
基于网络爬虫的高校网络舆情分析系统设计
2024-09-18 00:00:00系统设计
电子产品世界 2024年7期



摘要:网络舆情是指公众在互联网上对热点事件或普遍关注的问题的讨论现象,此现象实质上是现实社会情况的在线映射,将公众的观念和态度延伸至数字领域。目前,学生群体对网络舆情的关注度持续升高,但现有的舆情分析机制在效率和稳定性方面存在局限。基于此,构建了高校网络舆情分析系统,利用网络爬虫技术,自动收集并过滤学生在网上的讨论信息,有效监测舆情态势,以实现更为精准的管理和响应。
关键词:网络爬虫;高校;网络舆情
中图分类号:TP391.1;TP274 文献标识码:A
0 引言
高校校园网络发展的同时,大学生也受到了网络带来的负面影响。因此,高校应深入研究并制定科学、合理的网络舆情引导策略,以确保网络环境对大学生的负面影响得到有效控制[1]。为实现这一目标,开发基于网络爬虫技术的高校网络舆情分析系统显得尤为重要。该系统旨在对学生上网行为进行严谨的数据采集、清洗、去重和深度分析,为高校管理提供有力的数据支撑,以便及时制定应对策略[2]。
1 系统需求分析
网络舆情分析系统是专门在网络上搜集大家关心的舆情信息的工具。其工作原理为:①用户注册与权限管理。用户需按照规定流程进行账号注册,并完成身份验证以确保信息安全。注册成功后,用户需登录系统,根据个人权限进行数据管理和操作。②赋予网络爬虫配置,允许用户根据实际需求设定初始统一资源定位系统(uniform resourcelocator,URL)、搜索策略等关键参数。同时,加强对爬虫运行的监管,确保其在合法范围内进行数据抓取和处理。③将收集的舆情数据和新网址存储到数据库,这样可以更方便地查看和分析数据。④数据更新和过滤机制。专门设置服务器负责数据采集、更新和过滤,提高信息获取速度的同时,也能保证数据收集效果。
2 系统总体框架设计。
系统主要包括4 个部分,分别为Web 数据库、URL 数据库、服务器和客户端。其中,Web 数据库用于规范地存储网络爬虫搜集的网页信息,确保其完整性和准确性。URL 数据库承担收集网页中新链接的重要职责,并将这些链接有序地纳入爬虫待抓取的任务清单中,从而确保信息的及时更新和处理。服务器则负责调度URL、采集和解析网页数据、去除重复的网页信息、管理用户等[3]。客户端是用户平时用的界面,它能让用户在不同环境下进行便捷的操作,如管理网站、查看和交换数据、网络通信等。
3 系统功能模块设计
3.1 数据采集模块
网络舆情分析系统中的数据采集模块任务是通过网络爬虫技术搜集校园论坛和其他相关网站的信息,并将这些数据集成至数据库,为后续的数据预处理环节奠定基础。网络爬虫是数据采集模块的核心,主要负责协调各个子模块之间的互动。在数据采集过程中,需要确保各个环节准确无误,并运用相应的管理算法进行优化。具体数据采集流程如下:①调度模块负责全面协调网络爬虫捕获的URL 队列,根据实际需求分配相应URL。②下载模块遵循调度模块的指引,从校园论坛或其他网站下载相应网页,进而交由数据解析环节进行后续处理。③数据解析环节汇集数据处理算法,对网页中的目标数据和可继续爬取的URL 进行精确提取,并将这些关键信息及时传输至调度模块与存储单元[4]。④存储单元将获取的目标数据纳入数据库进行规范保存,确保数据的完整性和准确性。整个数据采集流程严谨规范,为高校相关工作提供有力支持。
3.2 数据预处理模块
经过严格的数据采集后,数据预处理模块将对网页数据进行深度处理与分析。在处理过程中,通过去除网页噪声,如广告等无关信息,确保数据的精确性;同时运用哈希散列算法,对重复网页进行有效去除,以提高数据的纯净度。如果之前已经下载过相同的网页,就不再重复下载。另外,该模块负责提取网页正文和标题的特征向量,然后进行分类,再计算特征权重,最后形成特征向量矩阵[5]。总之,该模块负责在海量的网页信息中,找到真正有用的内容。
3.3 舆情分析模块
舆情分析模块是整个系统的“大脑”,通过智能算法来解析文本信息,找出敏感内容,还能对人们的观点自动分类和分析。该模块分为3 个主要部分:识别话题、追踪话题和评估话题。①在识别话题时,用经过优化的Single-Pass 聚类算法,给关键词加上权重,让识别结果更准确。②在追踪话题时,根据实际需求构建分类模型,再用评估算法检查模型是否可靠,最后使用模型去判断新网页属于哪个类别。③在评估话题中,经过缜密的专家论证与详尽的实地调研,构建一套话题评估模型。该模型依托层次分析法,对各网页数据指标在评估体系中的权重进行科学严谨的界定,再运用加权平均法,计算评估结果,并将结果录入数据库。
3.4 舆情服务与管理模块
舆情服务与管理模块致力于为使用网络舆情分析系统的普通用户及管理员提供支持,以便他们能够高效地管理和应对舆情信息,使高校可以快速掌握和分析舆情动态。管理员还可利用该模块对用户进行管理,并设定相应权限。该模块的目的是确保系统稳定、安全地运行,为用户带来优质体验。
4 关键技术研究
4.1 搜索策略
当网络爬虫抓取网页时,可以采用广度、深度和最佳优先等搜索方法。鉴于系统需求,本文采用广度优先搜索策略作为爬虫运作模式。广度搜索听起来较为复杂,但其实就像在森林里迷路时,从起始节点出发,以辐射状的方式逐层向外扩散,对周边节点进行全面系统的遍历。在数据结构的“树”模型中,广度优先搜索如同以树的根节点为起始点,严格按照树的层级结构,逐层向上、从左至右、从上至下访问各个节点,确保无一遗漏,直至完成对所有节点的遍历工作 。广度优先搜索由近及远,层层寻找,直到找到目标或者查找完所有区域。
4.2 语义分析技术
语义分析是提升网络爬虫质量与效率的关键技术,在自然语言处理(natural language processing,NLP)领域,语义分析占据核心地位,其主要目标是运用多种算法对文本内容进行深入理解和分析,包括语用、语境、词法和句法等分析。通过使用主题网络爬虫技术和语义分析,轻松处理网页上的文字信息,精准地找到用户感兴趣的内容,同时把不相关的信息都去除。在建立一个高质量的爬虫系统时,通过向量空间模型(vector space model,VSM)算法来筛选网页数据,将文本信息变成多维度的向量,让复杂的语义分析变得简单明了。通过比较这些向量的相似度来量化分析语义的相似性。
计算向量相似度所使用的余弦距离数据公式为:
式中,sim(D1,D2)为两个网页的相似度,其值处于0 和1 之间;W1k 和W2k 均为网页第 k 个关键词的权重。
在处理网页信息时,通常采用余弦相似度作为度量标准,以科学、客观的方式评估文本间的关联性。通过整合语义分析技术,提高网络爬虫的工作效率,确保所获取信息的准确性和相关性,并提供数据基础。
5 系统测试
系统开展功能试验与性能试验,以全面验证其有效性与可靠性。检验系统所应实现的各项基本功能,确保其符合预期且能稳定运行。
5.1 系统功能试验
对于系统的用户登录、退出和注销等基本功能进行测试,系统功能测试情况如表1 所示。
从表1 可以看出,系统能够精准无误地执行用户登录、退出和注销功能。在用户尝试登录的过程中,若系统判断其为初次使用者,则提示用户进行账号注册;若密码输入出现错误,系统则将协助用户重新输入或引导其找回密码。
针对网络舆情信息的采集工作,本文运用黑盒测试的方法,对网络舆情信息收集、数据库管理等相关功能进行了全面而严谨的测试。网络舆情采集试验结果如表2 所示。
从表2 可以看出,本文设计的系统能够精确响应高校需求,高效且准确地完成网络舆情信息的采集与管理工作。其各项功能运行稳定,为舆情工作提供了有力保障。
5.2 系统性能试验
经过系统功能测试以及网络舆情采集试验后,该系统在网络爬虫收集舆情信息处理方面展现出了显著的实际效能。经过VSM 算法优化处理后的舆情信息数量得到了明显增加。同时,主题网络爬虫在捕获相关网页时与主题之间具有紧密关联性,其相关系数稳定保持在0.5 以上,具有较高的主题契合度。这一研究成果为高校在舆情信息处理和主题爬虫技术方面提供了有力的支持,有助于高校更加精准、高效地收集和分析网络舆情,为高校做决策提供更加准确的数据支持。
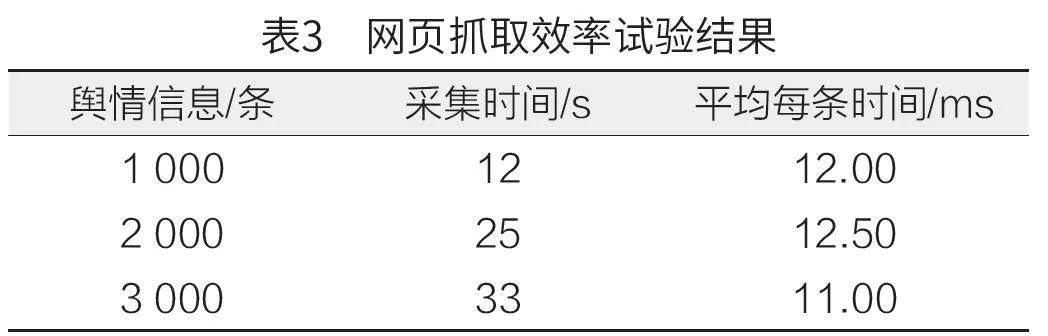
为了深入研究爬虫技术在抓取不同规模舆情信息时所需时间,对所收集舆情信息与既定主题之间的平均相似度WlDqId+UTeYBdeAhBJIjkqIcZsyGMcmEGdbYxYp0cg0=进行了科学评估,详细数据汇总如表3 所示。
由表3 可知,爬虫抓取一条舆情信息的速度大约为12 ms,这说明本文提出的系统抓舆情信息分析系统的效率较高。
6 结语
综上,本文通过运用网络爬虫技术,构建了一个针对高校的网络舆情分析系统。系统各个模块之间协同作业,确保整个系统稳定高效运行。经过基础测试,该系统能够实现舆情分析预警的各项功能。
参考文献
[1] 赵瑞丹,朱旭. 基于爬虫技术和语义分析的网络舆情采集系统设计[J]. 电子设计工程,2021,29(14):56-60.
[2] 朱琪. 基于网络爬虫的舆情分析预警系统设计[J]. 电子设计工程,2020,28(22):56-60.
[3] 沈旭,王新政,林子晴. 高校网络舆情突发事件预警系统研究与设计[J]. 现代计算机,2020(23):87-93.
[4] 杨嘉兴. 基于大数据技术下的高校舆情监测与分析[J]. 电脑爱好者(电子刊),2020(10):24-27.
[5] 曹军. 用户在网络舆情监测分析系统定制开发中的作用研究[J]. 新闻研究导刊,2023,14(17):1-4.
