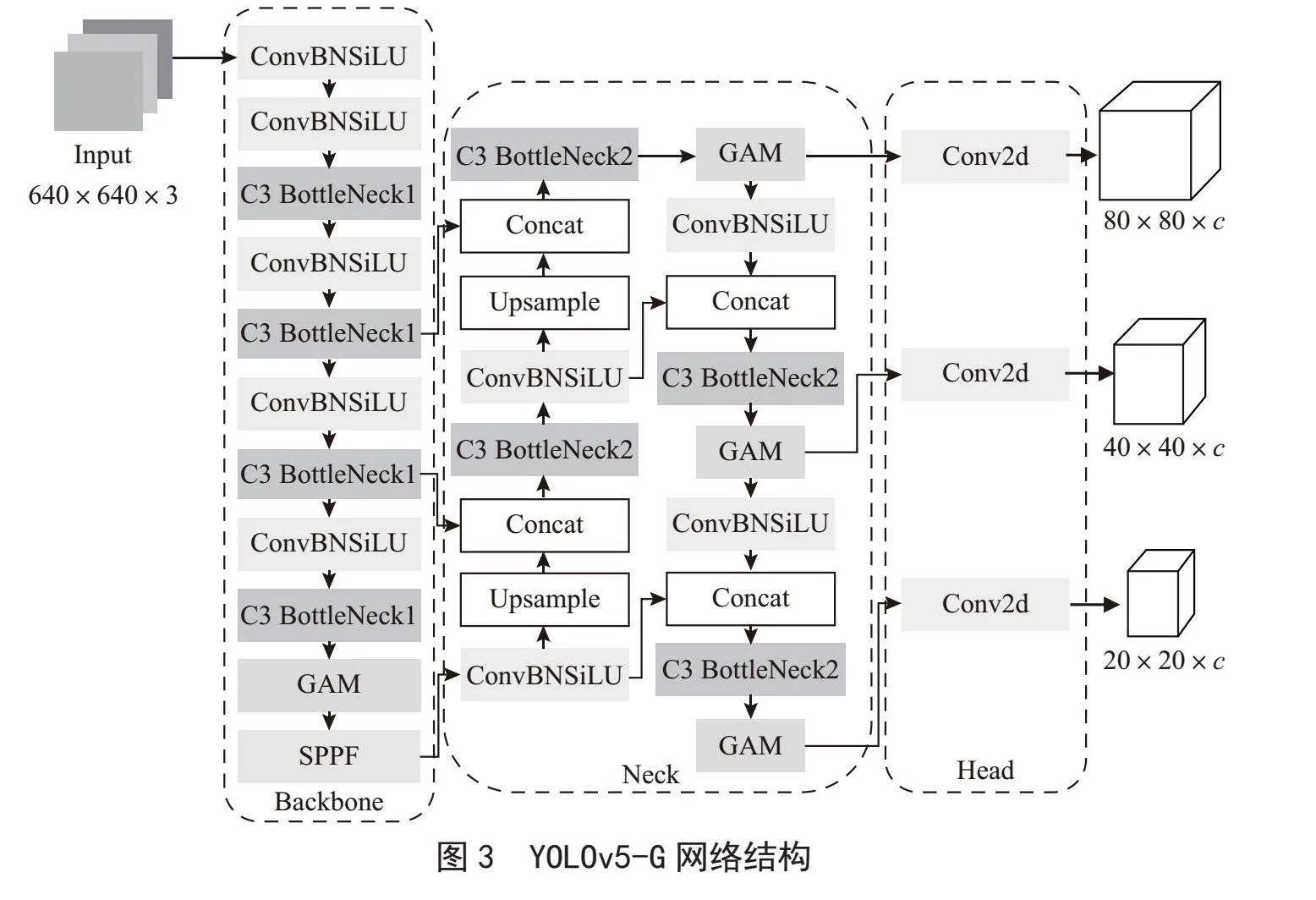
GAM模块能够在减少信息弥散的情况下放大全局交互特征,增强了网络的特征表达能力,能够使得YOLOv5模型更加精准地进行目标检测。YOLOv5-G将GAM模块引入主干网络和颈部,改进后的主干网络如图3所示。
2.2 α-IoU的引入
目标检测作为计算机视觉的核心问题,其检测性能依赖于损失函数的设计。边界框损失函数作为目标检测损失函数的重要组成部分,其良好的定义将为目标检测模型带来显著的性能提升。早期的目标检测工作使用IoU作为定位损失。然而,当目标框与预测框没有交集时,IoU损失会出现梯度消失现象,导致无法继续优化。这激发了几种改进的基于IoU的损失设计,包括GIoU [21]、DIoU [17]、CIoU,计算式为:
其中,B和Bgt表示预测框和目标框,C表示包含B和Bgt的最小闭包,ρ2(⋅)表示欧几里得距离,b和bgt表示预测框和目标框的中心点,w gt、hgt、w、h分别表示目标框及预测框的宽高。
α-IoU表示一种新的IoU损失家族,通过在现有的IoU损失中引入power变换,用于控制IoU损失对总损失函数的贡献,实现精准的预测框回归和目标检测。α-IoU对现有的基于IoU的损失进行了统一的幂化,合适的α值(即α>1)可以通过自适应地向上加权高IoU对象的损失和梯度,使得模型可以更加关注IoU高的目标,从而帮助提高定位精度。将α-IoU应用于GIoU、DIoU及CIoU,可得到α-GIoU,α-DIoU,α-CIoU,公式为:
本文将探究不同的α值(α = 1,2,3)与不同IoU损失的组合在本研究数据集上对YOLOv5模型性能的影响,并选取最优的α值与IoU损失的组合。2NpFh3/ihd4P5CXGYCfvygbFL6xYphTLgX++Gq+Llp0=
3 实验分析
3.1 实验设置
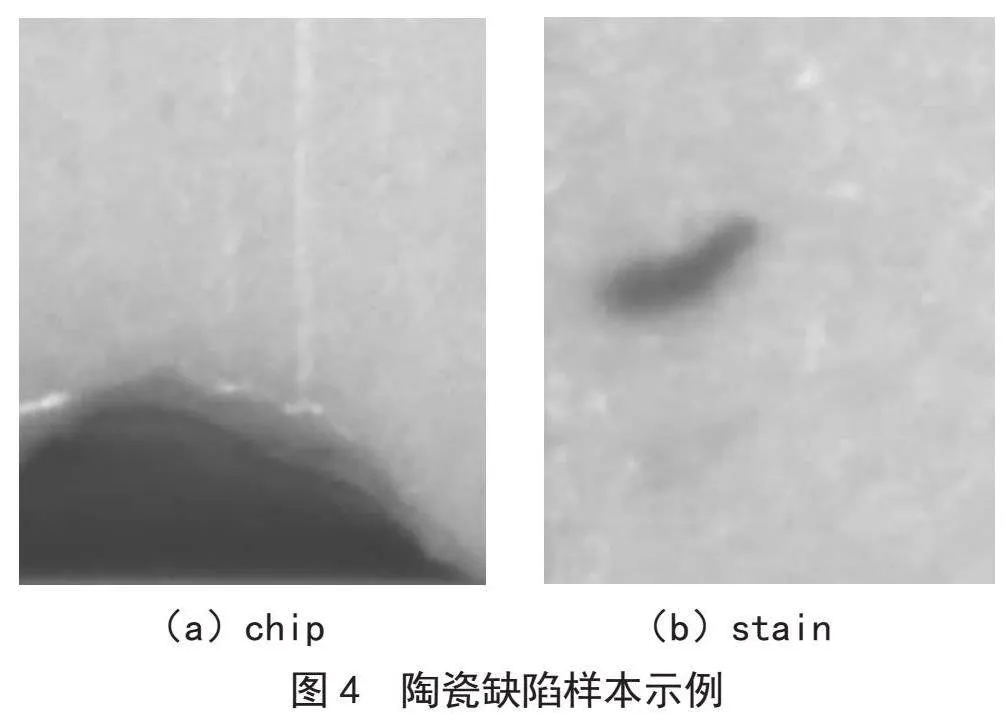
本实验中使用的数据集来自工业相机成像,包含1 052张含标签图片。样品的缺陷主要包括2种类别:chip(缺口)和stain(脏污),部分缺陷样本如图4所示。按照8:1:1的比例将数据集划分为训练集、验证集和测试集。原始图像尺寸为2 448×2 048×3,将所有输入图像尺寸统一裁剪为704×640×3。模型初始学习率为0.01,权重衰减系数为0.000 5,动量为0.937,Batch size为16,Epoch为450,使用Adam优化器进行参数优化。本实验基于PyTorch深度学习框架,CPU为Intel Core i7 6600U,GPU为NVIDIA GeForce RTX 3090,用于加速运算,开发环境为Python 3.7.9,PyTorch 1.10.2,CUDA 11.6。
3.2 评估指标
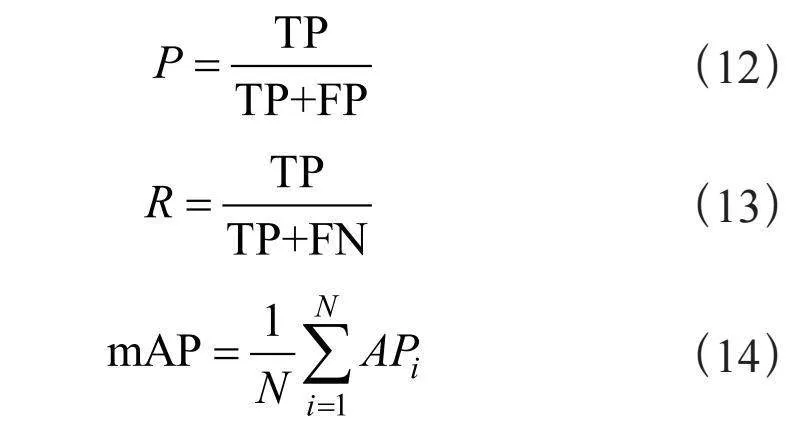
本实验采用精确率(P),召回率(R)以及目标检测领域常用的mAP50来评估YOLOv5模型及其改进模型的性能。计算式为:
精确率表示模型预测正确物体的能力,该指标表示在所有预测为缺陷的结果(TP+FP)中,模型预测为缺陷且正确的目标(TP)的占比。召回率表示模型能够找全正确物体的能力,该指标表示在所有的缺陷样本(TP+FN)中,模型预测为缺陷且正确的目标(TP)的占比。APi表示第i类的模型平均精度,若是多类别,则使用mAP(mean Average Precision)来衡量模型性能,计算方法为将多个AP值累加后求平均。mAP50是指在IoU阈值取0.5时的mAP值。
3.3 实验结果分析
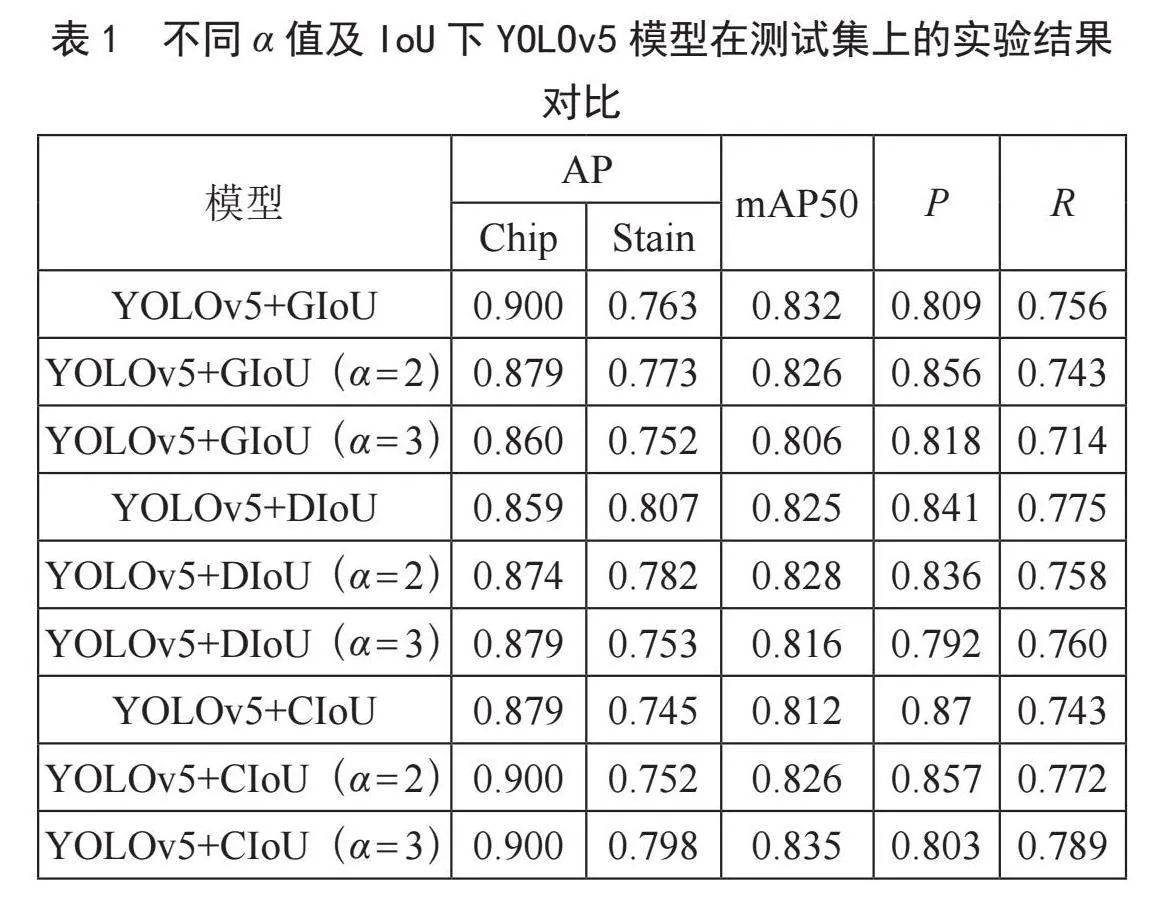
表1展示了YOLOv5模型在不同α值及IoU下,在测试集上的性能表现。通过表1可得出,YOLOv5在CIoU(α = 2)上具有最好的精确率,在CIoU(α = 3)上具有最好的召回率。对于不同模型的mAP50,CIoU(α = 3)表现最好,其次是GIoU和DIoU(α = 2)。YOLOv5+CIoU(α = 3)在本实验中获得了最好的mAP50和召回率,分别较之于YOLOv5原始模型(YOLOv5+CIoU)提升了2.3%、4.6%。因此,我们选用CIoU(α = 3)作为改进YOLOv5模型的边界框回归损失函数来提高模型的泛化能力。
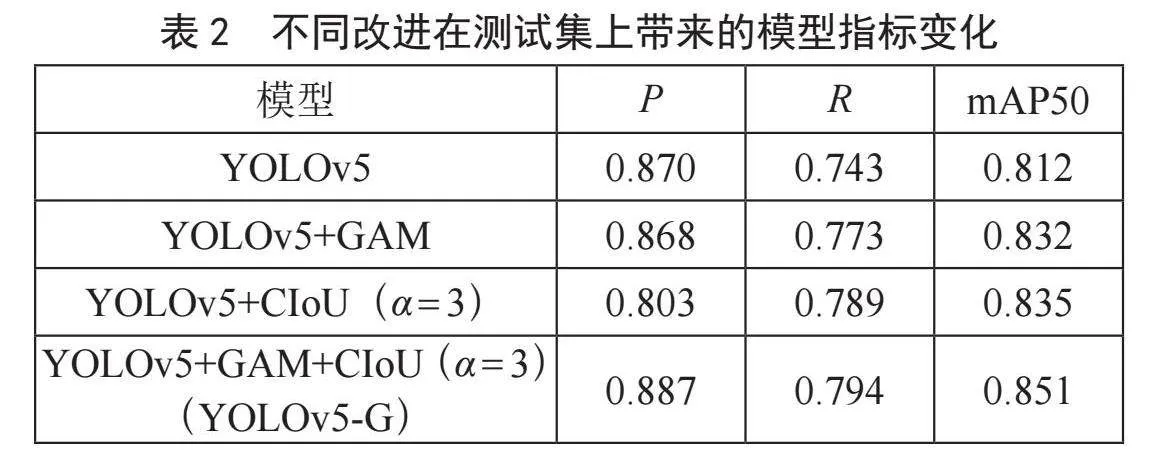
改进后的模型YOLOv5-G,在主干网络及颈部添加GAM模块,将α-CIoU作为边界框损失函数。将原模型及改进模型在测试集上进行测试,观察不同改进对模型性能变化的影响。从表2可以观察到,在引入GAM模块后,相较于YOLOv5基础模型,召回率提升了3.0%,mAP50提升了2.0%,但精确率略微有所下降。进一步地,将α-CIoU(α = 3)作为边界框损失函数,YOLOv5-G相较于原模型,在精确率、召回率、mAP50上均有明显提升,分别提升了1.7%、5.1%、3.9%。
图5展示了原图及改进前后模型在陶瓷表面缺陷数据集上的检测结果。第一、二组对比图中,YOLOv5分别漏检了一个chip缺陷及一个stain缺陷,而YOLOv5-G均将所有缺陷检出;第三组图像中,YOLOv5将图左下角的微小阴影误检为chip缺陷,YOLOv5-G未出现误检现象;第四组对比图中,YOLOv5漏检了一块较为明显的stain缺陷,YOLOv5-G均以较高的置信度正确检出,体现了更好的泛化性能。
4 结 论
本文基于YOLOv5提出了一种改进的陶瓷表面缺陷检测算法(YOLOv5-G),在主干网络及颈部加入全局注意力(GAM)模块,增强了模型的特征表达能力,提高了检测精度。引入α-CIoU(α = 3)边界框回归损失函数,进一步提高了缺陷的定位精度。实验结果表明,YOLOv5-G算法相较于YOLOv5模型在精确率、召回率和平均精度值方面均得到了提升,具有优秀的检测精度,能较好地应用于陶瓷表面缺陷检测任务中。
参考文献:
[1] CHESNOKOVA A A,KALAYEVA S Z,IVANOVA V A. Development of a Flaw Detection Material for the Magnetic Particle Method [J/OL].Journal of Physics: Conference Series,2017,881(1):12022[2023-11-20].https://iopscience.iop.org/article/10.1088/1742-6596/881/1/012022.
[2] PLESSIS A D,YADROITSAVA I,YADROITSEV I. Effects of Defects on Mechanical Properties in Metal Additive Manufacturing: A Review Focusing on X-ray Tomography Insights [J/OL].Materials & Design,2020,187:108385[2023-11-20].https://doi.org/10.1016/j.matdes.2019.108385.
[3] 罗东亮,蔡雨萱,杨子豪,等.工业缺陷检测深度学习方法综述 [J].中国科学:信息科学,2022,52(6):1002-1039.
[4] REN S Q,HE K M,GIRSHICK R,et al. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks [J].Advances in Neural Information Processing Systems,2017,39(6):1137-1149.
[5] REDMON J,FARHADI A. YOLO9000: Better,Faster,Stronger [C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu:IEEE,2017:6517-6525.
[6] REDMON J,FARHADI A. Yolov3: An Incremental Improvement [J/OL].arXiv:1804.02767 [cs.CV].(2018-04-08)[2023-12-01].https://arxiv.org/abs/1804.02767.
[7] BOCHKOVSKIY A,WANG C Y,LIAO H Y M. YOLOv4: Optimal Speed and Accuracy of Object Detection [J/OL].arXiv:2004.10934 [cs.CV].(2020-04-23)[2023-11-22].https://arxiv.org/abs/2009.10934.
[8] github. ultralytics/yolov5 [EB/OL].[2023-11-26].https://github.com/ultralytics/yolov5.
[9] 蒋亚军,曹昭辉,丁椒平,等.基于改进YOLOv5s模型纸杯缺陷检测方法 [J].包装工程,2023,44(11):249-258.
[10] 王恩芝,张团善,刘亚.基于改进Yolo v5的织物缺陷检测方法 [J].轻工机械,2022,40(2):54-60.
[11] 王旭,管声启,刘通,等.基于改进YOLOv5的陶瓷环缺陷检测算法 [J].轻工机械,2023,41(3):66-71.
[12] LIU Y C,SHAO Z R,HOFFMANN N. Global Attention Mechanism: Retain Information to Enhance Channel-Spatial Interactions [J/OL].arXiv:2112.05561 [cs.CV].(2021-12-10)[2023-10-26].https://arxiv.org/abs/2112.05561.
[13] HE J B,ERFANI S,MA X J,et al. Alpha-IoU: A Family of Power Intersection over Union Losses for Bounding Box Regression [J/OL].arXiv:2110.13675 [cs.CV].(2022-1022)[2023-10-26].https://arxiv.org/abs/2110.13675.
[14] HE K M,ZHANG X Y,REN S Q,et al. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2015,37(9):1904-1916.
[15] LIN T Y,DOLLAR P,GIRSHICK R,et al. Feature Pyramid Networks for Object Detection [C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Honolulu:IEEE,2017:936-944.
[16] LI H C,XIONG P F,AN J,et al. Pyramid Attention Network for Semantic Segmentation [J/OL].arXiv:1805.10180 [cs.CV].(2018-11-25)[2023-11-19].https://arxiv.org/abs/1805.10180v1.
[17] ZHENG Z H,WANG P,LIU W,et al. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression [C]//Proceedings of the 34th AAAI Conference on Artificial Intelligence.PaloAlto:AAAI Press,2020,34(7):12993-13000.
[18] HU J,SHEN L,ALBANIE S,et al. Squeeze-and-Excitation Networks [C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City:IEEE,2018:7132-7141.
[19] WOO S,PARK J,LEE JY,et al. CBAM: Convolutional Block Attention Module [C]//Proceedings of the 15th European Conference on Computer Vision.Munich:Springer,2018:3-19.
[20] MISRA D,NALAMADA T,ARASANIPALAI A U,et al. Rotate to Attend: Convolutional Triplet Attention Module [C]//Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision.Waikoloa:IEEE,2021:3138-3147.
[21] REZATOFIGHI H,TSOI N,GWAK J Y,et al. Generalized Intersection Over Union: A Metric and a Loss for Bounding Box Regression [C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Long Beach:IEEE,2019:658-666.
作者简介:潘金晶(1991—),女,汉族,安徽滁州人,首席算法专家,博士,研究方向:数据挖掘、推荐系统、深度学习、计算机视觉;曾成(1984—),男,汉族,湖北武汉人,首席软件官,博士,研究方向:软件算法及通信协议优化、深度学习算法在工业检测领域的应用与优化;张晶(1985—),女,汉族,湖北武汉人,总经理,本科,研究方向:工业视觉检测项目的开发和管理;李再勇(1990—),男,汉族,湖北襄阳人,项目经理,研究方向:工业视觉检测项目开发及管理;耿雪娜(1988—),女,汉族,吉林长春人,讲师,博士,研究方向:故障诊断、自动推理、专家系统的算法。
