
基于SRCNN的条形码图像超分辨率重建
2024-09-14 00:00:00孙天健袁小平房鸿超陈思宇
物联网技术 2024年3期


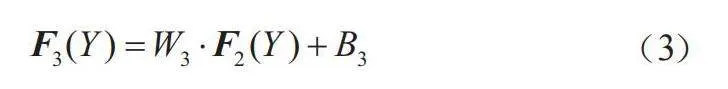


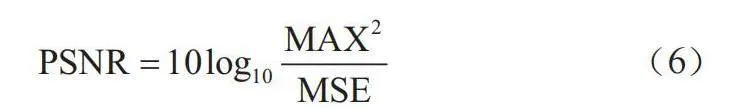

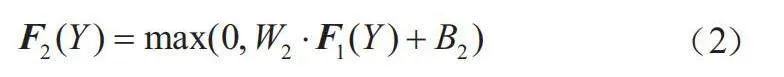


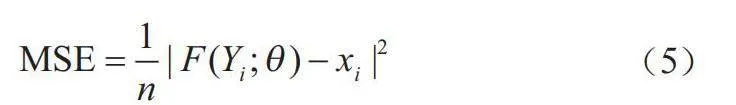
摘 要:针对像素较低的摄像头对条形码进行拍摄识别时,需要靠近条形码并保持较久的时间,且存在一定的扫描结果错误率等问题,利用卷积神经网络技术SRCNN对单幅低清晰度条形码图片进行超分辨率重建,将低分辨率图片转换为高分辨率图片。通过实验验证,SRCNN相对于传统超分方法,在图像处理和评价指标方面取得了更好的效果,实现了条形码图像的超分辨率重建,获得了更为清晰的图片。
关键词:条形码图像;超分辨率重建;双三次插值法;卷积神经网络;SRCNN;图像处理
中图分类号:TP391.41 文献标识码:A 文章编号:2095-1302(2024)03-0-03
0 引 言
在无人监督的药品库进行药品抓取任务中,通常以机械臂抓取为首选,搭配机器视觉进行手眼标定抓取。由于成像设备的局限性、药品盒标识条形码小,得到的图像分辨率较低,不利于药品的识别。提高条形码图像的分辨率,不仅便于提高机械臂抓取药品的准确率,也对生产生活中条形码的识别有一定的帮助。
为提高图像分辨率,常采用图像超分辨率(SR)法,即将图像从低分辨率恢复到高分辨率。传统图像超分辨率方法常用双三次插值(BiCubic)法、基于稀疏表示法[1-3]、基于局部嵌入法[4-6]、基于样例(Example-Based)法[7],这些经典的方法在提高图像分辨率上取得了一定的效果,但均是在插值过程中加入锐化的流程,本质上是通过人工观察、总结和试验得出来的方法,具有一定的局限性,在处理条形码图像后常常出现模糊、锐化过度的现象。
针对以上传统超分方法存在的问题,本文提出基于卷积神经网络(CNN)的超分辨率卷积神经网络(SRCNN)[8]的条形码超分辨率重建方法。SRCNN是基于深度学习,旨在实现一种端对端的网络模型,它具有结构简单且失真度低的特点,其被用于将低分辨率的图像转换为高分辨图像,证明深度学习在超分领域的应用可以超越传统的插值等算法,取得较高的表现力和良好的处理效果。
结合图像亮度增强技术、传统超分方法中的双三次插值法以及零填充技术,对条形码图像进行增亮、放大;然后通过加入零填充的SRCNN,实现低分辨率到高分辨率的非线性映射,得到相较于传统超分方法处理后效果更好的条形码图像及更高的PSNR值。
1 SRCNN模型分析
1.1 数据预处理
在将图像输入SRCNN前,需要进行图像的预处理:将获得的高分辨率图像X通过采样处理成低分辨率图像Y1,再使用双三次(BiCubic)插值法将低分辨率图像Y1放大至与输出高分辨率图片尺寸相同的低分辨率图像Y,如图1所示。
1.2 SRCNN模型结构
SRCNN的特点是仅使用三层网络,就取得相较于传统超分方法更好的结果,能够解决图像重建速度慢、计算量大的问题,其三层卷积的结构可以被解释为:图像子块的提取和特征表示、特征矩阵非线性映射和最终的特征重建。接着通过三层卷积网络拟合非线性映射,最后重建并输出高分辨率图像结果。其结构示意图如图2所示。
由于SRCNN的特性,三个部分的操作均可使用卷积完成。因此,虽然针对模型结构的解释与传统方法类似,但SRCNN却在数学上拥有更加简单的表达,以下为每层的操作内容:
(1)特征提取层
从输入的低分辨率图像中提取多个图像块,通过CNN以及ReLU层将图像块提取成向量,令所得的向量组成特征矩阵F1(Y):
(1)
式中:W1、B1分别是卷积核的参数和偏置量;窗口大小为f1×f1;通道数为Y,有n1个滤波器。
(2)非线性映射层
将特征矩阵再次使用卷积核过滤及ReLU层激活实现非线性映射,变成另一组维度不同的特征矩阵F2(Y),加深网络层数,表达式为:
(2)
式中:W2、B2分别是卷积核的参数和偏置量;采用1×1的卷积核;通道数为n1,有n2个滤波器。
在该层后可以继续增加非线性层,但在SRCNN构建时为推出一种通用性SR框架,所以选择只有一层非线性层的网络模型。
(3)图像重建层
本层借鉴传统超分方法的插值法,不使用ReLU层,直接对图像局部进行平均化,使用反卷积的方式做图像重建,将非线性层得到的特征矩阵还原为高分辨图像,表达式为:
(3)
式中,卷积核大小为n2×c×f3×f3。
1.3 加入零填充的SRCNN
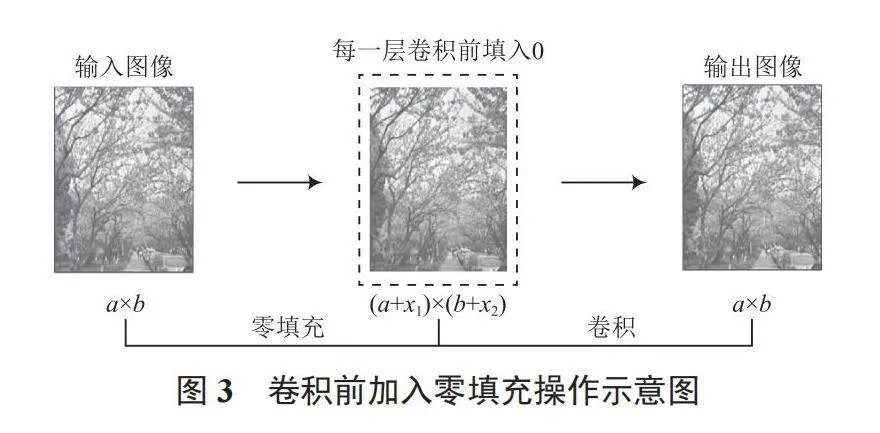
在SRCNN中,通常会使用过滤器(卷积核)来实现图像的卷积,从而实现图像的降维,即图像缩小;当使用多个过滤器实现多层的卷积,那么输出图像会持续缩小,很容易造成图像边缘有意义的信息丢失。
因此,为更好地实现图像超分辨率重建效果,本文在卷积层中加入零填充(zero-padding)[9-10],以保持输入和输出的空间维度相同,在水平轴和垂直轴的开始和结束处都添加0,即在卷积的时候,降低图像变小的速度,并防止图像边缘的信息丢失。加入零填充的SCRNN操作示意图如图3所示。
使用零填充时,对输出特征尺寸大小的影响通过式(4)计算。
(4)
式中:x为输出特征图的边长;a为输入边长;b为步长,不能整除时向上取整。
2 实验结果与分析
实验在使用Python3.9、PyTorch框架及具有以下规格的计算机上运行:Windows 10、CPU采用AMD Ryzen 74800H with Radeon Graphics、GPU采用NVIDIA GeForce GTX 1650、16 GB RAM。
2.1 数据集及评价指标
(1)数据集
训练集采用91-image作为SRCNN的实验数据集,模糊条形码图像集作为测试数据集,数据集在训练或测试前会进行修正处理,过程主要为高斯去噪、亮度提高、辐射校正和几何校正。
(2)SRCNN参数配置
模型的参数设置为:f1=9、f2=1、f3=5、n1=64、n2=32,SRCNN一共3层,前两层配置的学习率为10-4,最后一层的学习率配置为10-5,这样可以让最后一层取得较小的学习率,有利于网络收敛。
(3)损失函数
在实验中,选取MSE用作损失函数,该统计参数是预测数据和原始数据对应点误差的平方和的均值,表达式为:
(5)
式中:Y和X分别表示对应的低分辨率(LR)图像和高分辨率(HR)图像;i表示不同的通道;θ={Wi, Bi}表示网络的卷积参数;F(Yi; θ)表示网络的输入结果;n表示训练样本的数量。
(4)评价指标
峰值信噪比(PSNR)表示信号的最大可能功率与影响其精度的噪声之比,选取PSNR为评价指标,表达式为:
(6)
式中,MAX2为图片可能的最大像素值。
2.2 实验结果
采用像素为320×340的摄像头拍摄多种药品条形码,得到大量的低像素下较模糊的条形码图片,分别使用传统超分方法下的BiCubic法和加入零填充的SRCNN进行处理,取数据集中药品蒙脱石散的条形码图像展示,如图4、图5所示。可以看到SRCNN相对于传统超分BiCubic法在超分辨率重建效果上有直观的提升,能够体现更丰富的细节。
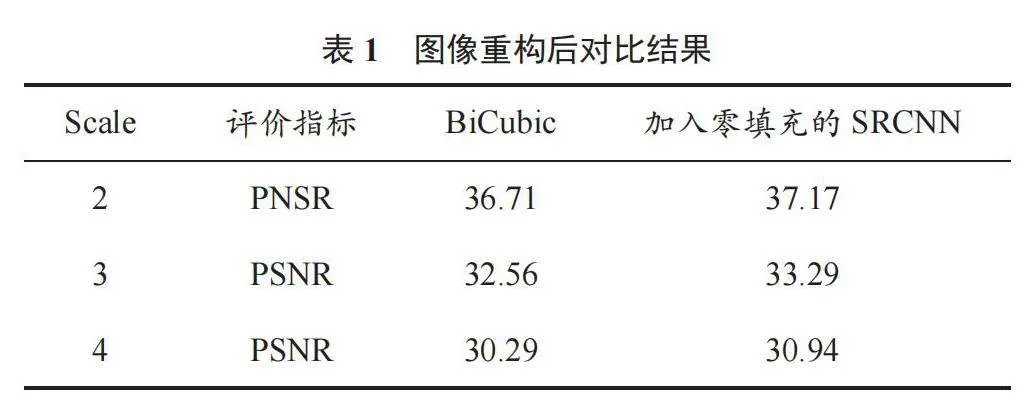
2.3 实验分析
针对图4和图5,在不同条形码图像输入规模上,使用评价指标公式(6)对其进行评价,可得到表1。由表1可以看出,在2、3、4三种图像规模下, SRCNN都具有更好的重构效果,拥有更高的PSNR值。
同时,在SRCNN处理条形码图像时可以测得模型的处理时间,见表2所列。由表1、表2可以发现,SRCNN在处理速度方面仍然不够理想,在图像重建上没有特别明显的效果,主要是存在两个固有的限制因素:首先,在图像预处理时使用双三次插值法将LR图像放大至所需图像的尺寸大小时,其计算复杂度为放大后图像的空间尺寸的平方;其次,在非线性映射层进行非线性映射时,采用更大的映射层可以提高映射的图像精准度,但运行时间也会相对增加。
因此,可以考虑采取相应的措施进行后续的改进:使用反卷积层在最后进行升采样,以代替双三次插值法;在非线性映射层前后分别添加收缩层和扩展层。改进后的SRCNN即为紧凑的沙漏型结构FSRCNN,它能够达到SRCNN处理速度的40倍以及更好的图像恢复效果,但SRCNN模型更为简单,在低分辨率药品条形码上进行超分辨率重建的处理效果已经可以达到预期,能明显提高识别条形码的速度和扫描读取的准确率。
3 结 语
针对成像设备的低分辨率的条形码图像,本文提出基于SRCNN对条形码图像进行超分辨率重建,通过图像的预处理和SRCNN,并加入零填充操作,将低分辨率图像非线性映射为高分辨率图像,得到更高的PSNR值和更清晰的图像,保证条形码在识别时的正确率和识别速度,提高了信息传递的速率和可靠度。
注:本文通讯作者为袁小平。
参考文献
[1] YANG J C,WRIGHT J,HUANG T,et al. Image super-resolution as sparse representation of raw image patches [C]// 2008 IEEE Conference on Computer Vision and Pattern Recognition. Anchorage,AK,USA:IEEE,2008:1-8.
[2]朱彦颖,赖芝岑,李凡,等.基于人脸识别的实验室考勤系统[J].物联网技术,2023,13(1):14-16.
[3] ADLER A,HEL-OR Y,ELAD M. A shrinkage learning approach for single image super-resolution with overcomplete representations [M]// DANIILIDIS K,MARAGOS P,PARAGIOS N. Computer Vision—ECCV 2010 Lecture Notes in Computer Science. Berlin,Heidelber:Springer,2010:622-635.
[4]李红岩,梁紫璇,赵峰,等.图像识别智能门禁[J].物联网技术,2023,13(1):104-106.
[5] GAO X,ZHANG K,TAO D,et al. Image super-resolution with sparse neighbor embedding [J]. IEEE transactions on image processing,2012,21(7):3194-3205.
[6] CHANG H,YEUNG D Y,XIONG Y M. Super-resolution through neighbor embedding [C]// Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition.Washington,DC,USA:IEEE,2004.
[7] ZHANG Y F,FAN Q L,BAO F X,et al. Single-image super-resolution based on rational fractal interpolation [J]. IEEE transactions on image processing,2018,27(8):3782-3797.
[8] DONG C,LOY C C,HE K,et al. Image super-resolution using deep convolutional networks [J]. IEEE transactions on pattern analysis and machine intelligence,2016,38(2):295-307.
[9]吕响,张书玉,宋英楠,等.基于深度学习下的卷积神经网络参数学习[J].渤海大学学报(自然科学版),2021,42(4):369-375.
[10]胡伏原,李林燕,尚欣茹,等.基于卷积神经网络的目标检测算法综述[J].苏州科技大学学报(自然科学版),2020,37(2):1-10.
作者简介:孙天健(2002—),男,本科生,研究方向为机器视觉。
袁小平(1966—),男,博士,教授,研究方向为物联网技术、机器学习、智能硬件加速。
房鸿超(2001—),男,本科生,研究方向为图像处理。
陈思宇(2002—),男,本科生,研究方向为机器视觉。
猜你喜欢
制造技术与机床(2018年12期)2018-12-23 02:40:52
电子制作(2018年18期)2018-11-14 01:48:20
中国公共安全(2017年8期)2017-10-13 08:12:21
中国公共安全(2017年8期)2017-10-13 08:12:20
科技创新与应用(2016年35期)2017-02-21 19:16:50
计算机应用(2016年12期)2017-01-13 20:26:21
软件导刊(2016年9期)2016-11-07 22:20:49
软件工程(2016年8期)2016-10-25 15:47:34
电脑知识与技术(2016年10期)2016-06-16 21:27:26
电气化铁道(2016年4期)2016-04-16 05:59:46
