
基于动态聚类的个性化联邦学习与模块化组合策略
2024-09-19 00:00:00周洪炜马源马旭
现代信息科技 2024年13期




摘 要:提出一种基于动态聚类的个性化联邦学习方法来解决联邦学习下数据异构的问题。此方法将优化目标向量与凝聚聚类算法相结合,在保证节省计算资源的同时,将数据差异较大的客户端动态划分到不同的集群中。此外,出于对训练模型可持续使用的考虑,进一步提出模块可组合策略,新的客户端只需将之前训练模型组合便可以得到一个适合本地任务的初始模型。客户端只需在该初始模型上进行少量训练便可以应用于本地任务。在Cafir-10和Minst数据集上,其模型的精确度要优于本地重新训练模型的精度。
关键词:联邦学习;个性化;深度神经网络;可组合;动态聚类
中图分类号:TP181 文献标识码:A 文章编号:2096-4706(2024)13-0061-05
Personalized Federated Learning Based on Dynamic Clustering and Modular Combinatorial Strategy
ZHOU Hongwei, MA Yuan, MA Xu
(Qufu Normal University, Qufu 273165, China)
Abstract: This paper proposes a personalized federated learning method based on dynamic clustering to address the issue of heterogeneous data in Federated Learning. This method combines the optimization target vector with the agglomerative clustering algorithm, dynamically divides clients with significant data differences into different clusters while conserving computing resources. Furthermore, in consideration of the sustainability of training models, the paper further proposes a modular combinatorial strategy, where new clients only need to combine previously trained models to obtain an initial model suitable for local tasks. The client only needs to perform a small amount of training on this initial model to apply it to local tasks. On the Cafir-10 and Minst datasets, the model's accuracy is superior to that of locally retrained models.
Keywords: Federated Learning; personalization; Deep Neural Network; combinatorial; dynamic clustering
0 引 言
传统的中心化机器学习需要客户端将本地的数据上传到服务器,并由服务器利用手机的数据完成模型的训练,然而数据离开了本地往往会造成第三方对于个人隐私数据的滥用。因此联邦平均算法[1]于2016年被谷歌学术提出,联邦平均算法作为经典分布式机器学算法可以使得客户端训练数据在不离开本地情况下完成模型的训练,这有助保护客户端数据的隐私和安全。因此联邦学习被广泛应用于医疗[2]、物联网[3-4]等领域。然而,一般的联邦学习算法面临客户端数据异构的情况时,通常训练的模型收敛过慢甚至模型可用性差。因此个性化联邦学习被提出来应对上述挑战。常见的个性化联邦学习方案有基于正则损失的联邦学习、基于参数解耦的个性化联邦学习以及基于个性化掩码的联邦学习等。基于正则损失的联邦学习是通过在本地优化目标上添加正则损失来约束本地优化,防止本地过拟合提高模型的泛化能力[5]。参数解耦则是通过将客户端模型拆分基础层和个性层,通过共享基础层参数提高模型泛化能力同时,本地对个性化层的训练来提高模型个性化能力[6]。个性化掩码则需要利用本地个性化掩码对于全局模型进行裁剪来得到适用于本地任务的模型[7]。尽管上述方案在一定程度上能够缓解数据异构带来的挑战,但是面对客户端数据差异较大的学习场景仍然表现不理想。因此近年来,基于客户端聚类个性化联邦学习方案被提出来解决上述的挑战。基于客户端聚类的主要思想是通过将数据差异较大客户端分到不同集群中去,来减少同一集群内部的数据异构性。为了能有效地将相似度客户端分到同一集群中,迭代联邦聚类算法[8]与软聚类联邦学习算法[9]提出依据不同集群模型在客户端的表现来确定客户端所属的集群,但是需要一定的先验知识预先确定客户端分组的数量。在实际应用中获取这些先验知识通常是困难的。因此,聚类联邦学习算法[10]提出通过计算客户端模型梯度之间的相似度对客户端集群进行递归二分类,这使得服务器无须预先确定客户端模型分组的数量。此外,层次聚合联邦学习算法[11]利用客户端模型参数之间的相似性对客户端进行层次凝聚聚类。然而,上述动态分组都依赖于计算客户端模型参数或者梯度的相似性,这是十分耗费服务器计算资源的。除此之外,以往的个性化联邦学习都忽略模型的可重复利用。新的客户端如果想要得到一个个性化模型需要从头开始训练,这通常造成计算资源极大的浪费。为了解决上述问题,本文提出了一种可以为服务器节省计算开销的动态聚类个性化联邦学习算法,并且提供了一个模块组合策略来提高模型利用率。
1 方案设计
1.1 框架设计
本文框架由服务器和客户端两大部分构成。根据动态聚类个性化联邦学习算法和模块可组合策略,本文将客户端进一步分为两类:一类是训练客户端,另一类是测试客户端。在动态聚类个性化联邦学习算法中,训练客户端和服务器被用于训练出若干个组模型。在可组合策略中,测试客户端(新客户端)需要对动态聚类个性化联邦学习算法中生成的若干个组模型作为模块进行筛选并组合。动态聚类个性化联邦学习算法的优化目标可以表示为:
其中,m表示动态聚类个性化联邦学习算法得到的模块数量。ℒi表示i-th训练客户端本的损失函数,Di则表示i-th客户端本地数据集。模块组合策略的优化目标可以表示为:
其中,ℒtest表示测试客户端本地的损失函数。Dtest则表示测试客户端本地数据集。
1.2 动态聚类个性化联邦学习算法
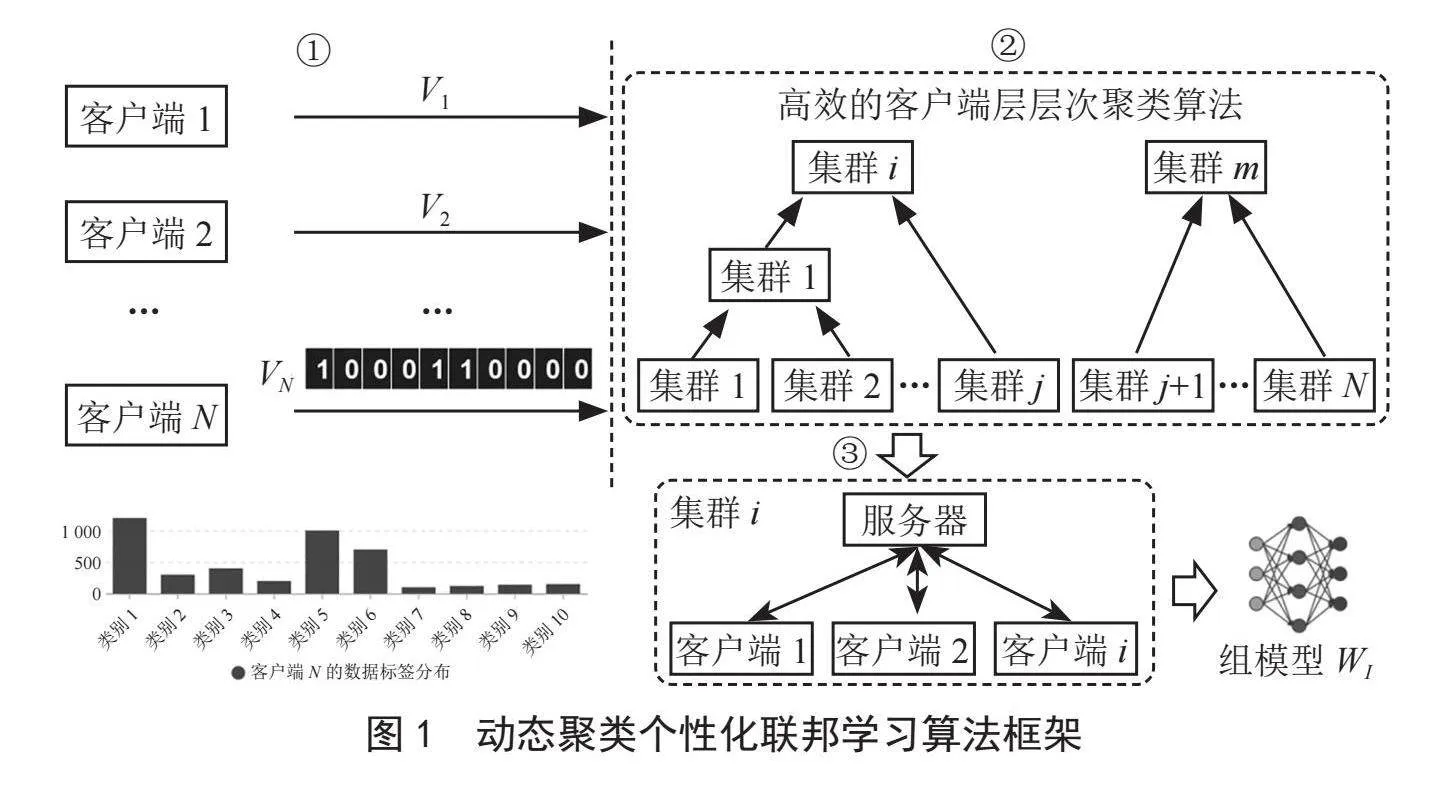
动态聚类个性化联邦学习算法使用层次凝聚聚类对数据异构的客户端进行动态分组。为了节省计算开销,我们通过衡量优化目标向量之间的相似性来代替衡量模型参数之间相似性,算法框架如图1所示。
第一阶段:客户端会生成一个优化目标向量Vi,该向量长度和全局数据集类别数量一致。如果客户端第j个类别数据占比高,客户端Ci会将Vi的第j维度设置为1,否则设置为0。在这里我们预先设置一个k值,客户端将本地数据占比最高的前k个类别对应的优化目标向量维度设置为1。随后客户端将优化目标向量上传到服务器。需要注意的是,客户端仅需要向服务器传输一次优化目标向量。
第二阶段:服务器在接收客户端的优化目标向量后首先对客户端进行分组。为了描述清晰,这里我们将服务器分组过程划分为三步:1)服务器计算每个簇的优化目标向量。具体来说,服务器对一个簇中的客户端优化目标向量加和,然后对加和后的结果取前k个最大值并将其对应的维度设置为1,其他维度设置为0。2)计算每个簇之间优化目标向量的相似度s。具体来说,服务器对任意两个簇的优化目标向量并进行按位与操作,最后服务器记录按位与结果中每一维的值相加来作为簇之间的相似度s(1≤s≤c,s ∈ Z),c表示全局数据集样本类别数量。3)服务器合并相似度最大的两个簇,并按照上一步计算新簇的优化目标向量。重复上述步骤直到簇之间的最小相似度满足s≤a,a是一个预先设定的值,停止组的合并得到m个分组。
第三阶段:随后对于同一组中的客户端进行联邦训练。具体来讲,在t-th轮服务器和客户端交互中,服务器将组模型 下发给客户端ci,客户端ci在本地数据集 上通过随机梯度下降算法对本地模型进行更新:
其中,ℒ表示本地的交叉熵损失函数,η表示学习率。然后,客户端将更新后模型 上传到服务器进行聚合:
其中,|C|表示当前客户端集群的大小。服务器和客户端持续上述操作直到模型收敛。
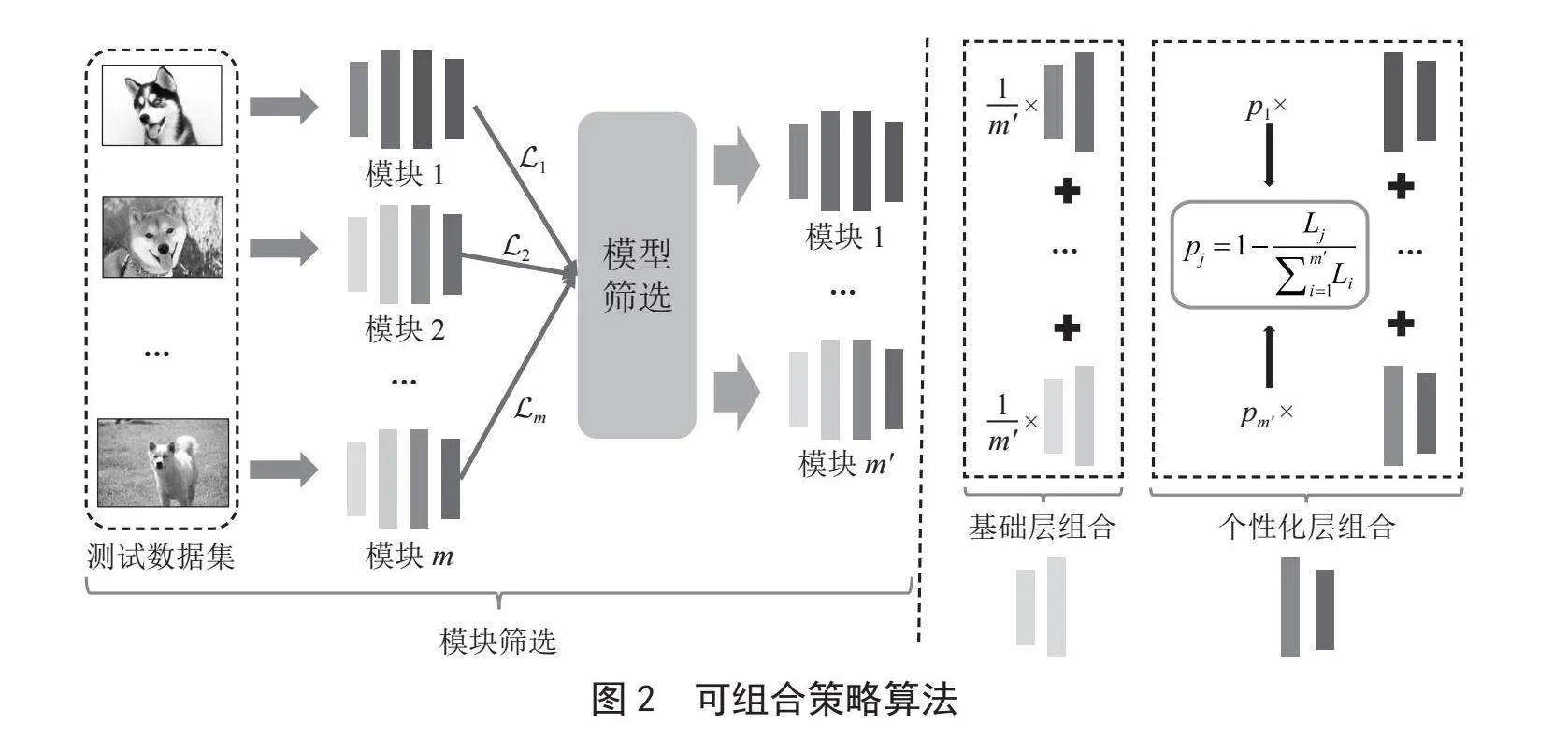
1.3 模块组合策略
测试客户端通过模块组合算法负责将训练好的m个组模型进行筛选和组合。如图2所示,测试客户端首先从服务器获取m个组模型w1,w2,…,wm,并利用本地的测试集对m个模块分别计算损失L1,L2,…,Lm。测试客户端依据计算损失从小到大对组模型进行排序。取m'个损失最小的模块w1,w2,…,wm',m'≤m。测试客户端对这m'个模块进行聚合。在本地更新阶段,需要将组合后的模型作为初始模型,并进行微调。这样不但节省了本地的计算开销,同时能够提升本地模型的性能。这是因为,这m'个模型都和本地任务具有一定的相关性,并且这些模块在此之前都在更为丰富的数据集上进行了训练。
为了进一步减少测试客户端计算开销,我们从模型参数解耦角度出发将m'个模块分为“基础层+个性化层”(靠近输入层部分的模型称为基础层wbase,靠近输出层部分的模型称为个性化层wperson)。在深度学习过程中,基础层被认为用于公共特征的提取,而个性化层则被用于本地任务的个性化决策。在模块聚合时,测试客户端m'个模块的前i层作为基础层并执行平均聚合操作:
对于个性化层的模型参数,测试客户端需要进行个性组合:
其中,pj表示第j个模块个性化层组合时的系数,然而如何设置pj是一个比较关键的问题,这将直接影响到组合后模型的性能。为了解决这个问题,本文提出将模块筛选过程得到的损失来作为聚合权重的依据。具体来说,损失越小意味,该模块越接近于本地的训练任务,在组合过程中对应的权重值pj应该越大。pj计算过程可以表示为:
测试客户端通过对m'个模块聚合得到的模型wnew,可以表示为:
测试客户端利用本地的数据集通过预先设定好学习率η的随机梯度下降对wnew进行微调。由于对 聚合时,不同模块的公共层是近似的,为了减少本地模型训练的计算开销,测试客户端仅对聚合后的个性化层 进行更新:
2 实验分析
2.1 实验设置
在本文中,我们选取Minist和Cafir10作为实验数据集。Minist是一个10分类的手写字体图片数据集,总共有70 000张样本。Cafir10是一个10分类的图片数据集,总共有60 000张样本。这两个数据集在训练客户端上是非独立同分布的。本文在两个数据集上均设置20个训练客户端。遵循常见的数据异构实验设置[8],预先将这些客户端划分为4个组,服务器选取2~3个类别的样本被分配给每个组的训练客户端。所有的数据都被拆分为70%的训练集和30%的测试集。本文选取Letnet-5深度神经网络来训练Minist数据集和CAFIR-10数据集。Letnet-5由两层卷积层、两层池化层以及三层全连接层构成。此外,随机选取2~3个类别测试客户端的本地数据集。为了公平,测试客户端本地数据集样本数量和训练客户端本地数据集样本数量保持一致。服务器与客户端交互次数我们设置为150轮,本地客户端更新周期e设置为5。学习率η设置为0.01,动态聚类阈值a设置为1。
2.2 个性化联邦学习算法性能评估
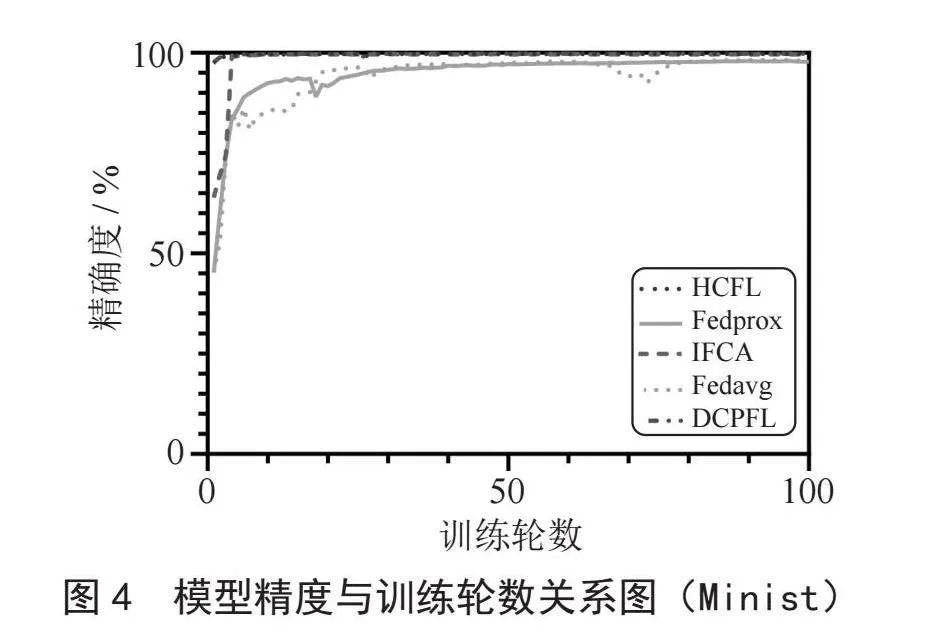
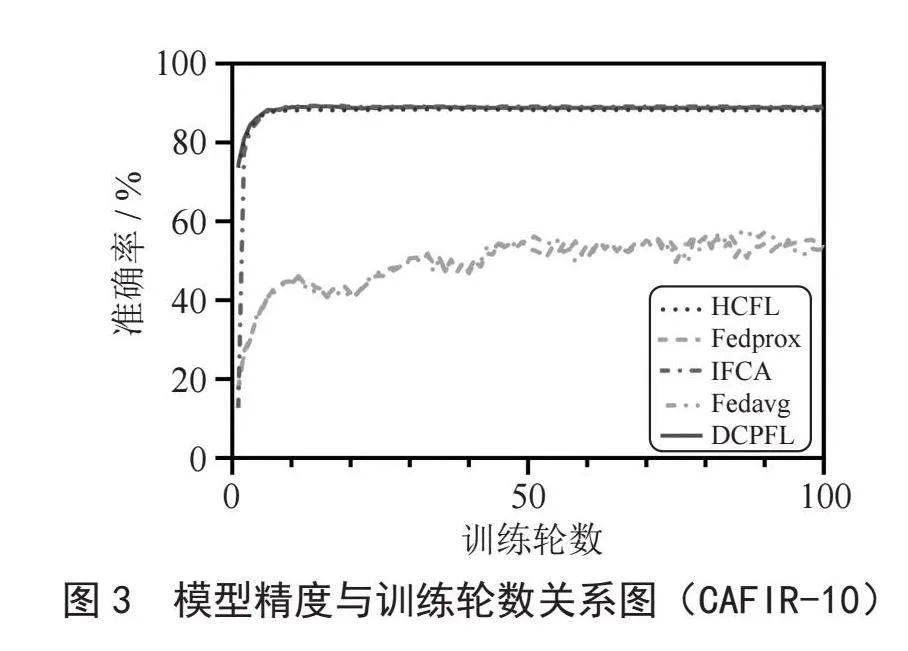
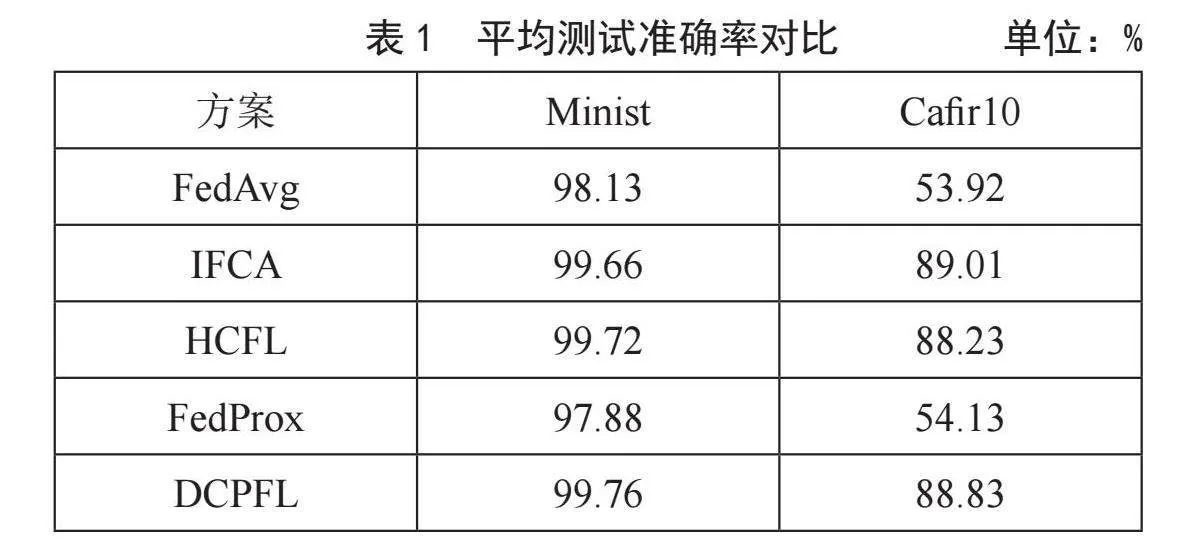
在本节中我们通过与本地训练算法(Local)、联邦平均算法(Fedavg)[1]以及流行的迭代联邦聚类算法(IFCA)[8]、正则损失联邦学习算法(fedprox)[5]、层次聚合联邦学习算法(HCFL)[11]进行了模型的准确度对比,来说明我们动态分组聚类算法(DCPFL)的有效性。如表1所示,我们将上述算法得到的模型测试精度进行了对比。从图3和图4中不难看出,在明显的客户端数据差异下,我们的方案要优于其他大部分的个性化学习方案。此外我们发现,DCPFL和HCFL收敛得更快,这是因为两者预先对客户端集群完成了划分,同一集群内数据异构性显著下降进而导致模型收敛速度要优于其他方案。
尽管IFCA和FLHC在精确度上与DCPFL精度接近,但是DCPFL每次每个客户端仅需要传输一个模型即可,IFCA需要传输K个模型(K与预先设定的组的数量相关,在这里我们预先设置K = 4),因此相对于IFCA,DCPFL更节省通信开销。因为HCFL需要通过计算模型参数之间的相似性进行层次聚类,而DCPFL仅需要依靠本地的优化目标向量的相似便可以完成聚类。不难发现优化目标向量远小于模型参数向量,因此DCPFL将比HCFL客户端分组算法更节省计算开销。
2.3 模块组合策略性能评估
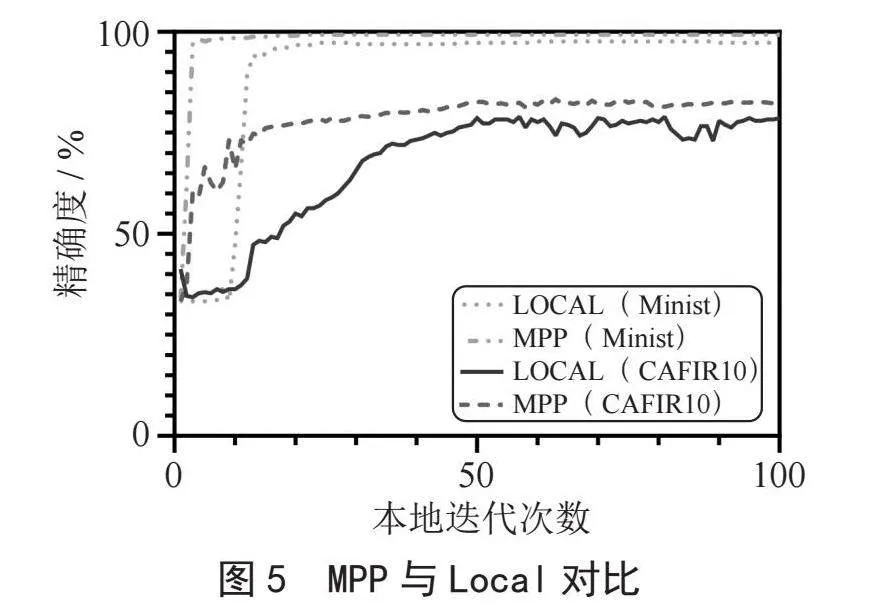
在本节,为了验证模块组合策略有效性,我们将测试客户端采用模块组合策略训练过程和本地训练过程进行了对比。从图5中可以看出模块组合策略下客户端模型收敛得更快,并且最终模型的准确率更高。由于相对本地更新全部的模型参数来讲,模块组合策略仅需要更新个性化层参数,这样不仅使得本地模型性能有了提升,还极大节省了客户端计算开销。
3 结 论
在本文中,我们提出了动态客户端聚类个性化联邦学习算法和模块组合策略,来提高数据异构场景下模型的可用性和可重复利用性。相对于经典的个性化联邦学习算法,我们不仅提高了模型精确度,同时极大节省了服务器和新客户端的计算开销。然而,本文提出的聚类算法目前仅适合客户端数据差异明显的简单场景。并且模块组合策略要求新的客户端的任务和训练模块的任务接近。因此在未来工作中,我们将进一步改进客户端聚类算法和模块组合策略,以适合更为复杂的数据异构场景和实现不同领域任务下的知识迁移。
参考文献:
[1] MCMAHAN B H,MOORE E,RAMAGE D,et al. Communication-Efficient Learning of Deep Networks from Decentralized Data [J/OL].arXiv:1602.05629 [cs.LG].(2023-01-23)[2023-11-20].https://arxiv.org/abs/1602.05629.
[2] TERRAIL J O,AYED S S,CYFFERS E,et al. FLamby: Datasets and Benchmarks for Cross-Silo Federated Learning in Realistic Healthcare Settings [J/OL]arD3K3QSY+lDrXVx8V8KOkxTITapOBWpYHhRZzsd9ISjc=Xiv:2210.04620 [cs.LG].(2023-05-05)[2023-11-20].https://arxiv.org/abs/2210.04620.
[3] KHAN L U,SAAD W,HAN Z,et al. Federated Learning for Internet of Things: Recent Advances, Taxonomy, and Open Challenges [J].IEEE Communications Surveys & Tutorials,2021,23(3):1759-1799.
[4] SUN W,LEI S Y,WANG L,et al. Adaptive0YJ1MMDr40pjfFRhPEOfe2TRhxOaZSEY7PPJ6F8+gWI= Federated Learning and Digital Twin for Industrial Internet of Things [J].IEEE Transactions on Industrial Informatics,2020,17(8):5605-5614.
[5] LI T,SAHU A K,ZAHEER M,et al. Federated Optimization in Heterogeneous Networks [J/OL]. arXiv:1812.06127 [cs.LG].(2020-04-21)[2023-11-20].https://arxiv.org/abs/1812.06127v5.
[6] ARIVAZHAGAN M G,AGGARWAL V,SINGH A K,et al. Federated Learning with Personalization Layers [J/OL].(2019-012-02)[2023-11-26].https://arxiv.org/abs/1912.00818.
[7] HUANG T S,LIU S W, SHEN L,et al. Achieving Personalized Federated Learning with Sparse Local Models [J/OL].arXiv:2201.11380 [cs.LG].(2022-02-27)[2023-11-26].https://arxiv.org/abs/2201.11380.
[8] GHOSH A,CHUNG J C,YIN D,et al. An Efficient Framework for Clustered Federated Learning [J].IEEE Transactions on Information Theory,2022,68(12):8076-8091.
[9] LI C X,LI G,VARSHNEY P K. Federated Learning With Soft Clustering [J].IEEE Internet of Things Journal,2022,9(10):7773-7782.
[10] SATTLER F,MÜLLER K R,SAMEK W. Clustered Federated Learning: Model-Agnostic Distributed Multitask Optimization Under Privacy Constraints [J].IEEE Transactions on Neural Networks and Learning Systems,2021,32(8):3710-3722.
[11] BRIGGS C,FAN Z,ANDRAS P. Federated Learning with Hierarchical Clustering of Local Updates to Improve Training on Non-IID Data [C]//2020 International Joint Conference on Neural Networks (IJCNN).Glasgow:IEEE,2020:1-9.
作者简介:周洪炜(1998.12—),男,汉族,山东潍坊人,硕士在读,研究方向:联邦学习、机器学习;马源(1997.05—),男,汉族,山东青岛人,硕士在读,研究方向:联邦学习、机器学习;马旭(1985.05—),男,汉族,山东济宁人,教授,博士,研究方向:电子信息、机器学习隐私保护、联邦学习。
