
基于深度学习和自注意力的光度立体方法方明权
2024-08-06 00:00:00宋滢
软件工程 2024年8期


关键词:光度立体;深度学习;自注意力;残差网络
中图分类号:TP389.1 文献标志码:A
0 引言(Introduction)
光度立体作为逆渲染邻域的一个分支,一直是计算机图形学中重要的研究方向,它广泛地应用于虚拟现实、视频游戏及影视制作等行业[1]。光度立体通过图像与光照之间的联系,推断出物体表面的法向信息。未标定的光度立体(Uncalibrated Photometric Stereo)是光度立体的一个重要的研究方向,旨在解决实际场景中,当相机和光源参数未精确标定时,如何准确推断物体表面法线的问题。在未标定的光度立体方法中,算法不要求事先知道相机和光源的内部参数,而是试图通过观察物体表面在不同光照条件下的亮度变化,还原物体的三维信息。这使得未标定的光度立体更具实用性,在现实应用中,准确地获得标定参数颇具挑战,甚至有时并不现实。通过解决未标定的问题,实现从实际图像中更加灵活地获取实用的三维几何信息。
本文设计了一个基于自注意力和多重最大池化的未标定光度立体算法模型。在估计光照信息阶段,通过在网络中加入自注意力模块,帮助网络能学习到长距离特征之间的联系,从而提升其感知能力。在法线估计阶段,本研究设计了一个多重特征提取和融合网络,通过对不同深度特征的有效融合,提升网络对多图像输入时的鲁棒性。
1 相关工作(Related work)
在传统的光度立体方法中[2],通常会假设物体的表面是基于朗伯反射模型(Lambertian Shading),这是一种理想的光照模型,然而现实中鲜有物体能完全符合其假设。后续提出的非朗伯模型光度立体方法更贴近现实物体表面特性,这些方法虽然更适用于现实的物体表面,但是均属于传统的计算方法,因此在可扩展性和使用效率上受到了限制。近年来,深度学习在计算机图形学与计算机视觉领域的应用为光度立体研究提供了新的思路和路径。
1.1 标定的光度立体方法
在深度学习中,标定的光度立体方法通常需要将光照信息作为网络训练的先验知识。CHEN 等[3]设计了PS-FCN(Photometric Stereo Fully Convolutional Network)网络用于估计表面法线,该方法将多张输入图片和其光照信息一起输入网络中,并使用一个最大池化层融合多张图片的共同特征,同时他们也提出了一个名为LCNet(Lighting Calibration Network)的网络用于估计光照的强度和方向。JU等[4]设计了一个多尺度的特征融合模块,该模块可以对高分辨率和深度的特征进行提取,将不同输入的同一层次特征分别叠加并输入下一层级的网络中,并利用多个最大池化层融合结果,同时他们还设计了一个卷积模块用于提高法线推断的准确度。虽然这些方法可以很好地估计法线,但是需要先验的光源信息,因此其实用性受到了限制。
1.2 未标定的光度立体方法
未标定的光度立体方法一般只使用图像信息而不依赖具体的光照条件来估计物体法线信息。CHEN等[5]提出一个名为SDPS-Net(Selfcalibrating Deep Photometric Stereo Network)的网络结构,其采用分段的方式分别估计光照和法线信息。LI等[6]提出了一种可以在常规光照作用下联合优化几何物体形状、光方向和光强度的方法。TIWARI等[7]提出了一个深度学习框架,分别将光照估计、图片重照明及表面法线估计3个任务结合,通过输入单张照片,该网络可以提取图片的全局和局部特征,并使用联合训练提高网络的效果。CHEN等[8]提出了一个名为GCNet(Guided Calibration Network)的网络结构,分别设计了一个光照估计网络和法线估计网络,采用独立和联合训练的方式分别优化网络的参数。
2 光度立体网络模型(The photometric stereonetwork model)
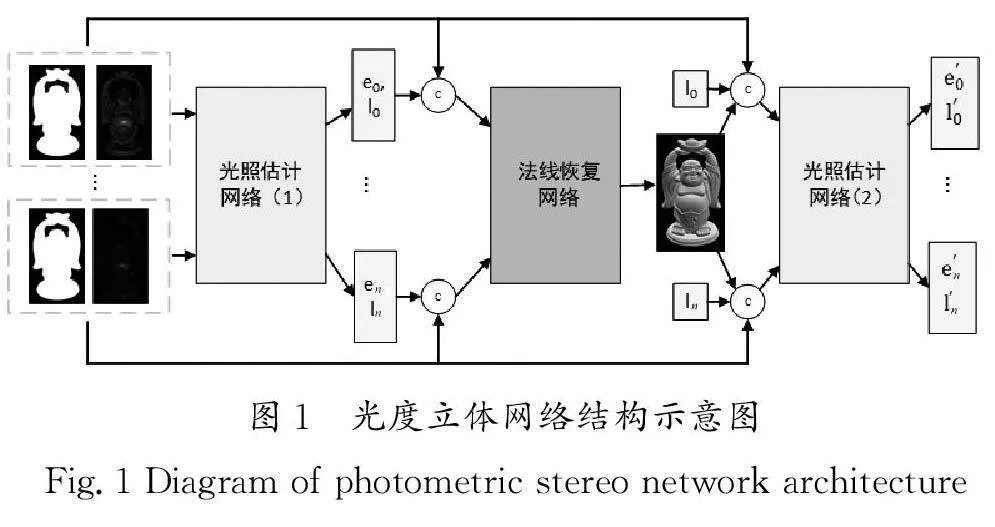
本文的网络结构由两个部分组成,分别是光照估计网络和法线恢复网络。网络结构的整体组合方式借鉴了CHEN等[8]的方法(图1),分别使用了两个光照估计网络和一个法线恢复网络。网络的输入是若干张不同光源作用的目标图像和物体遮罩图,将遮罩图和一张目标图像组合作为一组输入。通过利用不同光照下的图像,可以为网络提供充足的信息,实现光源和法向的准确估计。本文模型的训练流程如下:首先,使用第一个光照估计网络对输入图片的光源信息进行初步的预测;其次,法线恢复网络根据初步预测的光源信息和输入图片恢复图片的法线信息;最后,第二个光照估计网络总结已有的信息,进而恢复更准确的光照方向和光照强度。
2.1 光照估计网络
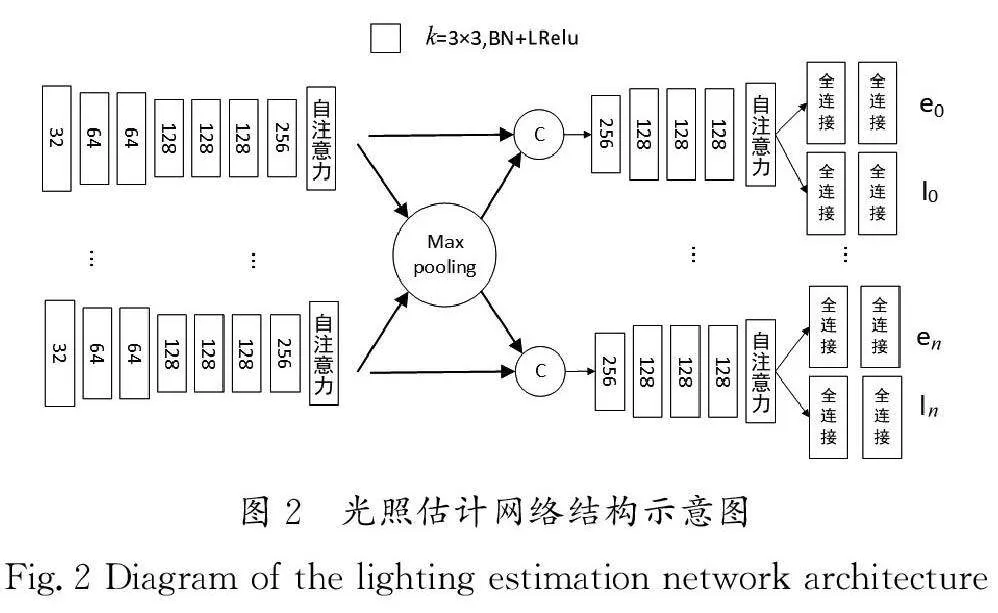
光照估计网络结构示意图如图2所示。对于输入的图片,首先,经过了7个卷积层和一个自注意力模块,每个卷积层后都加入了批归一化层和Leaky Relu激活函数,用于提高网络的性能、稳定性及泛化能力。其中,每个卷积核的大小都是3×3,采用步长为1和步长为2的卷积核交替对特征进行提取。其次,通过一个最大池化层将来自不同输入的特征进行融合,并拼接到各自原来的输入中。最后,通过4个卷积层、1个自注意力模块和2个全连接层,分别对光照方向和光照强度进行估计。其中,自注意力模块的设计借鉴了ZHANG等[9]的方法。
2.2 法线恢复网络
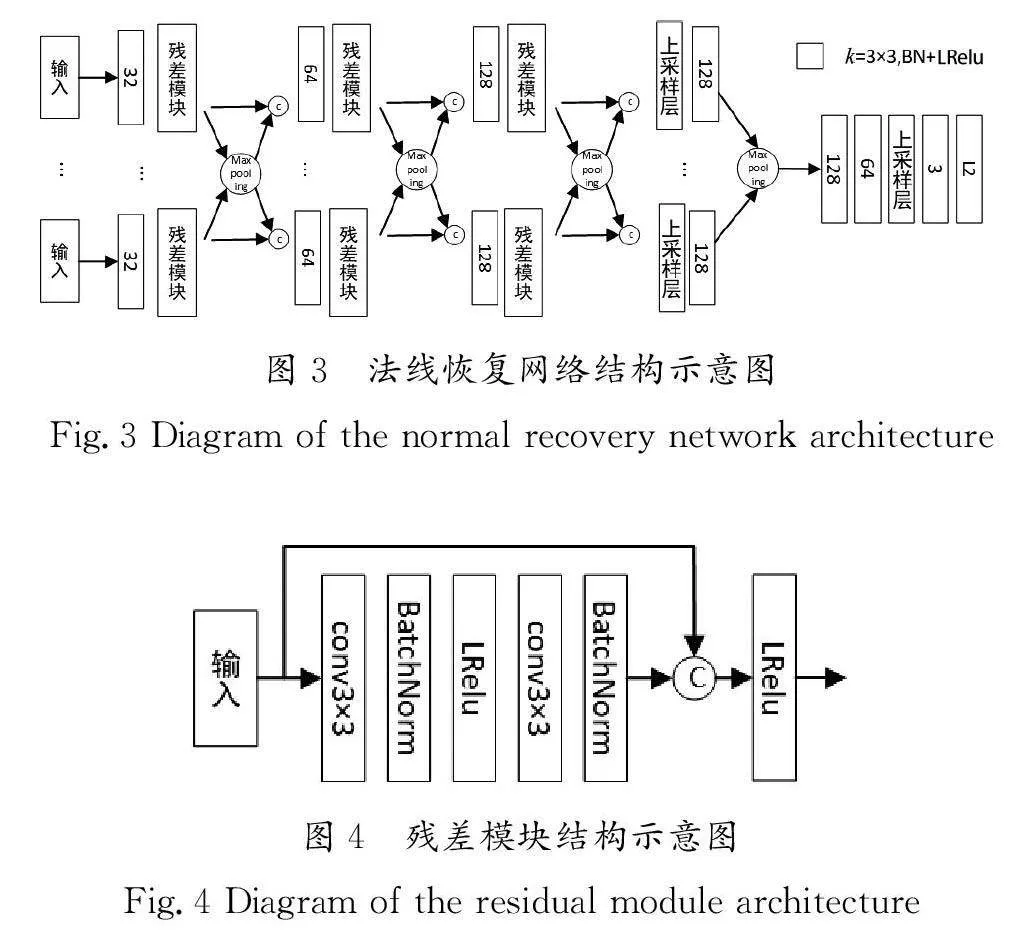
本文设计的法线恢复网络结构示意图如图3所示,它将图片和光源等信息作为输入条件,因为要对多个不同输入进行特征提取,所以该网络整体上采用并行计算的方式。法线恢复网络的前半部分总共有3组卷积层,由残差模块和最大池化层组成特征提取模块,每个卷积层都包含了批归一化层和LeakyRelu激活函数,使得非线性变换的结果更容易被学习。第一组的特征提取模块的卷积层的卷积核大小为3×3,步长为1,主要是为了提取浅层特征。后两组的卷积层的卷积核大小为3×3,步长为2,通过将步长设置为2,可以提升卷积核的感受野,并压缩提取后特征图的大小,从而起到减少计算量和避免过拟合的作用。
法线恢复网络的后半部分通过一个上采样层、卷积层及最大池化层,将所有输入的特征融合后进行综合性的卷积操作,其中上采样层采用反卷积的结构可以学习到更多的参数。将融合后的特征通过多个卷积和一个上采样层后,再通过L2激活函数将结果映射到真实的法向分布空间。
本文设计的残差模块结构示意图如图4所示,输入特征经过一个卷积核大小为3×3,步长为1的卷积层,再依次经过批归一化层、Leaky Relu激活函数、卷积层及批归一化层后,通过跳跃连接,将最初的输入和经过卷积后的输出合并后,通过Leaky Relu激活函数进行非线性变换映射。通过引入跳跃连接,使得残差模块不再直接学习输入到输出的映射,而是学习输入到输出的残差关系,从而更利于模型的学习,并减少过拟合和梯度消失等问题。
3 实验结果与分析(Experimental results andanalysis)
3.1 数据集
本文训练所使用的数据集来自CHEN等[10]提出的合成数据集,该数据集包含了blobby shape和sculpture shape两个部分,其中blobby shape数据集包含25 920个样本,sculptureshape数据集包含59 292个样本,总共85 212个样本。在训练过程中按照99∶1的比例划分训练集和验证集,并运用介于[-0.02,0.02]的噪声对样本进行数据增强,从而增强模型的泛化能力和鲁棒性。
3.2 实验环境
本文的实验环境在Windows11系统下进行,使用的GPU为RTX4080-16GB,CPU为AMD 5600X。本文使用PyTorch1.13.1作为训练用的框架,Python版本为3.8,使用Adam优化器,在训练过程中根据模型的特点动态调整了学习率和批量大小(BatchSize),从而加快模型的拟合速度。
3.3 结果分析
本文首先对光照估计网络的效果进行结果分析。使用DiLiGenT[11]作为测试用的数据集,该测试数据集总共有10个不同类型的样本,每个样本各包含96份光度图和法向信息图。在评价光照方向和法向时,使用平均角度误差(Mean AngularError,MAE)作为评价标准。在评价光照强度时,使用尺度恒定相对误差作为评价标准。
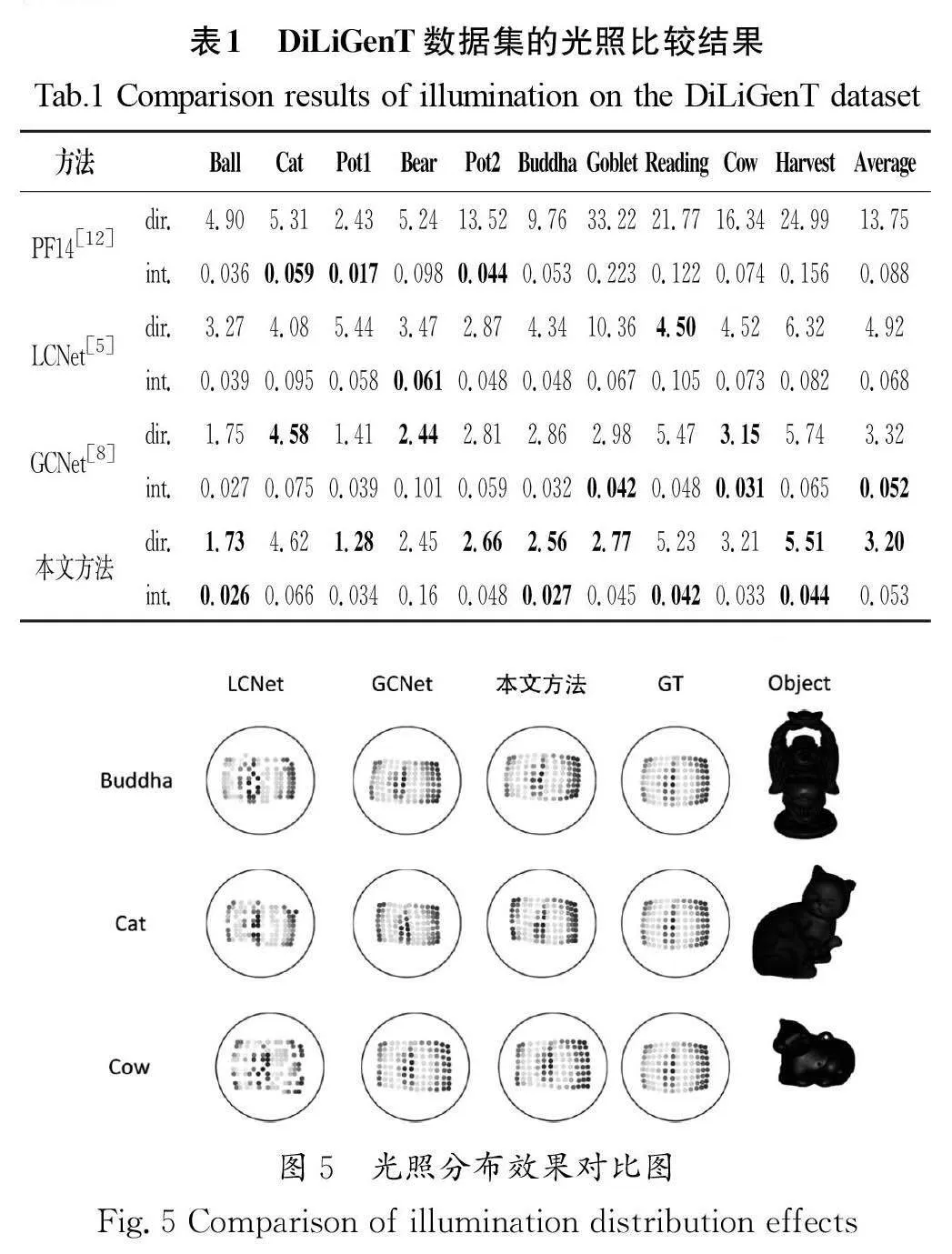
本文分别选择PF14[12]、LCNet和GCNet作为光照结果的比较对象,比较结果如表1所示,其中最好的数值以粗体形式标出。从表1中的数据可以发现,本文方法在光源法向的平均角度上有更低的误差,而光源强度也与表现最好的GCNet十分接近。
本文选取了部分光照分布效果对比图,这些样本均来自DiLiGenT数据集,如图5所示,在Buddha、Cat和Cow三个样本上,本文方法模拟的光照分布效果与真实光照分布更加接近,这从侧面印证了本文方法对提升光照分布的正面作用。
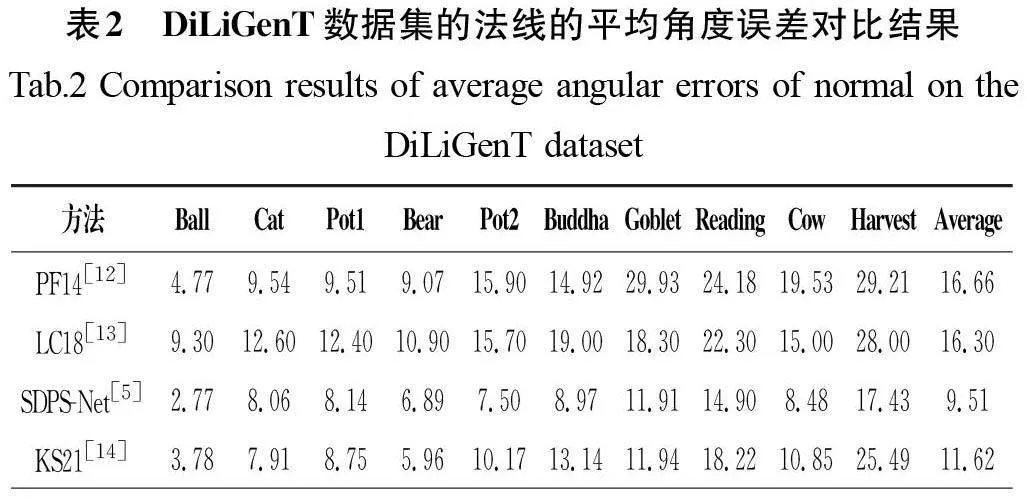
在分析对比法向网络的效果时,本文选取了目前效果最好的非标定光度立体方法作为对比对象,包括PF14(A RobustSolution to Uncalibrated Photometric Stereo Via Local DiffuseReflectance Maxima)[12]、LC18[13]、SDPS-Net[5]、KS21(InverseRendering for Photometric Stereo)[14]和SK22(Neural ArchitectureSearch for Uncalibrated Deep Photometric Stereo)[15]。除此之外,本文还将GCNet[8]的光照预测结果作为PS-FCN[10]的输入,将两者组合作为其中一个对比对象。DiLiGenT数据集的法线的平均角度误差对比结果如表2所示,本文方法在平均角度误差上取得了更好的表现,说明本文对法线恢复网络功能设计的有效性。
4 结论(Conclusion)
本文提出了一种基于深度学习和残差网络的光度立体方法。该方法采用分段的方式分别对输入图像的光源信息和法线进行估计,通过结合使用多重池化和残差网络的方式,提升了网络的拟合性能。在光源估计网络中,通过在特征融合前后加入自注意力模块使得网络可以学习到长距离的像素特征关系,从而提高网络对图像分解与信息的利用能力。在法线恢复网络中,通过设计由浅入深的特征融合层,使得网络可以更充分融合多图像输入的信息,同时在卷积过程中使用残差块的方式,可以加快网络反向传播的进程,从而提高特征的利用效率。
本文提出的基于深度学习和残差网络的光度立体方法虽然有助于提升对光源和法线估计的准确度,但是该方法存在一定的局限性,究其原因是本文方法采用先估计光照后估计法向的方式,这种分段式的网络设计虽然可以显著减少模型训练和拟合所需的时间,但是估计法线依赖估计光源的准确度,所以不可避免地存在误差。为了更好地解决这一问题,可以引入更多约束的方式,例如将输入图像分解为更全面的材质属性,将这些材质属性综合的渲染结果作为训练网络的约束方式,从而减小误差,提升准确度,但也会扩大模型的规模,因此需要做好兼顾与平衡。
作者简介:
方明权(1997-),男,硕士生。研究领域:计算机图形学,深度学习。
宋 滢(1981-),女,博士,副教授。研究领域:计算机图形学。
