
基于改进YOLOv5的安全帽检测算法
2024-09-12 00:00:00韩锟栋张涛彭玻钟亮吴胜波
现代电子技术 2024年5期







摘" 要: 为解决安全帽佩戴检测中密集小目标和目标受到遮挡场景下容易产生误检和漏检的问题,提出基于改进YOLOv5安全帽佩戴检测算法。首先,在安全帽的特征信息提取过程中引入微尺度检测层,以进一步融合多尺度特征,从而获得更为丰富的特征信息;然后,将坐标注意力机制插入到所提出的改进特征融合网络中,用于提取目标的位置信息,并通过实验验证了该方法的有效性;最后利用EIOU代替CIOU损失函数,加快收敛并改善回归精度和安全帽目标检测准确性。根据实验结果可以看出,改进的 YOLOv5算法对安全帽的平均检测准确率(mAP)为90.89%,比标准YOLOv5算法提升了2.25%,明显减少了误检、漏检情况,在面对密集小目标、目标被遮挡等复杂场景时,检测性能得到了有效的提升。除此之外,将改进后的YOLOv5安全帽检测算法部署到施工现场,可以展现出在密集小目标、目标被遮挡场景下更加优异的检测性能,具有很大的应用价值。
关键词: 人工智能; 目标检测; YOLOv5; 特征融合; 注意力机制; 损失函数
中图分类号: TN911.73⁃34; TP183; TP391.4" " " " " "文献标识码: A" " " " " " " 文章编号: 1004⁃373X(2024)05⁃0085⁃08
Safety helmet detection algorithm based on improved YOLOv5
HAN Kundong, ZHANG Tao, PENG Bo, ZHONG Liang, WU Shengbo
(School of Software, Xinjiang University, Urumqi 830000, China)
Abstract: In view of the 1 detection and missed detection in safety helmet wearing detection when the objects are small and dense or the objects are occluded, a safety helmet wearing detection algorithm based on improved YOLOv5 is proposed. In the process of extracting feature information of safety helmets, a micro⁃scale detection layer is introduced to further fuse multi⁃scale features and obtain richer feature information. The coordinate attention (CA) mechanism is inserted into the proposed improved feature fusion network, so as to extract the position information of the object, and the effectiveness of the method is verified in experiments. The EIOU (efficient⁃IoU) is used to replace the CIOU (complete intersection over union) loss function, which accelerates the convergence and improves the regression accuracy and the accuracy of the safety helmet object detection. According to the experimental results, it can be seen that the improved YOLOv5 algorithm has a mean average precision (mAP) of 90.89% for safety helmets, which is 2.25% higher than that of the standard YOLOv5 algorithm, which reduces 1 detection and missed detection significantly. In the scenes of facing dense small objects or occluded objects, the detection performance of the proposed method has been improved effectively. In addition, when the proposed algorithm is applied to the construction site, it shows more excellent detection performance when detecting dense small objects or occluded objects, so it has great application value.
Keywords: artificial intelligence; object detection; YOLOv5; feature fusion; attention mechanism; loss function
0" 引" 言
中国作为基础建设大国,生产建筑业是中国经济发展必不可少的推动力。建筑安全事故会对国家和个人造成巨大损失,在这些事故中绝大部分是因为施工人员未遵守安全行为准则造成的。目前监督施工人员佩戴安全帽的方式主要是人工监督,但人工监督存在雇佣人员成本高,监督人员因主观意识对实时情况缺乏客观性的判断等弊端。为了保证工地现场的施工安全,必需采取智能化的技术方式,减少施工现场中施工人员未佩戴安全帽施工这一违规现象的发生[1⁃3]。近年来,深度学习技术逐渐成为学者们研究的热门方向之一,使用深度学习算法代替人力进行安全帽佩戴的检测更加高效。
传统目标检测[4⁃5]一般通过滑动窗口的方法选择候选区域,然后用SIFT(Scale Invariant Feature Transform,尺度不变特征变换)[6]或者是HOG(Histogram of Oriented Gradient,方向梯度直方图)等方法提取特征[7],最后使用支持向量机(SVM)[8]等分类器进行分类处理。这些方法在对复杂背景下的运动图像进行目标检测时往往存在着漏检率较高的问题。与传统目标检测算法相比较,深度学习框架下的目标检测算法展现出较强的鲁棒性,其利用卷积神经网络自动提取目标特征,以代替传统人工提取模式。这种方法可以在复杂场景中取得良好的检测效果。深度学习框架中的目标检测算法可以划分为单阶段和两阶段。在第一阶段,采用了单步目标检测算法,而在第二阶段,则引入了多步骤融合目标检测算法,以达到更高效的检测效果。目标检测算法分两个阶段进行,先为检测目标产生若干候选区域,再把从全部候选区域提取出的特征图送入分类器对目标进行分类,通过目标损失函数进一步准确地获得边界框,从而获得最终检测结果[9]。多步操作获得的准确性一般较高,但是也由于步骤太多而降低了检测速度。单阶段目标检测算法采用端到端的方法,在输入端直接对图片信息进行特征提取操作并预测获取目标对象在图片上的位置及类别信息,最后将算法检测结果进行输出,采用该端到端检测方式使单阶段目标检测算法检测速率显著提高。相对于两阶段目标检测算法,将一阶段检测算法应用到工业领域中考虑到精确度高、速度快等特点,更具有实用性。
在头盔检测方面,Vishnu等将CNN应用于摩托车驾驶员头盔佩戴检测中,而该方法不能进行多个目标的检测与跟踪。文献[10⁃12]在原来Faster R⁃CNN模型的基础上,运用多尺寸输入图像进行训练,同时将锚点框(anchor box)数量增至12个,来增强模型对不同尺度目标的鲁棒性,提高了模型的分类准确率,但是实时检测的精确度仍然不能满足要求。林俊基于YOLO,方明等基于YOLOv2,施辉等基于YOLOv3,通过不同角度的改进、压缩网络结构、极大抑制算法改进和多尺度检测等,不断提高安全帽检测准确性和泛化能力[13⁃15]。但是在小目标、目标遮挡、密集人群这些复杂场景下,检测结果并不是很理想[16]。
针对基于YOLOv5[17]的安全帽目标检测算法存在的密集小目标、目标被遮挡场景下出现的误检、漏检问题,本文提出一种基于改进YOLOv5的安全帽检测算法。首先,在特征融合层添加微尺度检测层,以提取更丰富的安全帽特征信息,增强对小目标的检测能力;其次,在改进的特征融合层中嵌入坐标注意力机制(Coordinate Attention, CA)[18],提高模型的表达能力;最后,采用EIOU[19]损失函数替换CIOU[20](Complete Intersection over Union)损失函数解决了纵横比的模糊定义,加速了收敛并且提高了回归精度。经过在SHWD(Safety⁃Helmet⁃Wearing⁃Dataset)数据集中进行实验,结果表明改进后的算法对安全帽检测的平均精确度(mAP)比标准YOLOv5算法提升了2.25%,并且检测精确度优于其他经典的目标检测算法。
1" 算法介绍
1.1nbsp; YOLOv5算法原理
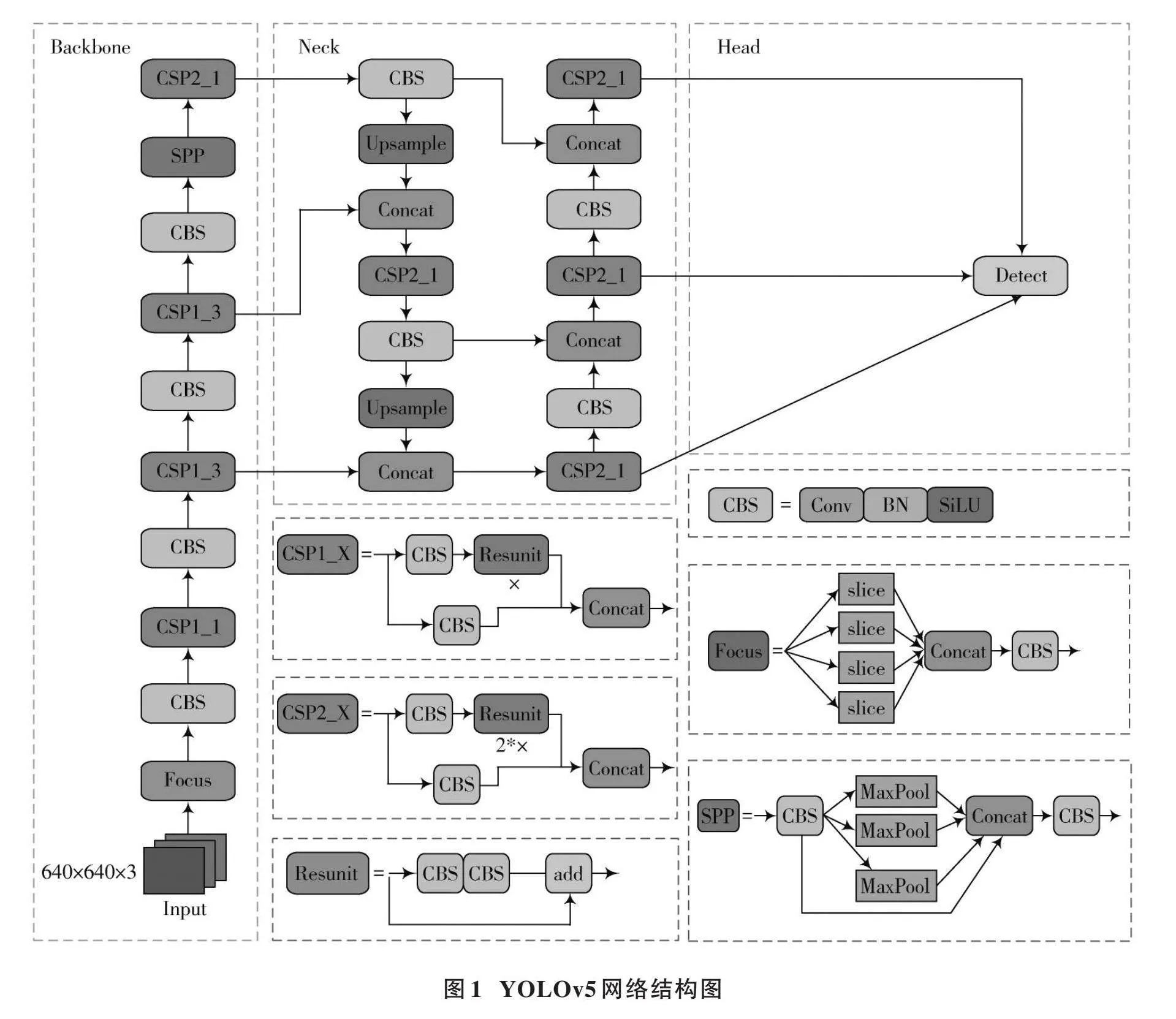
YOLOv5是一种一阶段的目标检测算法,采用单阶段检测器的思路,将整个检测过程简化为一个端到端的卷积神经网络,具有检测速度快、准确率高等优点。YOLOv5主要包含四种架构:YOLOv5⁃s、YOLOv5⁃m、YOLOv5⁃l和YOLOv5⁃x,该四种架构模型以深度来区分,参数数量依次增加。综合考虑研究模型的参数规模与检测效率,实验基于YOLOv5⁃s架构对安全帽检测的网络进行改进。YOLOv5算法的网络结构分为输入端、主干网络、颈部网络和预测网络。YOLOv5的整体结构如图1所示。
1.1.1" 主干网络
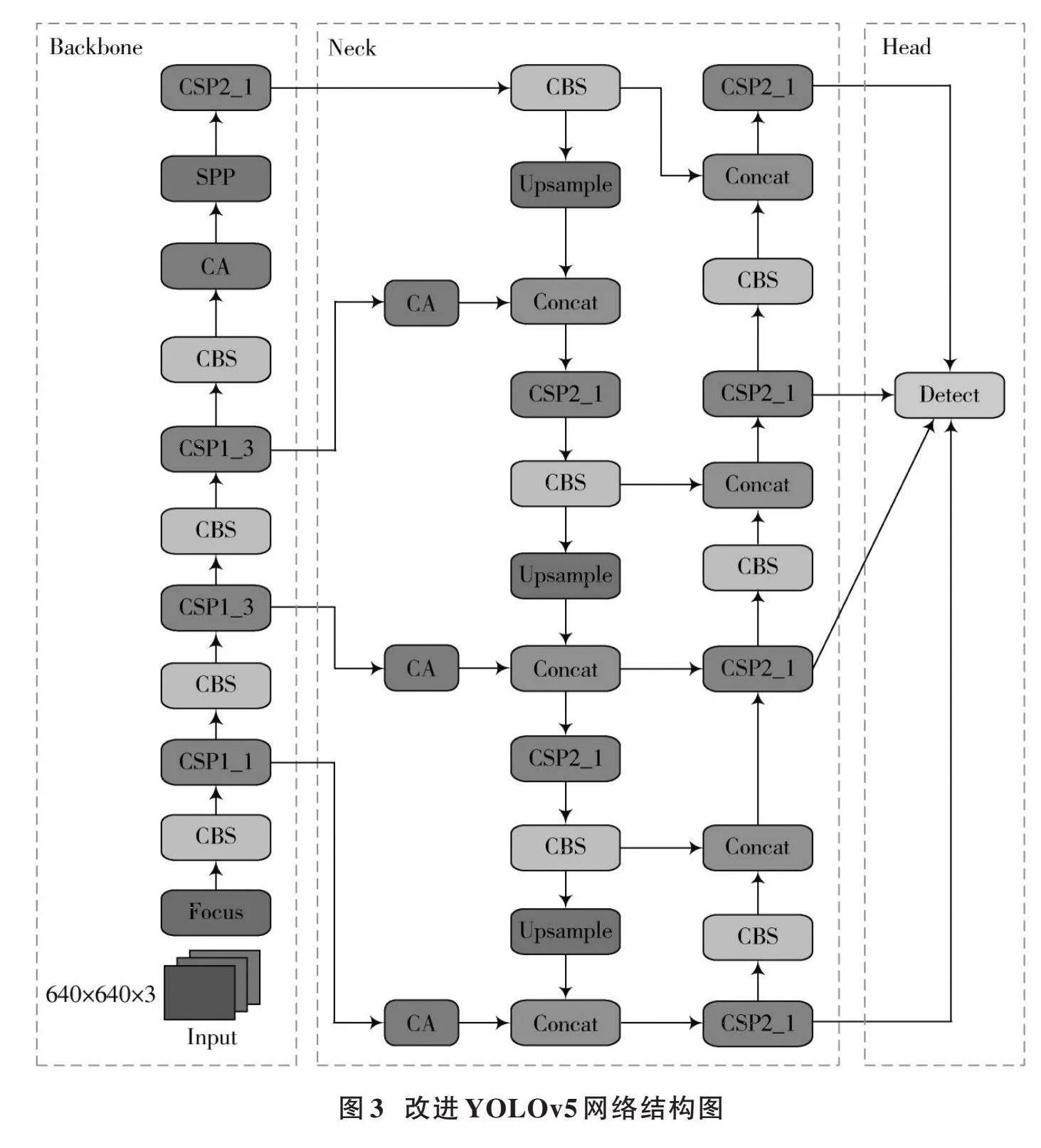
主干网络主要由Focus、CBS和SPP[21]等模块组成。如图2所示,Focus模块对输入图像进行切片,减少计算量并保证网络层获取更多特征信息,增大每个像素点的感受野,减少原始信息的丢失。CBS模块由卷积、BN和SiLU组成,有利于加快模型推理速度。主干特征提取网络采用SPP空间金字塔池化结构,通过池化核大小为5、9、13的卷积对输入特征图进行最大池化,避免图像失真,节约计算量。
1.1.2" 颈部网络
颈部网络是由特征金字塔网络(Feature Pyramid Network, FPN)[22]以及金字塔注意力网络(Pyramid Attention Network, PAN)[23]组成,FPN结构从上到下传递了高级的语义特征;PAN结构通过向下传递低级空间特征,使得各种尺寸的特征图均包含目标的语义信息和空间信息,从而实现了信息的全面覆盖。通过对主干特征网络提取的特征信息进行双向融合,进一步提升了特征提取的能力,从而达到特征增强和上下层信息流融合的目的。
1.1.3" 预测网络
预测网络涵盖了CIOU的损失和加权非极大值抑制,这两个因素共同作用于网络的稳定性和可靠性。本文提出了一种基于神经网络模型的自适应预测算法,该系统能够解决IOU(Intersection over Union)无法直接优化不重叠部分的问题,并在后期处理过程中保留最优框架,同时抑制这些冗余目标检测,从而实现更高效的优化。
2" 算法改进
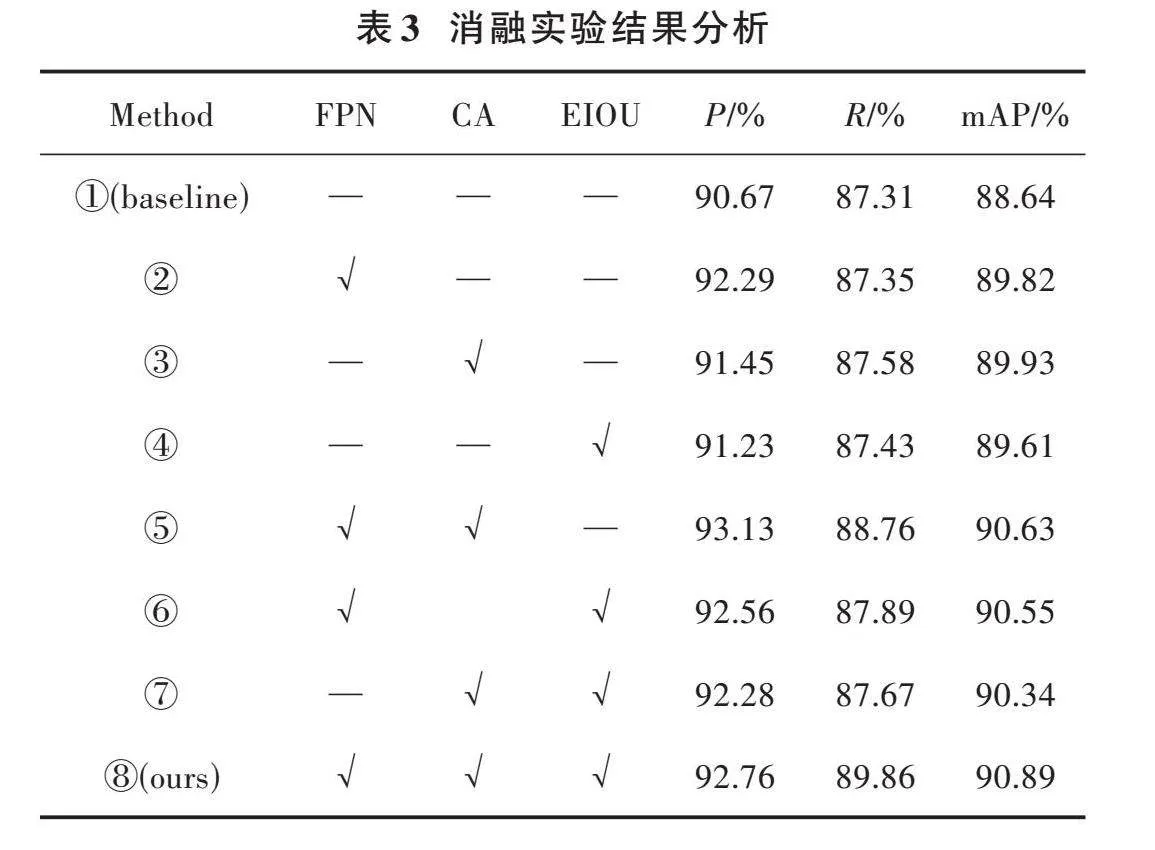
为解决安全帽佩戴图像检测中存在小目标、目标遮挡和密集人群而造成的漏检问题,提高模型对安全帽佩戴检测的性能以及鲁棒性,本文对YOLOv5算法中的特征融合网络、损失函数进行改进,并且加入注意力机制提高模型的表达能力。改进后的YOLOv5的整体结构如图3所示。
2.1" 特征融合网络的改进
YOLOv5模型结构设计了3个尺度特征检测层,分别为降采样得到的P3、P4、P5特征层,这三个特征层分别在主干特征提取网络的中间部分、中下部分和底层部分,为特征提取提供了必要的支撑。针对输入的640×640的图像,进行了8倍、16倍和32倍的下采样,得到了三个尺寸的特征图。在安全帽检测这项研究中,不同大小的目标可以在三个不同的尺度上被检测。在网络模型中低层特征图分辨率更高,包含目标特征明显,目标位置更准确;高层特征图在多次卷积操作后,获得了丰富的语义信息,但也会使特征图分辨率降低。由于在实际环境获取的图像中安全帽尺寸大小不一,摄像头与工人之间的距离较远,导致待检测的工人和安全帽的尺寸较小,从而造成漏检和检测效果差的情况。为缓解该现象,本文通过增加一个微尺度特征检测层,低层特征图与高层特征图通过拼接的方式融合后进行检测,可以有效提高检测准确率。本文添加一个对输入图像进行4倍下采样所得到的特征层P2,其对应的检测头具有感受野小、位置信息精确的优势,能够极大地提高小目标安全帽的检测效果。利用4个有效特征层进行FPN层的构建,将自顶向下传达高级语义特征和自底向上传达低级空间特征进行双向融合,极大地提升了检测性能,适用于施工场景中图像尺寸较小的安全帽检测。
2.2" 添加注意力机制
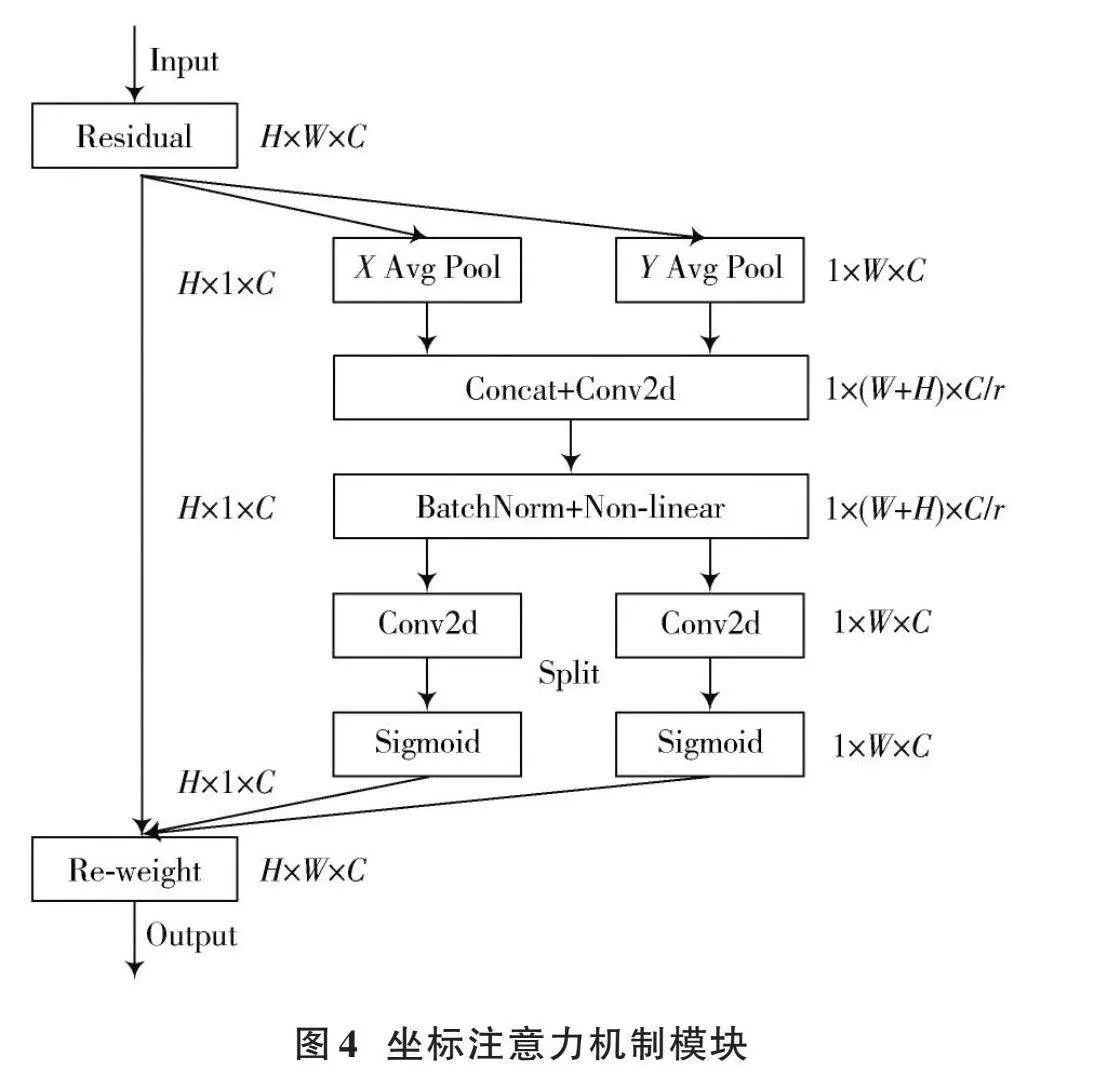
在深度神经网络中,坐标注意力机制(CA)被广泛运用于计算机视觉领域,以提高模型对特定内容和位置的关注度,从而优化模型性能。传统的注意力机制采用池化的方式对通道进行处理,这种方法只考虑了通道之间的信息,而忽略了物体的位置信息,从而导致空间信息的损失。同时,由于图像本身包含有大量冗余信息,因此无法有效地利用这些有用的特征。为了提高目标特征提取的准确性和抑制网络中的无效特征,采用特征融合网络中嵌入CA的策略,以达到更好的效果,并提出基于时空特性的图像配准算法。CA采用了一种特征重新校准策略,将位置信息嵌入到通道注意力中,从而实现通道注意力机制和空间注意力机制的有机结合。根据图像内容选择不同类型的特征并加入其中。方向敏感的特征图是由通道注意力机制在空间方向上形成的,而坐标敏感的特征图则是由空间注意力机制在一个方向上保留位置信息所形成的。由于这两个特性可以同时实现两种不同性质的特征融合,所以能有效地解决传统算法无法兼顾两类特征之间互补性的问题。通过将安全帽的重要特征信息与次要特征信息相结合,以进一步提高模型对待检测目标的检测精度和准确性。由于该算法需要在整个训练过程中自适应地更新权重值,导致计算量较大。因此,为了提高网络的精度,引入了一种坐标注意力机制,该机制具有简单灵活的特点,并且几乎不会带来任何额外的计算开销。
图4所呈现的是CA模块的具体实现构造。
CA模块的具体工作流程为:CA通过全局平均池化的方法将输入特征图分为宽度特征图和高度特征图两个方向,来获得图像在此两个方向的注意力,通过编码精确位置信息来获得高度特征图和宽度特征图。具体公式如下所示:
[zhc(h)=1W0≤ilt;Wxc(h,i)] (1)
[zwc(w)=1H0≤ilt;Hxc(j,w)] (2)
接着将获得的宽度和高度两个方向的特征图拼接在一起,之后将它们送入共享的卷积核1×1卷积变换函数进行变换操作。
[" " " " " " " f=δ(F1([zh,zw]))]" (3)
生成的[f]是一张空间信息在水平和竖直方向上的中间特征图,其中包含了一个非线性激活函数[δ],该函数被拆分为两个独立的张量,分别是[fh∈Rcr×h]和[fw∈Rcr×w],[r]以缩减率的形式呈现。
通过实验验证了算法可以得到较高准确率的图像分割结果。采用[1×1]卷积函数进行特征转换,将其转化为张量,其通道数与输入的[X]相同。
[gh=δFh(fh)] (4)
[gw=δFw(fw)]" (5)
通过以上计算后,本文会得到输入特征图中高度方向与宽度方向注意力权重的变化情况,从而为本文的研究工作提供了重要的参考依据。该方法获得的局部结构能够更好地描述原始纹理区域中的细节部分,并且可以有效减少冗余点。通过实验验证了算法可以得到较高准确率的图像分割结果。最后将原始特征图乘法加权计算得到具有注意力权重的特征图,该特征图表现出显著的宽度与高度方向特征差异。
[yc(i,j)=xc(i,j)×ghc(i)×gwc(j)] (6)
本研究将CA嵌入到改进的特征融合网络中,首先对于主干特征网络生成的4个有效特征层,在进行FPN层构建之前,对4个有效的特征层嵌入CA模块;其次,在进行FPN结构自顶向下传达高级语义特征时,对每次上采样后的结果嵌入CA模块;最后,在进行PAN结构自底向上传达低级空间特征时,对每次下采样的结果嵌入CA模块。
2.3" 改进YOLOv5算法的损失函数
YOLOv5算法采用预测框损失函数CIOU,但CIOU对预测框进行回归时,其宽度和高度纵横比一旦等于真实框宽度和高度时,预测框宽度和高度就不可能同时递增或递减,导致无法持续进行优化。
原始的CIOU损失函数如式(7)所示:
[LCIOU=1-IOU+ρ2(b,bgt)c2+αν] (7)
其中:
[α=ν(1-IOU)+ν] (8)
[ν=4π2arctanwgthgt-arctanwh2] (9)
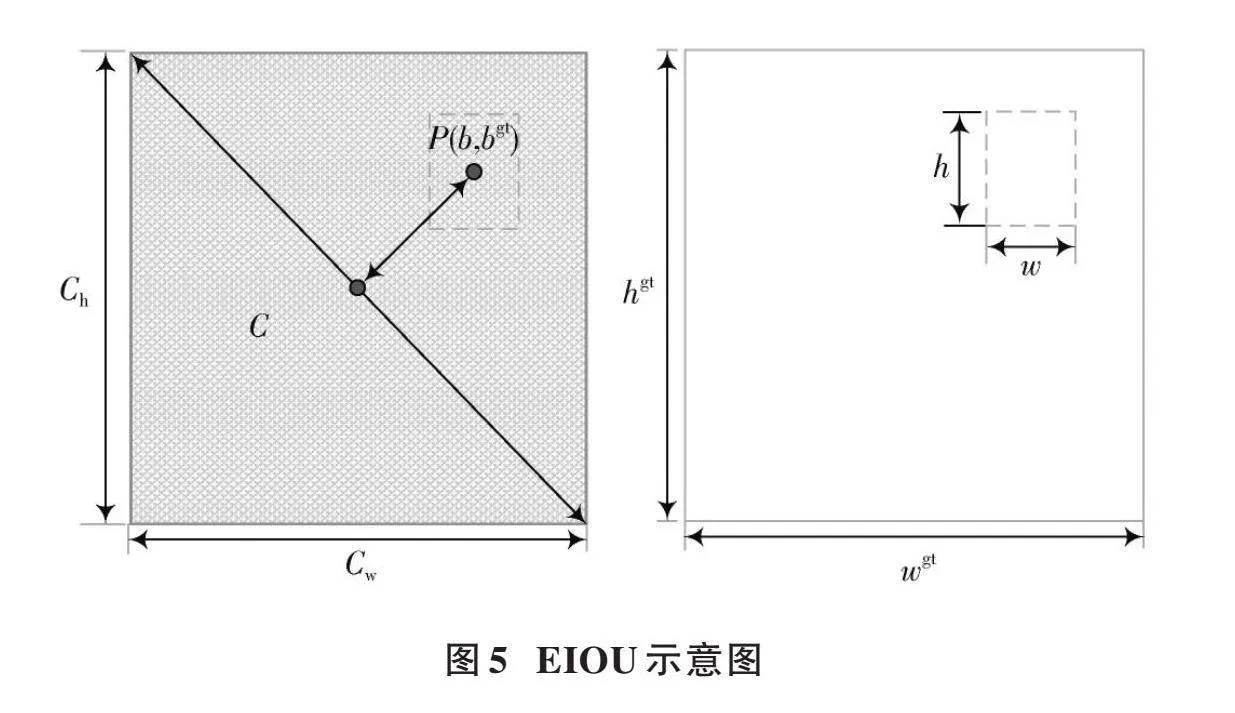
从上面的公式可以看出,CIOU将边界框的纵横比作为惩罚项加入到边界框损失函数中,在一定程度上可以加快预测框的回归收敛过程,但是一旦收敛到预测框和真实框的宽和高呈现出线性比例时,就会导致预测框回归时的宽和高不能同时增大或者减少,其惩罚项就失去了原本的作用,这样就无法有效地描述回归目标,可能会导致收敛缓慢并且回归不准确。为了解决这个问题,本文引入了EIOU(见图5),采用直接对[w]和[h]的预测结果进行惩罚的损失函数表达式,如公式(10)所示:
[LEIOU=LIOU+Ldis+Lasp=1-IOU+ρ2(b,bgt)c2+ρ2(w,wgt)c2w+ρ2(h,hgt)c2h]" (10)
式中:[c]代表涵盖预测框与真实框的最小外接框的对角线长度;[ch]和[cw]分别为其宽度和高度。在预测框与真实框中心点距离的计算中,将[ρ(w,wgt)]和[ρ(h,hgt)]分别视为横向差值和纵向差值,[ρ(b,bgt)]为预测框与真实框中心点距离,具体如下所示:
[ρ(w,wgt)=w-wgt] (11)
[ρ(h,hgt)=h-hgt] (12)
[ρ(b,bgt)=b-bgt] (13)
由EIOU损失函数计算公式可见,EIOU损失函数延续了CIOU中的方法,EIOU惩罚项以此为基础对纵横比影响因子进行拆分,并分别对目标框及锚框长宽进行计算,加快收敛速度。将纵横比中损失项分解成预测框宽高与最小外接框宽高之差,从而有效地增强收敛速度,回归精度明显提高。
3" 结果与分析
3.1" 实验环境以及实验参数
为了确保本文所提出的改进方法能够得到有效的验证,在实验环境中进行了相关配置,具体内容详见表1。
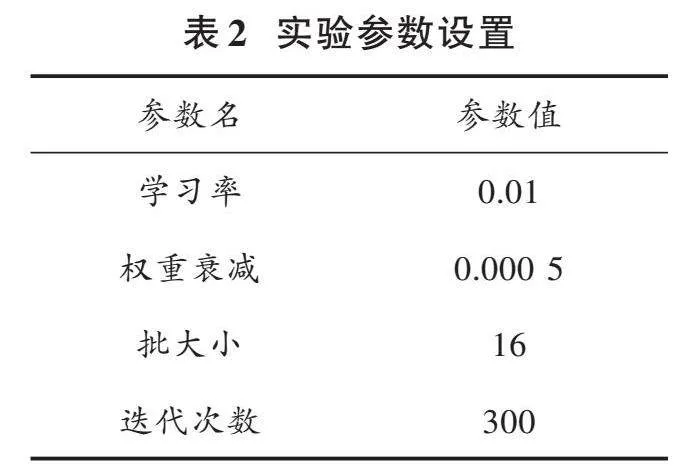
相关实验参数设置如表2所示。
3.2" 实验数据集
本文采用的数据集应包含不同季节和复杂天气背景下的施工现场,从而满足本文实验的要求。本实验采用的数据集是从公开的安全帽数据集SHWD(Safety⁃Helmet⁃Wearing⁃Dataset)中选择其中符合实验需求的一部分加上从网上爬虫获得的数据集,总共5 304张。该数据集包含不同尺度、不同场景、不同密集程度等各种情况,满足本文实验对环境复杂度的要求。该数据集分为两个类别,分别是戴安全帽的人(Helmet)与未戴安全帽的人(Person)。首先使用LabelImg工具对图像进行手动标注,然后按照8∶1∶1的随机原则将数据集划分为训练集、验证集和测试集,以便进行后续的数据处理和分析。部分数据如图6所示。
3.3" 评价指标
为了对模型的性能和安全帽检测的准确性进行评估,本文选用精确率(Precision, [P])、召回率(Recall, [R])和平均精度均值(mean Average Precision, mAP)这三个指标来衡量模型的表现,公式如式(14)~式(16)所示:
[P=TPTP+FP×100%] (14)
[R=TPTP+FN×100%] (15)
[mAP=01P(R)dRN] (16)
式中:TP(True Positive)为预测框和真实框相同的数量;FP(False Positive)为预测框和真实框不相同的数量;FN(False Negative)表示在预测过程中没有被正确检测到的图像中所包含的物体数量;[N]是本文中所划分类别的数量。
3.4" 实验结果与分析
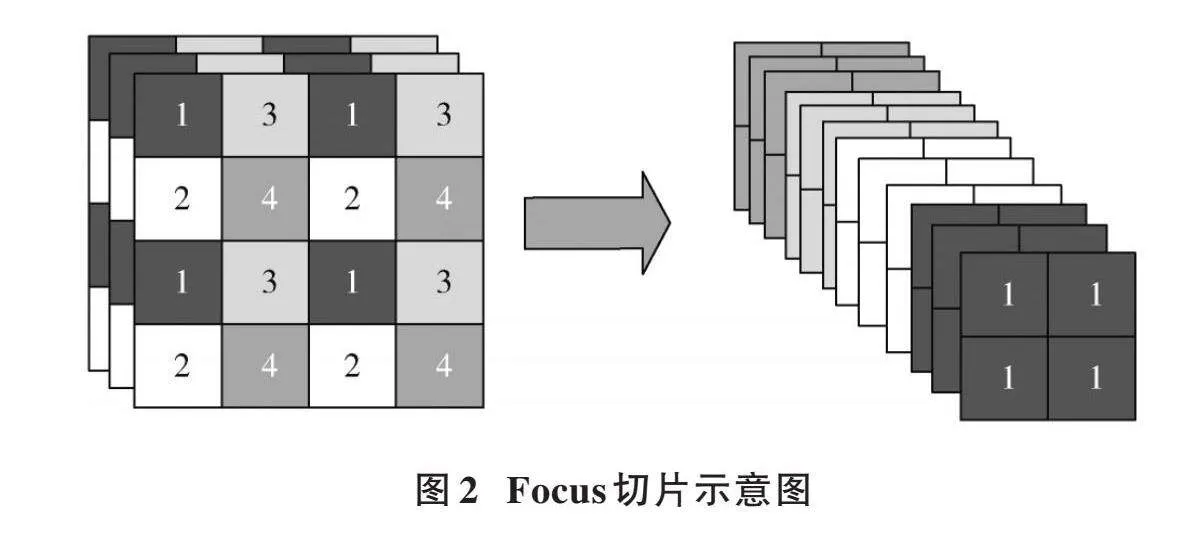
为了验证本文算法改进策略的有效性,基于YOLOv5基线进行了8组消融实验,各种实验模型得到的实验结果如表3所示。
表3中,FPN指在特征融合层添加微尺度检测层,CA为嵌入CA模块,EIOU为引入EIOU替换CIOU。通过实验①、实验②可以得知:引入FPN的目标检测网络相比于YOLOv5,mAP值提升了1.18%,说明特征融合层添加微尺度检测层融入了更多的底层特征图信息。通过实验②、实验⑤可以得知:引入CA的目标检测网络相对于YOLOv5+FPN,mAP值提升了0.81%,说明注意力机制可以有效地抑制无用信息,加强位置信息的提取,增强了特征提取能力。通过实验⑧可以得知:YOLOv5+FPN+CA+EIOU的mAP值为90.89[%],相比于YOLOv5基线提升了2.25[%]。总体来看,经过改进后的算法精度相比YOLOv5算法检测精度得到了较大的提升。
为了进一步验证改进算法的目标检测性能,在测试集上进行了一系列实验,以确保其有效性和可靠性。图7为原YOLOv5与改进算法在不同场景下的检测结果对比图,分为3个对照组。
图7a)和图7b)所呈现的是施工人员在复杂场景中佩戴安全帽的检测结果。从图7a)可以看出,原模型对于图中的小目标信息出现了漏检情况,而改进后的模型可以正常检测到。
观察图7c)与图7d)可以看出,拍摄密集人群时,本文算法检测结果明显更优,YOLOv5算法漏掉了右上角佩戴安全帽的目标。其根本原因是在卷积过程中模型会更偏向于关注图像的纹理信息,而忽略背景信息,使得最终生成的特征图信息不够丰富。而改进模型生成的特征图语义信息更加丰富,提高了精度,在一定程度上避免了漏检、误检的发生。
图7e)与图7f)是施工场地场景的YOLOv5原模型和本文改进模型的测试结果。从图7e)可以看出,部分被障碍物遮挡到的目标无法被识别出来从而导致漏检。而从图7f)中可以看出,改进后的YOLOv5模型网络可以正确识别出被遮挡到的目标,将坐标注意力机制嵌入特征融合层中可以显著提升重要特征信息的获取能力,使得最终生成的特征图信息更加丰富,提高了模型的表示能力,加强了模型对被遮挡目标的检测能力。
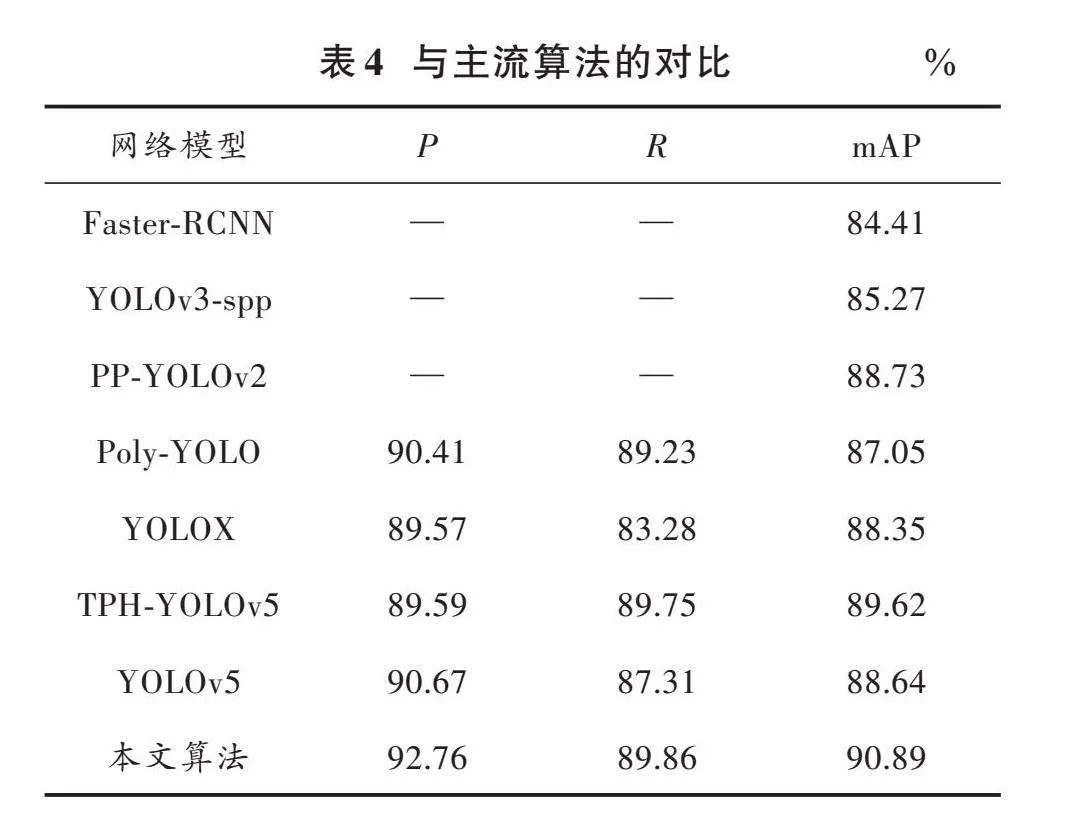
4" 与现有主流算法的对比实验
选取当前具有代表性且性能优异的目标检测算法分别训练同一个安全帽数据集,比较模型的性能,实验结果如表4所示。通过对比可知,本文基于YOLOv5改进后的算法在安全帽数据集中有更高的精度,在面对安全帽佩戴检测问题上具有更高的针对性。相较于Faster⁃RCNN,其mAP的精度提高了6.48%,相比在小目标领域检测精度比较高的TPH⁃YOLOv5提高1.27%。与改进前的原模型相比,mAP提高了2.25%,在多种不同模型的算法对比中表现出了一定的优越性。总体而言,本文所提出的优化方案具备相当的有效性。
5" 结" 语
本文提出一种基于改进YOLOv5的安全帽检测算法。首先,在特征融合层添加微尺度检测层,提取更丰富的安全帽特征信息,极大地提升了检测性能;其次,在改进的特征融合层中嵌入CA,增强重要的特征信息,抑制无用的特征信息,提高模型的表达能力;最后,采用EIOU损失函数替换CIOU损失函数解决了纵横比的模糊定义,加快了网络收敛,有助于提高回归精度。实验结果表明,所提出的改进版YOLOv5算法用于安全帽检测的平均精度值可以达到90.89%,对于安全帽的检测这一方向的研究具有良好的成效。在未来的工作中,将扩展现有方法实现对安全帽语义的识别,提高安全帽检测的实用性,并进一步优化安全帽检测网络的速度和检测性能。
参考文献
[1] WANG L, TANG J, LIAO Q. A study on radar target detection based on deep neural networks [J]. IEEE sensors letters, 2019, 3(3): 1⁃4.
[2] PATHAK A R, PANDEY M, RAUTARAY S. Application of deep learning for object detection [J]. Procedia computer science, 2018, 132: 1706⁃1717.
[3] JAMTSHO Y, RIYAMONGKOL P, WARANUSAST R. Real⁃time license plate detection for non⁃helmeted motorcyclist using YOLO [J]. ICT express, 2021, 7(1): 104⁃109.
[4] 徐守坤,王雅如,顾玉宛,等.基于改进Faster RCNN的安全帽佩戴检测研究[J].计算机应用研究,2020,37(3):901⁃905.
[5] 吴雪,宋晓茹,高嵩,等.基于深度学习的目标检测算法综述[J].传感器与微系统,2021,40(2):4⁃7.
[6] YING Z, HONGMEI G, WENGANG Y, et al. Earthquake⁃induced building damage recognition from unmanned aerial vehicle remote sensing using scale⁃invariant feature transform characteristics and support vector machine classification [J]. Earthquake spectra, 2023, 39(2): 962⁃984.
[7] AORUI G, HEMING S, CHAO L, et al. A novel fast intra algorithm for VVC based on histogram of oriented gradient [J]. Journal of visual communication and image representation, 2023, 95: 103888.
[8] 赵恒,胡胜男,徐进霞,等.基于DBN⁃SVM的电力智慧工地异常行为识别[J].自动化与仪器仪表,2023(5):92⁃95.
[9] GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2014: 580⁃587.
[10] XU X, ZHAO M, SHI P, et al. Crack detection and comparison study based on faster R⁃CNN and mask R⁃CNN [J]. Sensors, 2022, 22(3): 1215.
[11] CHEN Y, LI W, SAKARIDIS C, et al. Domain adaptive faster R⁃CNN for object detection in the wild [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2018: 3339⁃3348.
[12] 徐守坤,王雅如,顾玉宛,等.基于改进FasterRCNN的安全帽佩戴检测研究[J].计算机应用研究,2020,37(3):901⁃905.
[13] ZHOU F, ZHAO H, NIE Z. Safety helmet detection based on YOLOv5 [C]// 2021 IEEE International Conference on Power Electronics, Computer Applications (ICPECA). New York: IEEE, 2021: 6⁃11.
[14] HUANG L, FU Q, HE M, et al. Detection algorithm of safety helmet wearing based on deep learning [J]. Concurrency and computation: Practice and experience, 2021, 33(13): e6234.
[15] LONG X, CUI W, ZHENG Z. Safety helmet wearing detection based on deep learning [C]// 2019 IEEE 3rd Information Technology, Networking, Electronic and Automation Control Con⁃ference (ITNEC). New York: IEEE, 2019: 2495⁃2499.
[16] 李航,朱明.基于深度卷积神经网络的小目标检测算法[J].计算机工程与科学,2020,42(4):649⁃657.
[17] AN Q, XU Y, YU J, et al. Research on safety helmet detection algorithm based on improved YOLOv5s [J]. Sensors, 2023, 23(13): 5824.
[18] HOU Q, ZHOU D, FENG J. Coordinate attention for efficient mobile network design [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2021: 13713⁃13722.
[19] ZHANG Y F, REN W Q, ZHANG Z, et al. Focal and efficient IOU loss for accurate bounding box regression [J]. Neurocomputing, 2022, 506: 146⁃157.
[20] ZHENG Z, WANG P, LIU W, et al. Distance⁃IoU loss: Faster and better learning for bounding box regression [J]. Procee⁃dings of the AAAI Conference on Artificial Intelligence, 2020, 34(7): 12993⁃13000.
[21] 周华平,邓彬.融合多层次特征的deeplabV3+轻量级图像分割算法[J/OL].计算机工程与应用,1⁃9[2023⁃08⁃31].http://kns.cnki.net/kcms/detail/11.2127.TP.20230831.1205.012.html.
[22] CENGGORO T W, ASLAMIAH A H, YUNANTO A. Feature pyramid networks for crowd counting [J]. Procedia computer science, 2019, 157: 175⁃182.
[23] LIU S, QI L, QIN H, et al. Path aggregation network for instance segmentation [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2018: 8759⁃8768.
猜你喜欢
数字技术与应用(2019年2期)2019-05-14 08:25:10
现代电子技术(2018年8期)2018-04-13 06:36:32
软件工程(2017年11期)2018-01-05 08:06:09
智能计算机与应用(2017年5期)2017-11-08 12:11:51
科技资讯(2017年11期)2017-06-09 18:28:13
电子技术与软件工程(2017年5期)2017-04-23 23:37:37
现代电子技术(2017年7期)2017-04-14 19:20:42
软件(2016年4期)2017-01-20 09:38:03
科教导刊·电子版(2016年28期)2017-01-10 22:25:23
科学与财富(2016年28期)2016-10-14 23:45:18
