
融合MacBERT和Talking⁃Heads Attention实体关系联合抽取模型
2024-09-12 00:00:00王春亮姚洁仪李昭
现代电子技术 2024年5期




摘" 要: 针对现有的医学文本关系抽取任务模型在训练过程中存在语义理解能力不足,可能导致关系抽取的效果不尽人意的问题,文中提出一种融合MacBERT和Talking⁃Heads Attention的实体关系联合抽取模型。该模型首先利用MacBERT语言模型来获取动态字向量表达,MacBERT作为改进的BERT模型,能够减少预训练和微调阶段之间的差异,从而提高模型的泛化能力;然后,将这些动态字向量表达输入到双向门控循环单元(BiGRU)中,以便提取文本的上下文特征。BiGRU是一种改进的循环神经网络(RNN),具有更好的长期依赖捕获能力。在获取文本上下文特征之后,使用Talking⁃Heads Attention来获取全局特征。Talking⁃Heads Attention是一种自注意力机制,可以捕获文本中不同位置之间的关系,从而提高关系抽取的准确性。实验结果表明,与实体关系联合抽取模型GRTE相比,该模型[F1]值提升1%,precision值提升0.4%,recall值提升1.5%。
关键词: MacBERT; BiGRU; 关系抽取; 医学文本; Talking⁃Heads Attention; 深度学习; 全局特征; 神经网络
中图分类号: TN911.1⁃34" " " " " " " " " " " " " 文献标识码: A" " " " " " " " " " " "文章编号: 1004⁃373X(2024)05⁃0127⁃05
Entity relation joint extraction model fusing MacBERT and Talking⁃Heads Attention
WANG Chunliang1, YAO Jieyi1, 2, LI Zhao1, 2
(1. Hubei Key Laboratory of Intelligent Vision Based Monitoring for Hydroelectric Engineering, Yichang 443000, China;
2. College of Computer and Information Technology, China Three Gorges University, Yichang 443000, China)
Abstract: The existing models for the task of relation extraction of medical text have the deficiency of insufficient semantic comprehension during the training process. This may result in unsatisfactory extraction outcomes. Therefore, a joint extraction model that fuses MacBERT and Talking⁃Heads Attention for entity relation joint extraction is proposed. In the model, the MacBERT language model is utilized to obtain dynamic word vector representations. MacBERT, as an upgraded BERT model, can lessen the differences between the pre⁃training and fine⁃tuning stages, so as to improve the model′s generalization capability. The dynamic word vector representations are then fed into a bidirectional gated recurrent unit (BiGRU), so as to extract textual contextual features. BiGRU is an improved recurrent neural network (RNN) with better long⁃term dependency capture. After obtaining the text context features, the Talking⁃Heads Attention is used to obtain the global features. It is a self⁃attentive mechanism that can capture the relations between different locations in the text, so as to improve the accuracy of relation extraction. The experimental results show that the proposed model can improve the [F1] value by 1%, the precision value by 0.4% and the recall value by 1.5% in comparison with the entity relation joint extraction model GRTE.
Keywords: MacBERT; BiGRU; relation extraction; medical text; Talking⁃Heads Attention; deep learning; global feature; neural network
0" 引" 言
随着生物医学领域的不断发展,医疗数据的数字化记录日益增多。这些中文医疗文本中包含了丰富的医学知识,如病历、医学文献等。这些文本数据中包含着大量的实体和关系信息,如疾病、症状、药物等实体以及这些实体之间的关系。因此,构建一个稳定的关系抽取模型,将非结构化文本信息精准和全面地自动转化为符合大众需求的结构化信息,对于支持医疗领域的各种应用,如知识图谱[1]、信息检索等具有重要的意义。在关系抽取领域,大量学者进行了研究,以从非结构化的医学文本数据中提取出有用的信息,并服务于下游子任务。医学教材以及电子病例数据等均为非结构化的医学文本数据,从这些文本中识别出医学实体,并确定医学实体之间关系的过程即为医学领域的关系抽取。
基于深度学习的关系抽取方法在解决手动特征工程问题[2]方面取得了比较好的成果。基于深度学习的流水线实体关系抽取方法[3]主要是将命名实体识别和关系抽取作为两个独立的任务来完成。虽然这些方法能够自动获取文本特征,但它们无法有效解决错误传播的问题。与之不同,基于深度学习的联合抽取方法[4]的主要目的是同时实现句子中实体的识别和实体对关系之间关联信息的抽取,这显著提高了模型的性能。然而,现有的联合实体关系抽取模型在训练过程中存在语义理解能力不足的问题。针对上述问题,本文提出了一种融合MacBERT和Talking⁃Heads Attention的实体关系联合抽取模型。该模型旨在提高对医学文本的语义理解能力,从而更好地实现医学领域的实体关系抽取。
本文贡献如下:
1) 通过结合MacBERT的中文预训练模型和BiGRU的长距离依赖捕获能力,可以增强模型在复杂任务中的语义理解能力。
2) 通过引入Talking⁃Heads Attention,可以在保持较低计算复杂度的同时提高模型的准确性。
3) 将DuIE和CMeIE数据集应用于该模型得到了最好的结果。
1" 相关工作
关系抽取是指自动识别文本数据中实体并确定它们之间关系的任务。近年来,随着关系抽取技术的快速发展,基于深度学习的流水线和联合实体关系抽取方法在关系抽取方向得到广泛的应用。
1.1" 流水线实体关系抽取方法
基于神经网络的流水线实体关系抽取方法受到了广泛关注。其中,文献[5]提出了一种基于注意力机制的图卷积网络模型,该模型采用软剪枝方法,能够有选择地自动学习对关系提取任务有用的相关子结构。文献[6]融合了Bi⁃LSTM和CNN的特点,这种模型能够更好地捕捉实体之间的关系信息,提高了关系抽取的准确性和效率。文献[7]使用了两个独立的编码器,一个用于实体识别,另一个用于关系抽取,使用相同的预训练模型就达到了良好的性能。
1.2" 实体关系联合抽取方法
为了解决流水线关系抽取带来的误差传递和特征共享等问题,基于深度学习的实体关系联合抽取方法引起了越来越多研究者的关注。文献[8]提出一种编码器⁃解码器体系结构实体关系联合抽取方法(WDec)。文献[9]设计两种不同的编码器在学习过程中获取这两种不同类型的信息。考虑到关系三元组重叠问题,文献[10]提出一种基于多任务学习的模型(CopyMTL),具有新的实体复制体系结构。为了解决实体重叠问题,文献[11]提出了一个新的级联二进制标记框架(CasRel),该框架采用Span标记的方法,这种方法根据每个关系识别出相应的客体。然而,局部Span实体抽取方案缺乏鲁棒性。文献[12]提出了TPLinker关系抽取模型,该模型采用token对预测方案,通过执行两个[O(n2)]矩阵操作来提取实体,导致了关系冗余判断问题。文献[13]提出基于表格填充的面向全局特征的新型关系三元组提取模型(GRTE),该方法认为现有的方法在填充关系表时仅仅依赖于局部特征,局部特征从单一的token pair或者从有限的token pairs的填充历史中提取得到,然而却忽略了两种有价值的全局特征(Global Feature),即token pairs和各类关系的全局关联关系。文献[14]提出一种集合生成网络(SPN4RE),该模型通过二位图执行[O(n2)]矩阵操作匹配出最优三元组。文献[15]提出基于依存图卷积的实体关系抽取模型,该模型使用依存句法分析文本构图,然后通过双向GraphSage提取其结构特征,融入句法结构的特征向量在预测关系时有着更好的表现。
2" 模型算法架构
2.1" 编码器模块
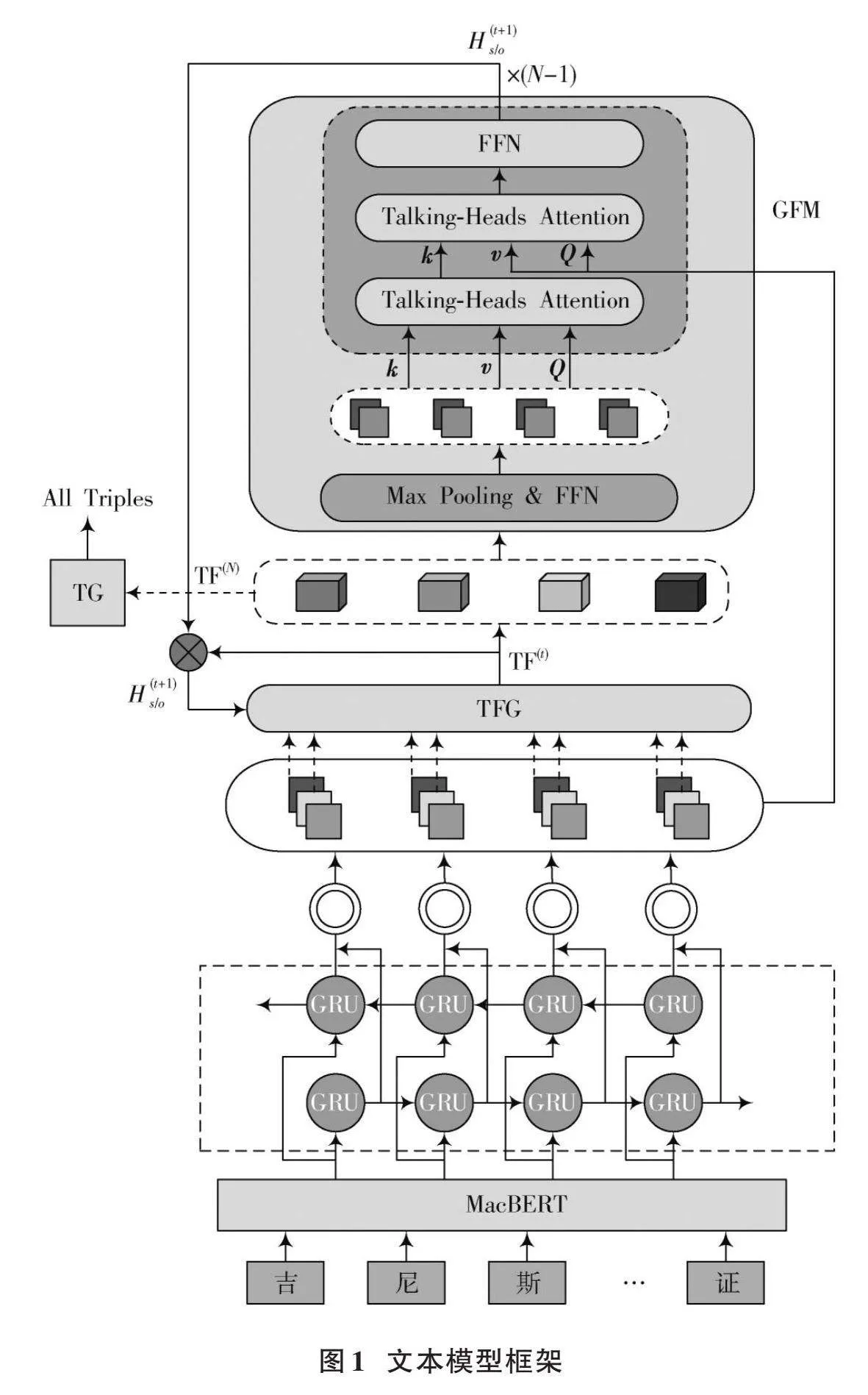
图1展示了本文提出的模型框架,该框架由四部分组成:MacBERT编码器层、BiGRU层、表格填充模块和解码层。其工作原理如下:
首先,利用MacBERT编码器层将中文文本数据转化为字符向量;然后,将MacBERT提取到的字符向量输入到BiGRU层中进行特征提取;接着,利用解码器对生成的字符向量进行解码,生成相应的标签序列。
本文中使用预训练Chinese⁃MacBERT⁃Base(Cased)模型与BiGRU作为编码器。首先编码器将给定的句子编码成一个字符特征序列[H]([H∈Rn×dh]),然后将[H]输入到两个分离的前馈网络(FFN)中,生成初始的主体特征和客体特征(分别表示为[H1s和H1o]),其公式如下:
[H1s=W1H+b1]" (1)
[H1o=W2H+b2]" (2)
式中:[W1/2∈Rdh×dh]是可训练的权重;[b1/2∈Rdh]是可训练的偏差。
2.1.1" MacBERT层
为了提升实体关系抽取模型的准确性,本文将MacBERT引入到本模型中。MacBERT是一种基于Transformer的中文自然语言处理模型,是在RoBERTa基础上进行修改得到的。MacBERT采用了一种改进的掩码策略,使用相似的词来进行掩码,而不是使用[MASK]标记,使得模型能够学习到丰富的词汇和句子表示。将MacBERT引入本模型中,可以使模型在抽取实体关系时更好地理解句子中的语义信息,从而提高关系抽取的精确性。其次,MacBERT是在大规模无标签文本数据上进行预训练,学习到通用的语言表示,可以使模型在关系抽取任务上具备更强的泛化能力。
2.1.2" BiGRU层
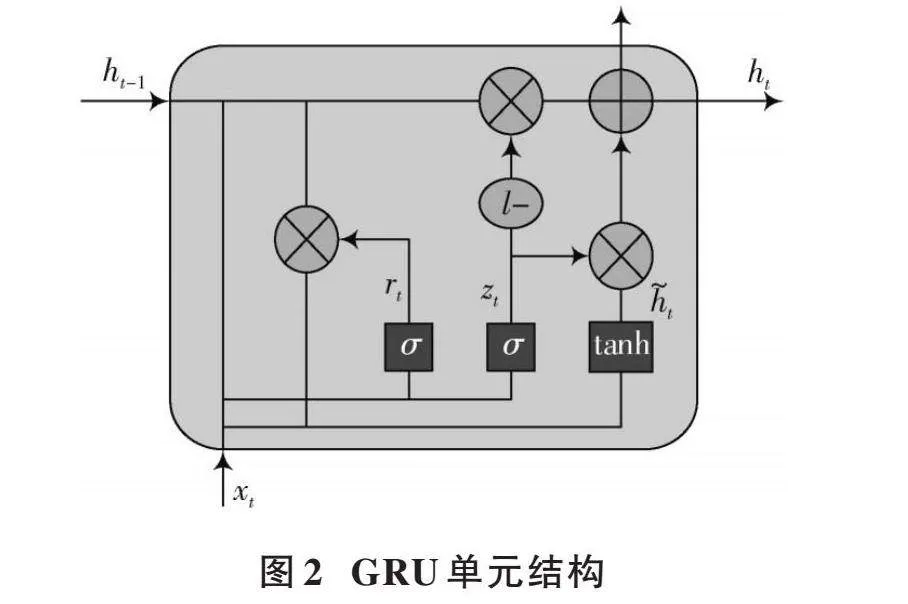
为了改进RNN,引入LSTM并进行了修改。LSTM包含三个门控单元:输入门、输出门和遗忘门。GRU将输入门和遗忘门合并成为更新门,以简化计算。GRU通过引入“记忆元素”和“门元素”,保存长期序列信息。“记忆元素”长期保存信息,不随时间流逝而消失;“门元素”包含更新门和重置门,处理输入数据和更新重置。重置门决定新输入与记忆元素的结合方式,更新门决定保存多少记忆元素到当前步长。其计算公式如下:
[zt=σ(Wzxt+Uzht-1+bz)] (3)
[rt=σ(Wrxt+Urht-1+br)] (4)
[ht=tanh(Wxt+rt⊗Uht-1)] (5)
[ht=zt⊗ht-1+(1-zt)⊗ht] (6)
GRU结构如图2所示。因单向GRU传输特征向量只能向前单向传播,易丢失重要特征,因此提出双向GRU网络结构,利用MacBERT层获取的字向量输入到双向GRU中进行特征提取,可充分利用特征向量联系上下文信息。
2.2" 表格填充模块和解码器模块
该方法将为每个关系维护一个表,该表中的项通常表示拥有该特定关系的两个实体的开始和结束位置。因此三元组关系抽取任务被转换为准确有效地填充这些表的任务。首先,给出一个句子[S]=[w1,w2,…,wn],将为每个关系[r]([r∈R],[R]是关系集)维护一个表[tabler](大小为[n]×[n])。TFG模块将第[t]次迭代时的主体特征和客体特征分别表示为[H(t)s]和[H(t)o]。然后将它们作为输入,该模块为每个关系生成一个表特征。关系[r]在第[t]次迭代时的表特征为[TF(t)r],它与[tabler]具有相同的大小,[TF(t)r]中的每个项表示实体对的标签特征。具体地说,对于一对([wi],[wj]),把它的标签特征表示为[TF(t)r(i,j)],用公式(7)计算:
[TF(t)r=WrGeLU(H(t)s,i∘H(t)o,j)+br] (7)
式中:“[∘]”表示哈达玛积;GeLU是激活函数;[H(t)s,i]和[H(t)o,j]分别是第[t]次迭代时字符[wi]和[wj]的特征表示。GFM模块挖掘期望的两类全局特征,在此基础上生成新的主体和客体特征,然后这两个新生成的特征将反馈给TFG进行下一次迭代。具体来说,该模块包括以下三个步骤:
步骤1:组合表特征。假设当前迭代是[t],首先将所有关系的表特征串联在一起,生成一个统一表特征(表示为[TF(t)]),并且这个统一表特征将包含实体对和关系的信息;然后,在[TF(t)]上使用最大池化操作和FFN模型,分别生成主体相关表特征[TF(t)s]和客体相关表特征[TF(t)o]等,如式(8)、式(9)所示:
[TF(t)s=Wsmaxpool(TF(t))+bs] (8)
[TF(t)o=Womaxpool(TF(t))+bo] (9)
式中:[Ws/o∈R(|L|×|R|)×dh]是可训练权重;[bs/o∈Rdh]是可训练偏差。
步骤2:挖掘期望的两类全局特征。首先,在[TF(t)s/o]上使用交谈注意力方法来挖掘全局关联关系;其次,采用交谈注意力方法挖掘字符对的全局关联。句子向量[H]也作为输入的一部分,由于输入句子是作为一个整体编码的,因此[H]可能在一定程度上包含了字符的全局语义信息,从而有助于从整个句子的角度挖掘字符对之间的全局关联;最后利用FFN模型生成新的主体和客体的特征。整个全局关联挖掘过程可以用以下公式计算:
[TF(t)(s/o)=TalkingHeadAtt(TF(t)(s/o))] (10)
[H(t+1)(s/o)=TalkingHeadAtt(TF(t)(s/o),H,H)] (11)
[H(t+1)(s/o)=GeLU(H(t+1)(s/o)W+b)] " " "(12)
步骤3:进一步调整步骤2生成的主体和客体特征。如果深度迭代TFG和GFM模块,本文的模型相当于一个非常深的网络,因此可能出现梯度消失。为了避免这种情况,使用残差网络生成最终的主体和客体特征,如公式(13)所示:
[H(t+1)(s/o)=LayerNorm(H(t)(so)+H(t+1)(so))]" (13)
TG模块以最后一次迭代时的表特征[TF(N)]为输入,式(14)、式(15)解码输出所有三元组:
[tabler(i,j)=softmax(TF(N)r(i,j))] " " (14)
[tabler(i,j)=argmaxℓ∈L(tabler(i,j)[ℓ])] " (15)
损失函数为:
[L=i=1nj=1nr=1R-logp(yr,(i,j)=tabler(i,j))=i=1nj=1nr=1R-logtabler(i,j)[yr,(i,j)]] " (16)
式中[yr,(i,j)∈1,ℓ]是([wi],[wj])关于关系[r]的真实标签索引。
3" 实验与结果分析
3.1" 数据集
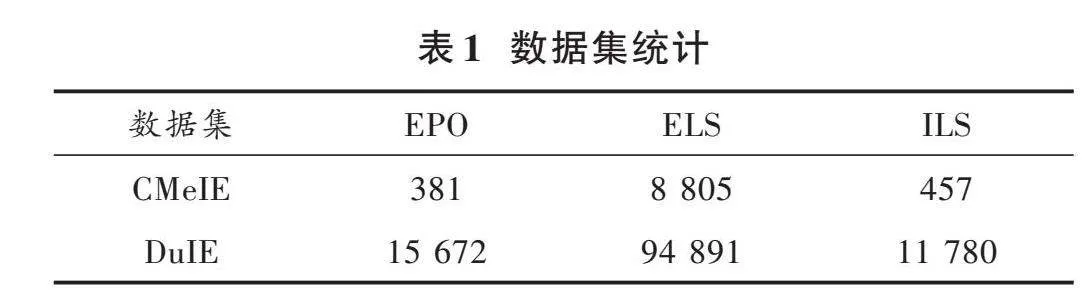
为了测试本文提出模型的性能,选取了两个公开的中文数据集。CMeIE是在CHIP2020中发布[16]的基于schema的中文医学信息抽取数据集。在数据集中近7.5万三元组数据,2.8万条疾病语句并定义了53个关系,包括10个同义子关系和其他43个其他子关系。DuIE是中国第一个大规模、高质量的IE数据集[17],数据集中包括49种常用的关系类型,45万个独特的主语谓语对象(SPO)三元组和21万条句子。
表1统计了2个数据集中的训练集和测试集的数据。
3.2" 实验设置
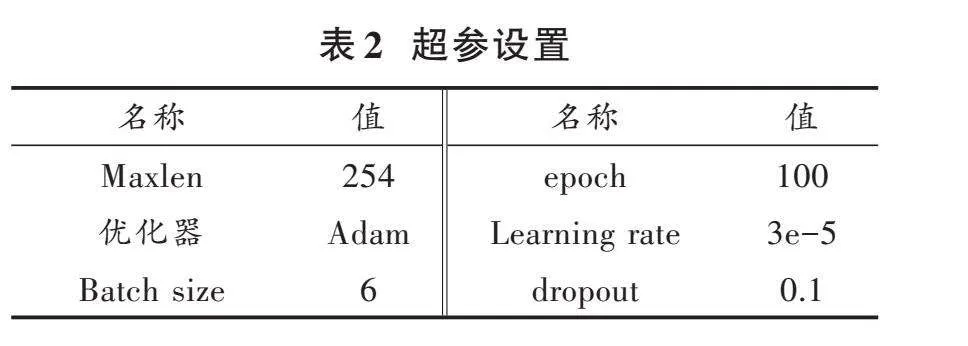
本实验环境如下:使用Ubuntu 20.04操作系统,显卡为RTX3090,显卡大小为64 GB,Python版本为3.8.10,深度学习框架为PyTorch版本为1.7.0。具体超参设置如表2所示。
3.3" 结果分析
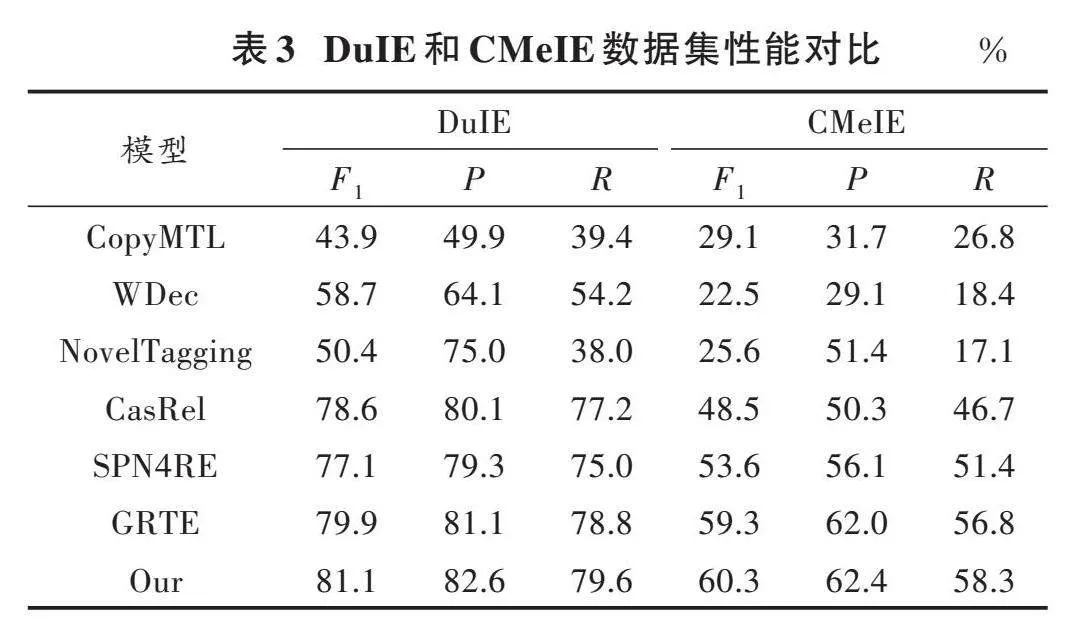
为了验证本文提出的模型在抽取任务中的性能,将几种模型与本文所提出的模型进行了对比,如表3所示。从表3的深度神经网络对比结果可以看出,本文提出的方法取得了最好的结果。
通过观察得出,本文提出的模型在所有的评估指标方面几乎都较优于其他关系抽取模型。值得注意的是,本文模型在CMeIE数据集上[F1]值相比GRTE值取得了1.0%的提升。其原因在于:本文提出的新模型在模型编码器模块将MacBERT预训练模型与BiGRU结构相结合,增强了模型的语义理解能力;其次引入Talking⁃Heads Attention模块,这是一种轻量级的注意力机制,通过将注意力权重映射到一个低维空间来减少计算复杂度。这种方法可以在保持高性能的同时,降低计算成本和内存需求。
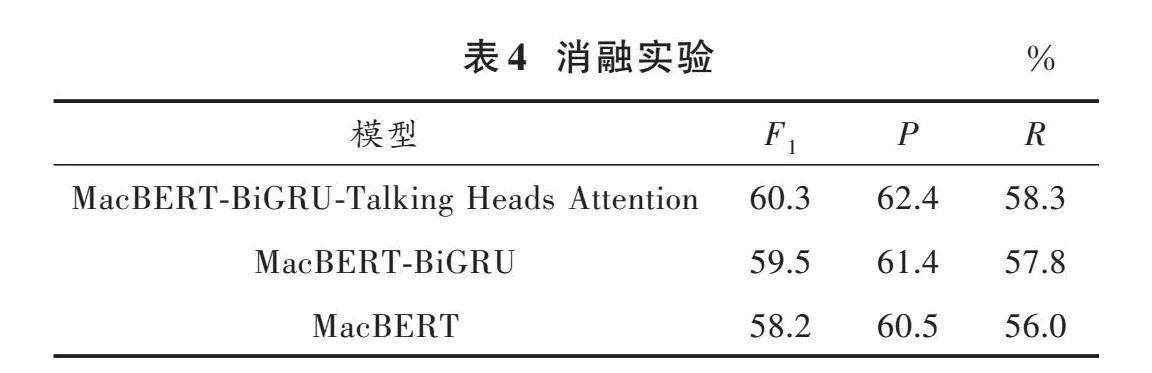
3.4" 模型消融实验
为了分析本文提出的实体关系联合抽取模型中各个模块在模型中的贡献,在CMeIE数据集上做了相关消融实验。表4展示了消融实验的性能指标结果。
BiGRU对模型性能的贡献:BiGRU能更好地捕捉到文本句子中的长距离依赖关系,提高模型语义理解能力。移除BiGRU后,模型可能在处理复杂句子结构时表现较差。
Talking⁃Heads Attention对模型性能的贡献:通过引入Talking⁃Heads Attention,可以在保持较低计算复杂度的同时提高模型的准确性。
4" 结" 论
本文为提高模型语义理解能力,提出一种融合MacBERT和Talking⁃Heads Attention的实体关系联合抽取模型。MacBERT可以通过对中文文本进行编码,得到更加准确和丰富的语义表示,BiGRU可以捕捉到文本中的上下文信息,并将这些信息应用于关系抽取任务中,两者结合可以进一步提高模型性能。通过引入Talking⁃Heads Attention,可以在保持较低计算复杂度的同时提高模型的准确性。由于Talking⁃Heads Attention降低了计算复杂度,因此可以加速模型的训练和推理过程,使其适用于大规模数据集和实时应用。然而,关系抽取任务中还存在一些挑战和问题:数据集中存在噪声和不一致性,这会对模型性能产生影响;数据集中存在长尾问题,即模型难以学习到数量较少的类别,如何处理长尾问题也是一个值得关注的问题。
注:本文通讯作者为王春亮。
参考文献
[1] 付瑞,李剑宇,王笳辉,等.面向领域知识图谱的实体关系联合抽取[J].华东师范大学学报(自然科学版),2021(5):24⁃36.
[2] 张东东,彭敦陆.ENT⁃BERT:结合BERT和实体信息的实体关系分类模型[J].小型微型计算机系统,2020,41(12):2557⁃2562.
[3] 张仰森,刘帅康,刘洋,等.基于深度学习的实体关系联合抽取研究综述[J].电子学报,2023,51(4):1093⁃1116.
[4] YU B, ZHANG Z, SHU X, et al. Joint extraction of entities and relations based on a novel decomposition strategy [C]// European Conference on Artificial Intelligence. [S.l.: s.n.], 2020: 2282⁃2289.
[5] ZHANG Y, GUO Z, LU W. Attention guided graph convolutional networks for relation extraction [EB/OL]. [2020⁃09⁃06]. https://arxiv.org/abs/1906.07510v5.
[6] LI Z, YANG Z, SHEN C, et al. Integrating shortest dependency path and sentence sequence into a deep learning framework for relation extraction in clinical text [J]. BMC medical informatics and decision making, 2019, 19(1): 1⁃8.
[7] ZHONG Z, CHEN D. A frustratingly easy approach for entity and relation extraction [EB/OL]. [2021⁃03⁃23]. https://arxiv.org/abs/2010.12812.
[8] NAYAK T, NG H T. Effective modeling of encoder⁃decoder architecture for joint entity and relation extraction [J]. Proceedings of the AAAI conference on artificial intelligence, 2020, 34(5): 8528⁃8535.
[9] WANG J, LU W. Two are better than one: Joint entity and relation extraction with table⁃sequence encoders [EB/OL]. [2020⁃10⁃08]. https://arxiv.org/abs/2010.03851v1.
[10] ZENG D, ZHANG R H, LIU Q. Copymtl: Copy mechanism for joint extraction of entities and relations with multi⁃task learning [J]. Proceedings of the AAAI conference on artificial intelligence, 2020, 34(5): 9507⁃9514.
[11] WEI Z, SU J, WANG Y, et al. A novel cascade binary tagging framework for relational triple extraction [C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2020: 1476⁃1488.
[12] WANG Y, YU B, ZHANG Y, et al. TPLinker: Single⁃stage joint extraction of entities and relations through token pair linking [C]// International Conference on Computational Linguistics. [S.l.]: International Committee on Computational Linguistics, 2020: 1572⁃1582.
[13] REN F, ZHANG L, YIN S, et al. A novel global feature⁃oriented relational triple extraction model based on table filling [EB/OL]. [2021⁃09⁃26]. edu/abs/2021arXiv210906705R/abstract.
[14] SUI D, CHEN Y, LIU K, et al. Joint entity and relation extraction with set prediction networks [EB/OL]. [2022⁃10⁃02]. https://arxiv.org/abs/2011.01675.
[15] 刘源,刘胜全,常超义,等.基于依存图卷积的实体关系抽取模型[J].现代电子技术,2022,45(13):111⁃117.
[16] GUAN T, ZAN H, ZHOU X, et al. CMeIE: Construction and evaluation of Chinese medical information extraction dataset [C]// Natural Language Processing and Chinese Computing: 9th CCF International Conference. Heidelberg, Germany: Springer International Publishing, 2020: 270⁃282.
[17] LI S, HE W, SHI Y, et al. DuIE: A large⁃scale Chinese dataset for information extraction [C]// Natural Language Processing and Chinese Computing: 8th CCF International Conference. Heidelberg, Germany: Springer International Publishing, 2019: 791⁃800.
猜你喜欢
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
中国外汇(2019年18期)2019-11-25 01:41:54
当代陕西(2019年10期)2019-06-03 10:12:04
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
哲学评论(2017年1期)2017-07-31 18:04:00
领导决策信息(2017年9期)2017-05-04 04:04:49
领导决策信息(2017年9期)2017-05-04 04:04:49
电子设计工程(2017年20期)2017-02-10 03:39:29
电子器件(2015年5期)2015-12-29 08:42:24
