
基于注意力权重机制和引导成本体积激励的三维重建多视图立体网络算法研究
2024-08-06 00:00:00郭晓栋贺平安代琦
软件工程 2024年8期


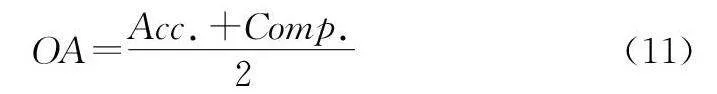
关键词:多视图立体;三维重建;注意力机制;成本体积
中图分类号:TP391 文献标志码:A
0 引言(Introduction)
多视图立体重建(MVS)使用多个不同视角的图像还原场景的三维几何结构,其作为计算机视觉领域的一个基本问题被广泛关注和研究了几十年[1]。
近年来,基于成本体积的深度学习方法已成为利用高分辨率图像进行MVS的首选技术[2-5]。这些方法在整个深度范围内对平面均匀采样构建成本体积,但若初始估计的深度与实际深度相差较大,则误差会迭代到最终精细层次,导致结果错误。
本文针对初始深度估计误差大的问题,在CVPMVSNET(Cost Volume Pyramid Based Depth Inference for Multi-ViewStereo)[4]的基础上设计了新的MVS网络。引入关注感受野的注意力机制[6]到特征提取网络,有利于后续的注意力加权学习。提出了注意力加权模块,以更加关注图像金字塔的多层次细节并计算出更精细的特征图,同时在三维卷积更深层,引入引导成本体积激励模块(GCE)[7]以补充成本体积。通过大量实验证明,该模型能平滑初始深度估计,在DTU数据集上的表现优于目前大多数先进算法的表现。
1 相关工作(Related work)
1.1 基于学习的MVS算法
采用卷积神经网络学习从多个视角图像推断深度图,再通过单独的多视图融合过程完成三维模型重建。YAO等[8]提出MVSNET(Multi-View Stereo Network)利用图像的单应性变换和基于方差的成本度量构建成本体积,随后通过三维卷积进行正则化处理,以获取深度图。虽然这种方法的重建效果较好,但是对内存的要求高。为了处理高分辨率图像,一些循环方法[9-11]使用GRU或者LSTM 以递归方式构建成本量,但通常为减少空间需求,会牺牲更多的运行时间。一些研究[12-14]不使用固定分辨率构建成本体积,而是通过从粗到精的多尺度方法迭代深度估计。这些多尺度方法通过在低分辨率下构建粗的成本体积估计深度图,然后在较高分辨率下构建局部的成本体积优化初始深度图。也有方法[14]注意到构建成本体积过早决策,但其稀疏体积造成了过多的参数及使用过多的内存。尽管从粗到精的多尺度方法迭代深度估计方式已经取得了较好效果,但是依然面临空间信息不够丰富和初始深度图过早估计的问题。本文引入关注感受野的空间通道注意力解决空间信息不够丰富的问题。与现有研究[14]不同,本文利用注意力加权和引入引导成本激励模块尝试解决初始深度图过早估计的问题。
1.2 立体匹配
立体匹配方法通常包括匹配成本计算、成本聚合、优化和视差细化4个过程的全部或部分[15-16]。本文受卷积神经网络的启发,引入端到端网络计算立体匹配和成本聚合,以获得更好的匹配结果。文献[17]至文献[19]尝试利用多尺度思想进行视差建模优化提升运算速度。文献[17]和文献[18]表明,三维卷积在聚合成本体积阶段,神经网络能从数据中捕获几何信息,利用空间变化的模块补充和丰富三维卷积。在文献[7]中利用引导成本体积激励方法实现了基于空间依赖的三维操作,提升了关注效率和速度。
1.3 注意力机制
注意力机制已被广泛应用于自然语言处理中,以捕捉上下文依赖信息[20]。注意力机制在语义分割、图像字幕和目标分类等计算机领域[21]都得到了应用。卷积神经网络的核心构建块是卷积算子,它能使网络通过每层的局部感受野内融合空间和通道信息构造信息特征。文献[22]至文献[24]将重点放在通道关系上,设计出有效的通道注意力,文献[25]和文献[26]将通道和空间注意相结合以取得更好的效果。但是,受限于卷积参数共享问题,现有的注意力并没有专门针对感受野的空间特征,ZHANG等[6]提出的方法很好地解决了上述问题。
2 方法(Method)
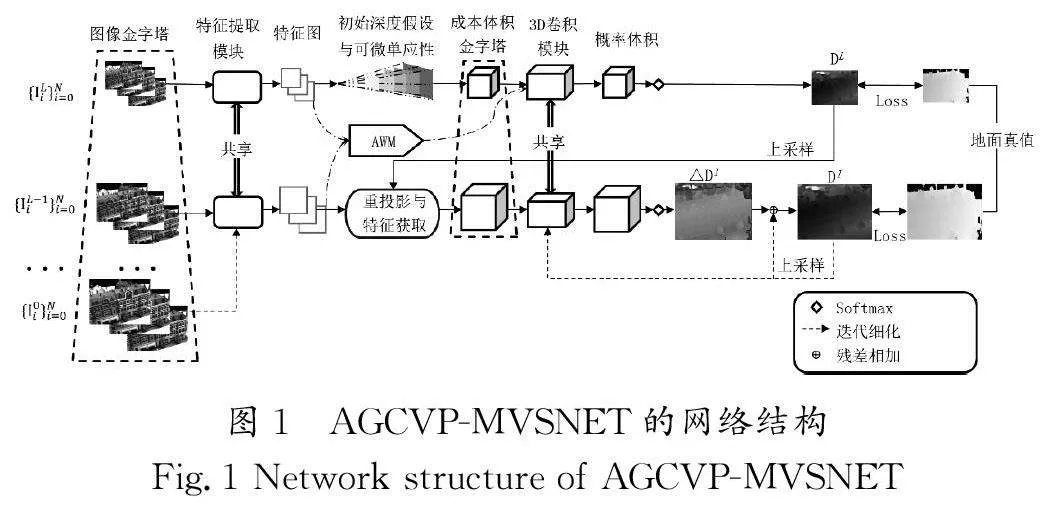
本文提出了多视图立体推断方法(AGCVP-MVSNET),其网络结构设计充分借鉴了立体匹配方法和注意力机制,利用基于由粗到精的方法构建成本体积金字塔,实现深度推断,AGCVP-MVSNET的网络结构如图1所示。
本文对多视图图像进行下采样,形成图像金字塔,构建了权值共享的特征提取模块,对每一层进行特征提取。深度推断从最粗层(L层)开始,使用基于方差的度量构建成本体积,并通过三维卷积层和Softmax操作对成本体积进行正则化,生成初始深度图。根据初始深度图和深度残差假设,迭代地构建部分代价体,以获得经过优化的更精确的深度图。本文方法的关键在于充分利用图像金字塔的每一层,生成注意力权重特征图并应用于正则化生成初始深度图,以避免迭代估计产生更大误差的深度估计。
2.1 特征提取网络
目前,类似于FPN(Feature Pyramid Network)的分层特征提取方法已经取得了不错的效果。这些模型通过堆叠多个卷积层,使网络能够学习到输入数据的复杂特征。然而,不同层级的卷积特征之间存在通信不畅的限制,导致特征表达能力无法达到理想的效果。
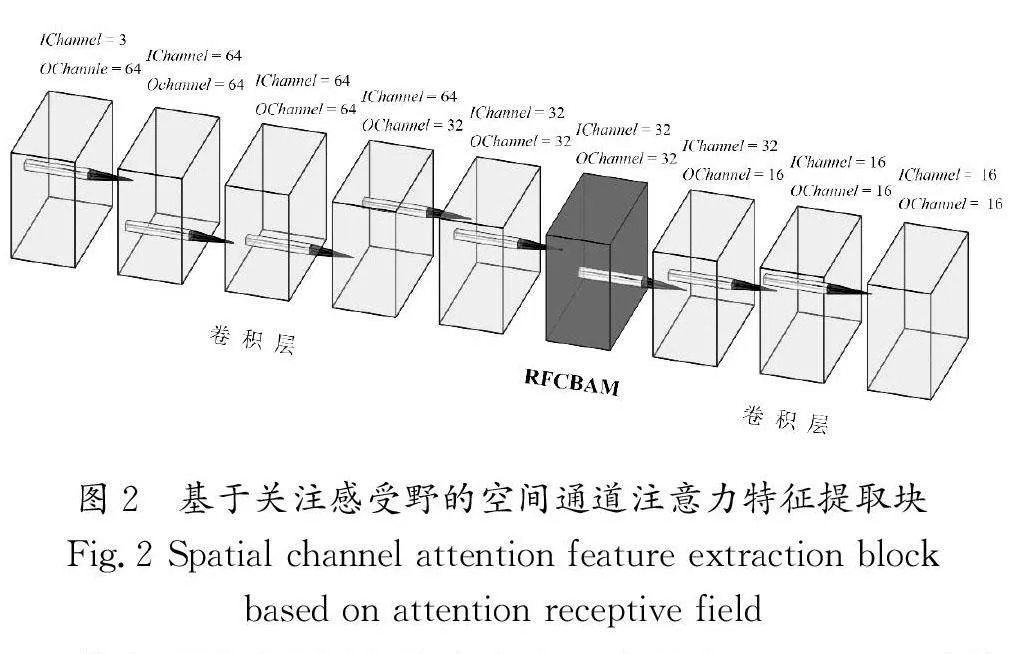
本文将RFCBAM(Receptive Filed Convolutional BlockAttention Module)[6]引入特征提取模块的中间层,专注于感受野的空间通道注意力机制。特征提取块由8个卷积层和1个RFCBAM中间层组成,基于关注感受野的空间通道注意力特征提取块如图2所示。
其中,所有卷积层的核大小为3,步长为1,IChannel为输入通道,OChannel为输出通道,中间层的特征通常包含更多的语义信息,将其放置在此处有助于更好地融合上下层信息,从而使特征提取网络发挥更好的效果。
关注感受野空间特征的卷积运算。目前,空间注意力机制最大的限制是不能完全解决大卷积核的参数共享问题。空间注意力的每个特征图上的像素点会对应乘以一个注意力权重。然而进行这样的卷积运算时,感受野特征重叠,导致注意力权重会在每个感受野特征中进行共享,而感受野注意力(Receptive-Field Attention,RFA)解决了这个问题,并考虑了感受野中每个特征的重要性。RFA通过和卷积操作的相互依赖提出了感受野注意卷积(RFACONV[6]),其是通过分组卷积提取感受野空间特征,计算公式如下:
3 实验(Experiment)
3.1 数据集
本文采用了DTU数据集和最新发布的BlendedMVS数据集进行实验验证。DTU数据集[28]是一个广泛使用的3D重建基准数据集,其特点是图像分辨率高,富含丰富的纹理和细节。此数据集涵盖124个场景,每个场景包含49个不同视角的拍摄,且每个视角均有7种不同亮度的图像,每张影像的分辨率为1 600×1 200。此外,该数据集包含带有深度图真值的训练影响集,可用于训练神经网络。研究人员使用与现有研究[8-9]一样的训练集和测试集划分比例。BlendedMVS数据集[29]是一个包含超过17 000个MVS训练样本的大规模合成数据集,涵盖了113个场景,包括建筑、雕塑和小物体。由于没有官方评估工具,因此研究人员对其结果进行了比较。
3.2 训练
本文设计的模型是基于PyTorch 实现的,并在CVPMVSNET代码的基础上进行了改进。考虑到本网络是通过由粗到精的迭代估计深度图进行构建的,因此可以使用低分辨率的图像尺寸训练模型,从而提高训练速度。
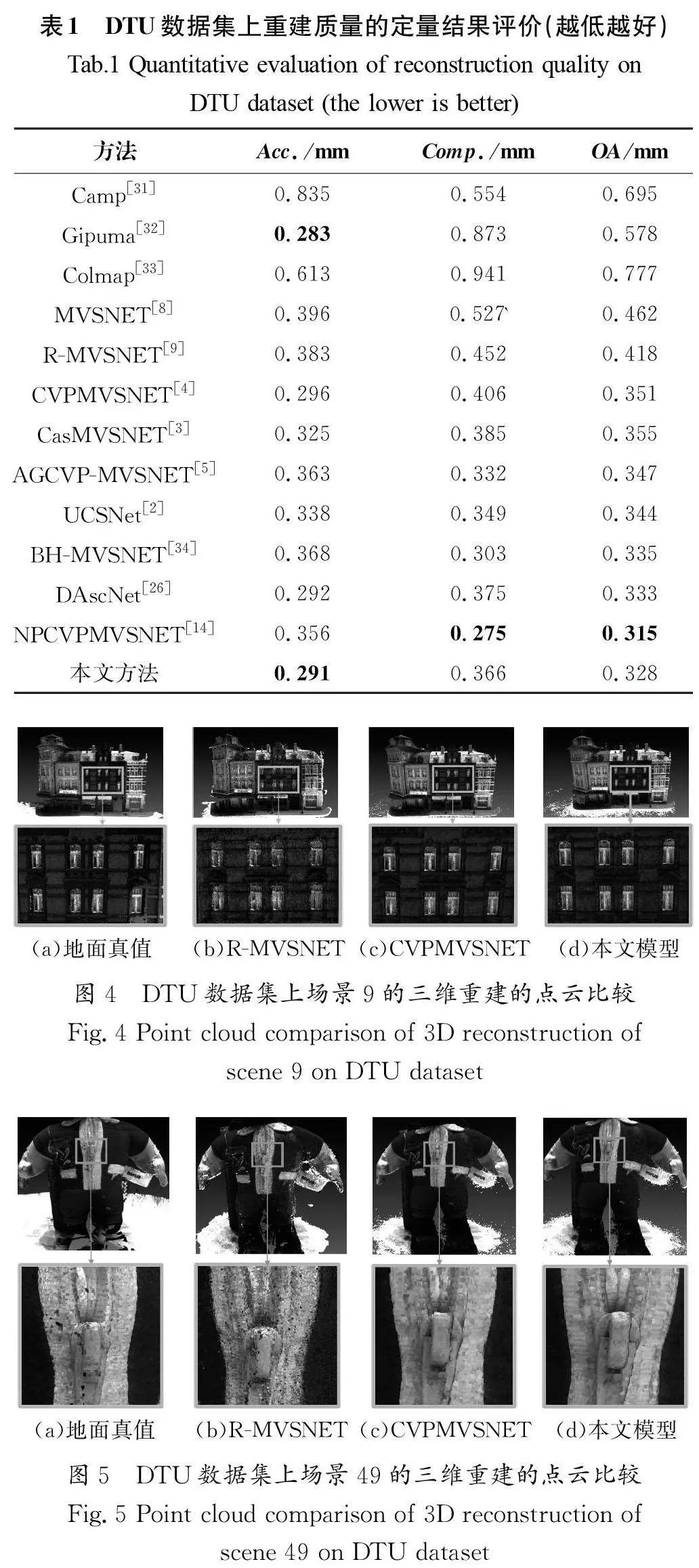
在DTU数据集上使用160×120的图像尺寸进行训练,训练后的权重文件在1600×1200全尺寸的测试集上进行评估。值得注意的是,为了能够训练三维卷积网络,要将图像尺寸的宽度和高度设置为能被16整除的值。此外,为了使注意力权重模块能够更好地工作,研究人员使用5张视图进行训练,并且在评估时使用同样的视图数量,以保证训练的权重文件能够更好地实现推断,在本文“3.5小节”的消融实验中展示不同视图的结果。使用ADAM(Adaptive Moment Estimation)[30]训练优化模型。网络在NVIDIA 2080Ti图形卡上训练29轮。设置初始学习率为0.001,然后在训练过程中,分别在完成第10轮、第12轮、第14轮和第20轮迭代之后,将学习率减半。研究人员使用修改过的fusibile工具箱预测深度图生成密集的点云[8]。对于定量评估DTU 数据集的重建效果,可以通过DTU数据集提供的官方MATLAB脚本计算精度和完整性。其中,精度(Acc.)是指深度图中估计深度与真实深度的一致程度,Comp.是指重建模型生成的点云与真实的点云之间的完整性,取两者均值为总体精度(OA),表示为公式(11):
3.3 DTU数据集上的结果
将本文改进的方法与传统的基于几何的方法和基于深度学习的方法进行比较。如表1所示,在训练视图数量为5、评估视图为4时,点云融合的精度为0.291,这一结果在目前重建效果中排名第二低,并且达到基于深度学习方法重建的最优水平,而总体精度为0.328,优于大部分其他方法。与初始的CVPMVSNET相比,精度提高了1.68%,完整度提高了9.85%,总体精度提高了6.55%,上述结果表明本文改进方法有效。
为了验证本文模型重建效果的优异性,在图4和图5中对比了2个DTU点云重建结果。图4展示了几种方法在DTU数据集场景9的三维重建效果。图4(c)和图4(d)都展现出相对较好的完整性,特别是在窗户部分,与图4(a)对比,图4(b)窗户细节略显模糊,图4(d)更关注微小的特征和纹理。
图5展示了几种方法在DTU数据集场景49的三维重建效果。与图5(c)和图5(d)都展现出相对较好的完整性,特别是在放大的拉链和衣领部分,图5(d)更加平滑和清晰。
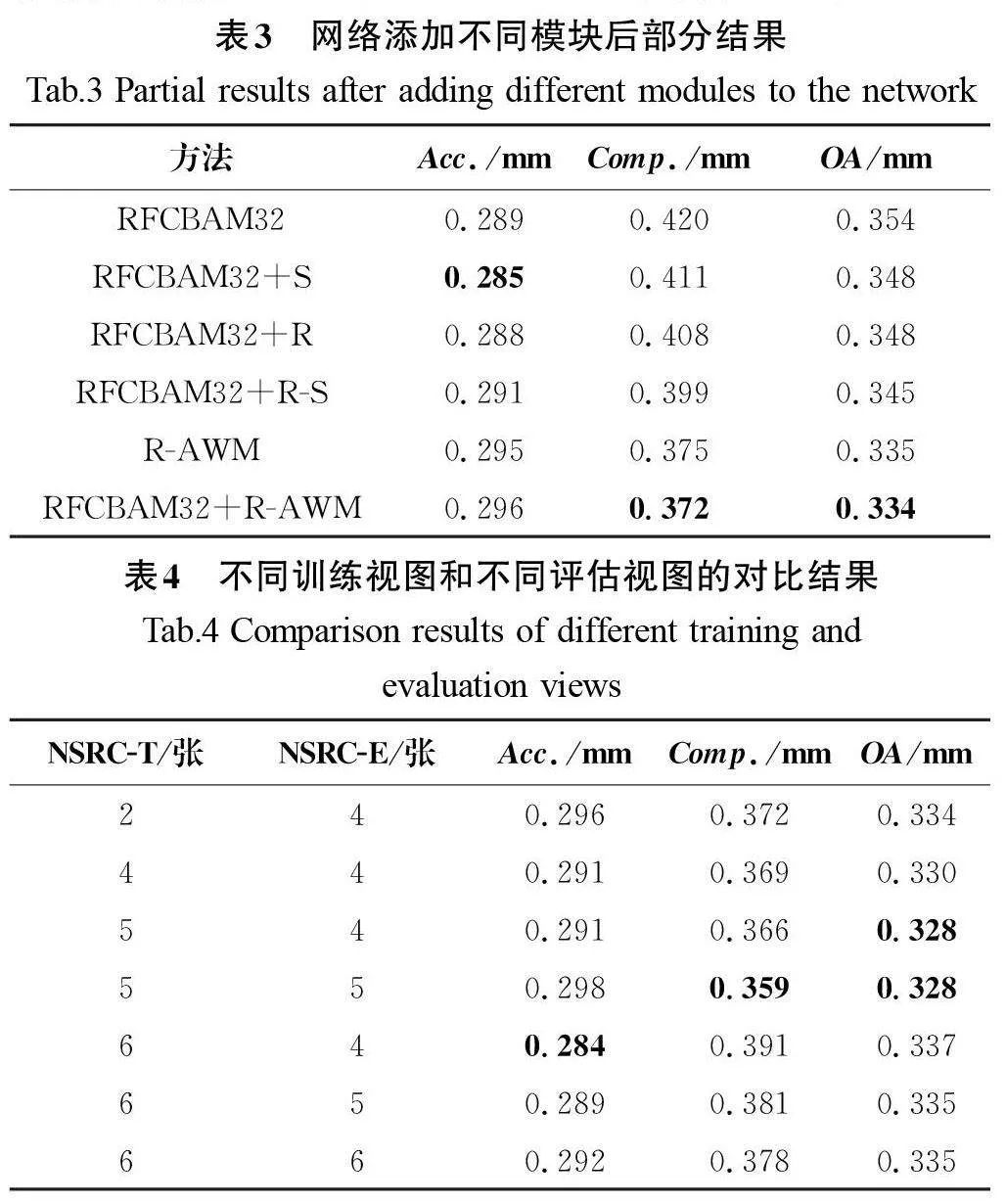
图6(b)和图6(c)展示了在DTU数据集的场景49、33及15(顺序从上到下)的部分视角的深度图对比。如图6(c)所示,与图6(b)相比,重建结果在边缘区域的清晰度和平滑度有所提高,如图6(c)中第一行的嘴巴、第二行兔子的尾巴部分及第三行城堡房顶的窗户轮廓,有更加高的清晰度和平滑度。
3.4BlendedMVS上的结果
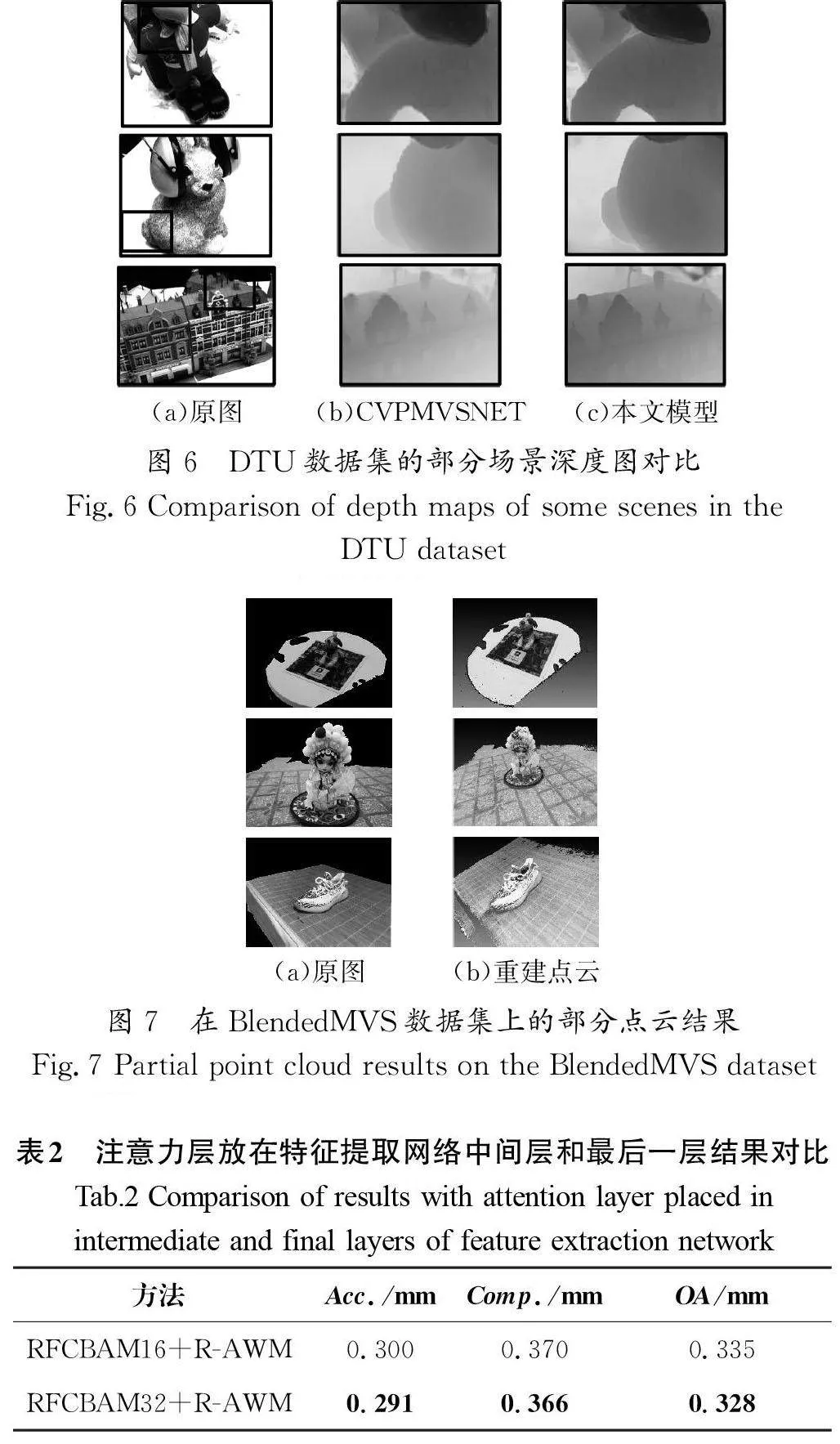
本文继续在BlendedMVS数据集评估本文方法的泛化能力。由于BlendedMVS数据集不包含官方提供的3D重建结果,因此只展示一些定性结果。本文使用DTU数据集上的训练视图为5的训练权重,依旧采用修改过的fusibile工具箱生成密集的点云及点云融合,在BlendedMVS官方2 048×1 536数据集上重设分辨率为1600×1184进行评估。图7展示了部分场景的重建结果,其中图7(a)是多视图图像某个视角的原图。不难看出,本文方法的训练权重不做任何更改,但在视角不固定的BlendedMVS数据集上依旧有较好的效果。
3.5 消融实验
对比注意力层放在特征提取网络中间层和最后一层的结果(表2)。保持和CVPMVSNET相同的训练参数,使用5张视图进行训练,结果显示RFCBAM 放在中间层时,Acc.、Comp.、OA值更低,对比放在最后一层时,准确度提高了3%,完整度提高了1.08%,总体精度提高了2.08%。上述结果表明注意力层在中间位置更有效。
表3在DTU数据集上对比分析了对CVPMVSNET在训练视图为2、评估视图为4时添加不同模块的指标对比结果。对比CVPMVSNET,只用注意力层替换特征提取中间层,准确度提高了2.3%,表明注意力层能更好地与地面真值点云的吻合。不添加注意力层,仅在图3两边GCE模块分别输入参考视角R和注意力加权特征图AWM,准确度提高了0.3%,完整性提高了8.2%,表明本文提出的加权特征图能更好地包含地面真实场景的信息。同时,使用RFCBAM32和R-AWM 的总体精度最低为0.335,比CVPMVSNET提高了4.56%。
此外,表4用表3中性能表现最好的方法,验证不同的训练视图(NSRC-T)和评估视图(NSRC-E)对DTU结果的影响,研究人员发现评估视图并不是越多越好。在训练和评估视图都为6的情况下,虽然准确度降到了0.284(目前最低为0.283),但是完整度升高导致总体精度下降,而在训练视图为5、评估视图为4时,结果最好。
4 结论(Conclusion)
针对MVS初始构建成本体积存在深度估计误差大的问题,本文提出了基于感受野的特征提取和注意力权重特征图匹配代价激励成本体积的方法。该方法改进了CVPMVSNET,在特征提取阶段能够充分提取像素之间的上下文信息,并且通过在粗层次使用注意力权重特征图对成本体积进行激励,避免了早期深度误差过大并迭代到更细的层次。在两个具有挑战性的基准数据集的实验结果表明,本文方法取得了良好的性能,并优于一些先进的方法,特别是与CVPMVSNET相比,重建的场景边缘深度更平滑,细节更丰富。未来,研究人员将进一步完善网络结构和激励成本体积方法,以降低内存需求,并提升对不同的应用程序的适应性。
作者简介:
郭晓栋(1998-),男,硕士生。研究领域:深度学习,计算机视觉。
贺平安(1969-),男,博士,教授。研究领域:数学模型,机器学习。
代 琦(1979-),男,博士,教授。研究领域:机器学习,图像处理,功能基因组分析。本文通信作者。
