
基于GAN与轴向区块注意力的心脏磁共振图像分割
2024-09-19 00:00:00王博胡怀飞
现代信息科技 2024年13期



摘 要:心脏磁共振图像分割对心功能分析和心脏疾病诊断具有十分重要的意义。针对传统心脏分割方法对心脏MR图像特征提取不全面,以及基于注意力机制的深度学习方法参数量过大的问题,设计一种基于GAN与轴向区块注意力的心脏磁共振图像分割模型,对图像特征进行多尺度、全方面地提取,结合GAN策略提升模型性能。实验结果表明,模型实现了图像的有效分割并提高了分割结果与真实标签之间的一致性。
关键词:图像分割;GAN网络;注意力机制;磁共振图像
中图分类号:TP391.4 文献标识码:A 文章编号:2096-4706(2024)13-0046-06
Cardiac Magnetic Resonance Image Segmentation Based on
GAN and Axial Block Attention
WANG Bo, HU Huaifei
(South-Central Minzu University, Wuhan 430074, China)
Abstract: Cardiac magnetic resonance image segmentation is of great significance for cardiac function analysis and cardiac disease diagnosis. Aiming at the problem that traditional cardiac segmentation methods can not fully extract features from cardiac MR images, and the Deep Learning method based on the Attention Mechanism has too many parameters. A cardiac magnetic resonance image segmentation model based on GAN and axial block attention is designed to extract image features at multiple scales and in all aspects, and combined with GAN strategy to improve model performance. Experimental results show that the model achieves effective segmentation of images and improves the consistency between segmentation results and real labels.
Keywords: image segmentation; GAN network; Attention Mechanism; magnetic resonance image
0 引 言
我国居民心血管疾病流行趋势明显,心血管疾病的发病人数持续增加[1]。磁共振(Magnetic Resonance, MR)技术能够得到清晰的组织结构图,使心功能分析在临床实践中变得更加精准全面[2]。由于患者MR图像数量庞大,临床医师在阅片上需要耗费大量的时间和精力[3]。如何避免主观因素影响实现高效准确地分割MR图像成为难题。
1 相关研究
卷积神经网络的应用不仅避免了主观影响,还加快了MR图像的分割速度。但卷积核具有局限性,无法有效获取长距离的依赖关系,限制了图像特征的表达能力。注意力机制(Attention Mechanism)通过动态学习模型的感兴趣区域,合理分配模型的权重,提升了模型的表达能力和整体性能,打破了卷积神经网络模型在特征提取方面的局限性。
Chen等[4]首次将自注意力机制引入医学图像分割任务,在U-Net模型中使用Transformer对所提取的特征信息进行全局编码,丰富了图像全局底层细节信息。Wang等[5]引入位置编码对全局信息进行编码,对自注意力模块进行降维操作,有效降低了网络模型的计算复杂度。Valanarasu等[6]在文献[5]的基础上向全局位置编码增加门控单元(Gated Unit),提出了轴向门控注意力(Axial Attention),通过控制信息流动约束了信息传递,对自注意力机制进行了改进。Tu等[7]使用网格注意力模块提取全局特征信息,结合区块注意力(Block Attention)模块提取局部特征信息,有效提升了模型对特征的提取表达能力。Rahman等[8]使用深度监督策略分别对模型进行并联、级联训练,所提出的逐级特征融合策略在得到深层特征信息的同时实现了模型间的信息交互,增强了模型对特征的表达能力。Tragakis等[9]提出一种全卷积Transformer模型(Fully Convolution Transformer, FCT),该模型在解码阶段引入自注意力结构,能够提取到长程语义依赖,结合逐级特征融合策略[8]将不同分辨率的特征图进行融合,进一步提升了模型的分割性能。
Goodfellow等[10]借鉴博弈论(Game Theory)思想提出生成对抗网络模型,通过生成器与鉴别器之间的博弈,训练模型预测出更加符合真实数据分布的结果,显著提升了预测的准确性和合理性。Kohl等[11]首次将生成对抗网络应用于医学图像分割领域,该模型的预测结果更加合理。Peiris等[12]采用双视图半监督对抗训练实现了医学图像的精准分割。Qi等[13]提出一种级联条件GAN模型,该模型级联两个多尺度特征融合模型作为生成器,实现了双心室的分割。
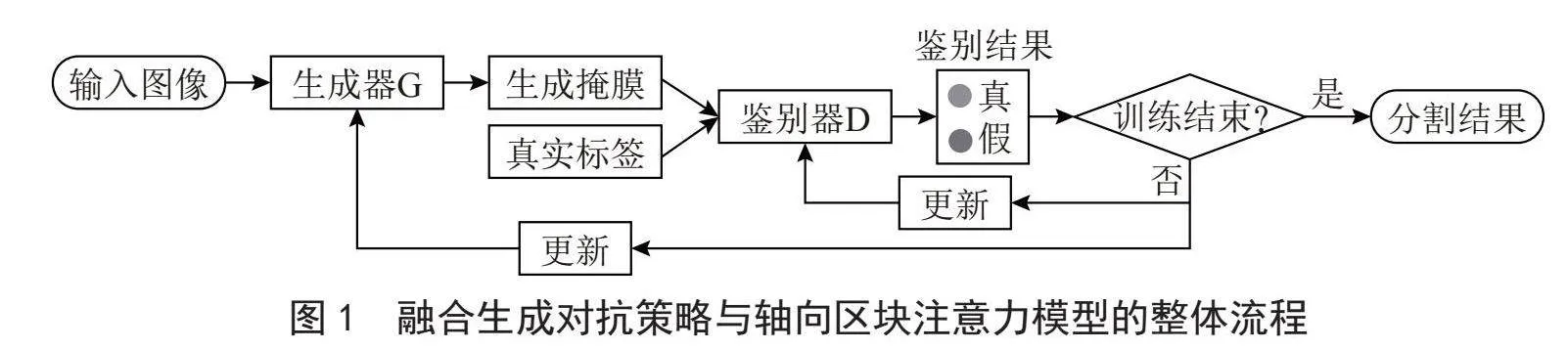
本文针对心脏MR图像特征提取不全面、使用注意力方法参数量大、计算量高的问题,提出一种基于GAN与轴向区块注意力的心脏MR图像分割模型,模型的整体框架如图1所示。该模型采用轴向门控注意力和区块注意力相结合的方式提取图像的全局代表性特征和局部代表性特征,并融合生成对抗策略协助模型进行学习数据的分布。该模型有效解决了图像特征提取不全面的问题,增强了分割结果与真实标签之间的一致性,提升了模型的特征提取能力和分割性能。
2 材料与方法
如图1所示,首先,将待分割的MR图像发送至由轴向门控注意力和区块注意力组成的生成器G,生成预测的分割结果B。其次,计算分割结果B与对应真实标签A之间的损失,并反馈给生成器。再次,将真实标签A与分割结果B一起送入鉴别器D中鉴别二者数据分布的一致性。将鉴别结果作为模型的损失,分别反馈给生成器和鉴别器以便更新各自模型的参数,重复此过程直至训练结束。
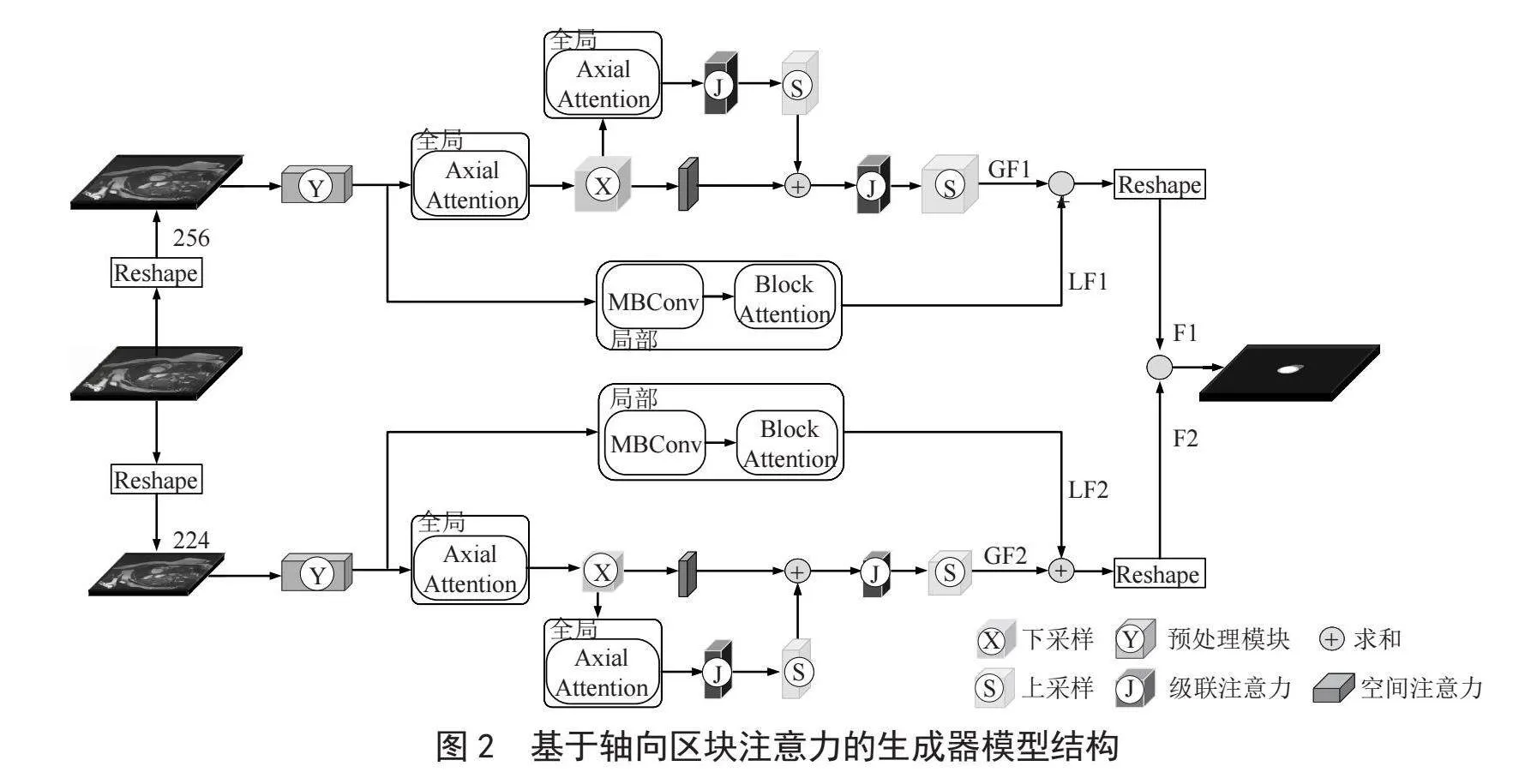
2.1 基于轴向区块注意力的生成器模型
基于轴向区块注意力的生成器模型结构如图2所示,将输入的心脏MR切片图像尺寸调整为256×256像素和224×224像素,分别送入两个结构相同的网络中并行训练。对于尺寸为256×256像素的图像,首先图像经过预处理模块后进行下采样操作。接着,使用轴向门控注意力[6]提取图像的全局特征信息,并使用逐级特征融合策略[8]融合提取到的特征信息,得到图像的全局特征信息GF1。同时,使用MBConv [14]模块对下采样的结果进行处理后,使用区块注意力[9]提取图像的局部特征信息,得到图像的局部特征信息LF1。接着,将提取到的全局特征信息GF1与局部特征信息LF1进行融合,再次调整图像的尺寸得到网络的输出结果F1。同理,对224×224像素的图像进行处理可得到结果F2。最后,将两个结果F1和F2进行融合,得到预测的分割结果。
2.1.1 轴向门控注意力
轴向注意力原理如图3(a)所示,设图像大小为M×M像素。轴向注意力对图中某点P的全局注意力是通过计算以点P为中心,横向一行与纵向一列的像素点得到的。与传统注意力机制相比,计算量由整幅图像降为横向与纵向两个轴上,即将全局注意力的计算量由M 2降低为2M,大大降低了模型的计算复杂度。同时,轴向门控注意力在轴向注意力的基础上增加了门控单元,动态调整轴向注意力的权重信息,进一步增强模型对图像全局代表性特征的提取能力,如式(1)所示:
式中,yij表示特征图中坐标为(i,j)像素点的轴向门控注意力结果,查询矩阵q = WQ×Fin,键值矩阵k = WK×Fin,值矩阵v = WV×Fin,分别由输入特征图Fin经可学习的映射矩阵WQ、WK、WV计算得到。pq、pk、pv分别表示查询矩阵、键值矩阵和值矩阵对应的位置编码项。GQ、GK、GV1分别表示作用于查询矩阵、键值矩阵和值矩阵的门控单元,GV2表示值矩阵对应位置编码的门控单元。门控单元可以不断地学习调控,增强模型的特征提取能力。
2.1.2 区块注意力
区块注意力原理如图3(b)所示,对输入特征图像进行区块划分,将整幅图像(M×M像素)划分为若干子图像块(m×m像素,m可被M整除)。通过分块的形式降低了模型的计算尺度,从而降低了计算复杂度,如式(2)所示:
式中,yo表示坐标为o (i,j)像素点的区块注意力结果,Nm×m表示一个子图像块中像素点的集合,e表示该子图像块中任意位置的像素点。当输入的图像尺寸不同时,可根据图像大小自由调节m的取值,调整区块注意力的作用范围,进而调整局部特征提取模块的性能。
2.2 鉴别器模型
鉴别器采用卷积神经网络,由二维卷积层、批归一化层与激活函数组成。计算分割结果B与真实标签A的交叉熵,用于更新生成器模型的参数。同时,将分割结果B与“假标签0”进行对比学习,将真实标签A与“真标签1”进行对比学习,学习得到的交叉熵加权求和,所得结果用于更新鉴别器模型的参数。通过上述学习策略,使鉴别器参与对生成器分割质量的调控,并且使鉴别器模型具备鉴别分割结果“真伪”的能力。
2.3 损失函数
实验中采用DICE损失和交叉熵损失(Cross Entropy, CE)度量真实标签A与生成器分割结果B之间的相似程度。
DICE损失即是通过计算真实标签A和分割结果B的未重叠率来衡量分割的准确性,如式(3)所示:
式中,| A ∩ B |表示二者重叠的区域,即分割结果预测正确的区域;| A | + | B |表示真实标签和分割结果图像的全部区域。
CE损失即是通过度量真实标签A和预测结果B数据分布之间的差异来衡量二者数据分布的一致性,如式(4)所示:
式中,i表示图像中第i个类别,Ai和Bi分别表示对应图像中第i个类别的概率。
2.3.1 生成器损失
生成器的损失函数由上述两种损失的线性组合构成,如式(5)所示:
式中,λ1、λ2与ω均表示可学习权重,且∑ λ = 1, 、 分别表示由生成器和鉴别器计算真实标签A与分割结果B的CE损失,LDICE则表示由生成器计算真实标签A与分割结果B的DICE损失。
2.3.2 鉴别器损失
鉴别器的损失函数由鉴别器训练得到的两部分CE损失共同构成,如式(6)所示:
式中,θ1、θ2均表示可学习权重,且∑θ = 1,LCE0表示由分割结果B和“假标签0”计算得到的CE损失。LCE1表示由真实标签A与“真标签1”计算得到的CE损失。
2.4 评价指标
通常采用DICE系数(DICE Coefficient)和豪斯多夫距离(Hausdorff Distance, HD)来评估模型的分割性能。
DICE系数表明图像重叠的程度,其值介于0~1之间,越接近于1表明分割结果B与真实标签A越相似,分割结果越准确,如式(7)所示:
HD通过计算两集合边界的最大距离来评估分割边界的一致性。HD越小表明两集合之间的边界越接近,一致性越强;反之表明两集合之间边界越疏远,一致性越弱,如式(8)所示:
式(9)表示计算真实标签A中任意点a到预测分割结果B中所有点的最小距离。接着,比较真实标签A中所有点的最小距离,选出最大值作为真实标签A到分割结果B的最大距离h(A,B)。同理,h(B,A)可求出分割结果B到真实标签A的最大距离。式(8)中的H(A,B)表示HD的值,取h(A,B)和h(B,A)中的最大值。
3 实验测试
3.1 实验数据集和实验相关配置
本实验所用数据集是由心脏分割挑战赛(Automated Cardiac Diagnosis Challenge, ACDC)提供的心脏MR图像[15]。该数据集是由150位患者舒张期(End Diastole, ED)和收缩期(End Systole, ES)的心脏MR图像以及对应的真实标签图像所构成。数据集中包括正常群体、既往心梗患者、扩张型心肌患者、肥厚型心肌患者和右心室异常患者的心脏MR图像,共五个医疗组,每个医疗组30例图像。每例MR图像的二维切片数量在9~18之间,对应的真实标签图像包括右心室(Right Ventricle, RV)、心肌(Myocardium, MYO)、左心室(Left Ventricle, LV)和背景四类标签。
数据集的划分如下:训练集包括五个医疗组各18例共计90例心脏MR图像,验证集包括五个医疗组各2例共计10例心脏MR图像,测试集使用官方挑战赛固定的五个医疗组各10例共计50例心脏MR图像。在训练前对所有待使用的MR图像进行切片和图像尺寸标准化预处理,通过裁剪和填充将图像修改为256×256像素。所有实验均在原始数据量的前提下进行,分别对舒张期和收缩期两个阶段预处理后的图像进行训练和验证。
本实验使用的是基于PyThorch框架搭建的网络模型,训练过程中分别将生成器和鉴别器的学习率设定为0.000 1和0.000 05,且分别使用Adam优化器和RMSprop优化器。Axi_Block表示仅使用轴向区块注意力模型作为生成器的模型;Axi_Block_GAN表示使用Axi_Block作为生成器并加上鉴别器的完整模型。
3.2 实验结果
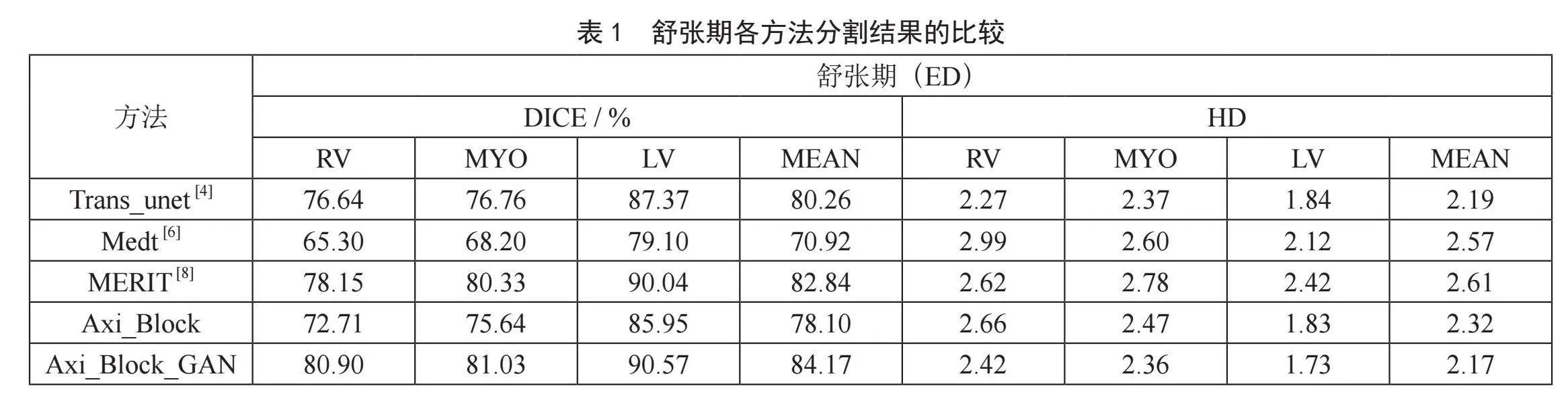
表1是所提模型与其他模型在心脏舒张期图像分割结果上的对比。实验结果表明:本文模型的右心室、心肌和左心室分割结果的DICE系数均高于其他方法,HD整体较好。心脏分割的平均DICE系数为84.17%(0.04),平均HD为2.17(0.54)。本文方法的分割精度优于其他方法,且分割的一致性最好。
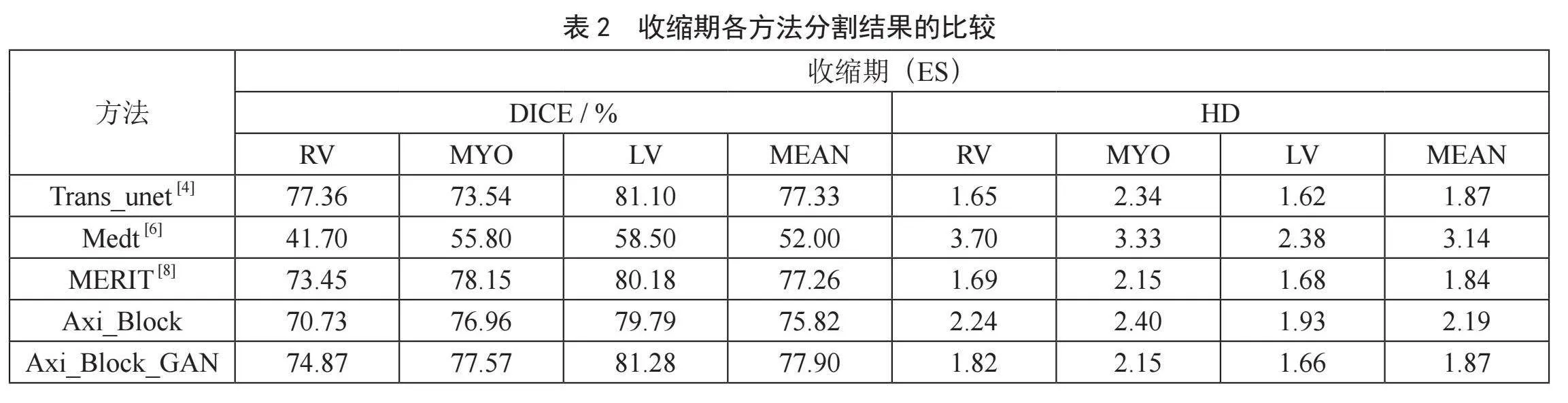
表2是所提模型与其他模型在心脏收缩期图像分割结果上的对比。实验结果表明:分割结果的DICE系数较好为77.90%(0.04),平均HD略高于其他方法为1.87(0.71)。本文方法的分割精度优于其他方法。
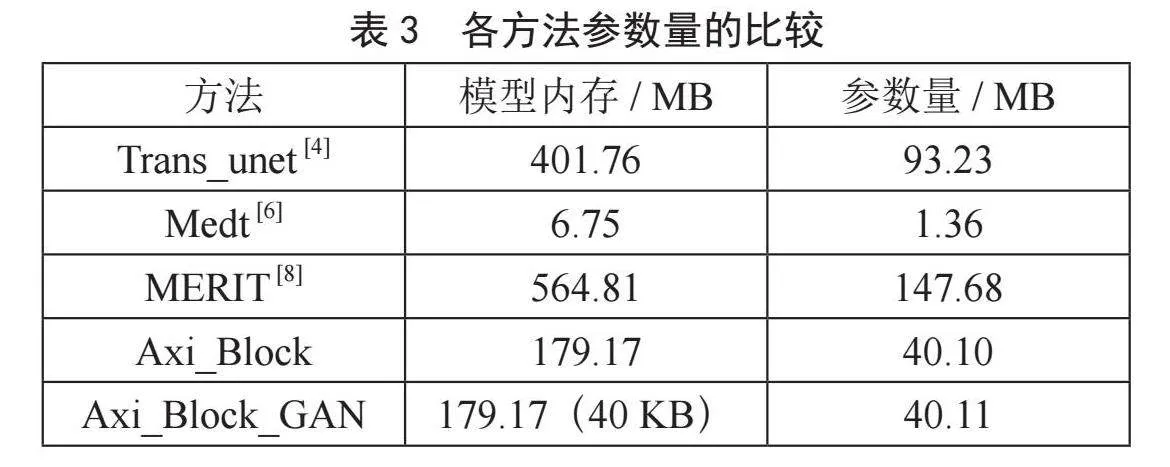
表3是各方法模型内存与参数量的比较。由Medt模型的实验数据可知,参数量与模型性能成正相关。本文方法在较少参数量的情况下表现出较好的性能,实验验证了本文方法的有效性与优越性。括号内为鉴别器模型所占内存大小。
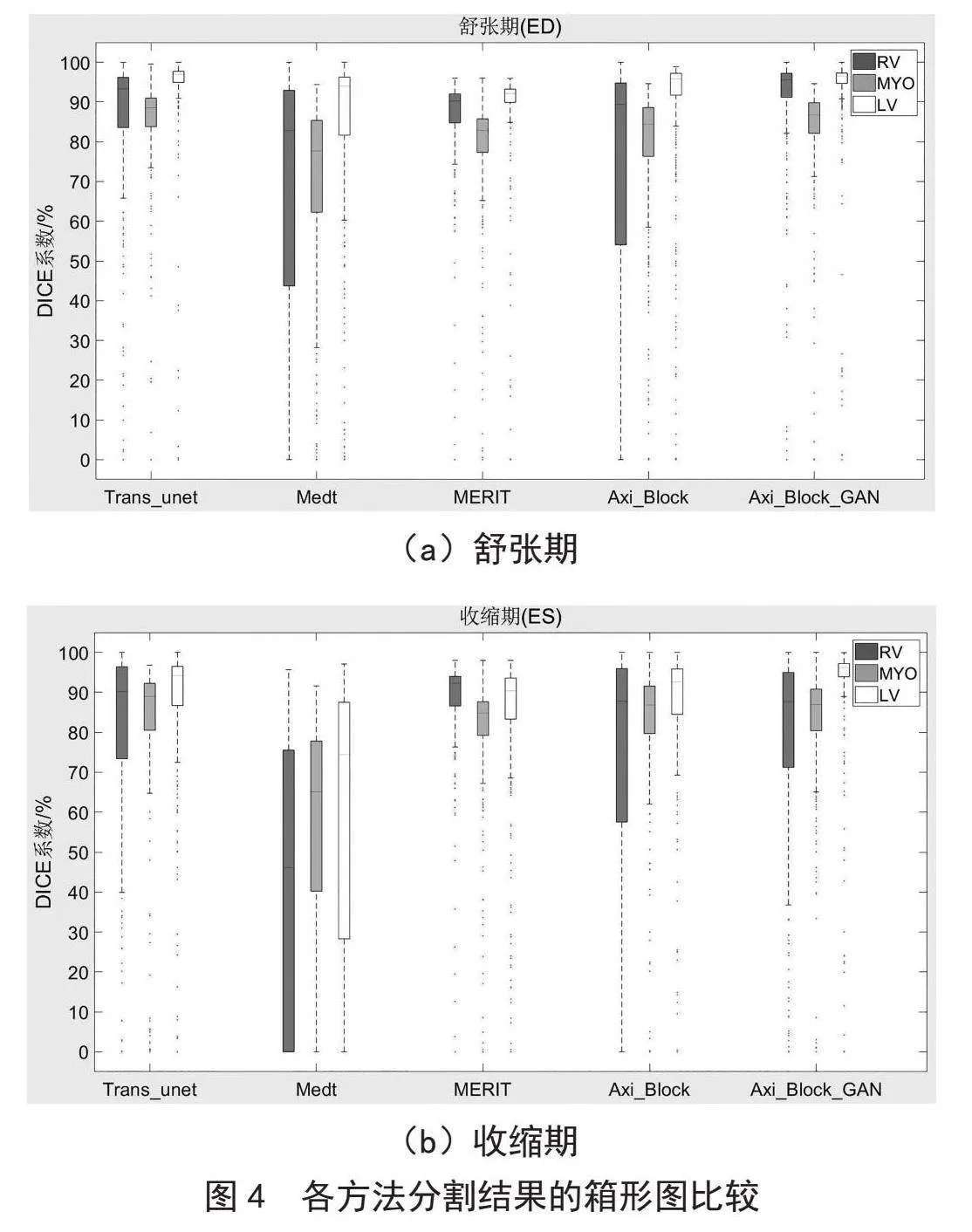
图4为上述各方法在舒张期和收缩期分割结果的箱形图比较。从图4(a)中可以看出,在舒张期本文方法具有较强的分割性能且整体更加稳定;从图4(b)中可以看出,在收缩期本文方法整体性能较好,且左心室分割效果最优。
表4是本文方法与其他方法分割结果的对比。标签图由左心室(白色部分)、心肌(浅灰色部分)、右心室(深灰色部分)和背景(黑色部分)组成。从对比图中可以看出,本文方法的结果与金标签图像更为接近,且各标签分割结果连续无细小伪影,整体的分割效果更加接近金标签更好。
4 结 论
采用轴向门控注意力提取图像的全局特征,结合区块注意力提取图像的局部特征,二者组合使用有效降低了模型的参数量,同时也充分提升了模型的特征提取能力;结合多尺度特征信息融合策略,得到更加丰富、全面的特征信息;使用生成对抗策略生成一致性更好的分割结果。实验结果表明,所提模型性能较好,分割结果准确且稳定。
参考文献:
[1] 陈伟伟,高润霖,刘力生,等.《中国心血管病报告2017》概要 [J].中国循环杂志,2018,33(1):1-8.
[2] KRAMER C M,BARKHAUSEN J,BUCCIARELLI-DUCCI C,et al. Standardized Cardiovascular Magnetic Resonance Imaging (CMR) Protocols: 2020 Update [J].Journal of Cardiovascular Magnetic Resonance,2020,22(1):1-18.
[3] LI Y Z,WANG Y,HUANG Y H,et al. RSU-Net: U-net Based on Residual and Self-attention Mechanism in the Segmentation of Cardiac Magnetic Resonance Images [J].Computer Methods and Programs in Biomedicine,2023,231:107437-107437.
[4] CHEN J N,LU Y Y,YU Q H,et al. Transunet: Transformers Make Strong Encoders for Medical Image Segmentation [J/OL].arXiv:2102.04306v1 [cs.CV].[2023-11-16].https://arxiv.org/abs/2102.04306.
[5] WANG H Y,ZHU Y K,GREEN B,et al. Axial-Deeplab: Stand-alone Axial-Attention for Panoptic Segmentation [C]//European Conference on Computer Vision. [S.I.]:Springer,2020:108-126.
[6] VALANARASU J M J,OZA P,HACIHALILOGLU I,et al. Medical Transformer: Gated Axial-attention for Medical Image Segmentation [C]//Medical Image Computing and Computer Assisted Intervention. [S.I.]:Springer,2021:36-46.
[7] TU Z Z,TALEBI H,ZHANG H,et al. MaxViT: Multi-axis Vision Transformer [C] //European Conference on Computer Vision. [S.I.]:Springer,2022:459-479.
[8] RAHMAN M M,MARCULESCU R. Medical Image Segmentation via Cascaded Attention Decoding [C]//Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. [S.I.]:IEEE,2023:6222-6231.
[9] TRAGAKIS A,KAUL C,MURRAY-SMITH R,et al. The Fully Convolutional Transformer for Medical Image Segmentation [C] //Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. [S.I.]:IEEE,2023:3660-3669.
[10] GOODFELLOW I J,POUGET-ABADIE J,MIRZA M,et al. Generative Adversarial nets [C]//Proceedings of the 27th International Conference on Neural Information Processing Systems. [S.I.]:Cambridge,2014:2672-2680.
[11] KOHL S,BONEKAMP D,SCHLEMMER H P,et al. Adversarial Networks for the Detection of Aggressive Prostate Cancer [J/OL].arXiv:1702.08014v1 [cs.CV].[2023-11-06].https://arxiv.org/abs/1702.08014.
[12] PEIRIS H,CHEN Z L,EGAN G,et al. Duo-SegNet: Adversarial Dual-views for Semi-supervised Medical Image Segmentation [C]//Medical Image Computing and Computer Assisted Intervention–MICCAI 2021. [S.I.]:Springer,2021:428-438.
[13] QI L,ZHANG H R,TAN W J,et al. Cascaded Conditional Generative Adversarial Networks with Multi-scale Attention Fusion for Automated Bi-ventricle Segmentation in Cardiac MRI [J].IEEE Access,2019,7:172305-172320.
[14] HOWARD A G,ZHU M L,CHEN B,et al. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications [J/OL].arXiv:1704.04861v1 [cs.CV].[2023-11-09].http://www.arxiv.org/abs/1704.04861 2017.
[15] BERNARD O,LALANDE A,ZOTTI C,et al. Deep Learning Techniques for Automatic MRI Cardiac Multi-Structures Segmentation and Diagnosis: Is the Problem Solved? [J].IEEE Transactions on Medical Imaging,2018,37(11):2514-2525.
作者简介:王博(1999—),男,汉族,河南安阳人,硕士研究生在读,研究方向:医学图像处理与人工智能。
