
基于云计算的Hadoop大数据平台挖挖掘算法研究
2024-09-18 00:00:00曹蓉
电子产品世界 2024年7期
摘要:通过数据中心资源实现云计算虚拟化,采用资源管理技术和虚拟化分布技术处理网络中的数据,并且将网络技术和实际需求相结合,在服务用户过程中能够以服务租赁的方式实现。Hadoop 大数据平台采用分布式集群系统,其主要特点为拓展能力强、具有较高的兼容性等,在多领域中被广泛应用。因此,分析了Hadoop 大数据平台设计,将其与平台设计原理进行结合,进而实现大数据服务平台的功能。
关键词:云计算;大数据挖掘;挖掘算法
中图分类号:TP311.13 文献标识码:A
0 引言
随着智能设备的不断普及,世界信息量早已经超过ZB 级(数据中心级别),大数据时代下如何对具有潜在价值的信息进行挖掘成为目前的研究热点。数据挖掘技术的发展速度无法满足信息量爆炸式增长的需求。例如,Apriori 算法要对原本数据进行检索,导致输入/ 输出(input/output,I/O)设备的开销增加;FPGrowth 算法在频繁迭代挖掘数据时,子树结构简单,这不利于开展大数据挖掘活动。因此,本文根据大数据环境特点对数据挖掘算法进行研究[1]。
1 相关技术研究
1.1 关联规则挖掘
关联规则挖掘指的是将各事物的联系进行挖掘,在各行业中应用挖掘的数据。例如,在超市购物中能够通过交易记录对各个类型物品相关性进行寻找,对购物者的行为进行分析,根据分析结果对客户进行精准分类。在数据挖掘前需要设置最小置信度和支持数,当支持数≥最小支持数项集时,以最小置信度对有效关联规则进行分析,对所有频繁项集进行挖掘:假设项集I={i1,i2,…,in},in 表示项,事物数据集Data=(T1,T2,…,Tn),Tn 表示事物,支持度表示项集A 和B 在事物集中的频率,置信度表示项集A 发生时项集B 的发生频率。
在关联规则挖掘过程中, 主要包括5 个要素:①事件。其是数据集的基本单元,如用户的行为、商品等。②信息增益。其能够对事件集合进行衡量,从而为用户提供信息度量标准。③事件集合。事件集合都是独立运行的(运行中互不相关)。④关联规则。关联规则指的是事物之间的关系规则。⑤支持度。支持度指的是数据集中的数据挖掘频率,对事件集合进行衡量。
这些要素的关系为:关联规则挖掘的基本单位就是事件集合,能够对数据集关联的关系进行描述;信息增益与支持度能够对关联规则和事件集合进行评估;通过信息增益、支持度和事件集合能够得出关联规则[2]。
1.2 Hadoop 简介
1.2.1 HDFS
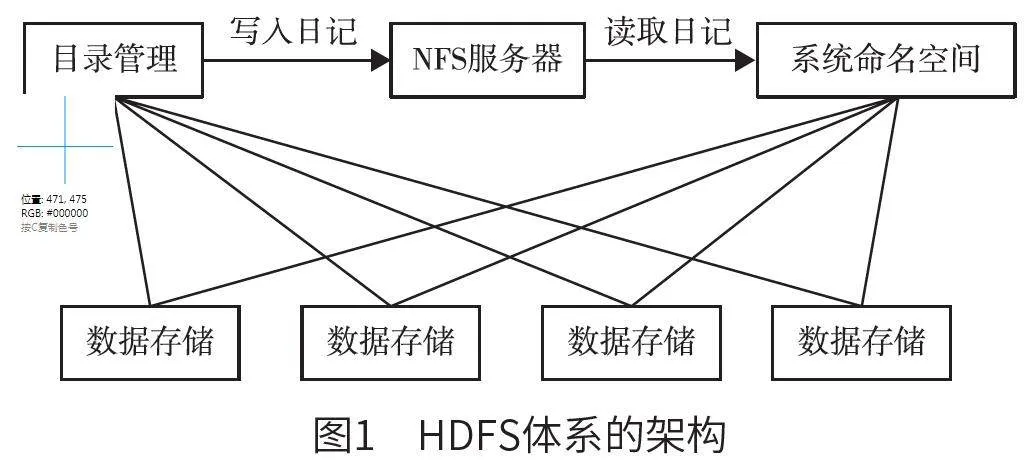
Hadoop 分布式文件系统(Hadoop distributedfile system,HDFS)为独立分布式文件系统,能够实现存储服务,并且可用性和容错性较高。根据流式数据访问实现数据节点的相互备份。存储块大小默认为6 M,用户能够自定义设置该参数。
HDFS 的结构主要包括访问客户端、数据存储和目录管理等3 个部分。其中,访问客户端为分布式文件系统应用程序;数据存储能够对系统基本单元进行存储;目录管理能够对系统空间进行命名,并且实现集群配置管理。图1 为HDFS 体系的架构。
1.2.2 MapReduce
MapReduce 为分布式计算框架,能够应用于离线大数据计算中。通过使用函数式编程模式和Reduce 函数、Map 函数,使并行计算得以实现。
1.3 Hadoop 云计算的数据挖掘
在实现数据挖掘的过程中,利用Hadoop 的集群特征对数据挖掘系统模块进行扩展,将集群并行计算和数据处理相结合,从而对数据进行有效的挖掘。Hadoop 指的是分布式系统基础架构,通过与MapReduce 编程模式相结合,完成对分布式程序的开发,充分使用集群高效存储和运算[3]。
2 基于云计算的Hadoop大数据挖掘平台
2.1 数据挖掘平台的架构
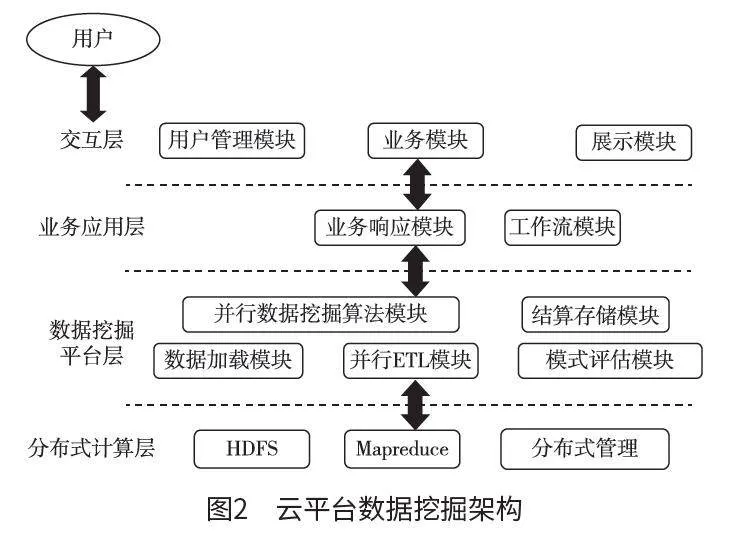
将系统的存储需求与数据异构性、繁杂性、分布性的特点相结合,实现基于Hadoop 架构的数据挖掘平台创建。基于用户需求,系统利用云计算集群平台将数据均匀分配到计算机节点中,并且针对需要处理的数据开展并行处理和分布式存储。在对存储架构进行设计时,能够使用HDFS 实现信息的收集和存储,并且针对不同应用程序编程接口(application programming interface,API)对系统的各种命令进行操作,对数据进行并行加载、存储和处理。对于需要处理的元数据进行分解和并行处理,在HBase 分布式数据库中存储数据结果。该架构基于分层思想,从上到下每层都需要透明化,使各个层都能够相互独立,从而使系统完善和扩展更加方便,图2 为云平台数据挖掘架构[4]。
(1)交互层。该层能够实现用户和系统的通信,通过图形界面使用户能够登录系统,从而能够为用户定制不同的业务,还能够查看输出结果,并且对结果进行有效保存。
(2)业务应用层。该层能够控制各业务流程,利用数据挖掘算法多模块的调用,从而实现交互层所提交的业务。该层能够处理用户提交的业务,并且对其进行调度和控制。此外,业务应用层还能够控制数据挖掘平台各模块。
(3)数据挖掘平台层。该层作为整个系统的核心,能够将数据挖掘阶段业务流的各模块提供至业务应用层中;能够实现任务算法并行化处理;还能够在业务应用层中实现结果的反馈,将任务提交到分布式计算层中。通过数据挖掘平台层能够实现的功能主要包括模式评估、数据结果展示、预处理等。
(4)分布式计算层。该层利用Hadoop 框架能够实现集群的计算和存储,并且具备系统运行模式,还能够实现分布式系统管理[5]。
2.2 HDFS 的读写数据体系
数据信息收集完毕后,Client(客户端)可以对分布式数据进行存储和处理。在文件读取过程中, 利用HDFSClient( 未完待续目录) 对FileSystem(文件系统)对象进行调用,NameNode(主节点)能够对文件块数据节点进行反馈,进而读取海量数据。针对输入流,Client 可以对Read(阅读模式)读取和调用。HDFSInputStream(输入流读写)可以从数据节点读取数据,得到数据集并且进行分析。
2.3 平台MapReduce 编程模型
在创建软件框架过程中,利用MapReduce 技术创建编程模型,表示MAP 映射和Reduce 规约,在大量数据并行技术中应用,能够创建输入模式,核心编程为:
public static class Map extends MapReduceBaseimplements Mapper {
static enum Counters { INPUT_WORDS }
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
private boolean caseSensitive = true;
private Set<String> patternsToSkip = new HashSet<String>()
;
由于运算过程中会生成临时文件,所以能够促进数据交换、提高运行速度,其具体工作流程如下。
(1)利用库文件将程序分解为多个小任务,如任务a、任务b、任务c 等。
(2)利用调度功能在作业区分配闲置任务,并且根据平台的大小实现任务数的分配。
(3)启动Map 作业区被分解的任务,实现数据输入后对数据信息的读取,利用关键字key 将数据信息传递给相关函数,并且存储计算过程中的临时文件。
(4)在本地空间存储临时文件关键字key,在作业区寻找响应位置后以输出文件的方式进行输出[6]。
3 实验分析
3.1 Hadoop 分布式环境创建
本文创建小型集群环境,主要包括1 个master节点和2 个slave 节点。
3.2 实验结果
本文使用FIMI repository 事务数据集,利用Web 爬虫得到170 万个Web 文档,对文档进行清理和信息提取。为了使实验运行更流畅,将原本的文件划分成为多个块,一共进行3 组实验,每组实验运行3 次。
3.2.1 并行挖掘结果
通过对比并行程序和串行程序的结果来评价挖掘结果。如果两者结果相同,表示并行算法可靠;如果两者结果相反,则说明存在问题,挖掘结果不精准。实验显示,两种算法的频繁项集数目相同,并且挖掘结果一致,因此证明本文提出的算法可靠,能够精准挖掘频繁项集。
3.2.2 并行和串行的效率
采用两个程序对不同数据进行挖掘,最小支持度为0.25,假如存在的数据量较小,就会提高工作调度并行算法的成本和挖掘时间,无法全面展示挖掘效率的优势。而串行算法在挖掘500 MB 及以上的数据量时,会出现内存不足等问题,从而影响运算的结果。因此要求串行算法改进单机配置,从而充分挖掘大数据量中的信息,而并行算法不会出现该问题。
此外,随着挖掘数据量的持续增加,数据挖掘的时间会降低,数据挖掘的速度也越来越接近对数增长的速度。本文方法对数据量增长的适应性良好,如果能够扩展计算节点,能够满足大数据量挖掘需求[7]。
4 结语
通过研究发现,在云计算不断发展的背景下,Hadoop 结构和流程设计数据挖掘平台的方法较简单,并且能够创建完整网络算法,通过仿真平台对本文方法进行分析,还能够达到云计算环境下的高速分布式计算和挖掘的目标。
参考文献
[1] 唐建海. 基于Hadoop 平台的网络安全趋势大数据挖掘算法[J]. 工业加热,2022,51(7):67-70.
[2] 张鹏飞, 江岸, 熊念. Hadoop 平台下基于优化X-means 算法的大数据聚类研究[J]. 计算机测量与控制,2023,31(12):284-289,309.
[3] 高寒. 基于电商平台的大数据挖掘系统的设计研究[J].信息记录材料,2023,24(11):204-206,209.
[4] 朱卫东,李子龙,乔良才. SSM_HADOOP 框架的高校学生手机用户信息大数据可视化研究[J]. 软件,2022,43(3):26-28.
[5] 李林国,查君琪,赵超,等. 基于Hadoop 平台的大数据可视化分析实现与应用[J]. 西安文理学院学报(自然科学版),2022,25(3):53-58.
[6] 王立俊,杜建华,刘骥超,等. 基于决策树挖掘算法的气象大数据云平台设计[J]. 计算机测量与控制,2022,30(11):140-146.
[7] 吉鹏飞,齐建东,朱文飞. 改进人工鱼群算法在Hadoop 作业调度算法的应用[J]. 计算机应用研究,2014,31(12):3572-3574,3579.
