
移动应用中的个性化新闻推荐算法研究与优化
2024-08-03 00:00:00王晋
无线互联科技 2024年12期



摘要:文章针对移动应用中的个性化新闻推荐算法进行了研究与优化,旨在提高用户体验和新闻推荐的精准度。文章重点研究内容推荐算法,该算法以标签为重点,算法整体过程包括数据准备、特征提取、相似度计算、推荐结果生成。所设计的算法通过Python语言以及NumPy、Pandas等库的支持得以实现。该研究可为移动应用中的个性化新闻推荐提供实用的技术方法,从而提升用户的满意度和参与度。
关键词:个性化新闻推荐;移动应用;内容推荐;余弦相似度
中图分类号:TP393文献标志码:A
0 引言
移动应用在当前社会中扮演着日益重要的角色,人们通过移动设备获取信息的方式已经成为主流。在这种情况下,个性化新闻推荐变得至关重要。随着信息爆炸式增长,用户面对的信息量变得庞大,而个性化新闻推荐能够根据用户的偏好和行为,提供定制化的新闻内容,从而节省用户的时间和精力,提高用户体验[1]。然而,移动应用中的个性化新闻推荐也面临着诸多挑战,包括数据稀疏性、算法复杂性、实时性要求等[2]。
本研究的意义在于通过对移动应用中的个性化新闻推荐算法进行研究和优化,可以有效提高用户的阅读体验。通过提供与用户兴趣相关的新闻内容,可以增加用户的参与度和黏性,进而提升移动应用的用户活跃度和用户忠诚度。此外,优化后的新闻推荐算法能够提高推荐的准确性,减少用户对不感兴趣内容的浏览,从而提高信息获取的效率。
1 基于内容的推荐算法设计与实现
1.1 算法框架
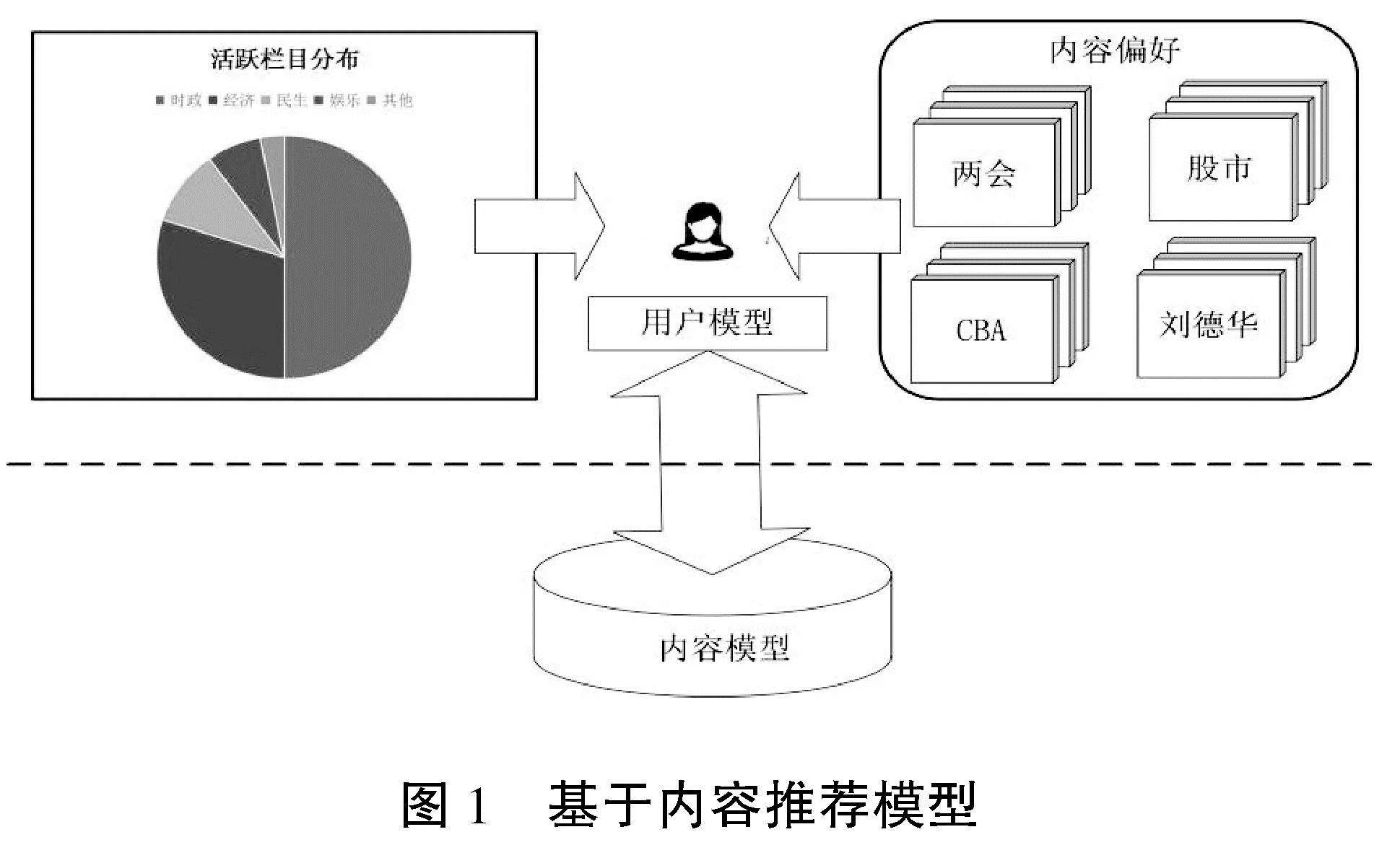
基于内容的推荐算法是个性化推荐系统中常用的一种方法,利用用户的历史行为和新闻内容特征进行推荐,以标签为关键点,将新闻内容分解为一系列标签;根据用户对新闻的浏览行为,将用户描述为一系列标签。这一算法的原理在于:通过对用户历史行为数据和新闻内容数据进行分析,提取用户兴趣标签和新闻内容标签,并计算它们之间的相似度,从而实现个性化推荐。基于内容推荐模型如图1所示。
1.2 数据准备
数据准备是个性化新闻推荐算法中至关重要的一步。这一阶段的目标是收集和处理用户的历史行为数据以及新闻内容数据,为后续的推荐模型训练和推荐结果生成做好准备[3]。
一方面,数据准备环节需要收集用户的历史阅读记录和新闻内容数据。用户的历史阅读记录包括用户点击过的新闻标题、类别、阅读时间等信息;新闻内容数据包括新闻的标题、摘要、正文内容、发布时间、类别标签等。这些数据可以通过用户浏览行为日志、点击记录以及新闻发布平台的应用程序编程接口等途径进行收集。另一方面,基于所收集数据,数据准备环节需要进行数据清洗和预处理。数据清洗的目的是去除重复数据、缺失数据以及异常数据,保证数据的质量和完整性;数据预处理的目的是对数据进行格式化、标准化,使其适用于算法的训练和分析。通过以上数据准备过程,可以获取用户的历史阅读记录和新闻内容数据,为后续的特征提取和模型训练过程做好准备[4-5]。
1.3 特征提取
在个性化新闻推荐算法中,特征提取是将原始数据转换为机器学习算法可以理解的特征表示过程。针对新闻内容数据,利用自然语言处理技术进行特征提取,常用的特征提取方法如表1所示。
以上特征提取方法可以根据实际情况选取,结合具体任务和数据集的特点使用。
1.4 相似度计算
在个性化新闻推荐算法中,相似度计算是衡量用户兴趣和新闻内容相关程度的重要步骤。本研究使用的相似度计算方法为余弦相似度(Cosine Similarity)等度量方法。假设用户向量为U=(u1,u2,…,um),新闻向量为N=(n1,n2,…,nn),其中,ui和ni分别为用户和新闻的特征值。
余弦相似度是衡量2个向量在方向上相似程度的一种方法,其计算公式为:
余弦相似度度量了2个向量之间的夹角,其值在[-1,1]范围内,数值越接近1表示2个向量的方向越相似,即用户对该新闻的兴趣越高。
1.5 推荐结果生成
1.5.1 推荐结果筛选
根据之前计算得到的用户与新闻的相似度,本文筛选出相似度较高的新闻作为推荐结果。所提方法设定一个相似度阈值,只推荐相似度得分高于阈值的新闻,以确保推荐的新闻与用户的兴趣相关性较高。
1.5.2 排序算法
推荐结果的排序可以根据不同的策略进行,常见的排序算法包括基于相似度的排序和基于评分的排序。基于相似度的排序将相似度高的新闻排在前面,而基于评分的排序则综合考虑相似度得分和其他因素(如新闻热度、时效性等)进行排序。
1.5.3 推荐结果呈现
所提算法将排序后的推荐结果呈现给用户,可以通过移动应用界面、推送通知等方式将推荐结果展示给用户,使用户方便地浏览和阅读推荐的新闻内容。
2 算法实现
2.1 数据加载与预处理
系统加载用户的历史阅读记录和新闻内容数据。可以使用Pandas库加载CSV文件或连接数据库。所提算法对数据进行预处理,包括去除重复值、处理缺失值等。
算法如下:
import pandas as pd
# 加载用户历史阅读记录和新闻内容数据
user_history = pd.read_csv('user_history.csv')
news_data = pd.read_csv('news_data.csv')
# 数据预处理
# 去除重复值
user_history = user_history.drop_duplicates()
news_data = news_data.drop_duplicates()
2.2 特征提取
针对新闻内容数据,利用自然语言处理技术进行特征提取,常见的特征包括关键词、词频、文本长度等。本文使用CountVectorizer、TfidfVectorizer等工具从文本中提取特征。
算法如下:
from sklearn.feature_extraction.text import Count Vectorizer
# 提取新闻内容的词频特征
vectorizer = CountVectorizer()
news_content_features = vectorizer.fit_transform(news_data['content'])
2.3 相似度计算
利用用户的历史阅读记录和新闻内容的特征,计算用户与新闻的相似度。常用的相似度计算方法包括余弦相似度。本文使用Scikit-learn库中的相似度计算函数实现相似度计算。
算法如下:
from sklearn.metrics.pairwise import cosine_similarity
# 计算用户历史阅读记录与新闻内容数据的相似度
user_news_similarity = cosine_similarity(user_history_features, news_content_features)
2.4 推荐结果生成
根据相似度计算结果生成个性化的推荐结果,选择相似度较高的新闻作为推荐结果,将未阅读的新闻推荐给用户。本文使用numpy.argsort()函数对相似度矩阵进行排序,选择前N个最相似的新闻作为推荐结果。
算法如下:
# 选择相似度较高的新闻作为推荐结果
top_news_indices = user_news_similarity.argsort()[:, ::-1][:, :top_n]
# 将推荐结果输出或展示给用户
for i, user_index in enumerate(top_news_indices):
recommended_news = news_data.iloc[user_index]['title']
print(f"用户{i+1}的推荐结果:{recommended_news}")
3 实验及分析
为验证优化后的个性化新闻推荐算法的实用性,本文招募了300个移动应用用户作为实验对象,分为实验组和对照组。实验组接受基于优化算法的推荐,而对照组将继续使用原有算法。本实验记录10天内用户的点击率、停留时间以及通过问卷调查收集的满意度数据。通过比较2组用户的点击率、停留时间和满意度调查结果,使用统计分析方法验证差异的显著性,评估优化算法对用户体验的影响。具体实验数据如表2所示。
数据显示,实验组用户相较于对照组表现出更高的点击率、稍长的平均停留时间以及更高的满意度调查得分。这表明优化后的个性化新闻推荐算法能够提供更相关和吸引人的新闻内容,在推荐相关性方面取得了显著的成效,有效地提高了用户的阅读体验和满意度。
4 结语
本文研究的基于内容的个性化新闻推荐算法在移动应用中得到了深入的分析与实现。实验结果表明,基于内容的推荐算法在移动应用中具有重要的应用前景,能够为用户提供个性化、准确的新闻推荐服务。未来可以进一步研究算法性能优化、相似度计算方法改进以及更多的特征提取技术探索,以满足不断变化的用户需求和推荐系统的发展。
参考文献
[1]黄瑶.人工智能时代新闻媒体创新发展对策探析[J].中国地市报人,2023(11):29-30.
[2]刁建雄,丁宁.智能流媒体时代的人机关系——Netflix内容推荐系统闭环设计一窥[J].青年记者,2023(23):113-115.
[3]谭跃龙.短视频个性化推荐服务对用户持续使用意愿的影响研究[J].商展经济,2023(23):118-121.
[4]王宇哲.基于内容的电影推荐算法研究[J].信息系统工程,2023(12):117-120.
[5]安丽达,王娟.推荐系统在新闻领域的研究综述[J].互联网周刊,2023(18):80-81.
Research and optimization of personalized news recommendation algorithm in mobile application
Abstract:This paper focuses on the research and optimization of personalized news recommendation algorithm in mobile application, aiming to improve user experience and the accuracy of news recommendation. The research primarily focuses on content-based recommendation algorithms, with an emphasis on tags. The overall process of the algorithm includes data preparation, feature extraction, similarity calculation, and recommendation result generation. The algorithm designed in this paper is implemented using the Python language with support from libraries such as NumPy and Pandas. Through this research, practical technical methods for personalized news recommendation in mobile applications are provided, thereby enhancing user satisfaction and engagement.
Key words: personalized news recommendation; mobile applications; content recommendation; cosine similarity
